 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Follow the Water: Finding Water, Snow and Clouds on Terrestrial Exoplanets with Photometry and Machine Learning
Mar 08, 2022
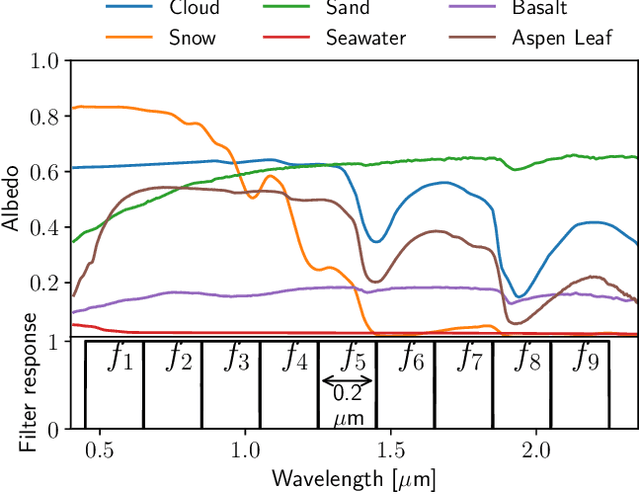
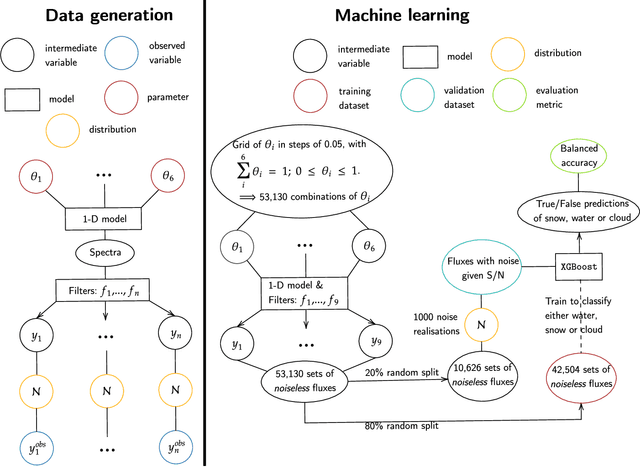
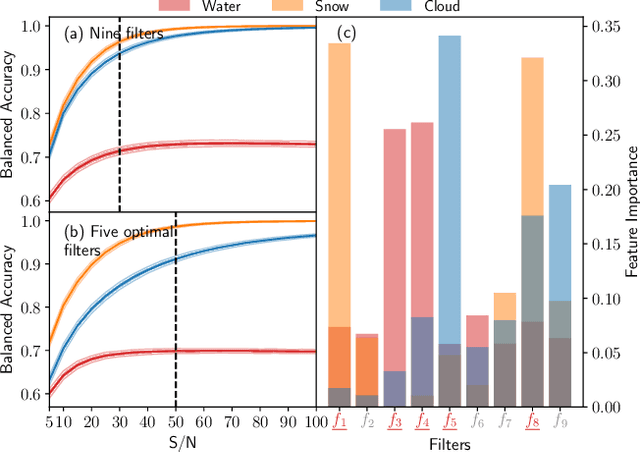
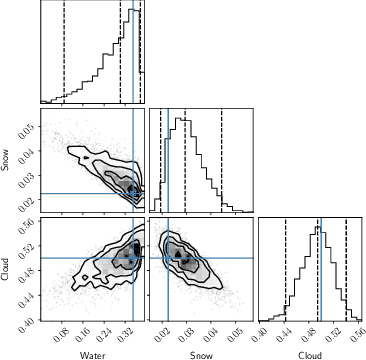
All life on Earth needs water. NASA's quest to follow the water links water to the search for life in the cosmos. Telescopes like JWST and mission concepts like HabEx, LUVOIR and Origins are designed to characterise rocky exoplanets spectroscopically. However, spectroscopy remains time-intensive and therefore, initial characterisation is critical to prioritisation of targets. Here, we study machine learning as a tool to assess water's existence through broadband-filter reflected photometric flux on Earth-like exoplanets in three forms: seawater, water-clouds and snow; based on 53,130 spectra of cold, Earth-like planets with 6 major surfaces. XGBoost, a well-known machine learning algorithm, achieves over 90\% balanced accuracy in detecting the existence of snow or clouds for S/N$\gtrsim 20$, and 70\% for liquid seawater for S/N $\gtrsim 30$. Finally, we perform mock Bayesian analysis with Markov-chain Monte Carlo with five filters identified to derive exact surface compositions to test for retrieval feasibility. The results show that the use of machine learning to identify water on the surface of exoplanets from broadband-filter photometry provides a promising initial characterisation tool of water in different forms. Planned small and large telescope missions could use this to aid their prioritisation of targets for time-intense follow-up observations.
Design of an Internet of Things System for Smart Hospitals
Apr 06, 2022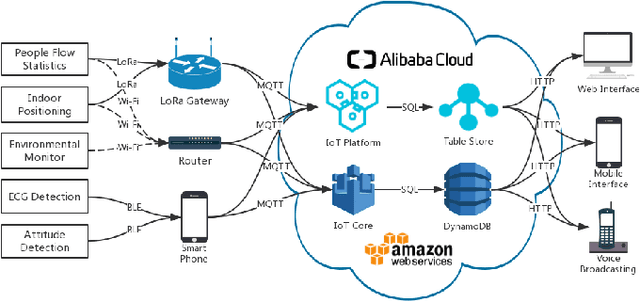
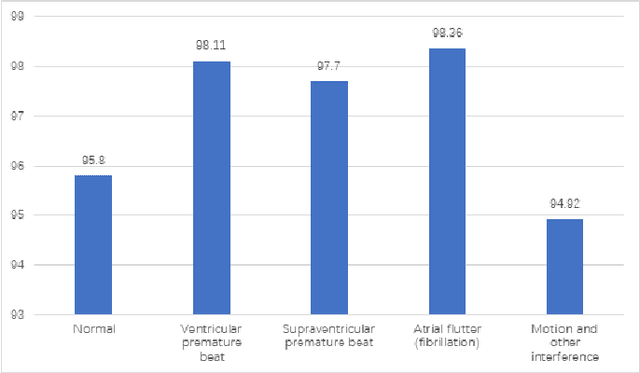
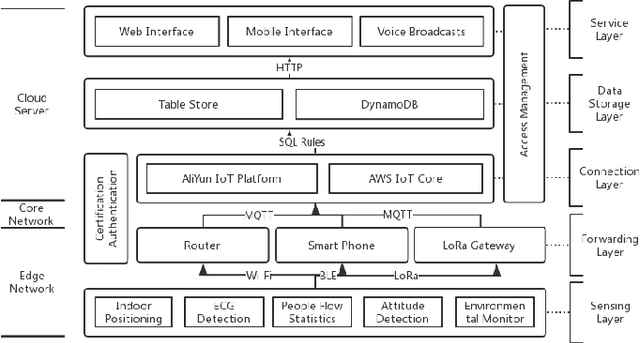
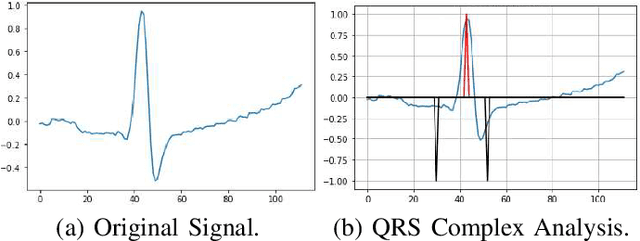
With the fast advancement of smart devices and Internet of Things (IoT) technologies, certain established situations are opening up new avenues of exploration. Particularly in the sphere of healthcare, the diverse and big population, the complicated and professional data, and the stringent environmental requirements for certain medical scenes and equipment all impose exceptionally high standards on hospital administration. As a result, an effective and secure Internet of things system is critical. This article proposes an IoT system that might be used in hospitals for a variety of purposes. This system collects data by LoRa, Wi-Fi, and other ways, uploads it to a cloud platform for processing over a secure connection, and then feeds it back to users in real-time via the user interface. This system enables precise indoor localization through the use of UWB, ECG signal detection, environmental monitoring, and data on people flow.
A Neural Vocoder Based Packet Loss Concealment Algorithm
Mar 26, 2022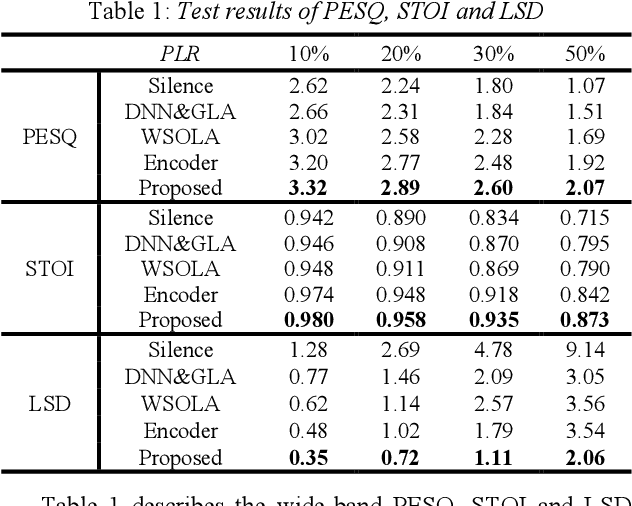
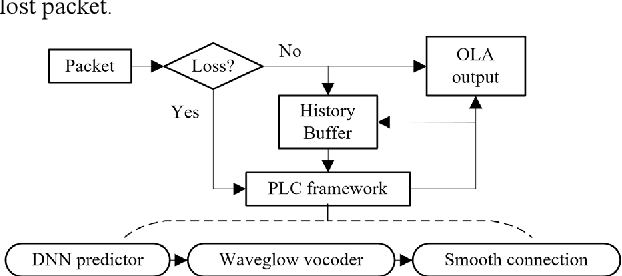
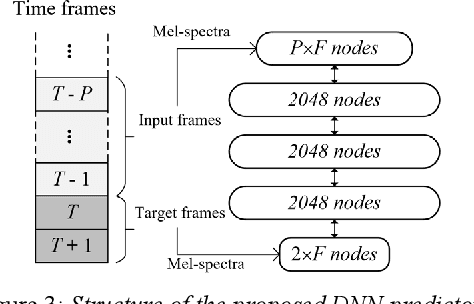
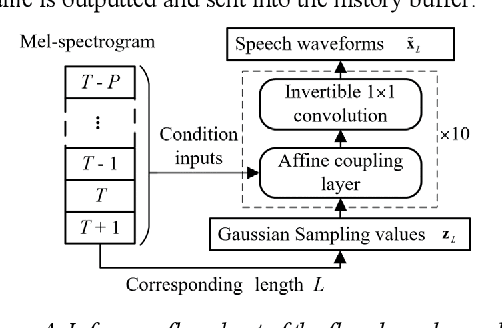
The packet loss problem seriously affects the quality of service in Voice over IP (VoIP) sceneries. In this paper, we investigated online receiver-based packet loss concealment which is much more portable and applicable. For ensuring the speech naturalness, rather than directly processing time-domain waveforms or separately reconstructing amplitudes and phases in frequency domain, a flow-based neural vocoder is adopted to generate the substitution waveform of lost packet from Mel-spectrogram which is generated from history contents by a well-designed neural predictor. Furthermore, a waveform similarity-based smoothing post-process is created to mitigate the discontinuity of speech and avoid the artifacts. The experimental results show the outstanding performance of the proposed method.
Anomaly Detection of Test-Time Evasion Attacks using Class-conditional Generative Adversarial Networks
May 21, 2021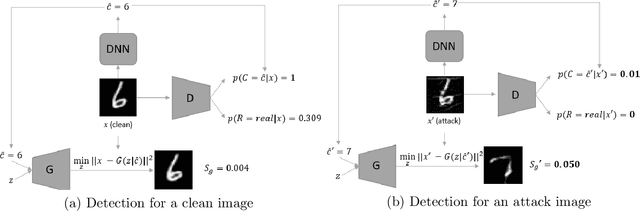
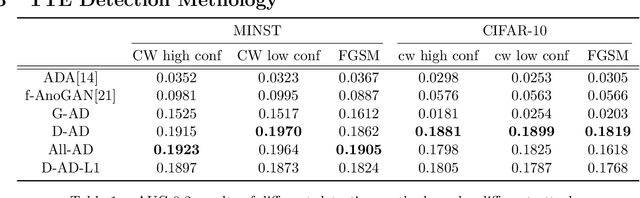
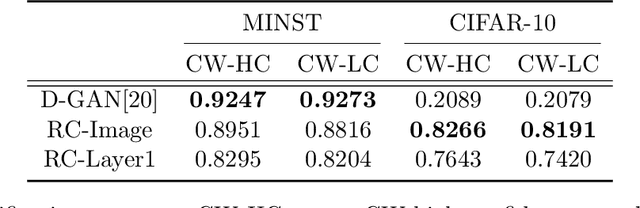
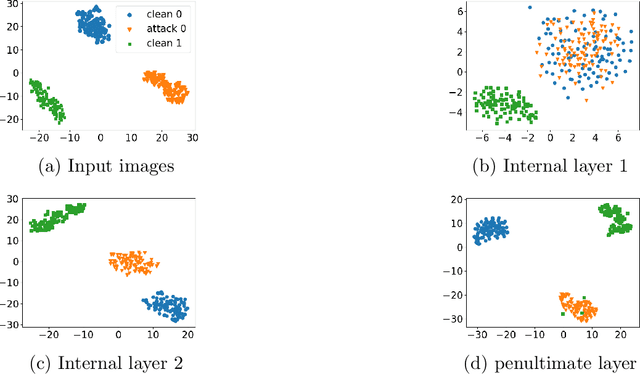
Deep Neural Networks (DNNs) have been shown vulnerable to adversarial (Test-Time Evasion (TTE)) attacks which, by making small changes to the input, alter the DNN's decision. We propose an attack detector based on class-conditional Generative Adversarial Networks (GANs). We model the distribution of clean data conditioned on the predicted class label by an Auxiliary Classifier GAN (ACGAN). Given a test sample and its predicted class, three detection statistics are calculated using the ACGAN Generator and Discriminator. Experiments on image classification datasets under different TTE attack methods show that our method outperforms state-of-the-art detection methods. We also investigate the effectiveness of anomaly detection using different DNN layers (input features or internal-layer features) and demonstrate that anomalies are harder to detect using features closer to the DNN's output layer.
R2LIVE: A Robust, Real-time, LiDAR-Inertial-Visual tightly-coupled state Estimator and mapping
Feb 24, 2021
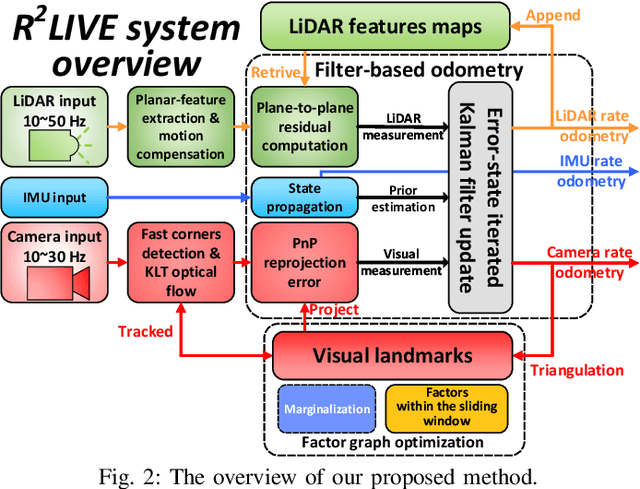
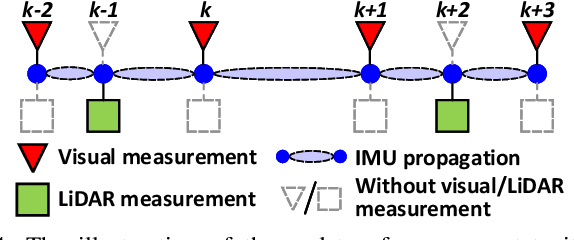
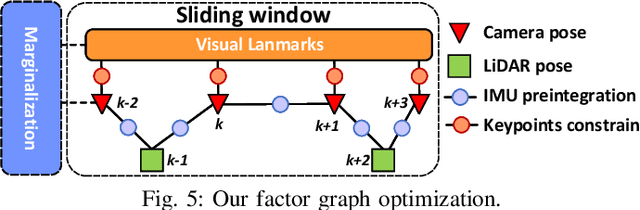
In this letter, we propose a robust, real-time tightly-coupled multi-sensor fusion framework, which fuses measurement from LiDAR, inertial sensor, and visual camera to achieve robust and accurate state estimation. Our proposed framework is composed of two parts: the filter-based odometry and factor graph optimization. To guarantee real-time performance, we estimate the state within the framework of error-state iterated Kalman-filter, and further improve the overall precision with our factor graph optimization. Taking advantage of measurement from all individual sensors, our algorithm is robust enough to various visual failure, LiDAR-degenerated scenarios, and is able to run in real-time on an on-board computation platform, as shown by extensive experiments conducted in indoor, outdoor, and mixed environment of different scale. Moreover, the results show that our proposed framework can improve the accuracy of state-of-the-art LiDAR-inertial or visual-inertial odometry. To share our findings and to make contributions to the community, we open source our codes on our Github.
Enabling faster and more reliable sonographic assessment of gestational age through machine learning
Mar 22, 2022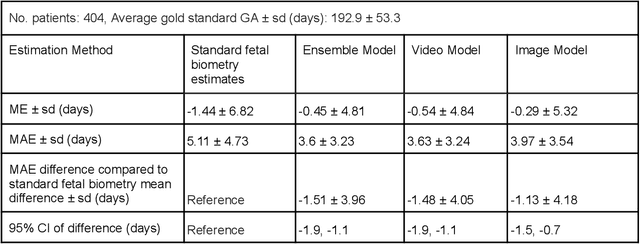
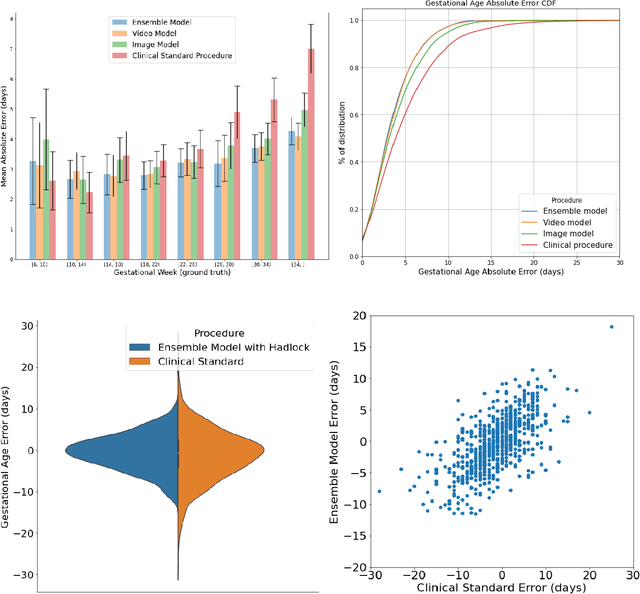
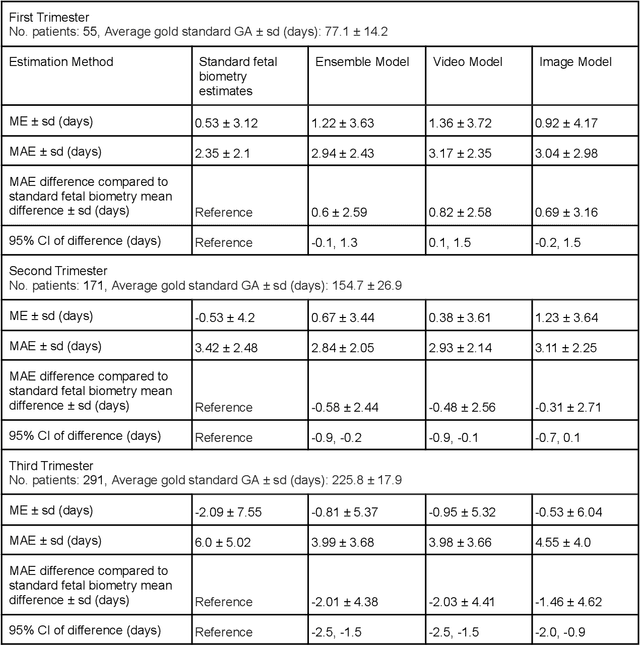
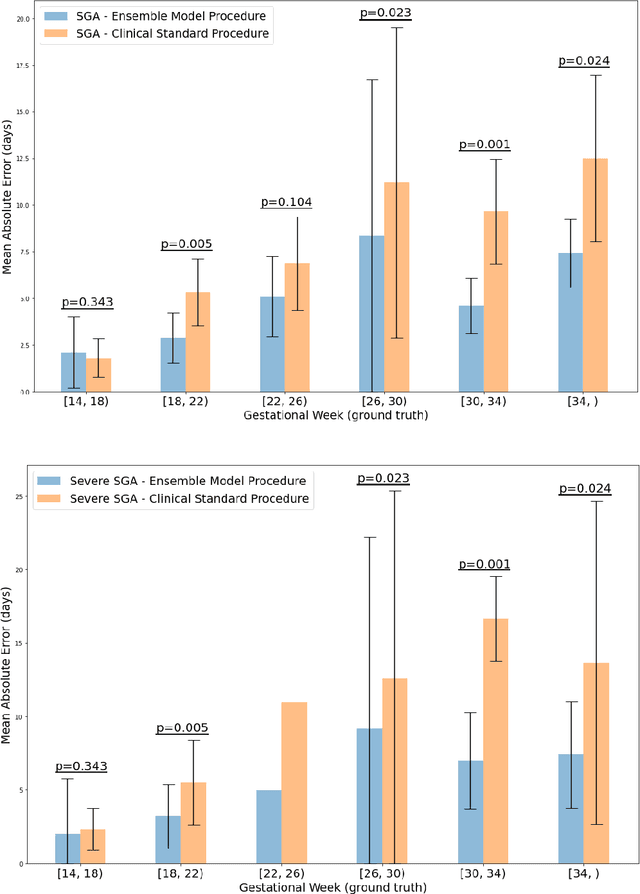
Fetal ultrasounds are an essential part of prenatal care and can be used to estimate gestational age (GA). Accurate GA assessment is important for providing appropriate prenatal care throughout pregnancy and identifying complications such as fetal growth disorders. Since derivation of GA from manual fetal biometry measurements (head, abdomen, femur) are operator-dependent and time-consuming, there have been a number of research efforts focused on using artificial intelligence (AI) models to estimate GA using standard biometry images, but there is still room to improve the accuracy and reliability of these AI systems for widescale adoption. To improve GA estimates, without significant change to provider workflows, we leverage AI to interpret standard plane ultrasound images as well as 'fly-to' ultrasound videos, which are 5-10s videos automatically recorded as part of the standard of care before the still image is captured. We developed and validated three AI models: an image model using standard plane images, a video model using fly-to videos, and an ensemble model (combining both image and video). All three were statistically superior to standard fetal biometry-based GA estimates derived by expert sonographers, the ensemble model has the lowest mean absolute error (MAE) compared to the clinical standard fetal biometry (mean difference: -1.51 $\pm$ 3.96 days, 95% CI [-1.9, -1.1]) on a test set that consisted of 404 participants. We showed that our models outperform standard biometry by a more substantial margin on fetuses that were small for GA. Our AI models have the potential to empower trained operators to estimate GA with higher accuracy while reducing the amount of time required and user variability in measurement acquisition.
Automatic Segmentation of Aircraft Dents in Point Clouds
May 03, 2022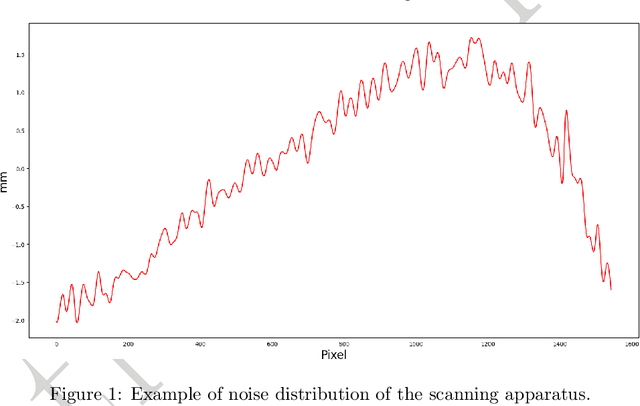
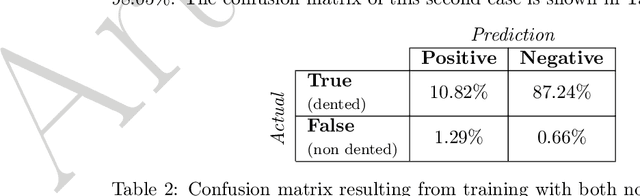
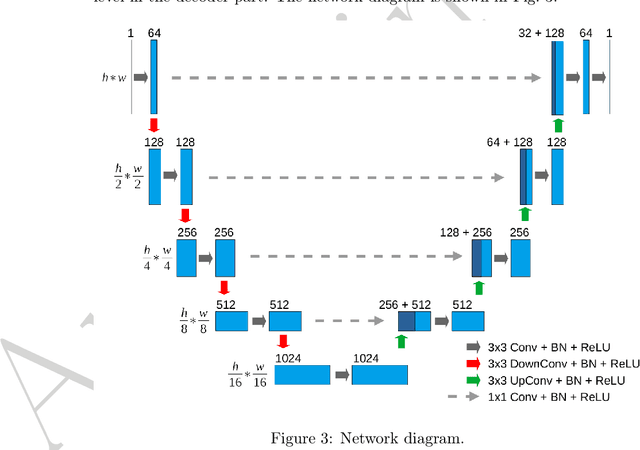

Dents on the aircraft skin are frequent and may easily go undetected during airworthiness checks, as their inspection process is tedious and extremely subject to human factors and environmental conditions. Nowadays, 3D scanning technologies are being proposed for more reliable, human-independent measurements, yet the process of inspection and reporting remains laborious and time consuming because data acquisition and validation are still carried out by the engineer. For full automation of dent inspection, the acquired point cloud data must be analysed via a reliable segmentation algorithm, releasing humans from the search and evaluation of damage. This paper reports on two developments towards automated dent inspection. The first is a method to generate a synthetic dataset of dented surfaces to train a fully convolutional neural network. The training of machine learning algorithms needs a substantial volume of dent data, which is not readily available. Dents are thus simulated in random positions and shapes, within criteria and definitions of a Boeing 737 structural repair manual. The noise distribution from the scanning apparatus is then added to reflect the complete process of 3D point acquisition on the training. The second proposition is a surface fitting strategy to convert 3D point clouds to 2.5D. This allows higher resolution point clouds to be processed with a small amount of memory compared with state-of-the-art methods involving 3D sampling approaches. Simulations with available ground truth data show that the proposed technique reaches an intersection-over-union of over 80%. Experiments over dent samples prove an effective detection of dents with a speed of over 500 000 points per second.
A Soft-Bodied Aerial Robot for Collision Resilience and Contact-Reactive Perching
Apr 27, 2022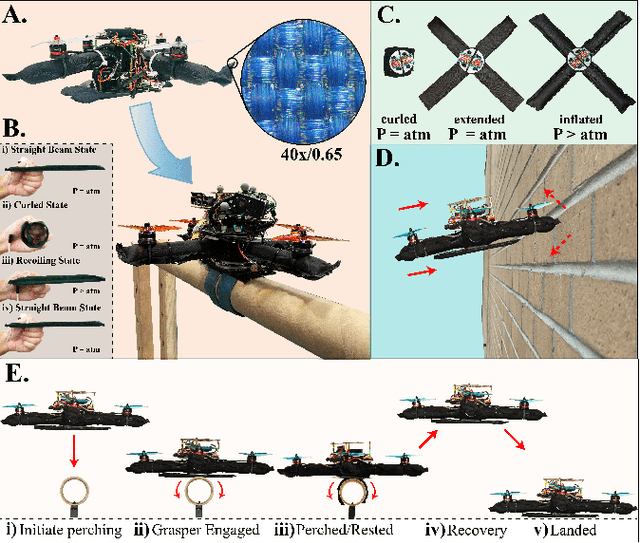
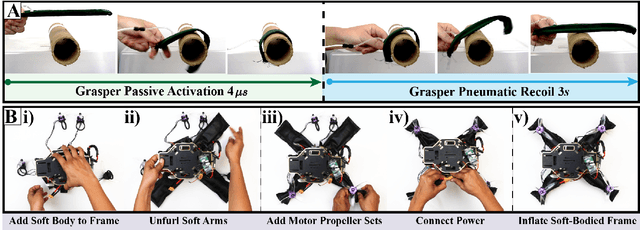
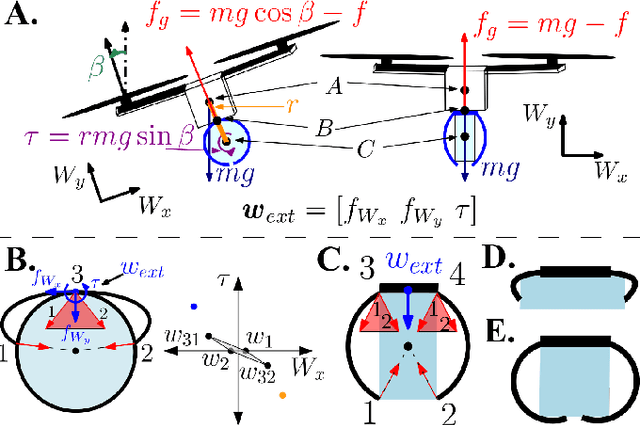

Compared to their biological counterparts, aerial robots demonstrate limited capabilities when tasked to interact in unstructured environments. Very often, the limitation lies in their inability to tolerate collisions and to successfully land, or perch, on objects of unknown shape. Over the past years, efforts to address this have introduced designs that incorporate mechanical impact protection and grasping/perching structures at the cost of reduced agility and flight time due to added weight and bulkiness. In this work, we develop a fabric-based, soft-bodied aerial robot (SoBAR) composed of both contact-reactive perching and embodied impact protection structures while remaining lightweight and streamlined. The robot is capable to 1) pneumatically vary its body stiffness for collision resilience and 2) utilize a hybrid fabric-based, bistable (HFB) grasper to perform passive grasping. When compared to conventional rigid drone frames the SoBAR successfully demonstrates its ability to dissipate impact from head-on collisions and maintain flight stability without any structural damage. Furthermore, in dynamic perching scenarios the HFB grasper is capable to convert impact energy upon contact into firm grasp through rapid body shape conforming in less than 4ms. We exhaustively study and offer insights for this novel perching scheme through grasping characterization, grasp wrench analysis, and experimental grasping validations in objects with various shapes. Finally, we demonstrate the complete control pipeline for SoBAR to approach an object, dynamically perch on it, recover from it, and land.
Deep Cellular Recurrent Network for Efficient Analysis of Time-Series Data with Spatial Information
Jan 12, 2021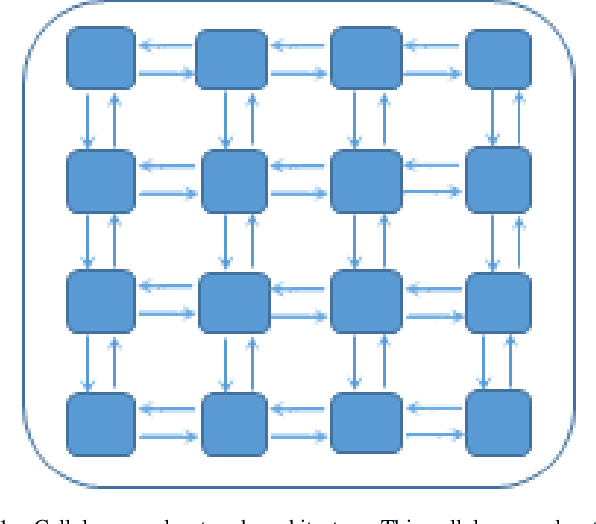
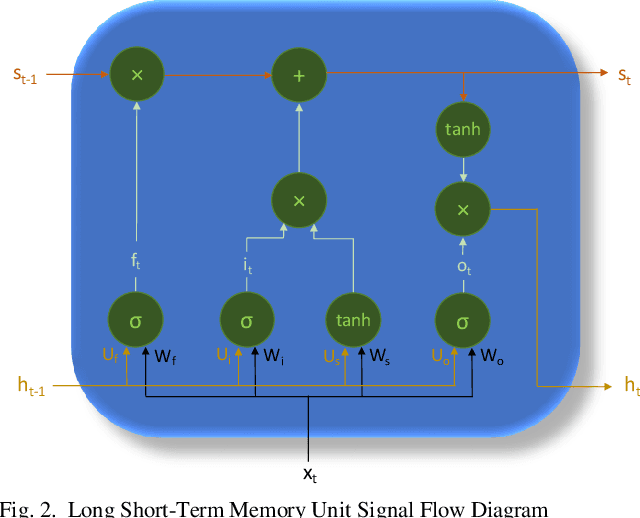
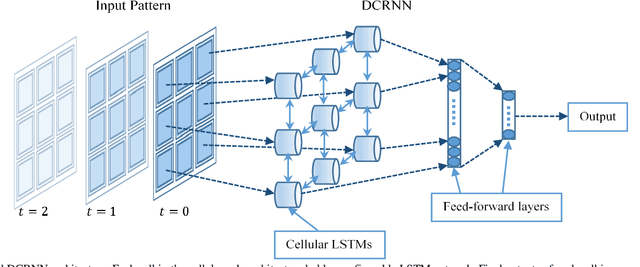
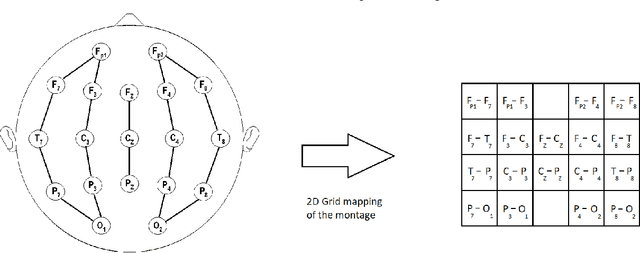
Efficient processing of large-scale time series data is an intricate problem in machine learning. Conventional sensor signal processing pipelines with hand engineered feature extraction often involve huge computational cost with high dimensional data. Deep recurrent neural networks have shown promise in automated feature learning for improved time-series processing. However, generic deep recurrent models grow in scale and depth with increased complexity of the data. This is particularly challenging in presence of high dimensional data with temporal and spatial characteristics. Consequently, this work proposes a novel deep cellular recurrent neural network (DCRNN) architecture to efficiently process complex multi-dimensional time series data with spatial information. The cellular recurrent architecture in the proposed model allows for location-aware synchronous processing of time series data from spatially distributed sensor signal sources. Extensive trainable parameter sharing due to cellularity in the proposed architecture ensures efficiency in the use of recurrent processing units with high-dimensional inputs. This study also investigates the versatility of the proposed DCRNN model for classification of multi-class time series data from different application domains. Consequently, the proposed DCRNN architecture is evaluated using two time-series datasets: a multichannel scalp EEG dataset for seizure detection, and a machine fault detection dataset obtained in-house. The results suggest that the proposed architecture achieves state-of-the-art performance while utilizing substantially less trainable parameters when compared to comparable methods in the literature.
Smart Interference Management xApp using Deep Reinforcement Learning
Apr 12, 2022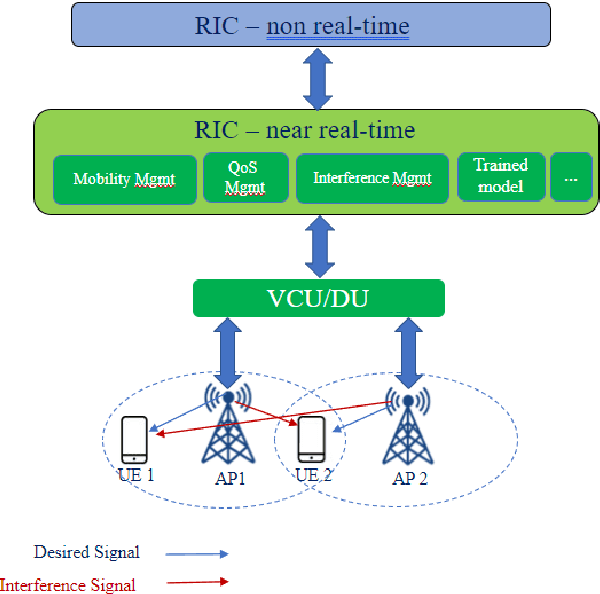
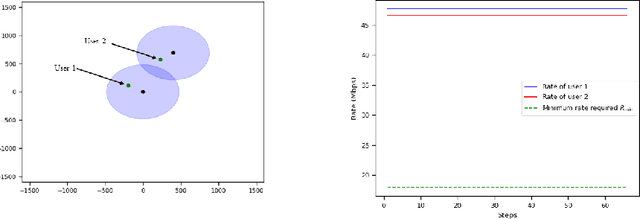
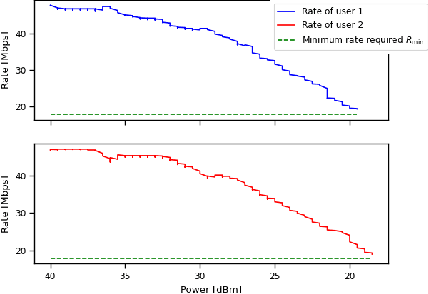
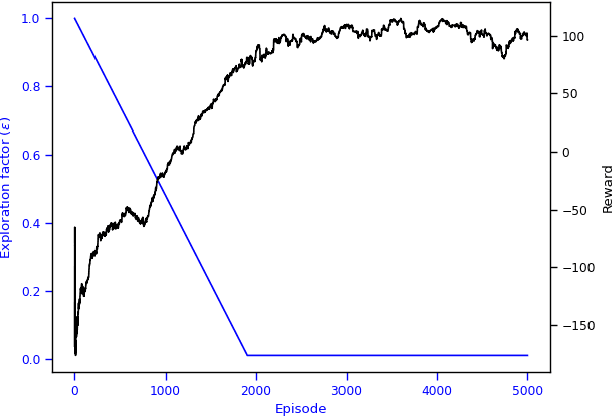
Interference continues to be a key limiting factor in cellular radio access network (RAN) deployments. Effective, data-driven, self-adapting radio resource management (RRM) solutions are essential for tackling interference, and thus achieving the desired performance levels particularly at the cell-edge. In future network architecture, RAN intelligent controller (RIC) running with near-real-time applications, called xApps, is considered as a potential component to enable RRM. In this paper, based on deep reinforcement learning (RL) xApp, a joint sub-band masking and power management is proposed for smart interference management. The sub-band resource masking problem is formulated as a Markov Decision Process (MDP) that can be solved employing deep RL to approximate the policy functions as well as to avoid extremely high computational and storage costs of conventional tabular-based approaches. The developed xApp is scalable in both storage and computation. Simulation results demonstrate advantages of the proposed approach over decentralized baselines in terms of the trade-off between cell-centre and cell-edge user rates, energy efficiency and computational efficiency.