 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ziv-Zakai Bound for DOAs Estimation
Sep 09, 2022
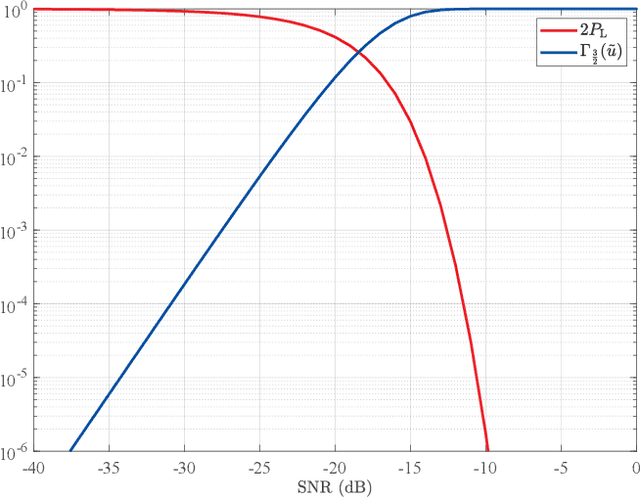
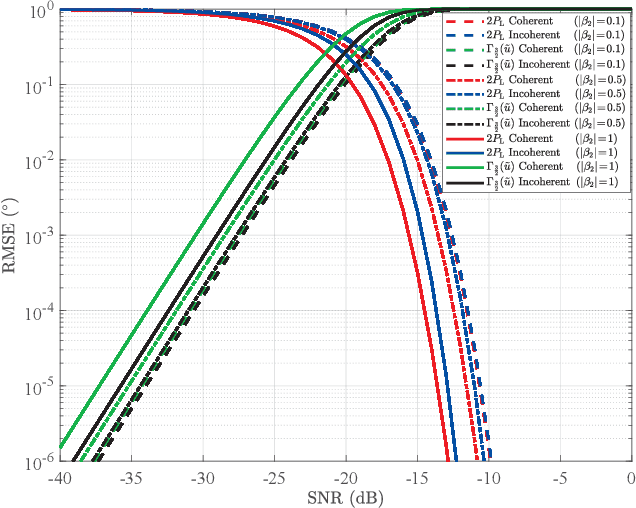
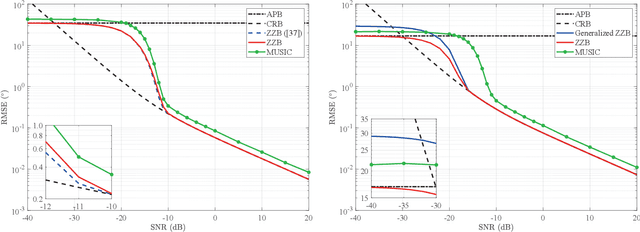
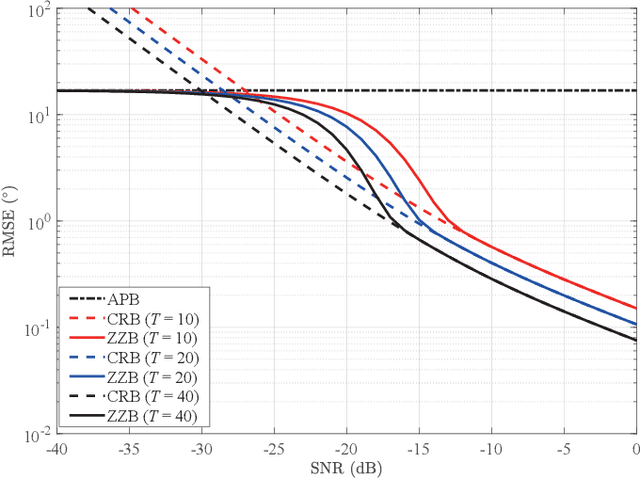
Lower bounds on the mean square error (MSE) play an important role in evaluating the estimation performance of nonlinear parameters including direction-of-arrival (DOA). Among numerous known bounds, the well-accepted Cramer-Rao bound (CRB) lower bounds the MSE in the asymptotic region only, due to its locality. By contrast, the less-adopted Ziv-Zakai bound (ZZB) is restricted by the single source assumption, although it is global tight. In this paper, we first derive an explicit ZZB applicable for hybrid coherent/incoherent multiple sources DOA estimation. In detail, we incorporate Woodbury matrix identity and Sylvester's determinant theorem to generalize the ZZB from single source DOA estimation to multiple sources DOA estimation, which, unfortunately, becomes invalid when it is far away from the asymptotic region. We then introduce the order statistics to describe the effect of ordering process during MSE calculation on the change of a priori distribution of DOAs, such that the derived ZZB can keep a tight bound on the MSE outside the asymptotic region. The derived ZZB is for the first time formulated as the function of the coherent coefficients between the coherent sources, and reveals the relationship between the MSE convergency in the a priori performance region and the number of sources. Moreover, the derived ZZB also provides a unified tight bound for both overdetermined DOAs estimation and underdetermined DOAs estimation. Simulation results demonstrate the obvious advantages of the derived ZZB over the CRB on evaluating and predicting the estimation performance of multiple sources DOA.
Toward Low-Cost End-to-End Spoken Language Understanding
Jul 01, 2022


Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies trying to reduce such cost while keeping competitive performance. At the same time we propose an extensive analysis where we measure the cost of our models in terms of training time and electric energy consumption, hopefully promoting a comprehensive evaluation procedure. The experiments are performed on the FSC and MEDIA corpora, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performance and using SSL models.
Adaptive Stochastic Gradient Descent for Fast and Communication-Efficient Distributed Learning
Aug 04, 2022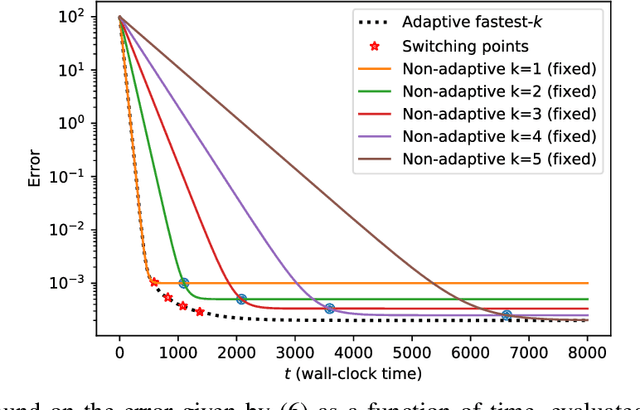
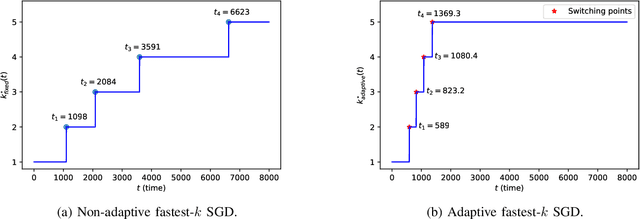
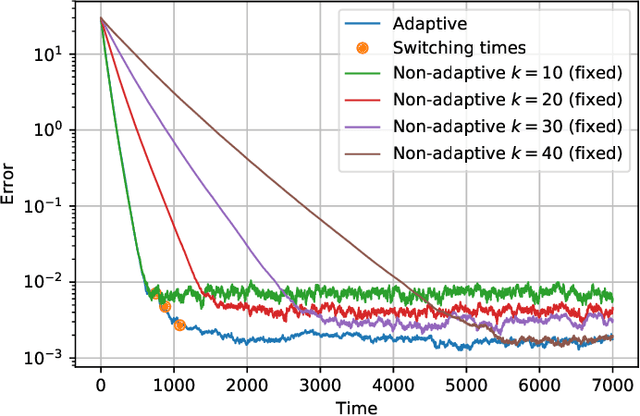
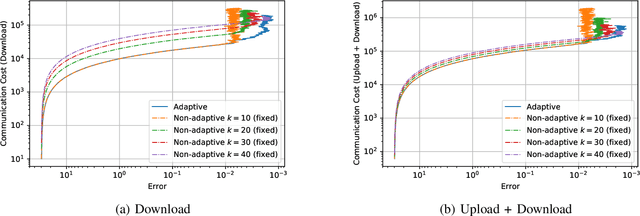
We consider the setting where a master wants to run a distributed stochastic gradient descent (SGD) algorithm on $n$ workers, each having a subset of the data. Distributed SGD may suffer from the effect of stragglers, i.e., slow or unresponsive workers who cause delays. One solution studied in the literature is to wait at each iteration for the responses of the fastest $k<n$ workers before updating the model, where $k$ is a fixed parameter. The choice of the value of $k$ presents a trade-off between the runtime (i.e., convergence rate) of SGD and the error of the model. Towards optimizing the error-runtime trade-off, we investigate distributed SGD with adaptive~$k$, i.e., varying $k$ throughout the runtime of the algorithm. We first design an adaptive policy for varying $k$ that optimizes this trade-off based on an upper bound on the error as a function of the wall-clock time that we derive. Then, we propose and implement an algorithm for adaptive distributed SGD that is based on a statistical heuristic. Our results show that the adaptive version of distributed SGD can reach lower error values in less time compared to non-adaptive implementations. Moreover, the results also show that the adaptive version is communication-efficient, where the amount of communication required between the master and the workers is less than that of non-adaptive versions.
Efficient Multi-view Clustering via Unified and Discrete Bipartite Graph Learning
Sep 09, 2022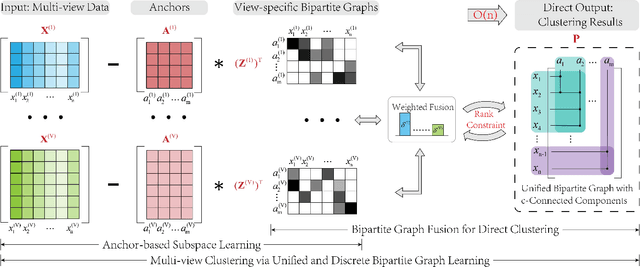
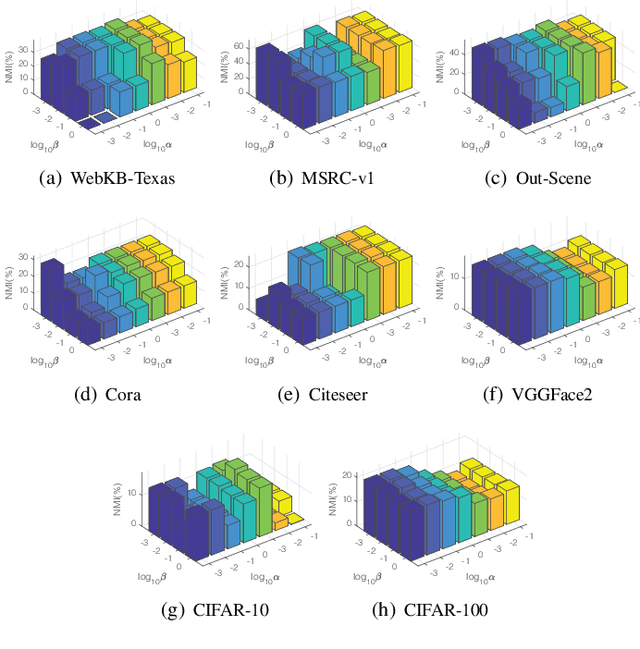
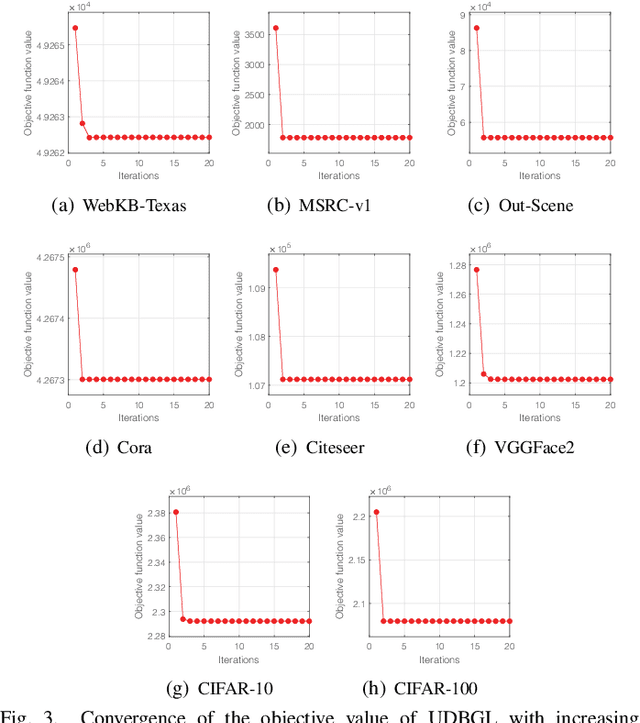
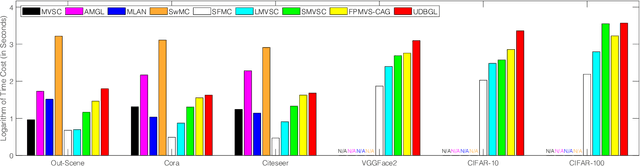
Although previous graph-based multi-view clustering algorithms have gained significant progress, most of them are still faced with three limitations. First, they often suffer from high computational complexity, which restricts their applications in large-scale scenarios. Second, they usually perform graph learning either at the single-view level or at the view-consensus level, but often neglect the possibility of the joint learning of single-view and consensus graphs. Third, many of them rely on the $k$-means for discretization of the spectral embeddings, which lack the ability to directly learn the graph with discrete cluster structure. In light of this, this paper presents an efficient multi-view clustering approach via unified and discrete bipartite graph learning (UDBGL). Specifically, the anchor-based subspace learning is incorporated to learn the view-specific bipartite graphs from multiple views, upon which the bipartite graph fusion is leveraged to learn a view-consensus bipartite graph with adaptive weight learning. Further, the Laplacian rank constraint is imposed to ensure that the fused bipartite graph has discrete cluster structures (with a specific number of connected components). By simultaneously formulating the view-specific bipartite graph learning, the view-consensus bipartite graph learning, and the discrete cluster structure learning into a unified objective function, an efficient minimization algorithm is then designed to tackle this optimization problem and directly achieve a discrete clustering solution without requiring additional partitioning, which notably has linear time complexity in data size. Experiments on a variety of multi-view datasets demonstrate the robustness and efficiency of our UDBGL approach.
Using Constant Learning Rate of Two Time-Scale Update Rule for Training Generative Adversarial Networks
Jan 28, 2022
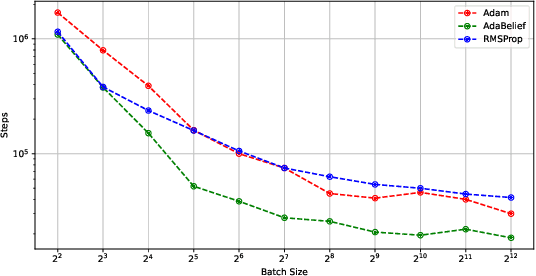
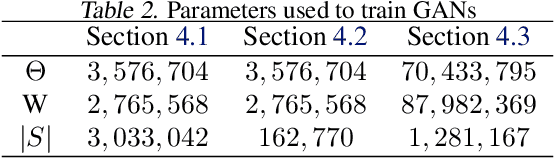
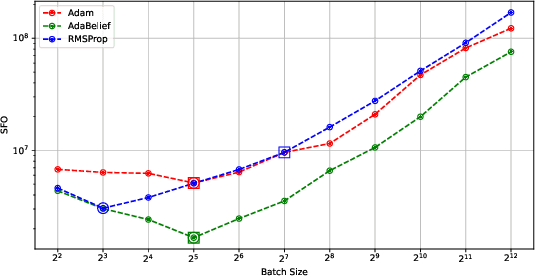
Previous numerical results have shown that a two time-scale update rule (TTUR) using constant learning rates is practically useful for training generative adversarial networks (GANs). Meanwhile, a theoretical analysis of TTUR to find a stationary local Nash equilibrium of a Nash equilibrium problem with two players, a discriminator and a generator, has been given using decaying learning rates. In this paper, we give a theoretical analysis of TTUR using constant learning rates to bridge the gap between theory and practice. In particular, we show that, for TTUR using constant learning rates, the number of steps needed to find a stationary local Nash equilibrium decreases as the batch size increases. We also provide numerical results to support our theoretical analyzes.
Interpretations Steered Network Pruning via Amortized Inferred Saliency Maps
Sep 07, 2022
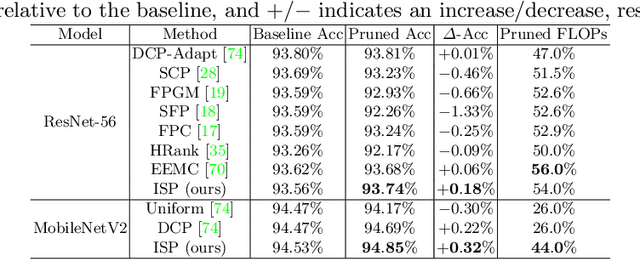
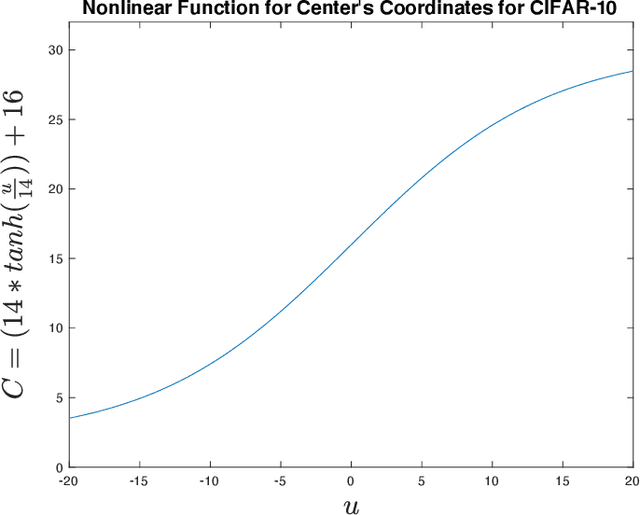
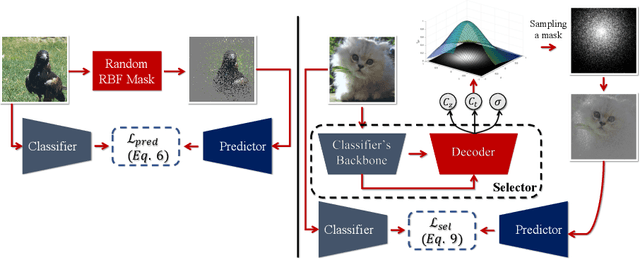
Convolutional Neural Networks (CNNs) compression is crucial to deploying these models in edge devices with limited resources. Existing channel pruning algorithms for CNNs have achieved plenty of success on complex models. They approach the pruning problem from various perspectives and use different metrics to guide the pruning process. However, these metrics mainly focus on the model's `outputs' or `weights' and neglect its `interpretations' information. To fill in this gap, we propose to address the channel pruning problem from a novel perspective by leveraging the interpretations of a model to steer the pruning process, thereby utilizing information from both inputs and outputs of the model. However, existing interpretation methods cannot get deployed to achieve our goal as either they are inefficient for pruning or may predict non-coherent explanations. We tackle this challenge by introducing a selector model that predicts real-time smooth saliency masks for pruned models. We parameterize the distribution of explanatory masks by Radial Basis Function (RBF)-like functions to incorporate geometric prior of natural images in our selector model's inductive bias. Thus, we can obtain compact representations of explanations to reduce the computational costs of our pruning method. We leverage our selector model to steer the network pruning by maximizing the similarity of explanatory representations for the pruned and original models. Extensive experiments on CIFAR-10 and ImageNet benchmark datasets demonstrate the efficacy of our proposed method. Our implementations are available at \url{https://github.com/Alii-Ganjj/InterpretationsSteeredPruning}
Deep Active Visual Attention for Real-time Robot Motion Generation: Emergence of Tool-body Assimilation and Adaptive Tool-use
Jun 29, 2022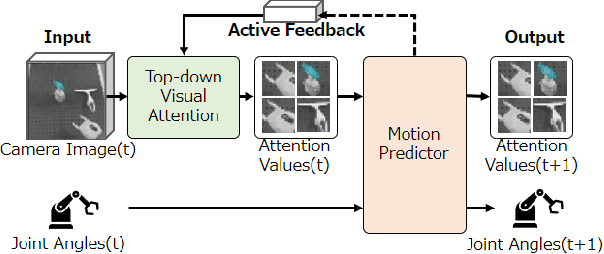

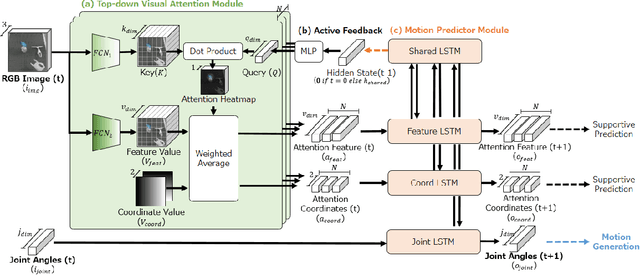
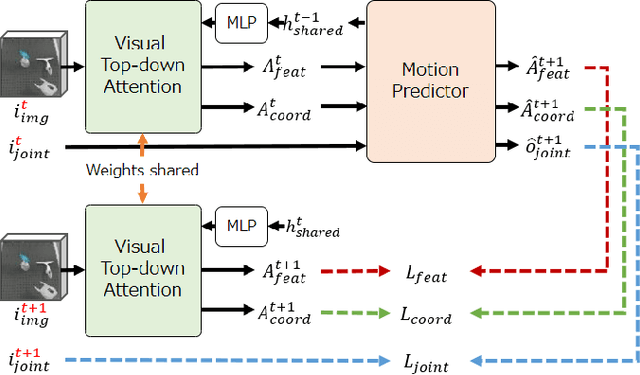
Sufficiently perceiving the environment is a critical factor in robot motion generation. Although the introduction of deep visual processing models have contributed in extending this ability, existing methods lack in the ability to actively modify what to perceive; humans perform internally during visual cognitive processes. This paper addresses the issue by proposing a novel robot motion generation model, inspired by a human cognitive structure. The model incorporates a state-driven active top-down visual attention module, which acquires attentions that can actively change targets based on task states. We term such attentions as role-based attentions, since the acquired attention directed to targets that shared a coherent role throughout the motion. The model was trained on a robot tool-use task, in which the role-based attentions perceived the robot grippers and tool as identical end-effectors, during object picking and object dragging motions respectively. This is analogous to a biological phenomenon called tool-body assimilation, in which one regards a handled tool as an extension of one's body. The results suggested an improvement of flexibility in model's visual perception, which sustained stable attention and motion even if it was provided with untrained tools or exposed to experimenter's distractions.
Rating the Crisis of Online Public Opinion Using a Multi-Level Index System
Jul 29, 2022



Online public opinion usually spreads rapidly and widely, thus a small incident probably evolves into a large social crisis in a very short time, and results in a heavy loss in credit or economic aspects. We propose a method to rate the crisis of online public opinion based on a multi-level index system to evaluate the impact of events objectively. Firstly, the dissemination mechanism of online public opinion is explained from the perspective of information ecology. According to the mechanism, some evaluation indexes are selected through correlation analysis and principal component analysis. Then, a classification model of text emotion is created via the training by deep learning to achieve the accurate quantification of the emotional indexes in the index system. Finally, based on the multi-level evaluation index system and grey correlation analysis, we propose a method to rate the crisis of online public opinion. The experiment with the real-time incident show that this method can objectively evaluate the emotional tendency of Internet users and rate the crisis in different dissemination stages of online public opinion. It is helpful to realizing the crisis warning of online public opinion and timely blocking the further spread of the crisis.
On the Convergence of Monte Carlo UCB for Random-Length Episodic MDPs
Sep 07, 2022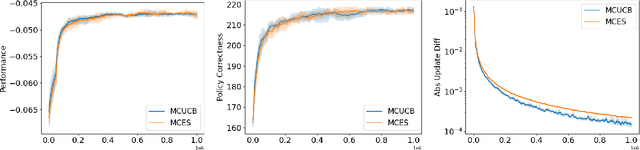
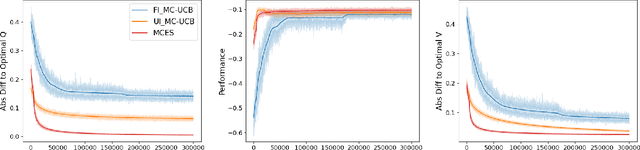
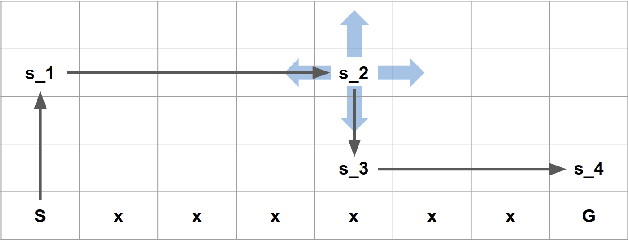
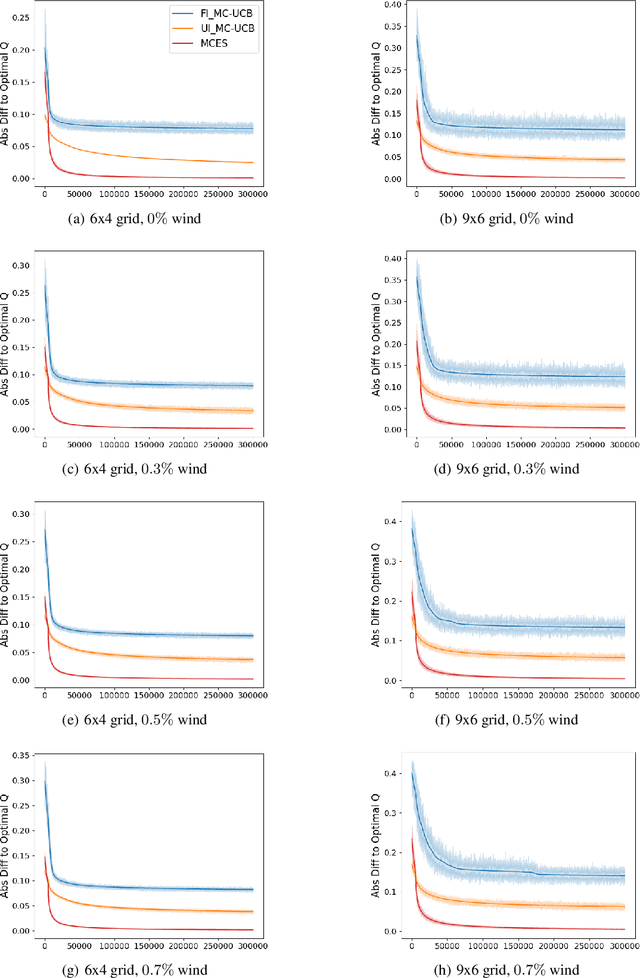
In reinforcement learning, Monte Carlo algorithms update the Q function by averaging the episodic returns. In the Monte Carlo UCB (MC-UCB) algorithm, the action taken in each state is the action that maximizes the Q function plus a UCB exploration term, which biases the choice of actions to those that have been chosen less frequently. Although there has been significant work on establishing regret bounds for MC-UCB, most of that work has been focused on finite-horizon versions of the problem, for which each episode terminates after a constant number of steps. For such finite-horizon problems, the optimal policy depends both on the current state and the time within the episode. However, for many natural episodic problems, such as games like Go and Chess and robotic tasks, the episode is of random length and the optimal policy is stationary. For such environments, it is an open question whether the Q-function in MC-UCB will converge to the optimal Q function; we conjecture that, unlike Q-learning, it does not converge for all MDPs. We nevertheless show that for a large class of MDPs, which includes stochastic MDPs such as blackjack and deterministic MDPs such as Go, the Q-function in MC-UCB converges almost surely to the optimal Q function. An immediate corollary of this result is that it also converges almost surely for all finite-horizon MDPs. We also provide numerical experiments, providing further insights into MC-UCB.
Reduced Optimal Power Flow Using Graph Neural Network
Jun 27, 2022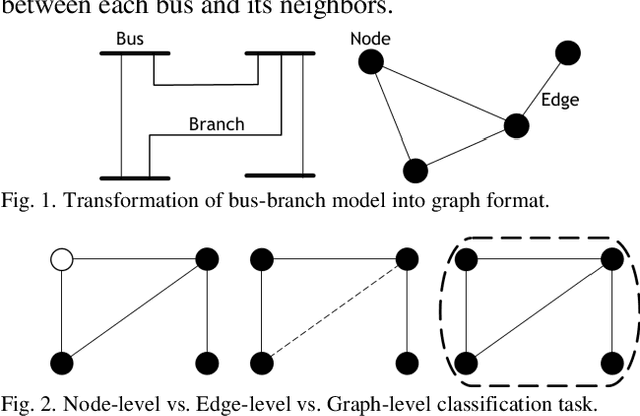
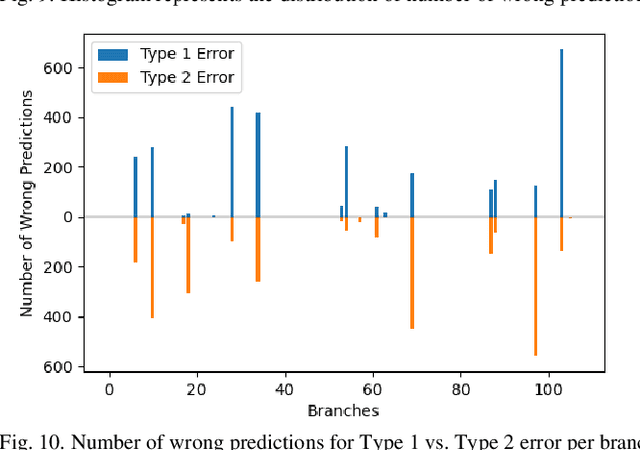
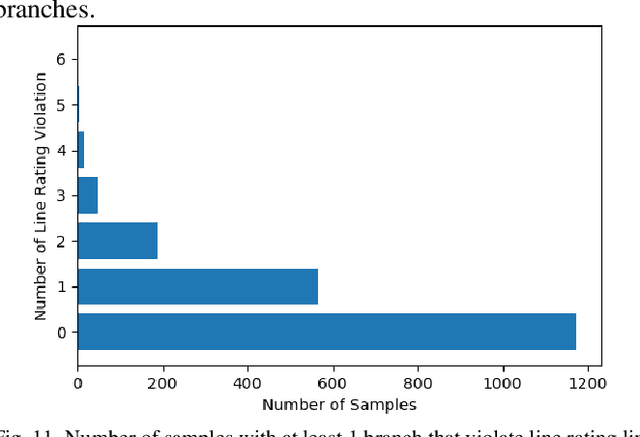
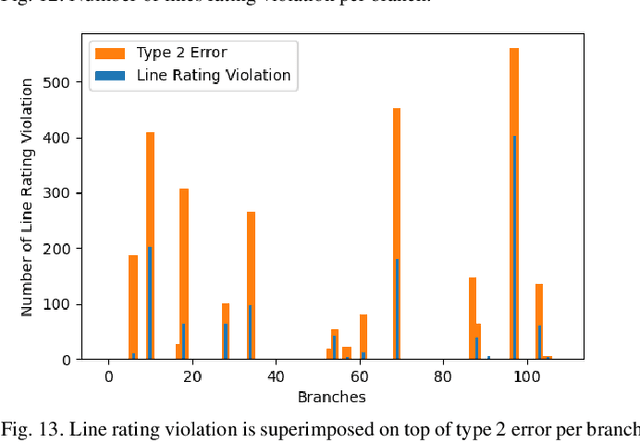
OPF problems are formulated and solved for power system operations, especially for determining generation dispatch points in real-time. For large and complex power system networks with large numbers of variables and constraints, finding the optimal solution for real-time OPF in a timely manner requires a massive amount of computing power. This paper presents a new method to reduce the number of constraints in the original OPF problem using a graph neural network (GNN). GNN is an innovative machine learning model that utilizes features from nodes, edges, and network topology to maximize its performance. In this paper, we proposed a GNN model to predict which lines would be heavily loaded or congested with given load profiles and generation capacities. Only these critical lines will be monitored in an OPF problem, creating a reduced OPF (ROPF) problem. Significant saving in computing time is expected from the proposed ROPF model. A comprehensive analysis of predictions from the GNN model was also made. It is concluded that the application of GNN for ROPF is able to reduce computing time while retaining solution quality.