 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph-Survival: A Survival Analysis Framework for Machine Learning on Temporal Network
Mar 14, 2022
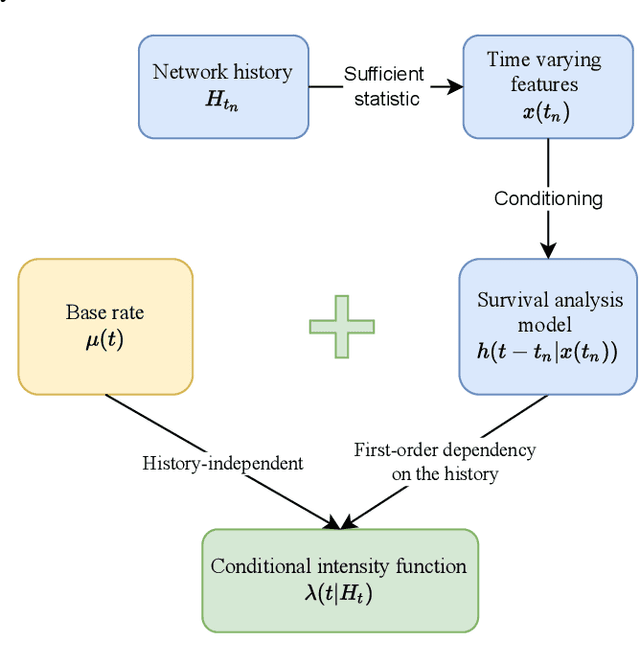
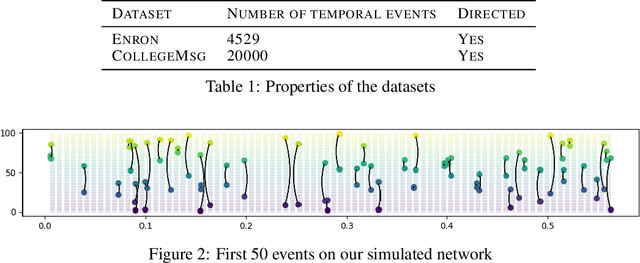
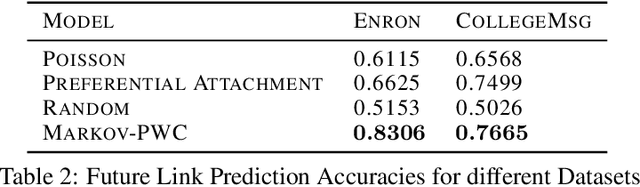
Continuous time temporal networks are attracting increasing attention due their omnipresence in real-world datasets and they manifold applications. While static network models have been successful in capturing static topological regularities, they often fail to model effects coming from the causal nature that explain the generation of networks. Exploiting the temporal aspect of networks has thus been the focus of various studies in the last decades. We propose a framework for designing generative models for continuous time temporal networks. Assuming a first order Markov assumption on the edge-specific temporal point processes enables us to flexibly apply survival analysis models directly on the waiting time between events, while using time-varying history-based features as covariates for these predictions. This approach links the well-documented field of temporal networks analysis through multivariate point processes, with methodological tools adapted from survival analysis. We propose a fitting method for models within this framework, and an algorithm for simulating new temporal networks having desired properties. We evaluate our method on a downstream future link prediction task, and provide a qualitative assessment of the network simulations.
Large-scale multi-objective influence maximisation with network downscaling
Apr 13, 2022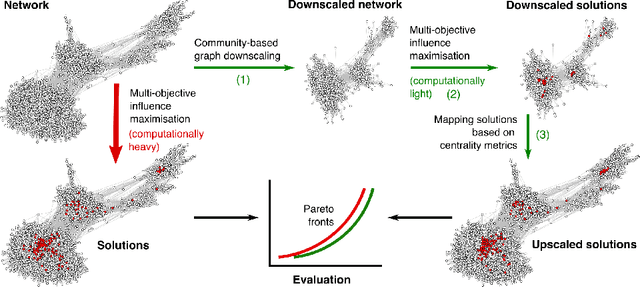

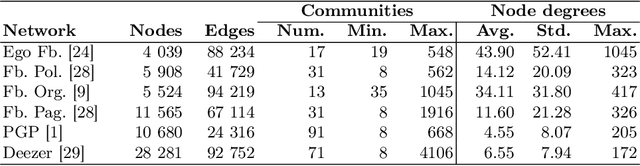
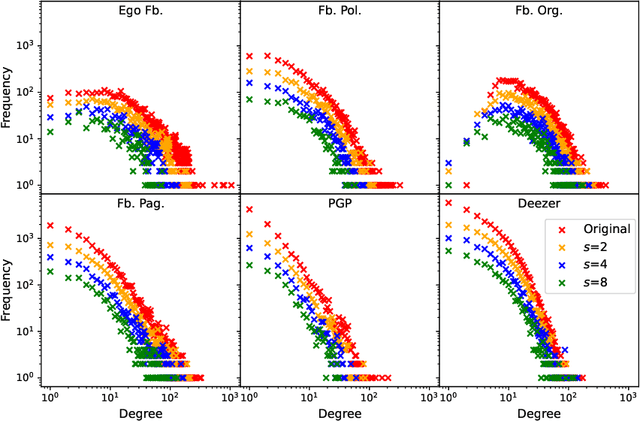
Finding the most influential nodes in a network is a computationally hard problem with several possible applications in various kinds of network-based problems. While several methods have been proposed for tackling the influence maximisation (IM) problem, their runtime typically scales poorly when the network size increases. Here, we propose an original method, based on network downscaling, that allows a multi-objective evolutionary algorithm (MOEA) to solve the IM problem on a reduced scale network, while preserving the relevant properties of the original network. The downscaled solution is then upscaled to the original network, using a mechanism based on centrality metrics such as PageRank. Our results on eight large networks (including two with $\sim$50k nodes) demonstrate the effectiveness of the proposed method with a more than 10-fold runtime gain compared to the time needed on the original network, and an up to $82\%$ time reduction compared to CELF.
An Experimental Review on Deep Learning Architectures for Time Series Forecasting
Mar 22, 2021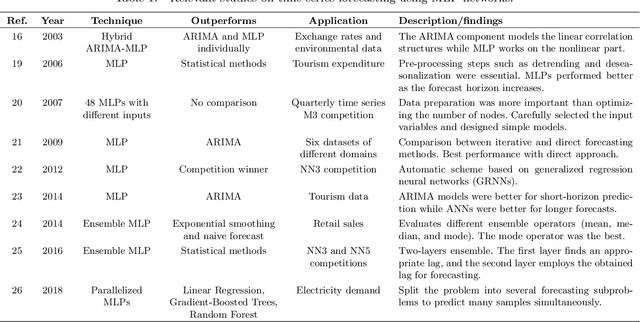
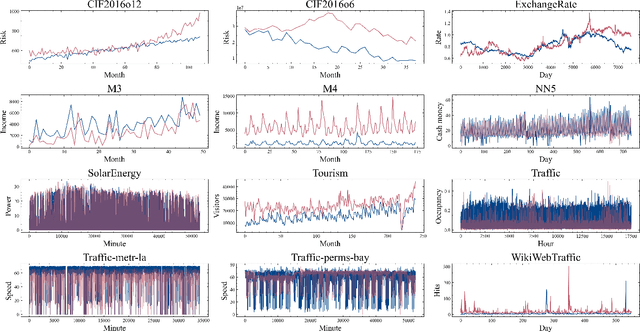
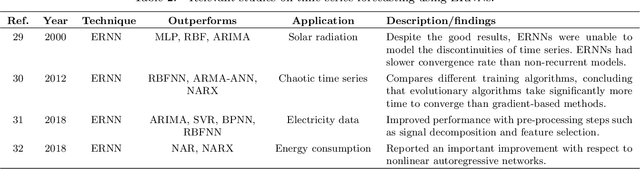
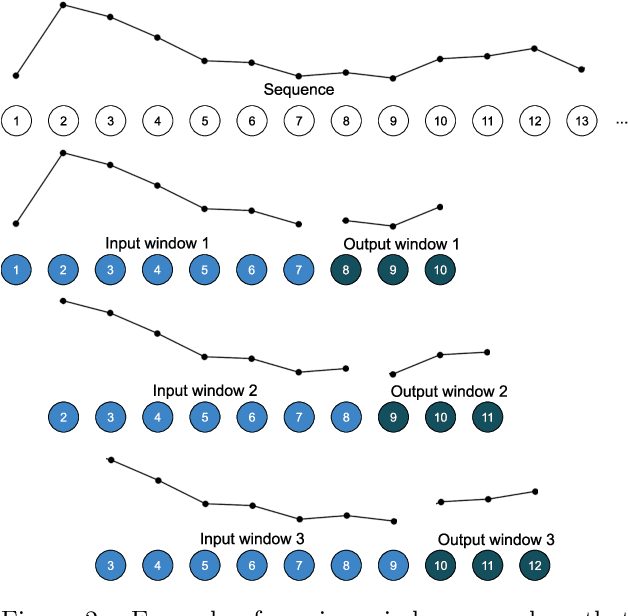
In recent years, deep learning techniques have outperformed traditional models in many machine learning tasks. Deep neural networks have successfully been applied to address time series forecasting problems, which is a very important topic in data mining. They have proved to be an effective solution given their capacity to automatically learn the temporal dependencies present in time series. However, selecting the most convenient type of deep neural network and its parametrization is a complex task that requires considerable expertise. Therefore, there is a need for deeper studies on the suitability of all existing architectures for different forecasting tasks. In this work, we face two main challenges: a comprehensive review of the latest works using deep learning for time series forecasting; and an experimental study comparing the performance of the most popular architectures. The comparison involves a thorough analysis of seven types of deep learning models in terms of accuracy and efficiency. We evaluate the rankings and distribution of results obtained with the proposed models under many different architecture configurations and training hyperparameters. The datasets used comprise more than 50000 time series divided into 12 different forecasting problems. By training more than 38000 models on these data, we provide the most extensive deep learning study for time series forecasting. Among all studied models, the results show that long short-term memory (LSTM) and convolutional networks (CNN) are the best alternatives, with LSTMs obtaining the most accurate forecasts. CNNs achieve comparable performance with less variability of results under different parameter configurations, while also being more efficient.
It Isn't Sh!tposting, It's My CAT Posting
May 18, 2022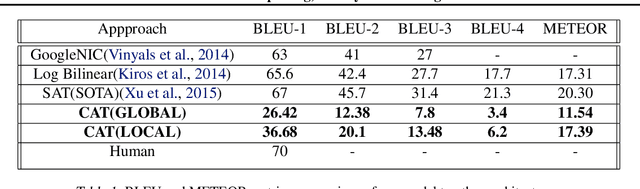


In this paper, we describe a novel architecture which can generate hilarious captions for a given input image. The architecture is split into two halves, i.e. image captioning and hilarious text conversion. The architecture starts with a pre-trained CNN model, VGG16 in this implementation, and applies attention LSTM on it to generate normal caption. These normal captions then are fed forward to our hilarious text conversion transformer which converts this text into something hilarious while maintaining the context of the input image. The architecture can also be split into two halves and only the seq2seq transformer can be used to generate hilarious caption by inputting a sentence.This paper aims to help everyday user to be more lazy and hilarious at the same time by generating captions using CATNet.
Cooperative Multi-Agent Trajectory Generation with Modular Bayesian Optimization
Jun 01, 2022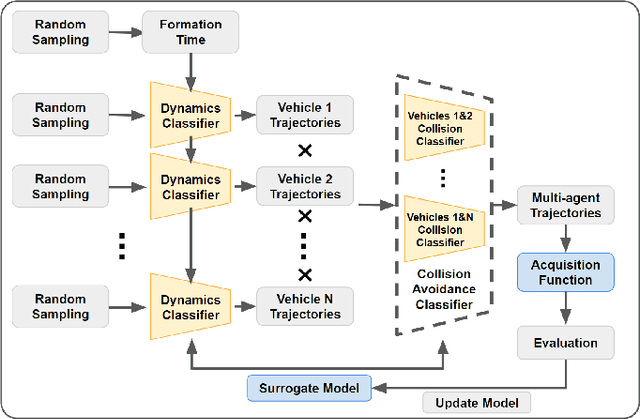
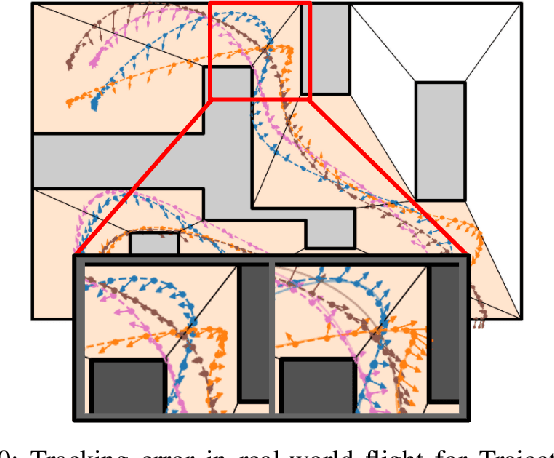
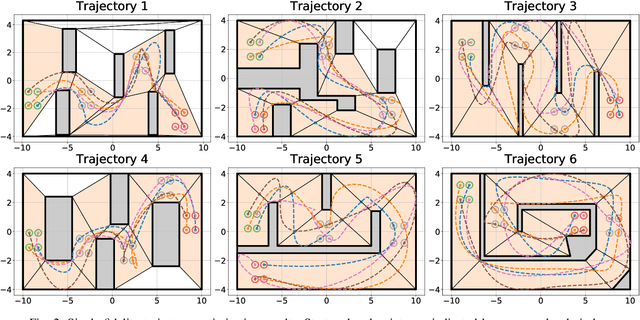
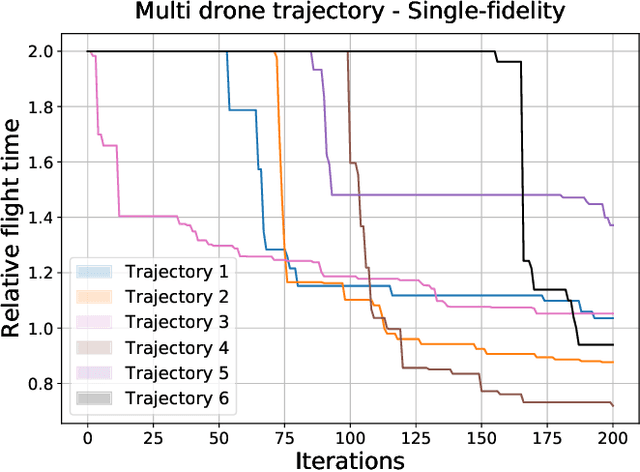
We present a modular Bayesian optimization framework that efficiently generates time-optimal trajectories for a cooperative multi-agent system, such as a team of UAVs. Existing methods for multi-agent trajectory generation often rely on overly conservative constraints to reduce the complexity of this high-dimensional planning problem, leading to suboptimal solutions. We propose a novel modular structure for the Bayesian optimization model that consists of multiple Gaussian process surrogate models that represent the dynamic feasibility and collision avoidance constraints. This modular structure alleviates the stark increase in computational cost with problem dimensionality and enables the use of minimal constraints in the joint optimization of the multi-agent trajectories. The efficiency of the algorithm is further improved by introducing a scheme for simultaneous evaluation of the Bayesian optimization acquisition function and random sampling. The modular BayesOpt algorithm was applied to optimize multi-agent trajectories through six unique environments using multi-fidelity evaluations from various data sources. It was found that the resulting trajectories are faster than those obtained from two baseline methods. The optimized trajectories were validated in real-world experiments using four quadcopters that fly within centimeters of each other at speeds up to 7.4 m/s.
Heterogeneous Graph Neural Networks using Self-supervised Reciprocally Contrastive Learning
Apr 30, 2022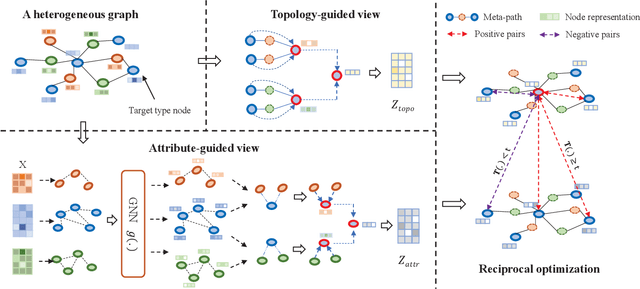
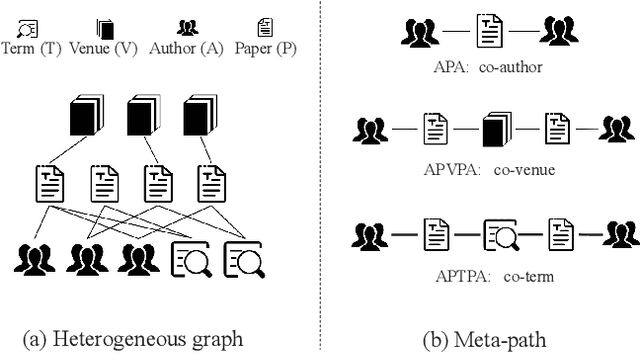
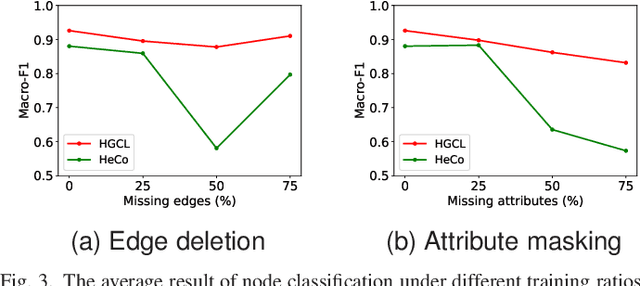
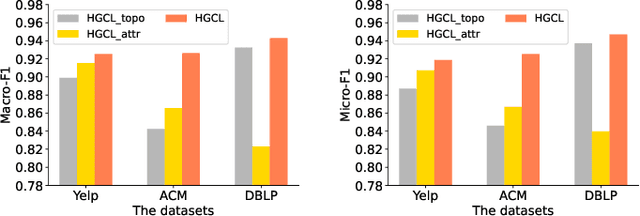
Heterogeneous graph neural network (HGNN) is a very popular technique for the modeling and analysis of heterogeneous graphs. Most existing HGNN-based approaches are supervised or semi-supervised learning methods requiring graphs to be annotated, which is costly and time-consuming. Self-supervised contrastive learning has been proposed to address the problem of requiring annotated data by mining intrinsic information hidden within the given data. However, the existing contrastive learning methods are inadequate for heterogeneous graphs because they construct contrastive views only based on data perturbation or pre-defined structural properties (e.g., meta-path) in graph data while ignore the noises that may exist in both node attributes and graph topologies. We develop for the first time a novel and robust heterogeneous graph contrastive learning approach, namely HGCL, which introduces two views on respective guidance of node attributes and graph topologies and integrates and enhances them by reciprocally contrastive mechanism to better model heterogeneous graphs. In this new approach, we adopt distinct but most suitable attribute and topology fusion mechanisms in the two views, which are conducive to mining relevant information in attributes and topologies separately. We further use both attribute similarity and topological correlation to construct high-quality contrastive samples. Extensive experiments on three large real-world heterogeneous graphs demonstrate the superiority and robustness of HGCL over state-of-the-art methods.
Computationally efficient joint coordination of multiple electric vehicle charging points using reinforcement learning
Mar 26, 2022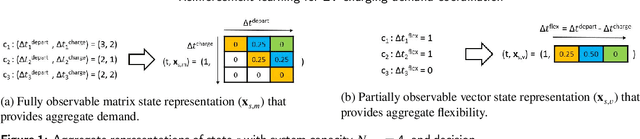
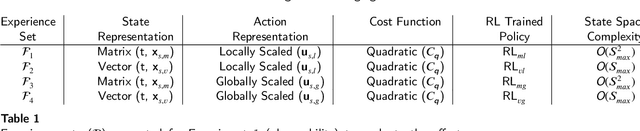
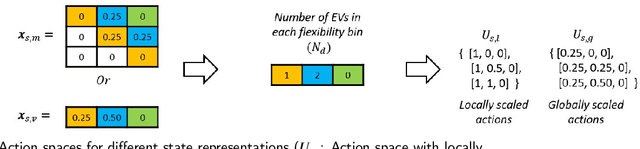

A major challenge in todays power grid is to manage the increasing load from electric vehicle (EV) charging. Demand response (DR) solutions aim to exploit flexibility therein, i.e., the ability to shift EV charging in time and thus avoid excessive peaks or achieve better balancing. Whereas the majority of existing research works either focus on control strategies for a single EV charger, or use a multi-step approach (e.g., a first high level aggregate control decision step, followed by individual EV control decisions), we rather propose a single-step solution that jointly coordinates multiple charging points at once. In this paper, we further refine an initial proposal using reinforcement learning (RL), specifically addressing computational challenges that would limit its deployment in practice. More precisely, we design a new Markov decision process (MDP) formulation of the EV charging coordination process, exhibiting only linear space and time complexity (as opposed to the earlier quadratic space complexity). We thus improve upon earlier state-of-the-art, demonstrating 30% reduction of training time in our case study using real-world EV charging session data. Yet, we do not sacrifice the resulting performance in meeting the DR objectives: our new RL solutions still improve the performance of charging demand coordination by 40-50% compared to a business-as-usual policy (that charges EV fully upon arrival) and 20-30% compared to a heuristic policy (that uniformly spreads individual EV charging over time).
Deepfake histological images for enhancing digital pathology
Jun 16, 2022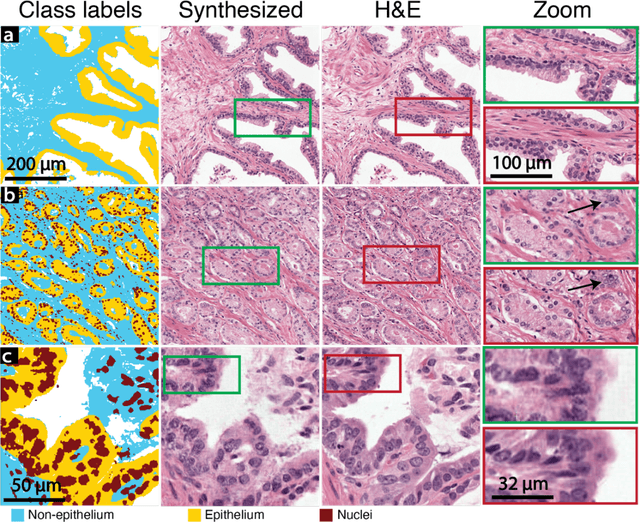
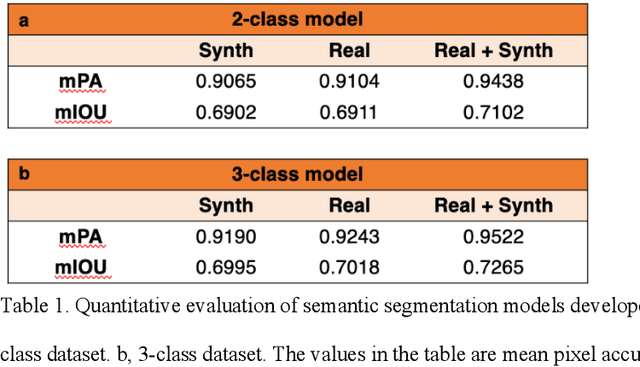
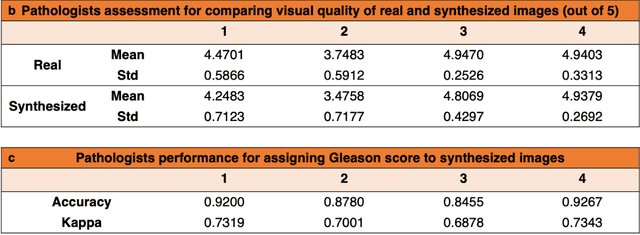
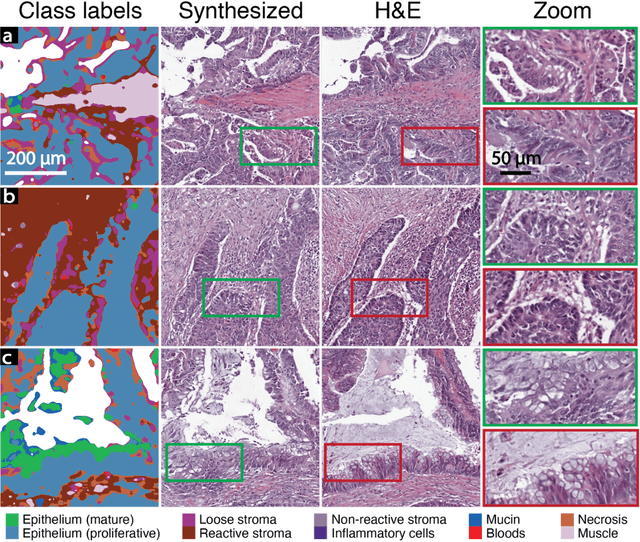
An optical microscopic examination of thinly cut stained tissue on glass slides prepared from a FFPE tissue blocks is the gold standard for tissue diagnostics. In addition, the diagnostic abilities and expertise of any pathologist is dependent on their direct experience with common as well as rarer variant morphologies. Recently, deep learning approaches have been used to successfully show a high level of accuracy for such tasks. However, obtaining expert-level annotated images is an expensive and time-consuming task and artificially synthesized histological images can prove greatly beneficial. Here, we present an approach to not only generate histological images that reproduce the diagnostic morphologic features of common disease but also provide a user ability to generate new and rare morphologies. Our approach involves developing a generative adversarial network model that synthesizes pathology images constrained by class labels. We investigated the ability of this framework in synthesizing realistic prostate and colon tissue images and assessed the utility of these images in augmenting diagnostic ability of machine learning methods as well as their usability by a panel of experienced anatomic pathologists. Synthetic data generated by our framework performed similar to real data in training a deep learning model for diagnosis. Pathologists were not able to distinguish between real and synthetic images and showed a similar level of inter-observer agreement for prostate cancer grading. We extended the approach to significantly more complex images from colon biopsies and showed that the complex microenvironment in such tissues can also be reproduced. Finally, we present the ability for a user to generate deepfake histological images via a simple markup of sematic labels.
Action Noise in Off-Policy Deep Reinforcement Learning: Impact on Exploration and Performance
Jun 08, 2022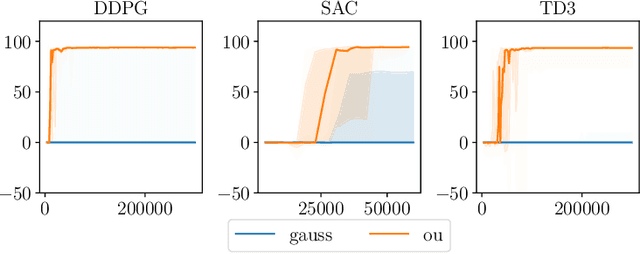
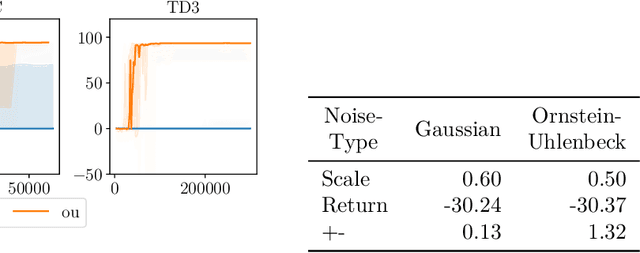
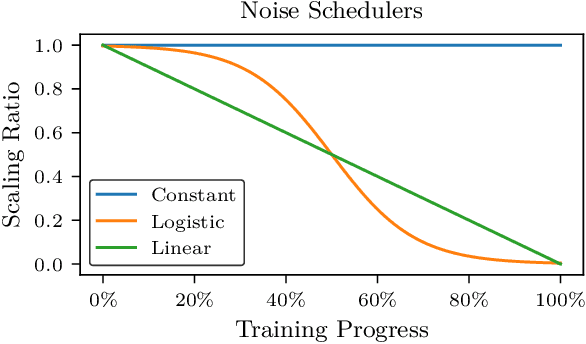
Many deep reinforcement learning algorithms rely on simple forms of exploration, such as the additive action-noise often used in continuous control domains. Typically, the scaling factor of this action noise is chosen as a hyper-parameter and kept constant during training. In this paper, we analyze how the learned policy is impacted by the noise type, scale, and reducing of the scaling factor over time. We consider the two most prominent types of action-noise: Gaussian and Ornstein-Uhlenbeck noise, and perform a vast experimental campaign by systematically varying the noise type and scale parameter, and by measuring variables of interest like the expected return of the policy and the state space coverage during exploration. For the latter, we propose a novel state-space coverage measure $\operatorname{X}_{\mathcal{U}\text{rel}}$ that is more robust to boundary artifacts than previously proposed measures. Larger noise scales generally increase state space coverage. However, we found that increasing the space coverage using a larger noise scale is often not beneficial. On the contrary, reducing the noise-scale over the training process reduces the variance and generally improves the learning performance. We conclude that the best noise-type and scale are environment dependent, and based on our observations, derive heuristic rules for guiding the choice of the action noise as a starting point for further optimization.
RoCourseNet: Distributionally Robust Training of a Prediction Aware Recourse Model
Jun 01, 2022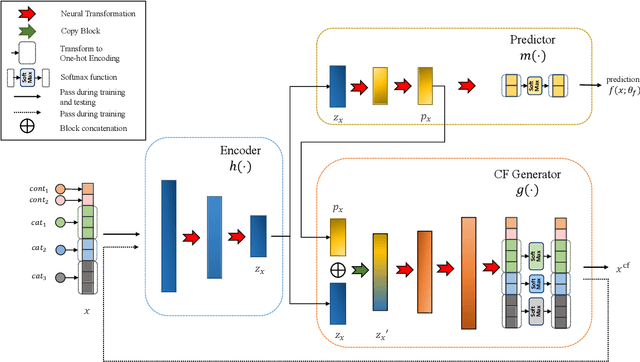
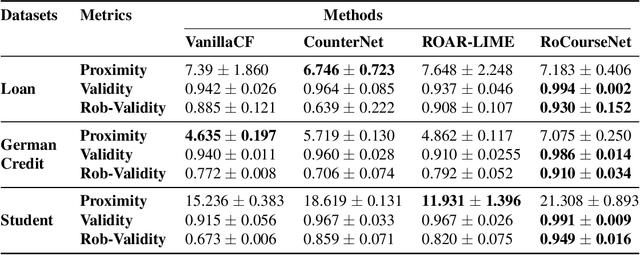
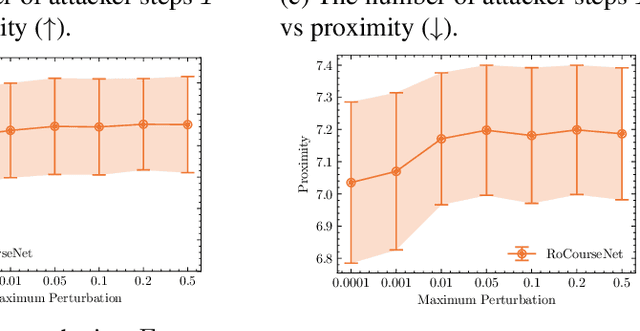
Counterfactual (CF) explanations for machine learning (ML) models are preferred by end-users, as they explain the predictions of ML models by providing a recourse case to individuals who are adversely impacted by predicted outcomes. Existing CF explanation methods generate recourses under the assumption that the underlying target ML model remains stationary over time. However, due to commonly occurring distributional shifts in training data, ML models constantly get updated in practice, which might render previously generated recourses invalid and diminish end-users trust in our algorithmic framework. To address this problem, we propose RoCourseNet, a training framework that jointly optimizes for predictions and robust recourses to future data shifts. We have three main contributions: (i) We propose a novel virtual data shift (VDS) algorithm to find worst-case shifted ML models by explicitly considering the worst-case data shift in the training dataset. (ii) We leverage adversarial training to solve a novel tri-level optimization problem inside RoCourseNet, which simultaneously generates predictions and corresponding robust recourses. (iii) Finally, we evaluate RoCourseNet's performance on three real-world datasets and show that RoCourseNet outperforms state-of-the-art baselines by 10% in generating robust CF explanations.