 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis and Extraction of Tempo-Spatial Events in an Efficient Archival CDN with Emphasis on Telegram
Sep 16, 2023This paper presents an efficient archival framework for exploring and tracking cyberspace large-scale data called Tempo-Spatial Content Delivery Network (TS-CDN). Social media data streams are renewing in time and spatial dimensions. Various types of websites and social networks (i.e., channels, groups, pages, etc.) are considered spatial in cyberspace. Accurate analysis entails encompassing the bulk of data. In TS-CDN by applying the hash function on big data an efficient content delivery network is created. Using hash function rebuffs data redundancy and leads to conclude unique data archive in large-scale. This framework based on entered query allows for apparent monitoring and exploring data in tempo-spatial dimension based on TF-IDF score. Also by conformance from i18n standard, the Unicode problem has been dissolved. For evaluation of TS-CDN framework, a dataset from Telegram news channels from March 23, 2020 (1399-01-01), to September 21, 2020 (1399-06-31) on topics including Coronavirus (COVID-19), vaccine, school reopening, flood, earthquake, justice shares, petroleum, and quarantine exploited. By applying hash on Telegram dataset in the mentioned time interval, a significant reduction in media files such as 39.8% for videos (from 79.5 GB to 47.8 GB), and 10% for images (from 4 GB to 3.6 GB) occurred. TS-CDN infrastructure in a web-based approach has been presented as a service-oriented system. Experiments conducted on enormous time series data, including different spatial dimensions (i.e., Khabare Fouri, Khabarhaye Fouri, Akhbare Rouze Iran, and Akhbare Rasmi Telegram news channels), demonstrate the efficiency and applicability of the implemented TS-CDN framework.
AI Annotated Recommendations in an Efficient Visual Learning Environment with Emphasis on YouTube (AI-EVL)
Mar 10, 2022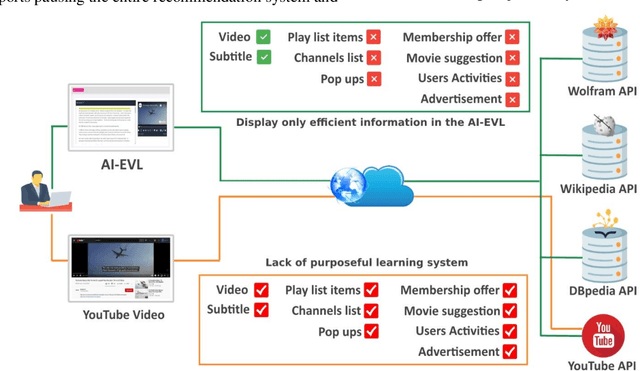
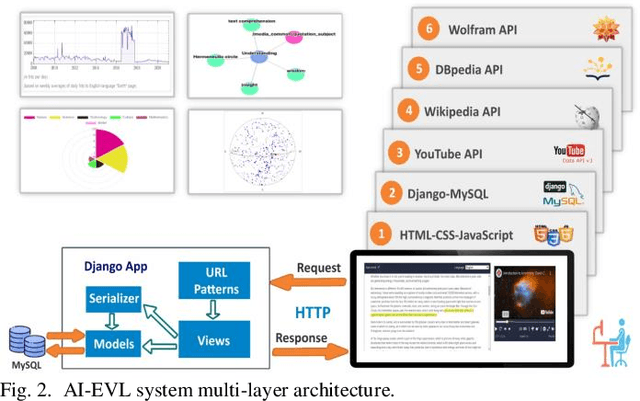
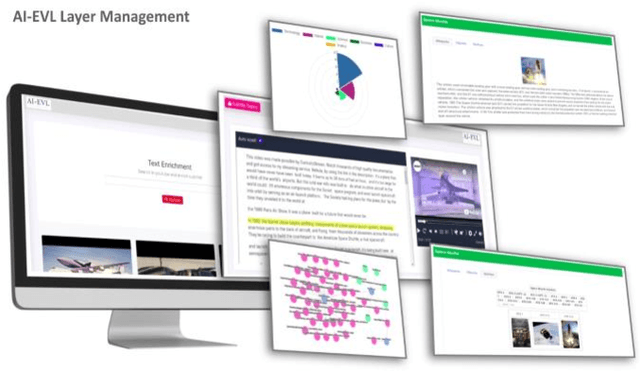
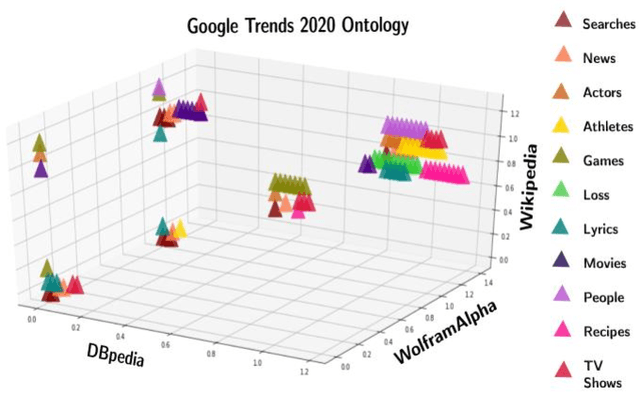
In this article, we create a system called AI-EVL. This is an annotated-based learning system. We extend AI to learning experience. If a user from the main YouTube page browses YouTube videos and a user from the AI-EVL system does the same, the amount of traffic used will be much less. It is due to ignoring unwanted contents which indicates a reduction in bandwidth usage too. This system is designed to be embedded with online learning tools and platforms to enrich their curriculum. In evaluating the system using Google 2020 trend data, we were able to extract rich ontological information for each data. Of the data collected, 34.86% belong to wolfram, 30.41% to DBpedia, and 34.73% to Wikipedia. The video subtitle information is displayed interactively and functionally to the user over time as the video is played. This effective visual learning system, due to the unique features, prevents the user's distraction and makes learning more focused. The information about the subtitle text is displayed in multiple layers including AI-annotated topics, Wikipedia/DBpedia, and Wolfram enriched texts via interactive and visual widgets.