 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Representation Learning for the Automatic Indexing of Sound Effects Libraries
Aug 18, 2022
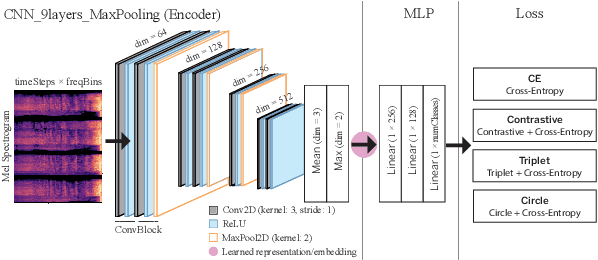
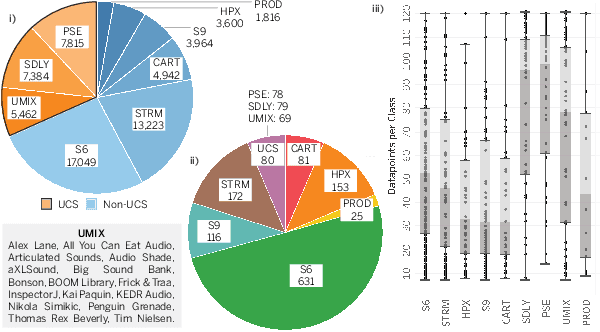
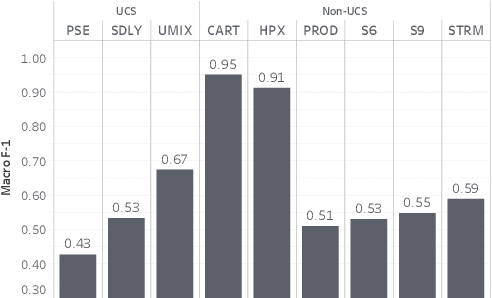
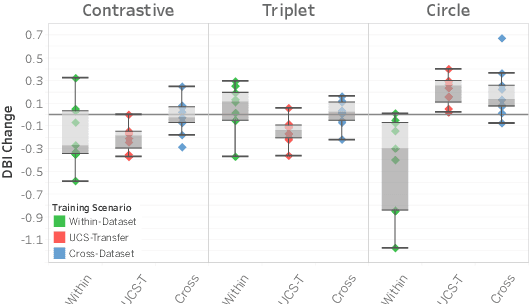
Labeling and maintaining a commercial sound effects library is a time-consuming task exacerbated by databases that continually grow in size and undergo taxonomy updates. Moreover, sound search and taxonomy creation are complicated by non-uniform metadata, an unrelenting problem even with the introduction of a new industry standard, the Universal Category System. To address these problems and overcome dataset-dependent limitations that inhibit the successful training of deep learning models, we pursue representation learning to train generalized embeddings that can be used for a wide variety of sound effects libraries and are a taxonomy-agnostic representation of sound. We show that a task-specific but dataset-independent representation can successfully address data issues such as class imbalance, inconsistent class labels, and insufficient dataset size, outperforming established representations such as OpenL3. Detailed experimental results show the impact of metric learning approaches and different cross-dataset training methods on representational effectiveness.
Continuous Prediction with Experts' Advice
Jun 01, 2022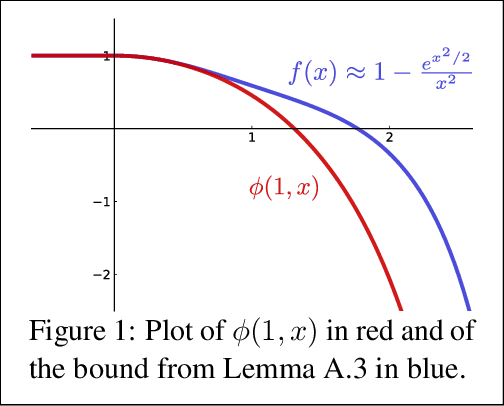
Prediction with experts' advice is one of the most fundamental problems in online learning and captures many of its technical challenges. A recent line of work has looked at online learning through the lens of differential equations and continuous-time analysis. This viewpoint has yielded optimal results for several problems in online learning. In this paper, we employ continuous-time stochastic calculus in order to study the discrete-time experts' problem. We use these tools to design a continuous-time, parameter-free algorithm with improved guarantees for the quantile regret. We then develop an analogous discrete-time algorithm with a very similar analysis and identical quantile regret bounds. Finally, we design an anytime continuous-time algorithm with regret matching the optimal fixed-time rate when the gains are independent Brownian Motions; in many settings, this is the most difficult case. This gives some evidence that, even with adversarial gains, the optimal anytime and fixed-time regrets may coincide.
SwinFIR: Revisiting the SwinIR with Fast Fourier Convolution and Improved Training for Image Super-Resolution
Aug 24, 2022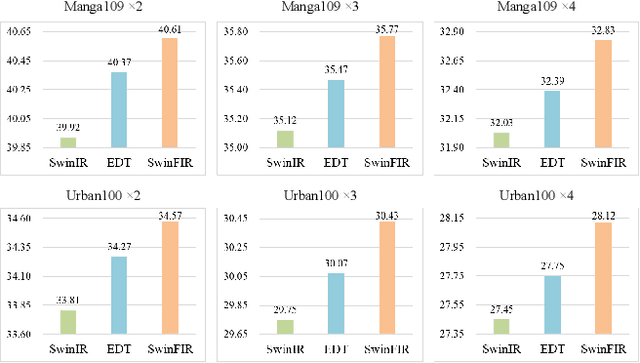
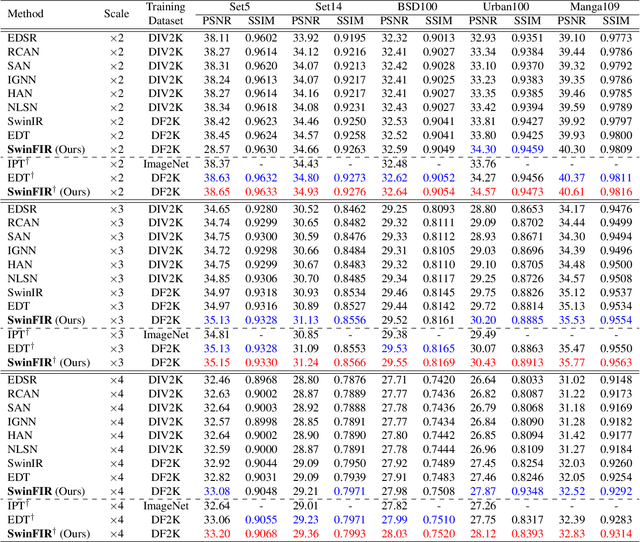


Transformer-based methods have achieved impressive image restoration performance due to their capacities to model long-range dependency compared to CNN-based methods. However, advances like SwinIR adopts the window-based and local attention strategy to balance the performance and computational overhead, which restricts employing large receptive fields to capture global information and establish long dependencies in the early layers. To further improve the efficiency of capturing global information, in this work, we propose SwinFIR to extend SwinIR by replacing Fast Fourier Convolution (FFC) components, which have the image-wide receptive field. We also revisit other advanced techniques, i.e, data augmentation, pre-training, and feature ensemble to improve the effect of image reconstruction. And our feature ensemble method enables the performance of the model to be considerably enhanced without increasing the training and testing time. We applied our algorithm on multiple popular large-scale benchmarks and achieved state-of-the-art performance comparing to the existing methods. For example, our SwinFIR achieves the PSNR of 32.83 dB on Manga109 dataset, which is 0.8 dB higher than the state-of-the-art SwinIR method.
A Multitask Deep Learning Model for Parsing Bridge Elements and Segmenting Defect in Bridge Inspection Images
Sep 06, 2022
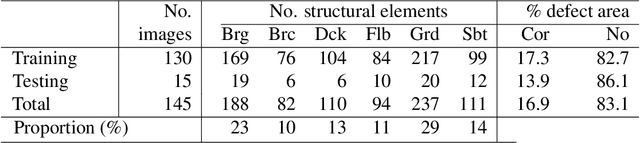
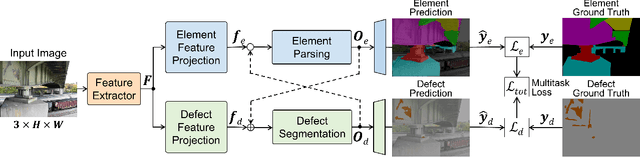
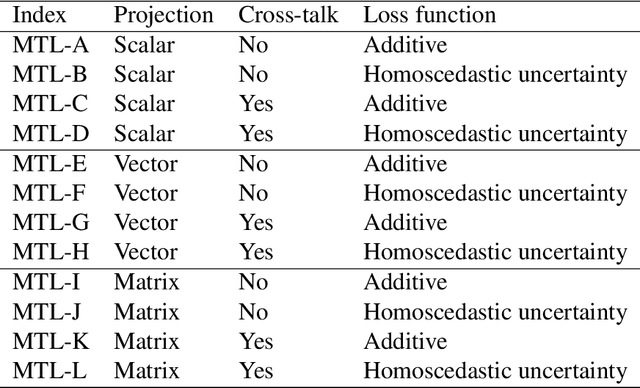
The vast network of bridges in the United States raises a high requirement for its maintenance and rehabilitation. The massive cost of manual visual inspection to assess the conditions of the bridges turns out to be a burden to some extent. Advanced robots have been leveraged to automate inspection data collection. Automating the segmentations of multiclass elements, as well as surface defects on the elements, in the large volume of inspection image data would facilitate an efficient and effective assessment of the bridge condition. Training separate single-task networks for element parsing (i.e., semantic segmentation of multiclass elements) and defect segmentation fails to incorporate the close connection between these two tasks in the inspection images where both recognizable structural elements and apparent surface defects are present. This paper is motivated to develop a multitask deep neural network that fully utilizes such interdependence between bridge elements and defects to boost the performance and generalization of the model. Furthermore, the effectiveness of the proposed network designs in improving the task performance was investigated, including feature decomposition, cross-talk sharing, and multi-objective loss function. A dataset with pixel-level labels of bridge elements and corrosion was developed for training and assessment of the models. Quantitative and qualitative results from evaluating the developed multitask deep neural network demonstrate that the recommended network outperforms the independent single-task networks not only in performance (2.59% higher mIoU on bridge parsing and 1.65% on corrosion segmentation) but also in computational time and implementation capability.
How important are socioeconomic factors for hurricane performance of power systems? An analysis of disparities through machine learning
Aug 18, 2022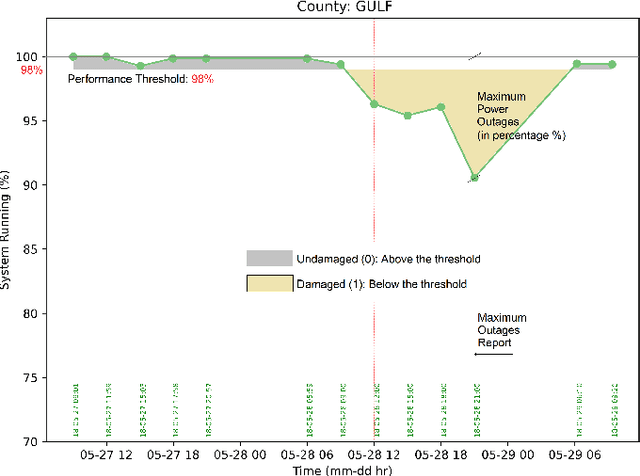
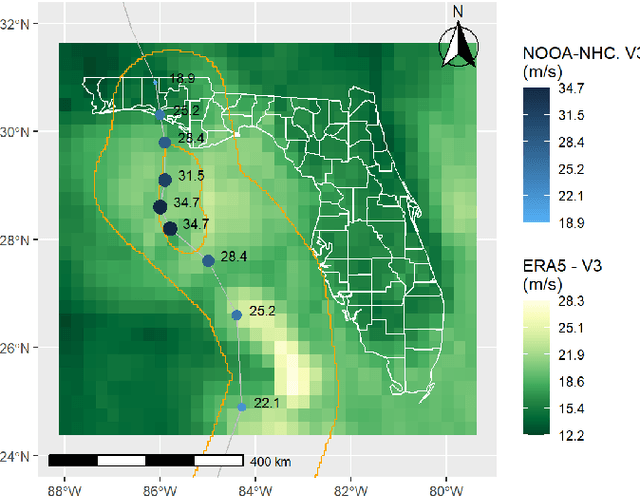
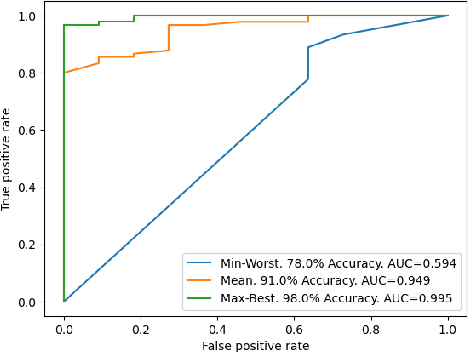
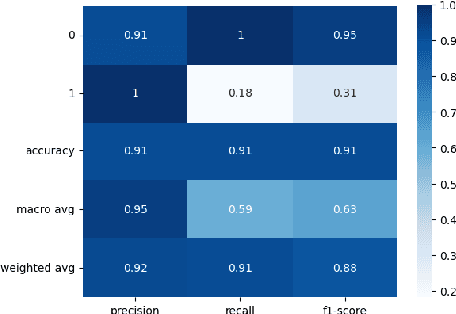
This paper investigates whether socioeconomic factors are important for the hurricane performance of the electric power system in Florida. The investigation is performed using the Random Forest classifier with Mean Decrease of Accuracy (MDA) for measuring the importance of a set of factors that include hazard intensity, time to recovery from maximum impact, and socioeconomic characteristics of the affected population. The data set (at county scale) for this study includes socioeconomic variables from the 5-year American Community Survey (ACS), as well as wind velocities, and outage data of five hurricanes including Alberto and Michael in 2018, Dorian in 2019, and Eta and Isaias in 2020. The study shows that socioeconomic variables are considerably important for the system performance model. This indicates that social disparities may exist in the occurrence of power outages, which directly impact the resilience of communities and thus require immediate attention.
FIgLib & SmokeyNet: Dataset and Deep Learning Model for Real-Time Wildland Fire Smoke Detection
Dec 16, 2021
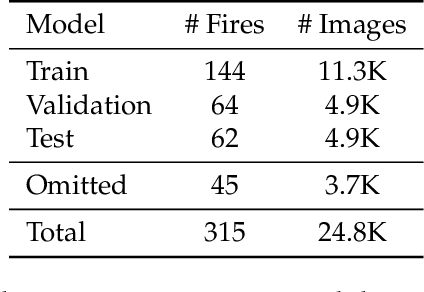
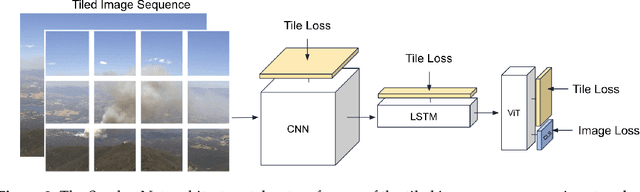
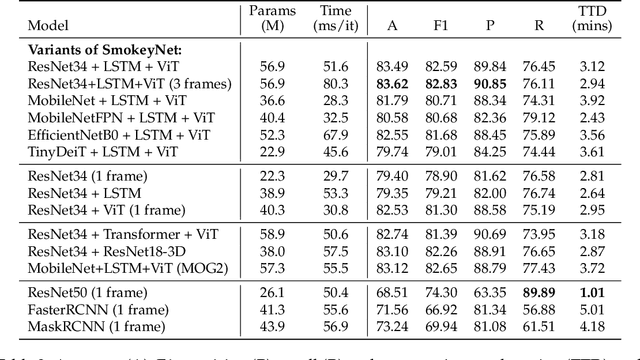
The size and frequency of wildland fires in the western United States have dramatically increased in recent years. On high fire-risk days, a small fire ignition can rapidly grow and get out of control. Early detection of fire ignitions from initial smoke can assist the response to such fires before they become difficult to manage. Past deep learning approaches for wildfire smoke detection have suffered from small or unreliable datasets that make it difficult to extrapolate performance to real-world scenarios. In this work, we present the Fire Ignition Library (FIgLib), a publicly-available dataset of nearly 25,000 labeled wildfire smoke images as seen from fixed-view cameras deployed in Southern California. We also introduce SmokeyNet, a novel deep learning architecture using spatio-temporal information from camera imagery for real-time wildfire smoke detection. When trained on the FIgLib dataset, SmokeyNet outperforms comparable baselines and rivals human performance. We hope that the availability of the FIgLib dataset and the SmokeyNet architecture will inspire further research into deep learning methods for wildfire smoke detection, leading to automated notification systems that reduce the time to wildfire response.
Deep Learning Closure Models for Large-Eddy Simulation of Flows around Bluff Bodies
Aug 10, 2022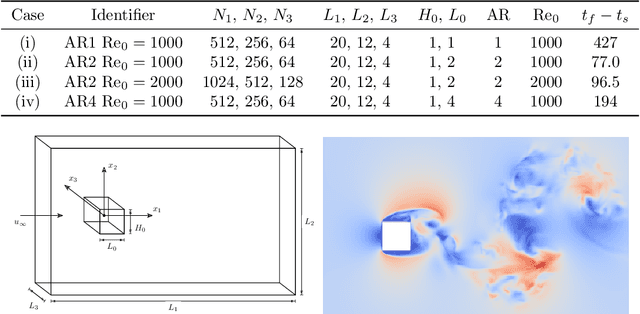
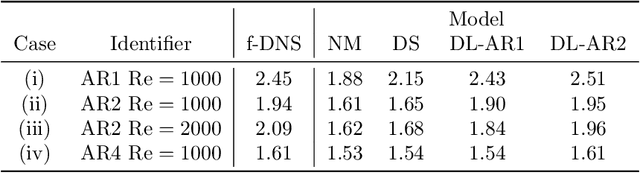
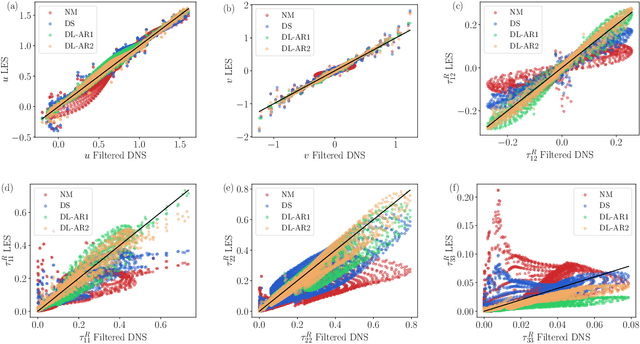
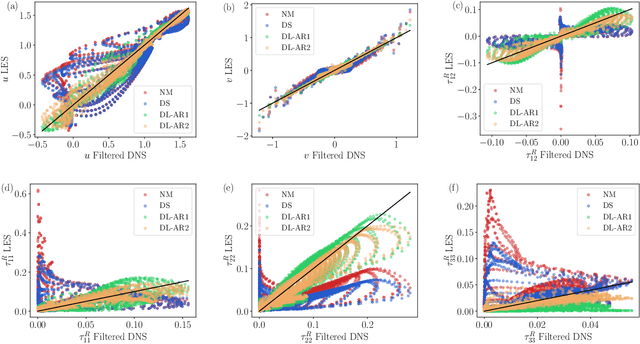
A deep learning (DL) closure model for large-eddy simulation (LES) is developed and evaluated for incompressible flows around a rectangular cylinder at moderate Reynolds numbers. Near-wall flow simulation remains a central challenge in aerodynamic modeling: RANS predictions of separated flows are often inaccurate, while LES can require prohibitively small near-wall mesh sizes. The DL-LES model is trained using adjoint PDE optimization methods to match, as closely as possible, direct numerical simulation (DNS) data. It is then evaluated out-of-sample (i.e., for new aspect ratios and Reynolds numbers not included in the training data) and compared against a standard LES model (the dynamic Smagorinsky model). The DL-LES model outperforms dynamic Smagorinsky and is able to achieve accurate LES predictions on a relatively coarse mesh (downsampled from the DNS grid by a factor of four in each Cartesian direction). We study the accuracy of the DL-LES model for predicting the drag coefficient, mean flow, and Reynolds stress. A crucial challenge is that the LES quantities of interest are the steady-state flow statistics; for example, the time-averaged mean velocity $\bar{u}(x) = \displaystyle \lim_{t \rightarrow \infty} \frac{1}{t} \int_0^t u(s,x) ds$. Calculating the steady-state flow statistics therefore requires simulating the DL-LES equations over a large number of flow times through the domain; it is a non-trivial question whether an unsteady partial differential equation model whose functional form is defined by a deep neural network can remain stable and accurate on $t \in [0, \infty)$. Our results demonstrate that the DL-LES model is accurate and stable over large physical time spans, enabling the estimation of the steady-state statistics for the velocity, fluctuations, and drag coefficient of turbulent flows around bluff bodies relevant to aerodynamic applications.
Magpie: Automatically Tuning Static Parameters for Distributed File Systems using Deep Reinforcement Learning
Jul 19, 2022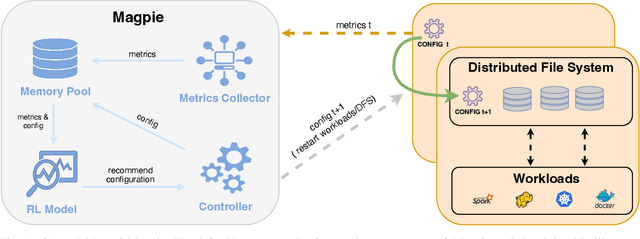
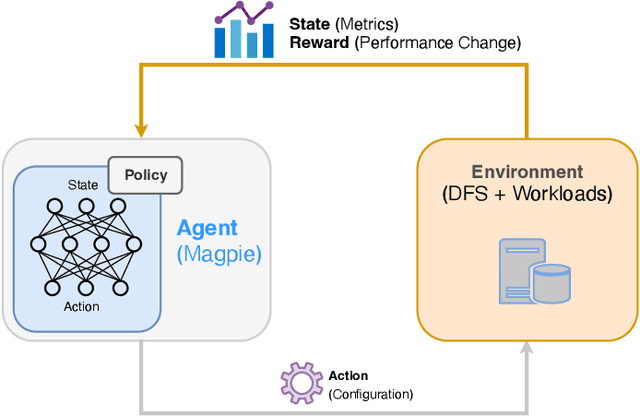
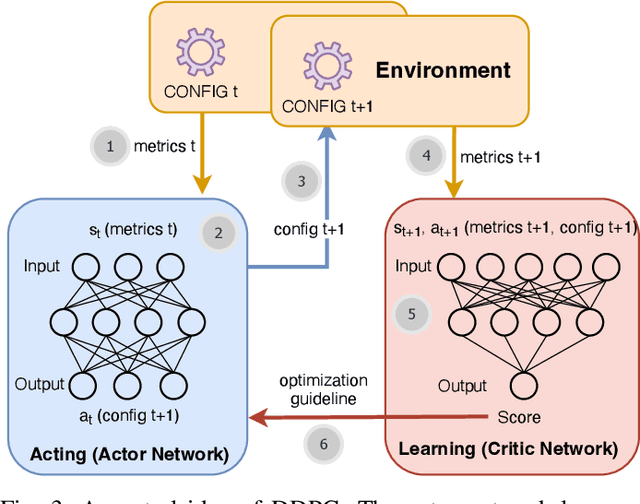
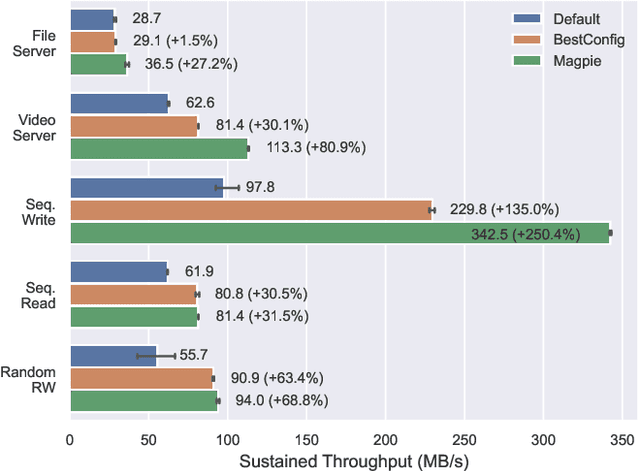
Distributed file systems are widely used nowadays, yet using their default configurations is often not optimal. At the same time, tuning configuration parameters is typically challenging and time-consuming. It demands expertise and tuning operations can also be expensive. This is especially the case for static parameters, where changes take effect only after a restart of the system or workloads. We propose a novel approach, Magpie, which utilizes deep reinforcement learning to tune static parameters by strategically exploring and exploiting configuration parameter spaces. To boost the tuning of the static parameters, our method employs both server and client metrics of distributed file systems to understand the relationship between static parameters and performance. Our empirical evaluation results show that Magpie can noticeably improve the performance of the distributed file system Lustre, where our approach on average achieves 91.8% throughput gains against default configuration after tuning towards single performance indicator optimization, while it reaches 39.7% more throughput gains against the baseline.
Real-Time Ground-Plane Refined LiDAR SLAM
Oct 21, 2021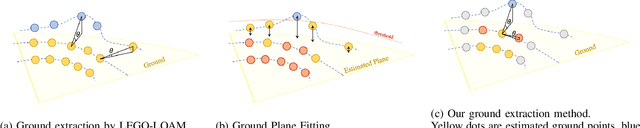

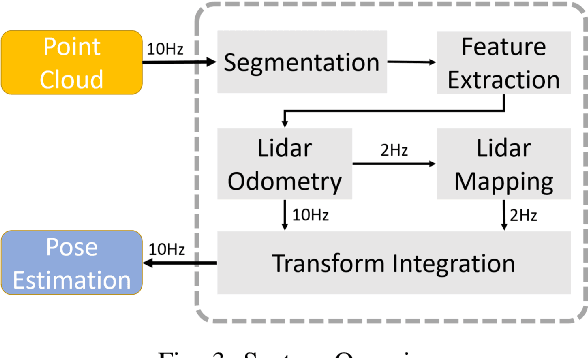
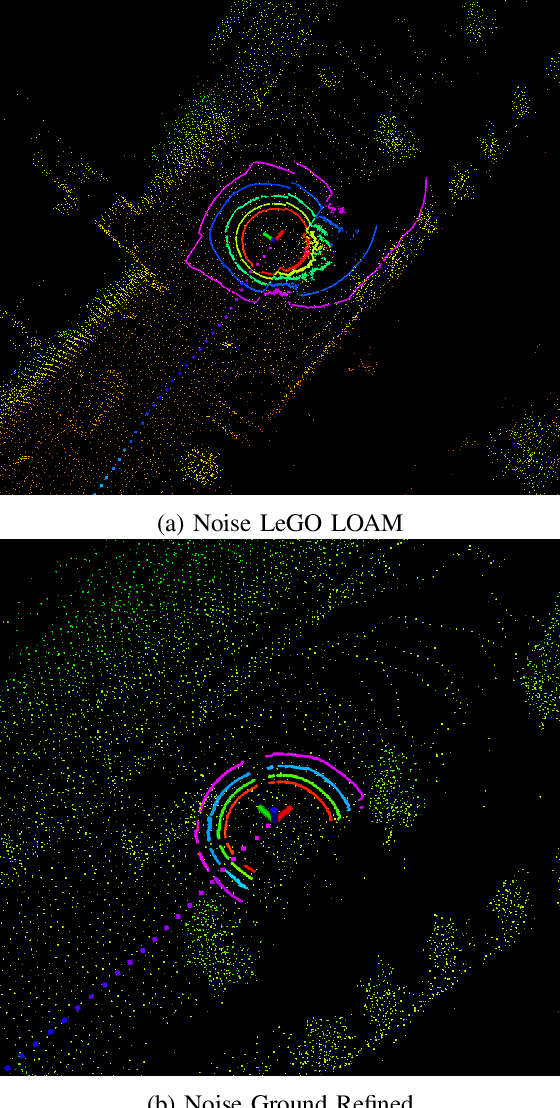
SLAM system using only point cloud has been proven successful in recent years. In most of these systems, they extract features for tracking after ground removal, which causes large variance on the z-axis. Ground actually provides robust information to obtain [t_z, \theta_{roll}, \theta_{pitch}]$. In this project, we followed the LeGO-LOAM, a light-weighted real-time SLAM system that extracts and registers ground as an addition to the original LOAM, and we proposed a new clustering-based method to refine the planar extraction algorithm for ground such that the system can handle much more noisy or dynamic environments. We implemented this method and compared it with LeGo-LOAM on our collected data of CMU campus, as well as a collected dataset for ATV (All-Terrain Vehicle) for off-road self-driving. Both visualization and evaluation results show obvious improvement of our algorithm.
Universality and diversity in word patterns
Aug 23, 2022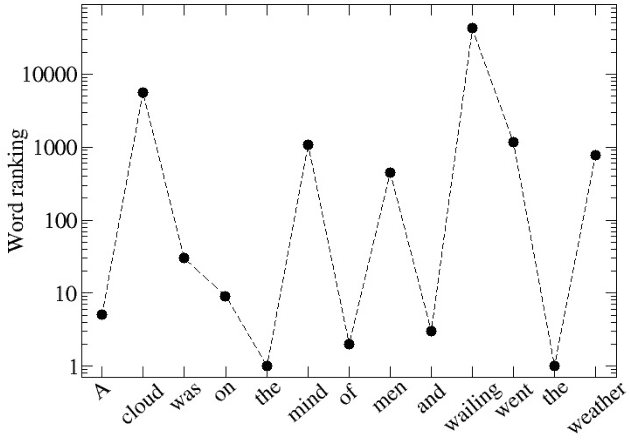
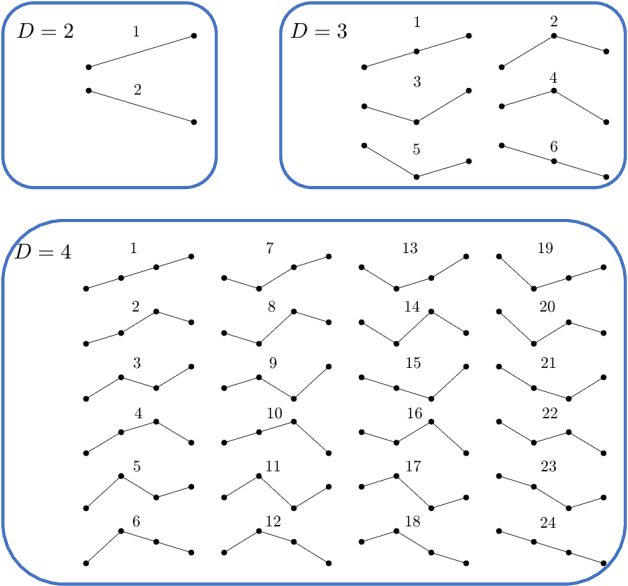
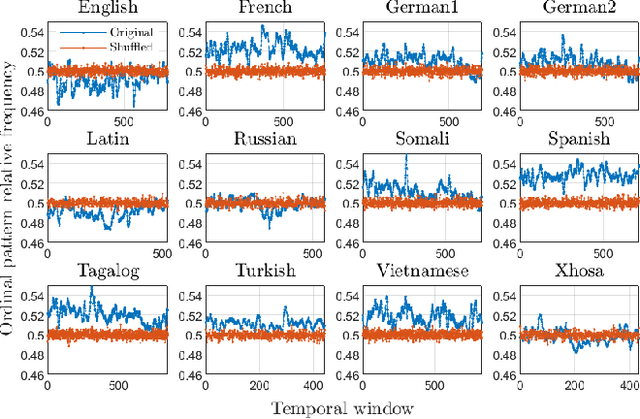
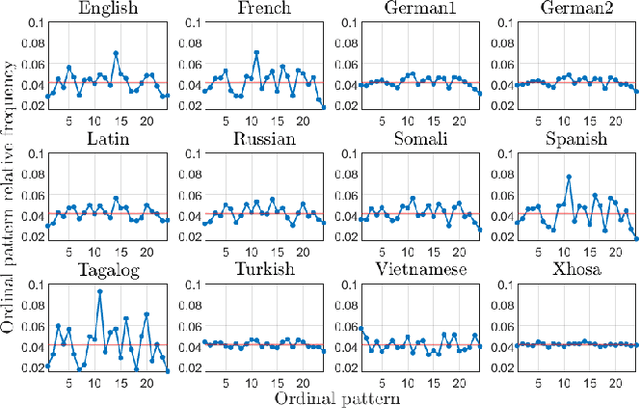
Words are fundamental linguistic units that connect thoughts and things through meaning. However, words do not appear independently in a text sequence. The existence of syntactic rules induce correlations among neighboring words. Further, words are not evenly distributed but approximately follow a power law since terms with a pure semantic content appear much less often than terms that specify grammar relations. Using an ordinal pattern approach, we present an analysis of lexical statistical connections for eleven major languages. We find that the diverse manners that languages utilize to express word relations give rise to unique pattern distributions. Remarkably, we find that these relations can be modeled with a Markov model of order 2 and that this result is universally valid for all the studied languages. Furthermore, fluctuations of the pattern distributions can allow us to determine the historical period when the text was written and its author. Taken together, these results emphasize the relevance of time series analysis and information-theoretic methods for the understanding of statistical correlations in natural languages.