 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Interacting Dynamical Systems with Latent Gaussian Process ODEs
May 24, 2022

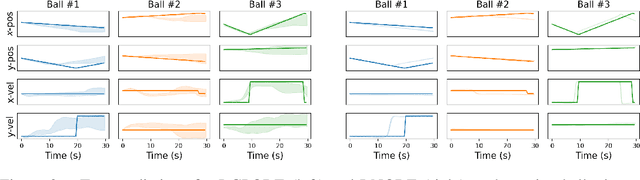
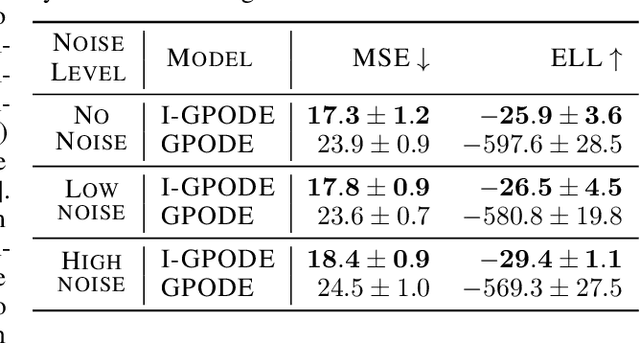
We study for the first time uncertainty-aware modeling of continuous-time dynamics of interacting objects. We introduce a new model that decomposes independent dynamics of single objects accurately from their interactions. By employing latent Gaussian process ordinary differential equations, our model infers both independent dynamics and their interactions with reliable uncertainty estimates. In our formulation, each object is represented as a graph node and interactions are modeled by accumulating the messages coming from neighboring objects. We show that efficient inference of such a complex network of variables is possible with modern variational sparse Gaussian process inference techniques. We empirically demonstrate that our model improves the reliability of long-term predictions over neural network based alternatives and it successfully handles missing dynamic or static information. Furthermore, we observe that only our model can successfully encapsulate independent dynamics and interaction information in distinct functions and show the benefit from this disentanglement in extrapolation scenarios.
Audio Similarity is Unreliable as a Proxy for Audio Quality
Jun 27, 2022
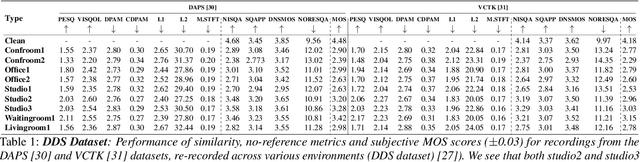

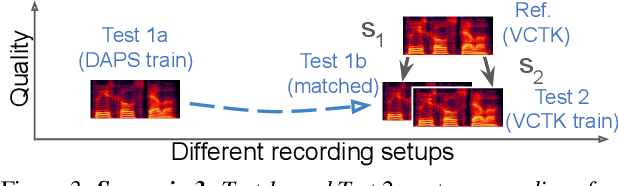
Many audio processing tasks require perceptual assessment. However, the time and expense of obtaining ``gold standard'' human judgments limit the availability of such data. Most applications incorporate full reference or other similarity-based metrics (e.g. PESQ) that depend on a clean reference. Researchers have relied on such metrics to evaluate and compare various proposed methods, often concluding that small, measured differences imply one is more effective than another. This paper demonstrates several practical scenarios where similarity metrics fail to agree with human perception, because they: (1) vary with clean references; (2) rely on attributes that humans factor out when considering quality, and (3) are sensitive to imperceptible signal level differences. In those scenarios, we show that no-reference metrics do not suffer from such shortcomings and correlate better with human perception. We conclude therefore that similarity serves as an unreliable proxy for audio quality.
A Proof of the Tree of Shapes in n-D
Jun 10, 2022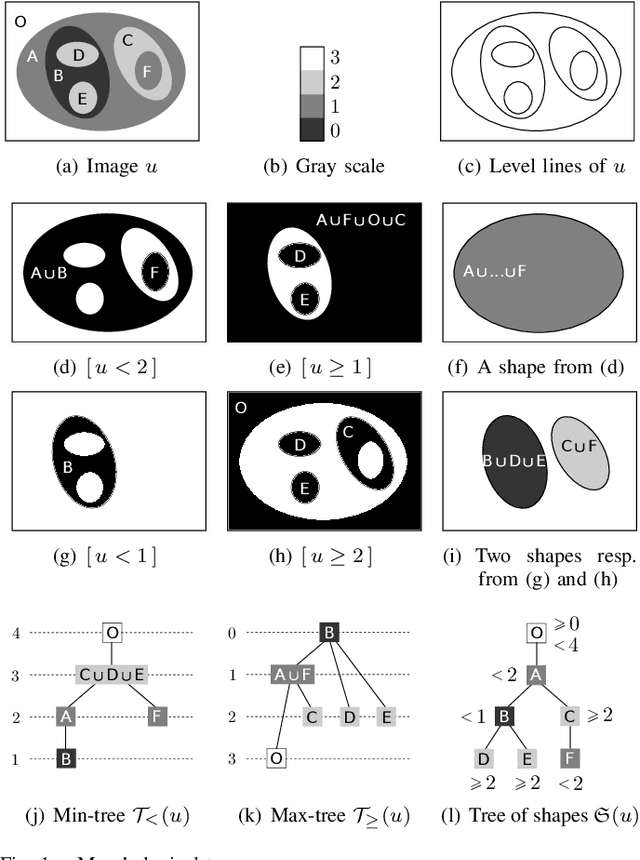
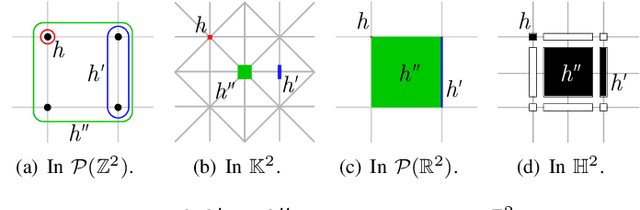
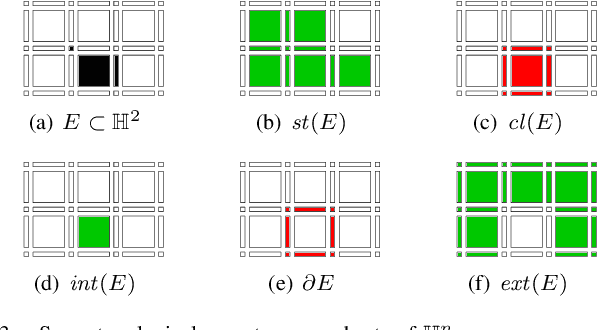
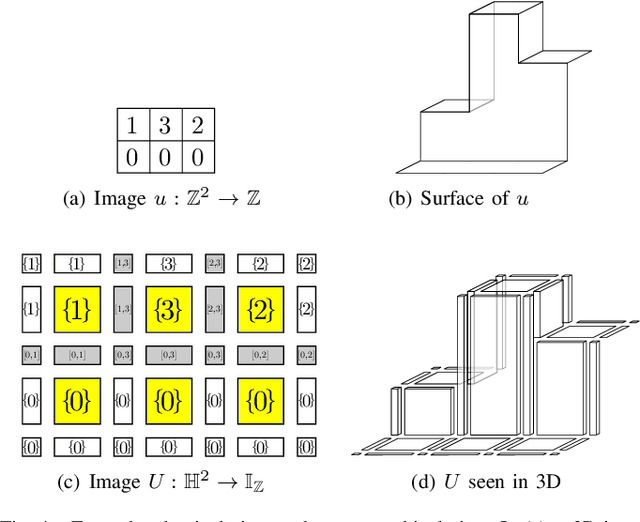
In this paper, we prove that the self-dual morphological hierarchical structure computed on a n-D gray-level wellcomposed image u by the algorithm of G{\'e}raud et al. [1] is exactly the mathematical structure defined to be the tree of shape of u in Najman et al [2]. We recall that this algorithm is in quasi-linear time and thus considered to be optimal. The tree of shapes leads to many applications in mathematical morphology and in image processing like grain filtering, shapings, image segmentation, and so on.
GPU-Accelerated Machine Learning in Non-Orthogonal Multiple Access
Jun 13, 2022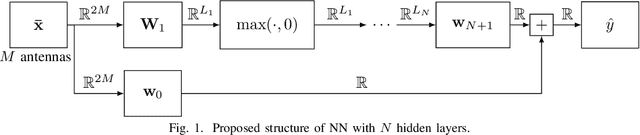

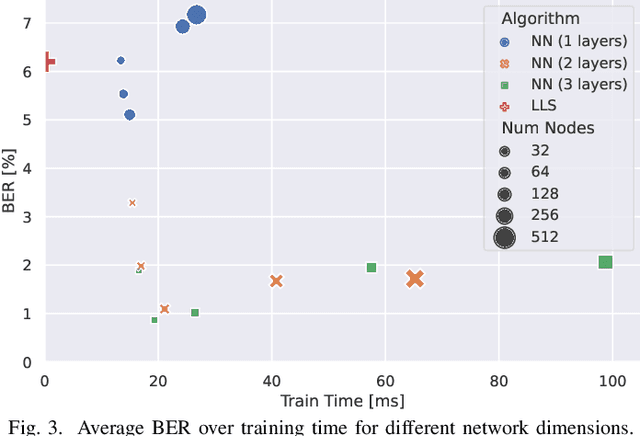
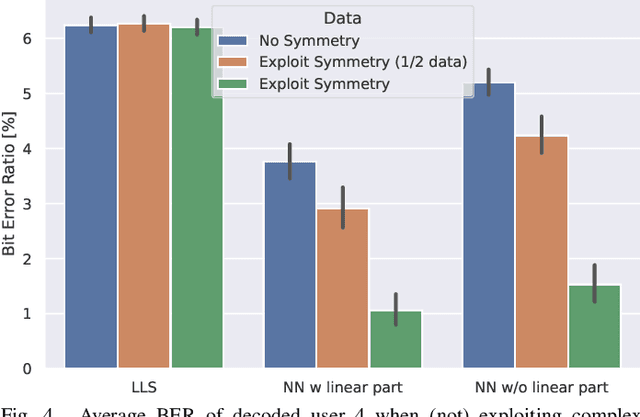
Non-orthogonal multiple access (NOMA) is an interesting technology that enables massive connectivity as required in future 5G and 6G networks. While purely linear processing already achieves good performance in NOMA systems, in certain scenarios, non-linear processing is mandatory to ensure acceptable performance. In this paper, we propose a neural network architecture that combines the advantages of both linear and non-linear processing. Its real-time detection performance is demonstrated by a highly efficient implementation on a graphics processing unit (GPU). Using real measurements in a laboratory environment, we show the superiority of our approach over conventional methods.
Microsimulation of Space Time Trellis Code
Feb 25, 2021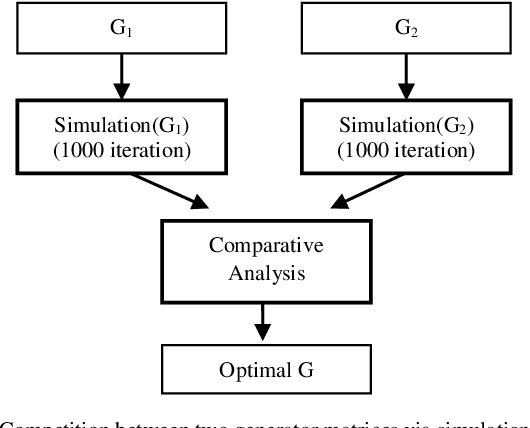

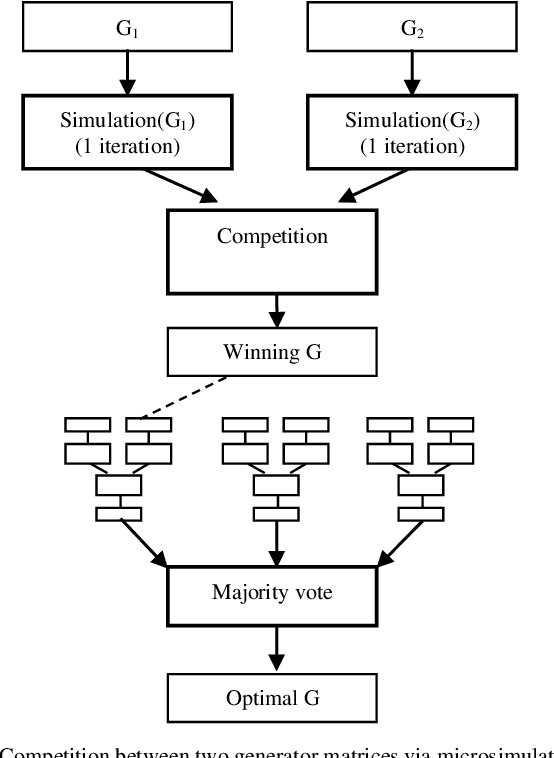

This letter explores the possibility of using microsimulation in space time trellis code. Performing a pairwise comparison between generator matrices is essential in the validation of optimality. This is often done with simulation, which can be a time consuming process altogether. Microsimulation considerably cuts down the computational cost of simulation by employing smaller data and iteration. The effort is feasible with the assistance of a machine learning model known as multilayer perceptron. When properly conducted, it can offer 93.86% accuracy and 98.25% reduction in temporal cost.
Supernova Light Curves Approximation based on Neural Network Models
Jun 27, 2022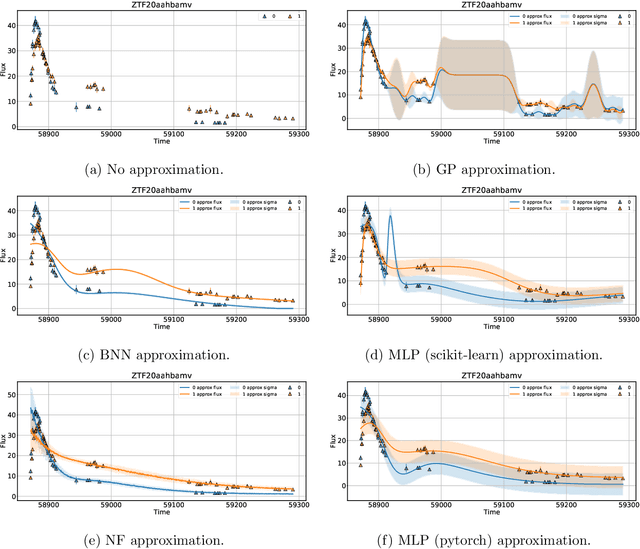
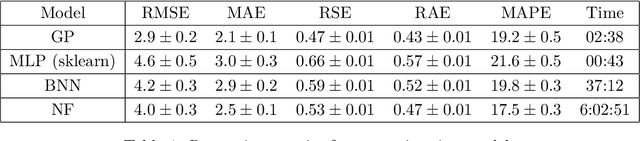

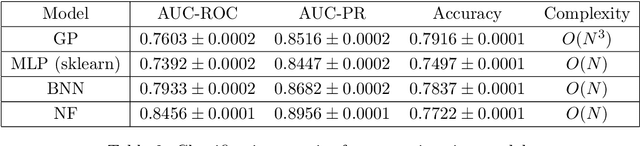
Photometric data-driven classification of supernovae becomes a challenge due to the appearance of real-time processing of big data in astronomy. Recent studies have demonstrated the superior quality of solutions based on various machine learning models. These models learn to classify supernova types using their light curves as inputs. Preprocessing these curves is a crucial step that significantly affects the final quality. In this talk, we study the application of multilayer perceptron (MLP), bayesian neural network (BNN), and normalizing flows (NF) to approximate observations for a single light curve. We use these approximations as inputs for supernovae classification models and demonstrate that the proposed methods outperform the state-of-the-art based on Gaussian processes applying to the Zwicky Transient Facility Bright Transient Survey light curves. MLP demonstrates similar quality as Gaussian processes and speed increase. Normalizing Flows exceeds Gaussian processes in terms of approximation quality as well.
PD/EUP Workshop Proceedings
Jul 15, 2022People who need robots are often not the same as people who can program them. This key observation in human-robot interaction (HRI) has lead to a number of challenges when developing robotic applications, since developers must understand the exact needs of end-users. Participatory Design (PD), the process of including stakeholders such as end users early in the robot design process, has been used with noteworthy success in HRI, but typically remains limited to the early phases of development. Resulting robot behaviors are often then hardcoded by engineers or utilized in Wizard-of-Oz (WoZ) systems that rarely achieve autonomy. End-User Programming (EUP), i.e., the research of tools allowing end users with limited computer knowledge to program systems, has been widely applied to the design of robot behaviors for interaction with humans, but these tools risk being used solely as research demonstrations only existing for the amount of time required for them to be evaluated and published. In the PD/EUP Workshop, we aim to facilitate mutual learning between these communities and to create communication opportunities that could help the larger HRI community work towards end-user personalized and adaptable interactions. Both PD and EUP will be key requirements if we want robots to be useful for wider society. From this workshop, we expect new collaboration opportunities to emerge and we aim to formalize new methodologies that integrate PD and EUP approaches.
3DVerifier: Efficient Robustness Verification for 3D Point Cloud Models
Jul 15, 2022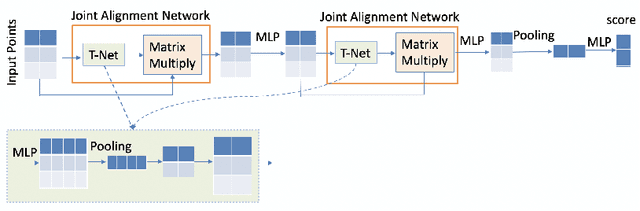
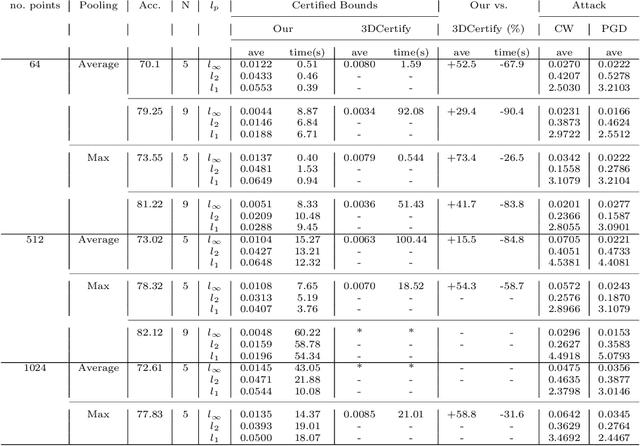

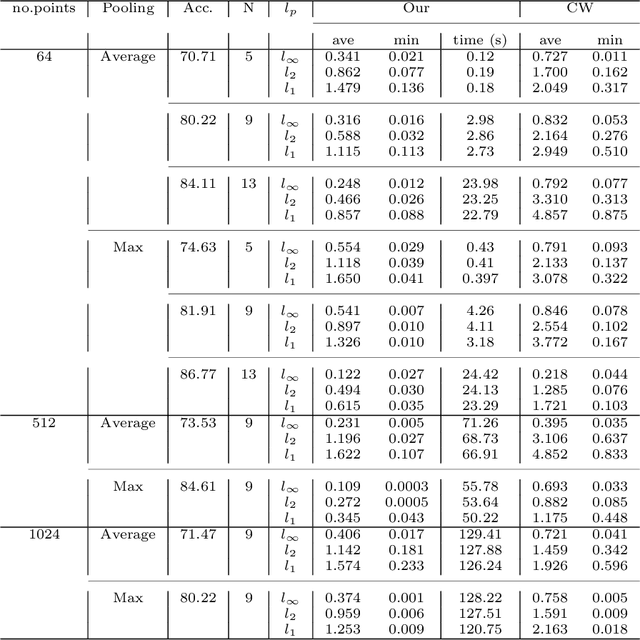
3D point cloud models are widely applied in safety-critical scenes, which delivers an urgent need to obtain more solid proofs to verify the robustness of models. Existing verification method for point cloud model is time-expensive and computationally unattainable on large networks. Additionally, they cannot handle the complete PointNet model with joint alignment network (JANet) that contains multiplication layers, which effectively boosts the performance of 3D models. This motivates us to design a more efficient and general framework to verify various architectures of point cloud models. The key challenges in verifying the large-scale complete PointNet models are addressed as dealing with the cross-non-linearity operations in the multiplication layers and the high computational complexity of high-dimensional point cloud inputs and added layers. Thus, we propose an efficient verification framework, 3DVerifier, to tackle both challenges by adopting a linear relaxation function to bound the multiplication layer and combining forward and backward propagation to compute the certified bounds of the outputs of the point cloud models. Our comprehensive experiments demonstrate that 3DVerifier outperforms existing verification algorithms for 3D models in terms of both efficiency and accuracy. Notably, our approach achieves an orders-of-magnitude improvement in verification efficiency for the large network, and the obtained certified bounds are also significantly tighter than the state-of-the-art verifiers. We release our tool 3DVerifier via https://github.com/TrustAI/3DVerifier for use by the community.
Fast Object Placement Assessment
May 28, 2022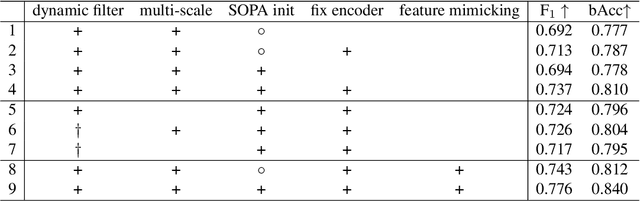
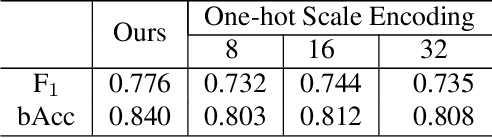
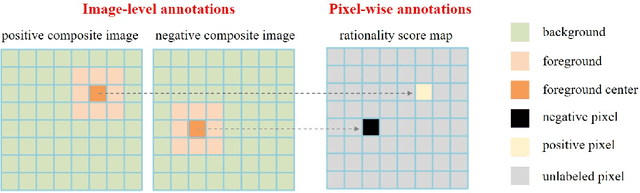

Object placement assessment (OPA) aims to predict the rationality score of a composite image in terms of the placement (e.g., scale, location) of inserted foreground object. However, given a pair of scaled foreground and background, to enumerate all the reasonable locations, existing OPA model needs to place the foreground at each location on the background and pass the obtained composite image through the model one at a time, which is very time-consuming. In this work, we investigate a new task named as fast OPA. Specifically, provided with a scaled foreground and a background, we only pass them through the model once and predict the rationality scores for all locations. To accomplish this task, we propose a pioneering fast OPA model with several innovations (i.e., foreground dynamic filter, background prior transfer, and composite feature mimicking) to bridge the performance gap between slow OPA model and fast OPA model. Extensive experiments on OPA dataset show that our proposed fast OPA model performs on par with slow OPA model but runs significantly faster.
DDKtor: Automatic Diadochokinetic Speech Analysis
Jun 29, 2022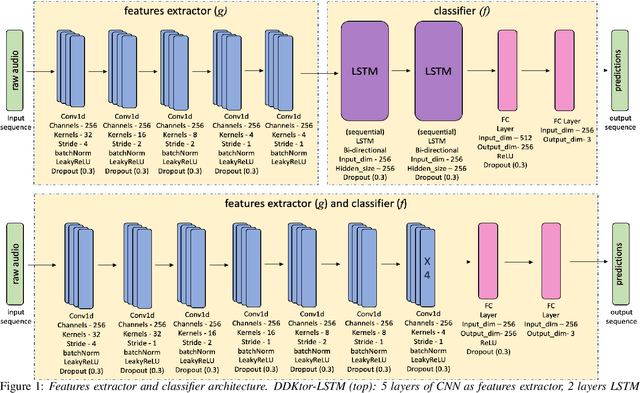
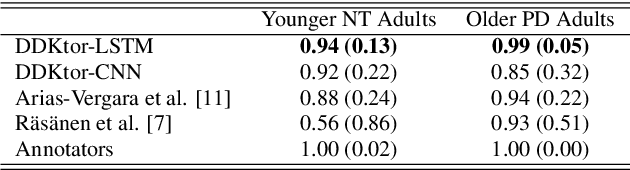
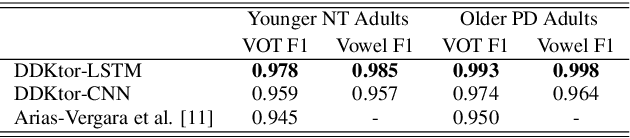
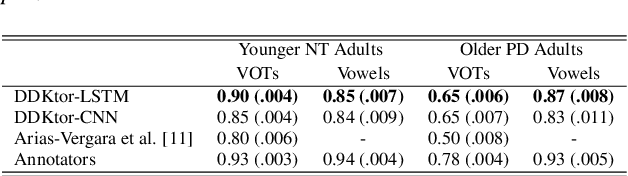
Diadochokinetic speech tasks (DDK), in which participants repeatedly produce syllables, are commonly used as part of the assessment of speech motor impairments. These studies rely on manual analyses that are time-intensive, subjective, and provide only a coarse-grained picture of speech. This paper presents two deep neural network models that automatically segment consonants and vowels from unannotated, untranscribed speech. Both models work on the raw waveform and use convolutional layers for feature extraction. The first model is based on an LSTM classifier followed by fully connected layers, while the second model adds more convolutional layers followed by fully connected layers. These segmentations predicted by the models are used to obtain measures of speech rate and sound duration. Results on a young healthy individuals dataset show that our LSTM model outperforms the current state-of-the-art systems and performs comparably to trained human annotators. Moreover, the LSTM model also presents comparable results to trained human annotators when evaluated on unseen older individuals with Parkinson's Disease dataset.