 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hierarchical autoregressive neural networks for statistical systems
Mar 21, 2022
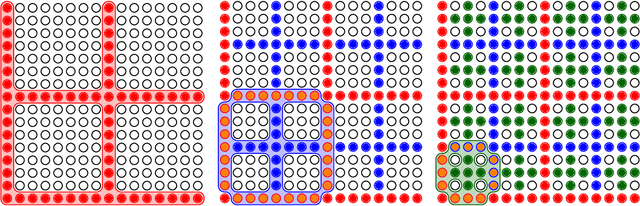

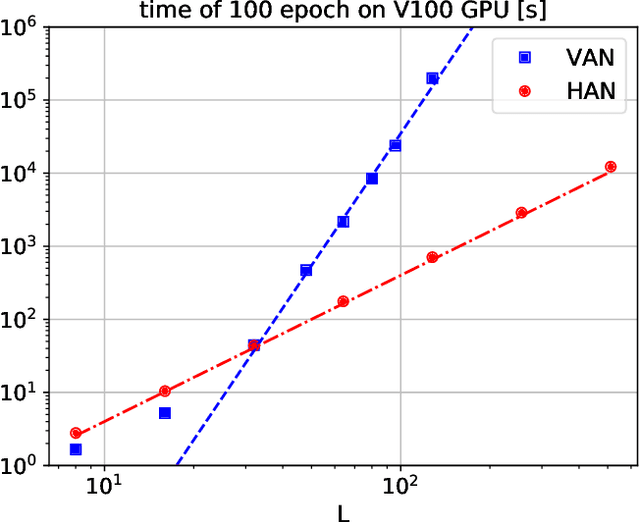
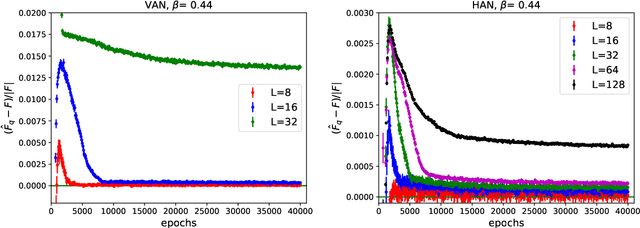
It was recently proposed that neural networks could be used to approximate many-dimensional probability distributions that appear e.g. in lattice field theories or statistical mechanics. Subsequently they can be used as variational approximators to asses extensive properties of statistical systems, like free energy, and also as neural samplers used in Monte Carlo simulations. The practical application of this approach is unfortunately limited by its unfavorable scaling both of the numerical cost required for training, and the memory requirements with the system size. This is due to the fact that the original proposition involved a neural network of width which scaled with the total number of degrees of freedom, e.g. $L^2$ in case of a two dimensional $L\times L$ lattice. In this work we propose a hierarchical association of physical degrees of freedom, for instance spins, to neurons which replaces it with the scaling with the linear extent $L$ of the system. We demonstrate our approach on the two-dimensional Ising model by simulating lattices of various sizes up to $128 \times 128$ spins, with time benchmarks reaching lattices of size $512 \times 512$. We observe that our proposal improves the quality of neural network training, i.e. the approximated probability distribution is closer to the target that could be previously achieved. As a consequence, the variational free energy reaches a value closer to its theoretical expectation and, if applied in a Markov Chain Monte Carlo algorithm, the resulting autocorrelation time is smaller. Finally, the replacement of a single neural network by a hierarchy of smaller networks considerably reduces the memory requirements.
A Subject-Independent Brain-Computer Interface Framework Based on Supervised Autoencoder
Apr 19, 2022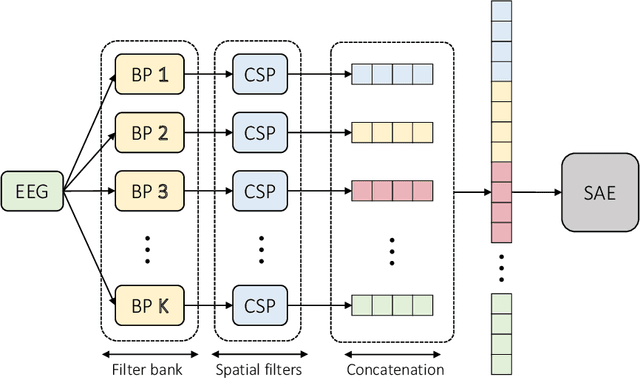
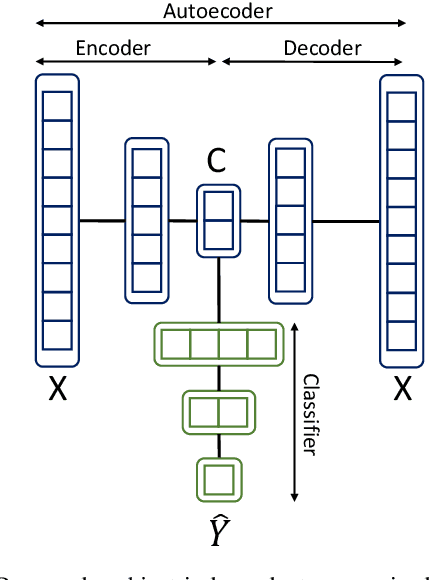
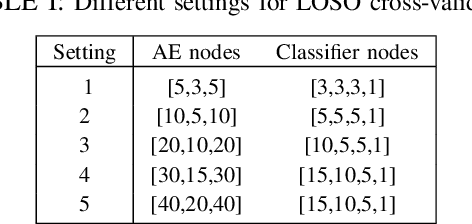
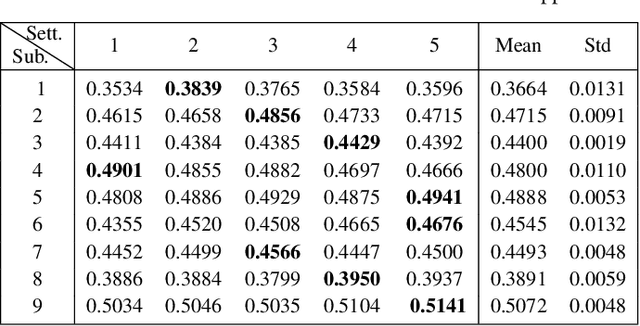
A calibration procedure is required in motor imagery-based brain-computer interface (MI-BCI) to tune the system for new users. This procedure is time-consuming and prevents na\"ive users from using the system immediately. Developing a subject-independent MI-BCI system to reduce the calibration phase is still challenging due to the subject-dependent characteristics of the MI signals. Many algorithms based on machine learning and deep learning have been developed to extract high-level features from the MI signals to improve the subject-to-subject generalization of a BCI system. However, these methods are based on supervised learning and extract features useful for discriminating various MI signals. Hence, these approaches cannot find the common underlying patterns in the MI signals and their generalization level is limited. This paper proposes a subject-independent MI-BCI based on a supervised autoencoder (SAE) to circumvent the calibration phase. The suggested framework is validated on dataset 2a from BCI competition IV. The simulation results show that our SISAE model outperforms the conventional and widely used BCI algorithms, common spatial and filter bank common spatial patterns, in terms of the mean Kappa value, in eight out of nine subjects.
A Learnable Variational Model for Joint Multimodal MRI Reconstruction and Synthesis
Apr 08, 2022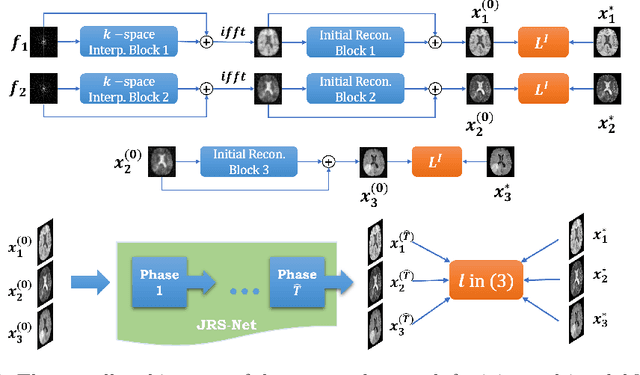
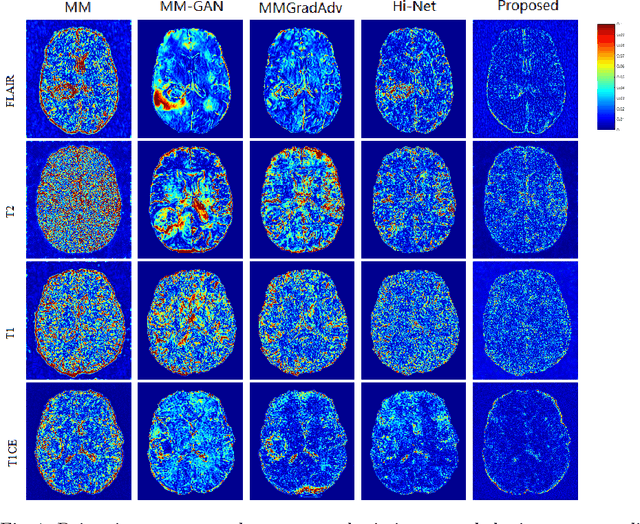

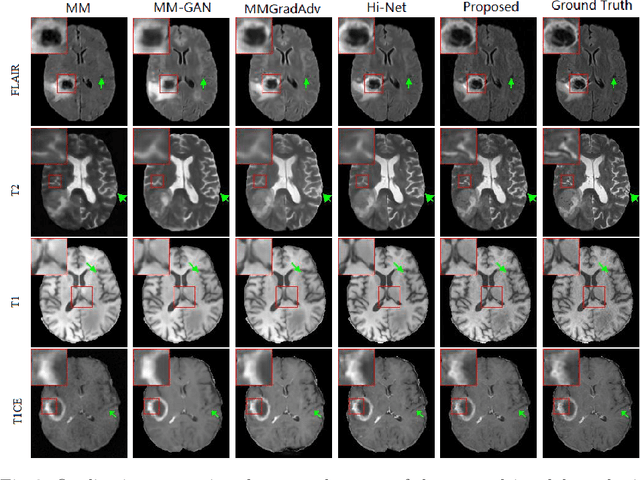
Generating multi-contrasts/modal MRI of the same anatomy enriches diagnostic information but is limited in practice due to excessive data acquisition time. In this paper, we propose a novel deep-learning model for joint reconstruction and synthesis of multi-modal MRI using incomplete k-space data of several source modalities as inputs. The output of our model includes reconstructed images of the source modalities and high-quality image synthesized in the target modality. Our proposed model is formulated as a variational problem that leverages several learnable modality-specific feature extractors and a multimodal synthesis module. We propose a learnable optimization algorithm to solve this model, which induces a multi-phase network whose parameters can be trained using multi-modal MRI data. Moreover, a bilevel-optimization framework is employed for robust parameter training. We demonstrate the effectiveness of our approach using extensive numerical experiments.
Holistic Approach to Measure Sample-level Adversarial Vulnerability and its Utility in Building Trustworthy Systems
May 05, 2022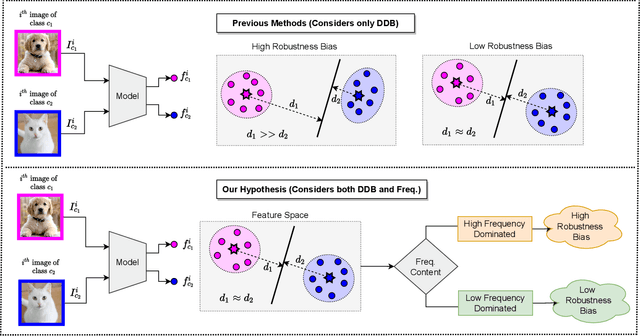
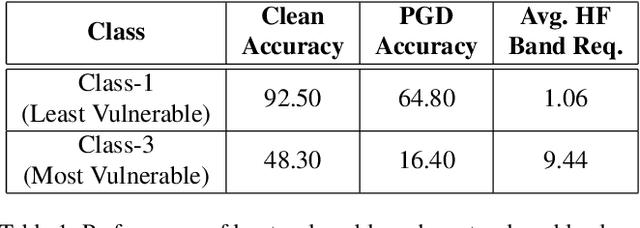
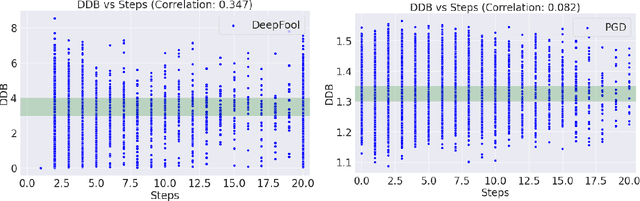

Adversarial attack perturbs an image with an imperceptible noise, leading to incorrect model prediction. Recently, a few works showed inherent bias associated with such attack (robustness bias), where certain subgroups in a dataset (e.g. based on class, gender, etc.) are less robust than others. This bias not only persists even after adversarial training, but often results in severe performance discrepancies across these subgroups. Existing works characterize the subgroup's robustness bias by only checking individual sample's proximity to the decision boundary. In this work, we argue that this measure alone is not sufficient and validate our argument via extensive experimental analysis. It has been observed that adversarial attacks often corrupt the high-frequency components of the input image. We, therefore, propose a holistic approach for quantifying adversarial vulnerability of a sample by combining these different perspectives, i.e., degree of model's reliance on high-frequency features and the (conventional) sample-distance to the decision boundary. We demonstrate that by reliably estimating adversarial vulnerability at the sample level using the proposed holistic metric, it is possible to develop a trustworthy system where humans can be alerted about the incoming samples that are highly likely to be misclassified at test time. This is achieved with better precision when our holistic metric is used over individual measures. To further corroborate the utility of the proposed holistic approach, we perform knowledge distillation in a limited-sample setting. We observe that the student network trained with the subset of samples selected using our combined metric performs better than both the competing baselines, viz., where samples are selected randomly or based on their distances to the decision boundary.
KSoF: The Kassel State of Fluency Dataset -- A Therapy Centered Dataset of Stuttering
Mar 10, 2022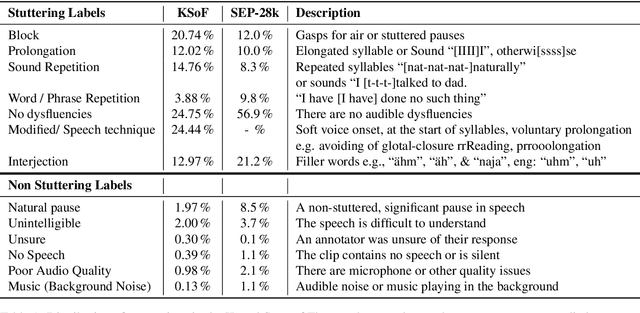
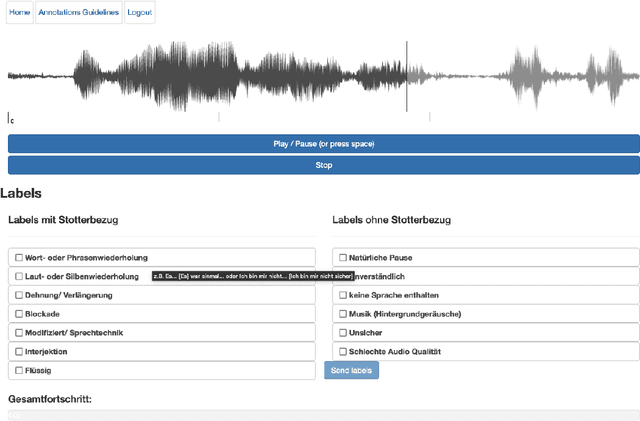
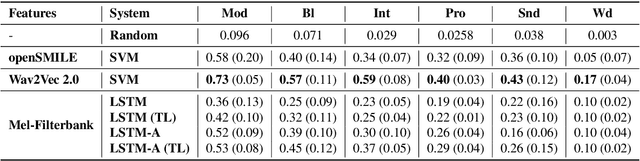
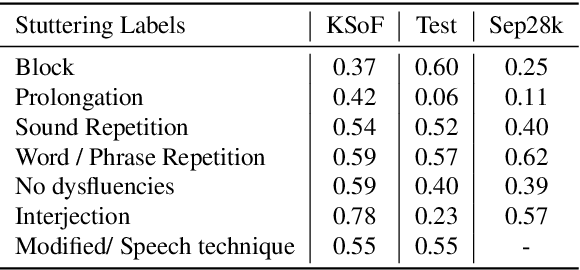
Stuttering is a complex speech disorder that negatively affects an individual's ability to communicate effectively. Persons who stutter (PWS) often suffer considerably under the condition and seek help through therapy. Fluency shaping is a therapy approach where PWSs learn to modify their speech to help them to overcome their stutter. Mastering such speech techniques takes time and practice, even after therapy. Shortly after therapy, success is evaluated highly, but relapse rates are high. To be able to monitor speech behavior over a long time, the ability to detect stuttering events and modifications in speech could help PWSs and speech pathologists to track the level of fluency. Monitoring could create the ability to intervene early by detecting lapses in fluency. To the best of our knowledge, no public dataset is available that contains speech from people who underwent stuttering therapy that changed the style of speaking. This work introduces the Kassel State of Fluency (KSoF), a therapy-based dataset containing over 5500 clips of PWSs. The clips were labeled with six stuttering-related event types: blocks, prolongations, sound repetitions, word repetitions, interjections, and - specific to therapy - speech modifications. The audio was recorded during therapy sessions at the Institut der Kasseler Stottertherapie. The data will be made available for research purposes upon request.
Conditional Injective Flows for Bayesian Imaging
Apr 19, 2022
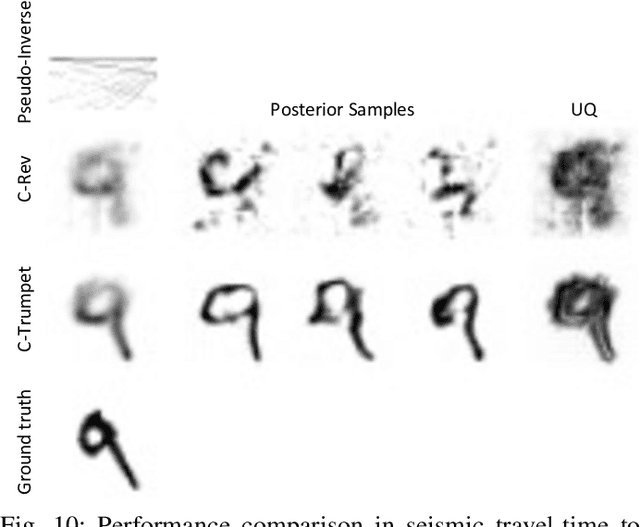

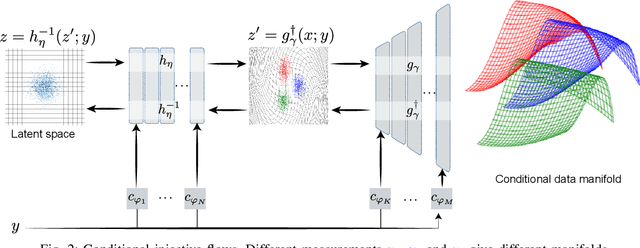
Most deep learning models for computational imaging regress a single reconstructed image. In practice, however, ill-posedness, nonlinearity, model mismatch, and noise often conspire to make such point estimates misleading or insufficient. The Bayesian approach models images and (noisy) measurements as jointly distributed random vectors and aims to approximate the posterior distribution of unknowns. Recent variational inference methods based on conditional normalizing flows are a promising alternative to traditional MCMC methods, but they come with drawbacks: excessive memory and compute demands for moderate to high resolution images and underwhelming performance on hard nonlinear problems. In this work, we propose C-Trumpets -- conditional injective flows specifically designed for imaging problems, which greatly diminish these challenges. Injectivity reduces memory footprint and training time while low-dimensional latent space together with architectural innovations like fixed-volume-change layers and skip-connection revnet layers, C-Trumpets outperform regular conditional flow models on a variety of imaging and image restoration tasks, including limited-view CT and nonlinear inverse scattering, with a lower compute and memory budget. C-Trumpets enable fast approximation of point estimates like MMSE or MAP as well as physically-meaningful uncertainty quantification.
Systematic Generalization in Neural Networks-based Multivariate Time Series Forecasting Models
Mar 07, 2021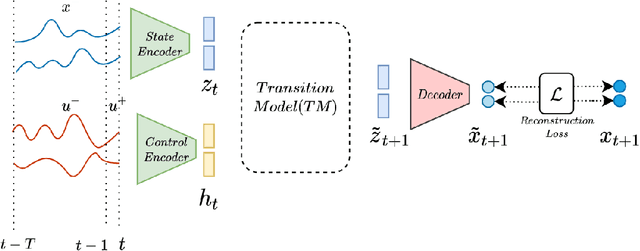
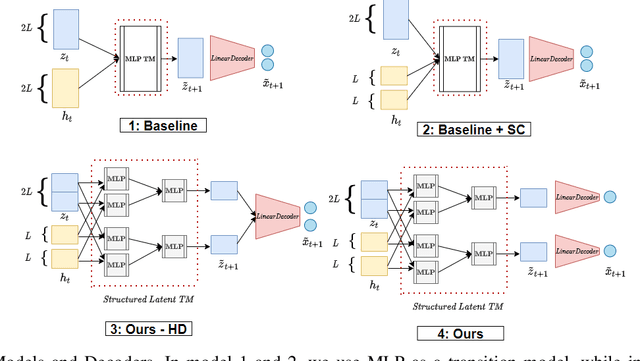
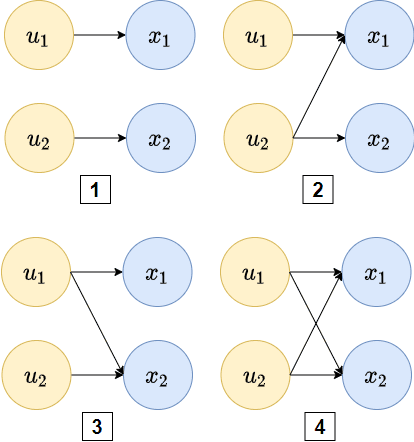
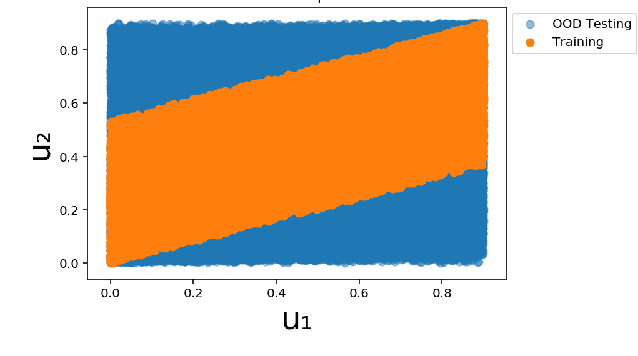
Systematic generalization aims to evaluate reasoning about novel combinations from known components, an intrinsic property of human cognition. In this work, we study systematic generalization of NNs in forecasting future time series of dependent variables in a dynamical system, conditioned on past time series of dependent variables, and past and future control variables. We focus on systematic generalization wherein the NN-based forecasting model should perform well on previously unseen combinations or regimes of control variables after being trained on a limited set of the possible regimes. For NNs to depict such out-of-distribution generalization, they should be able to disentangle the various dependencies between control variables and dependent variables. We hypothesize that a modular NN architecture guided by the readily-available knowledge of independence of control variables as a potentially useful inductive bias to this end. Through extensive empirical evaluation on a toy dataset and a simulated electric motor dataset, we show that our proposed modular NN architecture serves as a simple yet highly effective inductive bias that enabling better forecasting of the dependent variables up to large horizons in contrast to standard NNs, and indeed capture the true dependency relations between the dependent and the control variables.
An Interactive Image-based Modeling System
Mar 28, 2022


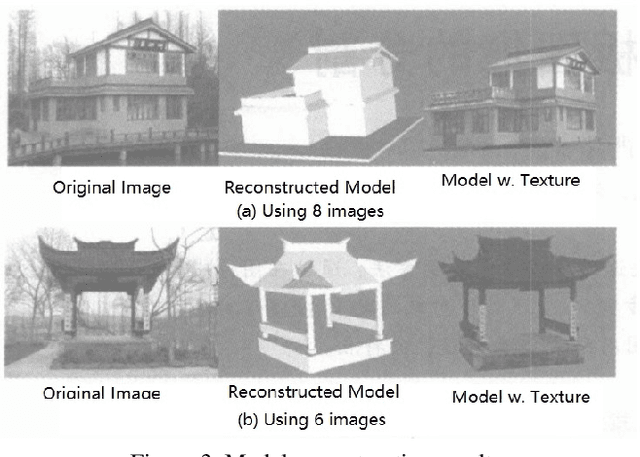
This paper propose a interactive 3D modeling method and corresponding system based on single or multiple uncalibrated images. The main feature of this method is that, according to the modeling habits of ordinary people, the 3D model of the target is reconstructed from coarse to fine images. On the basis of determining the approximate shape, the user adds or modify projection constraints and spatial constraints, and apply topology modification, gradually realize camera calibration, refine rough model, and finally complete the reconstruction of objects with arbitrary geometry and topology. During the interactive process, the geometric parameters and camera projection matrix are solved in real time, and the reconstruction results are displayed in a 3D window.
Run-Time Monitoring of Machine Learning for Robotic Perception: A Survey of Emerging Trends
Jan 05, 2021
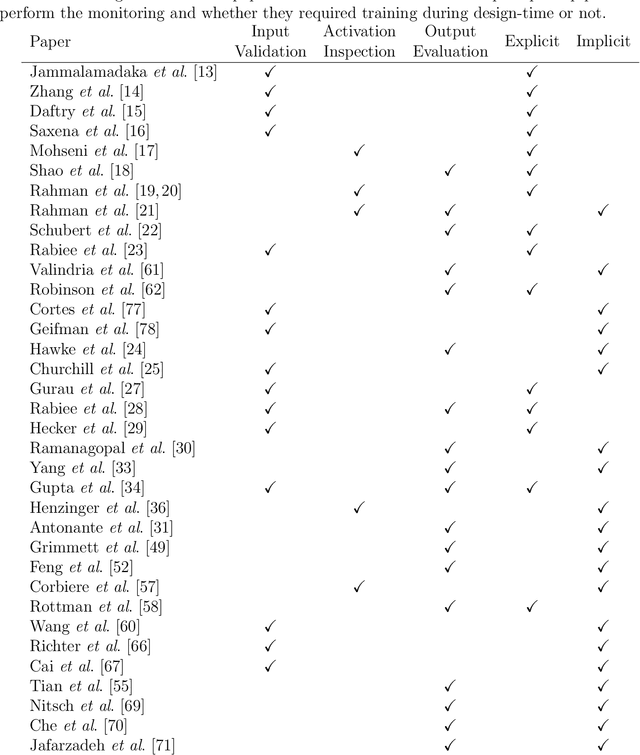
As deep learning continues to dominate all state-of-the-art computer vision tasks, it is increasingly becoming the essential building blocks for robotic perception. As a result, the research questions concerning the safety and reliability of learning-based perception are gaining increased importance. Although there is an established field that studies safety certification and convergence guarantee of complex software systems for decision-making during design-time, the uncertainty in run-time conditions and the unknown future deployment environments of autonomous systems as well as the complexity of learning-based perception systems make the generalisation of the verification results from design-time to run-time problematic. More attention is starting to shift towards run-time monitoring of performance and reliability of perception systems with several trends emerging in the literature in the face of such a challenge. This paper attempts to identify these trends and summarise the various approaches on the topic.
MIMO Channel Estimation using Score-Based Generative Models
Apr 14, 2022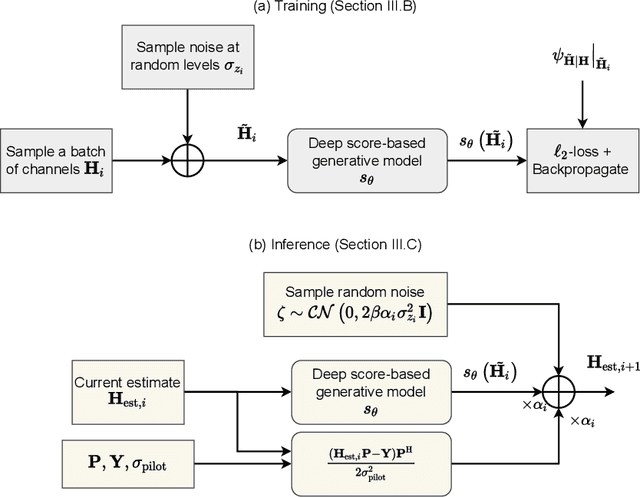
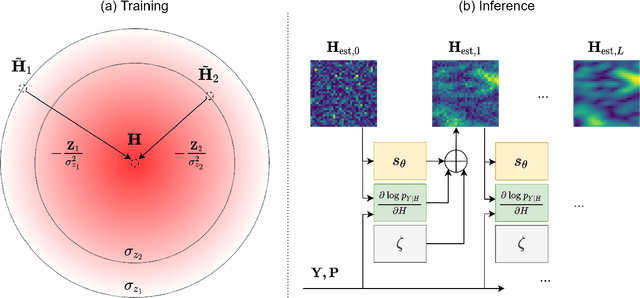

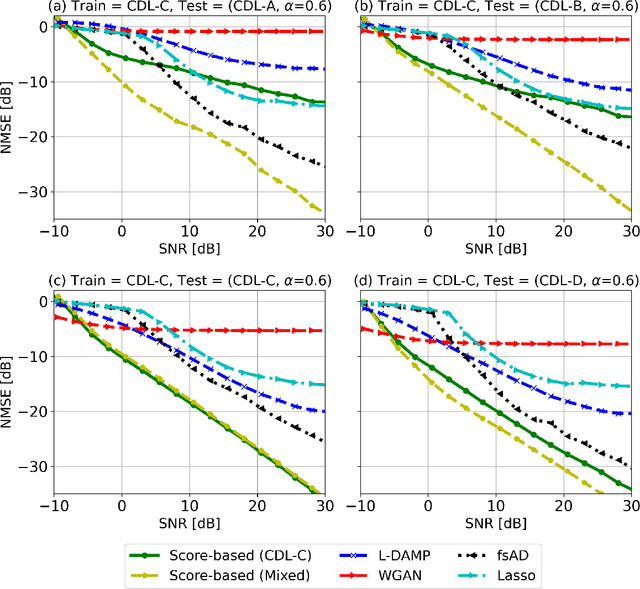
Channel estimation is a critical task in multiple-input multiple-output digital communications that has effects on end-to-end system performance. In this work, we introduce a novel approach for channel estimation using deep score-based generative models. These models are trained to estimate the gradient of the log-prior distribution, and can be used to iteratively refine estimates, given observed measurements of a signal. We introduce a framework for training score-based generative models for wireless channels, as well as performing channel estimation using posterior sampling at test time. We derive theoretical robustness guarantees of channel estimation with posterior sampling in single-input single-output scenarios, and show that the observations regarding estimation performance are verified experimentally in MIMO channels. Our results in simulated clustered delay line channels show competitive in-distribution performance without error floors in the high signal-to-noise ratio regime, and robust out-of-distribution performance, outperforming competing deep learning methods by up to 5 dB in end-to-end communication performance, while the complexity analysis reveals how model architecture can efficiently trade performance for estimation latency.