 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimation of the reduced density matrix and entanglement entropies using autoregressive networks
Jun 04, 2025We present an application of autoregressive neural networks to Monte Carlo simulations of quantum spin chains using the correspondence with classical two-dimensional spin systems. We use a hierarchy of neural networks capable of estimating conditional probabilities of consecutive spins to evaluate elements of reduced density matrices directly. Using the Ising chain as an example, we calculate the continuum limit of the ground state's von Neumann and R\'enyi bipartite entanglement entropies of an interval built of up to 5 spins. We demonstrate that our architecture is able to estimate all the needed matrix elements with just a single training for a fixed time discretization and lattice volume. Our method can be applied to other types of spin chains, possibly with defects, as well as to estimating entanglement entropies of thermal states at non-zero temperature.
NeuMC -- a package for neural sampling for lattice field theories
Mar 14, 2025We present the \texttt{NeuMC} software package, based on \pytorch, aimed at facilitating the research on neural samplers in lattice field theories. Neural samplers based on normalizing flows are becoming increasingly popular in the context of Monte-Carlo simulations as they can effectively approximate target probability distributions, possibly alleviating some shortcomings of the Markov chain Monte-Carlo methods. Our package provides tools to create such samplers for two-dimensional field theories.
Training normalizing flows with computationally intensive target probability distributions
Aug 25, 2023Machine learning techniques, in particular the so-called normalizing flows, are becoming increasingly popular in the context of Monte Carlo simulations as they can effectively approximate target probability distributions. In the case of lattice field theories (LFT) the target distribution is given by the exponential of the action. The common loss function's gradient estimator based on the "reparametrization trick" requires the calculation of the derivative of the action with respect to the fields. This can present a significant computational cost for complicated, non-local actions like e.g. fermionic action in QCD. In this contribution, we propose an estimator for normalizing flows based on the REINFORCE algorithm that avoids this issue. We apply it to two dimensional Schwinger model with Wilson fermions at criticality and show that it is up to ten times faster in terms of the wall-clock time as well as requiring up to $30\%$ less memory than the reparameterization trick estimator. It is also more numerically stable allowing for single precision calculations and the use of half-float tensor cores. We present an in-depth analysis of the origins of those improvements. We believe that these benefits will appear also outside the realm of the LFT, in each case where the target probability distribution is computationally intensive.
Mutual information of spin systems from autoregressive neural networks
Apr 26, 2023We describe a direct approach to estimate bipartite mutual information of a classical spin system based on Monte Carlo sampling enhanced by autoregressive neural networks. It allows studying arbitrary geometries of subsystems and can be generalized to classical field theories. We demonstrate it on the Ising model for four partitionings, including a multiply-connected even-odd division. We show that the area law is satisfied for temperatures away from the critical temperature: the constant term is universal, whereas the proportionality coefficient is different for the even-odd partitioning.
Simulating first-order phase transition with hierarchical autoregressive networks
Dec 09, 2022



We apply the Hierarchical Autoregressive Neural (HAN) network sampling algorithm to the two-dimensional $Q$-state Potts model and perform simulations around the phase transition at $Q=12$. We quantify the performance of the approach in the vicinity of the first-order phase transition and compare it with that of the Wolff cluster algorithm. We find a significant improvement as far as the statistical uncertainty is concerned at a similar numerical effort. In order to efficiently train large neural networks we introduce the technique of pre-training. It allows to train some neural networks using smaller system sizes and then employing them as starting configurations for larger system sizes. This is possible due to the recursive construction of our hierarchical approach. Our results serve as a demonstration of the performance of the hierarchical approach for systems exhibiting bimodal distributions. Additionally, we provide estimates of the free energy and entropy in the vicinity of the phase transition with statistical uncertainties of the order of $10^{-7}$ for the former and $10^{-3}$ for the latter based on a statistics of $10^6$ configurations.
Hierarchical autoregressive neural networks for statistical systems
Mar 21, 2022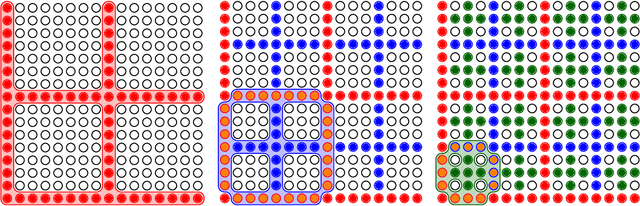

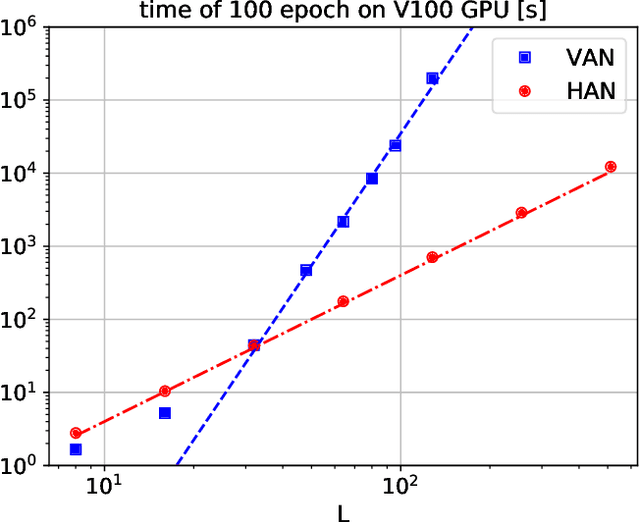
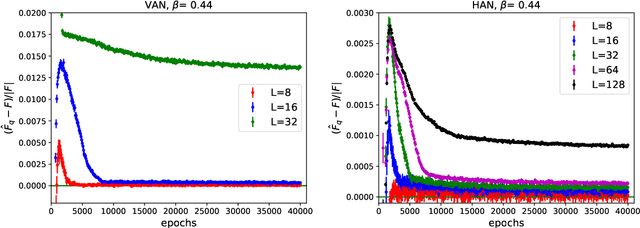
It was recently proposed that neural networks could be used to approximate many-dimensional probability distributions that appear e.g. in lattice field theories or statistical mechanics. Subsequently they can be used as variational approximators to asses extensive properties of statistical systems, like free energy, and also as neural samplers used in Monte Carlo simulations. The practical application of this approach is unfortunately limited by its unfavorable scaling both of the numerical cost required for training, and the memory requirements with the system size. This is due to the fact that the original proposition involved a neural network of width which scaled with the total number of degrees of freedom, e.g. $L^2$ in case of a two dimensional $L\times L$ lattice. In this work we propose a hierarchical association of physical degrees of freedom, for instance spins, to neurons which replaces it with the scaling with the linear extent $L$ of the system. We demonstrate our approach on the two-dimensional Ising model by simulating lattices of various sizes up to $128 \times 128$ spins, with time benchmarks reaching lattices of size $512 \times 512$. We observe that our proposal improves the quality of neural network training, i.e. the approximated probability distribution is closer to the target that could be previously achieved. As a consequence, the variational free energy reaches a value closer to its theoretical expectation and, if applied in a Markov Chain Monte Carlo algorithm, the resulting autocorrelation time is smaller. Finally, the replacement of a single neural network by a hierarchy of smaller networks considerably reduces the memory requirements.
Gradient estimators for normalising flows
Feb 02, 2022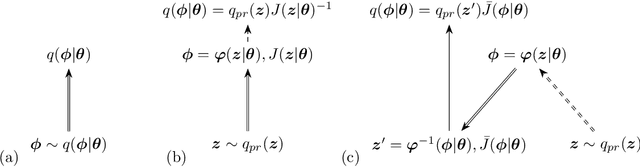
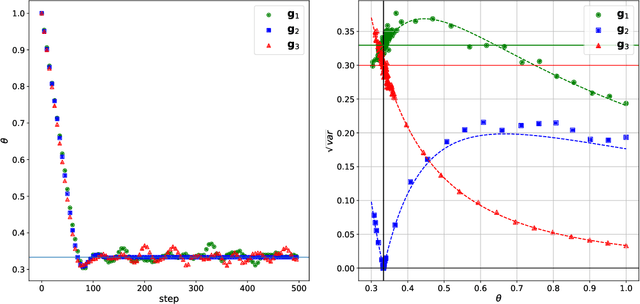

Recently a machine learning approach to Monte-Carlo simulations called Neural Markov Chain Monte-Carlo (NMCMC) is gaining traction. In its most popular form it uses the neural networks to construct normalizing flows which are then trained to approximate the desired target distribution. As this distribution is usually defined via a Hamiltonian or action, the standard learning algorithm requires estimation of the action gradient with respect to the fields. In this contribution we present another gradient estimator (and the corresponding [PyTorch implementation) that avoids this calculation, thus potentially speeding up training for models with more complicated actions. We also study the statistical properties of several gradient estimators and show that our formulation leads to better training results.
Analysis of autocorrelation times in Neural Markov Chain Monte Carlo simulations
Nov 19, 2021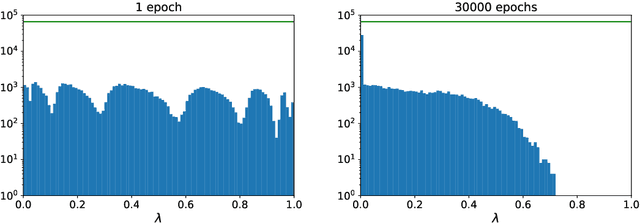
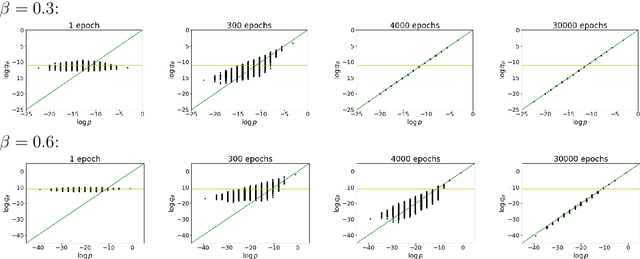
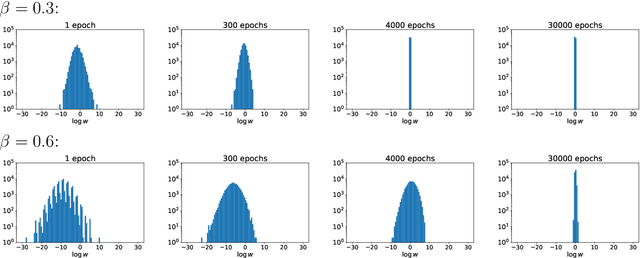
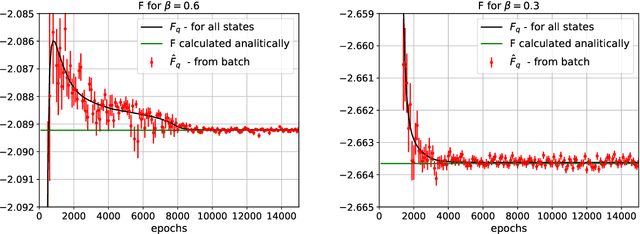
We provide a deepened study of autocorrelations in Neural Markov Chain Monte Carlo simulations, a version of the traditional Metropolis algorithm which employs neural networks to provide independent proposals. We illustrate our ideas using the two-dimensional Ising model. We propose several estimates of autocorrelation times, some inspired by analytical results derived for the Metropolized Independent Sampler, which we compare and study as a function of inverse temperature $\beta$. Based on that we propose an alternative loss function and study its impact on the autocorelation times. Furthermore, we investigate the impact of imposing system symmetries ($Z_2$ and/or translational) in the neural network training process on the autocorrelation times. Eventually, we propose a scheme which incorporates partial heat-bath updates. The impact of the above enhancements is discussed for a $16 \times 16$ spin system. The summary of our findings may serve as a guide to the implementation of Neural Markov Chain Monte Carlo simulations of more complicated models.