 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Noise and dose reduction in CT brain perfusion acquisition by projecting time attenuation curves onto lower dimensional spaces
Nov 02, 2021
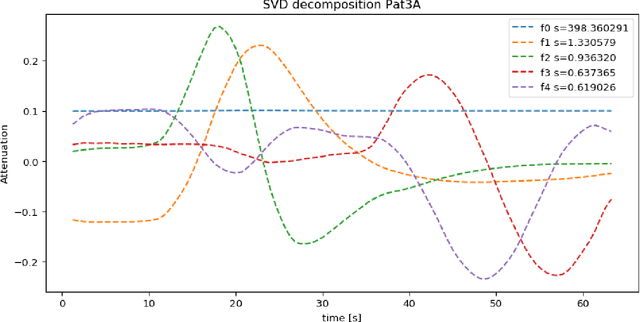
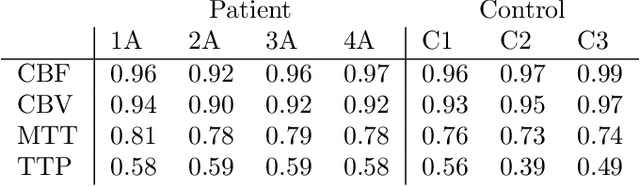
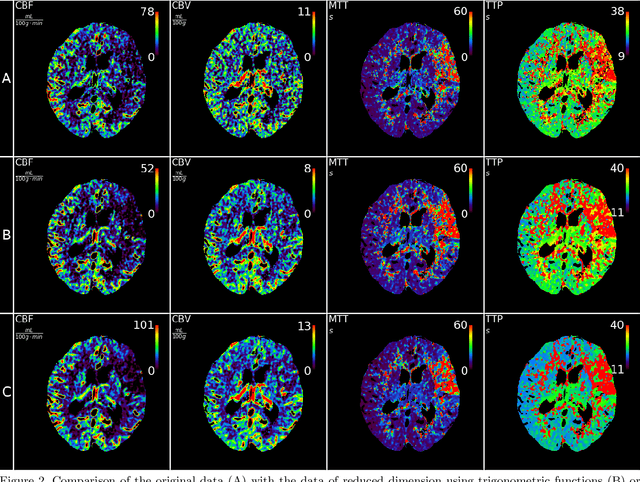

CT perfusion imaging (CTP) plays an important role in decision making for the treatment of acute ischemic stroke with large vessel occlusion. Since the CT perfusion scan time is approximately one minute, the patient is exposed to a non-negligible dose of ionizing radiation. However, further dose reduction increases the level of noise in the data and the resulting perfusion maps. We present a method for reducing noise in perfusion data based on dimension reduction of time attenuation curves. For dimension reduction, we use either the fit of the first five terms of the trigonometric polynomial or the first five terms of the SVD decomposition of the time attenuation profiles. CTP data from four patients with large vessel occlusion and three control subjects were studied. To compare the noise level in the perfusion maps, we use the wavelet estimation of the noise standard deviation implemented in the scikit-image package. We show that both methods significantly reduce noise in the data while preserving important information about the perfusion deficits. These methods can be used to further reduce the dose in CT perfusion protocols or in perfusion studies using C-arm CT, which are burdened by high noise levels.
Multiple Selection Extrapolation for Improved Spatial Error Concealment
Jul 14, 2022
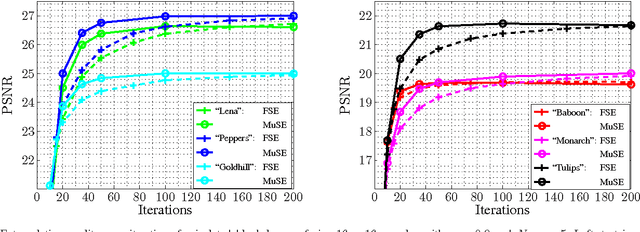
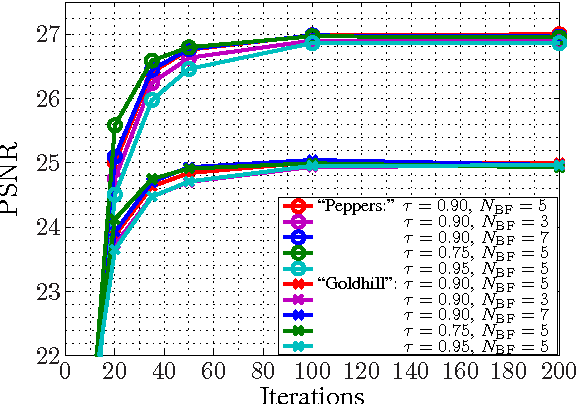

This contribution introduces a novel signal extrapolation algorithm and its application to image error concealment. The signal extrapolation is carried out by iteratively generating a model of the signal suffering from distortion. Thereby, the model results from a weighted superposition of two-dimensional basis functions whereas in every iteration step a set of these is selected and the approximation residual is projected onto the subspace they span. The algorithm is an improvement to the Frequency Selective Extrapolation that has proven to be an effective method for concealing lost or distorted image regions. Compared to this algorithm, the novel algorithm is able to reduce the processing time by a factor larger than three, by still preserving the very high extrapolation quality.
Deep Reinforcement Learning for System-on-Chip: Myths and Realities
Jul 29, 2022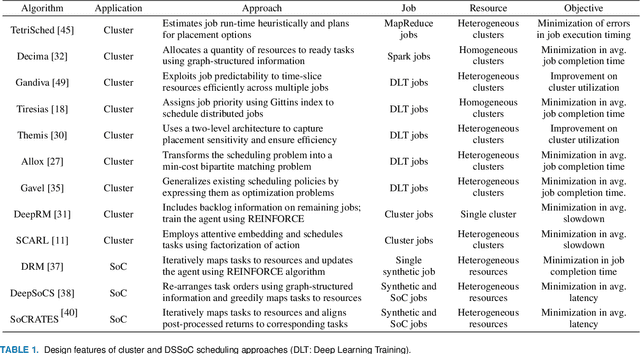
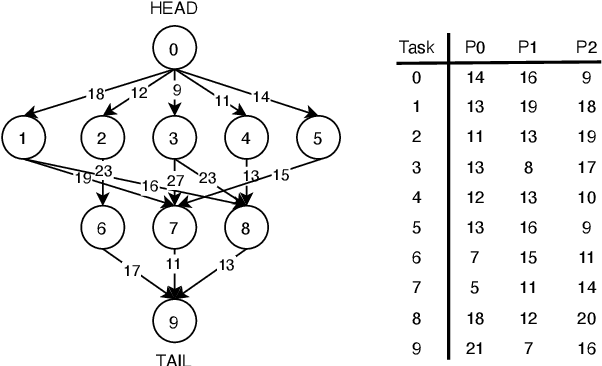
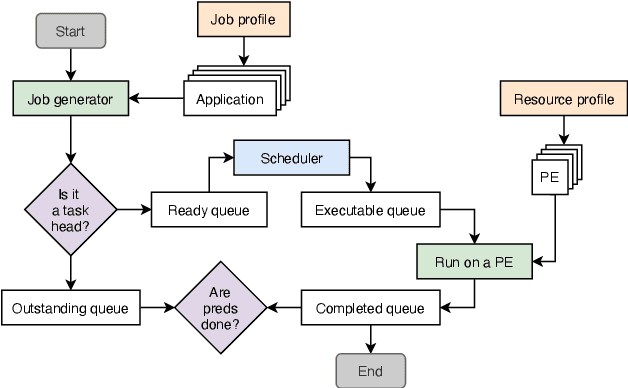

Neural schedulers based on deep reinforcement learning (DRL) have shown considerable potential for solving real-world resource allocation problems, as they have demonstrated significant performance gain in the domain of cluster computing. In this paper, we investigate the feasibility of neural schedulers for the domain of System-on-Chip (SoC) resource allocation through extensive experiments and comparison with non-neural, heuristic schedulers. The key finding is three-fold. First, neural schedulers designed for cluster computing domain do not work well for SoC due to i) heterogeneity of SoC computing resources and ii) variable action set caused by randomness in incoming jobs. Second, our novel neural scheduler technique, Eclectic Interaction Matching (EIM), overcomes the above challenges, thus significantly improving the existing neural schedulers. Specifically, we rationalize the underlying reasons behind the performance gain by the EIM-based neural scheduler. Third, we discover that the ratio of the average processing elements (PE) switching delay and the average PE computation time significantly impacts the performance of neural SoC schedulers even with EIM. Consequently, future neural SoC scheduler design must consider this metric as well as its implementation overhead for practical utility.
Task Embedding Temporal Convolution Networks for Transfer Learning Problems in Renewable Power Time-Series Forecast
Apr 29, 2022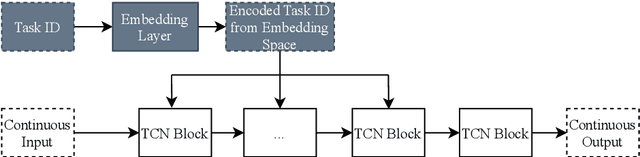
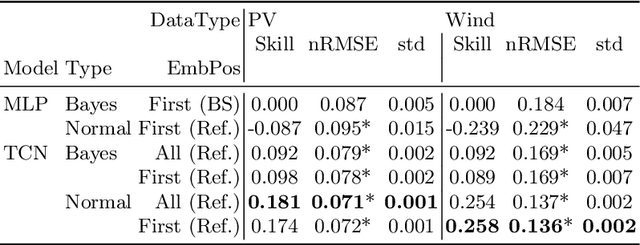
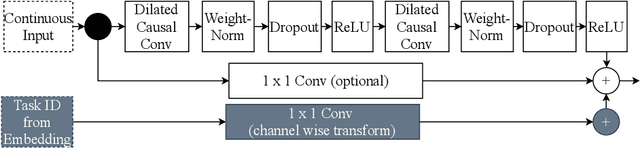
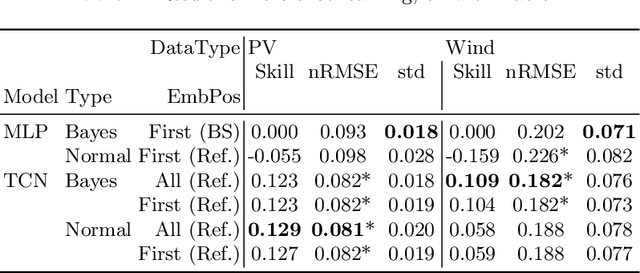
Task embeddings in multi-layer perceptrons for multi-task learning and inductive transfer learning in renewable power forecasts have recently been introduced. In many cases, this approach improves the forecast error and reduces the required training data. However, it does not take the seasonal influences in power forecasts within a day into account, i.e., the diurnal cycle. Therefore, we extended this idea to temporal convolutional networks to consider those seasonalities. We propose transforming the embedding space, which contains the latent similarities between tasks, through convolution and providing these results to the network's residual block. The proposed architecture significantly improves up to 25 percent for multi-task learning for power forecasts on the EuropeWindFarm and GermanSolarFarm dataset compared to the multi-layer perceptron approach. Based on the same data, we achieve a ten percent improvement for the wind datasets and more than 20 percent in most cases for the solar dataset for inductive transfer learning without catastrophic forgetting. Finally, we are the first proposing zero-shot learning for renewable power forecasts to provide predictions even if no training data is available.
Spatiotemporal singular value decomposition for denoising in photoacoustic imaging with low-energy excitation light source
Jul 09, 2022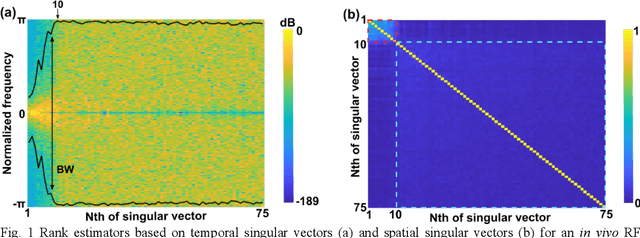
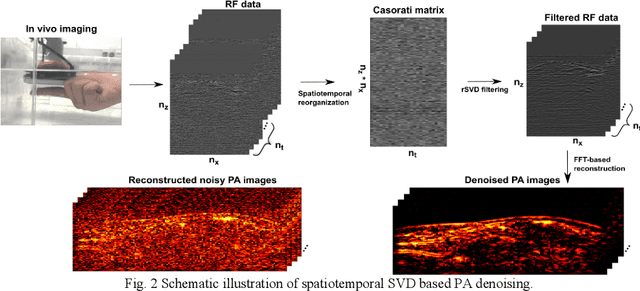
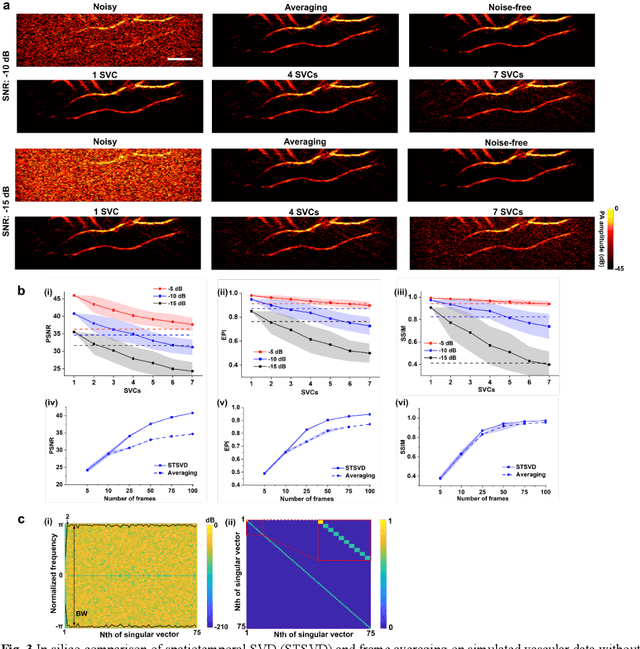
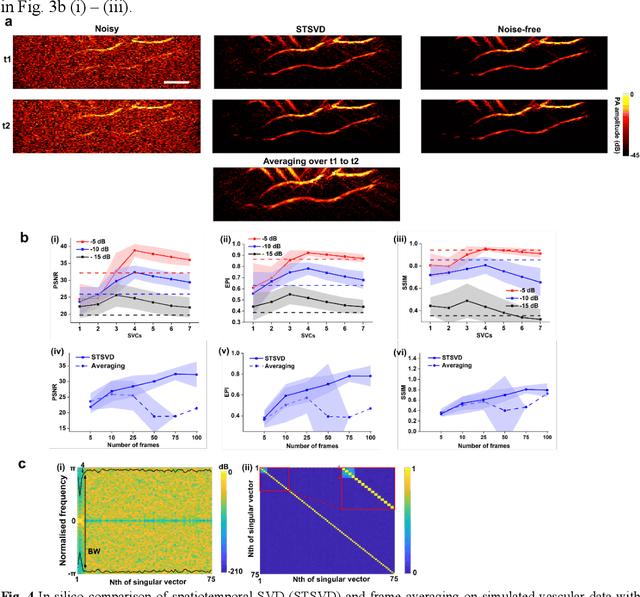
Photoacoustic (PA) imaging is an emerging hybrid imaging modality that combines rich optical spectroscopic contrast and high ultrasonic resolution and thus holds tremendous promise for a wide range of pre-clinical and clinical applications. Compact and affordable light sources such as light-emitting diodes (LEDs) and laser diodes (LDs) are promising alternatives to bulky and expensive solid-state laser systems that are commonly used as PA light sources. These could accelerate the clinical translation of PA technology. However, PA signals generated with these light sources are readily degraded by noise due to the low optical fluence, leading to decreased signal-to-noise ratio (SNR) in PA images. In this work, a spatiotemporal singular value decomposition (SVD) based PA denoising method was investigated for these light sources that usually have low fluence and high repetition rates. The proposed method leverages both spatial and temporal correlations between radiofrequency (RF) data frames. Validation was performed on simulations and in vivo PA data acquired from human fingers (2D) and forearm (3D) using a LED-based system. Spatiotemporal SVD greatly enhanced the PA signals of blood vessels corrupted by noise while preserving a high temporal resolution to slow motions, improving the SNR of in vivo PA images by 1.1, 0.7, and 1.9 times compared to single frame-based wavelet denoising, averaging across 200 frames, and single frame without denoising, respectively. The proposed method demonstrated a processing time of around 50 \mus per frame with SVD acceleration and GPU. Thus, spatiotemporal SVD is well suited to PA imaging systems with low-energy excitation light sources for real-time in vivo applications.
3D Multi-Object Tracking with Differentiable Pose Estimation
Jun 28, 2022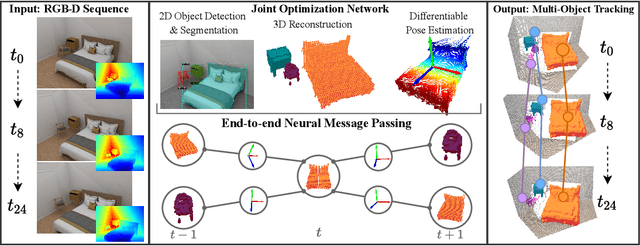
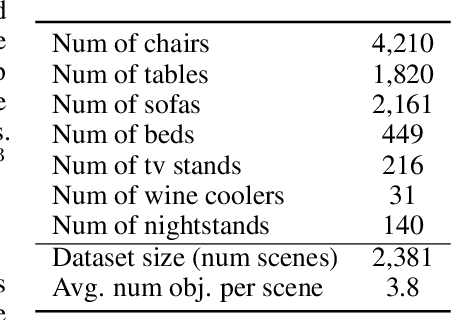
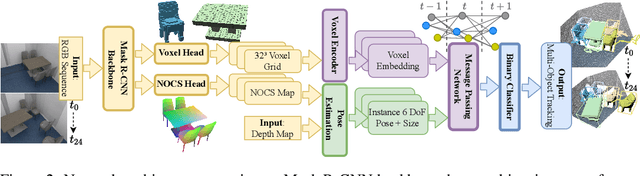
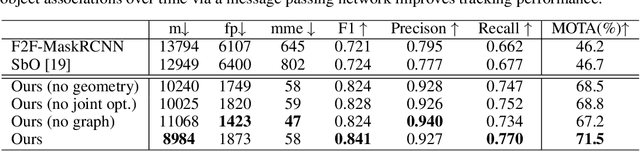
We propose a novel approach for joint 3D multi-object tracking and reconstruction from RGB-D sequences in indoor environments. To this end, we detect and reconstruct objects in each frame while predicting dense correspondences mappings into a normalized object space. We leverage those correspondences to inform a graph neural network to solve for the optimal, temporally-consistent 7-DoF pose trajectories of all objects. The novelty of our method is two-fold: first, we propose a new graph-based approach for differentiable pose estimation over time to learn optimal pose trajectories; second, we present a joint formulation of reconstruction and pose estimation along the time axis for robust and geometrically consistent multi-object tracking. In order to validate our approach, we introduce a new synthetic dataset comprising 2381 unique indoor sequences with a total of 60k rendered RGB-D images for multi-object tracking with moving objects and camera positions derived from the synthetic 3D-FRONT dataset. We demonstrate that our method improves the accumulated MOTA score for all test sequences by 24.8% over existing state-of-the-art methods. In several ablations on synthetic and real-world sequences, we show that our graph-based, fully end-to-end-learnable approach yields a significant boost in tracking performance.
GOAL: Towards Benchmarking Few-Shot Sports Game Summarization
Jul 18, 2022
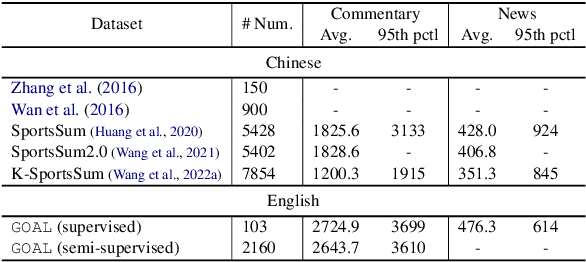
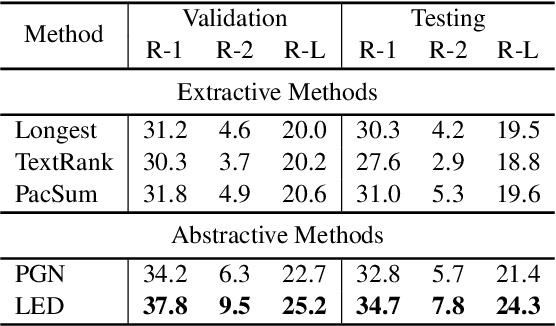

Sports game summarization aims to generate sports news based on real-time commentaries. The task has attracted wide research attention but is still under-explored probably due to the lack of corresponding English datasets. Therefore, in this paper, we release GOAL, the first English sports game summarization dataset. Specifically, there are 103 commentary-news pairs in GOAL, where the average lengths of commentaries and news are 2724.9 and 476.3 words, respectively. Moreover, to support the research in the semi-supervised setting, GOAL additionally provides 2,160 unlabeled commentary documents. Based on our GOAL, we build and evaluate several baselines, including extractive and abstractive baselines. The experimental results show the challenges of this task still remain. We hope our work could promote the research of sports game summarization. The dataset has been released at https://github.com/krystalan/goal.
Layer-Wise Partitioning and Merging for Efficient and Scalable Deep Learning
Jul 22, 2022
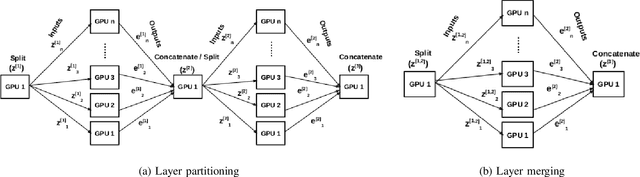

Deep Neural Network (DNN) models are usually trained sequentially from one layer to another, which causes forward, backward and update locking's problems, leading to poor performance in terms of training time. The existing parallel strategies to mitigate these problems provide suboptimal runtime performance. In this work, we have proposed a novel layer-wise partitioning and merging, forward and backward pass parallel framework to provide better training performance. The novelty of the proposed work consists of 1) a layer-wise partition and merging model which can minimise communication overhead between devices without the memory cost of existing strategies during the training process; 2) a forward pass and backward pass parallelisation and optimisation to address the update locking problem and minimise the total training cost. The experimental evaluation on real use cases shows that the proposed method outperforms the state-of-the-art approaches in terms of training speed; and achieves almost linear speedup without compromising the accuracy performance of the non-parallel approach.
Continuous-Time Model-Based Reinforcement Learning
Feb 10, 2021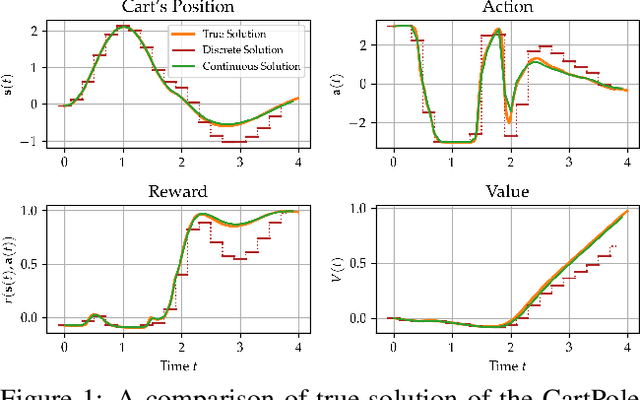


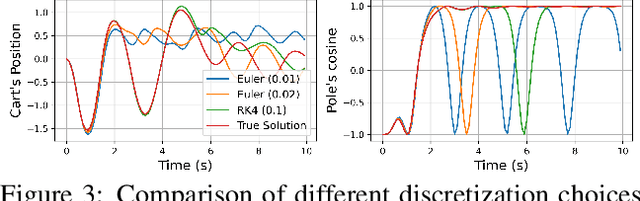
Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. To avoid time-discretization approximation of the underlying process, we propose a continuous-time MBRL framework based on a novel actor-critic method. Our approach also infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We implement and test our method on a new ODE-RL suite that explicitly solves continuous-time control systems. Our experiments illustrate that the model is robust against irregular and noisy data, is sample-efficient, and can solve control problems which pose challenges to discrete-time MBRL methods.
Beam Alignment for the Cell-Free mmWave Massive MU-MIMO Uplink
Jul 20, 2022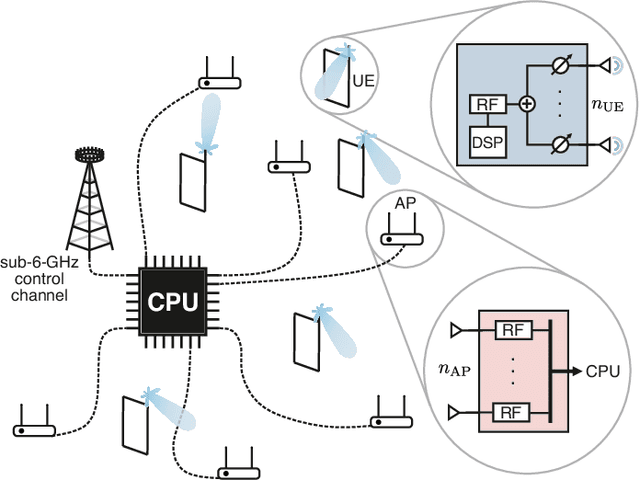
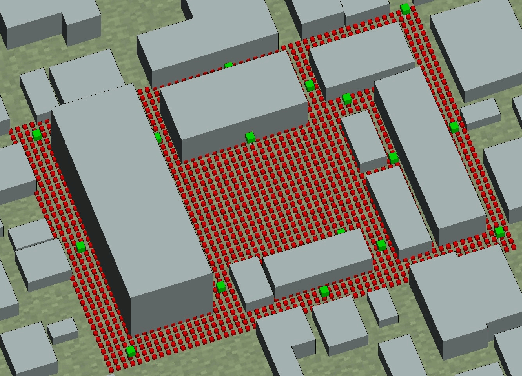
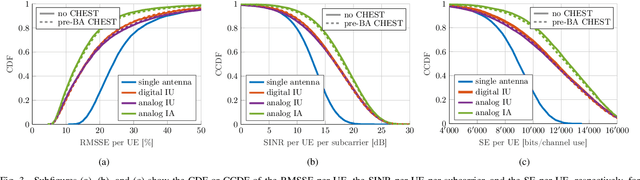
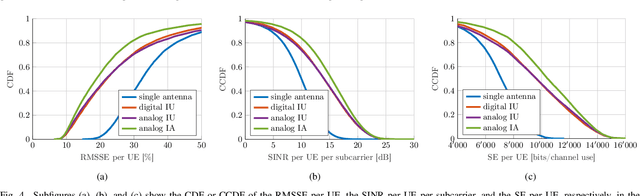
Millimeter-wave (mmWave) cell-free massive multi-user (MU) multiple-input multiple-output (MIMO) systems combine the large bandwidths available at mmWave frequencies with the improved coverage of cell-free systems. However, to combat the high path loss at mmWave frequencies, user equipments (UEs) must form beams in meaningful directions, i.e., to a nearby access point (AP). At the same time, multiple UEs should avoid transmitting to the same AP to reduce MU interference. We propose an interference-aware method for beam alignment (BA) in the cell-free mmWave massive MU-MIMO uplink. In the considered scenario, the APs perform full digital receive beamforming while the UEs perform analog transmit beamforming. We evaluate our method using realistic mmWave channels from a commercial ray-tracer, showing the superiority of the proposed method over omnidirectional transmission as well as over methods that do not take MU interference into account.