 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Two-stream Convolutional Network for Musculoskeletal and Neurological Disorders Prediction
Aug 18, 2022

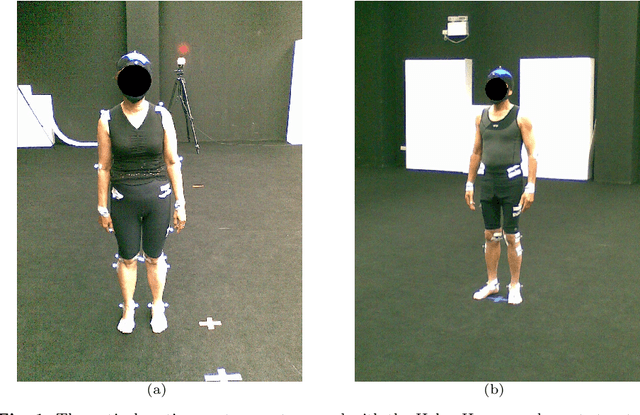
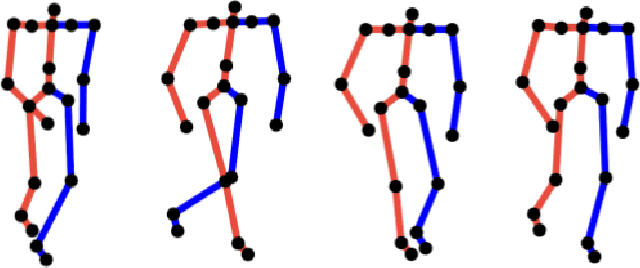

Musculoskeletal and neurological disorders are the most common causes of walking problems among older people, and they often lead to diminished quality of life. Analyzing walking motion data manually requires trained professionals and the evaluations may not always be objective. To facilitate early diagnosis, recent deep learning-based methods have shown promising results for automated analysis, which can discover patterns that have not been found in traditional machine learning methods. We observe that existing work mostly applies deep learning on individual joint features such as the time series of joint positions. Due to the challenge of discovering inter-joint features such as the distance between feet (i.e. the stride width) from generally smaller-scale medical datasets, these methods usually perform sub-optimally. As a result, we propose a solution that explicitly takes both individual joint features and inter-joint features as input, relieving the system from the need of discovering more complicated features from small data. Due to the distinctive nature of the two types of features, we introduce a two-stream framework, with one stream learning from the time series of joint position and the other from the time series of relative joint displacement. We further develop a mid-layer fusion module to combine the discovered patterns in these two streams for diagnosis, which results in a complementary representation of the data for better prediction performance. We validate our system with a benchmark dataset of 3D skeleton motion that involves 45 patients with musculoskeletal and neurological disorders, and achieve a prediction accuracy of 95.56%, outperforming state-of-the-art methods.
TrustToken, a Trusted SoC solution for Non-Trusted Intellectual Property (IP)s
Sep 26, 2022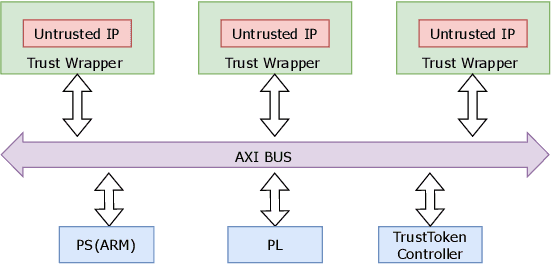

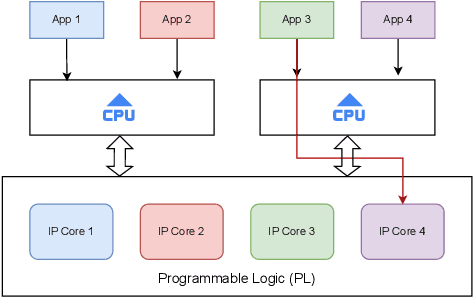
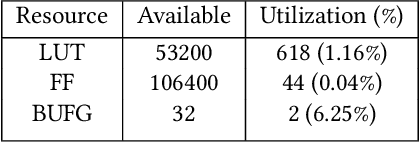
Secure and trustworthy execution in heterogeneous SoCs is a major priority in the modern computing system. Security of SoCs mainly addresses two broad layers of trust issues: 1. Protection against hardware security threats(Side-channel, IP Privacy, Cloning, Fault Injection, and Denial of Service); and 2. Protection against malicious software attacks running on SoC processors. To resist malicious software-level attackers from gaining unauthorized access and compromising security, we propose a root of trust-based trusted execution mechanism \textbf{\textit{(named as \textbf{TrustToken}) }}. TrustToken builds a security block to provide a root of trust-based IP security: secure key generation and truly random source. \textbf{TrustToken} only allows trusted communication between the non-trusted third-party IP and the rest of the SoC world by providing essential security features, i.e., secure, isolated execution, and trusted user interaction. The proposed design achieves this by interconnecting the third-party IP interface to \textbf{TrustToken} Controller and checking IP authorization(Token) signals \texttt{`correctness'} at run-time. \textbf{TrustToken} architecture shows a very low overhead resource utilization LUT (618, 1.16 \%), FF (44, 0.04 \%), and BUFG (2 , 6.25\%) in implementation. The experiment results show that TrustToken can provide a secure, low-cost, and trusted solution for non-trusted SoC IPs.
Surrogate Modeling of Melt Pool Thermal Field using Deep Learning
Aug 04, 2022
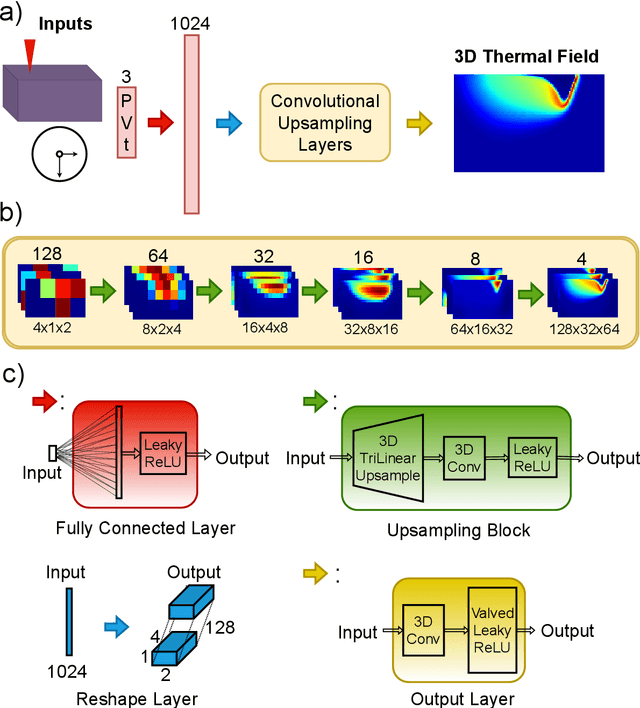
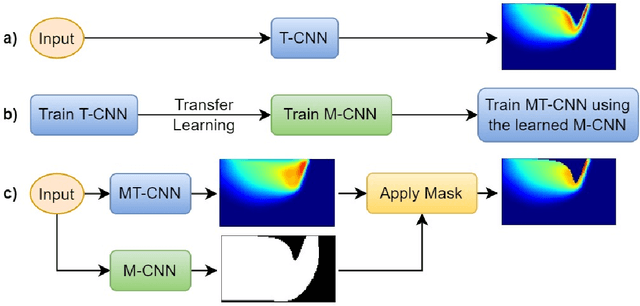
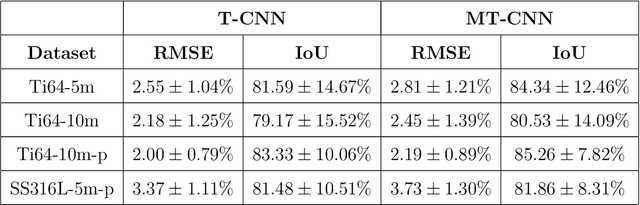
Powder-based additive manufacturing has transformed the manufacturing industry over the last decade. In Laser Powder Bed Fusion, a specific part is built in an iterative manner in which two-dimensional cross-sections are formed on top of each other by melting and fusing the proper areas of the powder bed. In this process, the behavior of the melt pool and its thermal field has a very important role in predicting the quality of the manufactured part and its possible defects. However, the simulation of such a complex phenomenon is usually very time-consuming and requires huge computational resources. Flow-3D is one of the software packages capable of executing such simulations using iterative numerical solvers. In this work, we create three datasets of single-trail processes using Flow-3D and use them to train a convolutional neural network capable of predicting the behavior of the three-dimensional thermal field of the melt pool solely by taking three parameters as input: laser power, laser velocity, and time step. The CNN achieves a relative Root Mean Squared Error of 2% to 3% for the temperature field and an average Intersection over Union score of 80% to 90% in predicting the melt pool area. Moreover, since time is included as one of the inputs of the model, the thermal field can be instantly obtained for any arbitrary time step without the need to iterate and compute all the steps
The Influence of Learning Rule on Representation Dynamics in Wide Neural Networks
Oct 05, 2022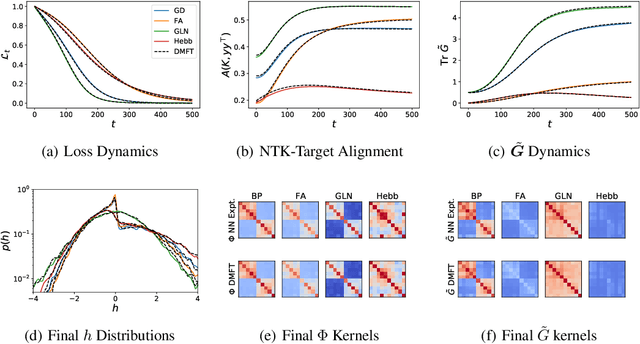
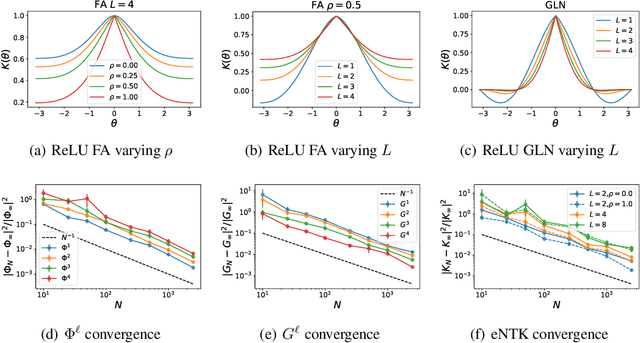

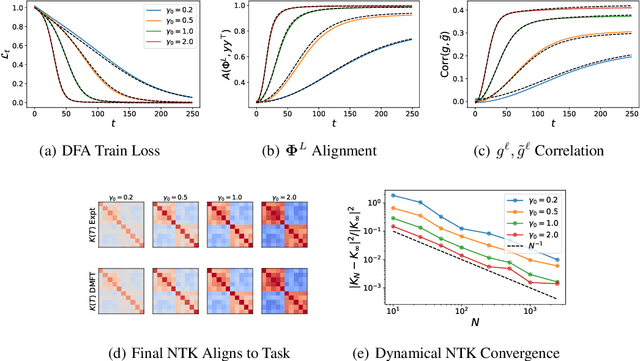
It is unclear how changing the learning rule of a deep neural network alters its learning dynamics and representations. To gain insight into the relationship between learned features, function approximation, and the learning rule, we analyze infinite-width deep networks trained with gradient descent (GD) and biologically-plausible alternatives including feedback alignment (FA), direct feedback alignment (DFA), and error modulated Hebbian learning (Hebb), as well as gated linear networks (GLN). We show that, for each of these learning rules, the evolution of the output function at infinite width is governed by a time varying effective neural tangent kernel (eNTK). In the lazy training limit, this eNTK is static and does not evolve, while in the rich mean-field regime this kernel's evolution can be determined self-consistently with dynamical mean field theory (DMFT). This DMFT enables comparisons of the feature and prediction dynamics induced by each of these learning rules. In the lazy limit, we find that DFA and Hebb can only learn using the last layer features, while full FA can utilize earlier layers with a scale determined by the initial correlation between feedforward and feedback weight matrices. In the rich regime, DFA and FA utilize a temporally evolving and depth-dependent NTK. Counterintuitively, we find that FA networks trained in the rich regime exhibit more feature learning if initialized with smaller correlation between the forward and backward pass weights. GLNs admit a very simple formula for their lazy limit kernel and preserve conditional Gaussianity of their preactivations under gating functions. Error modulated Hebb rules show very small task-relevant alignment of their kernels and perform most task relevant learning in the last layer.
Time Encoding of Finite-Rate-of-Innovation Signals
Aug 12, 2021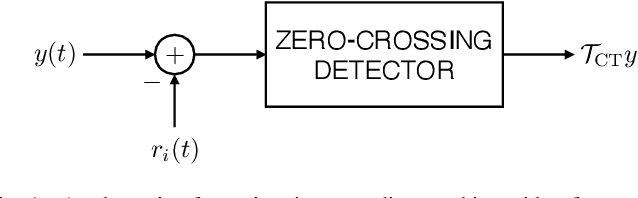
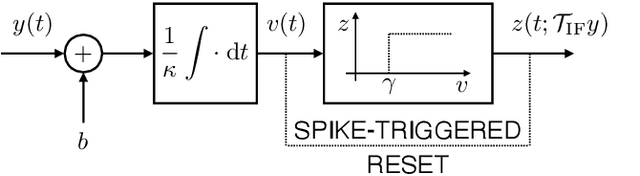
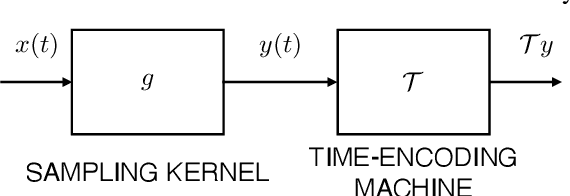
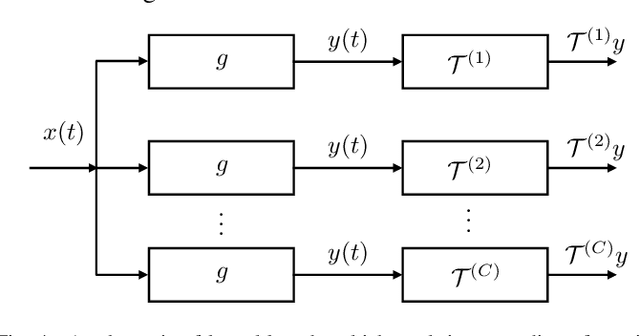
Time-encoding of continuous-time signals is an alternative sampling paradigm to conventional methods such as Shannon's sampling. In time-encoding, the signal is encoded using a sequence of time instants where an event occurs, and hence fall under event-driven sampling methods. Time-encoding can be designed agnostic to the global clock of the sampling hardware, which makes sampling asynchronous. Moreover, the encoding is sparse. This makes time-encoding energy efficient. However, the signal representation is nonstandard and in general, nonuniform. In this paper, we consider time-encoding of finite-rate-of-innovation signals, and in particular, periodic signals composed of weighted and time-shifted versions of a known pulse. We consider encoding using both crossing-time-encoding machine (C-TEM) and integrate-and-fire time-encoding machine (IF-TEM). We analyze how time-encoding manifests in the Fourier domain and arrive at the familiar sum-of-sinusoids structure of the Fourier coefficients that can be obtained starting from the time-encoded measurements via a suitable linear transformation. Thereafter, standard FRI techniques become applicable. Further, we extend the theory to multichannel time-encoding such that each channel operates with a lower sampling requirement. We also study the effect of measurement noise, where the temporal measurements are perturbed by additive noise. To combat the effect of noise, we propose a robust optimization framework to simultaneously denoise the Fourier coefficients and estimate the annihilating filter accurately. We provide sufficient conditions for time-encoding and perfect reconstruction using C-TEM and IF-TEM, and furnish extensive simulations to substantiate our findings.
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
Jan 18, 2022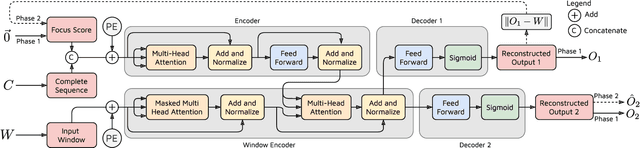
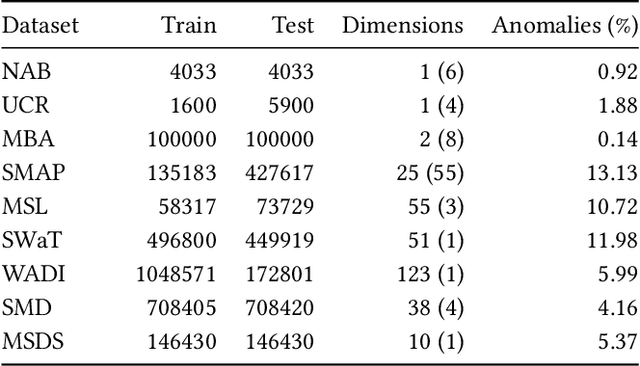
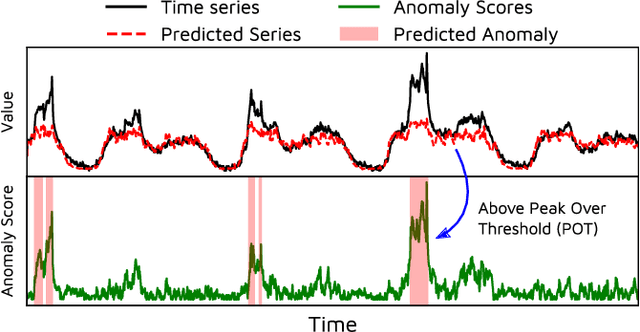
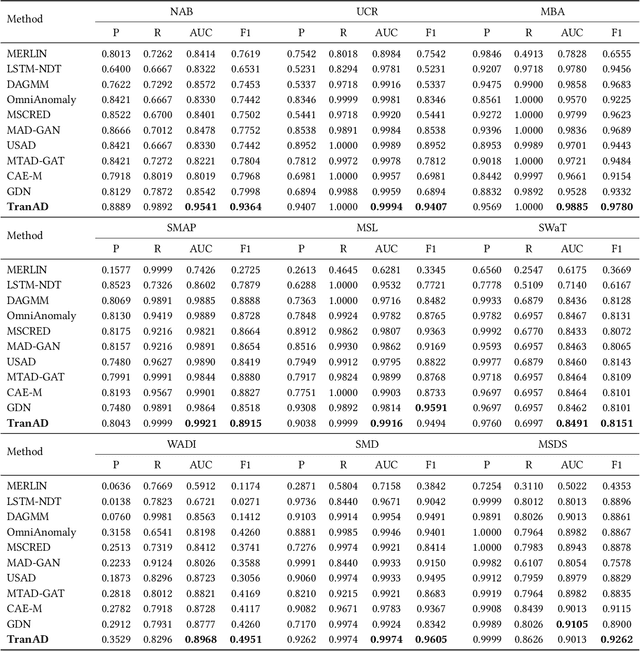
Efficient anomaly detection and diagnosis in multivariate time-series data is of great importance for modern industrial applications. However, building a system that is able to quickly and accurately pinpoint anomalous observations is a challenging problem. This is due to the lack of anomaly labels, high data volatility and the demands of ultra-low inference times in modern applications. Despite the recent developments of deep learning approaches for anomaly detection, only a few of them can address all of these challenges. In this paper, we propose TranAD, a deep transformer network based anomaly detection and diagnosis model which uses attention-based sequence encoders to swiftly perform inference with the knowledge of the broader temporal trends in the data. TranAD uses focus score-based self-conditioning to enable robust multi-modal feature extraction and adversarial training to gain stability. Additionally, model-agnostic meta learning (MAML) allows us to train the model using limited data. Extensive empirical studies on six publicly available datasets demonstrate that TranAD can outperform state-of-the-art baseline methods in detection and diagnosis performance with data and time-efficient training. Specifically, TranAD increases F1 scores by up to 17%, reducing training times by up to 99% compared to the baselines.
Out-of-Distribution Detection with Hilbert-Schmidt Independence Optimization
Sep 26, 2022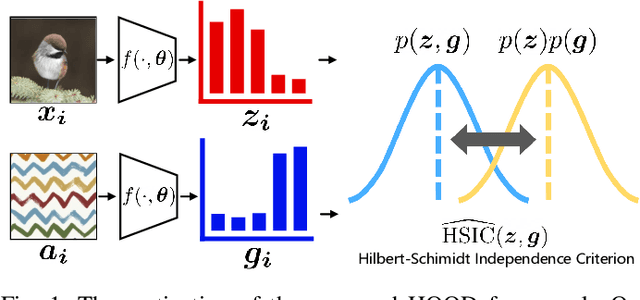
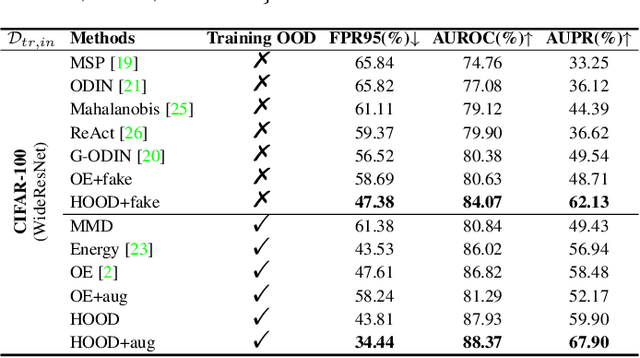
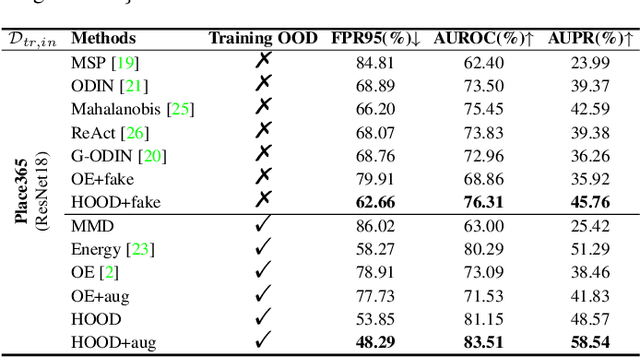
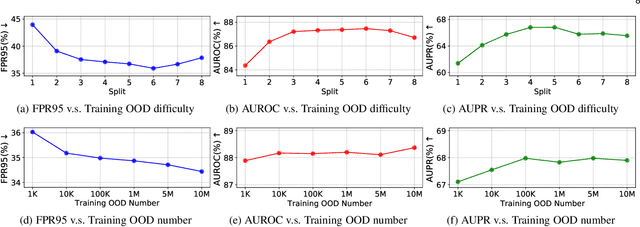
Outlier detection tasks have been playing a critical role in AI safety. There has been a great challenge to deal with this task. Observations show that deep neural network classifiers usually tend to incorrectly classify out-of-distribution (OOD) inputs into in-distribution classes with high confidence. Existing works attempt to solve the problem by explicitly imposing uncertainty on classifiers when OOD inputs are exposed to the classifier during training. In this paper, we propose an alternative probabilistic paradigm that is both practically useful and theoretically viable for the OOD detection tasks. Particularly, we impose statistical independence between inlier and outlier data during training, in order to ensure that inlier data reveals little information about OOD data to the deep estimator during training. Specifically, we estimate the statistical dependence between inlier and outlier data through the Hilbert-Schmidt Independence Criterion (HSIC), and we penalize such metric during training. We also associate our approach with a novel statistical test during the inference time coupled with our principled motivation. Empirical results show that our method is effective and robust for OOD detection on various benchmarks. In comparison to SOTA models, our approach achieves significant improvement regarding FPR95, AUROC, and AUPR metrics. Code is available: \url{https://github.com/jylins/hood}.
Bidirectional Language Models Are Also Few-shot Learners
Sep 29, 2022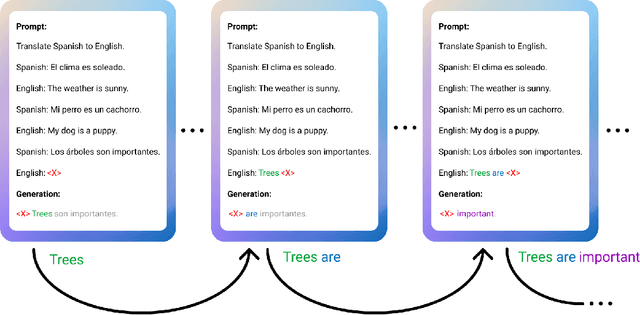

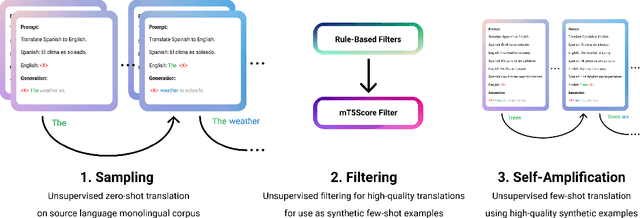
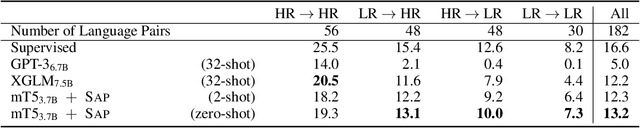
Large language models such as GPT-3 (Brown et al., 2020) can perform arbitrary tasks without undergoing fine-tuning after being prompted with only a few labeled examples. An arbitrary task can be reformulated as a natural language prompt, and a language model can be asked to generate the completion, indirectly performing the task in a paradigm known as prompt-based learning. To date, emergent prompt-based learning capabilities have mainly been demonstrated for unidirectional language models. However, bidirectional language models pre-trained on denoising objectives such as masked language modeling produce stronger learned representations for transfer learning. This motivates the possibility of prompting bidirectional models, but their pre-training objectives have made them largely incompatible with the existing prompting paradigm. We present SAP (Sequential Autoregressive Prompting), a technique that enables the prompting of bidirectional models. Utilizing the machine translation task as a case study, we prompt the bidirectional mT5 model (Xue et al., 2021) with SAP and demonstrate its few-shot and zero-shot translations outperform the few-shot translations of unidirectional models like GPT-3 and XGLM (Lin et al., 2021), despite mT5's approximately 50% fewer parameters. We further show SAP is effective on question answering and summarization. For the first time, our results demonstrate prompt-based learning is an emergent property of a broader class of language models, rather than only unidirectional models.
Energy Minimization in RIS-Assisted UAV-Enabled Wireless Power Transfer Systems
Aug 18, 2022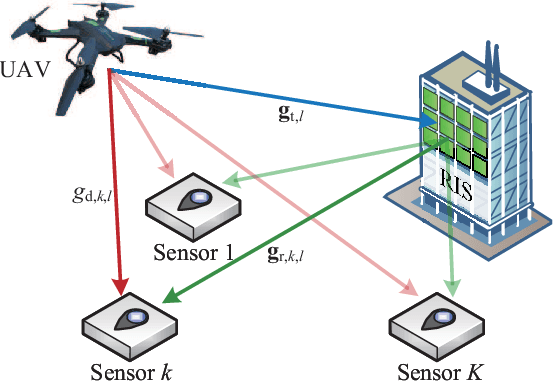
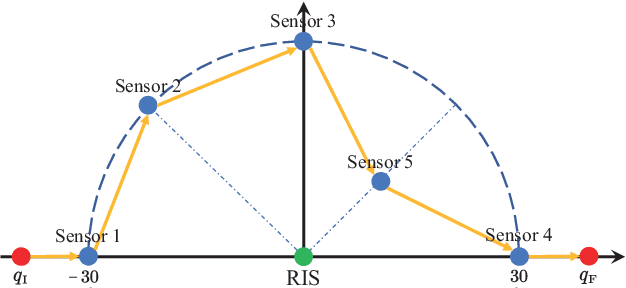
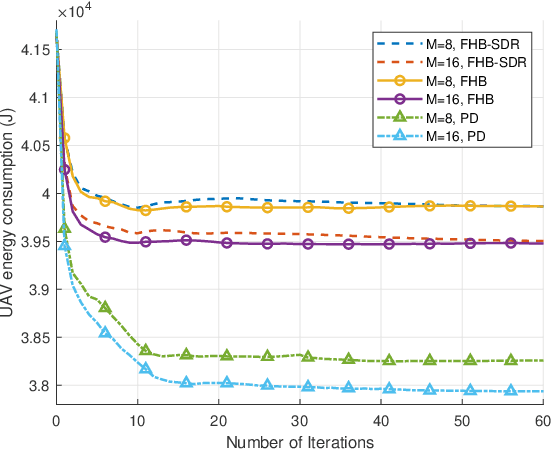
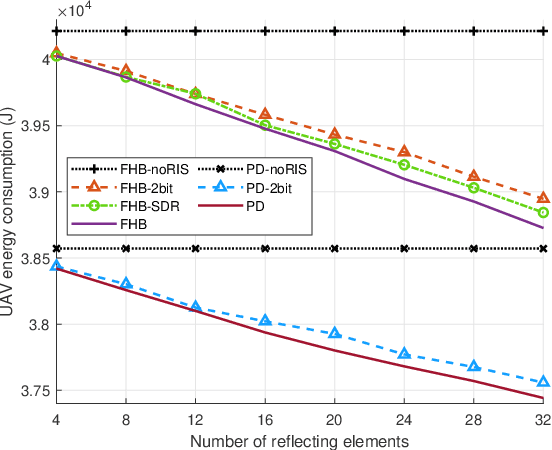
Unmanned aerial vehicle (UAV)-enabled wireless power transfer (WPT) systems offer significant advantages in coverage and deployment flexibility, but suffer from endurance limitations due to the limited onboard energy. This paper proposes to improve the energy efficiency of UAV-enabled WPT systems with multiple ground sensors by utilizing reconfigurable intelligent surface (RIS). Specifically, the total energy consumption of the UAV is minimized, while meeting the energy requirement of each sensor. Firstly, we consider a fly-hover-broadcast (FHB) protocol, in which the UAV radiates radio frequency (RF) signals only at several hovering locations. The energy minimization problem is formulated to jointly optimize the UAV's trajectory, hovering time and the RIS's reflection coefficients. To solve this complex non-convex problem, we propose an efficient algorithm. Specifically, the successive convex approximation (SCA) framework is adopted to jointly optimize the UAV's trajectory and hovering time, in which a minorization-maximization (MM) algorithm that maximizes the minimum charged energy of all sensors is provided to update the reflection coefficients. Then, we investigate the general scenario in which the RF signals are radiated during the flight, aiming to minimize the total energy consumption of the UAV by jointly optimizing the UAV's trajectory, flight time and the RIS's reflection coefficients. By applying the path discretization (PD) protocol, the optimization problem is formulated with a finite number of variables. A high-quality solution for this more challenging problem is obtained. Finally, our simulation results demonstrate the effectiveness of the proposed algorithm and the benefits of RIS in energy saving.
Hebbian Deep Learning Without Feedback
Sep 23, 2022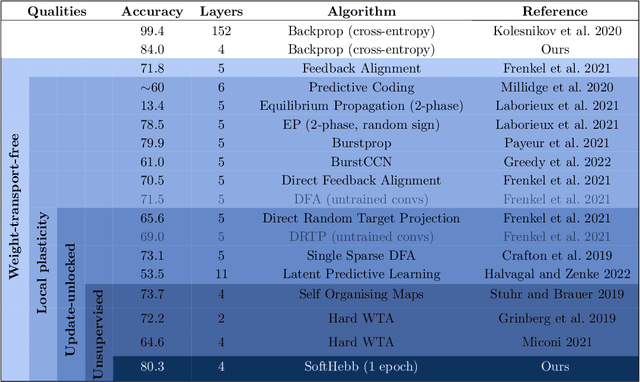
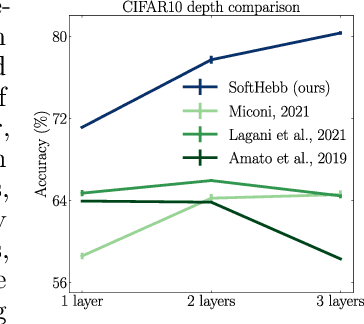

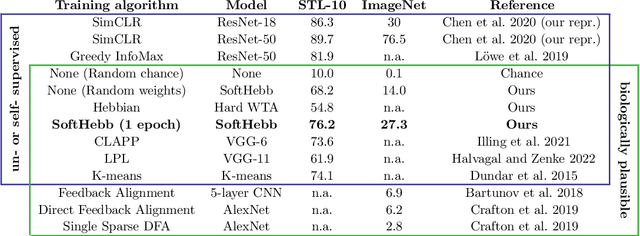
Recent approximations to backpropagation (BP) have mitigated many of BP's computational inefficiencies and incompatibilities with biology, but important limitations still remain. Moreover, the approximations significantly decrease accuracy in benchmarks, suggesting that an entirely different approach may be more fruitful. Here, grounded on recent theory for Hebbian learning in soft winner-take-all networks, we present multilayer SoftHebb, i.e. an algorithm that trains deep neural networks, without any feedback, target, or error signals. As a result, it achieves efficiency by avoiding weight transport, non-local plasticity, time-locking of layer updates, iterative equilibria, and (self-) supervisory or other feedback signals -- which were necessary in other approaches. Its increased efficiency and biological compatibility do not trade off accuracy compared to state-of-the-art bio-plausible learning, but rather improve it. With up to five hidden layers and an added linear classifier, accuracies on MNIST, CIFAR-10, STL-10, and ImageNet, respectively reach 99.4%, 80.3%, 76.2%, and 27.3%. In conclusion, SoftHebb shows with a radically different approach from BP that Deep Learning over few layers may be plausible in the brain and increases the accuracy of bio-plausible machine learning.