 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Formalizing Preferences Over Runtime Distributions
May 25, 2022
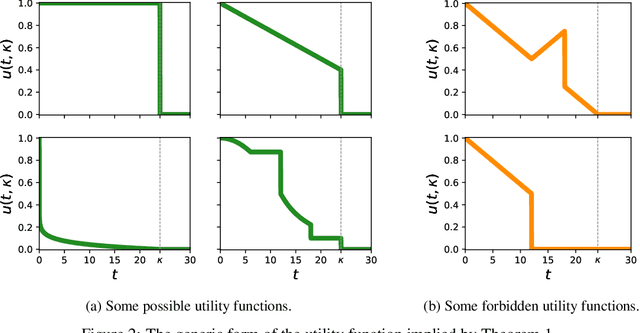
When trying to solve a computational problem we are often faced with a choice among algorithms that are all guaranteed to return the right answer but that differ in their runtime distributions (e.g., SAT solvers, sorting algorithms). This paper aims to lay theoretical foundations for such choices by formalizing preferences over runtime distributions. It might seem that we should simply prefer the algorithm that minimizes expected runtime. However, such preferences would be driven by exactly how slow our algorithm is on bad inputs, whereas in practice we are typically willing to cut off occasional, sufficiently long runs before they finish. We propose a principled alternative, taking a utility-theoretic approach to characterize the scoring functions that describe preferences over algorithms. These functions depend on the way our value for solving our problem decreases with time and on the distribution from which captimes are drawn. We describe examples of realistic utility functions and show how to leverage a maximum-entropy approach for modeling underspecified captime distributions. Finally, we show how to efficiently estimate an algorithm's expected utility from runtime samples.
SCGC : Self-Supervised Contrastive Graph Clustering
Apr 27, 2022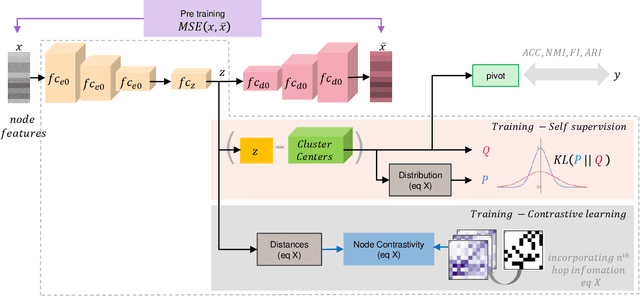
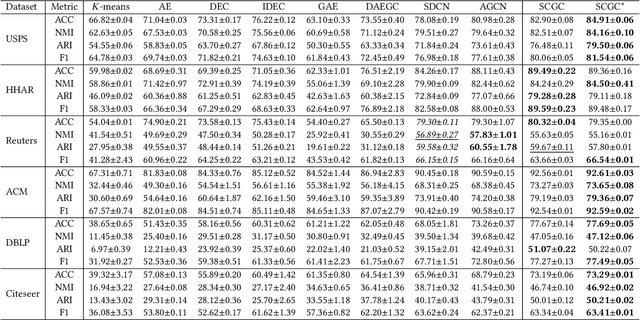
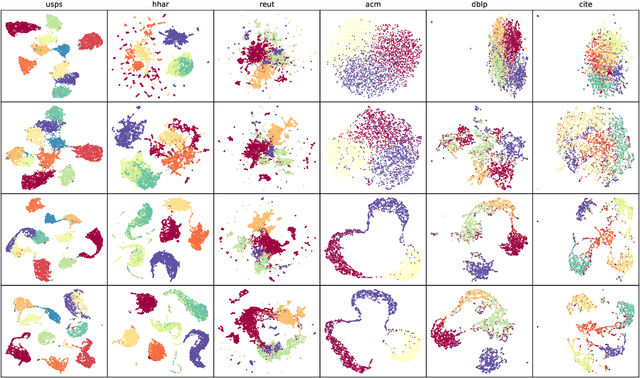
Graph clustering discovers groups or communities within networks. Deep learning methods such as autoencoders (AE) extract effective clustering and downstream representations but cannot incorporate rich structural information. While Graph Neural Networks (GNN) have shown great success in encoding graph structure, typical GNNs based on convolution or attention variants suffer from over-smoothing, noise, heterophily, are computationally expensive and typically require the complete graph being present. Instead, we propose Self-Supervised Contrastive Graph Clustering (SCGC), which imposes graph-structure via contrastive loss signals to learn discriminative node representations and iteratively refined soft cluster labels. We also propose SCGC*, with a more effective, novel, Influence Augmented Contrastive (IAC) loss to fuse richer structural information, and half the original model parameters. SCGC(*) is faster with simple linear units, completely eliminate convolutions and attention of traditional GNNs, yet efficiently incorporates structure. It is impervious to layer depth and robust to over-smoothing, incorrect edges and heterophily. It is scalable by batching, a limitation in many prior GNN models, and trivially parallelizable. We obtain significant improvements over state-of-the-art on a wide range of benchmark graph datasets, including images, sensor data, text, and citation networks efficiently. Specifically, 20% on ARI and 18% on NMI for DBLP; overall 55% reduction in training time and overall, 81% reduction on inference time. Our code is available at : https://github.com/gayanku/SCGC
"And Then There Were None": Cracking White-box DNN Watermarks via Invariant Neuron Transforms
Apr 30, 2022
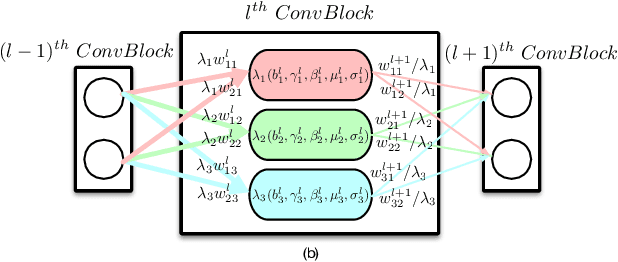
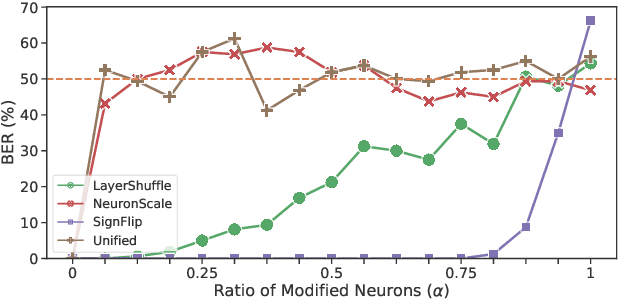
Recently, how to protect the Intellectual Property (IP) of deep neural networks (DNN) becomes a major concern for the AI industry. To combat potential model piracy, recent works explore various watermarking strategies to embed secret identity messages into the prediction behaviors or the internals (e.g., weights and neuron activation) of the target model. Sacrificing less functionality and involving more knowledge about the target model, the latter branch of watermarking schemes (i.e., white-box model watermarking) is claimed to be accurate, credible and secure against most known watermark removal attacks, with emerging research efforts and applications in the industry. In this paper, we present the first effective removal attack which cracks almost all the existing white-box watermarking schemes with provably no performance overhead and no required prior knowledge. By analyzing these IP protection mechanisms at the granularity of neurons, we for the first time discover their common dependence on a set of fragile features of a local neuron group, all of which can be arbitrarily tampered by our proposed chain of invariant neuron transforms. On $9$ state-of-the-art white-box watermarking schemes and a broad set of industry-level DNN architectures, our attack for the first time reduces the embedded identity message in the protected models to be almost random. Meanwhile, unlike known removal attacks, our attack requires no prior knowledge on the training data distribution or the adopted watermark algorithms, and leaves model functionality intact.
Longitudinal cardio-respiratory fitness prediction through free-living wearable sensors
May 06, 2022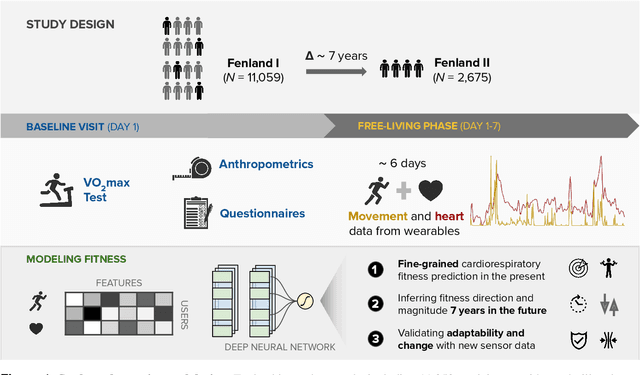
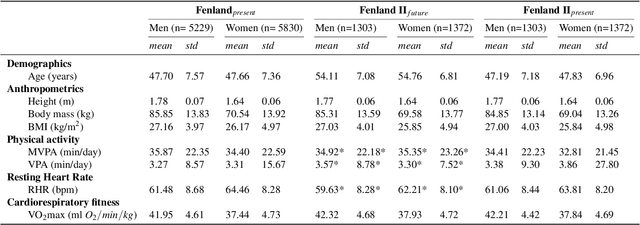
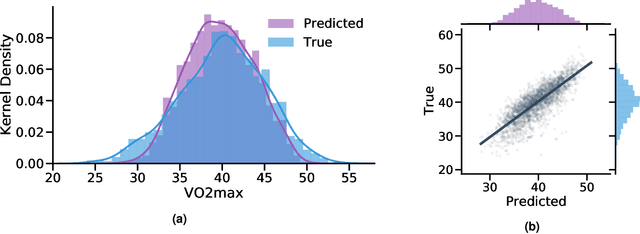
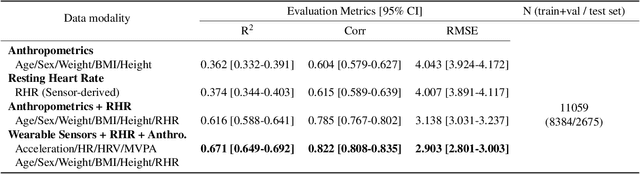
Cardiorespiratory fitness is an established predictor of metabolic disease and mortality. Fitness is directly measured as maximal oxygen consumption (VO2max), or indirectly assessed using heart rate response to a standard exercise test. However, such testing is costly and burdensome, limiting its utility and scalability. Fitness can also be approximated using resting heart rate and self-reported exercise habits but with lower accuracy. Modern wearables capture dynamic heart rate data which, in combination with machine learning models, could improve fitness prediction. In this work, we analyze movement and heart rate signals from wearable sensors in free-living conditions from 11,059 participants who also underwent a standard exercise test, along with a longitudinal repeat cohort of 2,675 participants. We design algorithms and models that convert raw sensor data into cardio-respiratory fitness estimates, and validate these estimates' ability to capture fitness profiles in a longitudinal cohort over time while subjects engaged in real-world (non-exercise) behaviour. Additionally, we validate our methods with a third external cohort of 181 participants who underwent maximal VO2max testing, which is considered the gold standard measurement because it requires reaching one's maximum heart rate and exhaustion level. Our results show that the developed models yield a high correlation (r = 0.82, 95CI 0.80-0.83), when compared to the ground truth in a holdout sample. These models outperform conventional non-exercise fitness models and traditional bio-markers using measurements of normal daily living without the need for a specific exercise test. Additionally, we show the adaptability and applicability of this approach for detecting fitness change over time in the longitudinal subsample that repeated measurements after 7 years.
Process Model Forecasting Using Time Series Analysis of Event Sequence Data
May 03, 2021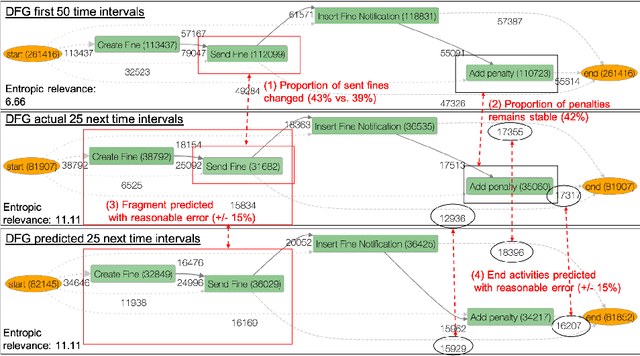

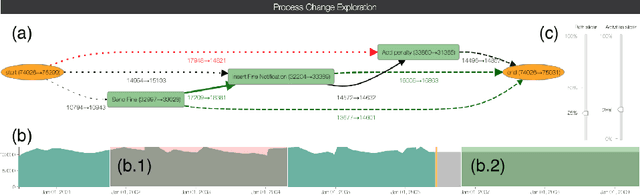
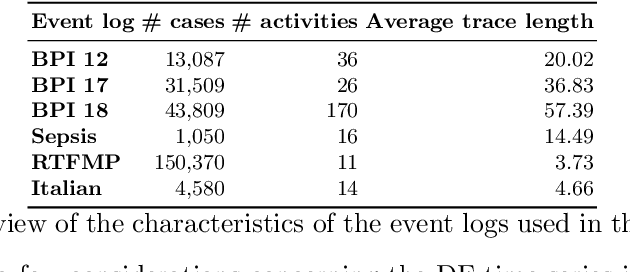
Process analytics is the field focusing on predictions for individual process instances or overall process models. At the instance level, various novel techniques have been recently devised, tackling next activity, remaining time, and outcome prediction. At the model level, there is a notable void. It is the ambition of this paper to fill this gap. To this end, we develop a technique to forecast the entire process model from historical event data. A forecasted model is a will-be process model representing a probable future state of the overall process. Such a forecast helps to investigate the consequences of drift and emerging bottlenecks. Our technique builds on a representation of event data as multiple time series, each capturing the evolution of a behavioural aspect of the process model, such that corresponding forecasting techniques can be applied. Our implementation demonstrates the accuracy of our technique on real-world event log data.
SyntheX: Scaling Up Learning-based X-ray Image Analysis Through In Silico Experiments
Jun 13, 2022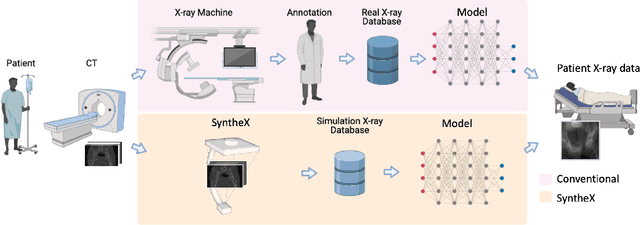

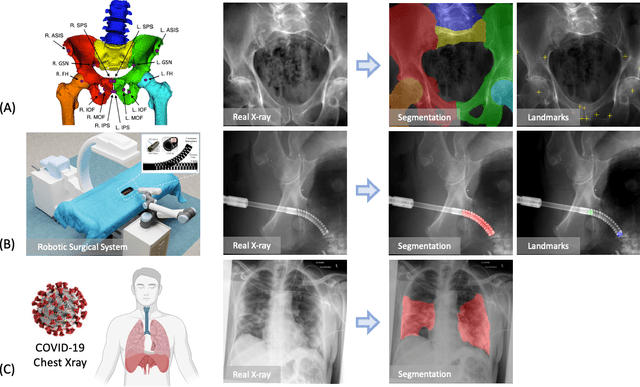

Artificial intelligence (AI) now enables automated interpretation of medical images for clinical use. However, AI's potential use for interventional images (versus those involved in triage or diagnosis), such as for guidance during surgery, remains largely untapped. This is because surgical AI systems are currently trained using post hoc analysis of data collected during live surgeries, which has fundamental and practical limitations, including ethical considerations, expense, scalability, data integrity, and a lack of ground truth. Here, we demonstrate that creating realistic simulated images from human models is a viable alternative and complement to large-scale in situ data collection. We show that training AI image analysis models on realistically synthesized data, combined with contemporary domain generalization or adaptation techniques, results in models that on real data perform comparably to models trained on a precisely matched real data training set. Because synthetic generation of training data from human-based models scales easily, we find that our model transfer paradigm for X-ray image analysis, which we refer to as SyntheX, can even outperform real data-trained models due to the effectiveness of training on a larger dataset. We demonstrate the potential of SyntheX on three clinical tasks: Hip image analysis, surgical robotic tool detection, and COVID-19 lung lesion segmentation. SyntheX provides an opportunity to drastically accelerate the conception, design, and evaluation of intelligent systems for X-ray-based medicine. In addition, simulated image environments provide the opportunity to test novel instrumentation, design complementary surgical approaches, and envision novel techniques that improve outcomes, save time, or mitigate human error, freed from the ethical and practical considerations of live human data collection.
An efficient estimation of time-varying parameters of dynamic models by combining offline batch optimization and online data assimilation
Oct 24, 2021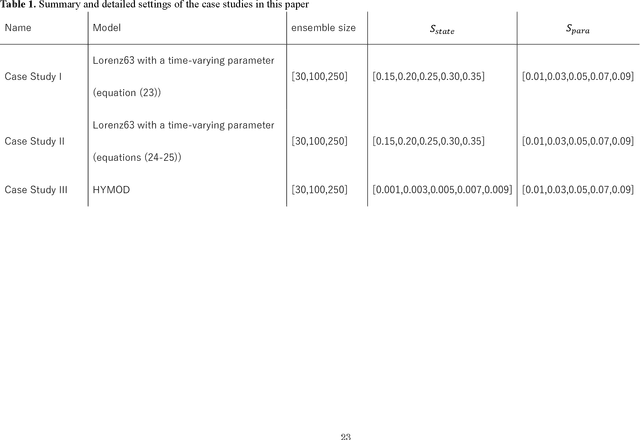

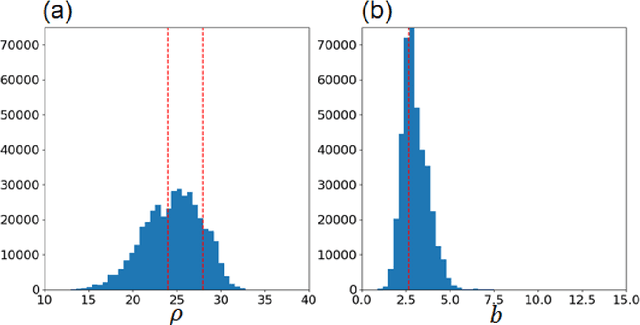
It is crucially important to estimate unknown parameters in earth system models by integrating observation and numerical simulation. For many applications in earth system sciences, the optimization method which allows parameters to temporally change is required. Here I present an efficient and practical method to estimate the time-varying parameters of relatively low dimensional models. I propose combining offline batch optimization and online data assimilation. In the newly proposed method, called Hybrid Offline Online Parameter Estimation with Particle Filtering (HOOPE-PF), I constrain the estimated model parameters in sequential data assimilation to the result of offline batch optimization in which the posterior distribution of model parameters is obtained by comparing the simulated and observed climatology. The HOOPE-PF outperforms the original sampling-importance-resampling particle filter in the synthetic experiment with the toy model and the real-data experiment with the conceptual hydrological model. The advantage of HOOPE-PF is that the performance of the online data assimilation is not greatly affected by the hyperparameter of ensemble data assimilation which contributes to inflating the ensemble variance of estimated parameters.
Online Non-linear Topology Identification from Graph-connected Time Series
Mar 31, 2021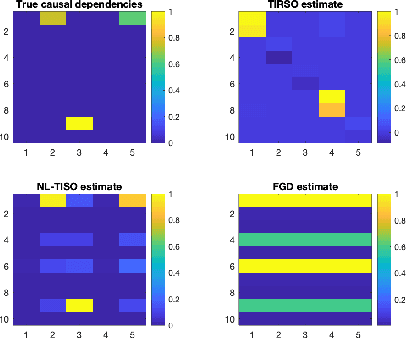
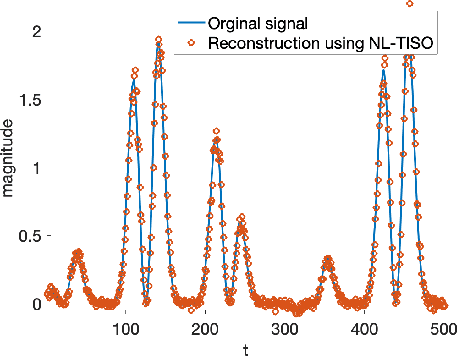
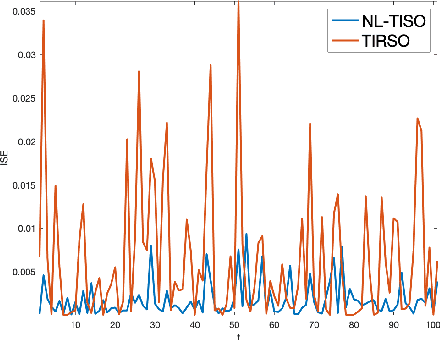
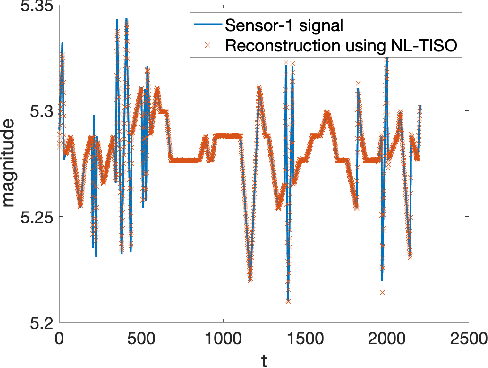
Estimating the unknown causal dependencies among graph-connected time series plays an important role in many applications, such as sensor network analysis, signal processing over cyber-physical systems, and finance engineering. Inference of such causal dependencies, often know as topology identification, is not well studied for non-linear non-stationary systems, and most of the existing methods are batch-based which are not capable of handling streaming sensor signals. In this paper, we propose an online kernel-based algorithm for topology estimation of non-linear vector autoregressive time series by solving a sparse online optimization framework using the composite objective mirror descent method. Experiments conducted on real and synthetic data sets show that the proposed algorithm outperforms the state-of-the-art methods for topology estimation.
Auto-SDE: Learning effective reduced dynamics from data-driven stochastic dynamical systems
May 09, 2022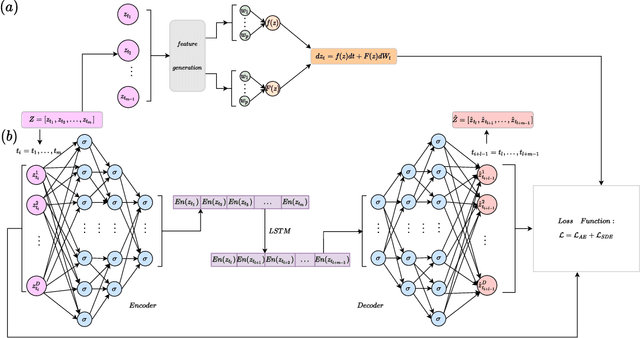
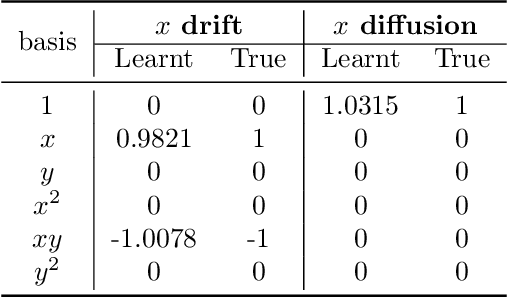
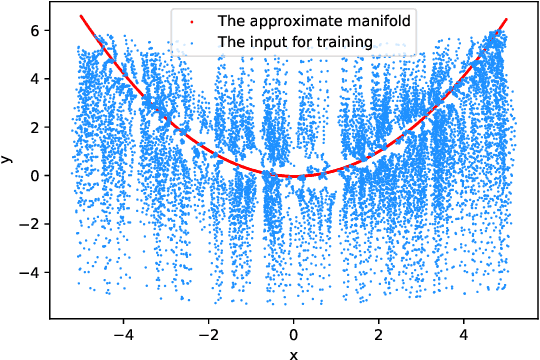
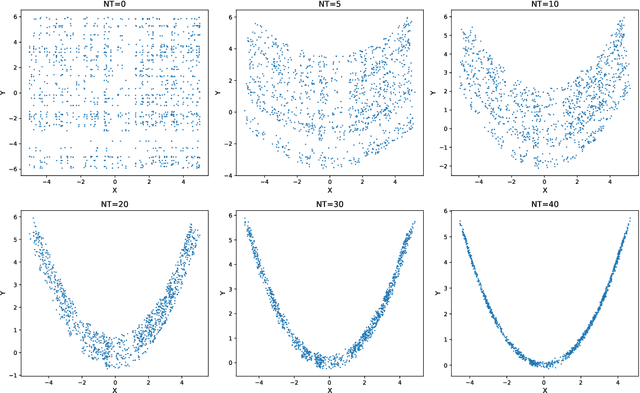
Multiscale stochastic dynamical systems have been widely adopted to scientific and engineering problems due to their capability of depicting complex phenomena in many real world applications. This work is devoted to investigating the effective reduced dynamics for a slow-fast stochastic dynamical system. Given observation data on a short-term period satisfying some unknown slow-fast stochastic system, we propose a novel algorithm including a neural network called Auto-SDE to learn invariant slow manifold. Our approach captures the evolutionary nature of a series of time-dependent autoencoder neural networks with the loss constructed from a discretized stochastic differential equation. Our algorithm is also proved to be accurate, stable and effective through numerical experiments under various evaluation metrics.
An Intelligent End-to-End Neural Architecture Search Framework for Electricity Forecasting Model Development
Mar 25, 2022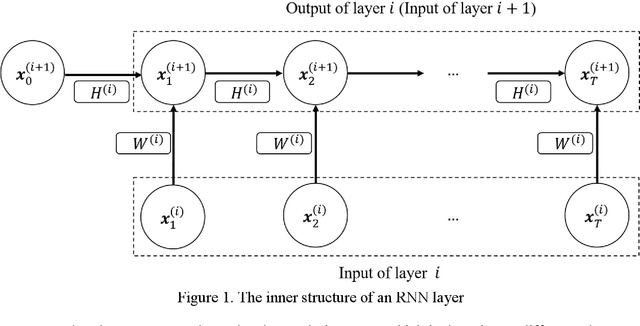

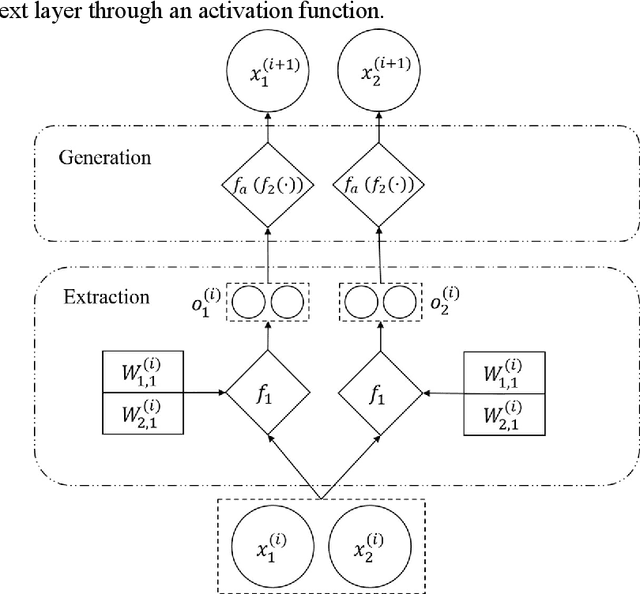

Recent years have witnessed an exponential growth in developing deep learning (DL) models for the time-series electricity forecasting in power systems. However, most of the proposed models are designed based on the designers' inherent knowledge and experience without elaborating on the suitability of the proposed neural architectures. Moreover, these models cannot be self-adjusted to the dynamically changing data patterns due to an inflexible design of their structures. Even though several latest studies have considered application of the neural architecture search (NAS) technique for obtaining a network with an optimized structure in the electricity forecasting sector, their training process is quite time-consuming, computationally expensive and not intelligent, indicating that the NAS application in electricity forecasting area is still at an infancy phase. In this research study, we propose an intelligent automated architecture search (IAAS) framework for the development of time-series electricity forecasting models. The proposed framework contains two primary components, i.e., network function-preserving transformation operation and reinforcement learning (RL)-based network transformation control. In the first component, we introduce a theoretical function-preserving transformation of recurrent neural networks (RNN) to the literature for capturing the hidden temporal patterns within the time-series data. In the second component, we develop three RL-based transformation actors and a net pool to intelligently and effectively search a high-quality neural architecture. After conducting comprehensive experiments on two publicly-available electricity load datasets and two wind power datasets, we demonstrate that the proposed IAAS framework significantly outperforms the ten existing models or methods in terms of forecasting accuracy and stability.