 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Speech Synthesis with Mixed Emotions
Aug 11, 2022
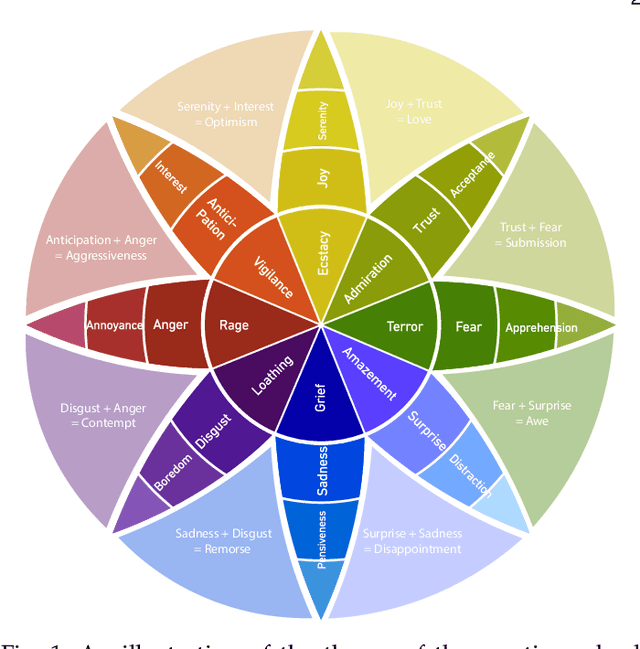

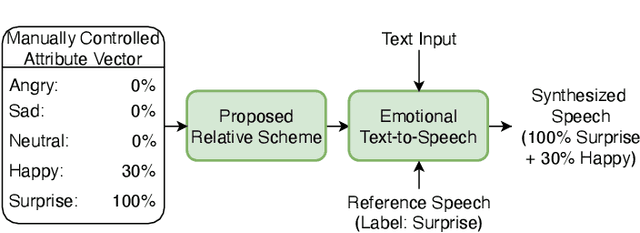
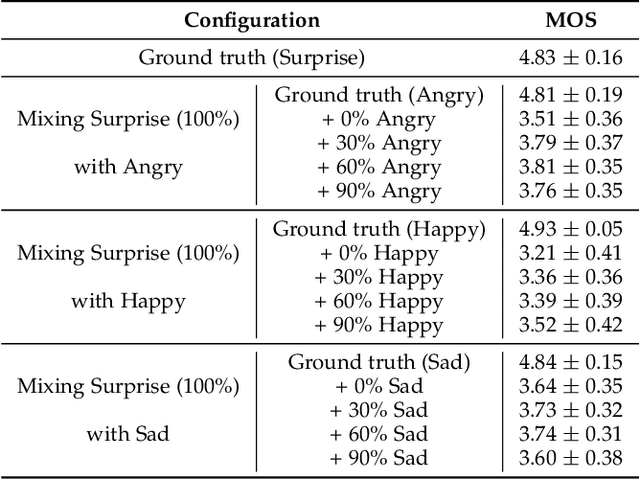
Emotional speech synthesis aims to synthesize human voices with various emotional effects. The current studies are mostly focused on imitating an averaged style belonging to a specific emotion type. In this paper, we seek to generate speech with a mixture of emotions at run-time. We propose a novel formulation that measures the relative difference between the speech samples of different emotions. We then incorporate our formulation into a sequence-to-sequence emotional text-to-speech framework. During the training, the framework does not only explicitly characterize emotion styles, but also explores the ordinal nature of emotions by quantifying the differences with other emotions. At run-time, we control the model to produce the desired emotion mixture by manually defining an emotion attribute vector. The objective and subjective evaluations have validated the effectiveness of the proposed framework. To our best knowledge, this research is the first study on modelling, synthesizing and evaluating mixed emotions in speech.
Generative Adversarial Super-Resolution at the Edge with Knowledge Distillation
Sep 07, 2022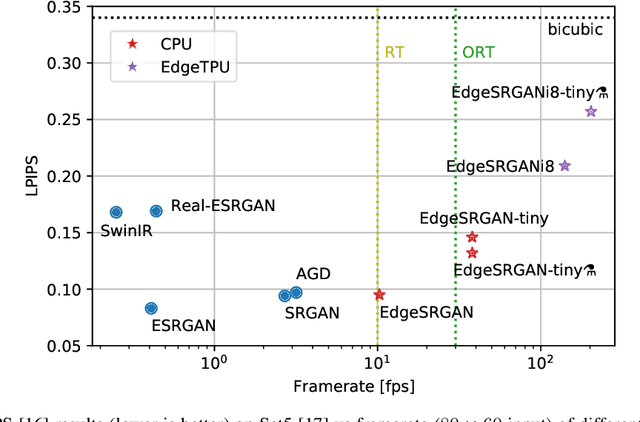
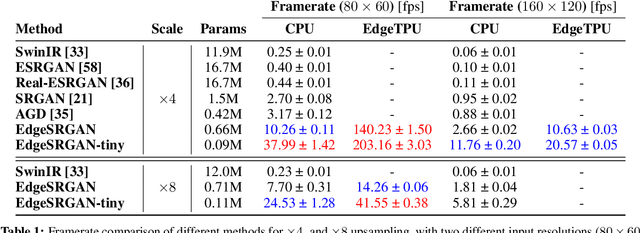
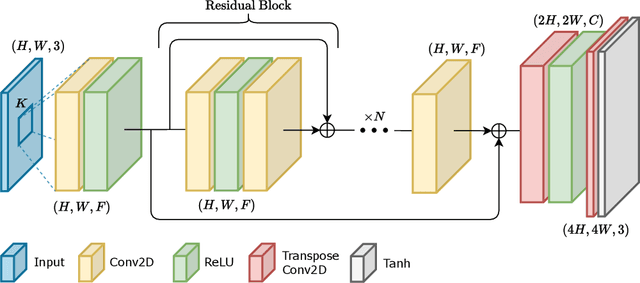
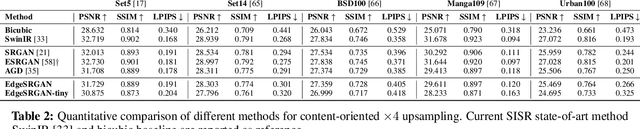
Single-Image Super-Resolution can support robotic tasks in environments where a reliable visual stream is required to monitor the mission, handle teleoperation or study relevant visual details. In this work, we propose an efficient Generative Adversarial Network model for real-time Super-Resolution. We adopt a tailored architecture of the original SRGAN and model quantization to boost the execution on CPU and Edge TPU devices, achieving up to 200 fps inference. We further optimize our model by distilling its knowledge to a smaller version of the network and obtain remarkable improvements compared to the standard training approach. Our experiments show that our fast and lightweight model preserves considerably satisfying image quality compared to heavier state-of-the-art models. Finally, we conduct experiments on image transmission with bandwidth degradation to highlight the advantages of the proposed system for mobile robotic applications.
Optimal Scaling for Locally Balanced Proposals in Discrete Spaces
Sep 16, 2022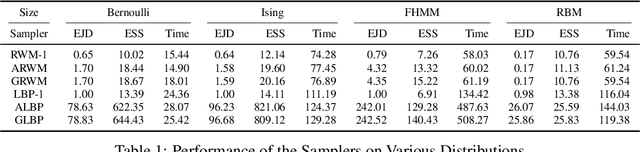
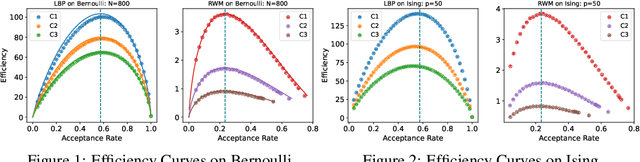
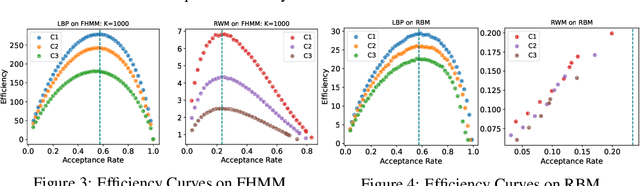
Optimal scaling has been well studied for Metropolis-Hastings (M-H) algorithms in continuous spaces, but a similar understanding has been lacking in discrete spaces. Recently, a family of locally balanced proposals (LBP) for discrete spaces has been proved to be asymptotically optimal, but the question of optimal scaling has remained open. In this paper, we establish, for the first time, that the efficiency of M-H in discrete spaces can also be characterized by an asymptotic acceptance rate that is independent of the target distribution. Moreover, we verify, both theoretically and empirically, that the optimal acceptance rates for LBP and random walk Metropolis (RWM) are $0.574$ and $0.234$ respectively. These results also help establish that LBP is asymptotically $O(N^\frac{2}{3})$ more efficient than RWM with respect to model dimension $N$. Knowledge of the optimal acceptance rate allows one to automatically tune the neighborhood size of a proposal distribution in a discrete space, directly analogous to step-size control in continuous spaces. We demonstrate empirically that such adaptive M-H sampling can robustly improve sampling in a variety of target distributions in discrete spaces, including training deep energy based models.
Multi-Scale Attention-based Multiple Instance Learning for Classification of Multi-Gigapixel Histology Images
Sep 07, 2022
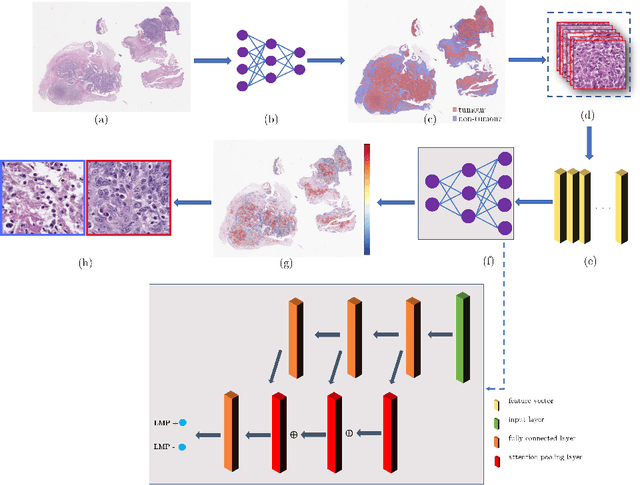
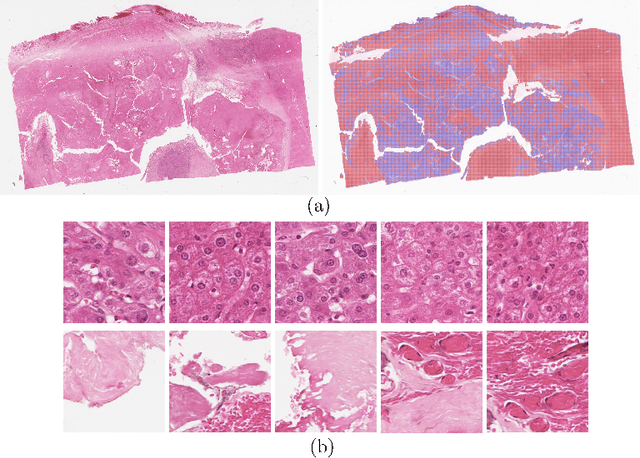

Histology images with multi-gigapixel of resolution yield rich information for cancer diagnosis and prognosis. Most of the time, only slide-level label is available because pixel-wise annotation is labour intensive task. In this paper, we propose a deep learning pipeline for classification in histology images. Using multiple instance learning, we attempt to predict the latent membrane protein 1 (LMP1) status of nasopharyngeal carcinoma (NPC) based on haematoxylin and eosin-stain (H&E) histology images. We utilised attention mechanism with residual connection for our aggregation layers. In our 3-fold cross-validation experiment, we achieved average accuracy, AUC and F1-score 0.936, 0.995 and 0.862, respectively. This method also allows us to examine the model interpretability by visualising attention scores. To the best of our knowledge, this is the first attempt to predict LMP1 status on NPC using deep learning.
FrameHopper: Selective Processing of Video Frames in Detection-driven Real-Time Video Analytics
Mar 22, 2022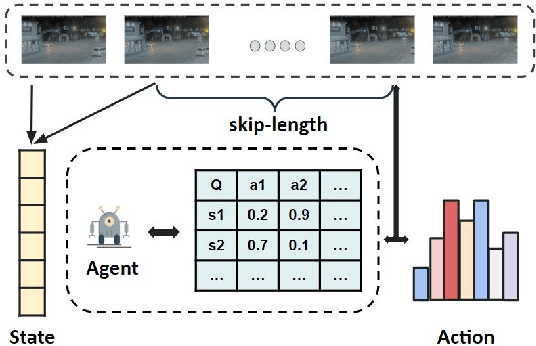
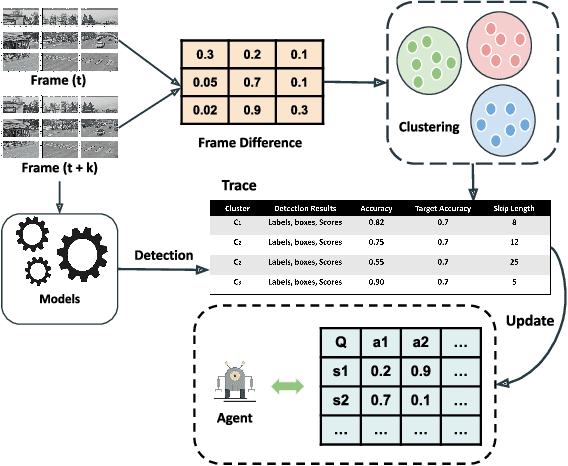
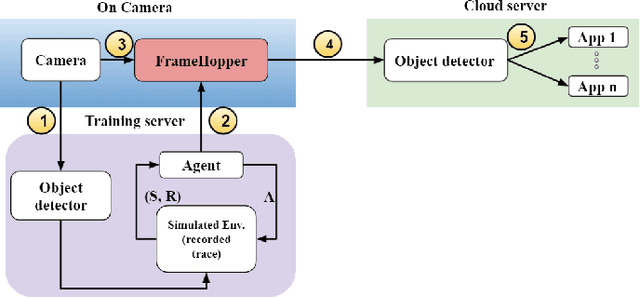

Detection-driven real-time video analytics require continuous detection of objects contained in the video frames using deep learning models like YOLOV3, EfficientDet. However, running these detectors on each and every frame in resource-constrained edge devices is computationally intensive. By taking the temporal correlation between consecutive video frames into account, we note that detection outputs tend to be overlapping in successive frames. Elimination of similar consecutive frames will lead to a negligible drop in performance while offering significant performance benefits by reducing overall computation and communication costs. The key technical questions are, therefore, (a) how to identify which frames to be processed by the object detector, and (b) how many successive frames can be skipped (called skip-length) once a frame is selected to be processed. The overall goal of the process is to keep the error due to skipping frames as small as possible. We introduce a novel error vs processing rate optimization problem with respect to the object detection task that balances between the error rate and the fraction of frames filtering. Subsequently, we propose an off-line Reinforcement Learning (RL)-based algorithm to determine these skip-lengths as a state-action policy of the RL agent from a recorded video and then deploy the agent online for live video streams. To this end, we develop FrameHopper, an edge-cloud collaborative video analytics framework, that runs a lightweight trained RL agent on the camera and passes filtered frames to the server where the object detection model runs for a set of applications. We have tested our approach on a number of live videos captured from real-life scenarios and show that FrameHopper processes only a handful of frames but produces detection results closer to the oracle solution and outperforms recent state-of-the-art solutions in most cases.
Dynamic MDETR: A Dynamic Multimodal Transformer Decoder for Visual Grounding
Sep 28, 2022

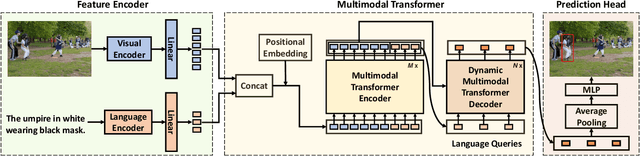
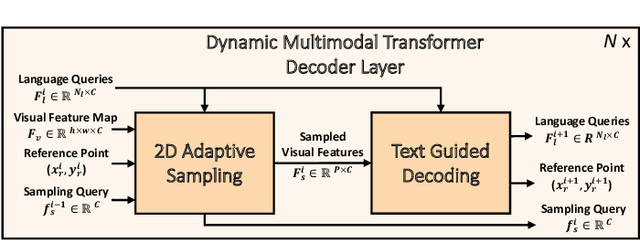
Multimodal transformer exhibits high capacity and flexibility to align image and text for visual grounding. However, the encoder-only grounding framework (e.g., TransVG) suffers from heavy computation due to the self-attention operation with quadratic time complexity. To address this issue, we present a new multimodal transformer architecture, coined as Dynamic MDETR, by decoupling the whole grounding process into encoding and decoding phases. The key observation is that there exists high spatial redundancy in images. Thus, we devise a new dynamic multimodal transformer decoder by exploiting this sparsity prior to speed up the visual grounding process. Specifically, our dynamic decoder is composed of a 2D adaptive sampling module and a text-guided decoding module. The sampling module aims to select these informative patches by predicting the offsets with respect to a reference point, while the decoding module works for extracting the grounded object information by performing cross attention between image features and text features. These two modules are stacked alternatively to gradually bridge the modality gap and iteratively refine the reference point of grounded object, eventually realizing the objective of visual grounding. Extensive experiments on five benchmarks demonstrate that our proposed Dynamic MDETR achieves competitive trade-offs between computation and accuracy. Notably, using only 9% feature points in the decoder, we can reduce ~44% GLOPs of the multimodal transformer, but still get higher accuracy than the encoder-only counterpart. In addition, to verify its generalization ability and scale up our Dynamic MDETR, we build the first one-stage CLIP empowered visual grounding framework, and achieve the state-of-the-art performance on these benchmarks.
A comprehensive survey on recent deep learning-based methods applied to surgical data
Sep 03, 2022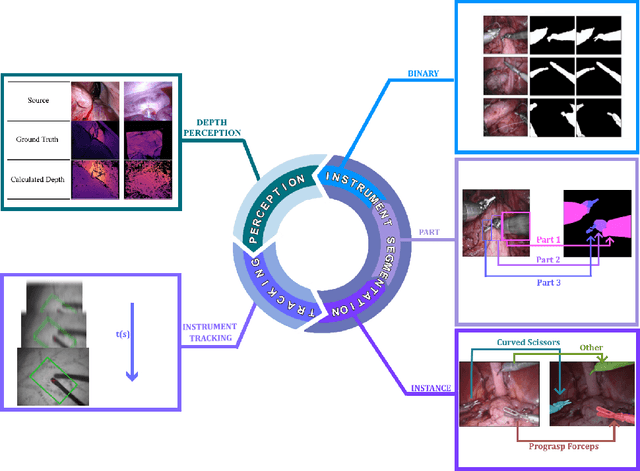

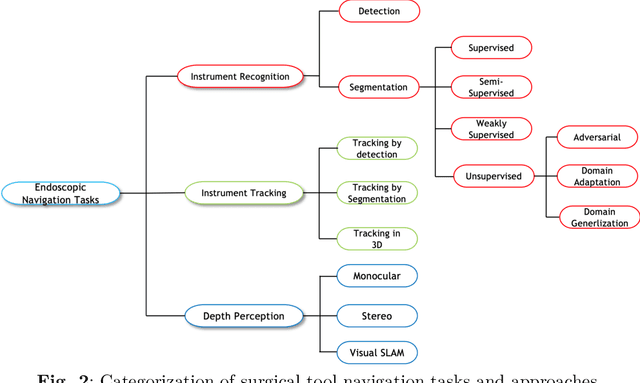
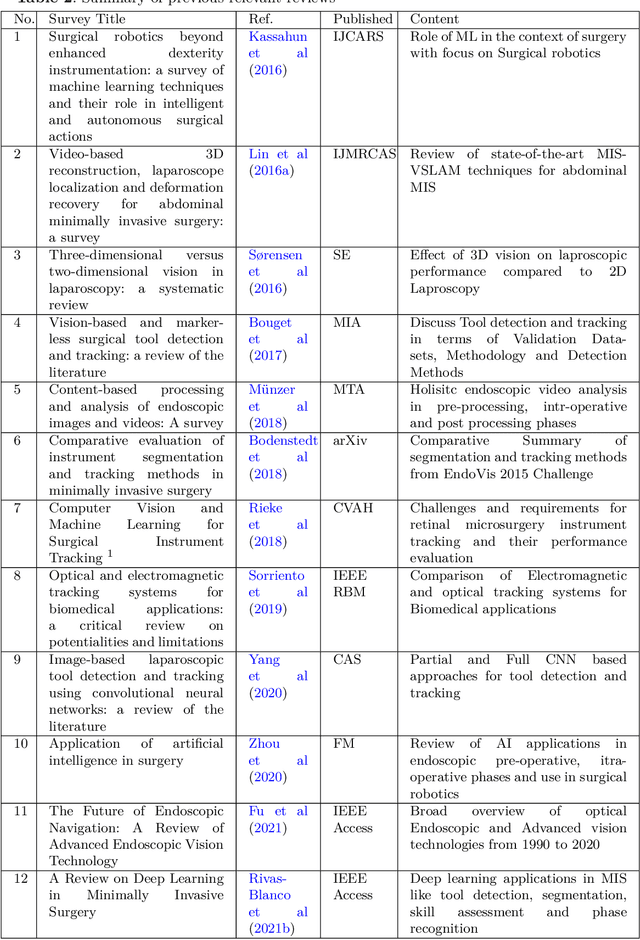
Minimally invasive surgery is highly operator dependant with lengthy procedural times causing fatigue and risk to patients. In order to mitigate these risks, real-time systems can help assist surgeons to navigate and track tools, by providing clear understanding of scene and avoid miscalculations during operation. While several efforts have been made in this direction, a lack of diverse datasets, as well as very dynamic scenes and its variability in each patient entails major hurdle in accomplishing robust systems. In this work, we present a systematic review of recent machine learning-based approaches including surgical tool localisation, segmentation, tracking and 3D scene perception. Furthermore, we present current gaps and directions of these invented methods and provide rational behind clinical integration of these approaches.
Deterministic and Stochastic Analysis of Deep Reinforcement Learning for Low Dimensional Sensing-based Navigation of Mobile Robots
Sep 13, 2022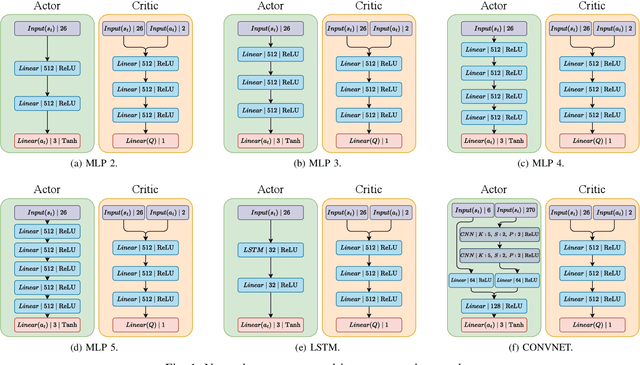
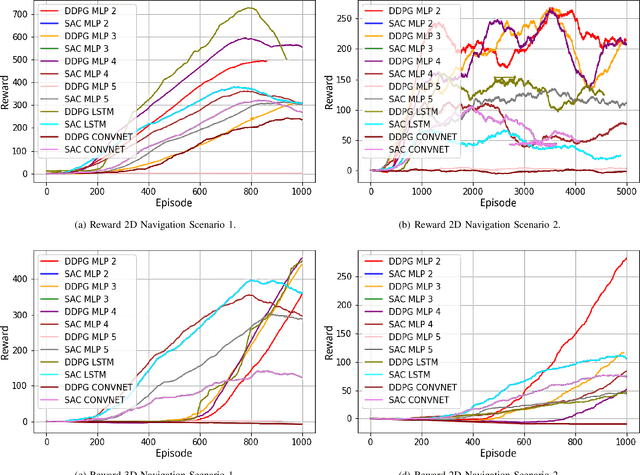
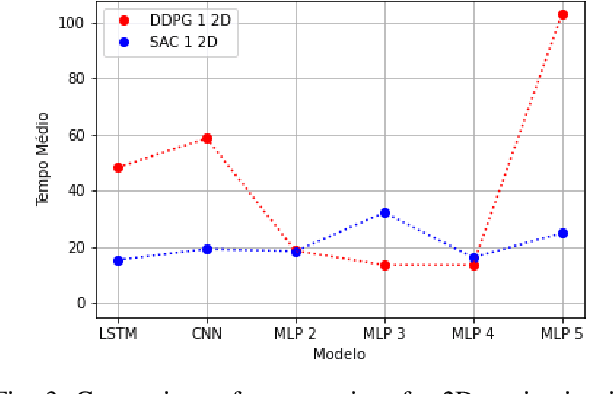
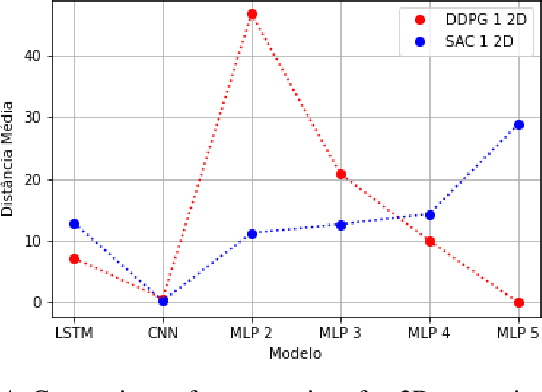
Deterministic and Stochastic techniques in Deep Reinforcement Learning (Deep-RL) have become a promising solution to improve motion control and the decision-making tasks for a wide variety of robots. Previous works showed that these Deep-RL algorithms can be applied to perform mapless navigation of mobile robots in general. However, they tend to use simple sensing strategies since it has been shown that they perform poorly with a high dimensional state spaces, such as the ones yielded from image-based sensing. This paper presents a comparative analysis of two Deep-RL techniques - Deep Deterministic Policy Gradients (DDPG) and Soft Actor-Critic (SAC) - when performing tasks of mapless navigation for mobile robots. We aim to contribute by showing how the neural network architecture influences the learning itself, presenting quantitative results based on the time and distance of navigation of aerial mobile robots for each approach. Overall, our analysis of six distinct architectures highlights that the stochastic approach (SAC) better suits with deeper architectures, while the opposite happens with the deterministic approach (DDPG).
That Slepen Al the Nyght with Open Ye! Cross-era Sequence Segmentation with Switch-memory
Sep 07, 2022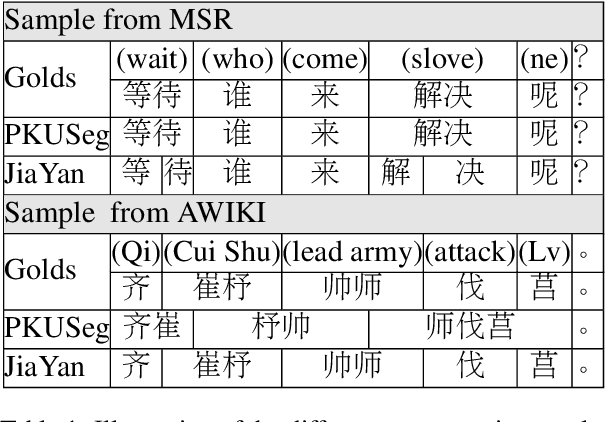
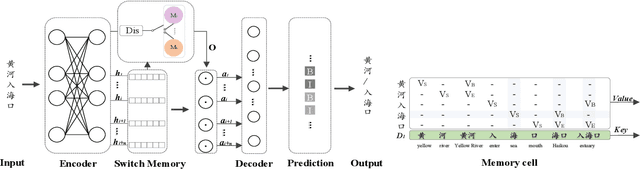

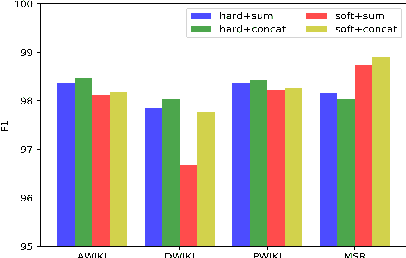
The evolution of language follows the rule of gradual change. Grammar, vocabulary, and lexical semantic shifts take place over time, resulting in a diachronic linguistic gap. As such, a considerable amount of texts are written in languages of different eras, which creates obstacles for natural language processing tasks, such as word segmentation and machine translation. Although the Chinese language has a long history, previous Chinese natural language processing research has primarily focused on tasks within a specific era. Therefore, we propose a cross-era learning framework for Chinese word segmentation (CWS), CROSSWISE, which uses the Switch-memory (SM) module to incorporate era-specific linguistic knowledge. Experiments on four corpora from different eras show that the performance of each corpus significantly improves. Further analyses also demonstrate that the SM can effectively integrate the knowledge of the eras into the neural network.
An Explainable Stacked Ensemble Model for Static Route-Free Estimation of Time of Arrival
Mar 17, 2022
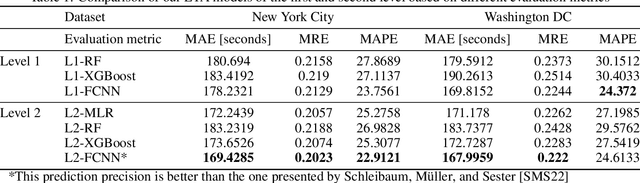
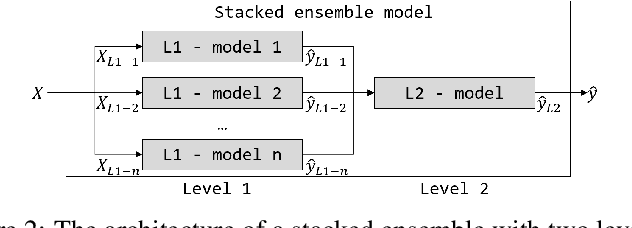
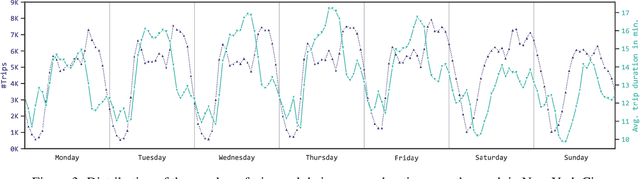
To compare alternative taxi schedules and to compute them, as well as to provide insights into an upcoming taxi trip to drivers and passengers, the duration of a trip or its Estimated Time of Arrival (ETA) is predicted. To reach a high prediction precision, machine learning models for ETA are state of the art. One yet unexploited option to further increase prediction precision is to combine multiple ETA models into an ensemble. While an increase of prediction precision is likely, the main drawback is that the predictions made by such an ensemble become less transparent due to the sophisticated ensemble architecture. One option to remedy this drawback is to apply eXplainable Artificial Intelligence (XAI). The contribution of this paper is three-fold. First, we combine multiple machine learning models from our previous work for ETA into a two-level ensemble model - a stacked ensemble model - which on its own is novel; therefore, we can outperform previous state-of-the-art static route-free ETA approaches. Second, we apply existing XAI methods to explain the first- and second-level models of the ensemble. Third, we propose three joining methods for combining the first-level explanations with the second-level ones. Those joining methods enable us to explain stacked ensembles for regression tasks. An experimental evaluation shows that the ETA models correctly learned the importance of those input features driving the prediction.