 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Context Information for Generic Event Boundary Captioning
Jul 03, 2022
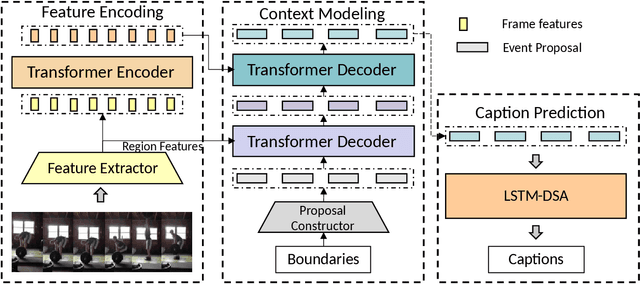
Generic Event Boundary Captioning (GEBC) aims to generate three sentences describing the status change for a given time boundary. Previous methods only process the information of a single boundary at a time, which lacks utilization of video context information. To tackle this issue, we design a model that directly takes the whole video as input and generates captions for all boundaries parallelly. The model could learn the context information for each time boundary by modeling the boundary-boundary interactions. Experiments demonstrate the effectiveness of context information. The proposed method achieved a 72.84 score on the test set, and we reached the $2^{nd}$ place in this challenge. Our code is available at: \url{https://github.com/zjr2000/Context-GEBC}
Rapid Lung Ultrasound COVID-19 Severity Scoring with Resource-Efficient Deep Feature Extraction
Jul 22, 2022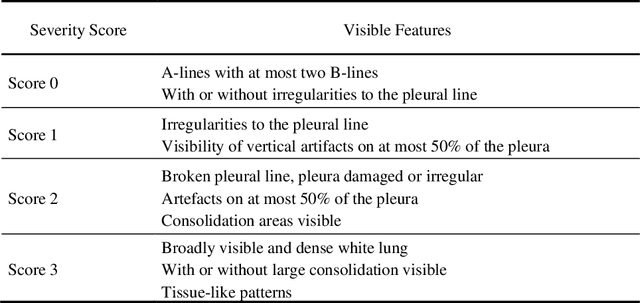
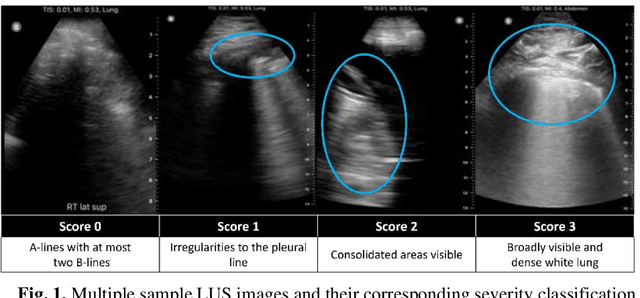
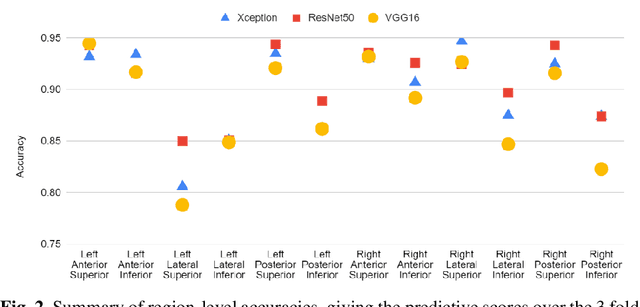
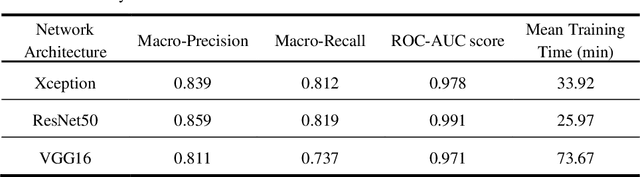
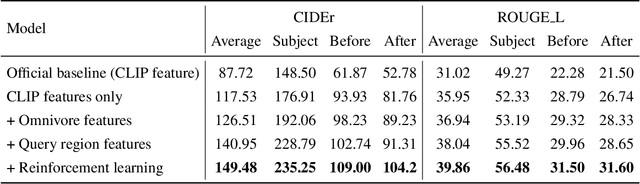
Artificial intelligence-based analysis of lung ultrasound imaging has been demonstrated as an effective technique for rapid diagnostic decision support throughout the COVID-19 pandemic. However, such techniques can require days- or weeks-long training processes and hyper-parameter tuning to develop intelligent deep learning image analysis models. This work focuses on leveraging 'off-the-shelf' pre-trained models as deep feature extractors for scoring disease severity with minimal training time. We propose using pre-trained initializations of existing methods ahead of simple and compact neural networks to reduce reliance on computational capacity. This reduction of computational capacity is of critical importance in time-limited or resource-constrained circumstances, such as the early stages of a pandemic. On a dataset of 49 patients, comprising over 20,000 images, we demonstrate that the use of existing methods as feature extractors results in the effective classification of COVID-19-related pneumonia severity while requiring only minutes of training time. Our methods can achieve an accuracy of over 0.93 on a 4-level severity score scale and provides comparable per-patient region and global scores compared to expert annotated ground truths. These results demonstrate the capability for rapid deployment and use of such minimally-adapted methods for progress monitoring, patient stratification and management in clinical practice for COVID-19 patients, and potentially in other respiratory diseases.
Learning Dynamic Manipulation Skills from Haptic-Play
Jul 28, 2022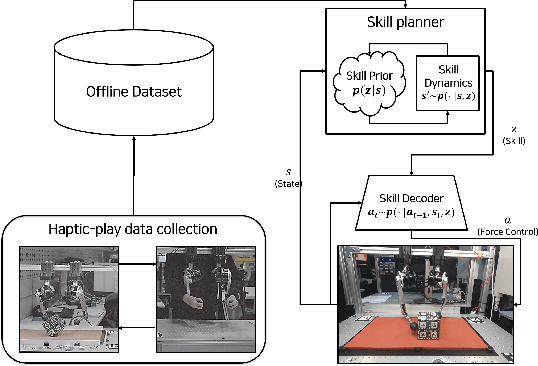

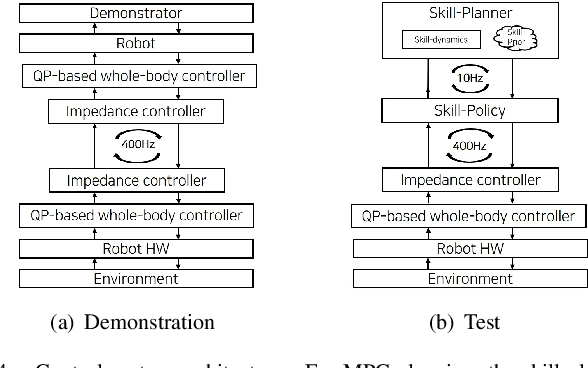
In this paper, we propose a data-driven skill learning approach to solve highly dynamic manipulation tasks entirely from offline teleoperated play data. We use a bilateral teleoperation system to continuously collect a large set of dexterous and agile manipulation behaviors, which is enabled by providing direct force feedback to the operator. We jointly learn the state conditional latent skill distribution and skill decoder network in the form of goal-conditioned policy and skill conditional state transition dynamics using a two-stage generative modeling framework. This allows one to perform robust model-based planning, both online and offline planning methods, in the learned skill-space to accomplish any given downstream tasks at test time. We provide both simulated and real-world dual-arm box manipulation experiments showing that a sequence of force-controlled dynamic manipulation skills can be composed in real-time to successfully configure the box to the randomly selected target position and orientation; please refer to the supplementary video, https://youtu.be/LA5B236ILzM.
Memristive Computing for Efficient Inference on Resource Constrained Devices
Aug 21, 2022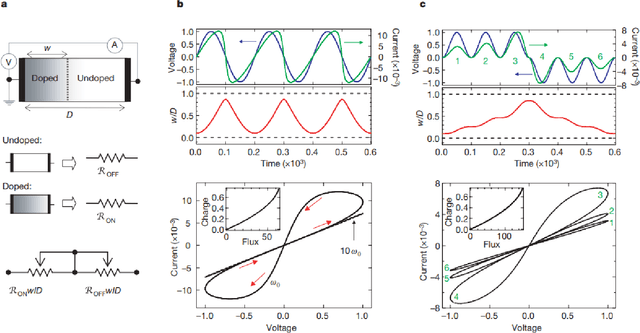
The advent of deep learning has resulted in a number of applications which have transformed the landscape of the research area in which it has been applied. However, with an increase in popularity, the complexity of classical deep neural networks has increased over the years. As a result, this has leads to considerable problems during deployment on devices with space and time constraints. In this work, we perform a review of the present advancements in non-volatile memory and how the use of resistive RAM memory, particularly memristors, can help to progress the state of research in deep learning. In other words, we wish to present an ideology that advances in the field of memristive technology can greatly influence and impact deep learning inference on edge devices.
Graph-PHPA: Graph-based Proactive Horizontal Pod Autoscaling for Microservices using LSTM-GNN
Sep 06, 2022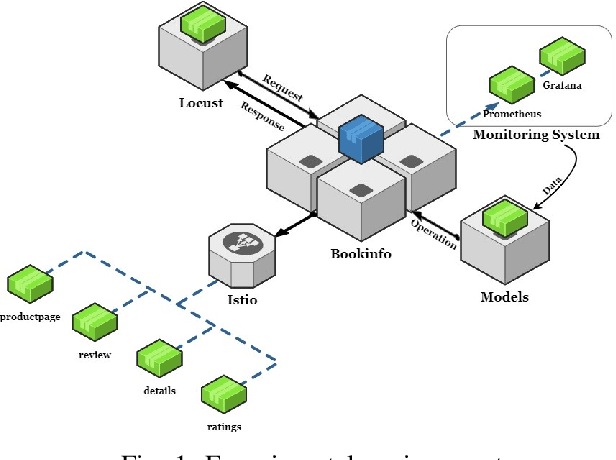
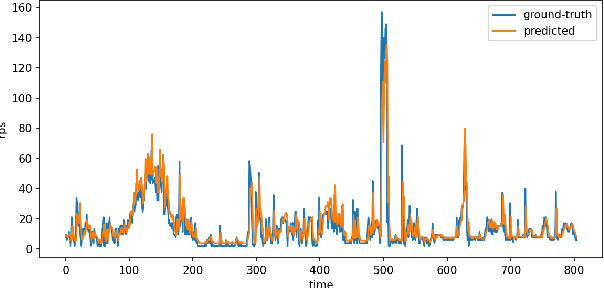
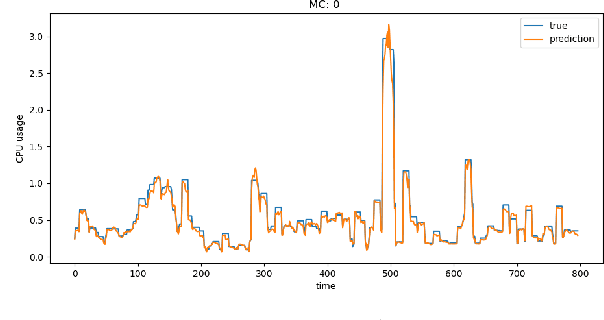
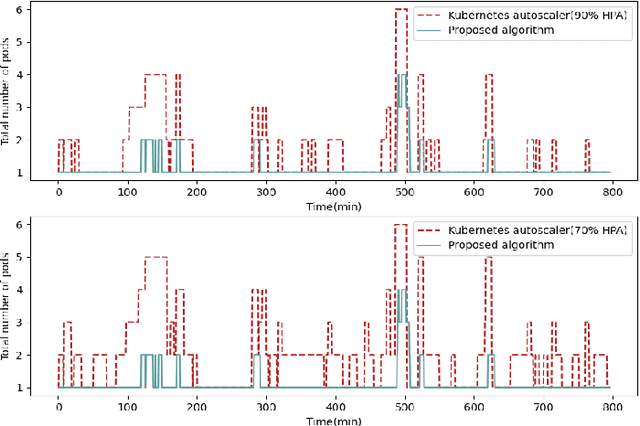
Microservice-based architecture has become prevalent for cloud-native applications. With an increasing number of applications being deployed on cloud platforms every day leveraging this architecture, more research efforts are required to understand how different strategies can be applied to effectively manage various cloud resources at scale. A large body of research has deployed automatic resource allocation algorithms using reactive and proactive autoscaling policies. However, there is still a gap in the efficiency of current algorithms in capturing the important features of microservices from their architecture and deployment environment, for example, lack of consideration of graphical dependency. To address this challenge, we propose Graph-PHPA, a graph-based proactive horizontal pod autoscaling strategy for allocating cloud resources to microservices leveraging long short-term memory (LSTM) and graph neural network (GNN) based prediction methods. We evaluate the performance of Graph-PHPA using the Bookinfo microservices deployed in a dedicated testing environment with real-time workloads generated based on realistic datasets. We demonstrate the efficacy of Graph-PHPA by comparing it with the rule-based resource allocation scheme in Kubernetes as our baseline. Extensive experiments have been implemented and our results illustrate the superiority of our proposed approach in resource savings over the reactive rule-based baseline algorithm in different testing scenarios.
Riemannian Diffusion Models
Aug 16, 2022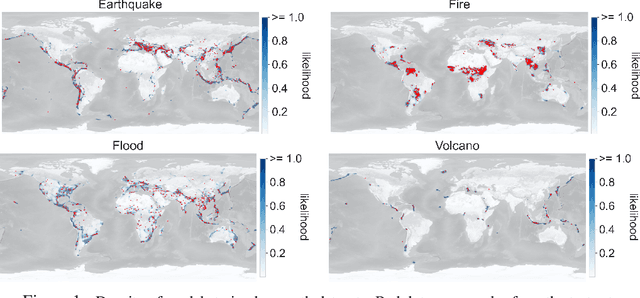
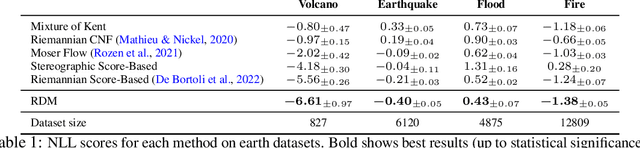

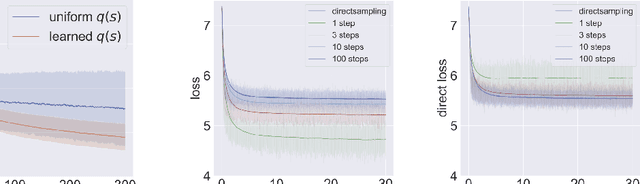
Diffusion models are recent state-of-the-art methods for image generation and likelihood estimation. In this work, we generalize continuous-time diffusion models to arbitrary Riemannian manifolds and derive a variational framework for likelihood estimation. Computationally, we propose new methods for computing the Riemannian divergence which is needed in the likelihood estimation. Moreover, in generalizing the Euclidean case, we prove that maximizing this variational lower-bound is equivalent to Riemannian score matching. Empirically, we demonstrate the expressive power of Riemannian diffusion models on a wide spectrum of smooth manifolds, such as spheres, tori, hyperboloids, and orthogonal groups. Our proposed method achieves new state-of-the-art likelihoods on all benchmarks.
HistoPerm: A Permutation-Based View Generation Approach for Learning Histopathologic Feature Representations
Sep 13, 2022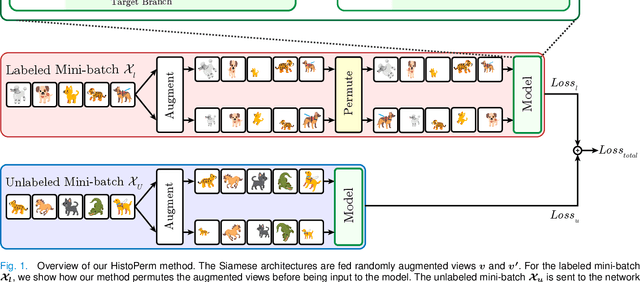
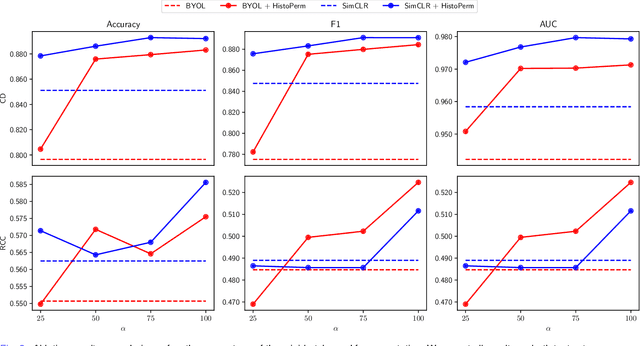
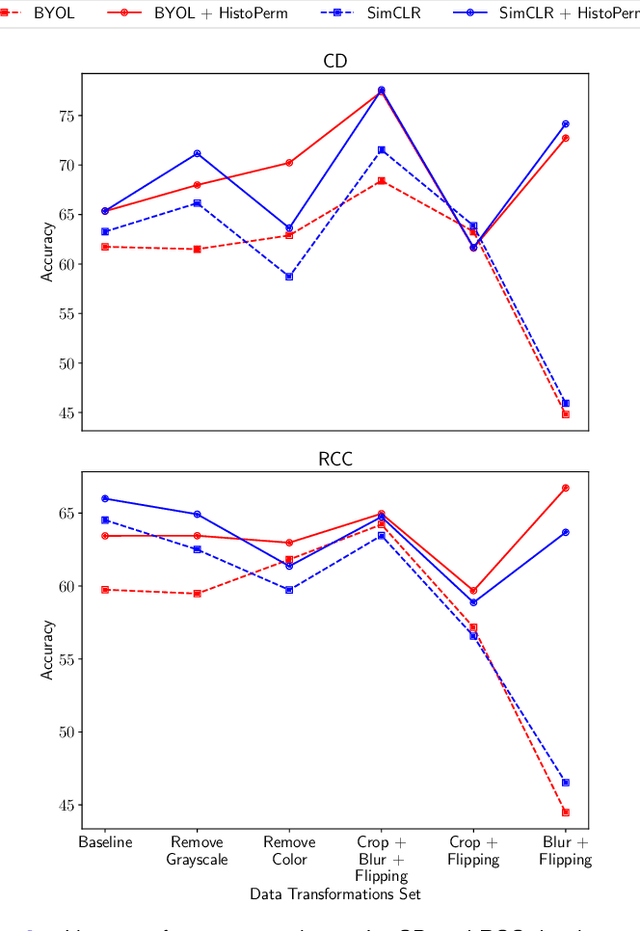
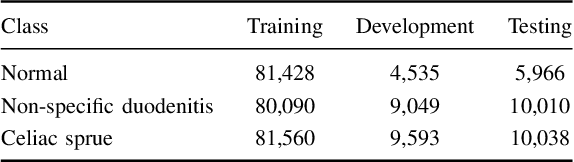
Recently, deep learning methods have been successfully applied to solve numerous challenges in the field of digital pathology. However, many of these approaches are fully supervised and require annotated images. Annotating a histology image is a time-consuming and tedious process for even a highly skilled pathologist, and, as such, most histology datasets lack region-of-interest annotations and are weakly labeled. In this paper, we introduce HistoPerm, a view generation approach designed for improving the performance of representation learning techniques on histology images in weakly supervised settings. In HistoPerm, we permute augmented views of patches generated from whole-slide histology images to improve classification accuracy. These permuted views belong to the same original slide-level class but are produced from distinct patch instances. We tested adding HistoPerm to BYOL and SimCLR, two prominent representation learning methods, on two public histology datasets for Celiac disease and Renal Cell Carcinoma. For both datasets, we found improved performance in terms of accuracy, F1-score, and AUC compared to the standard BYOL and SimCLR approaches. Particularly, in a linear evaluation configuration, HistoPerm increases classification accuracy on the Celiac disease dataset by 8% for BYOL and 3% for SimCLR. Similarly, with HistoPerm, classification accuracy increases by 2% for BYOL and 0.25% for SimCLR on the Renal Cell Carcinoma dataset. The proposed permutation-based view generation approach can be adopted in common representation learning frameworks to capture histopathology features in weakly supervised settings and can lead to whole-slide classification outcomes that are close to, or even better than, fully supervised methods.
TAFA: Design Automation of Analog Mixed-Signal FIR Filters Using Time Approximation Architecture
Dec 15, 2021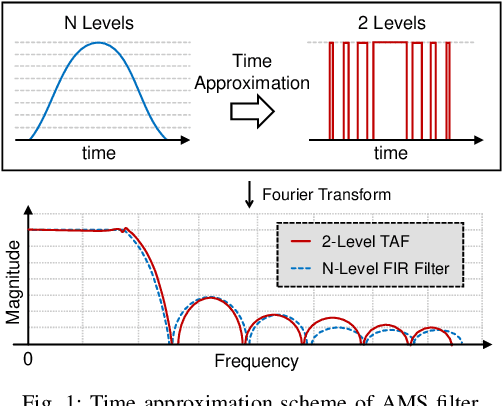
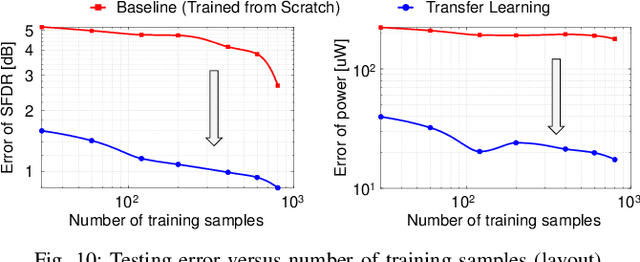
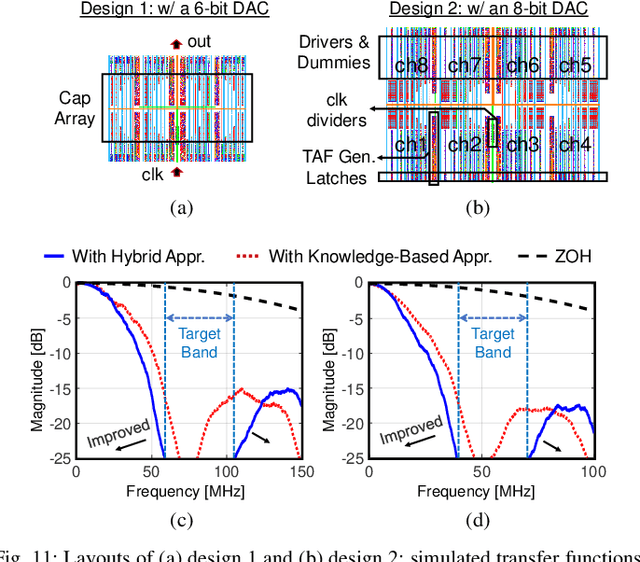
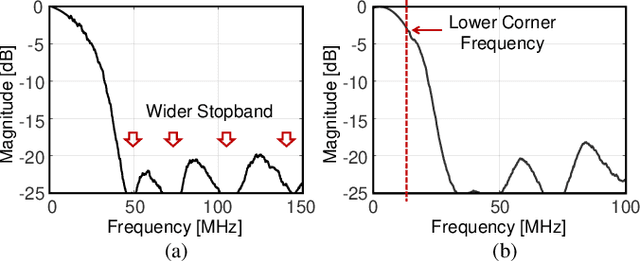
A digital finite impulse response (FIR) filter design is fully synthesizable, thanks to the mature CAD support of digital circuitry. On the contrary, analog mixed-signal (AMS) filter design is mostly a manual process, including architecture selection, schematic design, and layout. This work presents a systematic design methodology to automate AMS FIR filter design using a time approximation architecture without any tunable passive component, such as switched capacitor or resistor. It not only enhances the flexibility of the filter but also facilitates design automation with reduced analog complexity. The proposed design flow features a hybrid approximation scheme that automatically optimize the filter's impulse response in light of time quantization effects, which shows significant performance improvement with minimum designer's efforts in the loop. Additionally, a layout-aware regression model based on an artificial neural network (ANN), in combination with gradient-based search algorithm, is used to automate and expedite the filter design. With the proposed framework, we demonstrate rapid synthesis of AMS FIR filters in 65nm process from specification to layout.
FastCPH: Efficient Survival Analysis for Neural Networks
Aug 21, 2022
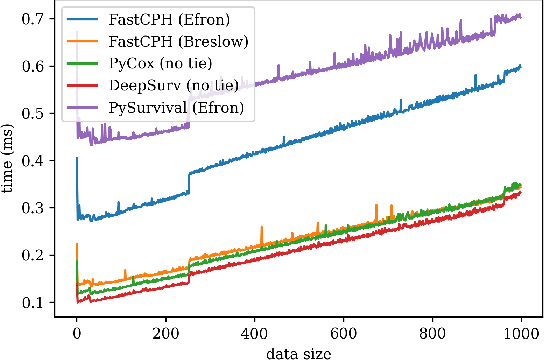
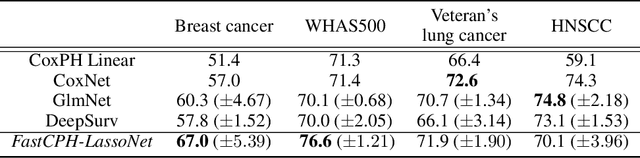
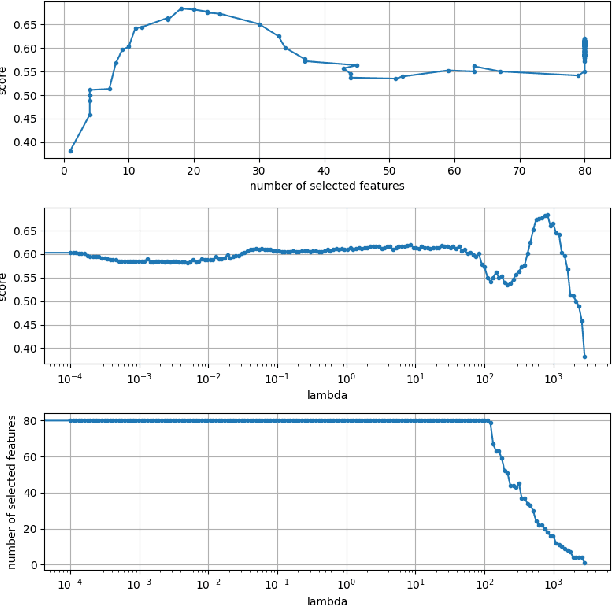
The Cox proportional hazards model is a canonical method in survival analysis for prediction of the life expectancy of a patient given clinical or genetic covariates -- it is a linear model in its original form. In recent years, several methods have been proposed to generalize the Cox model to neural networks, but none of these are both numerically correct and computationally efficient. We propose FastCPH, a new method that runs in linear time and supports both the standard Breslow and Efron methods for tied events. We also demonstrate the performance of FastCPH combined with LassoNet, a neural network that provides interpretability through feature sparsity, on survival datasets. The final procedure is efficient, selects useful covariates and outperforms existing CoxPH approaches.
An Experimental Study on Learning Correlated Equilibrium in Routing Games
Jul 31, 2022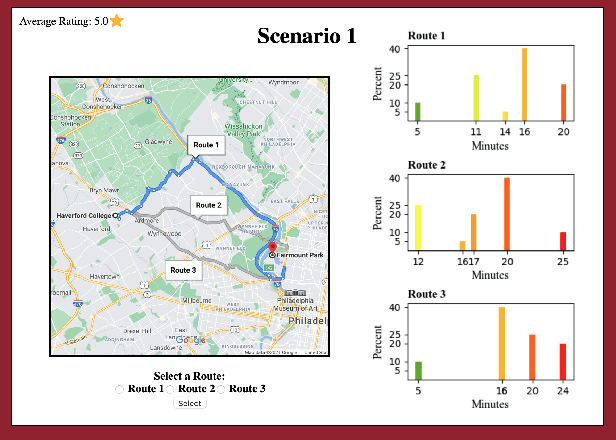
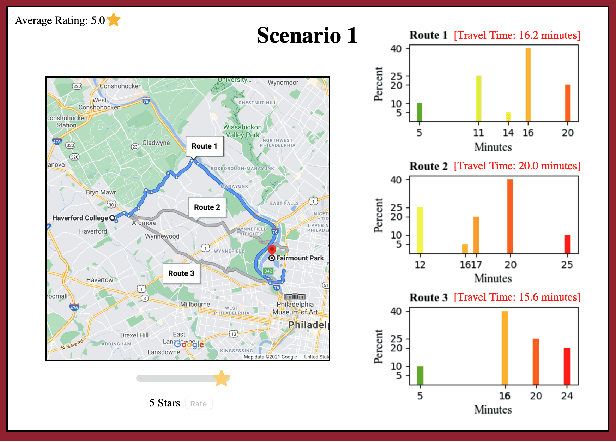
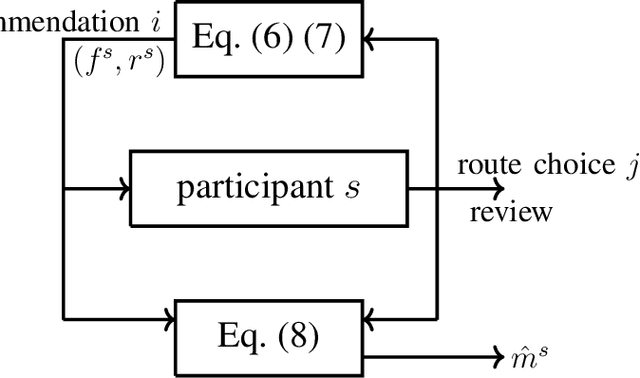
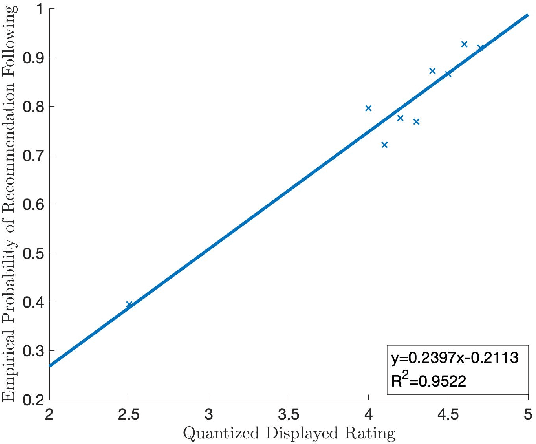
We study route choice in a repeated routing game where an uncertain state of nature determines link latency functions, and agents receive private route recommendation. The state is sampled in an i.i.d. manner in every round from a publicly known distribution, and the recommendations are generated by a randomization policy whose mapping from the state is known publicly. In a one-shot setting, the agents are said to obey recommendation if it gives the smallest travel time in a posteriori expectation. A plausible extension to repeated setting is that the likelihood of following recommendation in a round is related to regret from previous rounds. If the regret is of satisficing type with respect to a default choice and is averaged over past rounds and over all agents, then the asymptotic outcome under an obedient recommendation policy coincides with the one-shot outcome. We report findings from an experiment with one participant at a time engaged in repeated route choice decision on computer. In every round, the participant is shown travel time distribution for each route, a route recommendation generated by an obedient policy, and a rating suggestive of average experience of previous participants with the quality of recommendation. Upon entering route choice, the actual travel times are revealed. The participant evaluates the quality of recommendation by submitting a review. This is combined with historical reviews to update rating for the next round. Data analysis from 33 participants each with 100 rounds suggests moderate negative correlation between the display rating and the average regret, and a strong positive correlation between the rating and the likelihood of following recommendation. Overall, under obedient recommendation policy, the rating converges close to its maximum value by the end of the experiments in conjunction with very high frequency of following recommendations.