 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leaning-Based Control of an Immersive-Telepresence Robot
Aug 22, 2022
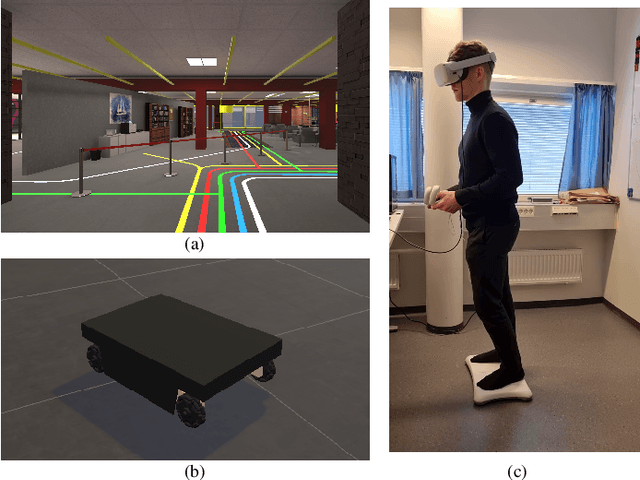


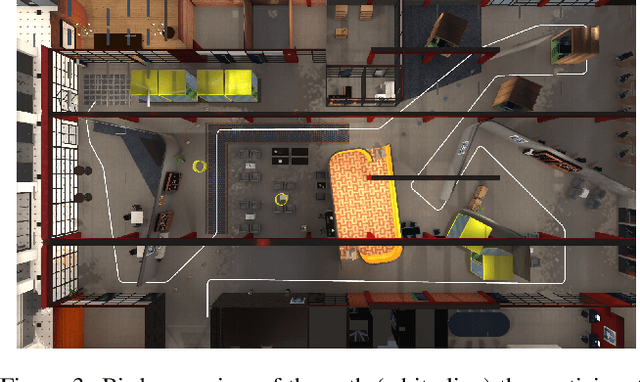
In this paper, we present an implementation of a leaning-based control of a differential drive telepresence robot and a user study in simulation, with the goal of bringing the same functionality to a real telepresence robot. The participants used a balance board to control the robot and viewed the virtual environment through a head-mounted display. The main motivation for using a balance board as the control device stems from Virtual Reality (VR) sickness; even small movements of your own body matching the motions seen on the screen decrease the sensory conflict between vision and vestibular organs, which lies at the heart of most theories regarding the onset of VR sickness. To test the hypothesis that the balance board as a control method would be less sickening than using joysticks, we designed a user study (N=32, 15 women) in which the participants drove a simulated differential drive robot in a virtual environment with either a Nintendo Wii Balance Board or joysticks. However, our pre-registered main hypotheses were not supported; the joystick did not cause any more VR sickness on the participants than the balance board, and the board proved to be statistically significantly more difficult to use, both subjectively and objectively. Analyzing the open-ended questions revealed these results to be likely connected, meaning that the difficulty of use seemed to affect sickness; even unlimited training time before the test did not make the use as easy as the familiar joystick. Thus, making the board easier to use is a key to enable its potential; we present a few possibilities towards this goal.
Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
Aug 15, 2022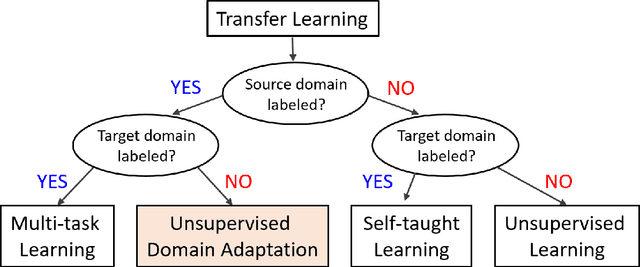

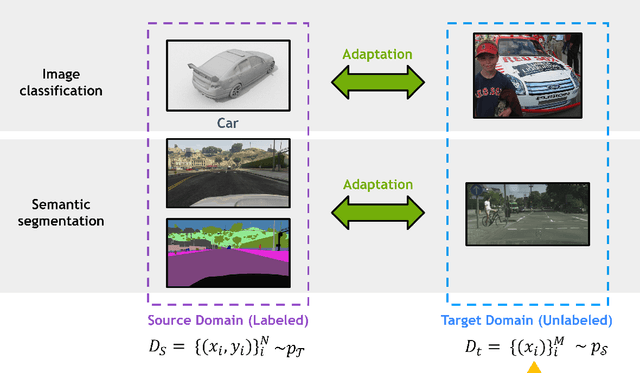
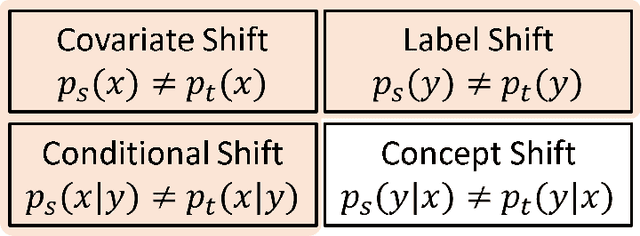
Deep learning has become the method of choice to tackle real-world problems in different domains, partly because of its ability to learn from data and achieve impressive performance on a wide range of applications. However, its success usually relies on two assumptions: (i) vast troves of labeled datasets are required for accurate model fitting, and (ii) training and testing data are independent and identically distributed. Its performance on unseen target domains, thus, is not guaranteed, especially when encountering out-of-distribution data at the adaptation stage. The performance drop on data in a target domain is a critical problem in deploying deep neural networks that are successfully trained on data in a source domain. Unsupervised domain adaptation (UDA) is proposed to counter this, by leveraging both labeled source domain data and unlabeled target domain data to carry out various tasks in the target domain. UDA has yielded promising results on natural image processing, video analysis, natural language processing, time-series data analysis, medical image analysis, etc. In this review, as a rapidly evolving topic, we provide a systematic comparison of its methods and applications. In addition, the connection of UDA with its closely related tasks, e.g., domain generalization and out-of-distribution detection, has also been discussed. Furthermore, deficiencies in current methods and possible promising directions are highlighted.
Comprehensive Dataset of Face Manipulations for Development and Evaluation of Forensic Tools
Aug 24, 2022
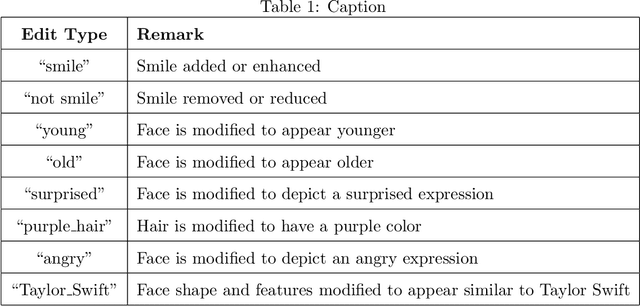


Digital media (e.g., photographs, video) can be easily created, edited, and shared. Tools for editing digital media are capable of doing so while also maintaining a high degree of photo-realism. While many types of edits to digital media are generally benign, others can also be applied for malicious purposes. State-of-the-art face editing tools and software can, for example, artificially make a person appear to be smiling at an inopportune time, or depict authority figures as frail and tired in order to discredit individuals. Given the increasing ease of editing digital media and the potential risks from misuse, a substantial amount of effort has gone into media forensics. To this end, we created a challenge dataset of edited facial images to assist the research community in developing novel approaches to address and classify the authenticity of digital media. Our dataset includes edits applied to controlled, portrait-style frontal face images and full-scene in-the-wild images that may include multiple (i.e., more than one) face per image. The goals of our dataset is to address the following challenge questions: (1) Can we determine the authenticity of a given image (edit detection)? (2) If an image has been edited, can we \textit{localize} the edit region? (3) If an image has been edited, can we deduce (classify) what edit type was performed? The majority of research in image forensics generally attempts to answer item (1), detection. To the best of our knowledge, there are no formal datasets specifically curated to evaluate items (2) and (3), localization and classification, respectively. Our hope is that our prepared evaluation protocol will assist researchers in improving the state-of-the-art in image forensics as they pertain to these challenges.
Robust Reinforcement Learning using Offline Data
Aug 10, 2022
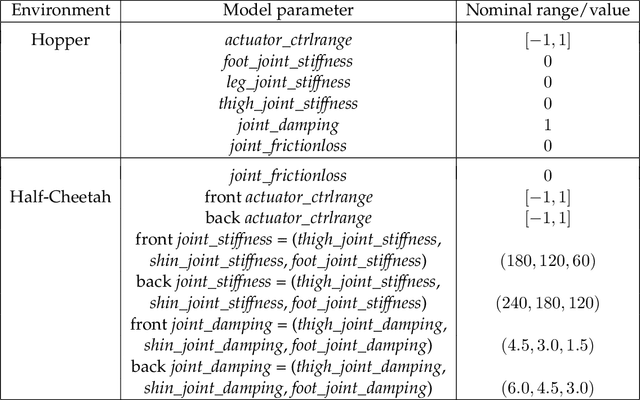
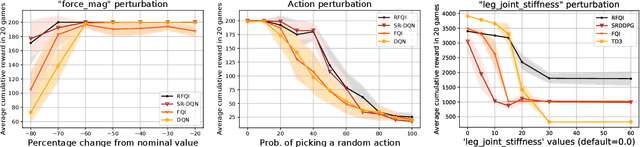
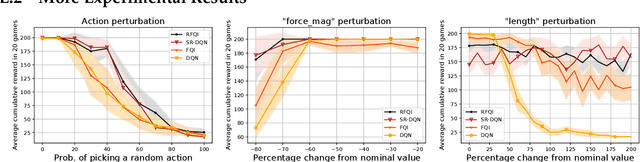
The goal of robust reinforcement learning (RL) is to learn a policy that is robust against the uncertainty in model parameters. Parameter uncertainty commonly occurs in many real-world RL applications due to simulator modeling errors, changes in the real-world system dynamics over time, and adversarial disturbances. Robust RL is typically formulated as a max-min problem, where the objective is to learn the policy that maximizes the value against the worst possible models that lie in an uncertainty set. In this work, we propose a robust RL algorithm called Robust Fitted Q-Iteration (RFQI), which uses only an offline dataset to learn the optimal robust policy. Robust RL with offline data is significantly more challenging than its non-robust counterpart because of the minimization over all models present in the robust Bellman operator. This poses challenges in offline data collection, optimization over the models, and unbiased estimation. In this work, we propose a systematic approach to overcome these challenges, resulting in our RFQI algorithm. We prove that RFQI learns a near-optimal robust policy under standard assumptions and demonstrate its superior performance on standard benchmark problems.
Satellite image data downlink scheduling problem with family attribute: Model &Algorithm
Jul 04, 2022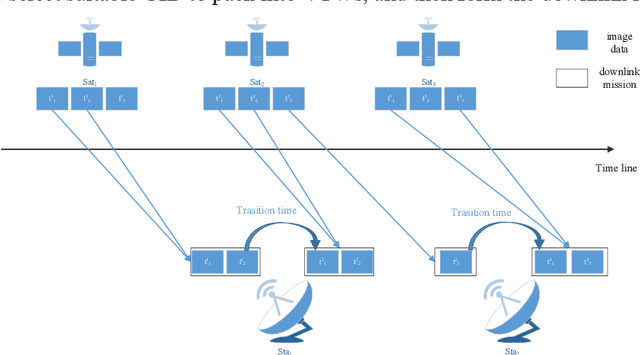

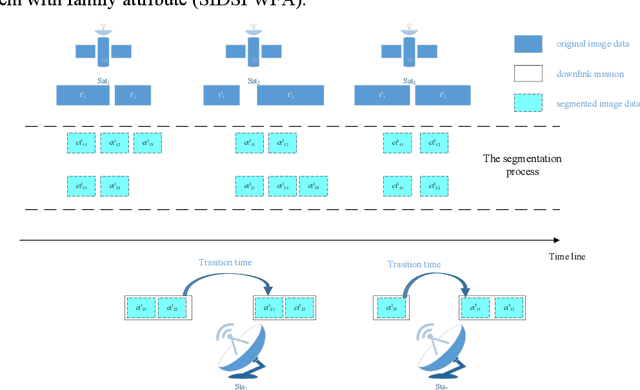
The asynchronous development between the observation capability and the transition capability results in that an original image data (OID) formed by one-time observation cannot be completely transmitted in one transmit chance between the EOS and GS (named as a visible time window, VTW). It needs to segment the OID to several segmented image data (SID) and then transmits them in several VTWs, which enriches the extension of satellite image data downlink scheduling problem (SIDSP). We define the novel SIDSP as satellite image data downlink scheduling problem with family attribute (SIDSPWFA), in which some big OID is segmented by a fast segmentation operator first, and all SID and other no-segmented OID is transmitted in the second step. Two optimization objectives, the image data transmission failure rate (FR) and the segmentation times (ST), are then designed to formalize SIDSPWFA as a bi-objective discrete optimization model. Furthermore, a bi-stage differential evolutionary algorithm(DE+NSGA-II) is developed holding several bi-stage operators. Extensive simulation instances show the efficiency of models, strategies, algorithms and operators is analyzed in detail.
Fuse and Attend: Generalized Embedding Learning for Art and Sketches
Aug 20, 2022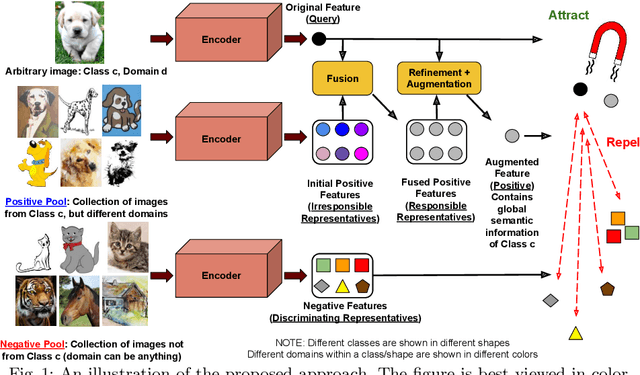
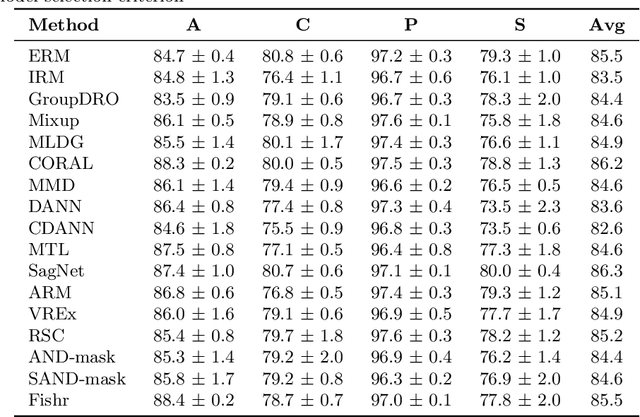
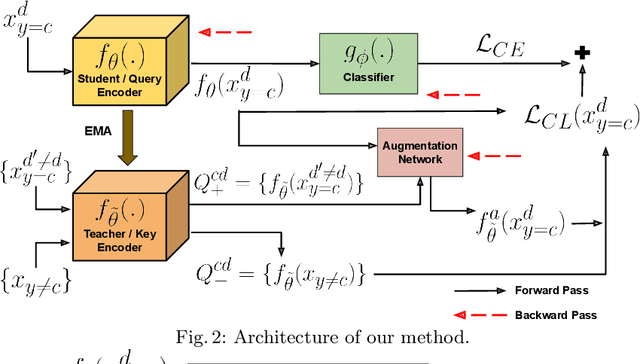
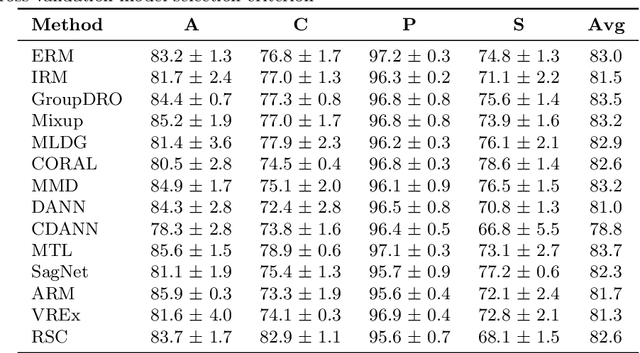
While deep Embedding Learning approaches have witnessed widespread success in multiple computer vision tasks, the state-of-the-art methods for representing natural images need not necessarily perform well on images from other domains, such as paintings, cartoons, and sketch. This is because of the huge shift in the distribution of data from across these domains, as compared to natural images. Domains like sketch often contain sparse informative pixels. However, recognizing objects in such domains is crucial, given multiple relevant applications leveraging such data, for instance, sketch to image retrieval. Thus, achieving an Embedding Learning model that could perform well across multiple domains is not only challenging, but plays a pivotal role in computer vision. To this end, in this paper, we propose a novel Embedding Learning approach with the goal of generalizing across different domains. During training, given a query image from a domain, we employ gated fusion and attention to generate a positive example, which carries a broad notion of the semantics of the query object category (from across multiple domains). By virtue of Contrastive Learning, we pull the embeddings of the query and positive, in order to learn a representation which is robust across domains. At the same time, to teach the model to be discriminative against examples from different semantic categories (across domains), we also maintain a pool of negative embeddings (from different categories). We show the prowess of our method using the DomainBed framework, on the popular PACS (Photo, Art painting, Cartoon, and Sketch) dataset.
Multi-Frequency Information Enhanced Channel Attention Module for Speaker Representation Learning
Jul 10, 2022

Recently, attention mechanisms have been applied successfully in neural network-based speaker verification systems. Incorporating the Squeeze-and-Excitation block into convolutional neural networks has achieved remarkable performance. However, it uses global average pooling (GAP) to simply average the features along time and frequency dimensions, which is incapable of preserving sufficient speaker information in the feature maps. In this study, we show that GAP is a special case of a discrete cosine transform (DCT) on time-frequency domain mathematically using only the lowest frequency component in frequency decomposition. To strengthen the speaker information extraction ability, we propose to utilize multi-frequency information and design two novel and effective attention modules, called Single-Frequency Single-Channel (SFSC) attention module and Multi-Frequency Single-Channel (MFSC) attention module. The proposed attention modules can effectively capture more speaker information from multiple frequency components on the basis of DCT. We conduct comprehensive experiments on the VoxCeleb datasets and a probe evaluation on the 1st 48-UTD forensic corpus. Experimental results demonstrate that our proposed SFSC and MFSC attention modules can efficiently generate more discriminative speaker representations and outperform ResNet34-SE and ECAPA-TDNN systems with relative 20.9% and 20.2% reduction in EER, without adding extra network parameters.
Conformal Prediction with Temporal Quantile Adjustments
May 23, 2022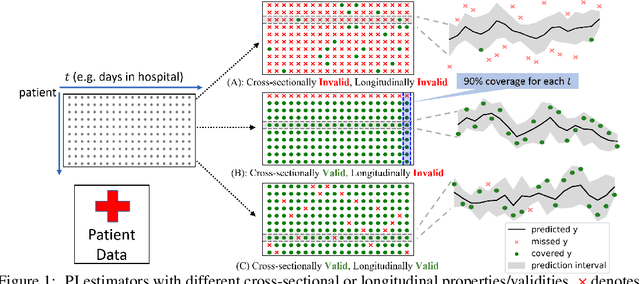
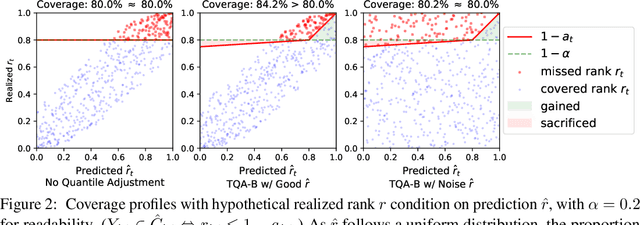
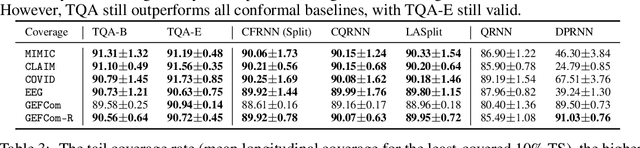
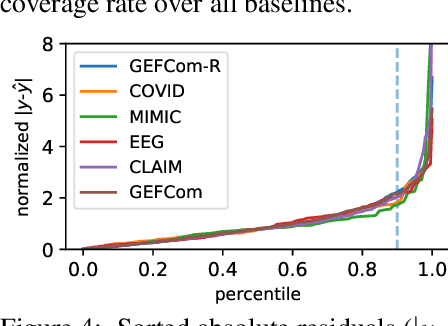
We develop Temporal Quantile Adjustment (TQA), a general method to construct efficient and valid prediction intervals (PIs) for regression on cross-sectional time series data. Such data is common in many domains, including econometrics and healthcare. A canonical example in healthcare is predicting patient outcomes using physiological time-series data, where a population of patients composes a cross-section. Reliable PI estimators in this setting must address two distinct notions of coverage: cross-sectional coverage across a cross-sectional slice, and longitudinal coverage along the temporal dimension for each time series. Recent works have explored adapting Conformal Prediction (CP) to obtain PIs in the time series context. However, none handles both notions of coverage simultaneously. CP methods typically query a pre-specified quantile from the distribution of nonconformity scores on a calibration set. TQA adjusts the quantile to query in CP at each time $t$, accounting for both cross-sectional and longitudinal coverage in a theoretically-grounded manner. The post-hoc nature of TQA facilitates its use as a general wrapper around any time series regression model. We validate TQA's performance through extensive experimentation: TQA generally obtains efficient PIs and improves longitudinal coverage while preserving cross-sectional coverage.
Formalizing and Evaluating Requirements of Perception Systems for Automated Vehicles using Spatio-Temporal Perception Logic
Jun 29, 2022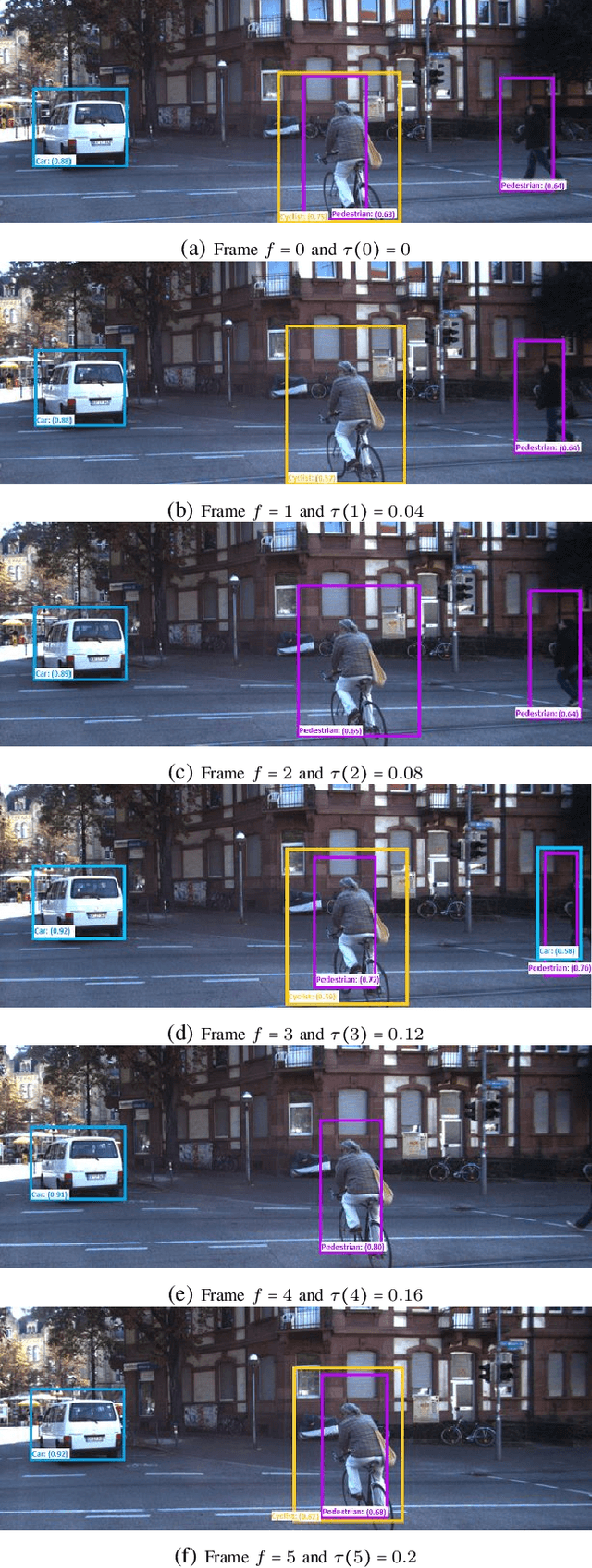


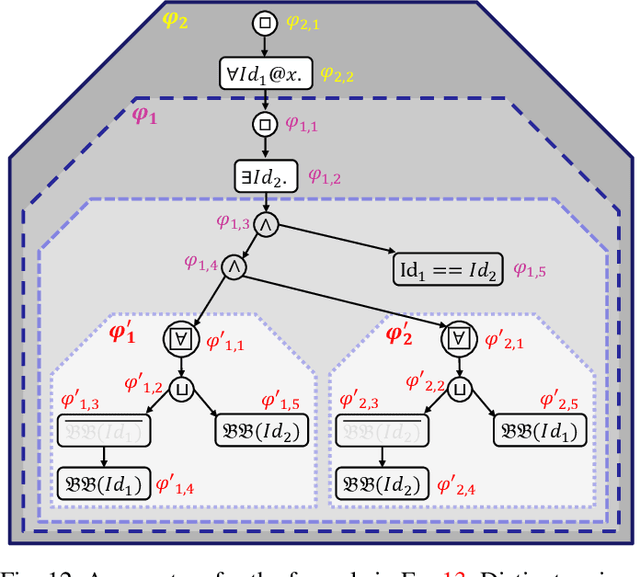
Automated vehicles (AV) heavily depend on robust perception systems. Current methods for evaluating vision systems focus mainly on frame-by-frame performance. Such evaluation methods appear to be inadequate in assessing the performance of a perception subsystem when used within an AV. In this paper, we present a logic -- referred to as Spatio-Temporal Perception Logic (STPL) -- which utilizes both spatial and temporal modalities. STPL enables reasoning over perception data using spatial and temporal relations. One major advantage of STPL is that it facilitates basic sanity checks on the real-time performance of the perception system, even without ground-truth data in some cases. We identify a fragment of STPL which is efficiently monitorable offline in polynomial time. Finally, we present a range of specifications for AV perception systems to highlight the types of requirements that can be expressed and analyzed through offline monitoring with STPL.
Analysis of Quality Diversity Algorithms for the Knapsack Problem
Jul 28, 2022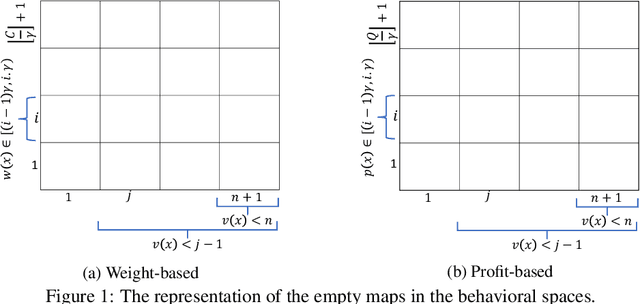

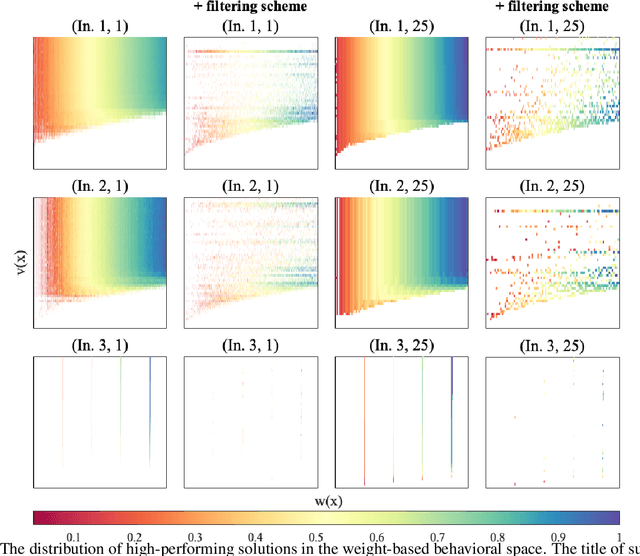

Quality diversity (QD) algorithms have been shown to be very successful when dealing with problems in areas such as robotics, games and combinatorial optimization. They aim to maximize the quality of solutions for different regions of the so-called behavioural space of the underlying problem. In this paper, we apply the QD paradigm to simulate dynamic programming behaviours on knapsack problem, and provide a first runtime analysis of QD algorithms. We show that they are able to compute an optimal solution within expected pseudo-polynomial time, and reveal parameter settings that lead to a fully polynomial randomised approximation scheme (FPRAS). Our experimental investigations evaluate the different approaches on classical benchmark sets in terms of solutions constructed in the behavioural space as well as the runtime needed to obtain an optimal solution.