 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visually Grounded Task and Motion Planning for Mobile Manipulation
Feb 24, 2022

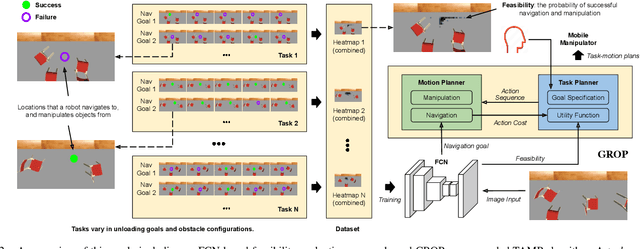
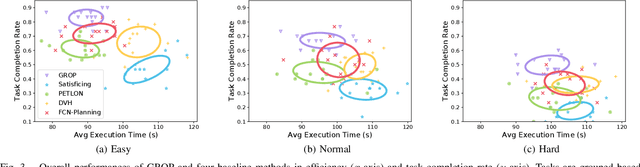
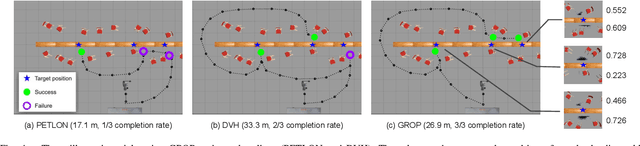
Task and motion planning (TAMP) algorithms aim to help robots achieve task-level goals, while maintaining motion-level feasibility. This paper focuses on TAMP domains that involve robot behaviors that take extended periods of time (e.g., long-distance navigation). In this paper, we develop a visual grounding approach to help robots probabilistically evaluate action feasibility, and introduce a TAMP algorithm, called GROP, that optimizes both feasibility and efficiency. We have collected a dataset that includes 96,000 simulated trials of a robot conducting mobile manipulation tasks, and then used the dataset to learn to ground symbolic spatial relationships for action feasibility evaluation. Compared with competitive TAMP baselines, GROP exhibited a higher task-completion rate while maintaining lower or comparable action costs. In addition to these extensive experiments in simulation, GROP is fully implemented and tested on a real robot system.
Fast Graph Neural Tangent Kernel via Kronecker Sketching
Dec 04, 2021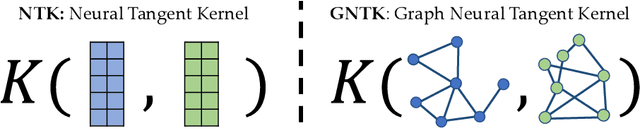

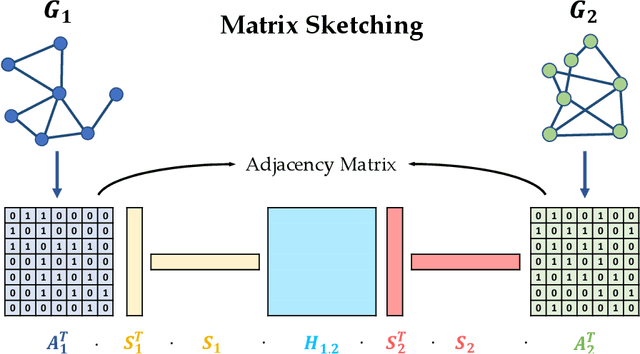
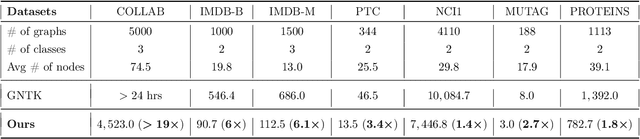
Many deep learning tasks have to deal with graphs (e.g., protein structures, social networks, source code abstract syntax trees). Due to the importance of these tasks, people turned to Graph Neural Networks (GNNs) as the de facto method for learning on graphs. GNNs have become widely applied due to their convincing performance. Unfortunately, one major barrier to using GNNs is that GNNs require substantial time and resources to train. Recently, a new method for learning on graph data is Graph Neural Tangent Kernel (GNTK) [Du, Hou, Salakhutdinov, Poczos, Wang and Xu 19]. GNTK is an application of Neural Tangent Kernel (NTK) [Jacot, Gabriel and Hongler 18] (a kernel method) on graph data, and solving NTK regression is equivalent to using gradient descent to train an infinite-wide neural network. The key benefit of using GNTK is that, similar to any kernel method, GNTK's parameters can be solved directly in a single step. This can avoid time-consuming gradient descent. Meanwhile, sketching has become increasingly used in speeding up various optimization problems, including solving kernel regression. Given a kernel matrix of $n$ graphs, using sketching in solving kernel regression can reduce the running time to $o(n^3)$. But unfortunately such methods usually require extensive knowledge about the kernel matrix beforehand, while in the case of GNTK we find that the construction of the kernel matrix is already $O(n^2N^4)$, assuming each graph has $N$ nodes. The kernel matrix construction time can be a major performance bottleneck when the size of graphs $N$ increases. A natural question to ask is thus whether we can speed up the kernel matrix construction to improve GNTK regression's end-to-end running time. This paper provides the first algorithm to construct the kernel matrix in $o(n^2N^3)$ running time.
A Survey on Dynamic Neural Networks for Natural Language Processing
Feb 15, 2022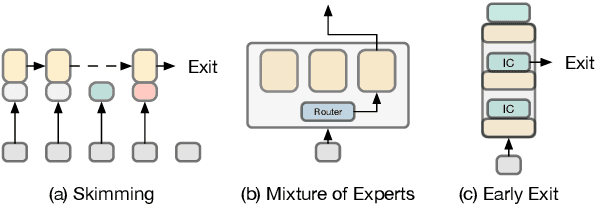
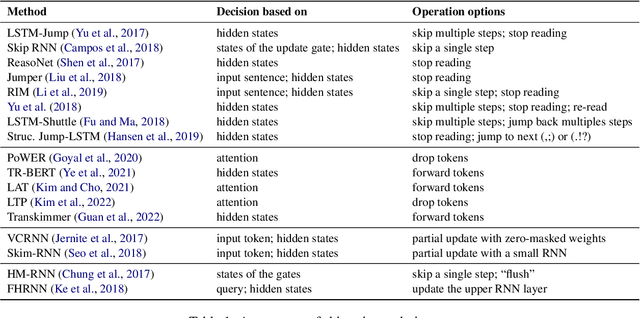
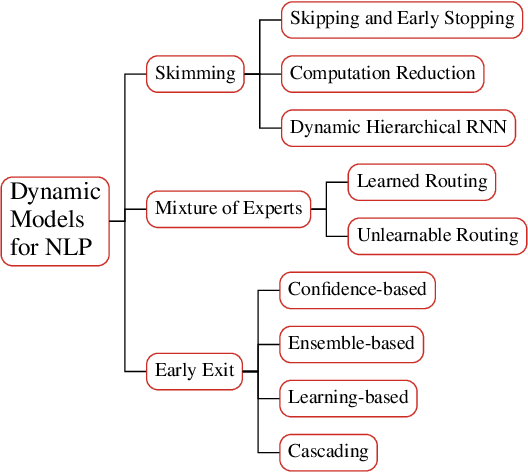

Effectively scaling large Transformer models is a main driver of recent advances in natural language processing. Dynamic neural networks, as an emerging research direction, are capable of scaling up neural networks with sub-linear increases in computation and time by dynamically adjusting their computational path based on the input. Dynamic neural networks could be a promising solution to the growing parameter numbers of pretrained language models, allowing both model pretraining with trillions of parameters and faster inference on mobile devices. In this survey, we summarize progress of three types of dynamic neural networks in NLP: skimming, mixture of experts, and early exit. We also highlight current challenges in dynamic neural networks and directions for future research.
AI Annotated Recommendations in an Efficient Visual Learning Environment with Emphasis on YouTube (AI-EVL)
Mar 10, 2022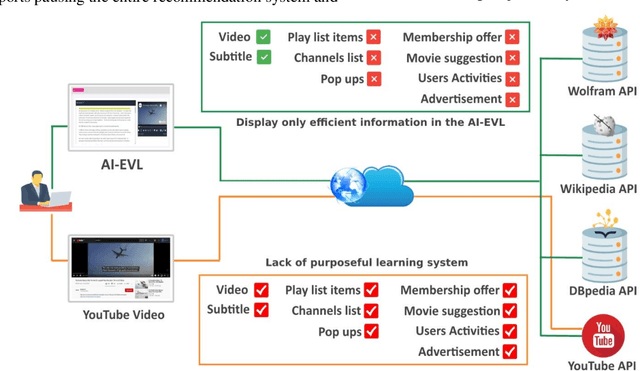
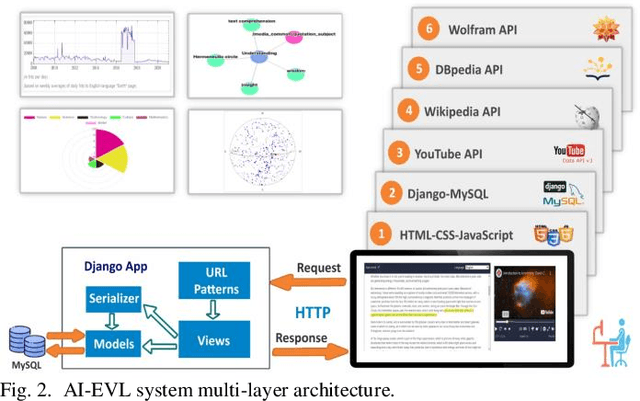
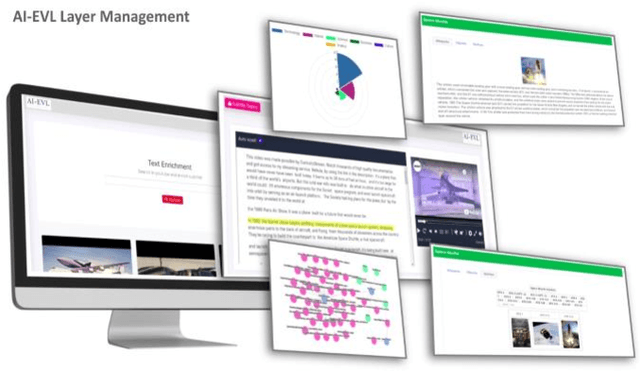
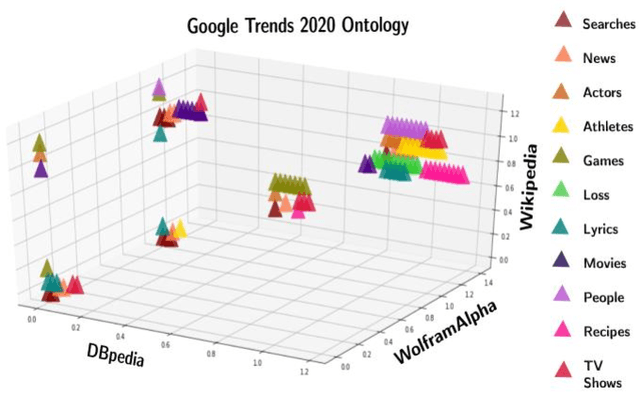
In this article, we create a system called AI-EVL. This is an annotated-based learning system. We extend AI to learning experience. If a user from the main YouTube page browses YouTube videos and a user from the AI-EVL system does the same, the amount of traffic used will be much less. It is due to ignoring unwanted contents which indicates a reduction in bandwidth usage too. This system is designed to be embedded with online learning tools and platforms to enrich their curriculum. In evaluating the system using Google 2020 trend data, we were able to extract rich ontological information for each data. Of the data collected, 34.86% belong to wolfram, 30.41% to DBpedia, and 34.73% to Wikipedia. The video subtitle information is displayed interactively and functionally to the user over time as the video is played. This effective visual learning system, due to the unique features, prevents the user's distraction and makes learning more focused. The information about the subtitle text is displayed in multiple layers including AI-annotated topics, Wikipedia/DBpedia, and Wolfram enriched texts via interactive and visual widgets.
Orthogonalising gradients to speed up neural network optimisation
Feb 14, 2022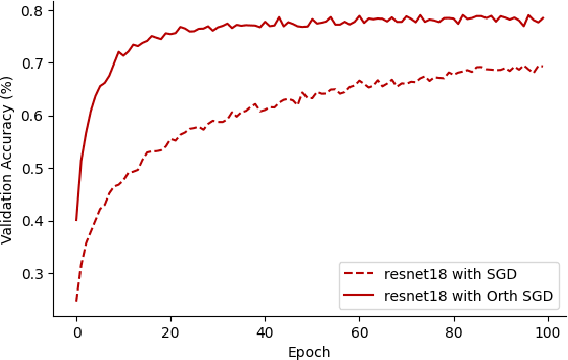
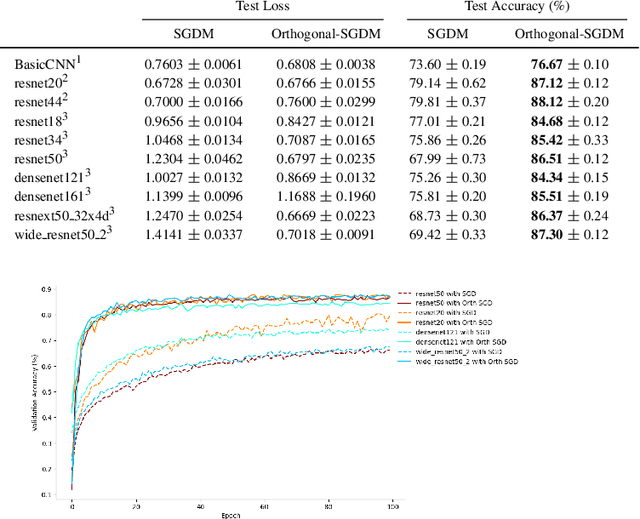
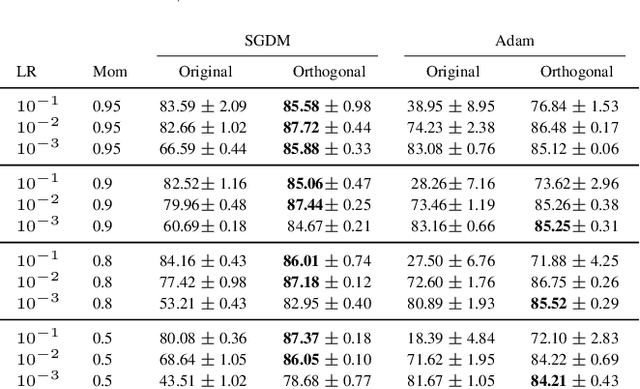
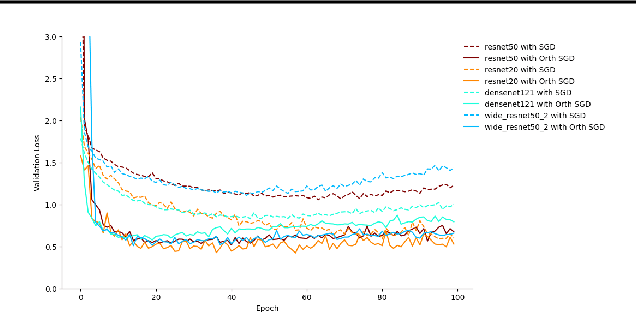
The optimisation of neural networks can be sped up by orthogonalising the gradients before the optimisation step, ensuring the diversification of the learned representations. We orthogonalise the gradients of the layer's components/filters with respect to each other to separate out the intermediate representations. Our method of orthogonalisation allows the weights to be used more flexibly, in contrast to restricting the weights to an orthogonalised sub-space. We tested this method on ImageNet and CIFAR-10 resulting in a large decrease in learning time, and also obtain a speed-up on the semi-supervised learning BarlowTwins. We obtain similar accuracy to SGD without fine-tuning and better accuracy for na\"ively chosen hyper-parameters.
Nonnegative-Constrained Joint Collaborative Representation with Union Dictionary for Hyperspectral Anomaly Detection
Mar 18, 2022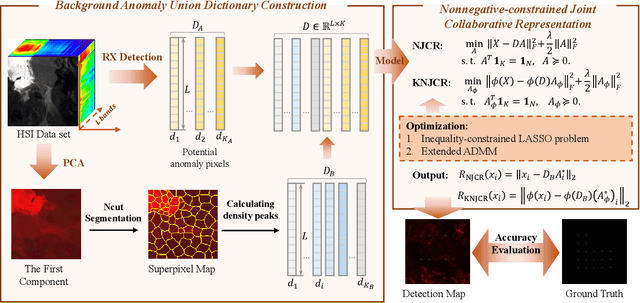
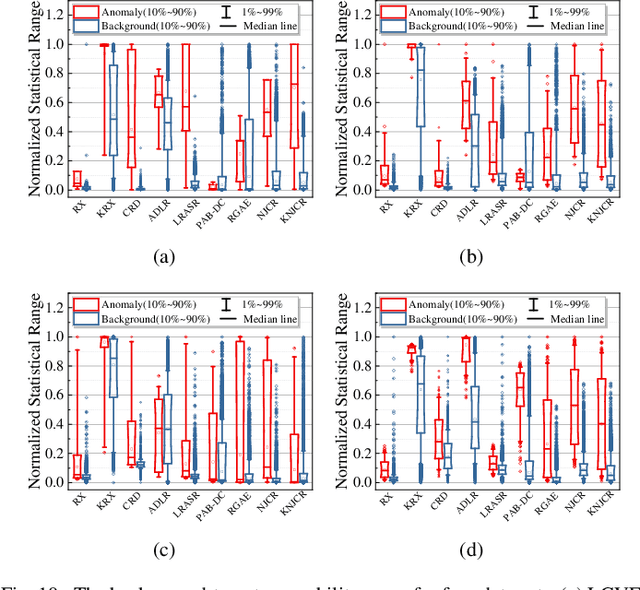
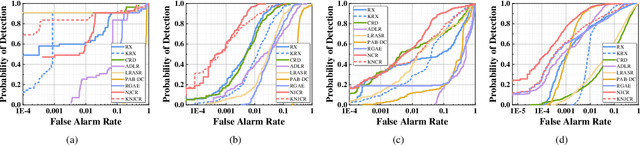
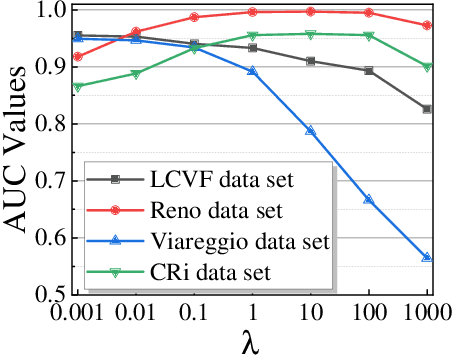
Recently, many collaborative representation-based (CR) algorithms have been proposed for hyperspectral anomaly detection. CR-based detectors approximate the image by a linear combination of background dictionaries and the coefficient matrix, and derive the detection map by utilizing recovery residuals. However, these CR-based detectors are often established on the premise of precise background features and strong image representation, which are very difficult to obtain. In addition, pursuing the coefficient matrix reinforced by the general $l_2$-min is very time consuming. To address these issues, a nonnegative-constrained joint collaborative representation model is proposed in this paper for the hyperspectral anomaly detection task. To extract reliable samples, a union dictionary consisting of background and anomaly sub-dictionaries is designed, where the background sub-dictionary is obtained at the superpixel level and the anomaly sub-dictionary is extracted by the pre-detection process. And the coefficient matrix is jointly optimized by the Frobenius norm regularization with a nonnegative constraint and a sum-to-one constraint. After the optimization process, the abnormal information is finally derived by calculating the residuals that exclude the assumed background information. To conduct comparable experiments, the proposed nonnegative-constrained joint collaborative representation (NJCR) model and its kernel version (KNJCR) are tested in four HSI data sets and achieve superior results compared with other state-of-the-art detectors.
Manipulating UAV Imagery for Satellite Model Training, Calibration and Testing
Mar 22, 2022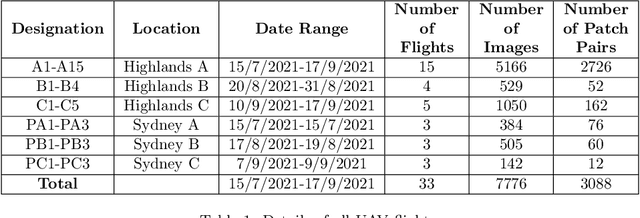


Modern livestock farming is increasingly data driven and frequently relies on efficient remote sensing to gather data over wide areas. High resolution satellite imagery is one such data source, which is becoming more accessible for farmers as coverage increases and cost falls. Such images can be used to detect and track animals, monitor pasture changes, and understand land use. Many of the data driven models being applied to these tasks require ground truthing at resolutions higher than satellites can provide. Simultaneously, there is a lack of available aerial imagery focused on farmland changes that occur over days or weeks, such as herd movement. With this goal in mind, we present a new multi-temporal dataset of high resolution UAV imagery which is artificially degraded to match satellite data quality. An empirical blurring metric is used to calibrate the degradation process against actual satellite imagery of the area. UAV surveys were flown repeatedly over several weeks, for specific farm locations. This 5cm/pixel data is sufficiently high resolution to accurately ground truth cattle locations, and other factors such as grass cover. From 33 wide area UAV surveys, 1869 patches were extracted and artificially degraded using an accurate satellite optical model to simulate satellite data. Geographic patches from multiple time periods are aligned and presented as sets, providing a multi-temporal dataset that can be used for detecting changes on farms. The geo-referenced images and 27,853 manually annotated cattle labels are made publicly available.
SwinUNet3D -- A Hierarchical Architecture for Deep Traffic Prediction using Shifted Window Transformers
Jan 17, 2022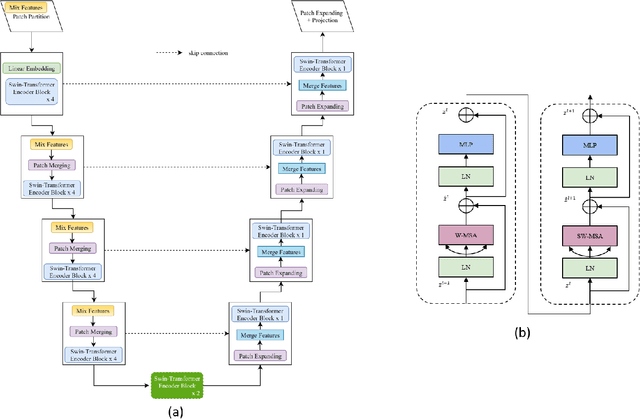
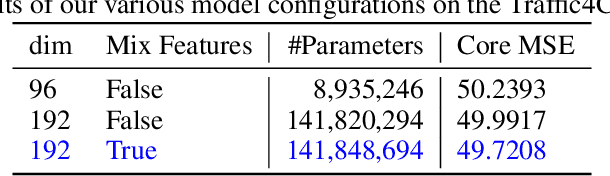

Traffic forecasting is an important element of mobility management, an important key that drives the logistics industry. Over the years, lots of work have been done in Traffic forecasting using time series as well as spatiotemporal dynamic forecasting. In this paper, we explore the use of vision transformer in a UNet setting. We completely remove all convolution-based building blocks in UNet, while using 3D shifted window transformer in both encoder and decoder branches. In addition, we experiment with the use of feature mixing just before patch encoding to control the inter-relationship of the feature while avoiding contraction of the depth dimension of our spatiotemporal input. The proposed network is tested on the data provided by Traffic Map Movie Forecasting Challenge 2021(Traffic4cast2021), held in the competition track of Neural Information Processing Systems (NeurIPS). Traffic4cast2021 task is to predict an hour (6 frames) of traffic conditions (volume and average speed)from one hour of given traffic state (12 frames averaged in 5 minutes time span). Source code is available online at https://github.com/bojesomo/Traffic4Cast2021-SwinUNet3D.
Respecting causality is all you need for training physics-informed neural networks
Mar 14, 2022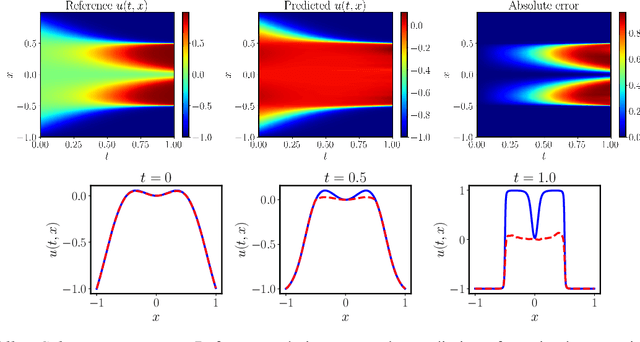
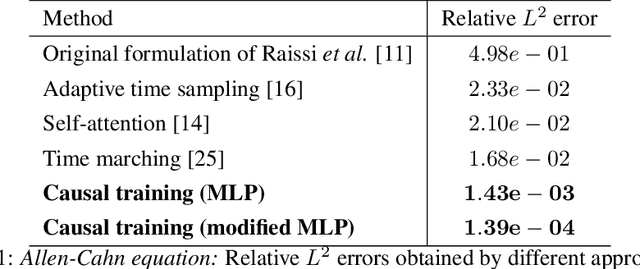
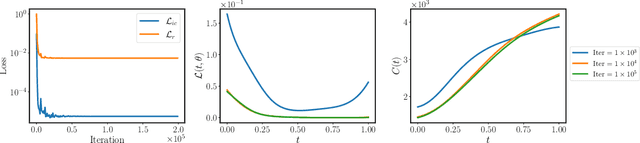
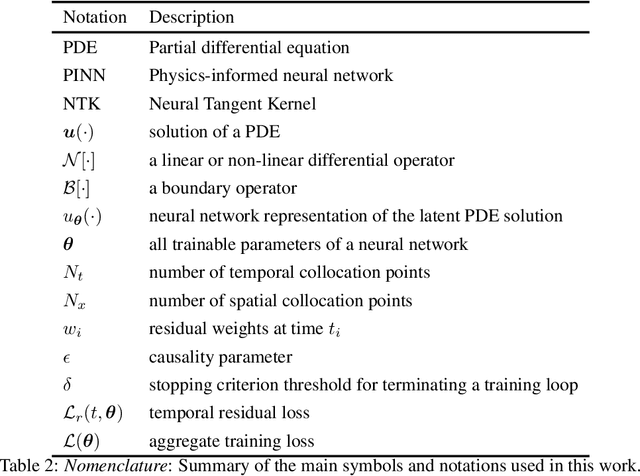
While the popularity of physics-informed neural networks (PINNs) is steadily rising, to this date PINNs have not been successful in simulating dynamical systems whose solution exhibits multi-scale, chaotic or turbulent behavior. In this work we attribute this shortcoming to the inability of existing PINNs formulations to respect the spatio-temporal causal structure that is inherent to the evolution of physical systems. We argue that this is a fundamental limitation and a key source of error that can ultimately steer PINN models to converge towards erroneous solutions. We address this pathology by proposing a simple re-formulation of PINNs loss functions that can explicitly account for physical causality during model training. We demonstrate that this simple modification alone is enough to introduce significant accuracy improvements, as well as a practical quantitative mechanism for assessing the convergence of a PINNs model. We provide state-of-the-art numerical results across a series of benchmarks for which existing PINNs formulations fail, including the chaotic Lorenz system, the Kuramoto-Sivashinsky equation in the chaotic regime, and the Navier-Stokes equations in the turbulent regime. To the best of our knowledge, this is the first time that PINNs have been successful in simulating such systems, introducing new opportunities for their applicability to problems of industrial complexity.
Functional Connectivity Based Classification of ADHD Using Different Atlases
Mar 01, 2022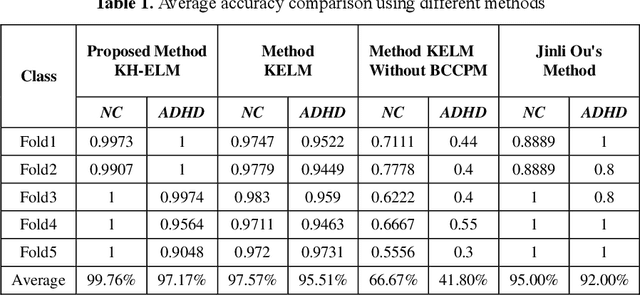
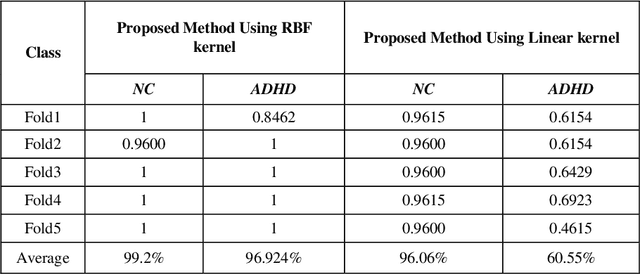
These days, computational diagnosis strategies of neuropsychiatric disorders are gaining attention day by day. It's critical to determine the brain's functional connectivity based on Functional-Magnetic-Resonance-Imaging(fMRI) to diagnose the disorder. It's known as a chronic disease, and millions of children amass the symptoms of this disease, so there is much vacuum for the researcher to formulate a model to improve the accuracy to diagnose ADHD accurately. In this paper, we consider the functional connectivity of a brain extracted using various time templates/Atlases. Local-Binary Encoding-Method (LBEM) algorithm is utilized for feature extraction, while Hierarchical- Extreme-Learning-Machine (HELM) is used to classify the extracted features. To validate our approach, fMRI data of 143 normal and 100 ADHD affected children is used for experimental purpose. Our experimental results are based on comparing various Atlases given as CC400, CC200, and AAL. Our model achieves high performance with CC400 as compared to other Atlases