 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SpOT: Spatiotemporal Modeling for 3D Object Tracking
Jul 12, 2022
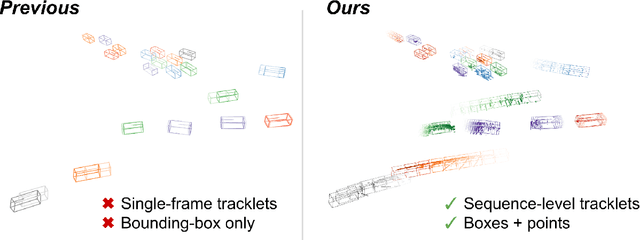
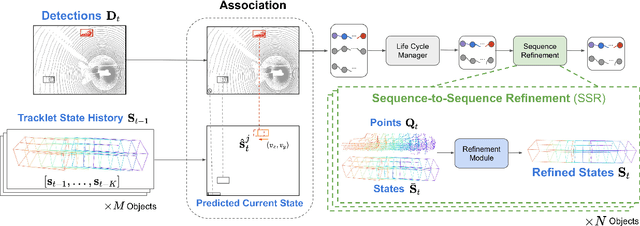
3D multi-object tracking aims to uniquely and consistently identify all mobile entities through time. Despite the rich spatiotemporal information available in this setting, current 3D tracking methods primarily rely on abstracted information and limited history, e.g. single-frame object bounding boxes. In this work, we develop a holistic representation of traffic scenes that leverages both spatial and temporal information of the actors in the scene. Specifically, we reformulate tracking as a spatiotemporal problem by representing tracked objects as sequences of time-stamped points and bounding boxes over a long temporal history. At each timestamp, we improve the location and motion estimates of our tracked objects through learned refinement over the full sequence of object history. By considering time and space jointly, our representation naturally encodes fundamental physical priors such as object permanence and consistency across time. Our spatiotemporal tracking framework achieves state-of-the-art performance on the Waymo and nuScenes benchmarks.
A Continuous-time Stochastic Gradient Descent Method for Continuous Data
Dec 07, 2021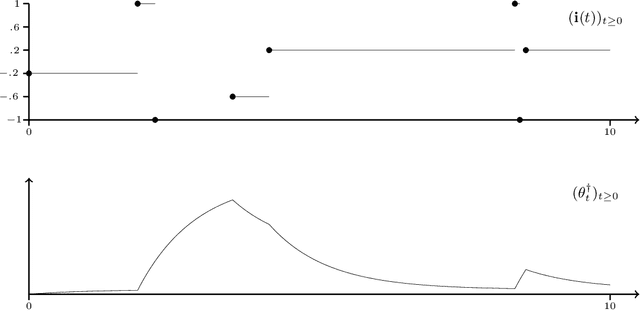
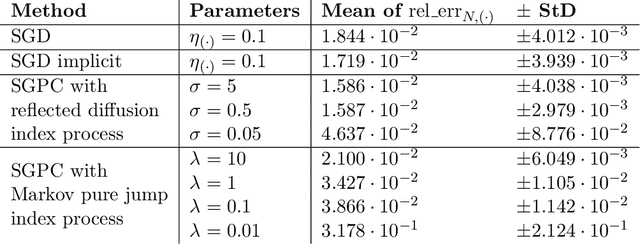
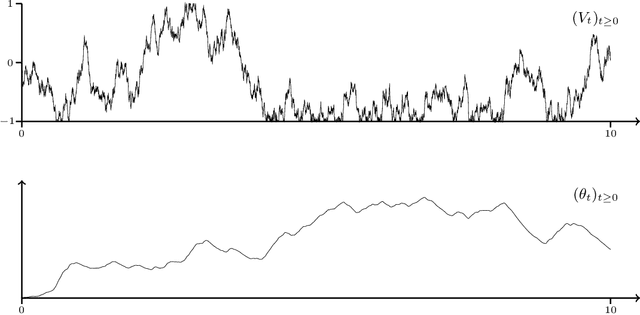
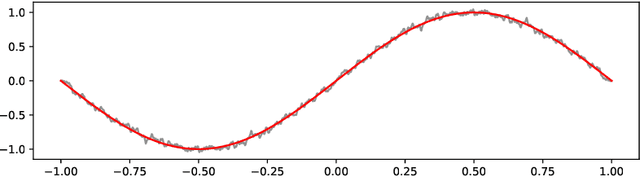
Optimization problems with continuous data appear in, e.g., robust machine learning, functional data analysis, and variational inference. Here, the target function is given as an integral over a family of (continuously) indexed target functions - integrated with respect to a probability measure. Such problems can often be solved by stochastic optimization methods: performing optimization steps with respect to the indexed target function with randomly switched indices. In this work, we study a continuous-time variant of the stochastic gradient descent algorithm for optimization problems with continuous data. This so-called stochastic gradient process consists in a gradient flow minimizing an indexed target function that is coupled with a continuous-time index process determining the index. Index processes are, e.g., reflected diffusions, pure jump processes, or other L\'evy processes on compact spaces. Thus, we study multiple sampling patterns for the continuous data space and allow for data simulated or streamed at runtime of the algorithm. We analyze the approximation properties of the stochastic gradient process and study its longtime behavior and ergodicity under constant and decreasing learning rates. We end with illustrating the applicability of the stochastic gradient process in a polynomial regression problem with noisy functional data, as well as in a physics-informed neural network.
Efficiency Evaluation of Banks with Many Branches using a Heuristic Framework and Dynamic Data Envelopment Optimization Approach: A Real Case Study
Sep 11, 2022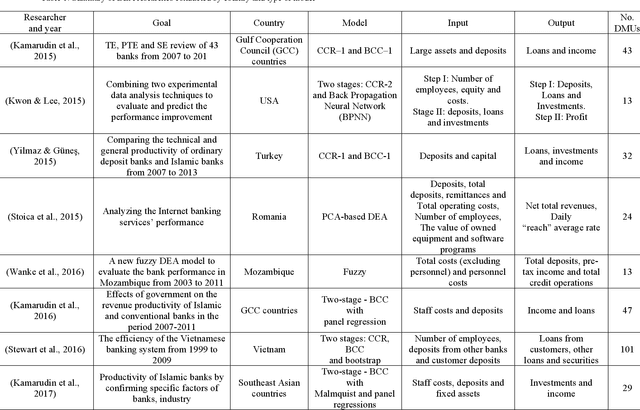
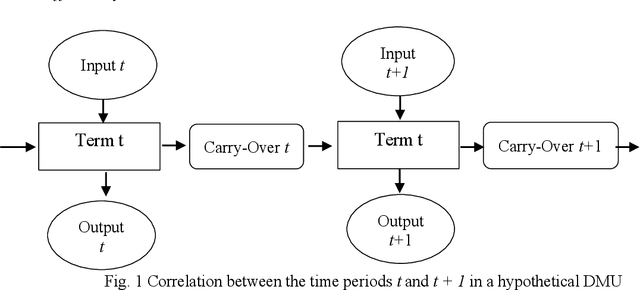

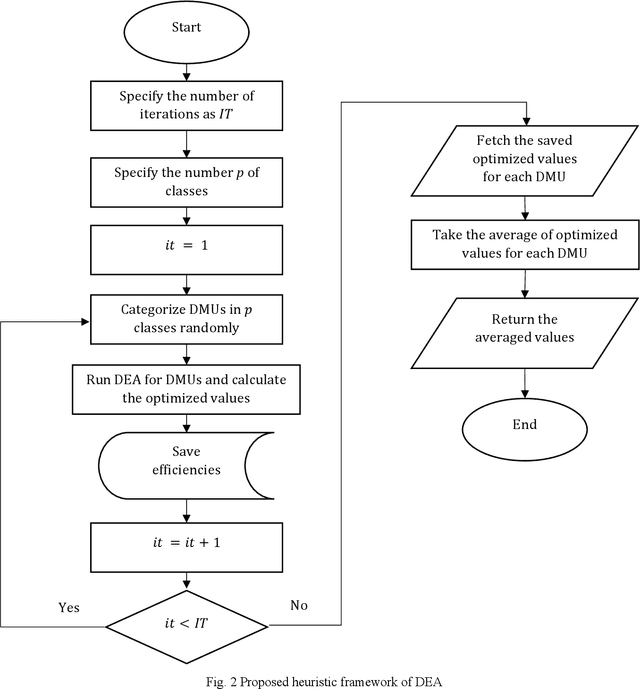
Evaluating the efficiency of organizations and branches within an organization is a challenging issue for managers. Evaluation criteria allow organizations to rank their internal units, identify their position concerning their competitors, and implement strategies for improvement and development purposes. Among the methods that have been applied in the evaluation of bank branches, non-parametric methods have captured the attention of researchers in recent years. One of the most widely used non-parametric methods is the data envelopment analysis (DEA) which leads to promising results. However, the static DEA approaches do not consider the time in the model. Therefore, this paper uses a dynamic DEA (DDEA) method to evaluate the branches of a private Iranian bank over three years (2017-2019). The results are then compared with static DEA. After ranking the branches, they are clustered using the K-means method. Finally, a comprehensive sensitivity analysis approach is introduced to help the managers to decide about changing variables to shift a branch from one cluster to a more efficient one.
Anomaly Detection in Aerial Videos with Transformers
Sep 25, 2022

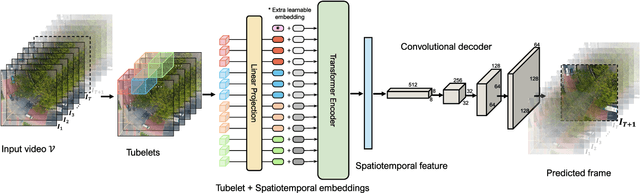
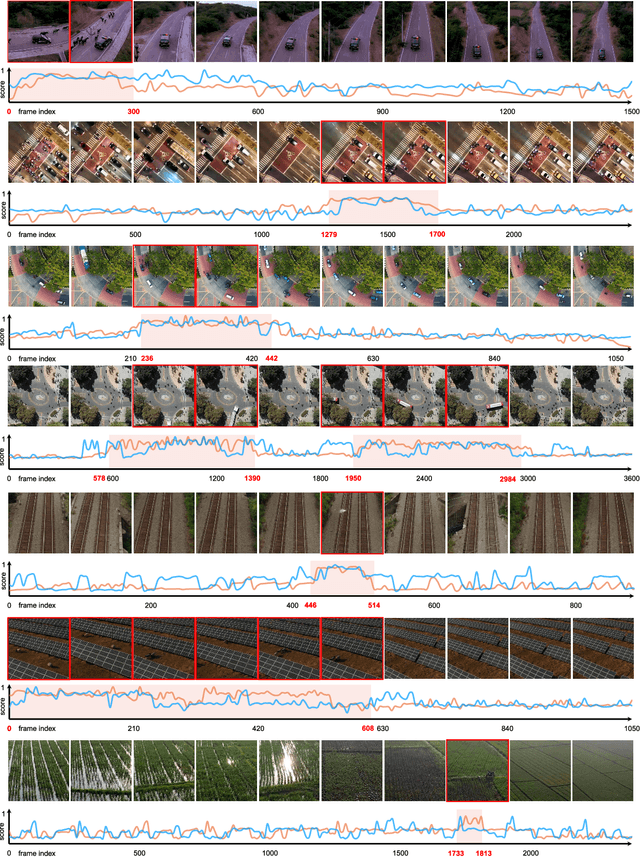
Unmanned aerial vehicles (UAVs) are widely applied for purposes of inspection, search, and rescue operations by the virtue of low-cost, large-coverage, real-time, and high-resolution data acquisition capacities. Massive volumes of aerial videos are produced in these processes, in which normal events often account for an overwhelming proportion. It is extremely difficult to localize and extract abnormal events containing potentially valuable information from long video streams manually. Therefore, we are dedicated to developing anomaly detection methods to solve this issue. In this paper, we create a new dataset, named DroneAnomaly, for anomaly detection in aerial videos. This dataset provides 37 training video sequences and 22 testing video sequences from 7 different realistic scenes with various anomalous events. There are 87,488 color video frames (51,635 for training and 35,853 for testing) with the size of $640 \times 640$ at 30 frames per second. Based on this dataset, we evaluate existing methods and offer a benchmark for this task. Furthermore, we present a new baseline model, ANomaly Detection with Transformers (ANDT), which treats consecutive video frames as a sequence of tubelets, utilizes a Transformer encoder to learn feature representations from the sequence, and leverages a decoder to predict the next frame. Our network models normality in the training phase and identifies an event with unpredictable temporal dynamics as an anomaly in the test phase. Moreover, To comprehensively evaluate the performance of our proposed method, we use not only our Drone-Anomaly dataset but also another dataset. We will make our dataset and code publicly available. A demo video is available at https://youtu.be/ancczYryOBY. We make our dataset and code publicly available .
CLAIRE -- Parallelized Diffeomorphic Image Registration for Large-Scale Biomedical Imaging Applications
Sep 16, 2022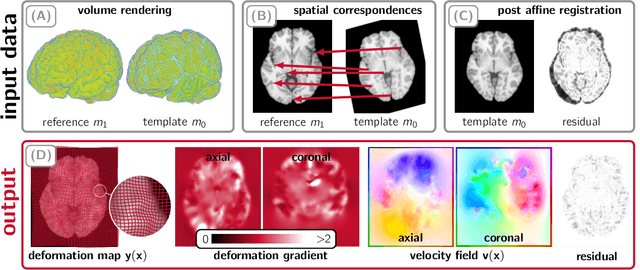


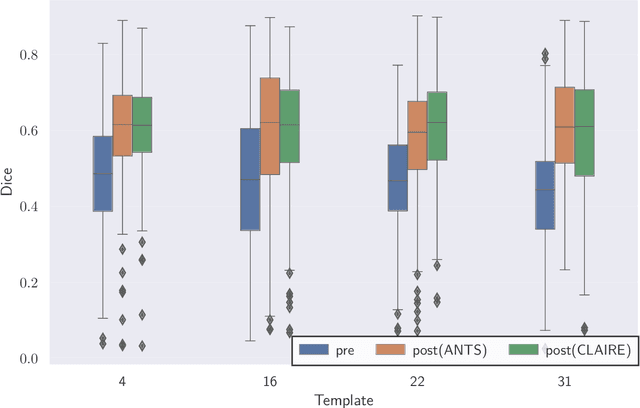
We study the performance of CLAIRE -- a diffeomorphic multi-node, multi-GPU image-registration algorithm, and software -- in large-scale biomedical imaging applications with billions of voxels. At such resolutions, most existing software packages for diffeomorphic image registration are prohibitively expensive. As a result, practitioners first significantly downsample the original images and then register them using existing tools. Our main contribution is an extensive analysis of the impact of downsampling on registration performance. We study this impact by comparing full-resolution registrations obtained with CLAIRE to lower-resolution registrations for synthetic and real-world imaging datasets. Our results suggest that registration at full resolution can yield a superior registration quality -- but not always. For example, downsampling a synthetic image from $1024^3$ to $256^3$ decreases the Dice coefficient from 92% to 79%. However, the differences are less pronounced for noisy or low-contrast high-resolution images. CLAIRE allows us not only to register images of clinically relevant size in a few seconds but also to register images at unprecedented resolution in a reasonable time. The highest resolution considered is CLARITY images of size $2816\times3016\times1162$. To the best of our knowledge, this is the first study on image registration quality at such resolutions.
Tranception: protein fitness prediction with autoregressive transformers and inference-time retrieval
May 27, 2022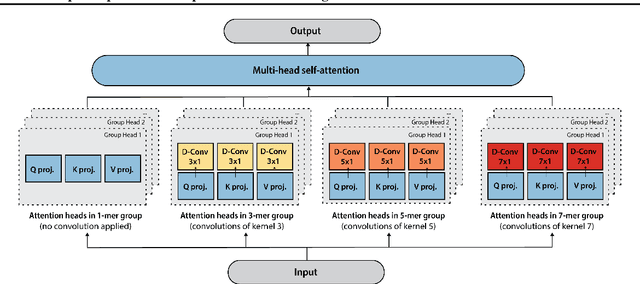
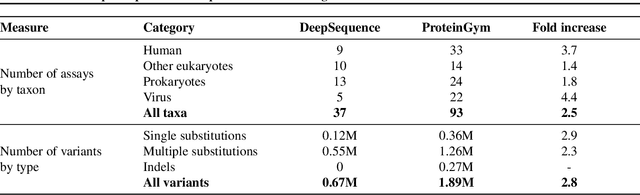
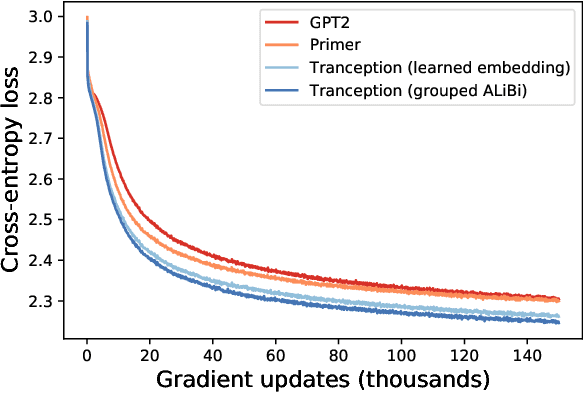
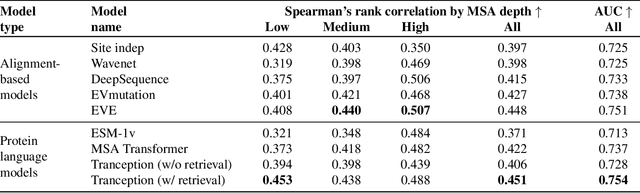
The ability to accurately model the fitness landscape of protein sequences is critical to a wide range of applications, from quantifying the effects of human variants on disease likelihood, to predicting immune-escape mutations in viruses and designing novel biotherapeutic proteins. Deep generative models of protein sequences trained on multiple sequence alignments have been the most successful approaches so far to address these tasks. The performance of these methods is however contingent on the availability of sufficiently deep and diverse alignments for reliable training. Their potential scope is thus limited by the fact many protein families are hard, if not impossible, to align. Large language models trained on massive quantities of non-aligned protein sequences from diverse families address these problems and show potential to eventually bridge the performance gap. We introduce Tranception, a novel transformer architecture leveraging autoregressive predictions and retrieval of homologous sequences at inference to achieve state-of-the-art fitness prediction performance. Given its markedly higher performance on multiple mutants, robustness to shallow alignments and ability to score indels, our approach offers significant gain of scope over existing approaches. To enable more rigorous model testing across a broader range of protein families, we develop ProteinGym -- an extensive set of multiplexed assays of variant effects, substantially increasing both the number and diversity of assays compared to existing benchmarks.
Gradient Norm Minimization of Nesterov Acceleration: $o(1/k^3)$
Sep 19, 2022In the history of first-order algorithms, Nesterov's accelerated gradient descent (NAG) is one of the milestones. However, the cause of the acceleration has been a mystery for a long time. It has not been revealed with the existence of gradient correction until the high-resolution differential equation framework proposed in [Shi et al., 2021]. In this paper, we continue to investigate the acceleration phenomenon. First, we provide a significantly simplified proof based on precise observation and a tighter inequality for $L$-smooth functions. Then, a new implicit-velocity high-resolution differential equation framework, as well as the corresponding implicit-velocity version of phase-space representation and Lyapunov function, is proposed to investigate the convergence behavior of the iterative sequence $\{x_k\}_{k=0}^{\infty}$ of NAG. Furthermore, from two kinds of phase-space representations, we find that the role played by gradient correction is equivalent to that by velocity included implicitly in the gradient, where the only difference comes from the iterative sequence $\{y_{k}\}_{k=0}^{\infty}$ replaced by $\{x_k\}_{k=0}^{\infty}$. Finally, for the open question of whether the gradient norm minimization of NAG has a faster rate $o(1/k^3)$, we figure out a positive answer with its proof. Meanwhile, a faster rate of objective value minimization $o(1/k^2)$ is shown for the case $r > 2$.
Pathfinding in Random Partially Observable Environments with Vision-Informed Deep Reinforcement Learning
Sep 11, 2022
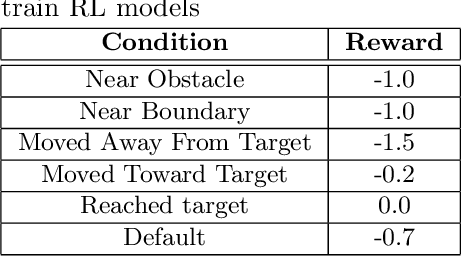
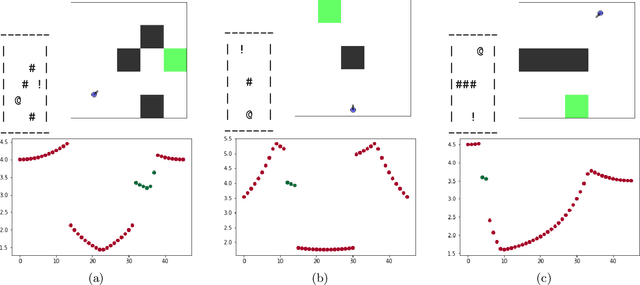
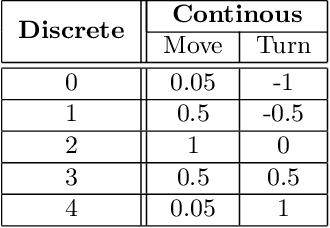
Deep reinforcement learning is a technique for solving problems in a variety of environments, ranging from Atari video games to stock trading. This method leverages deep neural network models to make decisions based on observations of a given environment with the goal of maximizing a reward function that can incorporate cost and rewards for reaching goals. With the aim of pathfinding, reward conditions can include reaching a specified target area along with costs for movement. In this work, multiple Deep Q-Network (DQN) agents are trained to operate in a partially observable environment with the goal of reaching a target zone in minimal travel time. The agent operates based on a visual representation of its surroundings, and thus has a restricted capability to observe the environment. A comparison between DQN, DQN-GRU, and DQN-LSTM is performed to examine each models capabilities with two different types of input. Through this evaluation, it is been shown that with equivalent training and analogous model architectures, a DQN model is able to outperform its recurrent counterparts.
Multigraph Topology Design for Cross-Silo Federated Learning
Jul 21, 2022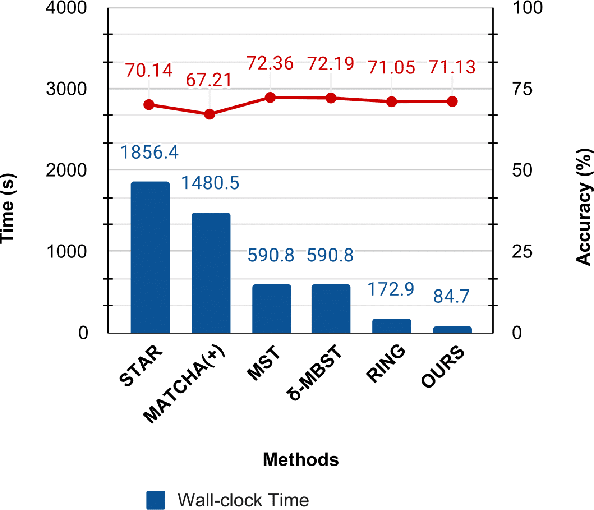
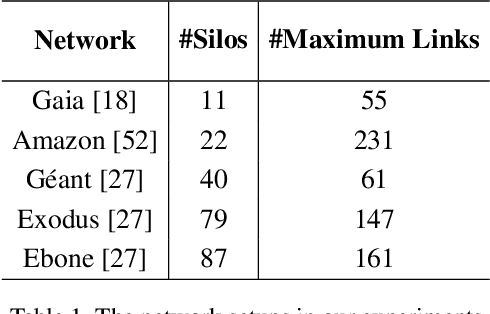
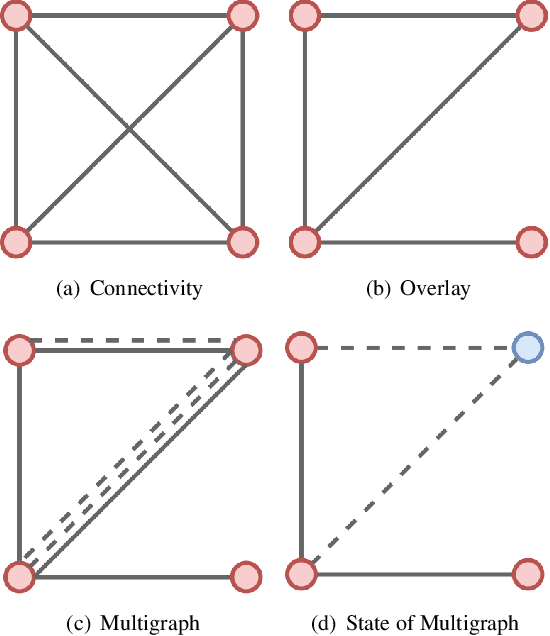
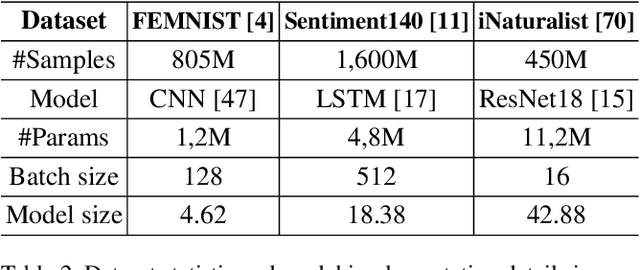
Cross-silo federated learning utilizes a few hundred reliable data silos with high-speed access links to jointly train a model. While this approach becomes a popular setting in federated learning, designing a robust topology to reduce the training time is still an open problem. In this paper, we present a new multigraph topology for cross-silo federated learning. We first construct the multigraph using the overlay graph. We then parse this multigraph into different simple graphs with isolated nodes. The existence of isolated nodes allows us to perform model aggregation without waiting for other nodes, hence reducing the training time. We further propose a new distributed learning algorithm to use with our multigraph topology. The intensive experiments on public datasets show that our proposed method significantly reduces the training time compared with recent state-of-the-art topologies while ensuring convergence and maintaining the model's accuracy.
Real-time detection of anomalies in large-scale transient surveys
Oct 29, 2021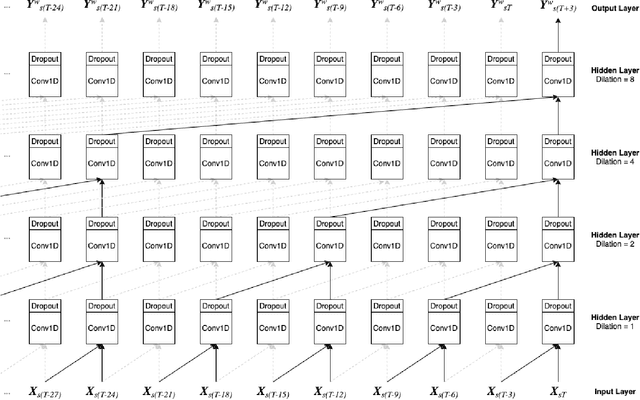

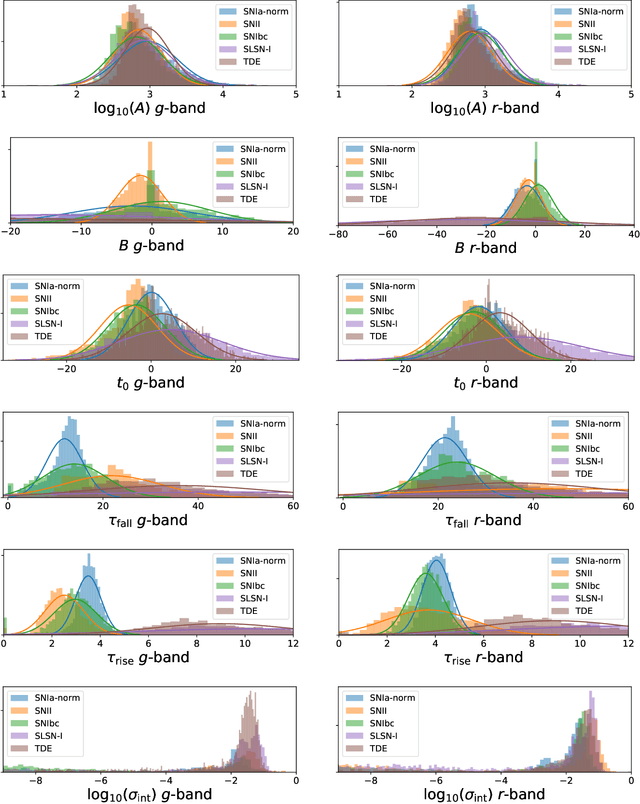
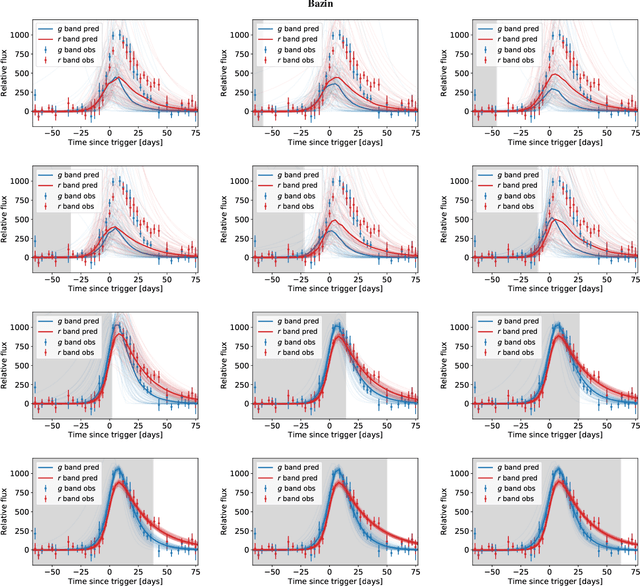
New time-domain surveys, such as the Rubin Observatory Legacy Survey of Space and Time (LSST), will observe millions of transient alerts each night, making standard approaches of visually identifying new and interesting transients infeasible. We present two novel methods of automatically detecting anomalous transient light curves in real-time. Both methods are based on the simple idea that if the light curves from a known population of transients can be accurately modelled, any deviations from model predictions are likely anomalies. The first modelling approach is a probabilistic neural network built using Temporal Convolutional Networks (TCNs) and the second is an interpretable Bayesian parametric model of a transient. We demonstrate our methods' ability to provide anomaly scores as a function of time on light curves from the Zwicky Transient Facility. We show that the flexibility of neural networks, the attribute that makes them such a powerful tool for many regression tasks, is what makes them less suitable for anomaly detection when compared with our parametric model. The parametric model is able to identify anomalies with respect to common supernova classes with low false anomaly rates and high true anomaly rates achieving Area Under the Receive Operating Characteristic (ROC) Curve (AUC) scores above 0.8 for most rare classes such as kilonovae, tidal disruption events, intermediate luminosity transients, and pair-instability supernovae. Our ability to identify anomalies improves over the lifetime of the light curves. Our framework, used in conjunction with transient classifiers, will enable fast and prioritised follow-up of unusual transients from new large-scale surveys.