 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End License Plate Recognition Pipeline for Real-time Low Resource Video Based Applications
Aug 18, 2021


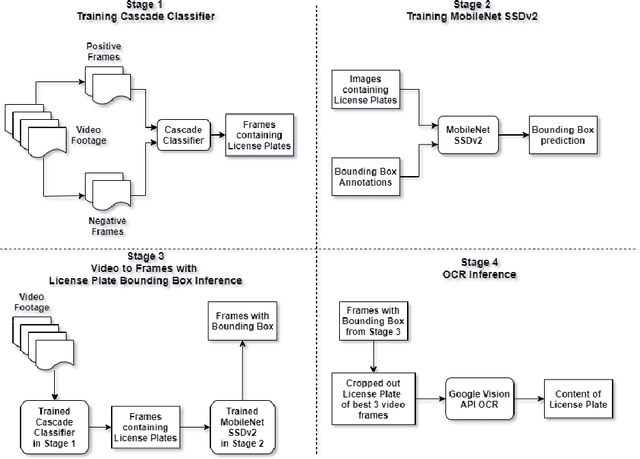
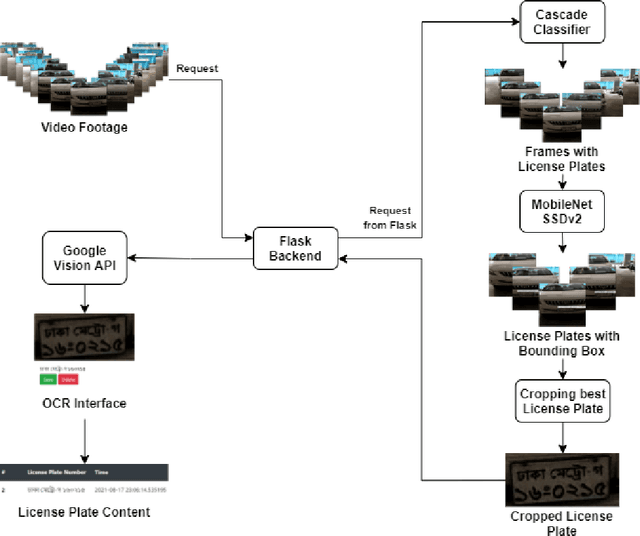
Automatic License Plate Recognition systems aim to provide an end-to-end solution towards detecting, localizing, and recognizing license plate characters from vehicles appearing in video frames. However, deploying such systems in the real world requires real-time performance in low-resource environments. In our paper, we propose a novel two-stage detection pipeline paired with Vision API that aims to provide real-time inference speed along with consistently accurate detection and recognition performance. We used a haar-cascade classifier as a filter on top of our backbone MobileNet SSDv2 detection model. This reduces inference time by only focusing on high confidence detections and using them for recognition. We also impose a temporal frame separation strategy to identify multiple vehicle license plates in the same clip. Furthermore, there are no publicly available Bangla license plate datasets, for which we created an image dataset and a video dataset containing license plates in the wild. We trained our models on the image dataset and achieved an AP(0.5) score of 86% and tested our pipeline on the video dataset and observed reasonable detection and recognition performance (82.7% detection rate, and 60.8% OCR F1 score) with real-time processing speed (27.2 frames per second).
A Parallel Novelty Search Metaheuristic Applied to a Wildfire Prediction System
Jul 24, 2022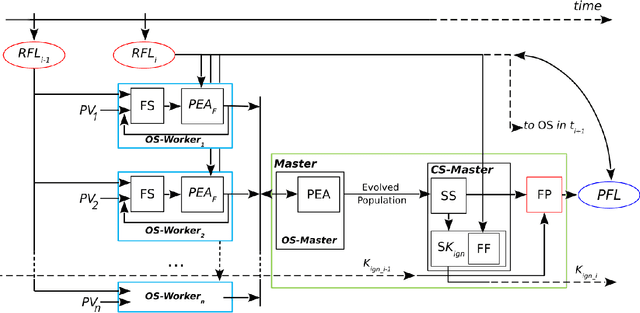
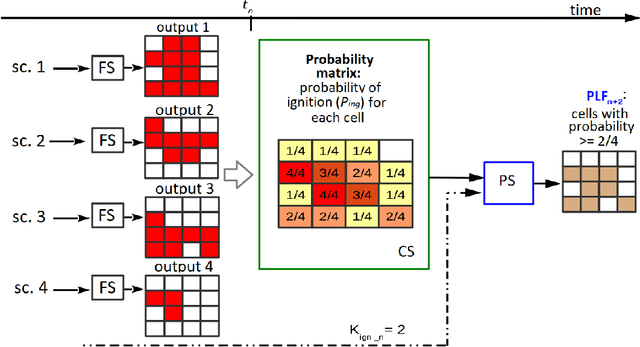
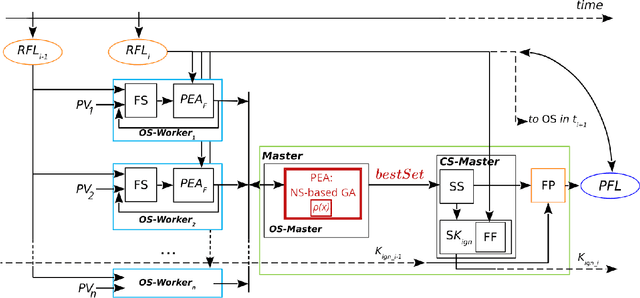
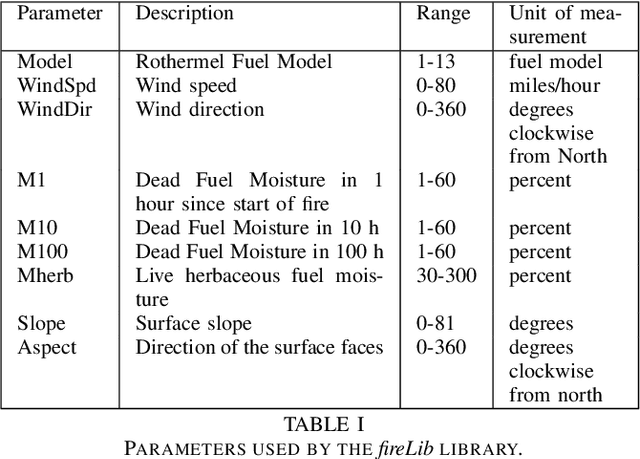
Wildfires are a highly prevalent multi-causal environmental phenomenon. The impact of this phenomenon includes human losses, environmental damage and high economic costs. To mitigate these effects, several computer simulation systems have been developed in order to predict fire behavior based on a set of input parameters, also called a scenario (wind speed and direction; temperature; etc.). However, the results of a simulation usually have a high degree of error due to the uncertainty in the values of some variables, because they are not known, or because their measurement may be imprecise, erroneous, or impossible to perform in real time. Previous works have proposed the combination of multiple results in order to reduce this uncertainty. State-of-the-art methods are based on parallel optimization strategies that use a fitness function to guide the search among all possible scenarios. Although these methods have shown improvements in the quality of predictions, they have some limitations related to the algorithms used for the selection of scenarios. To overcome these limitations, in this work we propose to apply the Novelty Search paradigm, which replaces the objective function by a measure of the novelty of the solutions found, which allows the search to continuously generate solutions with behaviors that differ from one another. This approach avoids local optima and may be able to find useful solutions that would be difficult or impossible to find by other algorithms. As with existing methods, this proposal may also be adapted to other propagation models (floods, avalanches or landslides).
Sparse Ellipsometry: Portable Acquisition of Polarimetric SVBRDF and Shape with Unstructured Flash Photography
Jul 09, 2022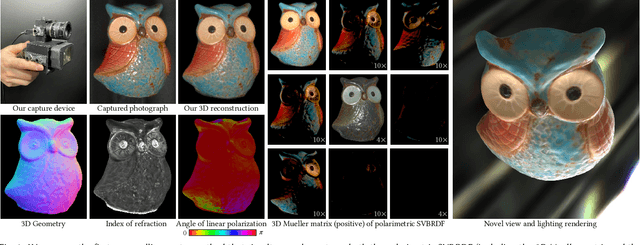
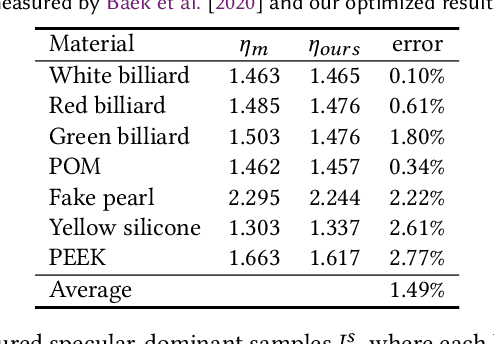
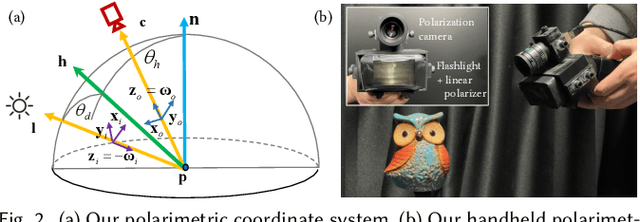
Ellipsometry techniques allow to measure polarization information of materials, requiring precise rotations of optical components with different configurations of lights and sensors. This results in cumbersome capture devices, carefully calibrated in lab conditions, and in very long acquisition times, usually in the order of a few days per object. Recent techniques allow to capture polarimetric spatially-varying reflectance information, but limited to a single view, or to cover all view directions, but limited to spherical objects made of a single homogeneous material. We present sparse ellipsometry, a portable polarimetric acquisition method that captures both polarimetric SVBRDF and 3D shape simultaneously. Our handheld device consists of off-the-shelf, fixed optical components. Instead of days, the total acquisition time varies between twenty and thirty minutes per object. We develop a complete polarimetric SVBRDF model that includes diffuse and specular components, as well as single scattering, and devise a novel polarimetric inverse rendering algorithm with data augmentation of specular reflection samples via generative modeling. Our results show a strong agreement with a recent ground-truth dataset of captured polarimetric BRDFs of real-world objects.
Varying Joint Patterns and Compensatory Strategies Can Lead to the Same Functional Gait Outcomes: A Case Study
Jun 27, 2022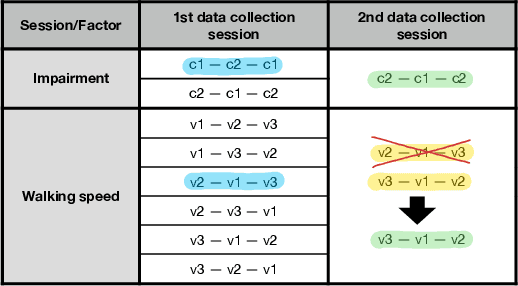
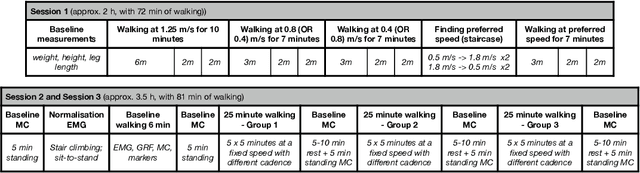
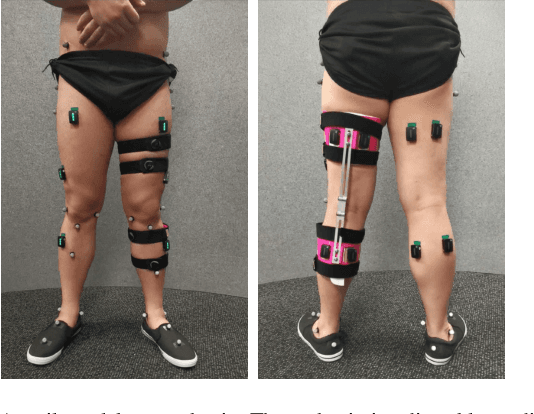
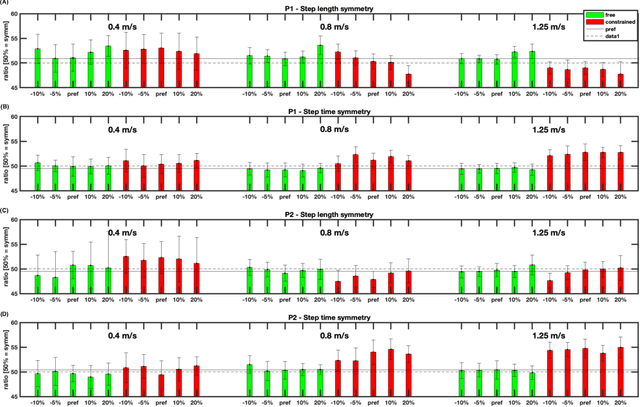
This paper analyses joint-space walking mechanisms and redundancies in delivering functional gait outcomes. Multiple biomechanical measures are analysed for two healthy male adults who participated in a multi-factorial study and walked during three sessions. Both participants employed varying intra- and inter-personal compensatory strategies (e.g., vaulting, hip hiking) across walking conditions and exhibited notable gait pattern alterations while keeping task-space (functional) gait parameters invariant. They also preferred various levels of asymmetric step length but kept their symmetric step time consistent and cadence-invariant during free walking. The results demonstrate the importance of an individualised approach and the need for a paradigm shift from functional (task-space) to joint-space gait analysis in attending to (a)typical gaits and delivering human-centred human-robot interaction.
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
Nov 19, 2021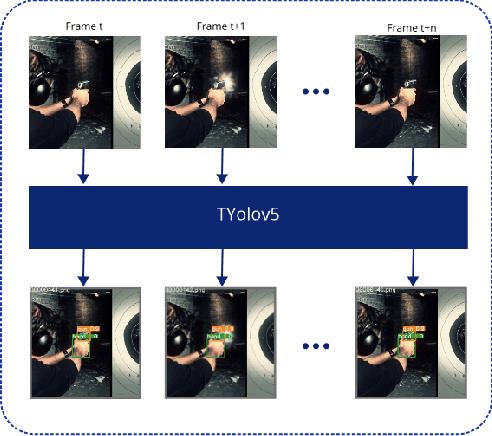
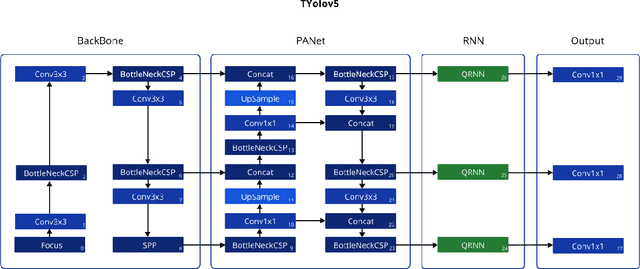
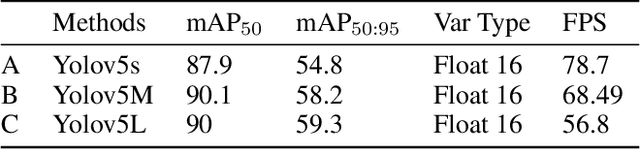
Timely handgun detection is a crucial problem to improve public safety; nevertheless, the effectiveness of many surveillance systems still depends of finite human attention. Much of the previous research on handgun detection is based on static image detectors, leaving aside valuable temporal information that could be used to improve object detection in videos. To improve the performance of surveillance systems, a real-time temporal handgun detection system should be built. Using Temporal Yolov5, an architecture based on Quasi-Recurrent Neural Networks, temporal information is extracted from video to improve the results of handgun detection. Moreover, two publicly available datasets are proposed, labeled with hands, guns, and phones. One containing 2199 static images to train static detectors, and another with 5960 frames of videos to train temporal modules. Additionally, we explore two temporal data augmentation techniques based on Mosaic and Mixup. The resulting systems are three temporal architectures: one focused in reducing inference with a mAP$_{50:95}$ of 55.9, another in having a good balance between inference and accuracy with a mAP$_{50:95}$ of 59, and a last one specialized in accuracy with a mAP$_{50:95}$ of 60.2. Temporal Yolov5 achieves real-time detection in the small and medium architectures. Moreover, it takes advantage of temporal features contained in videos to perform better than Yolov5 in our temporal dataset, making TYolov5 suitable for real-world applications. The source code is publicly available at https://github.com/MarioDuran/TYolov5.
Simultaneous Contact-Rich Grasping and Locomotion via Distributed Optimization Enabling Free-Climbing for Multi-Limbed Robots
Jul 05, 2022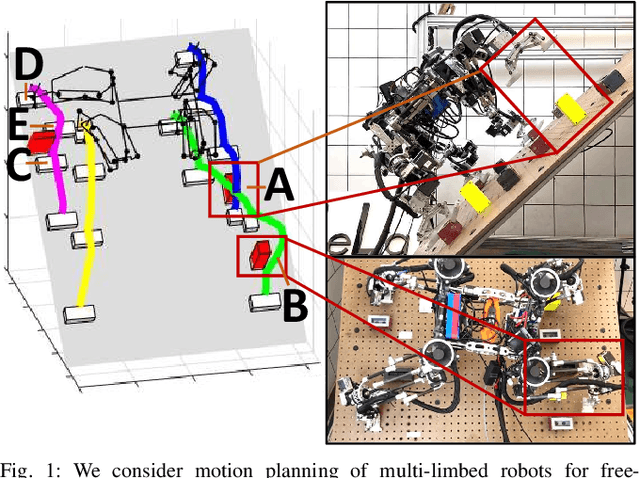
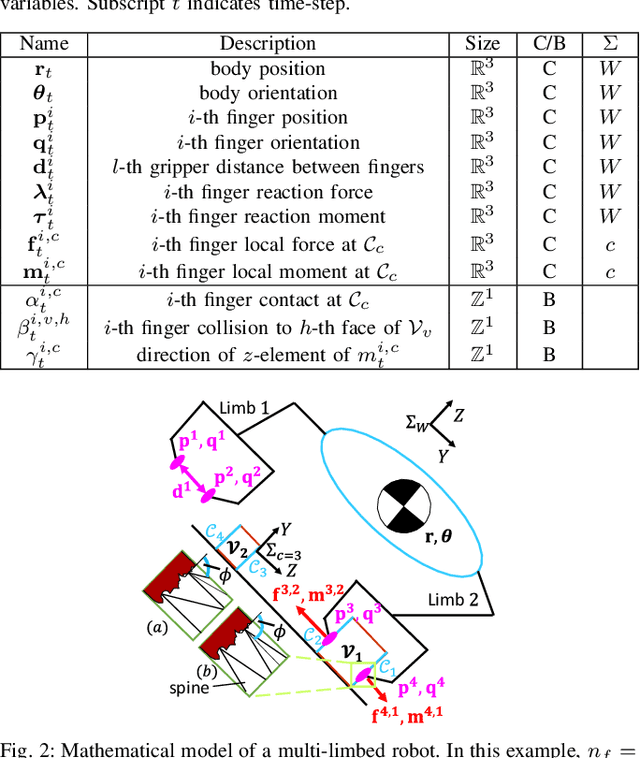
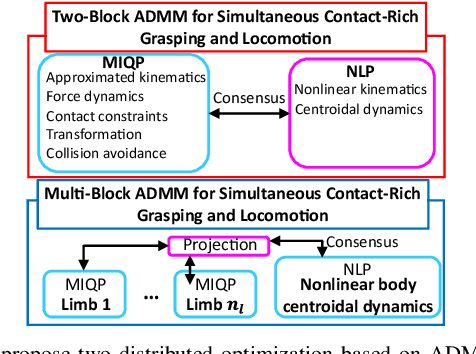
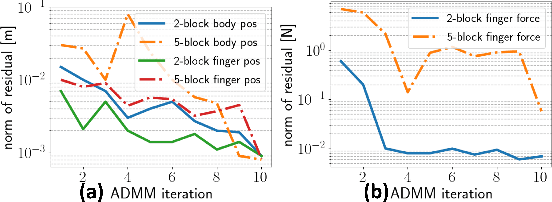
While motion planning of locomotion for legged robots has shown great success, motion planning for legged robots with dexterous multi-finger grasping is not mature yet. We present an efficient motion planning framework for simultaneously solving locomotion (e.g., centroidal dynamics), grasping (e.g., patch contact), and contact (e.g., gait) problems. To accelerate the planning process, we propose distributed optimization frameworks based on Alternating Direction Methods of Multipliers (ADMM) to solve the original large-scale Mixed-Integer NonLinear Programming (MINLP). The resulting frameworks use Mixed-Integer Quadratic Programming (MIQP) to solve contact and NonLinear Programming (NLP) to solve nonlinear dynamics, which are more computationally tractable and less sensitive to parameters. Also, we explicitly enforce patch contact constraints from limit surfaces with micro-spine grippers. We demonstrate our proposed framework in the hardware experiments, showing that the multi-limbed robot is able to realize various motions including free-climbing at a slope angle 45{\deg} with a much shorter planning time.
SCAI: A Spectral data Classification framework with Adaptive Inference for the IoT platform
Jun 24, 2022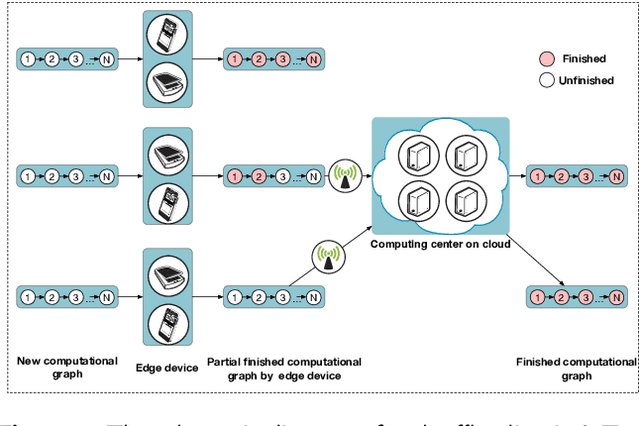

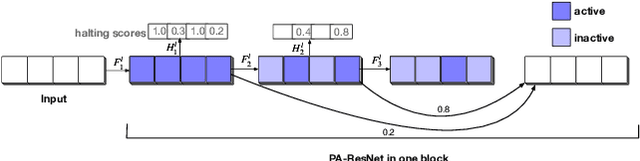
Currently, it is a hot research topic to realize accurate, efficient, and real-time identification of massive spectral data with the help of deep learning and IoT technology. Deep neural networks played a key role in spectral analysis. However, the inference of deeper models is performed in a static manner, and cannot be adjusted according to the device. Not all samples need to allocate all computation to reach confident prediction, which hinders maximizing the overall performance. To address the above issues, we propose a Spectral data Classification framework with Adaptive Inference. Specifically, to allocate different computations for different samples while better exploiting the collaboration among different devices, we leverage Early-exit architecture, place intermediate classifiers at different depths of the architecture, and the model outputs the results when the prediction confidence reaches a preset threshold. We propose a training paradigm of self-distillation learning, the deepest classifier performs soft supervision on the shallow ones to maximize their performance and training speed. At the same time, to mitigate the vulnerability of performance to the location and number settings of intermediate classifiers in the Early-exit paradigm, we propose a Position-Adaptive residual network. It can adjust the number of layers in each block at different curve positions, so it can focus on important positions of the curve (e.g.: Raman peak), and accurately allocate the appropriate computational budget based on task performance and computing resources. To the best of our knowledge, this paper is the first attempt to conduct optimization by adaptive inference for spectral detection under the IoT platform. We conducted many experiments, the experimental results show that our proposed method can achieve higher performance with less computational budget than existing methods.
Gated Transformer Networks for Multivariate Time Series Classification
Mar 26, 2021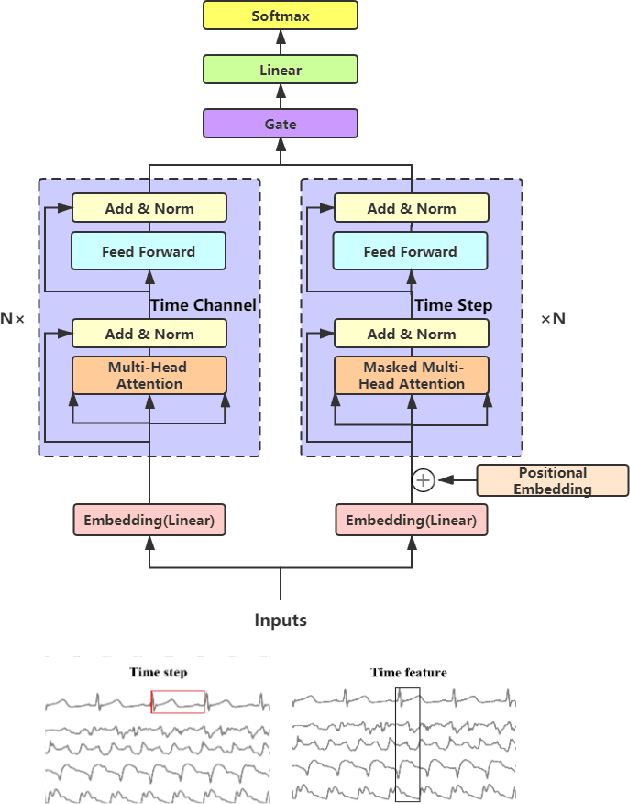
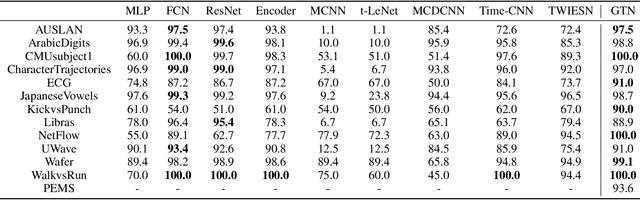
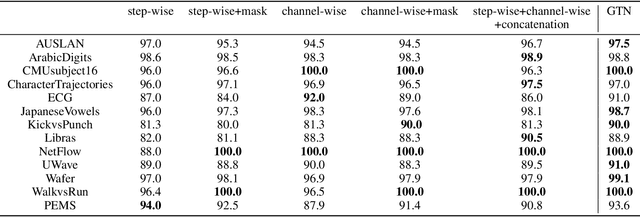
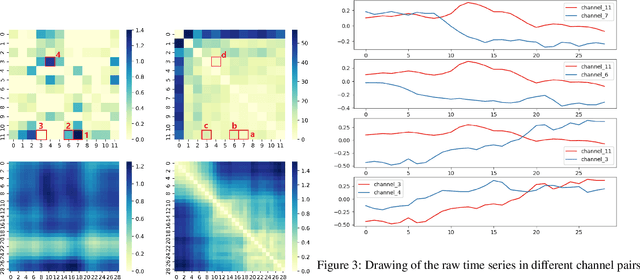
Deep learning model (primarily convolutional networks and LSTM) for time series classification has been studied broadly by the community with the wide applications in different domains like healthcare, finance, industrial engineering and IoT. Meanwhile, Transformer Networks recently achieved frontier performance on various natural language processing and computer vision tasks. In this work, we explored a simple extension of the current Transformer Networks with gating, named Gated Transformer Networks (GTN) for the multivariate time series classification problem. With the gating that merges two towers of Transformer which model the channel-wise and step-wise correlations respectively, we show how GTN is naturally and effectively suitable for the multivariate time series classification task. We conduct comprehensive experiments on thirteen dataset with full ablation study. Our results show that GTN is able to achieve competing results with current state-of-the-art deep learning models. We also explored the attention map for the natural interpretability of GTN on time series modeling. Our preliminary results provide a strong baseline for the Transformer Networks on multivariate time series classification task and grounds the foundation for future research.
On the Effects of Different Types of Label Noise in Multi-Label Remote Sensing Image Classification
Jul 28, 2022

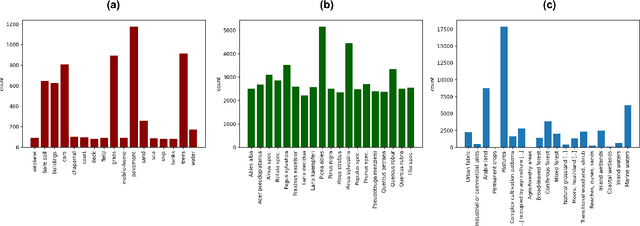

The development of accurate methods for multi-label classification (MLC) of remote sensing (RS) images is one of the most important research topics in RS. To address MLC problems, the use of deep neural networks that require a high number of reliable training images annotated by multiple land-cover class labels (multi-labels) have been found popular in RS. However, collecting such annotations is time-consuming and costly. A common procedure to obtain annotations at zero labeling cost is to rely on thematic products or crowdsourced labels. As a drawback, these procedures come with the risk of label noise that can distort the learning process of the MLC algorithms. In the literature, most label noise robust methods are designed for single label classification (SLC) problems in computer vision (CV), where each image is annotated by a single label. Unlike SLC, label noise in MLC can be associated with: 1) subtractive label-noise (a land cover class label is not assigned to an image while that class is present in the image); 2) additive label-noise (a land cover class label is assigned to an image although that class is not present in the given image); and 3) mixed label-noise (a combination of both). In this paper, we investigate three different noise robust CV SLC methods and adapt them to be robust for multi-label noise scenarios in RS. During experiments we study the effects of different types of multi-label noise and evaluate the adapted methods rigorously. To this end, we also introduce a synthetic multi-label noise injection strategy that is more adequate to simulate operational scenarios compared to the uniform label noise injection strategy, in which the labels of absent and present classes are flipped at uniform probability. Further, we study the relevance of different evaluation metrics in MLC problems under noisy multi-labels.
Mesh-based Dynamics with Occlusion Reasoning for Cloth Manipulation
Jun 06, 2022
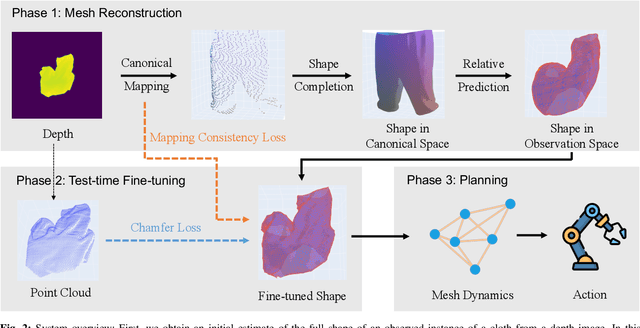
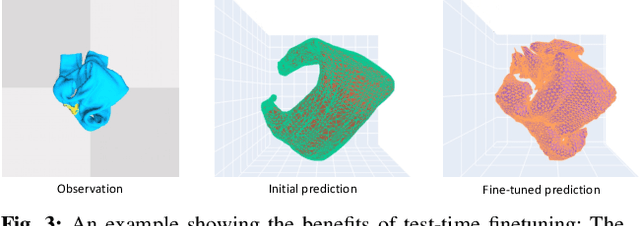

Self-occlusion is challenging for cloth manipulation, as it makes it difficult to estimate the full state of the cloth. Ideally, a robot trying to unfold a crumpled or folded cloth should be able to reason about the cloth's occluded regions. We leverage recent advances in pose estimation for cloth to build a system that uses explicit occlusion reasoning to unfold a crumpled cloth. Specifically, we first learn a model to reconstruct the mesh of the cloth. However, the model will likely have errors due to the complexities of the cloth configurations and due to ambiguities from occlusions. Our main insight is that we can further refine the predicted reconstruction by performing test-time finetuning with self-supervised losses. The obtained reconstructed mesh allows us to use a mesh-based dynamics model for planning while reasoning about occlusions. We evaluate our system both on cloth flattening as well as on cloth canonicalization, in which the objective is to manipulate the cloth into a canonical pose. Our experiments show that our method significantly outperforms prior methods that do not explicitly account for occlusions or perform test-time optimization.