 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PIETS: Parallelised Irregularity Encoders for Forecasting with Heterogeneous Time-Series
Sep 30, 2021
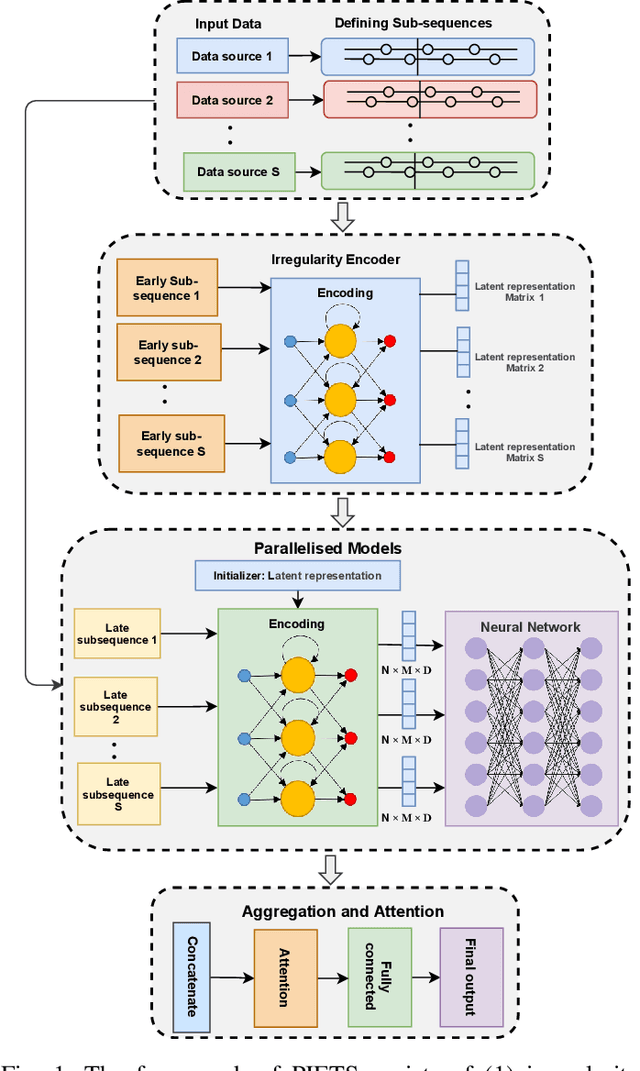
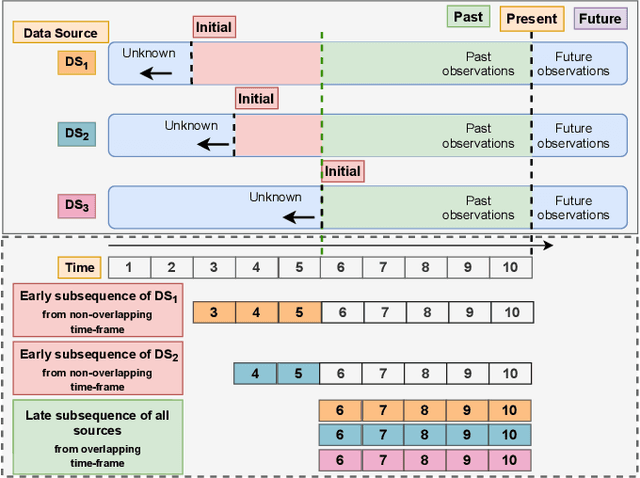
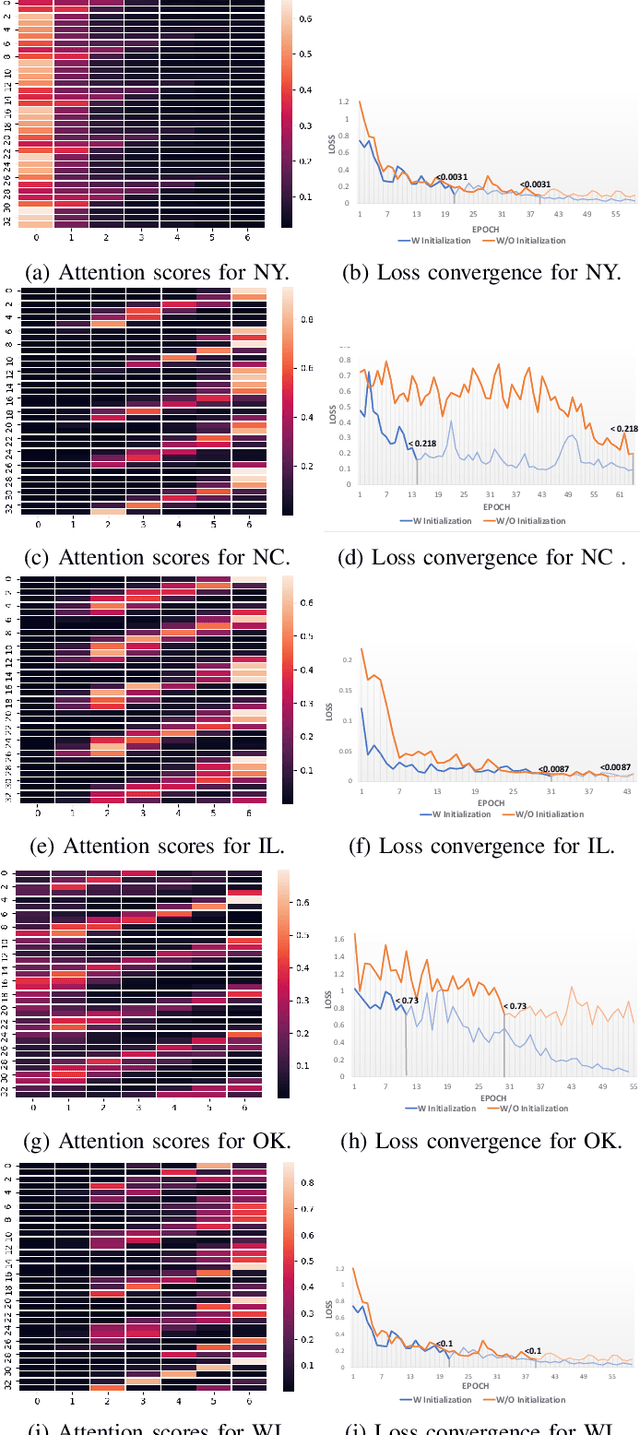
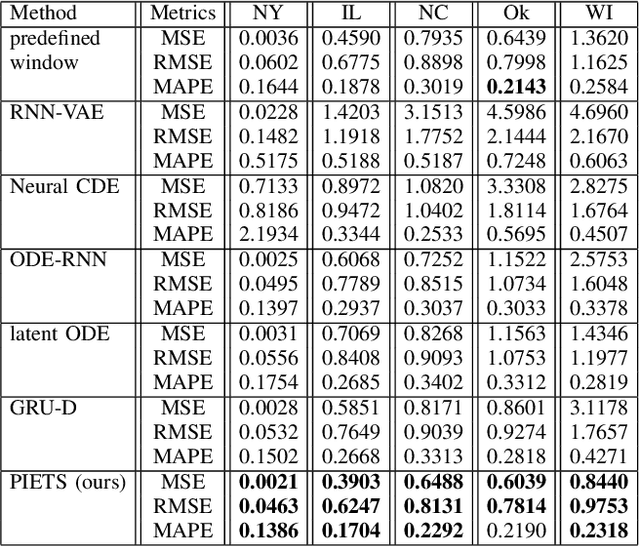
Heterogeneity and irregularity of multi-source data sets present a significant challenge to time-series analysis. In the literature, the fusion of multi-source time-series has been achieved either by using ensemble learning models which ignore temporal patterns and correlation within features or by defining a fixed-size window to select specific parts of the data sets. On the other hand, many studies have shown major improvement to handle the irregularity of time-series, yet none of these studies has been applied to multi-source data. In this work, we design a novel architecture, PIETS, to model heterogeneous time-series. PIETS has the following characteristics: (1) irregularity encoders for multi-source samples that can leverage all available information and accelerate the convergence of the model; (2) parallelised neural networks to enable flexibility and avoid information overwhelming; and (3) attention mechanism that highlights different information and gives high importance to the most related data. Through extensive experiments on real-world data sets related to COVID-19, we show that the proposed architecture is able to effectively model heterogeneous temporal data and outperforms other state-of-the-art approaches in the prediction task.
IoT Book Bot
Sep 04, 2022
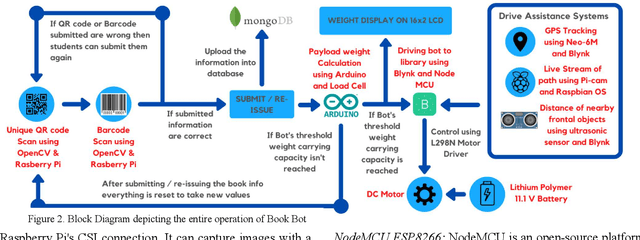
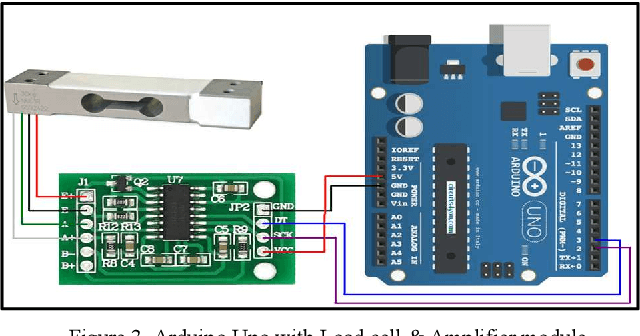

In order to ease the process of library management many technologies have been adopted but most of them focus on inventory management. There has hardly been any progress of automation in the field of issuing and returning books to the library on time. In colleges and schools, hostellers often forget to timely return the issued books back to the library. To solve the above issue and to ensure timely submission of the issued books, this work develops a Book-Bot which solves these complexities. The bot can commute from point A to point B, scan and verify QR Codes and Barcodes. The bot will have a certain payload capacity for carrying books. The QR code and Barcode scanning will be enabled by a Pi Camera, OpenCV and Raspberry Pi, thus making the exchange of books safe and secure. The odometry maneuvers of the bot will be controlled manually via a Blynk App. This paper focuses on how human intervention can be reduced and automates the issue part of library management system with the help of a bot.
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022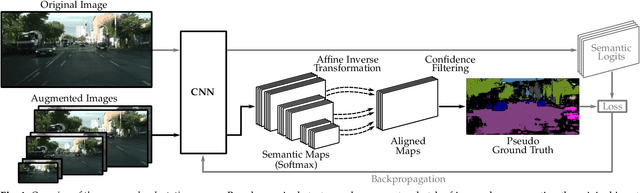

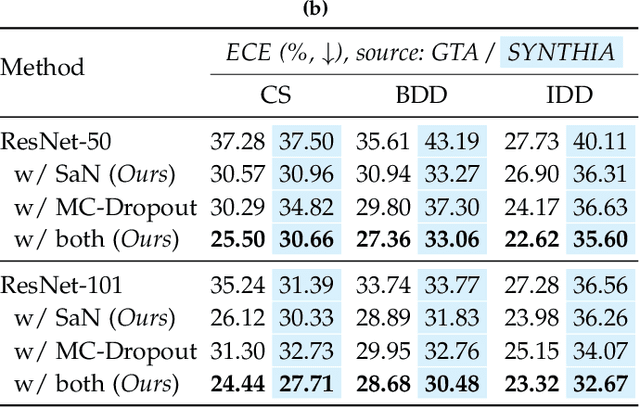
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.
Real-time Mortality Prediction Using MIMIC-IV ICU Data Via Boosted Nonparametric Hazards
Oct 17, 2021
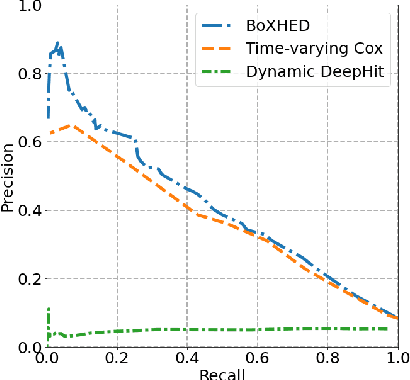
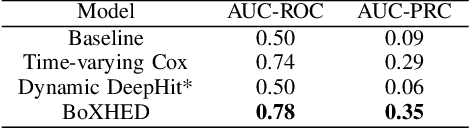
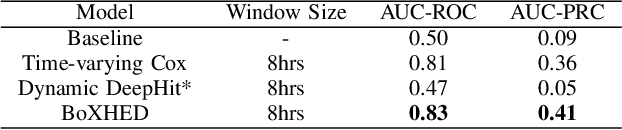
Electronic Health Record (EHR) systems provide critical, rich and valuable information at high frequency. One of the most exciting applications of EHR data is in developing a real-time mortality warning system with tools from survival analysis. However, most of the survival analysis methods used recently are based on (semi)parametric models using static covariates. These models do not take advantage of the information conveyed by the time-varying EHR data. In this work, we present an application of a highly scalable survival analysis method, BoXHED 2.0 to develop a real-time in-ICU mortality warning indicator based on the MIMIC IV data set. Importantly, BoXHED can incorporate time-dependent covariates in a fully nonparametric manner and is backed by theory. Our in-ICU mortality model achieves an AUC-PRC of 0.41 and AUC-ROC of 0.83 out of sample, demonstrating the benefit of real-time monitoring.
Mathematical Framework for Online Social Media Regulation
Sep 12, 2022
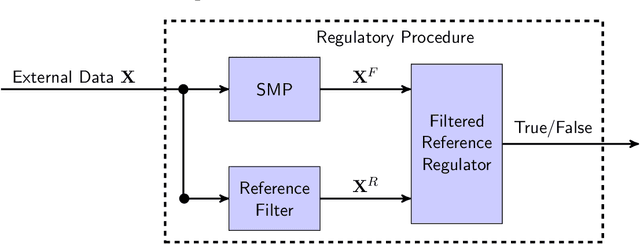
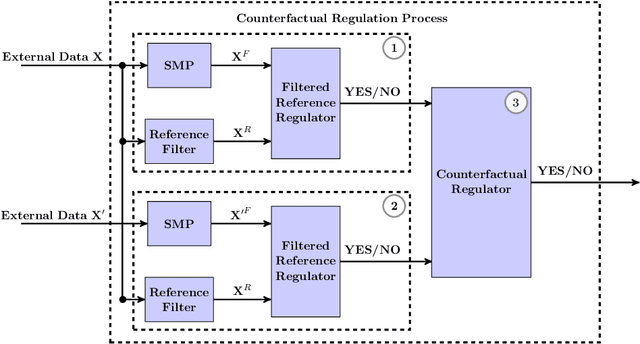
Social media platforms (SMPs) leverage algorithmic filtering (AF) as a means of selecting the content that constitutes a user's feed with the aim of maximizing their rewards. Selectively choosing the contents to be shown on the user's feed may yield a certain extent of influence, either minor or major, on the user's decision-making, compared to what it would have been under a natural/fair content selection. As we have witnessed over the past decade, algorithmic filtering can cause detrimental side effects, ranging from biasing individual decisions to shaping those of society as a whole, for example, diverting users' attention from whether to get the COVID-19 vaccine or inducing the public to choose a presidential candidate. The government's constant attempts to regulate the adverse effects of AF are often complicated, due to bureaucracy, legal affairs, and financial considerations. On the other hand SMPs seek to monitor their own algorithmic activities to avoid being fined for exceeding the allowable threshold. In this paper, we mathematically formalize this framework and utilize it to construct a data-driven statistical algorithm to regulate the AF from deflecting users' beliefs over time, along with sample and complexity guarantees. We show that our algorithm is robust against potential adversarial users. This state-of-the-art algorithm can be used either by authorities acting as external regulators or by SMPs for self-regulation.
KORSAL: Key-point Detection based Online Real-Time Spatio-Temporal Action Localization
Nov 05, 2021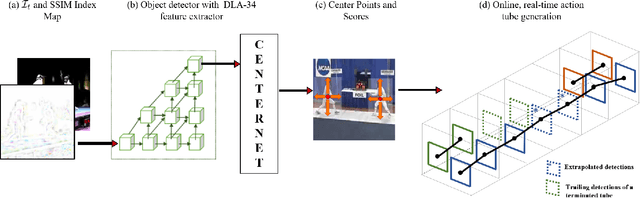
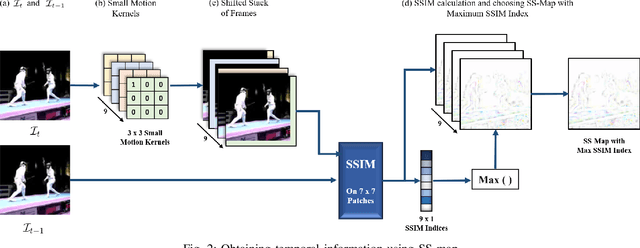

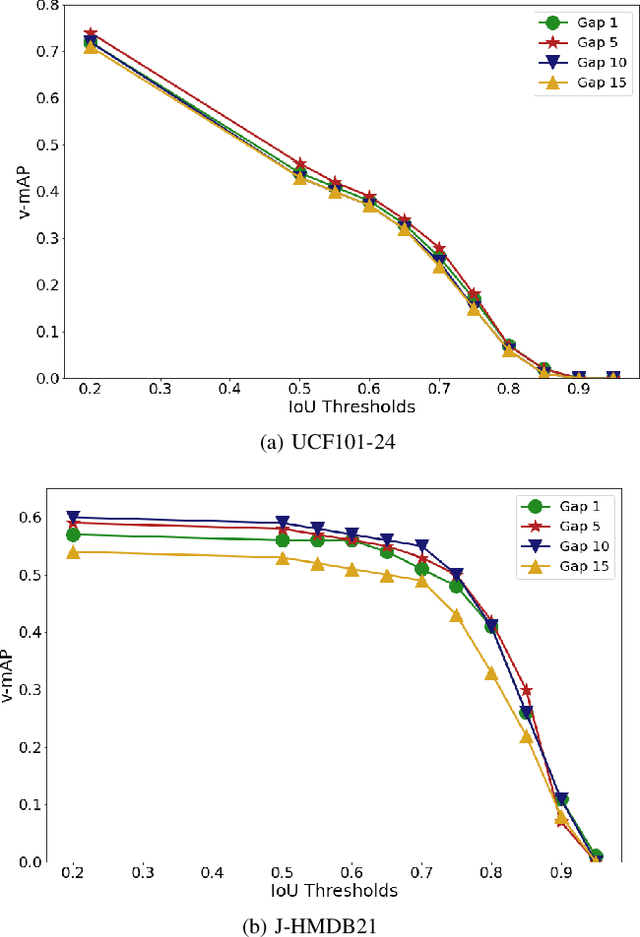
Real-time and online action localization in a video is a critical yet highly challenging problem. Accurate action localization requires the utilization of both temporal and spatial information. Recent attempts achieve this by using computationally intensive 3D CNN architectures or highly redundant two-stream architectures with optical flow, making them both unsuitable for real-time, online applications. To accomplish activity localization under highly challenging real-time constraints, we propose utilizing fast and efficient key-point based bounding box prediction to spatially localize actions. We then introduce a tube-linking algorithm that maintains the continuity of action tubes temporally in the presence of occlusions. Further, we eliminate the need for a two-stream architecture by combining temporal and spatial information into a cascaded input to a single network, allowing the network to learn from both types of information. Temporal information is efficiently extracted using a structural similarity index map as opposed to computationally intensive optical flow. Despite the simplicity of our approach, our lightweight end-to-end architecture achieves state-of-the-art frame-mAP of 74.7% on the challenging UCF101-24 dataset, demonstrating a performance gain of 6.4% over the previous best online methods. We also achieve state-of-the-art video-mAP results compared to both online and offline methods. Moreover, our model achieves a frame rate of 41.8 FPS, which is a 10.7% improvement over contemporary real-time methods.
Identification of Cognitive Workload during Surgical Tasks with Multimodal Deep Learning
Sep 12, 2022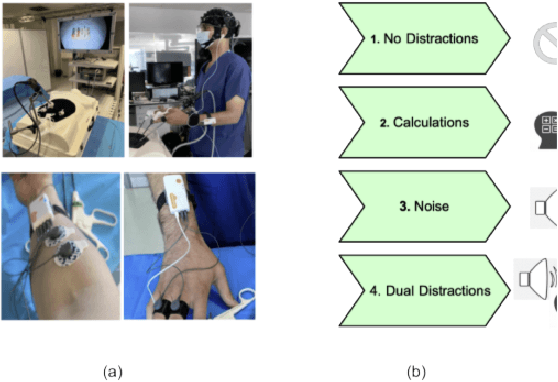
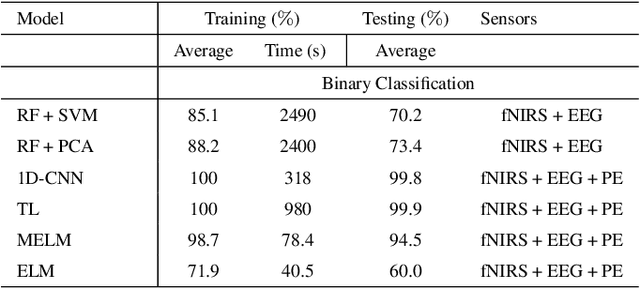
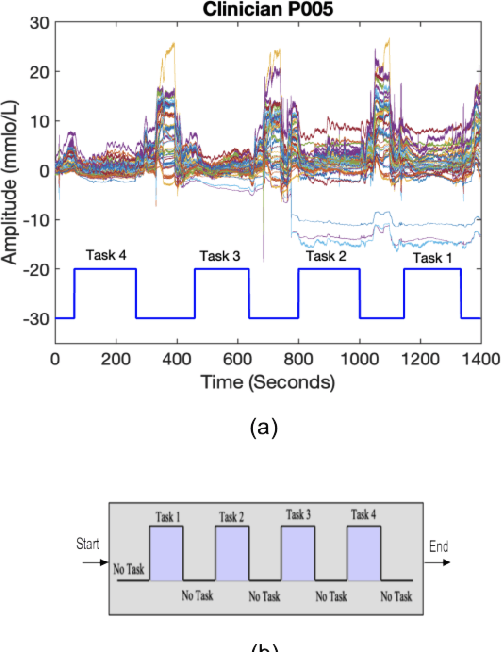
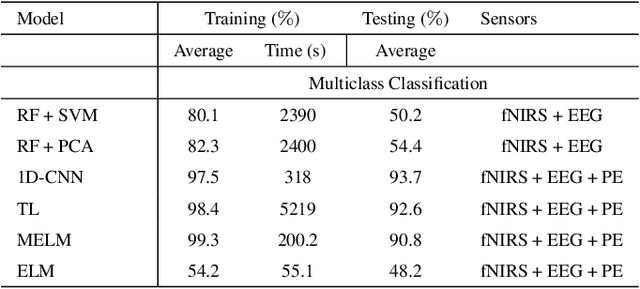
In operating Rooms (ORs), activities are usually different from other typical working environments. In particular, surgeons are frequently exposed to multiple psycho-organizational constraints that may cause negative repercussions on their health and performance. This is commonly attributed to an increase in the associated Cognitive Workload (CWL) that results from dealing with unexpected and repetitive tasks, as well as large amounts of information and potentially risky cognitive overload. In this paper, a cascade of two machine learning approaches is suggested for the multimodal recognition of CWL in a number of four different surgical tasks. First, a model based on the concept of transfer learning is used to identify if a surgeon is experiencing any CWL. Secondly, a Convolutional Neural Network (CNN) uses this information to identify different types of CWL associated to each surgical task. The suggested multimodal approach consider adjacent signals from electroencephalogram (EEG), functional near-infrared spectroscopy (fNIRS) and pupil eye diameter. The concatenation of signals allows complex correlations in terms of time (temporal) and channel location (spatial). Data collection is performed by a Multi-sensing AI Environment for Surgical Task $\&$ Role Optimisation platform (MAESTRO) developed at HARMS Lab. To compare the performance of the proposed methodology, a number of state-of-art machine learning techniques have been implemented. The tests show that the proposed model has a precision of 93%.
Dynamic Regret of Adaptive Gradient Methods for Strongly Convex Problems
Sep 04, 2022
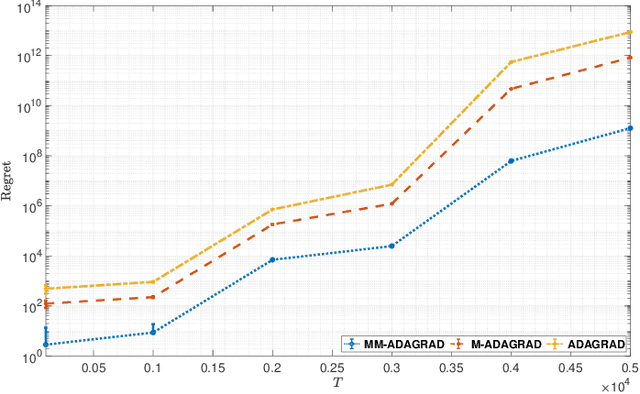
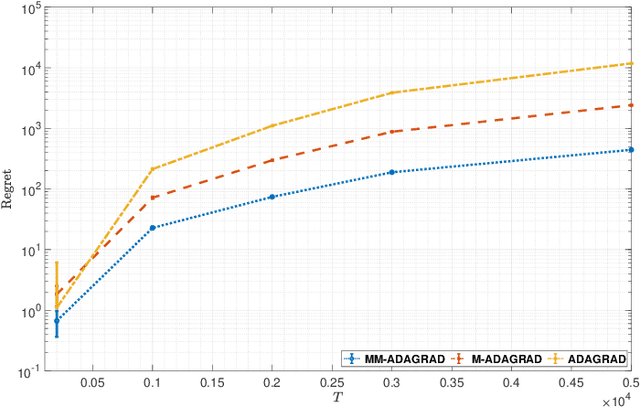
Adaptive gradient algorithms such as ADAGRAD and its variants have gained popularity in the training of deep neural networks. While many works as for adaptive methods have focused on the static regret as a performance metric to achieve a good regret guarantee, the dynamic regret analyses of these methods remain unclear. As opposed to the static regret, dynamic regret is considered to be a stronger concept of performance measurement in the sense that it explicitly elucidates the non-stationarity of the environment. In this paper, we go through a variant of ADAGRAD (referred to as M-ADAGRAD ) in a strong convex setting via the notion of dynamic regret, which measures the performance of an online learner against a reference (optimal) solution that may change over time. We demonstrate a regret bound in terms of the path-length of the minimizer sequence that essentially reflects the non-stationarity of environments. In addition, we enhance the dynamic regret bound by exploiting the multiple accesses of the gradient to the learner in each round. Empirical results indicate that M-ADAGRAD works also well in practice.
Hybrid Parallel Imaging and Compressed Sensing MRI Reconstruction with GRAPPA Integrated Multi-loss Supervised GAN
Sep 19, 2022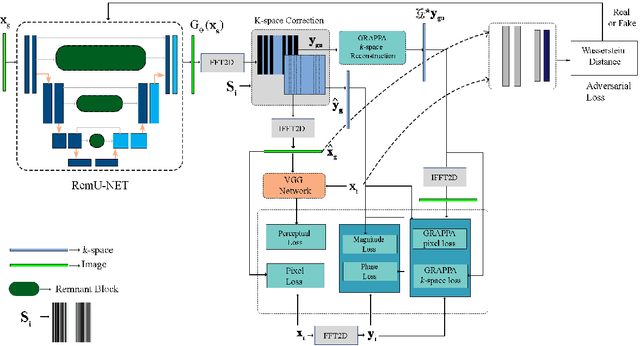



Objective: Parallel imaging accelerates the acquisition of magnetic resonance imaging (MRI) data by acquiring additional sensitivity information with an array of receiver coils resulting in reduced phase encoding steps. Compressed sensing magnetic resonance imaging (CS-MRI) has achieved popularity in the field of medical imaging because of its less data requirement than parallel imaging. Parallel imaging and compressed sensing (CS) both speed up traditional MRI acquisition by minimizing the amount of data captured in the k-space. As acquisition time is inversely proportional to the number of samples, the inverse formation of an image from reduced k-space samples leads to faster acquisition but with aliasing artifacts. This paper proposes a novel Generative Adversarial Network (GAN) namely RECGAN-GR supervised with multi-modal losses for de-aliasing the reconstructed image. Methods: In contrast to existing GAN networks, our proposed method introduces a novel generator network namely RemU-Net integrated with dual-domain loss functions including weighted magnitude and phase loss functions along with parallel imaging-based loss i.e., GRAPPA consistency loss. A k-space correction block is proposed as refinement learning to make the GAN network self-resistant to generating unnecessary data which drives the convergence of the reconstruction process faster. Results: Comprehensive results show that the proposed RECGAN-GR achieves a 4 dB improvement in the PSNR among the GAN-based methods and a 2 dB improvement among conventional state-of-the-art CNN methods available in the literature. Conclusion and significance: The proposed work contributes to significant improvement in the image quality for low retained data leading to 5x or 10x faster acquisition.
Highly precise AMCW time-of-flight scanning sensor based on digital-parallel demodulation
Dec 16, 2021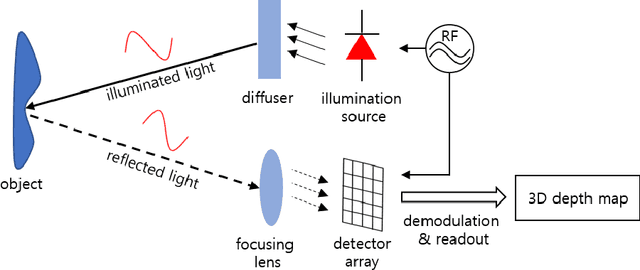
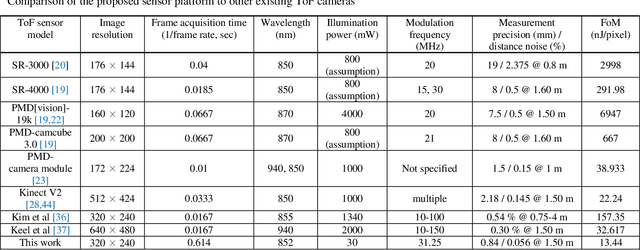
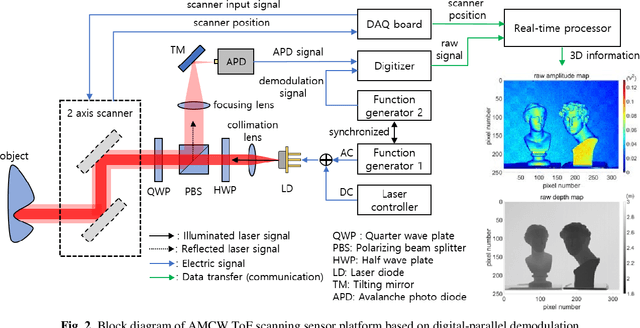
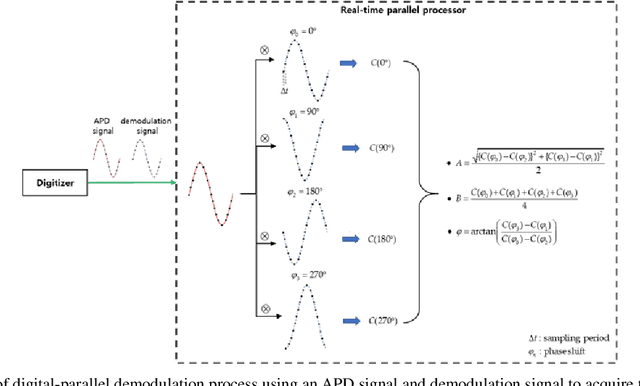
In this paper, a novel amplitude-modulated continuous wave (AMCW) time-of-flight (ToF) scanning sensor based on digital-parallel demodulation is proposed and demonstrated in the aspect of distance measurement precision. Since digital-parallel demodulation utilizes a high-amplitude demodulation signal with zero-offset, the proposed sensor platform can maintain extremely high demodulation contrast. Meanwhile, as all cross correlated samples are calculated in parallel and in extremely short integration time, the proposed sensor platform can utilize a 2D laser scanning structure with a single photo detector, maintaining a moderate frame rate. This optical structure can increase the received optical SNR and remove the crosstalk of image pixel array. Based on these measurement properties, the proposed AMCW ToF scanning sensor shows highly precise 3D depth measurement performance. In this study, this precise measurement performance is explained in detail. Additionally, the actual measurement performance of the proposed sensor platform is experimentally validated under various conditions.