 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Degradation Modeling and Prognostic Analysis Under Unknown Failure Modes
Feb 29, 2024
Operating units often experience various failure modes in complex systems, leading to distinct degradation paths. Relying on a prognostic model trained on a single failure mode may lead to poor generalization performance across multiple failure modes. Therefore, accurately identifying the failure mode is of critical importance. Current prognostic approaches either ignore failure modes during degradation or assume known failure mode labels, which can be challenging to acquire in practice. Moreover, the high dimensionality and complex relations of sensor signals make it challenging to identify the failure modes accurately. To address these issues, we propose a novel failure mode diagnosis method that leverages a dimension reduction technique called UMAP (Uniform Manifold Approximation and Projection) to project and visualize each unit's degradation trajectory into a lower dimension. Then, using these degradation trajectories, we develop a time series-based clustering method to identify the training units' failure modes. Finally, we introduce a monotonically constrained prognostic model to predict the failure mode labels and RUL of the test units simultaneously using the obtained failure modes of the training units. The proposed prognostic model provides failure mode-specific RUL predictions while preserving the monotonic property of the RUL predictions across consecutive time steps. We evaluate the proposed model using a case study with the aircraft gas turbine engine dataset.
Causal Graph ODE: Continuous Treatment Effect Modeling in Multi-agent Dynamical Systems
Feb 29, 2024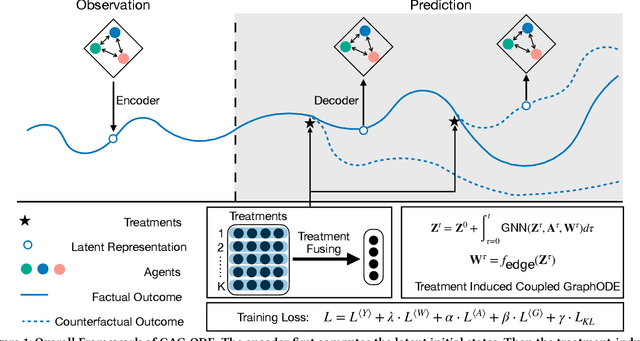
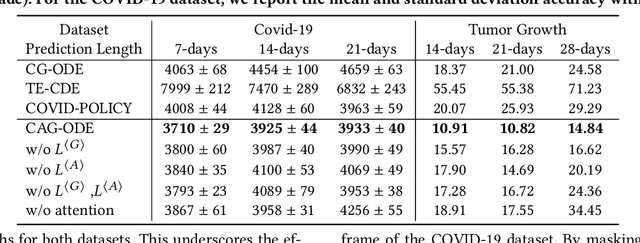
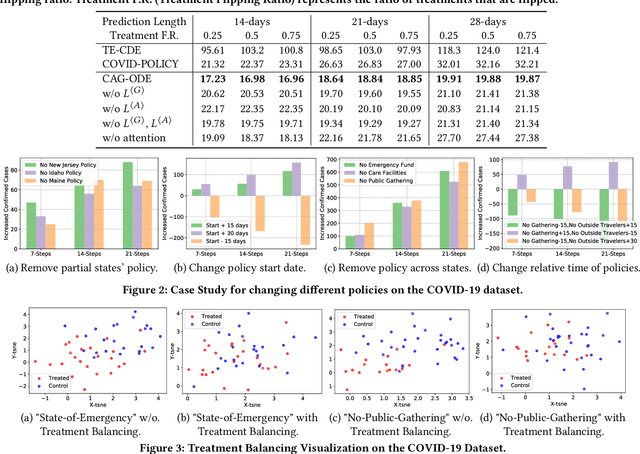

Real-world multi-agent systems are often dynamic and continuous, where the agents co-evolve and undergo changes in their trajectories and interactions over time. For example, the COVID-19 transmission in the U.S. can be viewed as a multi-agent system, where states act as agents and daily population movements between them are interactions. Estimating the counterfactual outcomes in such systems enables accurate future predictions and effective decision-making, such as formulating COVID-19 policies. However, existing methods fail to model the continuous dynamic effects of treatments on the outcome, especially when multiple treatments (e.g., "stay-at-home" and "get-vaccine" policies) are applied simultaneously. To tackle this challenge, we propose Causal Graph Ordinary Differential Equations (CAG-ODE), a novel model that captures the continuous interaction among agents using a Graph Neural Network (GNN) as the ODE function. The key innovation of our model is to learn time-dependent representations of treatments and incorporate them into the ODE function, enabling precise predictions of potential outcomes. To mitigate confounding bias, we further propose two domain adversarial learning-based objectives, which enable our model to learn balanced continuous representations that are not affected by treatments or interference. Experiments on two datasets (i.e., COVID-19 and tumor growth) demonstrate the superior performance of our proposed model.
Transformers for Supervised Online Continual Learning
Mar 03, 2024
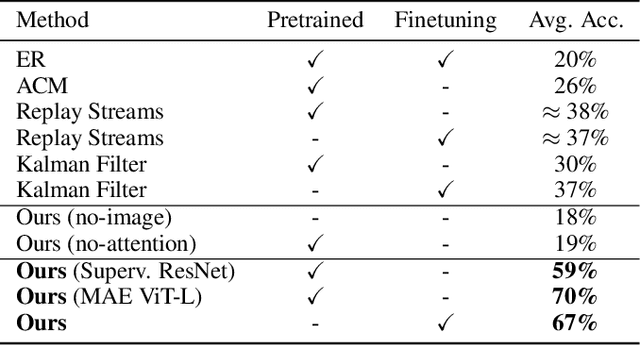
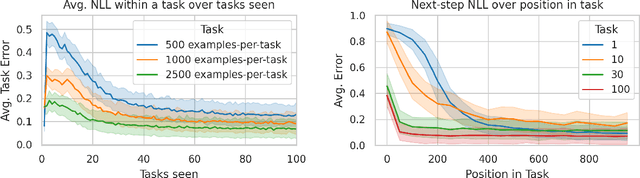
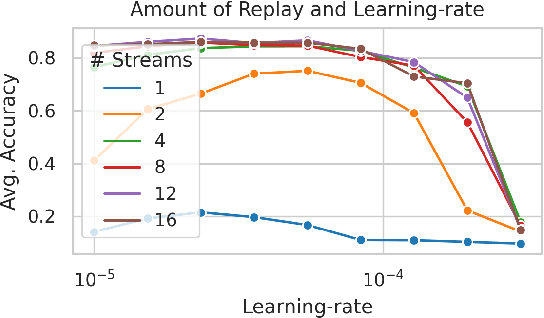
Transformers have become the dominant architecture for sequence modeling tasks such as natural language processing or audio processing, and they are now even considered for tasks that are not naturally sequential such as image classification. Their ability to attend to and to process a set of tokens as context enables them to develop in-context few-shot learning abilities. However, their potential for online continual learning remains relatively unexplored. In online continual learning, a model must adapt to a non-stationary stream of data, minimizing the cumulative nextstep prediction loss. We focus on the supervised online continual learning setting, where we learn a predictor $x_t \rightarrow y_t$ for a sequence of examples $(x_t, y_t)$. Inspired by the in-context learning capabilities of transformers and their connection to meta-learning, we propose a method that leverages these strengths for online continual learning. Our approach explicitly conditions a transformer on recent observations, while at the same time online training it with stochastic gradient descent, following the procedure introduced with Transformer-XL. We incorporate replay to maintain the benefits of multi-epoch training while adhering to the sequential protocol. We hypothesize that this combination enables fast adaptation through in-context learning and sustained longterm improvement via parametric learning. Our method demonstrates significant improvements over previous state-of-the-art results on CLOC, a challenging large-scale real-world benchmark for image geo-localization.
Image-based Deep Learning for the time-dependent prediction of fresh concrete properties
Feb 09, 2024Increasing the degree of digitisation and automation in the concrete production process can play a crucial role in reducing the CO$_2$ emissions that are associated with the production of concrete. In this paper, a method is presented that makes it possible to predict the properties of fresh concrete during the mixing process based on stereoscopic image sequences of the concretes flow behaviour. A Convolutional Neural Network (CNN) is used for the prediction, which receives the images supported by information on the mix design as input. In addition, the network receives temporal information in the form of the time difference between the time at which the images are taken and the time at which the reference values of the concretes are carried out. With this temporal information, the network implicitly learns the time-dependent behaviour of the concretes properties. The network predicts the slump flow diameter, the yield stress and the plastic viscosity. The time-dependent prediction potentially opens up the pathway to determine the temporal development of the fresh concrete properties already during mixing. This provides a huge advantage for the concrete industry. As a result, countermeasures can be taken in a timely manner. It is shown that an approach based on depth and optical flow images, supported by information of the mix design, achieves the best results.
POBEVM: Real-time Video Matting via Progressively Optimize the Target Body and Edge
Feb 15, 2024Deep convolutional neural networks (CNNs) based approaches have achieved great performance in video matting. Many of these methods can produce accurate alpha estimation for the target body but typically yield fuzzy or incorrect target edges. This is usually caused by the following reasons: 1) The current methods always treat the target body and edge indiscriminately; 2) Target body dominates the whole target with only a tiny proportion target edge. For the first problem, we propose a CNN-based module that separately optimizes the matting target body and edge (SOBE). And on this basis, we introduce a real-time, trimap-free video matting method via progressively optimizing the matting target body and edge (POBEVM) that is much lighter than previous approaches and achieves significant improvements in the predicted target edge. For the second problem, we propose an Edge-L1-Loss (ELL) function that enforces our network on the matting target edge. Experiments demonstrate our method outperforms prior trimap-free matting methods on both Distinctions-646 (D646) and VideoMatte240K(VM) dataset, especially in edge optimization.
Probabilistic positioning via ray tracing with noisy angle of arrival measurements
Mar 01, 2024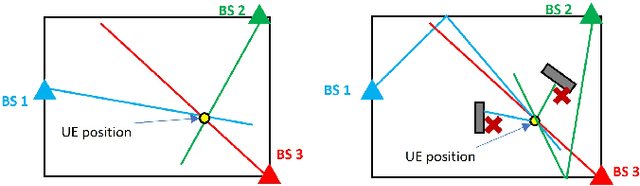
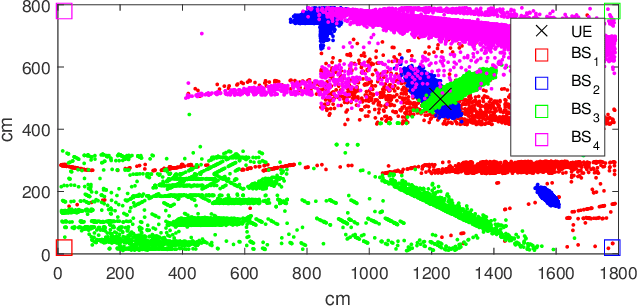
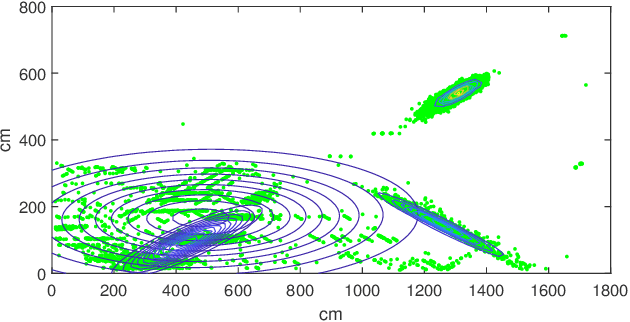

This paper investigates the problems of interference prediction and sensing for efficient spectrum access and link adaptation. The considered approach for interference prediction relies on a parametric model. However, we assume that the number of observations available to learn theses parameters is limited. This implies that they should be treated as random variables rather than fixed values. We show how this can impact the spectrum access and link adaptation strategies. We also introduce the notion of "interferer-coherence time" to establish the number of independent interferer state realizations experienced by a codeword. We explain how it can be computed taking into account the model uncertainty and how this impacts the link adaptation.
Mixer is more than just a model
Feb 28, 2024Recently, MLP structures have regained popularity, with MLP-Mixer standing out as a prominent example. In the field of computer vision, MLP-Mixer is noted for its ability to extract data information from both channel and token perspectives, effectively acting as a fusion of channel and token information. Indeed, Mixer represents a paradigm for information extraction that amalgamates channel and token information. The essence of Mixer lies in its ability to blend information from diverse perspectives, epitomizing the true concept of "mixing" in the realm of neural network architectures. Beyond channel and token considerations, it is possible to create more tailored mixers from various perspectives to better suit specific task requirements. This study focuses on the domain of audio recognition, introducing a novel model named Audio Spectrogram Mixer with Roll-Time and Hermit FFT (ASM-RH) that incorporates insights from both time and frequency domains. Experimental results demonstrate that ASM-RH is particularly well-suited for audio data and yields promising outcomes across multiple classification tasks.
DynaWarp -- Efficient, large-scale log storage and retrieval
Feb 28, 2024Modern, large scale monitoring systems have to process and store vast amounts of log data in near real-time. At query time the systems have to find relevant logs based on the content of the log message using support structures that can scale to these amounts of data while still being efficient to use. We present our novel DynaWarp membership sketch, capable of answering Multi-Set Multi-Membership-Queries, that can be used as an alternative to existing indexing structures for streamed log data. In our experiments, DynaWarp required up to 93% less storage space than the tested state-of-the-art inverted index and had up to four orders of magnitude less false-positives than the tested state-of-the-art membership sketch. Additionally, DynaWarp achieved up to 250 times higher query throughput than the tested inverted index and up to 240 times higher query throughput than the tested membership sketch.
Log Neural Controlled Differential Equations: The Lie Brackets Make a Difference
Feb 28, 2024The vector field of a controlled differential equation (CDE) describes the relationship between a control path and the evolution of a solution path. Neural CDEs (NCDEs) treat time series data as observations from a control path, parameterise a CDE's vector field using a neural network, and use the solution path as a continuously evolving hidden state. As their formulation makes them robust to irregular sampling rates, NCDEs are a powerful approach for modelling real-world data. Building on neural rough differential equations (NRDEs), we introduce Log-NCDEs, a novel and effective method for training NCDEs. The core component of Log-NCDEs is the Log-ODE method, a tool from the study of rough paths for approximating a CDE's solution. On a range of multivariate time series classification benchmarks, Log-NCDEs are shown to achieve a higher average test set accuracy than NCDEs, NRDEs, and two state-of-the-art models, S5 and the linear recurrent unit.
ADL4D: Towards A Contextually Rich Dataset for 4D Activities of Daily Living
Feb 27, 2024Hand-Object Interactions (HOIs) are conditioned on spatial and temporal contexts like surrounding objects, pre- vious actions, and future intents (for example, grasping and handover actions vary greatly based on objects proximity and trajectory obstruction). However, existing datasets for 4D HOI (3D HOI over time) are limited to one subject inter- acting with one object only. This restricts the generalization of learning-based HOI methods trained on those datasets. We introduce ADL4D, a dataset of up to two subjects inter- acting with different sets of objects performing Activities of Daily Living (ADL) like breakfast or lunch preparation ac- tivities. The transition between multiple objects to complete a certain task over time introduces a unique context lacking in existing datasets. Our dataset consists of 75 sequences with a total of 1.1M RGB-D frames, hand and object poses, and per-hand fine-grained action annotations. We develop an automatic system for multi-view multi-hand 3D pose an- notation capable of tracking hand poses over time. We inte- grate and test it against publicly available datasets. Finally, we evaluate our dataset on the tasks of Hand Mesh Recov- ery (HMR) and Hand Action Segmentation (HAS).