 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Escaping Spurious Local Minima of Low-Rank Matrix Factorization Through Convex Lifting
Apr 29, 2022
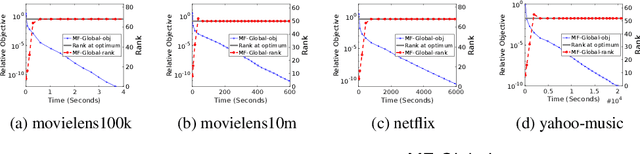
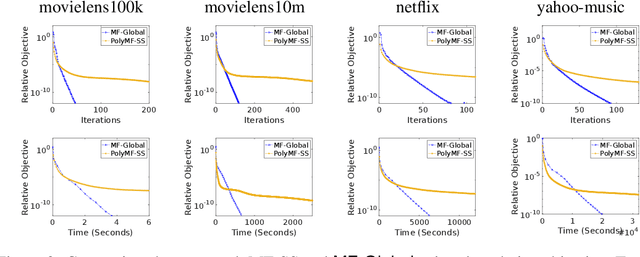
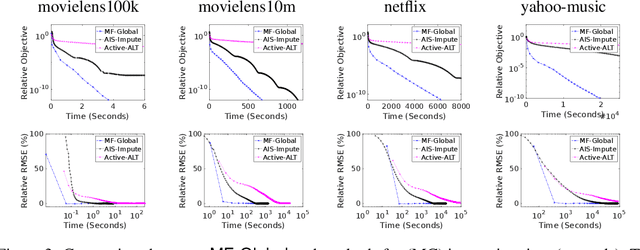
This work proposes a rapid global solver for nonconvex low-rank matrix factorization (MF) problems that we name MF-Global. Through convex lifting steps, our method efficiently escapes saddle points and spurious local minima ubiquitous in noisy real-world data, and is guaranteed to always converge to the global optima. Moreover, the proposed approach adaptively adjusts the rank for the factorization and provably identifies the optimal rank for MF automatically in the course of optimization through tools of manifold identification, and thus it also spends significantly less time on parameter tuning than existing MF methods, which require an exhaustive search for this optimal rank. On the other hand, when compared to methods for solving the lifted convex form only, MF-Global leads to significantly faster convergence and much shorter running time. Experiments on real-world large-scale recommendation system problems confirm that MF-Global can indeed effectively escapes spurious local solutions at which existing MF approaches stuck, and is magnitudes faster than state-of-the-art algorithms for the lifted convex form.
Finding Patterns in Visualized Data by Adding Redundant Visual Information
May 27, 2022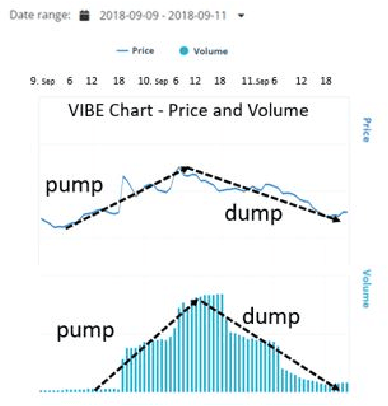


We present "PATRED", a technique that uses the addition of redundant information to facilitate the detection of specific, generally described patterns in line-charts during the visual exploration of the charts. We compared different versions of this technique, that differed in the way redundancy was added, using nine distance metrics (such as Euclidean, Pearson, Mutual Information and Jaccard) with judgments from data scientists which served as the "ground truth". Results were analyzed with correlations (R2), F1 scores and Mutual Information with the average ranking by the data scientists. Some distance metrics consistently benefit from the addition of redundant information, while others are only enhanced for specific types of data perturbations. The results demonstrate the value of adding redundancy to improve the identification of patterns in time-series data during visual exploration.
Conditional Generation of Medical Time Series for Extrapolation to Underrepresented Populations
Jan 20, 2022
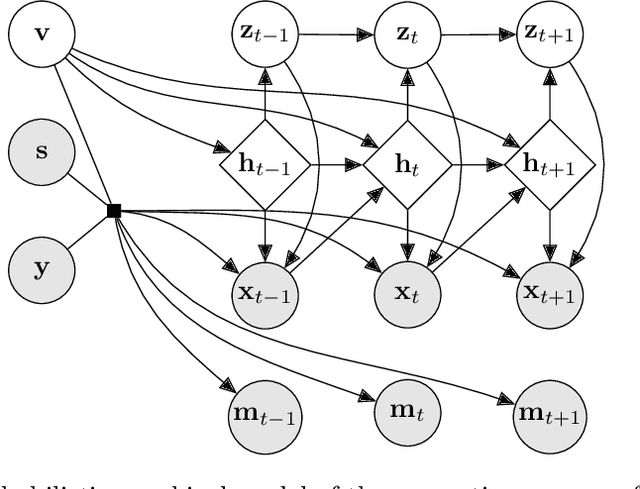
The widespread adoption of electronic health records (EHRs) and subsequent increased availability of longitudinal healthcare data has led to significant advances in our understanding of health and disease with direct and immediate impact on the development of new diagnostics and therapeutic treatment options. However, access to EHRs is often restricted due to their perceived sensitive nature and associated legal concerns, and the cohorts therein typically are those seen at a specific hospital or network of hospitals and therefore not representative of the wider population of patients. Here, we present HealthGen, a new approach for the conditional generation of synthetic EHRs that maintains an accurate representation of real patient characteristics, temporal information and missingness patterns. We demonstrate experimentally that HealthGen generates synthetic cohorts that are significantly more faithful to real patient EHRs than the current state-of-the-art, and that augmenting real data sets with conditionally generated cohorts of underrepresented subpopulations of patients can significantly enhance the generalisability of models derived from these data sets to different patient populations. Synthetic conditionally generated EHRs could help increase the accessibility of longitudinal healthcare data sets and improve the generalisability of inferences made from these data sets to underrepresented populations.
Toward a Wearable Biosensor Ecosystem on ROS 2 for Real-time Human-Robot Interaction Systems
Oct 08, 2021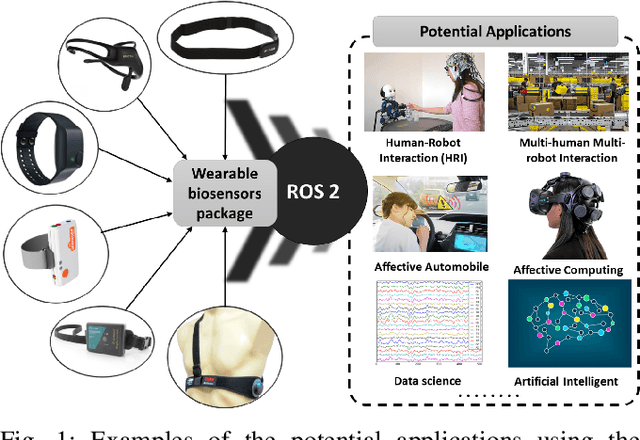
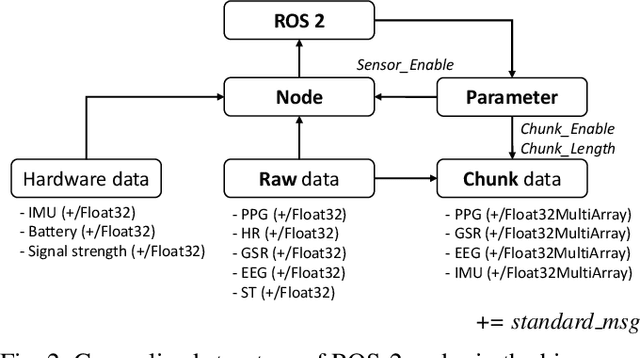

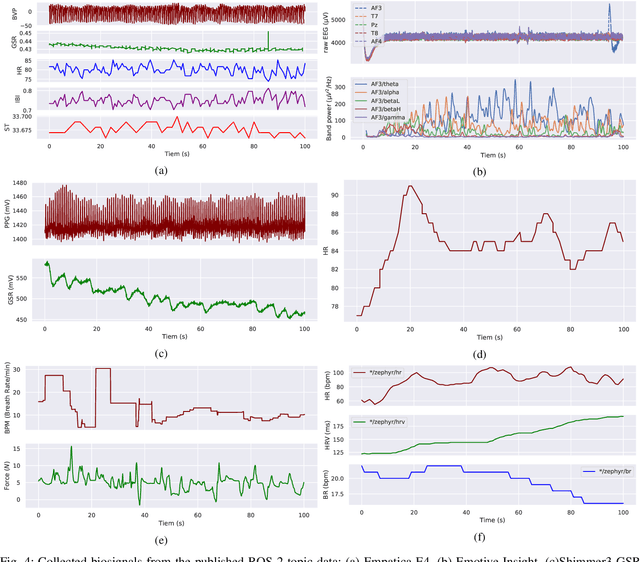
Wearable biosensors can enable continuous human data capture, facilitating development of real-world Human-Robot Interaction (HRI) systems. However, a lack of standardized libraries and implementations adds extraneous complexity to HRI system designs, and precludes collaboration across disciplines and institutions. Here, we introduce a novel wearable biosensor package for the Robot Operating System 2 (ROS 2) system. The ROS2 officially supports real-time computing and multi-robot systems, and thus provides easy-to-use and reliable streaming data from multiple nodes. The package standardizes biosensor HRI integration, lowers the technical barrier of entry, and expands the biosensor ecosystem into the robotics field. Each biosensor package node follows a generalized node and topic structure concentrated on ease of use. Current package capabilities, listed by biosensor, highlight package standardization. Collected example data demonstrate a full integration of each biosensor into ROS2. We expect that standardization of this biosensors package for ROS2 will greatly simplify use and cross-collaboration across many disciplines. The wearable biosensor package is made publicly available on GitHub at \https://github.com/SMARTlab-Purdue/ros2-foxy-wearable-biosensors.
Regression Trees on Grassmann Manifold for Adapting Reduced-Order Models
Jun 22, 2022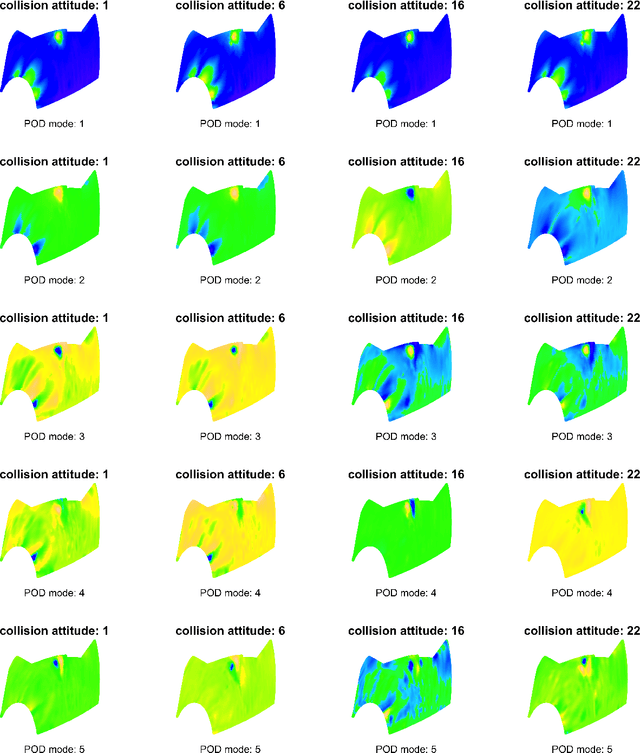
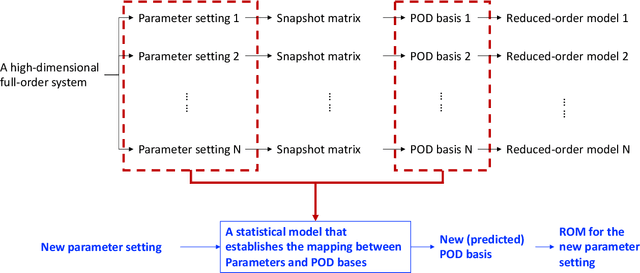
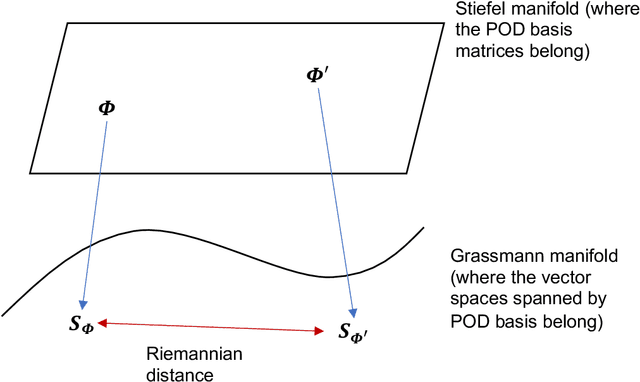
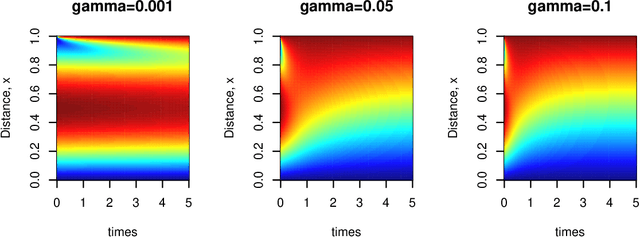
Low dimensional and computationally less expensive Reduced-Order Models (ROMs) have been widely used to capture the dominant behaviors of high-dimensional systems. A ROM can be obtained, using the well-known Proper Orthogonal Decomposition (POD), by projecting the full-order model to a subspace spanned by modal basis modes which are learned from experimental, simulated or observational data, i.e., training data. However, the optimal basis can change with the parameter settings. When a ROM, constructed using the POD basis obtained from training data, is applied to new parameter settings, the model often lacks robustness against the change of parameters in design, control, and other real-time operation problems. This paper proposes to use regression trees on Grassmann Manifold to learn the mapping between parameters and POD bases that span the low-dimensional subspaces onto which full-order models are projected. Motivated by the fact that a subspace spanned by a POD basis can be viewed as a point in the Grassmann manifold, we propose to grow a tree by repeatedly splitting the tree node to maximize the Riemannian distance between the two subspaces spanned by the predicted POD bases on the left and right daughter nodes. Five numerical examples are presented to comprehensively demonstrate the performance of the proposed method, and compare the proposed tree-based method to the existing interpolation method for POD basis and the use of global POD basis. The results show that the proposed tree-based method is capable of establishing the mapping between parameters and POD bases, and thus adapt ROMs for new parameters.
On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-smoothness and Beyond
Jun 10, 2022
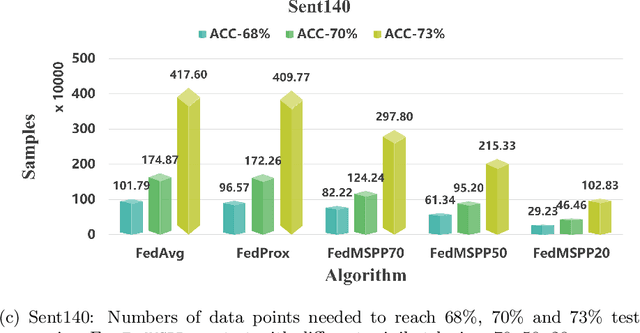
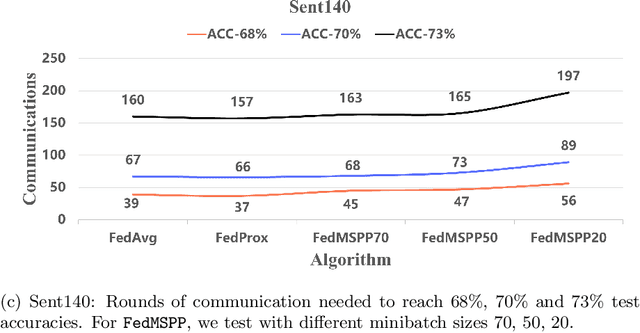
The FedProx algorithm is a simple yet powerful distributed proximal point optimization method widely used for federated learning (FL) over heterogeneous data. Despite its popularity and remarkable success witnessed in practice, the theoretical understanding of FedProx is largely underinvestigated: the appealing convergence behavior of FedProx is so far characterized under certain non-standard and unrealistic dissimilarity assumptions of local functions, and the results are limited to smooth optimization problems. In order to remedy these deficiencies, we develop a novel local dissimilarity invariant convergence theory for FedProx and its minibatch stochastic extension through the lens of algorithmic stability. As a result, we contribute to derive several new and deeper insights into FedProx for non-convex federated optimization including: 1) convergence guarantees independent on local dissimilarity type conditions; 2) convergence guarantees for non-smooth FL problems; and 3) linear speedup with respect to size of minibatch and number of sampled devices. Our theory for the first time reveals that local dissimilarity and smoothness are not must-have for FedProx to get favorable complexity bounds. Preliminary experimental results on a series of benchmark FL datasets are reported to demonstrate the benefit of minibatching for improving the sample efficiency of FedProx.
Extensive Study of Multiple Deep Neural Networks for Complex Random Telegraph Signals
May 31, 2022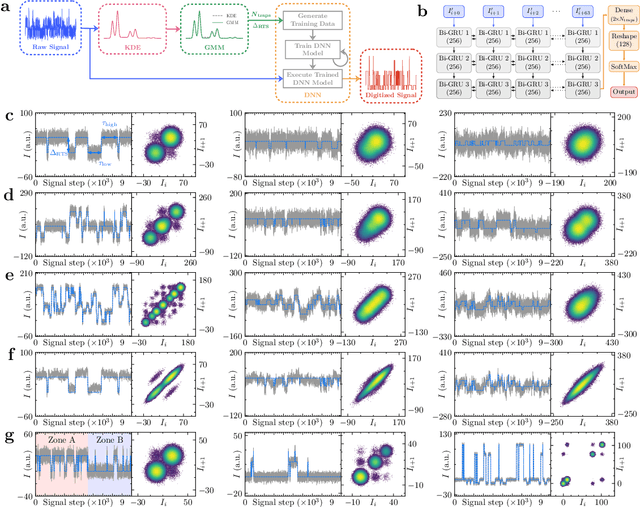
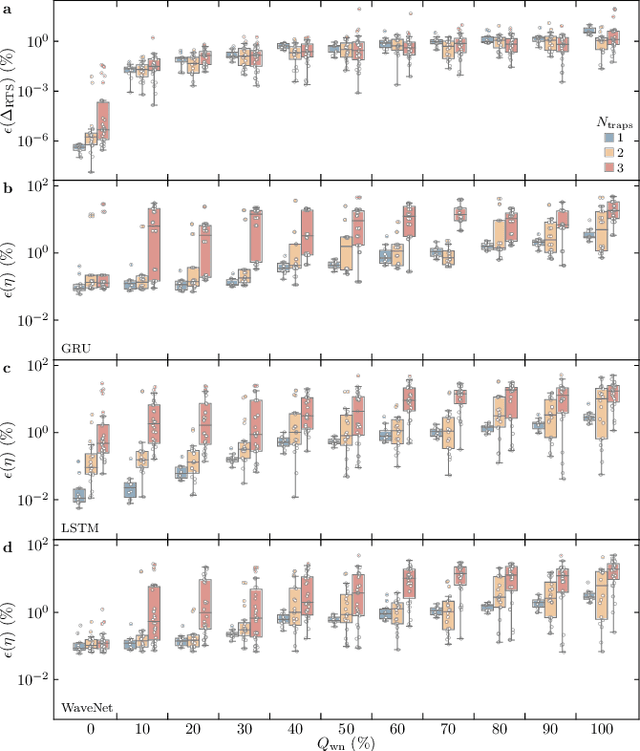
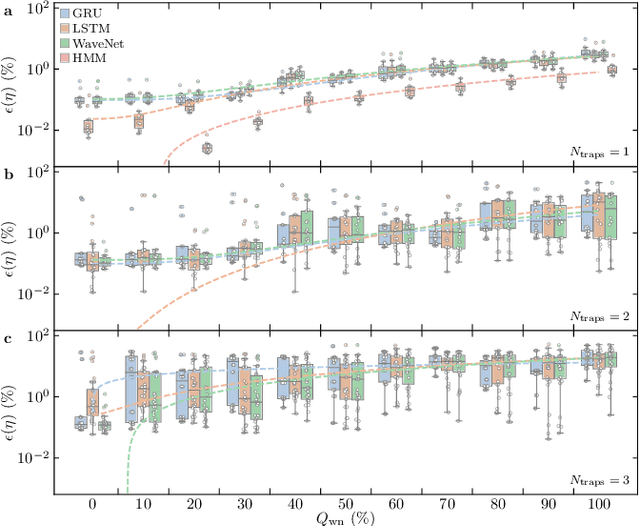
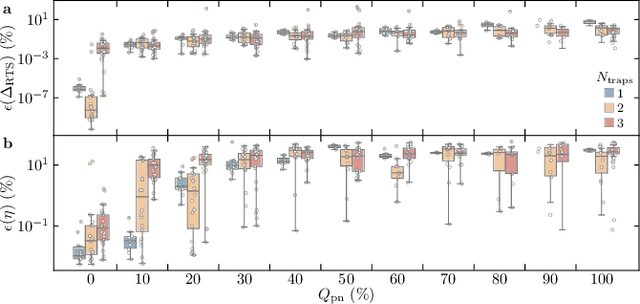
Time-fluctuating signals are ubiquitous and diverse in many physical, chemical, and biological systems, among which random telegraph signals (RTSs) refer to a series of instantaneous switching events between two discrete levels from single-particle movements. Reliable RTS analyses are crucial prerequisite to identify underlying mechanisms related to performance sensitivity. When numerous levels partake, complex patterns of multilevel RTSs occur, making their quantitative analysis exponentially difficult, hereby systematic approaches are found elusive. Here, we present a three-step analysis protocol via progressive knowledge-transfer, where the outputs of early step are passed onto a subsequent step. Especially, to quantify complex RTSs, we build three deep neural network architectures that can process temporal data well and demonstrate the model accuracy extensively with a large dataset of different RTS types affected by controlling background noise size. Our protocol offers structured schemes to quantify complex RTSs from which meaningful interpretation and inference can ensue.
FastMapSVM: Classifying Complex Objects Using the FastMap Algorithm and Support-Vector Machines
Apr 07, 2022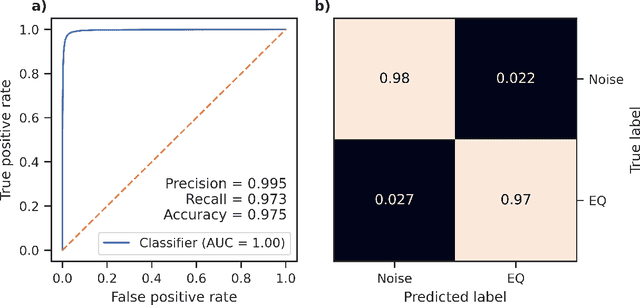

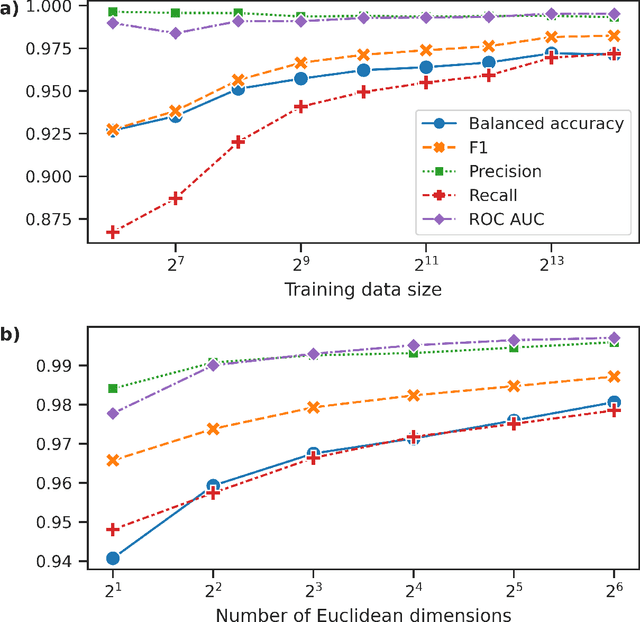
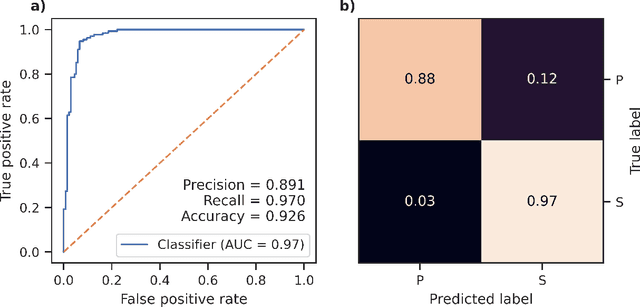
Neural Networks and related Deep Learning methods are currently at the leading edge of technologies used for classifying objects. However, they generally demand large amounts of time and data for model training; and their learned models can sometimes be difficult to interpret. In this paper, we present FastMapSVM, a novel interpretable Machine Learning framework for classifying complex objects. FastMapSVM combines the strengths of FastMap and Support-Vector Machines. FastMap is an efficient linear-time algorithm that maps complex objects to points in a Euclidean space, while preserving pairwise non-Euclidean distances between them. We demonstrate the efficiency and effectiveness of FastMapSVM in the context of classifying seismograms. We show that its performance, in terms of precision, recall, and accuracy, is comparable to that of other state-of-the-art methods. However, compared to other methods, FastMapSVM uses significantly smaller amounts of time and data for model training. It also provides a perspicuous visualization of the objects and the classification boundaries between them. We expect FastMapSVM to be viable for classification tasks in many other real-world domains.
Lightweight Conditional Model Extrapolation for Streaming Data under Class-Prior Shift
Jun 10, 2022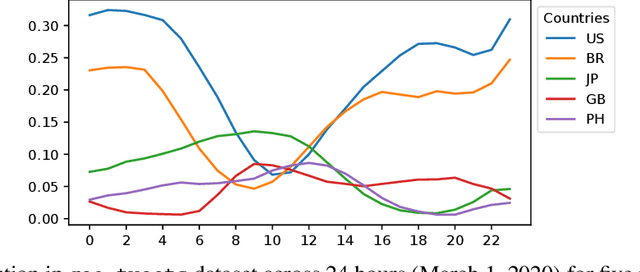
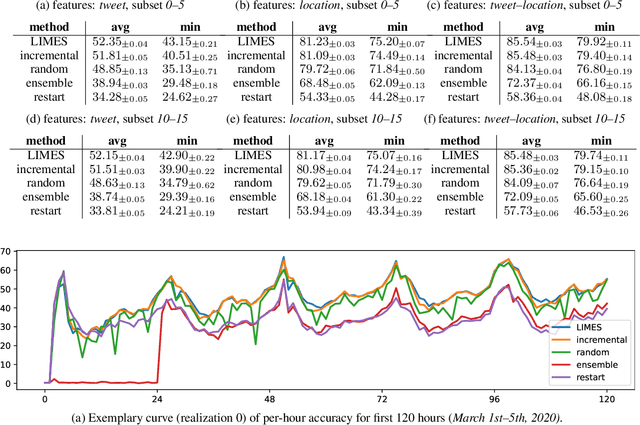
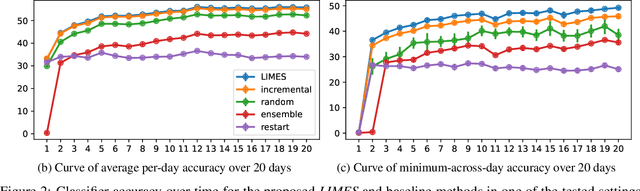
We introduce LIMES, a new method for learning with non-stationary streaming data, inspired by the recent success of meta-learning. The main idea is not to attempt to learn a single classifier that would have to work well across all occurring data distributions, nor many separate classifiers, but to exploit a hybrid strategy: we learn a single set of model parameters from which a specific classifier for any specific data distribution is derived via classifier adaptation. Assuming a multi-class classification setting with class-prior shift, the adaptation step can be performed analytically with only the classifier's bias terms being affected. Another contribution of our work is an extrapolation step that predicts suitable adaptation parameters for future time steps based on the previous data. In combination, we obtain a lightweight procedure for learning from streaming data with varying class distribution that adds no trainable parameters and almost no memory or computational overhead compared to training a single model. Experiments on a set of exemplary tasks using Twitter data show that LIMES achieves higher accuracy than alternative approaches, especially with respect to the relevant real-world metric of lowest within-day accuracy.
Supervised learning and tree search for real-time storage allocation in Robotic Mobile Fulfillment Systems
May 31, 2021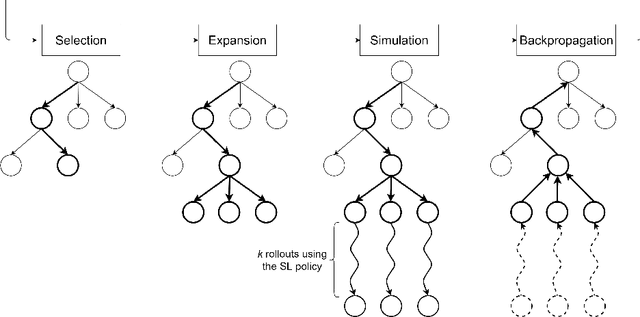
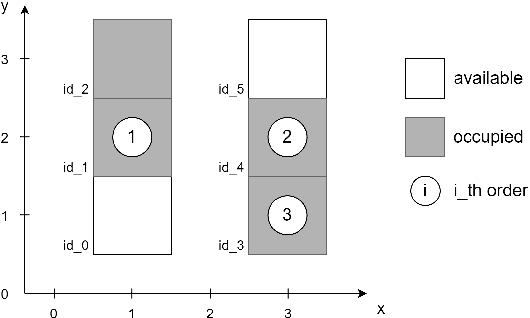
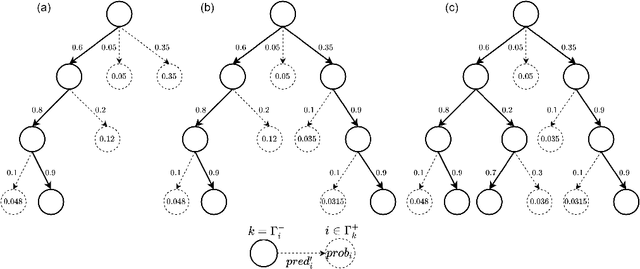
A Robotic Mobile Fulfillment System is a robotised parts-to-picker system that is particularly well-suited for e-commerce warehousing. One distinguishing feature of this type of warehouse is its high storage modularity. Numerous robots are moving shelves simultaneously, and the shelves can be returned to any open location after the picking operation is completed. This work focuses on the real-time storage allocation problem to minimise the travel time of the robots. An efficient -- but computationally costly -- Monte Carlo Tree Search method is used offline to generate high-quality experience. This experience can be learned by a neural network with a proper coordinates-based features representation. The obtained neural network is used as an action predictor in several new storage policies, either as-is or in rollout and supervised tree search strategies. Resulting performance levels depend on the computing time available at a decision step and are consistently better compared to real-time decision rules from the literature.