 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
May 19, 2022

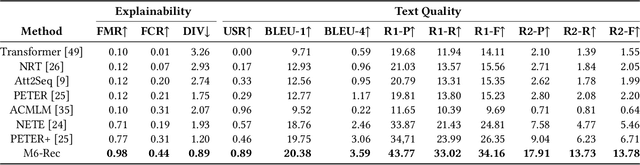
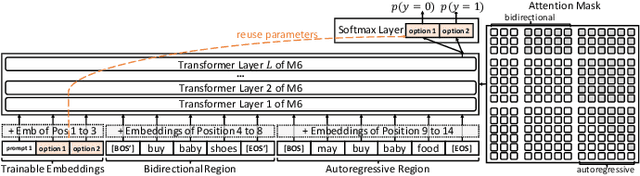

Industrial recommender systems have been growing increasingly complex, may involve \emph{diverse domains} such as e-commerce products and user-generated contents, and can comprise \emph{a myriad of tasks} such as retrieval, ranking, explanation generation, and even AI-assisted content production. The mainstream approach so far is to develop individual algorithms for each domain and each task. In this paper, we explore the possibility of developing a unified foundation model to support \emph{open-ended domains and tasks} in an industrial recommender system, which may reduce the demand on downstream settings' data and can minimize the carbon footprint by avoiding training a separate model from scratch for every task. Deriving a unified foundation is challenging due to (i) the potentially unlimited set of downstream domains and tasks, and (ii) the real-world systems' emphasis on computational efficiency. We thus build our foundation upon M6, an existing large-scale industrial pretrained language model similar to GPT-3 and T5, and leverage M6's pretrained ability for sample-efficient downstream adaptation, by representing user behavior data as plain texts and converting the tasks to either language understanding or generation. To deal with a tight hardware budget, we propose an improved version of prompt tuning that outperforms fine-tuning with negligible 1\% task-specific parameters, and employ techniques such as late interaction, early exiting, parameter sharing, and pruning to further reduce the inference time and the model size. We demonstrate the foundation model's versatility on a wide range of tasks such as retrieval, ranking, zero-shot recommendation, explanation generation, personalized content creation, and conversational recommendation, and manage to deploy it on both cloud servers and mobile devices.
On the Time Discretization of the Feynman-Kac Forward-Backward Stochastic Differential Equations for Value Function Approximation
Mar 26, 2021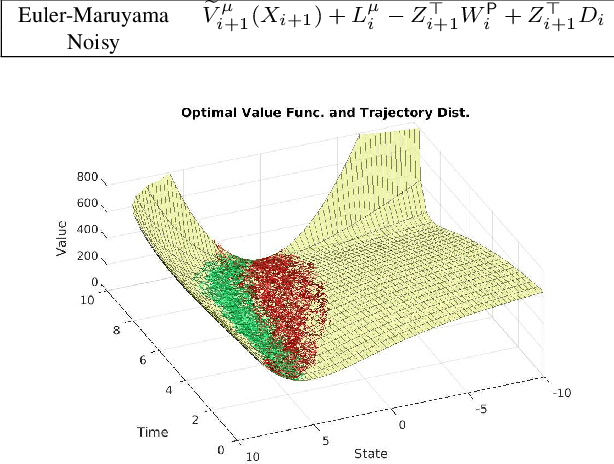

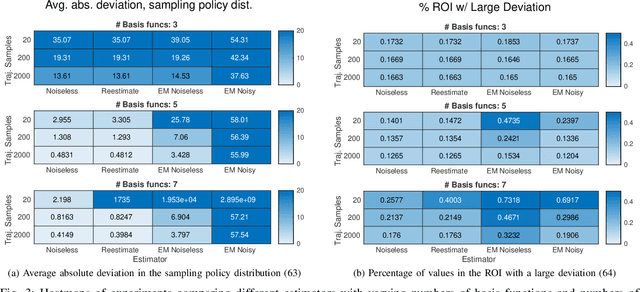
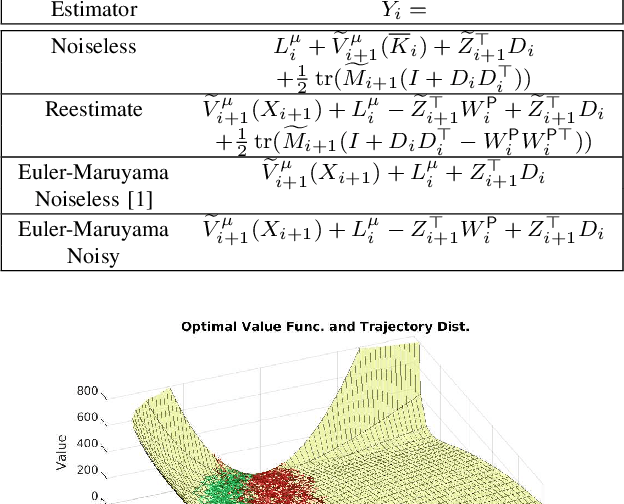
Novel numerical estimators are proposed for the forward-backward stochastic differential equations (FBSDE) appearing in the Feynman-Kac representation of the value function. In contrast to the current numerical method approaches based on discretization of the continuous-time FBSDE results, we propose a converse approach, by first obtaining a discrete-time approximation of the on-policy value function, and then developing a discrete-time result which resembles the continuous-time counterpart. This approach yields improved numerical estimators in the function approximation phase, and demonstrates enhanced error analysis for those value function estimators. Numerical results and error analysis are demonstrated on a scalar nonlinear stochastic optimal control problem, and they show improvements in the performance of the proposed estimators in comparison with the state-of-the-art methodologies.
Towards efficient models for real-time deep noise suppression
Jan 22, 2021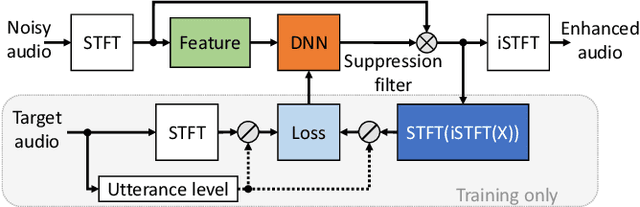

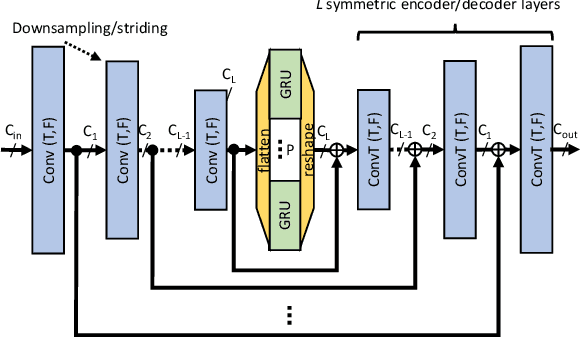
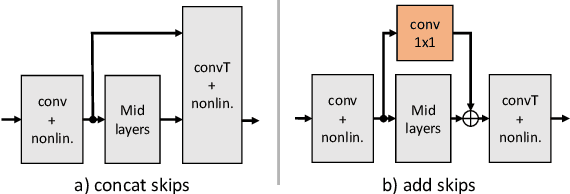
With recent research advancements, deep learning models are becoming attractive and powerful choices for speech enhancement in real-time applications. While state-of-the-art models can achieve outstanding results in terms of speech quality and background noise reduction, the main challenge is to obtain compact enough models, which are resource efficient during inference time. An important but often neglected aspect for data-driven methods is that results can be only convincing when tested on real-world data and evaluated with useful metrics. In this work, we investigate reasonably small recurrent and convolutional-recurrent network architectures for speech enhancement, trained on a large dataset considering also reverberation. We show interesting tradeoffs between computational complexity and the achievable speech quality, measured on real recordings using a highly accurate MOS estimator. It is shown that the achievable speech quality is a function of network complexity, and show which models have better tradeoffs.
PARAFAC2$\times$N: Coupled Decomposition of Multi-modal Data with Drift in N Modes
May 06, 2022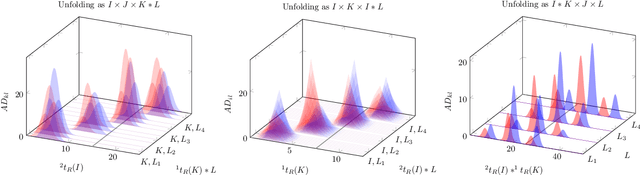
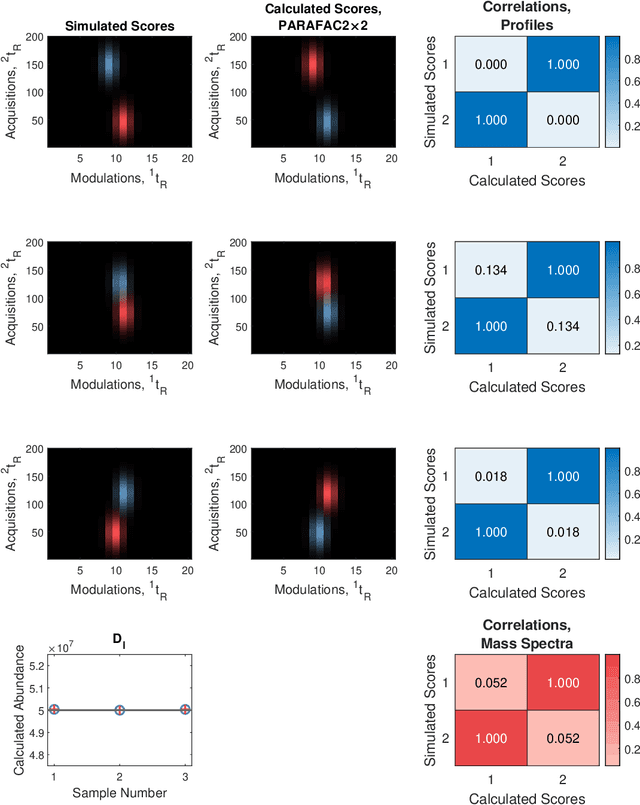
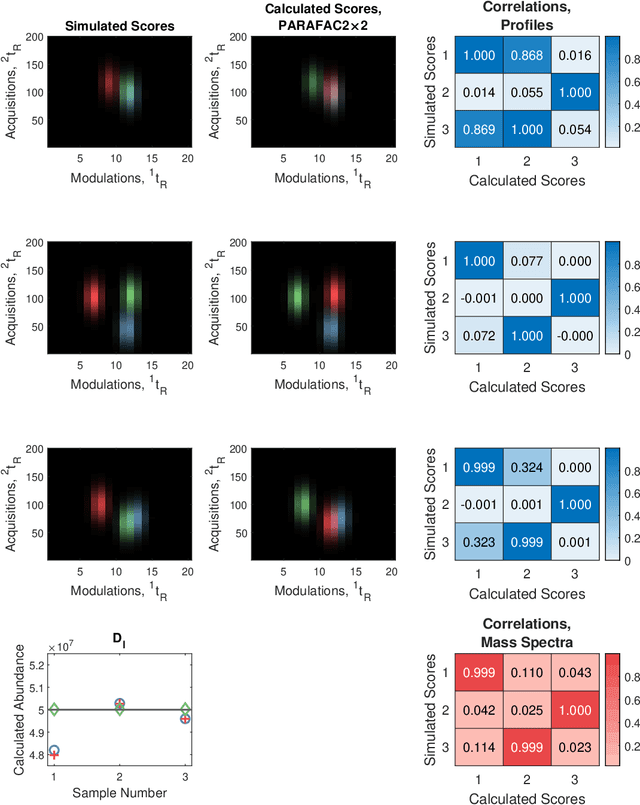
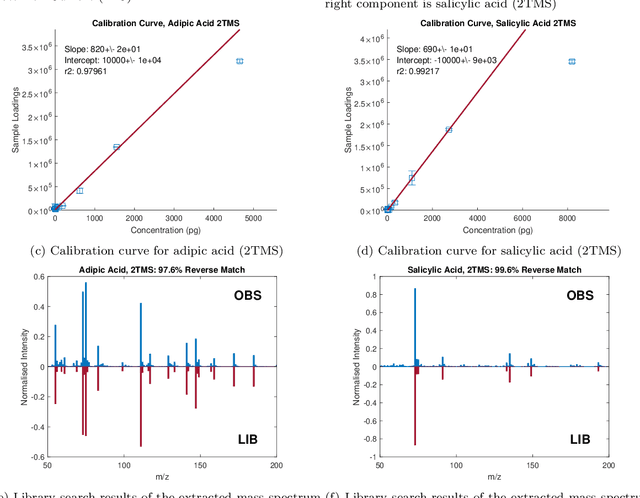
Reliable analysis of comprehensive two-dimensional gas chromatography - time-of-flight mass spectrometry (GC$\times$GC-TOFMS) data is considered to be a major bottleneck for its widespread application. For multiple samples, GC$\times$GC-TOFMS data for specific chromatographic regions manifests as a 4th order tensor of I mass spectral acquisitions, J mass channels, K modulations, and L samples. Chromatographic drift is common along both the first-dimension (modulations), and along the second-dimension (mass spectral acquisitions), while drift along the mass channel and sample dimensions is for all practical purposes nonexistent. A number of solutions to handling GC$\times$GC-TOFMS data have been proposed: these involve reshaping the data to make it amenable to either 2nd order decomposition techniques based on Multivariate Curve Resolution (MCR), or 3rd order decomposition techniques such as Parallel Factor Analysis 2 (PARAFAC2). PARAFAC2 has been utilised to model chromatographic drift along one mode, which has enabled its use for robust decomposition of multiple GC-MS experiments. Although extensible, it is not straightforward to implement a PARAFAC2 model that accounts for drift along multiple modes. In this submission, we demonstrate a new approach and a general theory for modelling data with drift along multiple modes, for applications in multidimensional chromatography with multivariate detection.
Linear-Time Self Attention with Codeword Histogram for Efficient Recommendation
May 28, 2021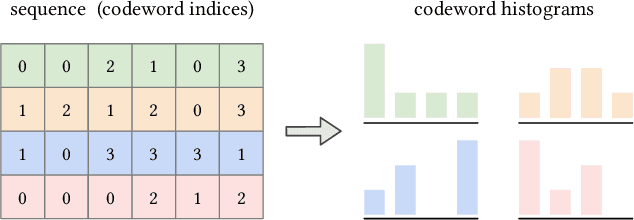
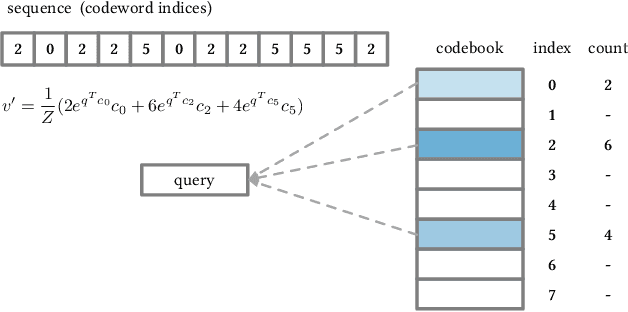
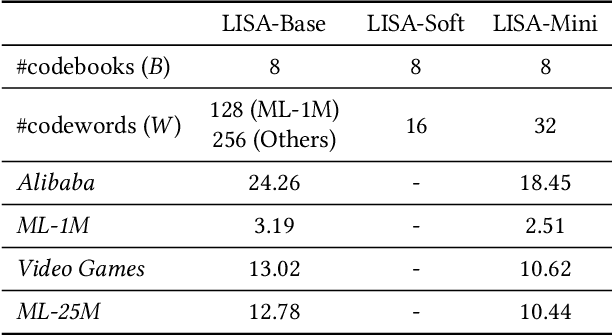
Self-attention has become increasingly popular in a variety of sequence modeling tasks from natural language processing to recommendation, due to its effectiveness. However, self-attention suffers from quadratic computational and memory complexities, prohibiting its applications on long sequences. Existing approaches that address this issue mainly rely on a sparse attention context, either using a local window, or a permuted bucket obtained by locality-sensitive hashing (LSH) or sorting, while crucial information may be lost. Inspired by the idea of vector quantization that uses cluster centroids to approximate items, we propose LISA (LInear-time Self Attention), which enjoys both the effectiveness of vanilla self-attention and the efficiency of sparse attention. LISA scales linearly with the sequence length, while enabling full contextual attention via computing differentiable histograms of codeword distributions. Meanwhile, unlike some efficient attention methods, our method poses no restriction on casual masking or sequence length. We evaluate our method on four real-world datasets for sequential recommendation. The results show that LISA outperforms the state-of-the-art efficient attention methods in both performance and speed; and it is up to 57x faster and 78x more memory efficient than vanilla self-attention.
Optimizing Hyperparameters in CNNs using Bilevel Programming in Time Series Data
Jan 19, 2021
Hyperparameter optimization has remained a central topic within the machine learning community due to its ability to produce state-of-the-art results. With the recent interest growing in the usage of CNNs for time series prediction, we propose the notion of optimizing Hyperparameters in CNNs for the purpose of time series prediction. In this position paper, we give away the idea of modeling the concerned hyperparameter optimization problem using bilevel programming.
SepTr: Separable Transformer for Audio Spectrogram Processing
Mar 17, 2022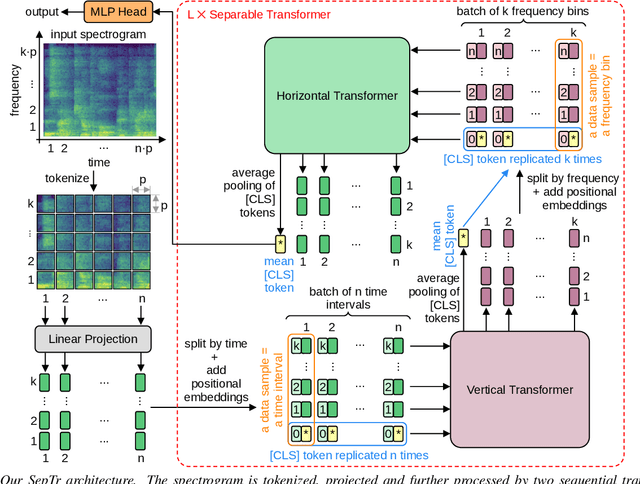
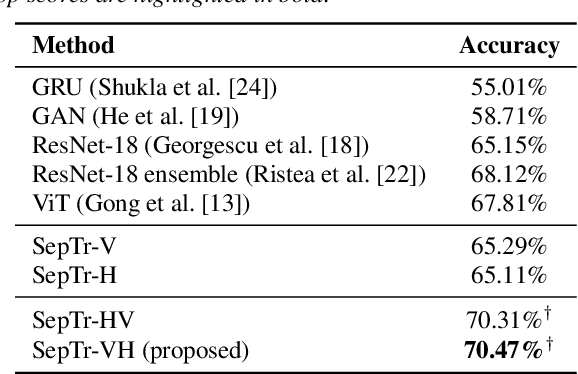
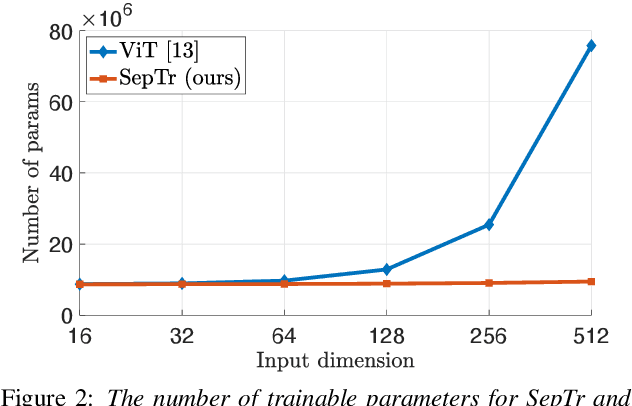
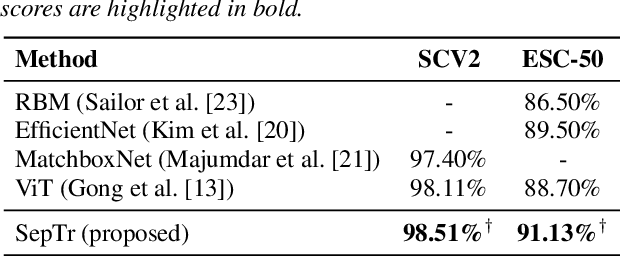
Following the successful application of vision transformers in multiple computer vision tasks, these models have drawn the attention of the signal processing community. This is because signals are often represented as spectrograms (e.g. through Discrete Fourier Transform) which can be directly provided as input to vision transformers. However, naively applying transformers to spectrograms is suboptimal. Since the axes represent distinct dimensions, i.e. frequency and time, we argue that a better approach is to separate the attention dedicated to each axis. To this end, we propose the Separable Transformer (SepTr), an architecture that employs two transformer blocks in a sequential manner, the first attending to tokens within the same frequency bin, and the second attending to tokens within the same time interval. We conduct experiments on three benchmark data sets, showing that our separable architecture outperforms conventional vision transformers and other state-of-the-art methods. Unlike standard transformers, SepTr linearly scales the number of trainable parameters with the input size, thus having a lower memory footprint. Our code is available as open source at https://github.com/ristea/septr.
Dynamic super-resolution in particle tracking problems
Apr 08, 2022Particle tracking in biological imaging is concerned with reconstructing the trajectories, locations, or velocities of the targeting particles. The standard approach of particle tracking consists of two steps: first reconstructing statically the source locations in each time step, and second applying tracking techniques to obtain the trajectories and velocities. In contrast, the dynamic reconstruction seeks to simultaneously recover the source locations and velocities from all frames, which enjoys certain advantages. In this paper, we provide a rigorous mathematical analysis for the resolution limit of reconstructing source number, locations, and velocities by general dynamical reconstruction in particle tracking problems, by which we demonstrate the possibility of achieving super-resolution for the dynamic reconstruction. We show that when the location-velocity pairs of the particles are separated beyond certain distances (the resolution limits), the number of particles and the location-velocity pair can be stably recovered. The resolution limits are related to the cut-off frequency of the imaging system, signal-to-noise ratio, and the sparsity of the source. By these estimates, we also derive a stability result for a sparsity-promoting dynamic reconstruction. In addition, we further show that the reconstruction of velocities has a better resolution limit which improves constantly as the particles moving. This result is derived by an observation that the inherent cut-off frequency for the velocity recovery can be viewed as the total observation time multiplies the cut-off frequency of the imaging system, which may lead to a better resolution limit as compared to the one for each diffraction-limited frame. It is anticipated that this observation can inspire new reconstruction algorithms that improve the resolution of particle tracking in practice.
Latency Overhead of ROS2 for Modular Time-Critical Systems
Jan 12, 2021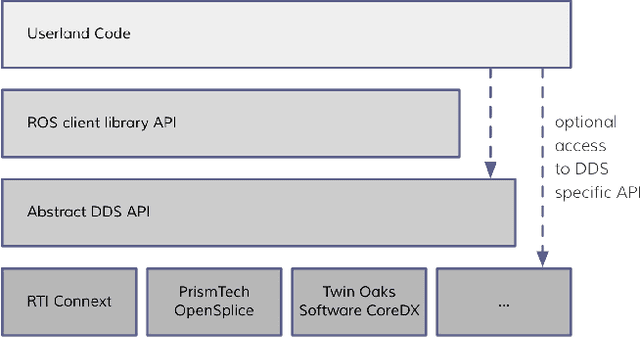
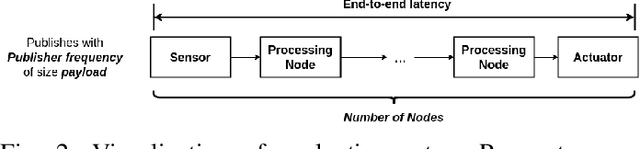
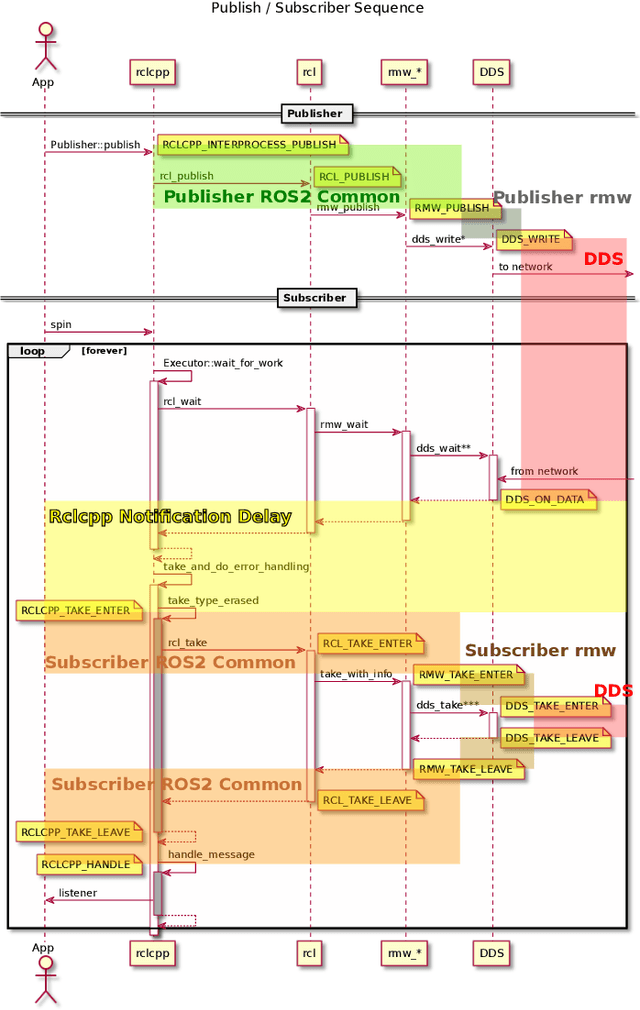
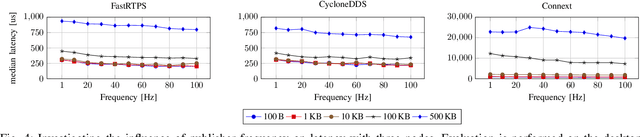
Robot Operating System 2 (ROS2) targets distributed real-time systems. Especially in tight real-time control loops, latency in data processing and communication can lead to instabilities. As ROS2 encourages splitting of the data-processing pipelines into several modules, it is important to understand the latency implications of such modularization. In this paper, we investigate the end-to-end latency of ROS2 data-processing pipeline with different Data Distribution Service (DDS) middlewares. In addition, we profile the ROS2 stack and point out latency bottlenecks. Our findings indicate that end-to-end latency strongly depends on the used DDS middleware. Moreover, we show that ROS2 can lead to 50 % latency overhead compared to using low-level DDS communications. Our results imply guidelines for designing modular ROS2 architectures and indicate possibilities for reducing the ROS2 overhead.
Efficient Training of Neural Transducer for Speech Recognition
Apr 22, 2022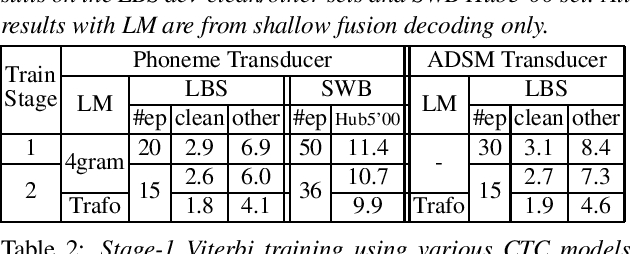
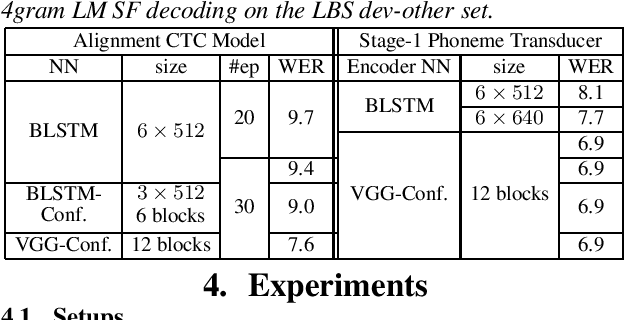
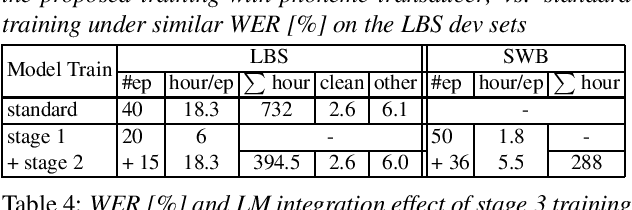
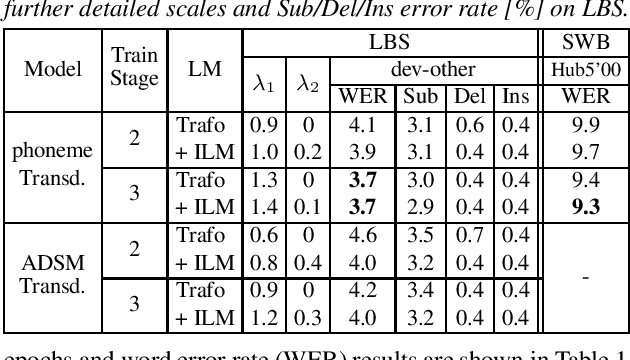
As one of the most popular sequence-to-sequence modeling approaches for speech recognition, the RNN-Transducer has achieved evolving performance with more and more sophisticated neural network models of growing size and increasing training epochs. While strong computation resources seem to be the prerequisite of training superior models, we try to overcome it by carefully designing a more efficient training pipeline. In this work, we propose an efficient 3-stage progressive training pipeline to build highly-performing neural transducer models from scratch with very limited computation resources in a reasonable short time period. The effectiveness of each stage is experimentally verified on both Librispeech and Switchboard corpora. The proposed pipeline is able to train transducer models approaching state-of-the-art performance with a single GPU in just 2-3 weeks. Our best conformer transducer achieves 4.1% WER on Librispeech test-other with only 35 epochs of training.