 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Truth-Table Net: A New Convolutional Architecture Encodable By Design Into SAT Formulas
Aug 18, 2022
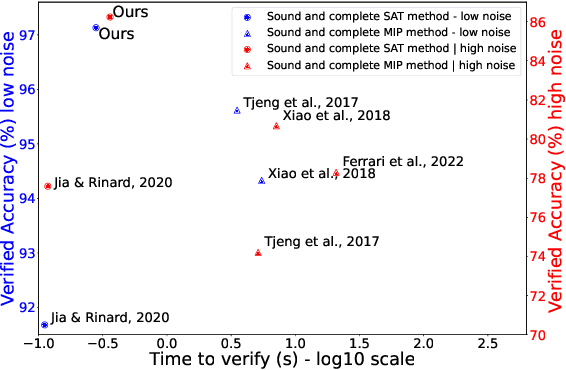
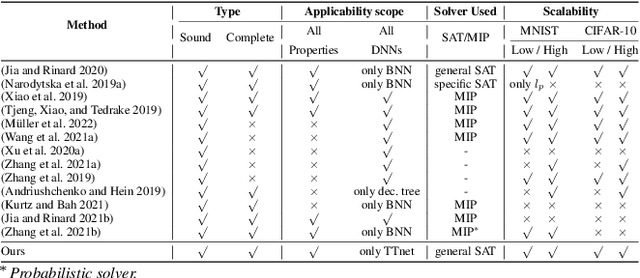
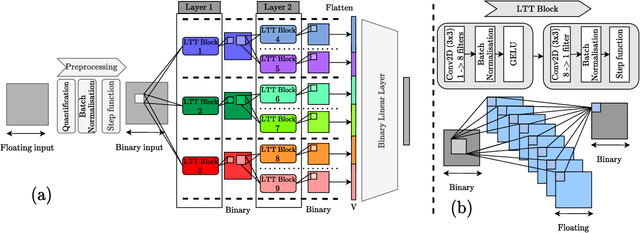
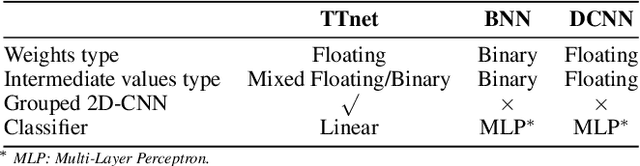
With the expanding role of neural networks, the need for complete and sound verification of their property has become critical. In the recent years, it was established that Binary Neural Networks (BNNs) have an equivalent representation in Boolean logic and can be formally analyzed using logical reasoning tools such as SAT solvers. However, to date, only BNNs can be transformed into a SAT formula. In this work, we introduce Truth Table Deep Convolutional Neural Networks (TTnets), a new family of SAT-encodable models featuring for the first time real-valued weights. Furthermore, it admits, by construction, some valuable conversion features including post-tuning and tractability in the robustness verification setting. The latter property leads to a more compact SAT symbolic encoding than BNNs. This enables the use of general SAT solvers, making property verification easier. We demonstrate the value of TTnets regarding the formal robustness property: TTnets outperform the verified accuracy of all BNNs with a comparable computation time. More generally, they represent a relevant trade-off between all known complete verification methods: TTnets achieve high verified accuracy with fast verification time, being complete with no timeouts. We are exploring here a proof of concept of TTnets for a very important application (complete verification of robustness) and we believe this novel real-valued network constitutes a practical response to the rising need for functional formal verification. We postulate that TTnets can apply to various CNN-based architectures and be extended to other properties such as fairness, fault attack and exact rule extraction.
PlaneSLAM: Plane-based LiDAR SLAM for Motion Planning in Structured 3D Environments
Sep 29, 2022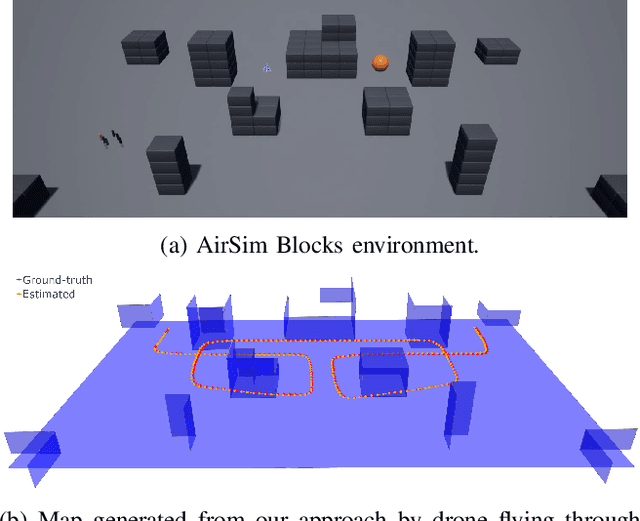
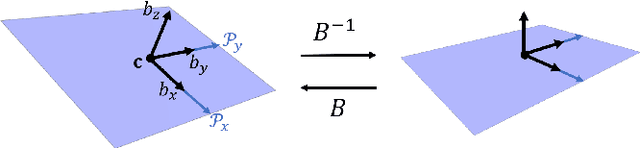
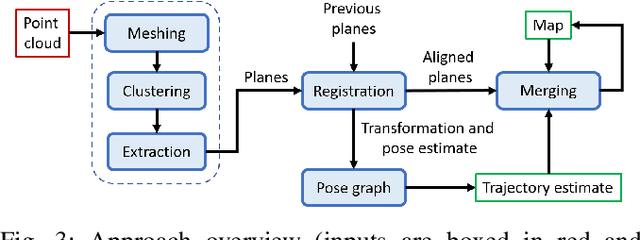
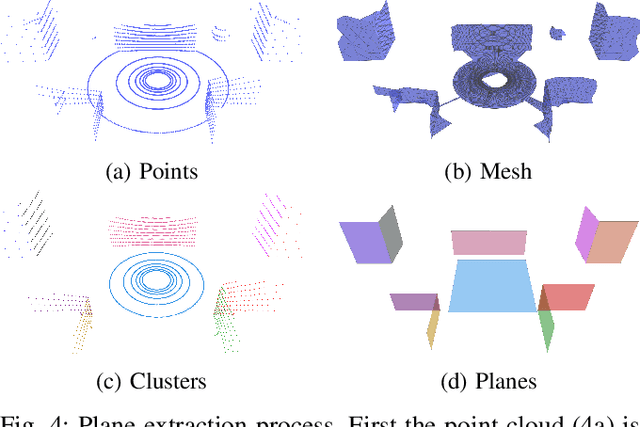
LiDAR sensors are a powerful tool for robot simultaneous localization and mapping (SLAM) in unknown environments, but the raw point clouds they produce are dense, computationally expensive to store, and unsuited for direct use by downstream autonomy tasks, such as motion planning. For integration with motion planning, it is desirable for SLAM pipelines to generate lightweight geometric map representations. Such representations are also particularly well-suited for man-made environments, which can often be viewed as a so-called "Manhattan world" built on a Cartesian grid. In this work we present a 3D LiDAR SLAM algorithm for Manhattan world environments which extracts planar features from point clouds to achieve lightweight, real-time localization and mapping. Our approach generates plane-based maps which occupy significantly less memory than their point cloud equivalents, and are suited towards fast collision checking for motion planning. By leveraging the Manhattan world assumption, we target extraction of orthogonal planes to generate maps which are more structured and organized than those of existing plane-based LiDAR SLAM approaches. We demonstrate our approach in the high-fidelity AirSim simulator and in real-world experiments with a ground rover equipped with a Velodyne LiDAR. For both cases, we are able to generate high quality maps and trajectory estimates at a rate matching the sensor rate of 10 Hz.
Exploration, Path Planning with Obstacle and Collision Avoidance in a Dynamic Environment
Aug 19, 2022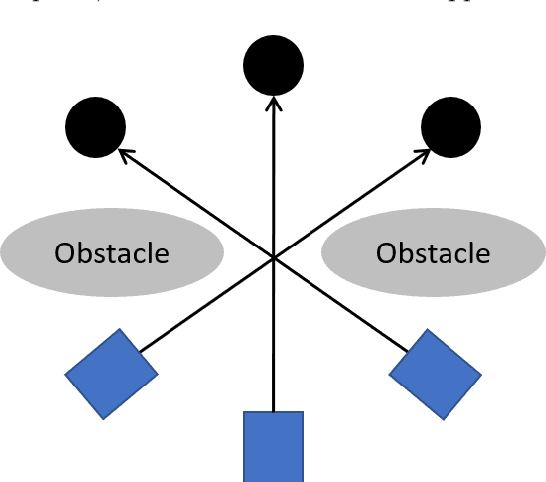

If we give a robot the task of moving an object from its current position to another location in an unknown environment, the robot must explore the map, identify all types of obstacles, and then determine the best route to complete the task. We proposed a mathematical model to find an optimal path planning that avoids collisions with all static and moving obstacles and has the minimum completion time and the minimum distance traveled. In this model, the bounding box around obstacles and robots is not considered, so the robot can move very close to the obstacles without colliding with them. We considered two types of obstacles: deterministic, which include all static obstacles such as walls that do not move and all moving obstacles whose movements have a fixed pattern, and non-deterministic, which include all obstacles whose movements can occur in any direction with some probability distribution at any time. We also consider the acceleration and deceleration of the robot to improve collision avoidance.
Volumetric-based Contact Point Detection for 7-DoF Grasping
Sep 14, 2022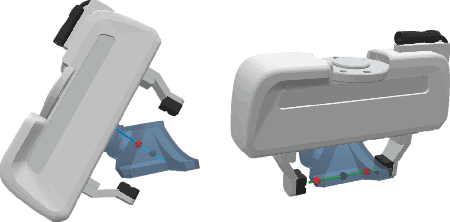
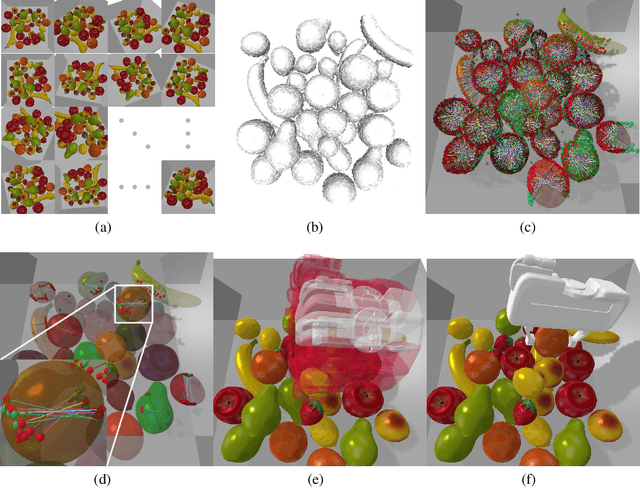
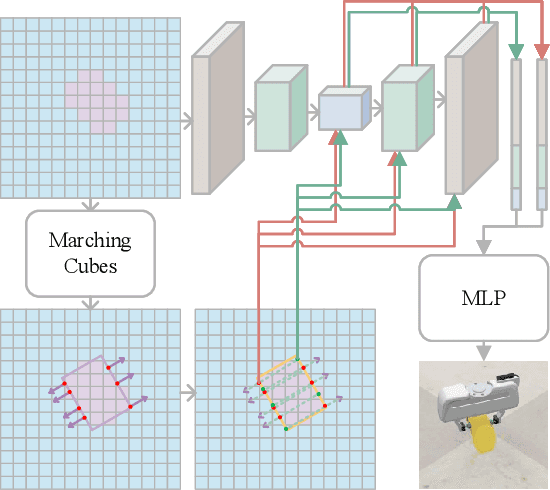
In this paper, we propose a novel grasp pipeline based on contact point detection on the truncated signed distance function (TSDF) volume to achieve closed-loop 7-degree-of-freedom (7-DoF) grasping on cluttered environments. The key aspects of our method are that 1) the proposed pipeline exploits the TSDF volume in terms of multi-view fusion, contact-point sampling and evaluation, and collision checking, which provides reliable and collision-free 7-DoF gripper poses with real-time performance; 2) the contact-based pose representation effectively eliminates the ambiguity introduced by the normal-based methods, which provides a more precise and flexible solution. Extensive simulated and real-robot experiments demonstrate that the proposed pipeline can select more antipodal and stable grasp poses and outperforms normal-based baselines in terms of the grasp success rate in both simulated and physical scenarios.
Advance quantum image representation and compression using DCTEFRQI approach
Aug 30, 2022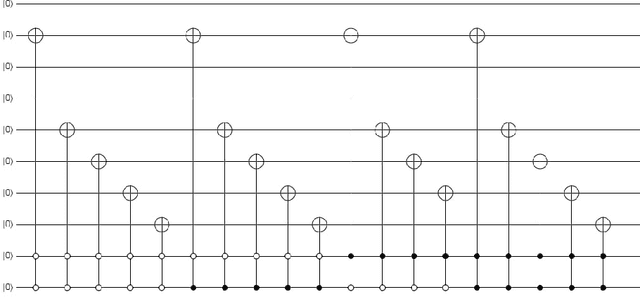
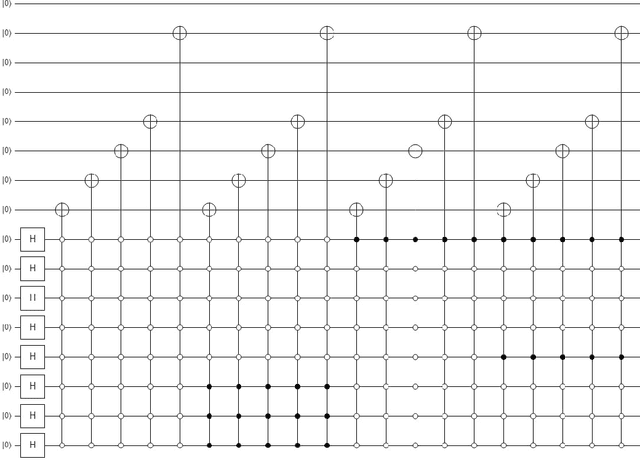
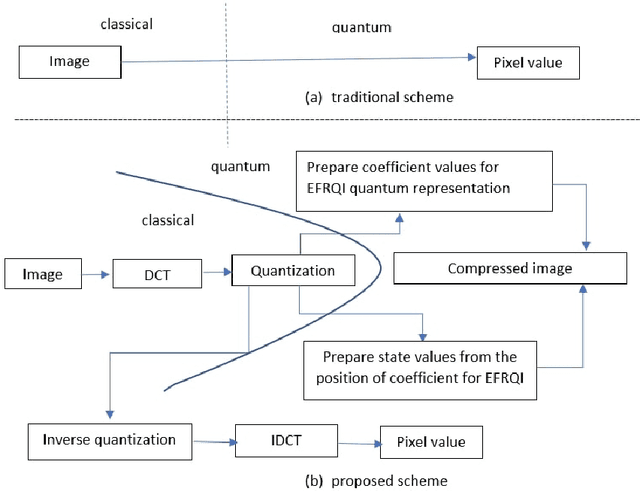
In recent year, quantum image processing got a lot of attention in the field of image processing due to opportunity to place huge image data in quantum Hilbert space. Hilbert space or Euclidean space has infinite dimension to locate and process the image data faster. Moreover, several researches show that, the computational time of quantum process is faster than classical computer. By encoding and compressing the image in quantum domain is still challenging issue. From literature survey, we have proposed a DCTEFRQI (Direct Cosine Transform Efficient Flexible Representation of Quantum Image) algorithm to represent and compress gray image efficiently which save computational time and minimize the complexity of preparation. The objective of this work is to represent and compress various gray image size in quantum computer using DCT(Discrete Cosine Transform) and EFRQI (Efficient Flexible Representation of Quantum Image) approach together. Quirk simulation tool is used to design corresponding quantum image circuit. Due to limitation of qubit, total 16 numbers of qubit are used to represent the gray scale image among those 8 are used to map the coefficient values and the rest 8 are used to generate the corresponding coefficient position. Theoretical analysis and experimental result show that, proposed DCTEFRQI scheme provides better representation and compression compare to DCT-GQIR, DWT-GQIR and DWT-EFRQI in terms of PSNR(Peak Signal to Noise Ratio) and bit rate..
Computing Abductive Explanations for Boosted Trees
Sep 16, 2022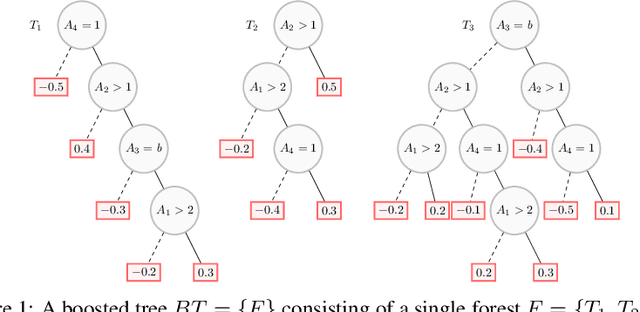

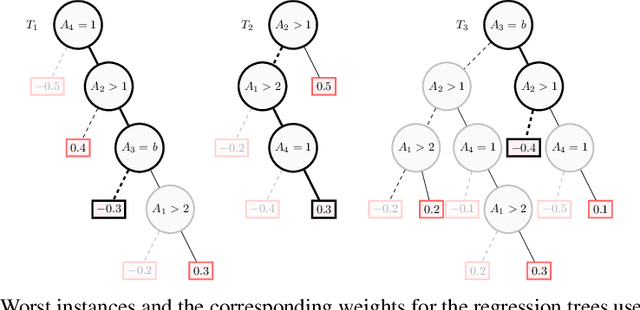
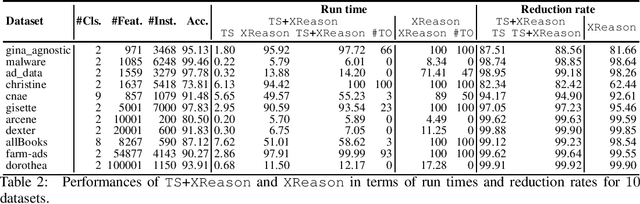
Boosted trees is a dominant ML model, exhibiting high accuracy. However, boosted trees are hardly intelligible, and this is a problem whenever they are used in safety-critical applications. Indeed, in such a context, rigorous explanations of the predictions made are expected. Recent work have shown how subset-minimal abductive explanations can be derived for boosted trees, using automated reasoning techniques. However, the generation of such well-founded explanations is intractable in the general case. To improve the scalability of their generation, we introduce the notion of tree-specific explanation for a boosted tree. We show that tree-specific explanations are abductive explanations that can be computed in polynomial time. We also explain how to derive a subset-minimal abductive explanation from a tree-specific explanation. Experiments on various datasets show the computational benefits of leveraging tree-specific explanations for deriving subset-minimal abductive explanations.
Automatic Rule Generation for Time Expression Normalization
Aug 31, 2021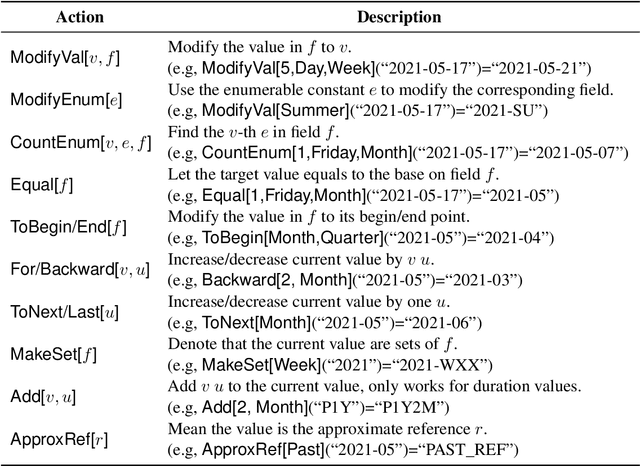
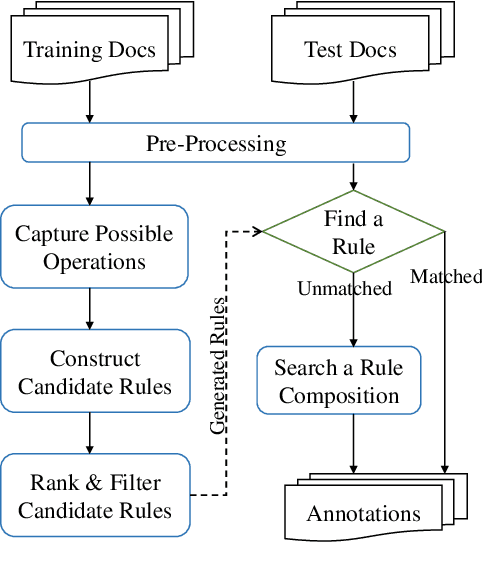

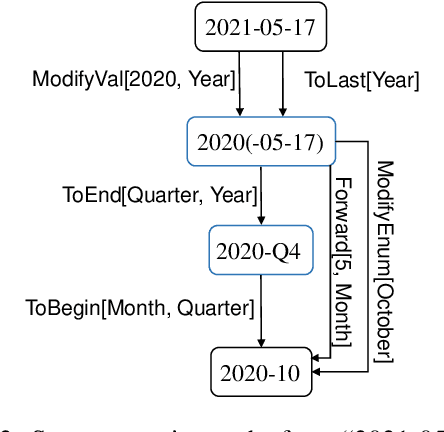
The understanding of time expressions includes two sub-tasks: recognition and normalization. In recent years, significant progress has been made in the recognition of time expressions while research on normalization has lagged behind. Existing SOTA normalization methods highly rely on rules or grammars designed by experts, which limits their performance on emerging corpora, such as social media texts. In this paper, we model time expression normalization as a sequence of operations to construct the normalized temporal value, and we present a novel method called ARTime, which can automatically generate normalization rules from training data without expert interventions. Specifically, ARTime automatically captures possible operation sequences from annotated data and generates normalization rules on time expressions with common surface forms. The experimental results show that ARTime can significantly surpass SOTA methods on the Tweets benchmark, and achieves competitive results with existing expert-engineered rule methods on the TempEval-3 benchmark.
Hierarchical Collision Avoidance for Adaptive-Speed Multirotor Teleoperation
Sep 17, 2022
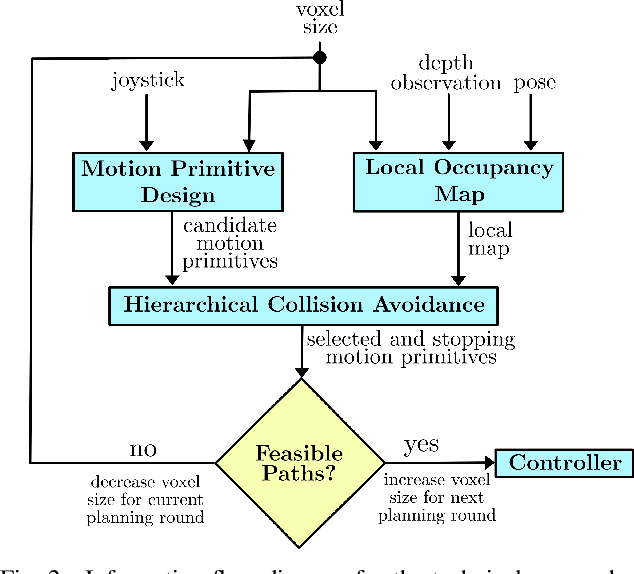
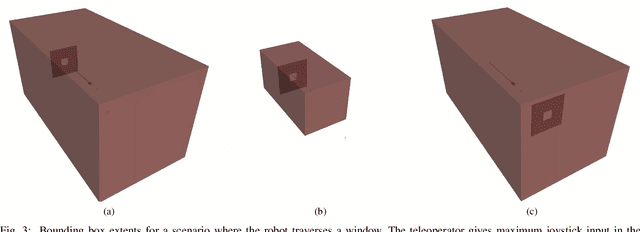

This paper improves safe motion primitives-based teleoperation of a multirotor by developing a hierarchical collision avoidance method that modulates maximum speed based on environment complexity and perceptual constraints. Safe speed modulation is challenging in environments that exhibit varying clutter. Existing methods fix maximum speed and map resolution, which prevents vehicles from accessing tight spaces and places the cognitive load for changing speed on the operator. We address these gaps by proposing a high-rate (10 Hz) teleoperation approach that modulates the maximum vehicle speed through hierarchical collision checking. The hierarchical collision checker simultaneously adapts the local map's voxel size and maximum vehicle speed to ensure motion planning safety. The proposed methodology is evaluated in simulation and real-world experiments and compared to a non-adaptive motion primitives-based teleoperation approach. The results demonstrate the advantages of the proposed teleoperation approach both in time taken and the ability to complete the task without requiring the user to specify a maximum vehicle speed.
Towards Frame Rate Agnostic Multi-Object Tracking
Oct 07, 2022

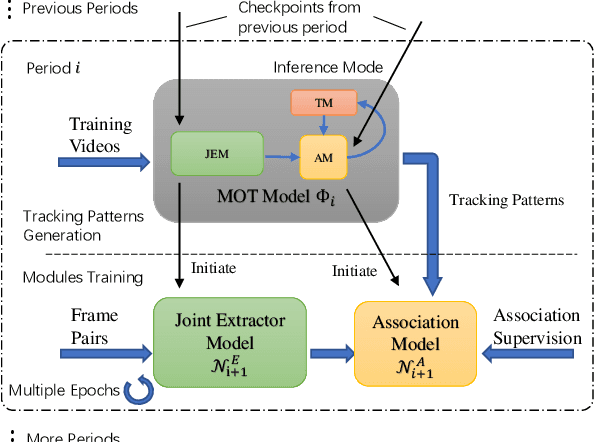
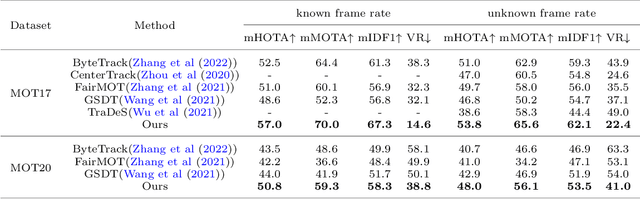
Multi-Object Tracking (MOT) is one of the most fundamental computer vision tasks which contributes to a variety of video analysis applications. Despite the recent promising progress, current MOT research is still limited to a fixed sampling frame rate of the input stream. In fact, we empirically find that the accuracy of all recent state-of-the-art trackers drops dramatically when the input frame rate changes. For a more intelligent tracking solution, we shift the attention of our research work to the problem of Frame Rate Agnostic MOT (FraMOT). In this paper, we propose a Frame Rate Agnostic MOT framework with Periodic training Scheme (FAPS) to tackle the FraMOT problem for the first time. Specifically, we propose a Frame Rate Agnostic Association Module (FAAM) that infers and encodes the frame rate information to aid identity matching across multi-frame-rate inputs, improving the capability of the learned model in handling complex motion-appearance relations in FraMOT. Besides, the association gap between training and inference is enlarged in FraMOT because those post-processing steps not included in training make a larger difference in lower frame rate scenarios. To address it, we propose Periodic Training Scheme (PTS) to reflect all post-processing steps in training via tracking pattern matching and fusion. Along with the proposed approaches, we make the first attempt to establish an evaluation method for this new task of FraMOT in two different modes, i.e., known frame rate and unknown frame rate, aiming to handle a more complex situation. The quantitative experiments on the challenging MOT datasets (FraMOT version) have clearly demonstrated that the proposed approaches can handle different frame rates better and thus improve the robustness against complicated scenarios.
In the realm of hybrid Brain: Human Brain and AI
Oct 07, 2022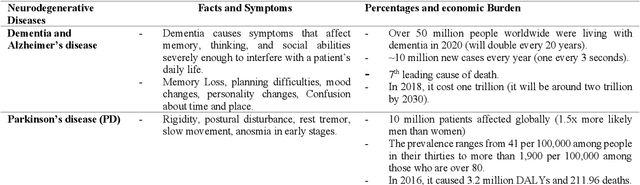
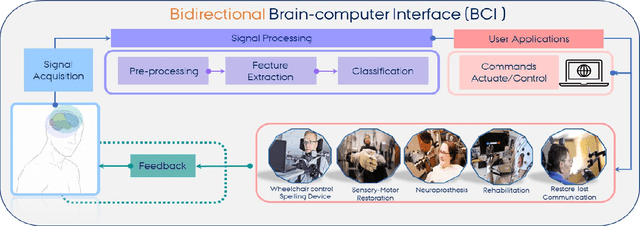
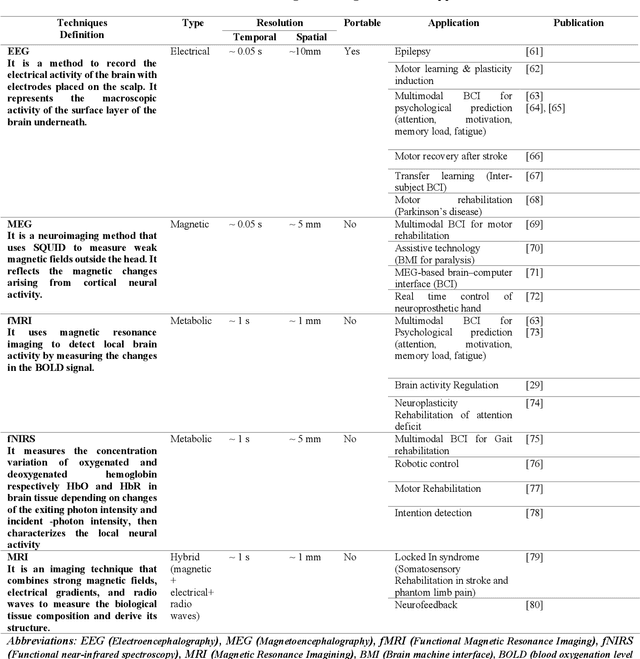
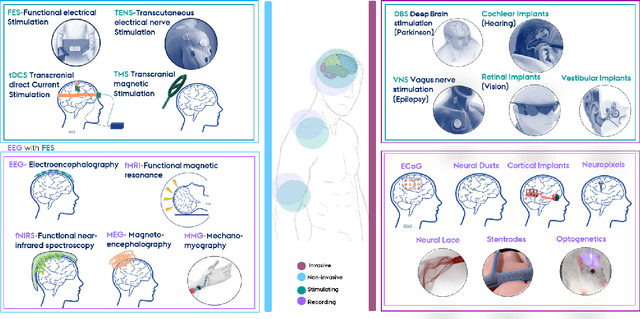
With the recent developments in neuroscience and engineering, it is now possible to record brain signals and decode them. Also, a growing number of stimulation methods have emerged to modulate and influence brain activity. Current brain-computer interface (BCI) technology is mainly on therapeutic outcomes, it already demonstrated its efficiency as assistive and rehabilitative technology for patients with severe motor impairments. Recently, artificial intelligence (AI) and machine learning (ML) technologies have been used to decode brain signals. Beyond this progress, combining AI with advanced BCIs in the form of implantable neurotechnologies grants new possibilities for the diagnosis, prediction, and treatment of neurological and psychiatric disorders. In this context, we envision the development of closed loop, intelligent, low-power, and miniaturized neural interfaces that will use brain inspired AI techniques with neuromorphic hardware to process the data from the brain. This will be referred to as Brain Inspired Brain Computer Interfaces (BI-BCIs). Such neural interfaces would offer access to deeper brain regions and better understanding for brain's functions and working mechanism, which improves BCIs operative stability and system's efficiency. On one hand, brain inspired AI algorithms represented by spiking neural networks (SNNs) would be used to interpret the multimodal neural signals in the BCI system. On the other hand, due to the ability of SNNs to capture rich dynamics of biological neurons and to represent and integrate different information dimensions such as time, frequency, and phase, it would be used to model and encode complex information processing in the brain and to provide feedback to the users. This paper provides an overview of the different methods to interface with the brain, presents future applications and discusses the merger of AI and BCIs.