 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircuitFormer: A Circuit Language Model for Analog Topology Design from Natural Language Prompt
May 07, 2026Automating analog circuit design remains a longstanding challenge in Electronic Design Automation (EDA). While Transformer-based Large Language Models (LLMs) have revolutionized software code generation, their application to analog hardware design is hindered by two critical limitations: (i) the scarcity of analog design datasets containing natural language description of a design and its corresponding netlist, and (ii) the inefficiency of general-purpose tokenizers (e.g., Byte Pair Encoding (BPE)) in capturing the inherent graph structure of circuits. To bridge this gap, first, we curate the largest annotated dataset of analog circuit netlists to date, comprising 31,341 netlist-natural language description pairs across all major circuit classes. Furthermore, we propose Circuit Tokenizer (CKT), a novel circuit graph tokenizer designed to encode netlist connectivity by explicitly mining frequent subcircuits. In terms of scalability, CKT overcomes the bottleneck of prior circuit graph serialization methods where vocabulary size scales linearly with maximum number of components in the dataset, n_max, (O(n_max)); instead, CKT decouples vocabulary growth from circuit complexity, achieving a constant O(1) complexity. Empirically, CKT outperforms standard BPE on circuit topology representation, reducing sequence length by 57% and achieving a 2.3x superior compression ratio using a compact, fixed vocabulary of size 512. Leveraging this optimized tokenization, we train a circuit-specific language model, CircuitFormer, a 511M parameter encoder-decoder transformer. Our model achieves 100% syntactic correctness and an 83% functional success rate across all major analog circuit categories, outperforming state-of-the-art open-source LLMs by 10% and 14%, respectively, while requiring 240x fewer parameters. The dataset is publicly available at https://huggingface.co/datasets/touhid314/cktformer-dataset.
ChartZero: Synthetic Priors Enable Zero Shot Chart Data Extraction
May 07, 2026Automated data extraction from line charts remains fundamentally bottlenecked by extreme stylistic diversity and a severe scarcity of comprehensively annotated, real-world datasets. Current end-to-end pipelines depend heavily on costly manual annotations, crippling their ability to generalize across arbitrary aesthetics and grid layouts. Furthermore, existing models suffer from two critical failure modes during reconstruction. First, extracting thin, intersecting curves frequently causes structural fragmentation and the erasure of fine visual details, as standard architectures struggle against complex backgrounds. Second, semantic association is notoriously error-prone; current pipelines rely on rigid spatial heuristics that easily break down against the unpredictable legend placements of in-the-wild charts. Finally, measuring true progress is hindered by evaluation protocols that assess isolated sub-tasks rather than holistic, end-to-end data reconstruction. To address these foundational issues, we introduce ChartZero, a parsing framework that leverages synthetic priors to enable robust zero-shot chart data extraction. By training exclusively on a purely synthetic dataset of simple mathematical functions, our model completely bypasses the real-world annotation bottleneck. We overcome curve fragmentation via a novel Global Orthogonal Instance (GOI) loss, and replace brittle spatial rules with an open-vocabulary, Vision-Language Model (VLM)-guided legend matching strategy. Accompanied by a new metric and benchmark specifically designed for full end-to-end reconstruction, our evaluations demonstrate that ChartZero significantly advances generalized plot digitization without requiring real-world supervision. Code and dataset will be released upon acceptance.
LAsset: An LLM-assisted Security Asset Identification Framework for System-on-Chip (SoC) Verification
Jan 06, 2026The growing complexity of modern system-on-chip (SoC) and IP designs is making security assurance difficult day by day. One of the fundamental steps in the pre-silicon security verification of a hardware design is the identification of security assets, as it substantially influences downstream security verification tasks, such as threat modeling, security property generation, and vulnerability detection. Traditionally, assets are determined manually by security experts, requiring significant time and expertise. To address this challenge, we present LAsset, a novel automated framework that leverages large language models (LLMs) to identify security assets from both hardware design specifications and register-transfer level (RTL) descriptions. The framework performs structural and semantic analysis to identify intra-module primary and secondary assets and derives inter-module relationships to systematically characterize security dependencies at the design level. Experimental results show that the proposed framework achieves high classification accuracy, reaching up to 90% recall rate in SoC design, and 93% recall rate in IP designs. This automation in asset identification significantly reduces manual overhead and supports a scalable path forward for secure hardware development.
BugWhisperer: Fine-Tuning LLMs for SoC Hardware Vulnerability Detection
May 28, 2025

The current landscape of system-on-chips (SoCs) security verification faces challenges due to manual, labor-intensive, and inflexible methodologies. These issues limit the scalability and effectiveness of security protocols, making bug detection at the Register-Transfer Level (RTL) difficult. This paper proposes a new framework named BugWhisperer that utilizes a specialized, fine-tuned Large Language Model (LLM) to address these challenges. By enhancing the LLM's hardware security knowledge and leveraging its capabilities for text inference and knowledge transfer, this approach automates and improves the adaptability and reusability of the verification process. We introduce an open-source, fine-tuned LLM specifically designed for detecting security vulnerabilities in SoC designs. Our findings demonstrate that this tailored LLM effectively enhances the efficiency and flexibility of the security verification process. Additionally, we introduce a comprehensive hardware vulnerability database that supports this work and will further assist the research community in enhancing the security verification process.
LLM for SoC Security: A Paradigm Shift
Oct 09, 2023



As the ubiquity and complexity of system-on-chip (SoC) designs increase across electronic devices, the task of incorporating security into an SoC design flow poses significant challenges. Existing security solutions are inadequate to provide effective verification of modern SoC designs due to their limitations in scalability, comprehensiveness, and adaptability. On the other hand, Large Language Models (LLMs) are celebrated for their remarkable success in natural language understanding, advanced reasoning, and program synthesis tasks. Recognizing an opportunity, our research delves into leveraging the emergent capabilities of Generative Pre-trained Transformers (GPTs) to address the existing gaps in SoC security, aiming for a more efficient, scalable, and adaptable methodology. By integrating LLMs into the SoC security verification paradigm, we open a new frontier of possibilities and challenges to ensure the security of increasingly complex SoCs. This paper offers an in-depth analysis of existing works, showcases practical case studies, demonstrates comprehensive experiments, and provides useful promoting guidelines. We also present the achievements, prospects, and challenges of employing LLM in different SoC security verification tasks.
TrustToken, a Trusted SoC solution for Non-Trusted Intellectual Property s
Sep 26, 2022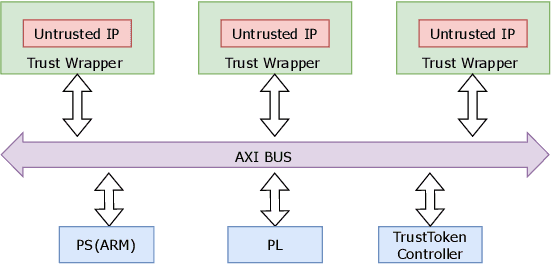

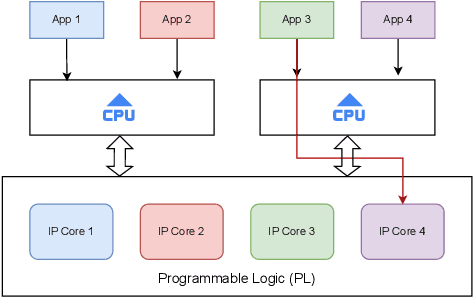
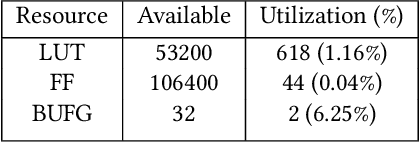
Secure and trustworthy execution in heterogeneous SoCs is a major priority in the modern computing system. Security of SoCs mainly addresses two broad layers of trust issues: 1. Protection against hardware security threats(Side-channel, IP Privacy, Cloning, Fault Injection, and Denial of Service); and 2. Protection against malicious software attacks running on SoC processors. To resist malicious software-level attackers from gaining unauthorized access and compromising security, we propose a root of trust-based trusted execution mechanism \textbf{\textit{(named as \textbf{TrustToken}) }}. TrustToken builds a security block to provide a root of trust-based IP security: secure key generation and truly random source. \textbf{TrustToken} only allows trusted communication between the non-trusted third-party IP and the rest of the SoC world by providing essential security features, i.e., secure, isolated execution, and trusted user interaction. The proposed design achieves this by interconnecting the third-party IP interface to \textbf{TrustToken} Controller and checking IP authorization(Token) signals \texttt{`correctness'} at run-time. \textbf{TrustToken} architecture shows a very low overhead resource utilization LUT (618, 1.16 \%), FF (44, 0.04 \%), and BUFG (2 , 6.25\%) in implementation. The experiment results show that TrustToken can provide a secure, low-cost, and trusted solution for non-trusted SoC IPs.