 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Half-sibling regression meets exoplanet imaging: PSF modeling and subtraction using a flexible, domain knowledge-driven, causal framework
Apr 07, 2022
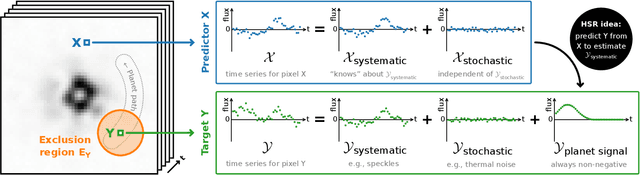
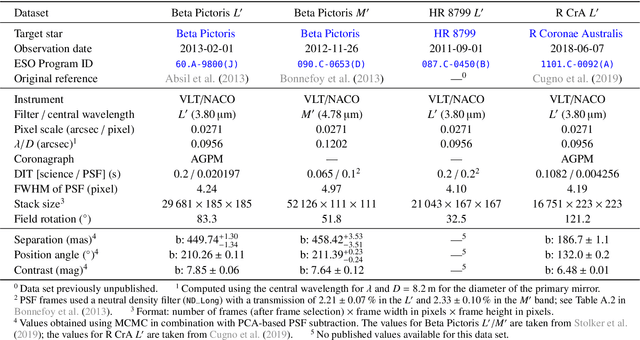
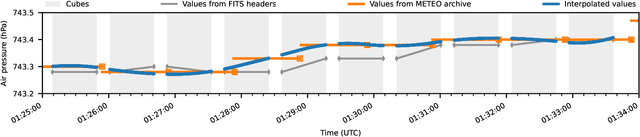
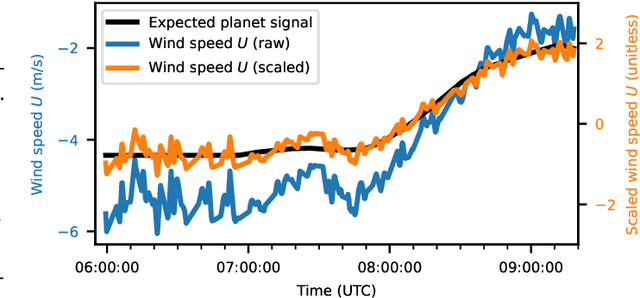
High-contrast imaging of exoplanets hinges on powerful post-processing methods to denoise the data and separate the signal of a companion from its host star, which is typically orders of magnitude brighter. Existing post-processing algorithms do not use all prior domain knowledge that is available about the problem. We propose a new method that builds on our understanding of the systematic noise and the causal structure of the data-generating process. Our algorithm is based on a modified version of half-sibling regression (HSR), a flexible denoising framework that combines ideas from the fields of machine learning and causality. We adapt the method to address the specific requirements of high-contrast exoplanet imaging data obtained in pupil tracking mode. The key idea is to estimate the systematic noise in a pixel by regressing the time series of this pixel onto a set of causally independent, signal-free predictor pixels. We use regularized linear models in this work; however, other (non-linear) models are also possible. In a second step, we demonstrate how the HSR framework allows us to incorporate observing conditions such as wind speed or air temperature as additional predictors. When we apply our method to four data sets from the VLT/NACO instrument, our algorithm provides a better false-positive fraction than PCA-based PSF subtraction, a popular baseline method in the field. Additionally, we find that the HSR-based method provides direct and accurate estimates for the contrast of the exoplanets without the need to insert artificial companions for calibration in the data sets. Finally, we present first evidence that using the observing conditions as additional predictors can improve the results. Our HSR-based method provides an alternative, flexible and promising approach to the challenge of modeling and subtracting the stellar PSF and systematic noise in exoplanet imaging data.
Pretraining Graph Neural Networks for few-shot Analog Circuit Modeling and Design
Apr 01, 2022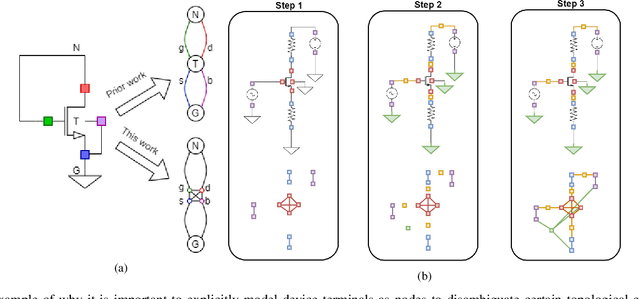
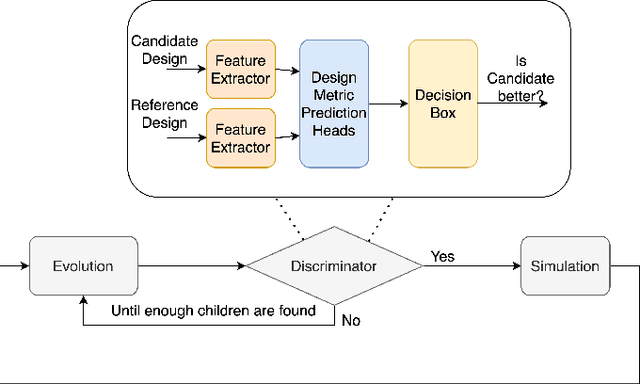
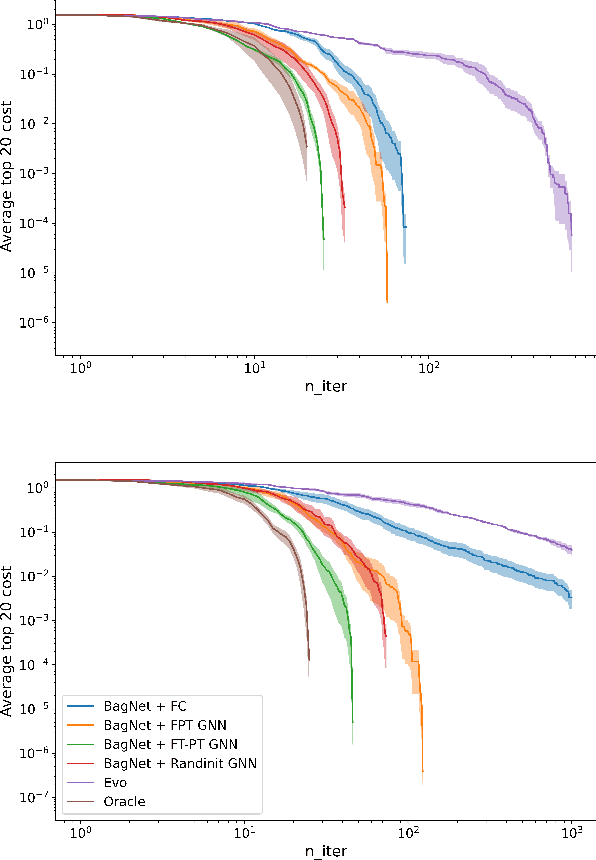

Being able to predict the performance of circuits without running expensive simulations is a desired capability that can catalyze automated design. In this paper, we present a supervised pretraining approach to learn circuit representations that can be adapted to new circuit topologies or unseen prediction tasks. We hypothesize that if we train a neural network (NN) that can predict the output DC voltages of a wide range of circuit instances it will be forced to learn generalizable knowledge about the role of each circuit element and how they interact with each other. The dataset for this supervised learning objective can be easily collected at scale since the required DC simulation to get ground truth labels is relatively cheap. This representation would then be helpful for few-shot generalization to unseen circuit metrics that require more time consuming simulations for obtaining the ground-truth labels. To cope with the variable topological structure of different circuits we describe each circuit as a graph and use graph neural networks (GNNs) to learn node embeddings. We show that pretraining GNNs on prediction of output node voltages can encourage learning representations that can be adapted to new unseen topologies or prediction of new circuit level properties with up to 10x more sample efficiency compared to a randomly initialized model. We further show that we can improve sample efficiency of prior SoTA model-based optimization methods by 2x (almost as good as using an oracle model) via fintuning pretrained GNNs as the feature extractor of the learned models.
Stuttgart Open Relay Degradation Dataset (SOReDD)
Apr 04, 2022
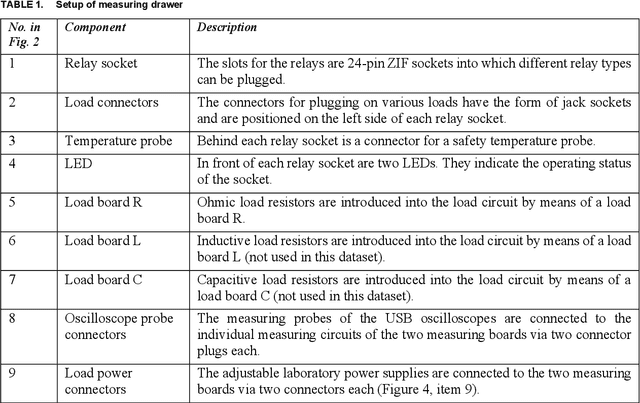


Real-life industrial use cases for machine learning oftentimes involve heterogeneous and dynamic assets, processes and data, resulting in a need to continuously adapt the learning algorithm accordingly. Industrial transfer learning offers to lower the effort of such adaptation by allowing the utilization of previously acquired knowledge in solving new (variants of) tasks. Being data-driven methods, the development of industrial transfer learning algorithms naturally requires appropriate datasets for training. However, open-source datasets suitable for transfer learning training, i.e. spanning different assets, processes and data (variants), are rare. With the Stuttgart Open Relay Degradation Dataset (SOReDD) we want to offer such a dataset. It provides data on the degradation of different electromechanical relays under different operating conditions, allowing for a large number of different transfer scenarios. Although such relays themselves are usually inexpensive standard components, their failure often leads to the failure of a machine as a whole due to their role as the central power switching element of a machine. The main cost factor in the event of a relay defect is therefore not the relay itself, but the reduced machine availability. It is therefore desirable to predict relay degradation as accurately as possible for specific applications in order to be able to replace relays in good time and avoid unplanned machine downtimes. Nevertheless, data-driven failure prediction for electromechanical relays faces the challenge that relay degradation behavior is highly dependent on the operating conditions, high-resolution measurement data on relay degradation behavior is only collected in rare cases, and such data can then only cover a fraction of the possible operating environments. Relays are thus representative of many other central standard components in automation technology.
Elastic 3D Wavefield Simulation on budget GPUs using the GLSL shading language
Dec 30, 2021
Forward wavefield simulation is an important step in Full Waveform Inversion systems. Fast simulations are instrumental to get inversion result in reasonable time frames. Most of research and software aims towards utilizing costly computer clusters composed of multiple CPUs and numerous high end GPUs to shorten the forward simulation time. Using this type of hardware has some disadvantages as: high cost, complex programming models and unavailability of resources. In this work, we present a finite difference elastic 3D wavefield forward simulation that takes advantage of any modern low end GPU, by using the GLSL shading language.Some of the advantages of using GLSL are: runs in any modern GPU, has a simplified computing and memory model and provides state of art performance thanks to its very well optimized vendor developed drivers. We show that our GLSL implementation easily outperforms a multicore CPU implementation in a modern PC. We further benchmark our result using a real seismic event, and show that we can get accurate simulations in reasonable time using our system.
Online Target Localization using Adaptive Belief Propagation in the HMM Framework
Mar 18, 2022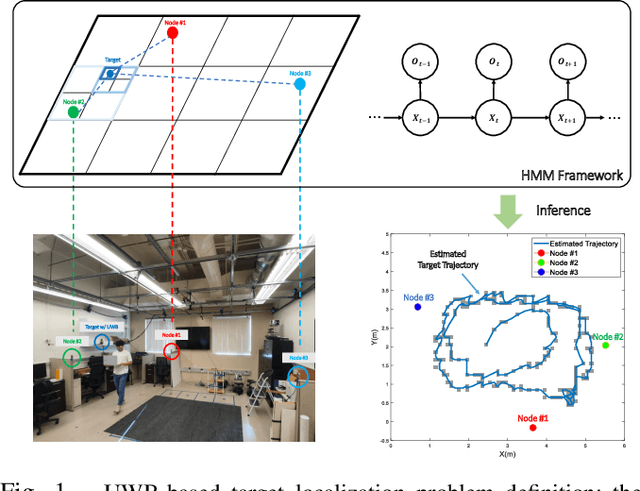
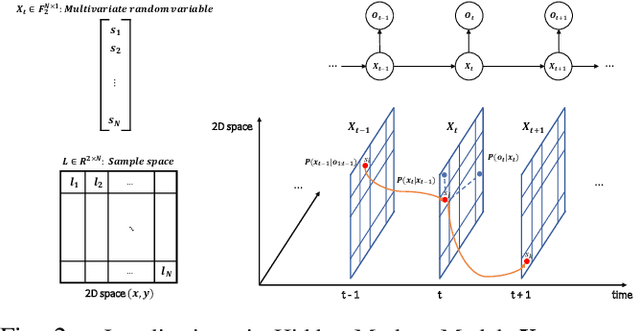
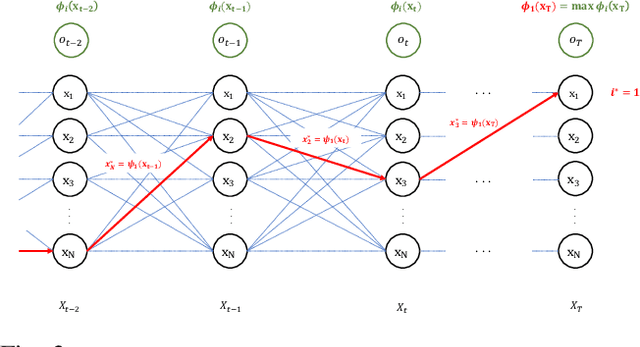
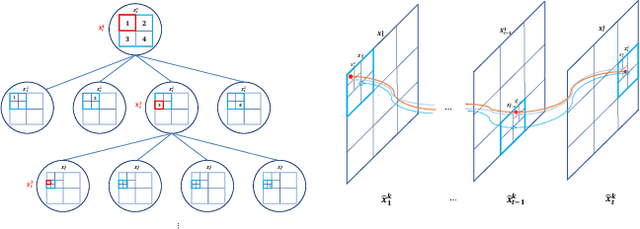
This paper proposes a novel adaptive sample space-based Viterbi algorithm for ultra-wideband (UWB) based target localization in an online manner. As the discretized area of interest is defined as a finite number of hidden states, the most probable trajectory of the unspecified agent is computed efficiently via dynamic programming in a Hidden Markov Model (HMM) framework. Furthermore, the approach has no requirements about Gaussian assumption and linearization for Bayesian calculation. However, the issue of computational complexity becomes very critical as the number of hidden states increases for estimation accuracy and large space. Previous localization works, based on discrete-state HMM, handle a small number of hidden variables, which represent specific paths or places. Inspired by the k-d Tree algorithm (e.g., quadtree) that is commonly used in the computer vision field, we propose a belief propagation in the most probable belief space with a low to high-resolution sequentially, thus reducing the required resources significantly. Our method has three advantages for localization: (a) no Gaussian assumptions and linearization, (b) handling the whole area of interest, not specific or small map representations, (c) reducing computation time and required memory size. Experimental tests demonstrate our results.
SleepPPG-Net: a deep learning algorithm for robust sleep staging from continuous photoplethysmography
Feb 11, 2022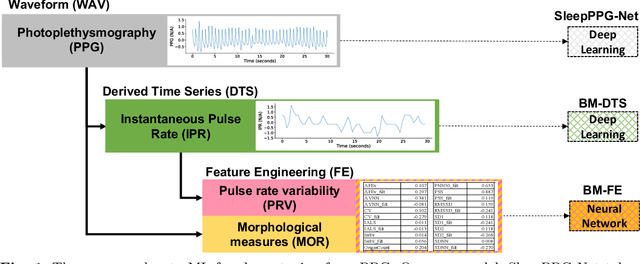
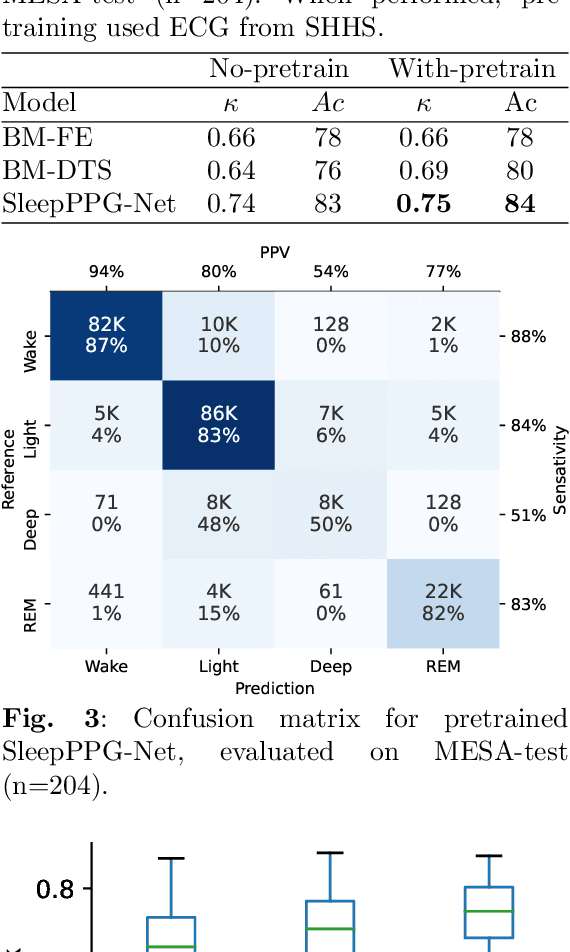
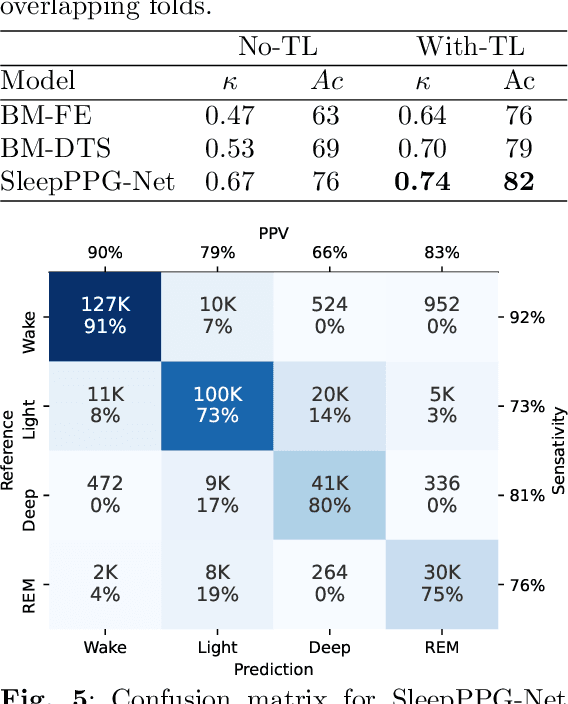
Introduction: Sleep staging is an essential component in the diagnosis of sleep disorders and management of sleep health. It is traditionally measured in a clinical setting and requires a labor-intensive labeling process. We hypothesize that it is possible to perform robust 4-class sleep staging using the raw photoplethysmography (PPG) time series and modern advances in deep learning (DL). Methods: We used two publicly available sleep databases that included raw PPG recordings, totalling 2,374 patients and 23,055 hours. We developed SleepPPG-Net, a DL model for 4-class sleep staging from the raw PPG time series. SleepPPG-Net was trained end-to-end and consists of a residual convolutional network for automatic feature extraction and a temporal convolutional network to capture long-range contextual information. We benchmarked the performance of SleepPPG-Net against models based on the best-reported state-of-the-art (SOTA) algorithms. Results: When benchmarked on a held-out test set, SleepPPG-Net obtained a median Cohen's Kappa ($\kappa$) score of 0.75 against 0.69 for the best SOTA approach. SleepPPG-Net showed good generalization performance to an external database, obtaining a $\kappa$ score of 0.74 after transfer learning. Perspective: Overall, SleepPPG-Net provides new SOTA performance. In addition, performance is high enough to open the path to the development of wearables that meet the requirements for usage in clinical applications such as the diagnosis and monitoring of obstructive sleep apnea.
The First AI4TSP Competition: Learning to Solve Stochastic Routing Problems
Jan 25, 2022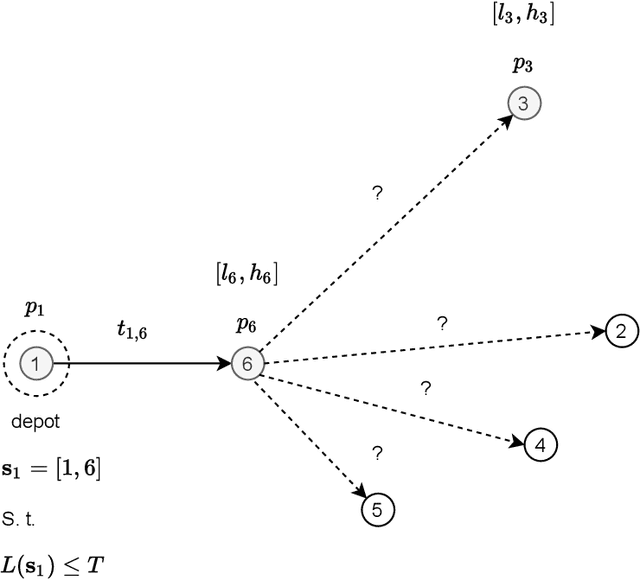
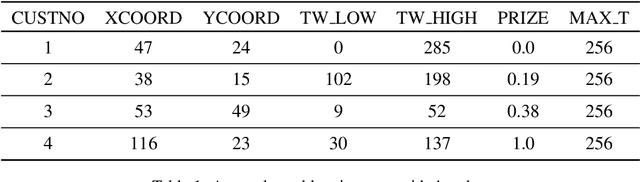
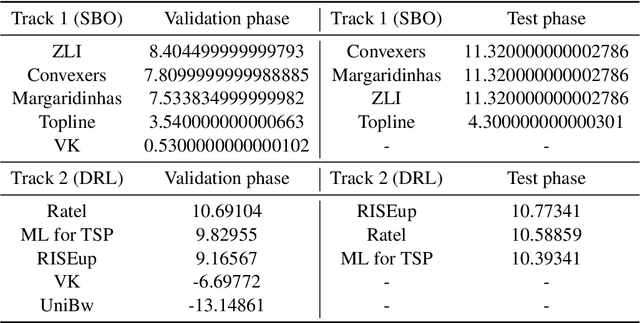
This paper reports on the first international competition on AI for the traveling salesman problem (TSP) at the International Joint Conference on Artificial Intelligence 2021 (IJCAI-21). The TSP is one of the classical combinatorial optimization problems, with many variants inspired by real-world applications. This first competition asked the participants to develop algorithms to solve a time-dependent orienteering problem with stochastic weights and time windows (TD-OPSWTW). It focused on two types of learning approaches: surrogate-based optimization and deep reinforcement learning. In this paper, we describe the problem, the setup of the competition, the winning methods, and give an overview of the results. The winning methods described in this work have advanced the state-of-the-art in using AI for stochastic routing problems. Overall, by organizing this competition we have introduced routing problems as an interesting problem setting for AI researchers. The simulator of the problem has been made open-source and can be used by other researchers as a benchmark for new AI methods.
Suum Cuique: Studying Bias in Taboo Detection with a Community Perspective
Mar 22, 2022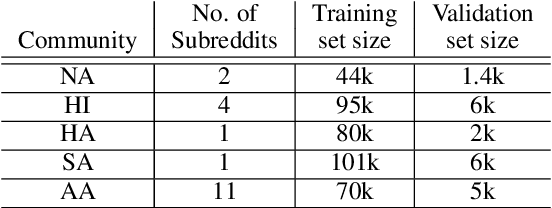
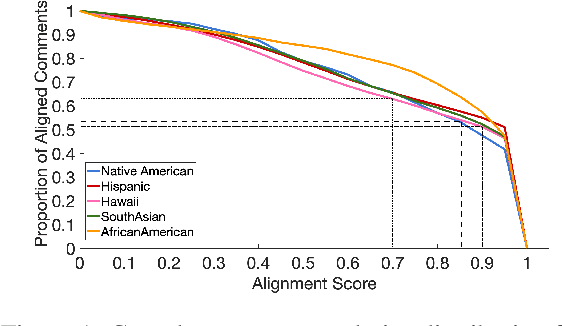
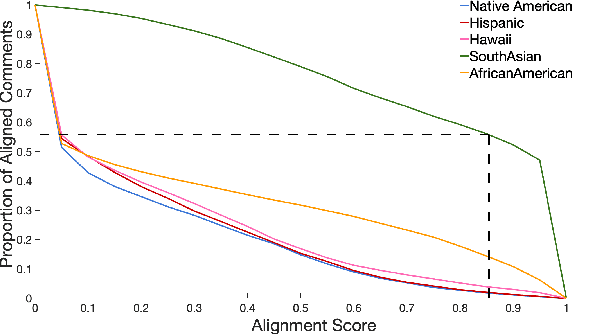
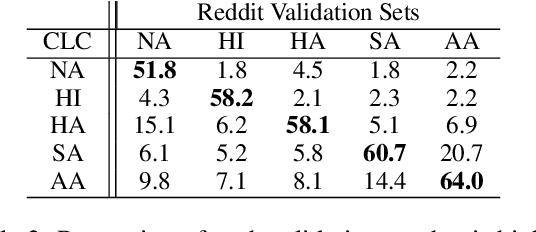
Prior research has discussed and illustrated the need to consider linguistic norms at the community level when studying taboo (hateful/offensive/toxic etc.) language. However, a methodology for doing so, that is firmly founded on community language norms is still largely absent. This can lead both to biases in taboo text classification and limitations in our understanding of the causes of bias. We propose a method to study bias in taboo classification and annotation where a community perspective is front and center. This is accomplished by using special classifiers tuned for each community's language. In essence, these classifiers represent community level language norms. We use these to study bias and find, for example, biases are largest against African Americans (7/10 datasets and all 3 classifiers examined). In contrast to previous papers we also study other communities and find, for example, strong biases against South Asians. In a small scale user study we illustrate our key idea which is that common utterances, i.e., those with high alignment scores with a community (community classifier confidence scores) are unlikely to be regarded taboo. Annotators who are community members contradict taboo classification decisions and annotations in a majority of instances. This paper is a significant step toward reducing false positive taboo decisions that over time harm minority communities.
Real-Time Violence Detection Using CNN-LSTM
Jul 15, 2021
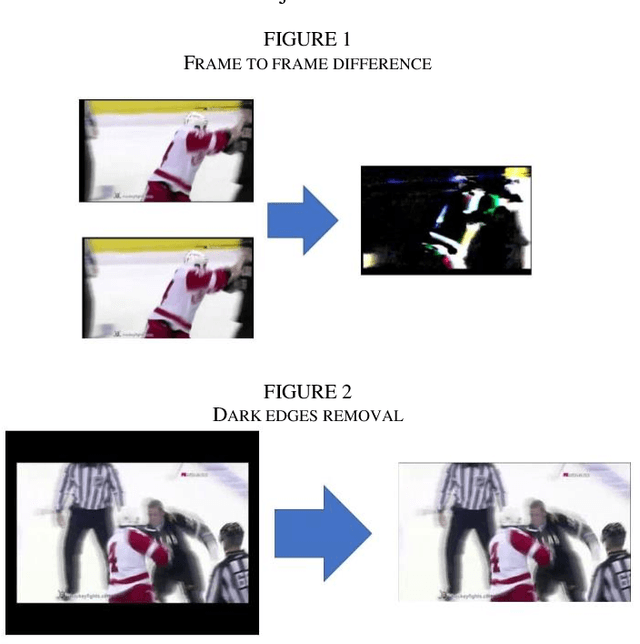

Violence rates however have been brought down about 57% during the span of the past 4 decades yet it doesn't change the way that the demonstration of violence actually happens, unseen by the law. Violence can be mass controlled sometimes by higher authorities, however, to hold everything in line one must "Microgovern" over each movement occurring in every road of each square. To address the butterfly effects impact in our setting, I made a unique model and a theorized system to handle the issue utilizing deep learning. The model takes the input of the CCTV video feeds and after drawing inference, recognizes if a violent movement is going on. And hypothesized architecture aims towards probability-driven computation of video feeds and reduces overhead from naively computing for every CCTV video feeds.
Occupancy Map Prediction for Improved Indoor Robot Navigation
Mar 08, 2022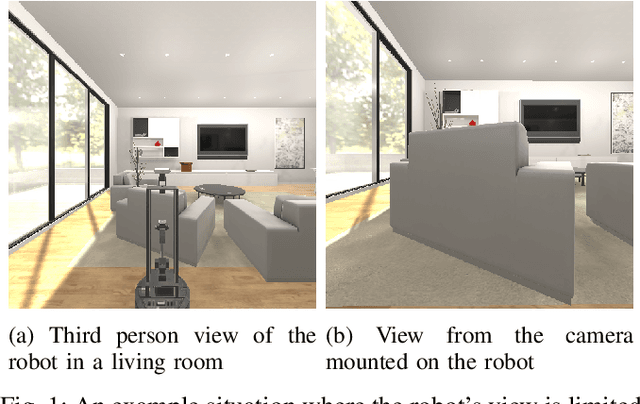
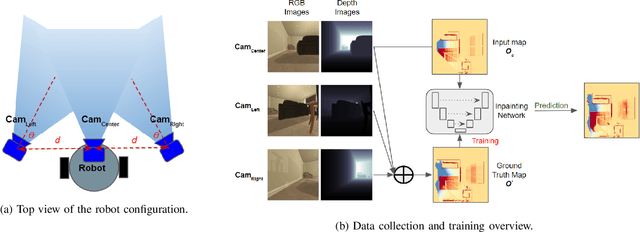
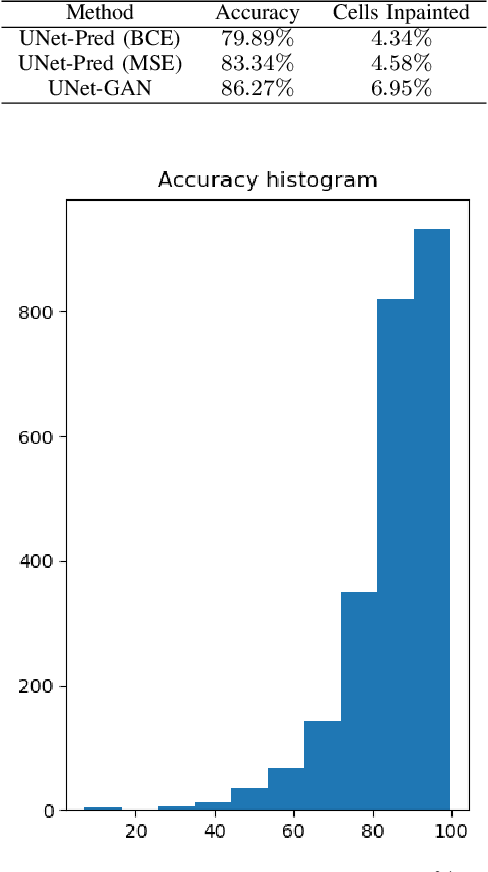
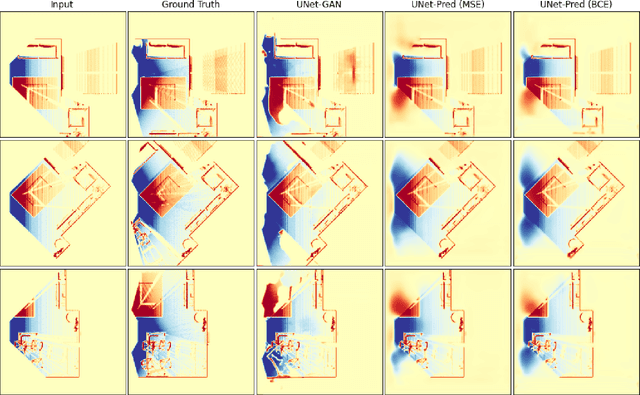
In the typical path planning pipeline for a ground robot, we build a map (e.g., an occupancy grid) of the environment as the robot moves around. While navigating indoors, a ground robot's knowledge about the environment may be limited by the occlusions in its surroundings. Therefore, the map will have many as-yet-unknown regions that may need to be avoided by a conservative planner. Instead, if a robot is able to correctly infer what its surroundings and occluded regions look like, the navigation can be further optimized. In this work, we propose an approach using pix2pix and UNet to infer the occupancy grid in unseen areas near the robot as an image-to-image translation task. Our approach simplifies the task of occupancy map prediction for the deep learning network and reduces the amount of data required compared to similar existing methods. We show that the predicted map improves the navigation time in simulations over the existing approaches.