 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Typical Behavior of Bandit Algorithms
Oct 11, 2022
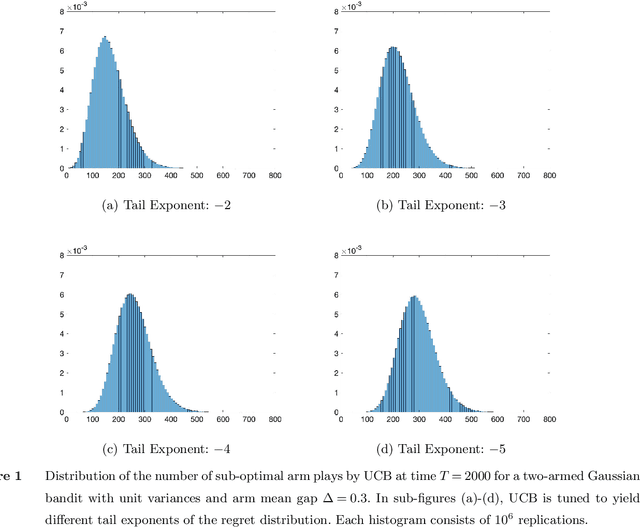
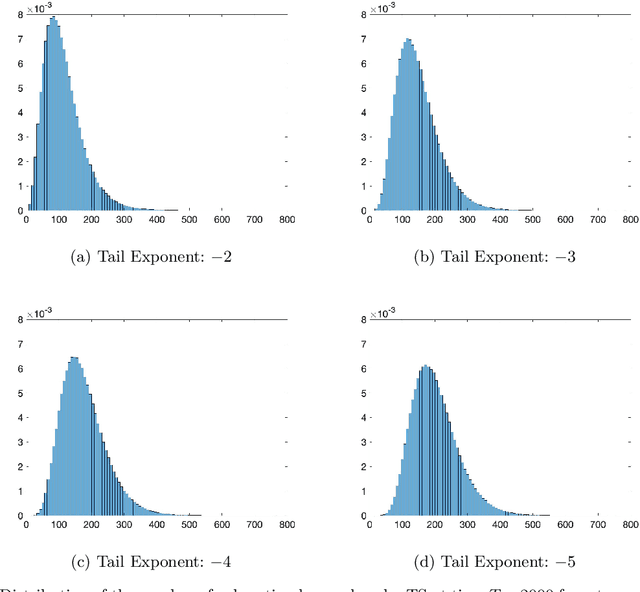
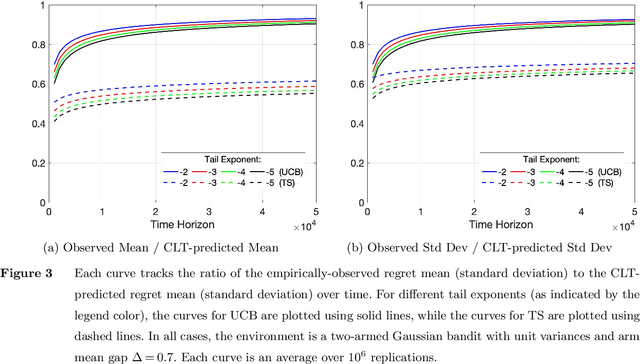
We establish strong laws of large numbers and central limit theorems for the regret of two of the most popular bandit algorithms: Thompson sampling and UCB. Here, our characterizations of the regret distribution complement the characterizations of the tail of the regret distribution recently developed by Fan and Glynn (2021) (arXiv:2109.13595). The tail characterizations there are associated with atypical bandit behavior on trajectories where the optimal arm mean is under-estimated, leading to mis-identification of the optimal arm and large regret. In contrast, our SLLN's and CLT's here describe the typical behavior and fluctuation of regret on trajectories where the optimal arm mean is properly estimated. We find that Thompson sampling and UCB satisfy the same SLLN and CLT, with the asymptotics of both the SLLN and the (mean) centering sequence in the CLT matching the asymptotics of expected regret. Both the mean and variance in the CLT grow at $\log(T)$ rates with the time horizon $T$. Asymptotically as $T \to \infty$, the variability in the number of plays of each sub-optimal arm depends only on the rewards received for that arm, which indicates that each sub-optimal arm contributes independently to the overall CLT variance.
CASAPose: Class-Adaptive and Semantic-Aware Multi-Object Pose Estimation
Oct 11, 2022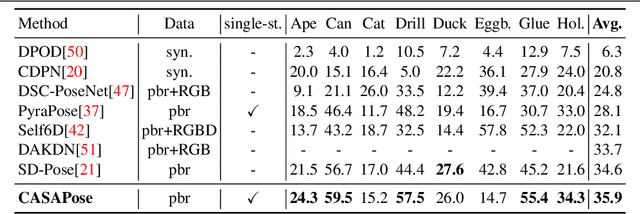

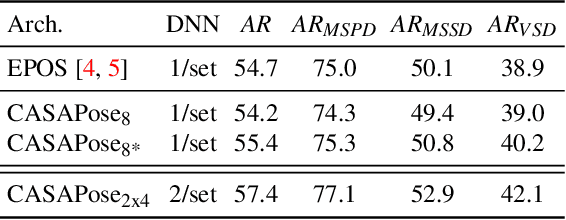
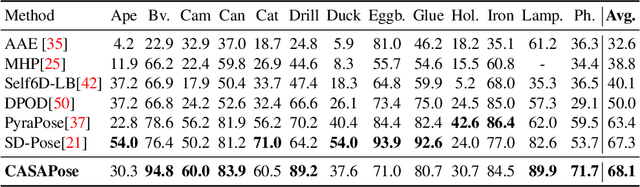
Applications in the field of augmented reality or robotics often require joint localisation and 6d pose estimation of multiple objects. However, most algorithms need one network per object class to be trained in order to provide the best results. Analysing all visible objects demands multiple inferences, which is memory and time-consuming. We present a new single-stage architecture called CASAPose that determines 2D-3D correspondences for pose estimation of multiple different objects in RGB images in one pass. It is fast and memory efficient, and achieves high accuracy for multiple objects by exploiting the output of a semantic segmentation decoder as control input to a keypoint recognition decoder via local class-adaptive normalisation. Our new differentiable regression of keypoint locations significantly contributes to a faster closing of the domain gap between real test and synthetic training data. We apply segmentation-aware convolutions and upsampling operations to increase the focus inside the object mask and to reduce mutual interference of occluding objects. For each inserted object, the network grows by only one output segmentation map and a negligible number of parameters. We outperform state-of-the-art approaches in challenging multi-object scenes with inter-object occlusion and synthetic training.
Trading Off Resource Budgets for Improved Regret Bounds
Oct 11, 2022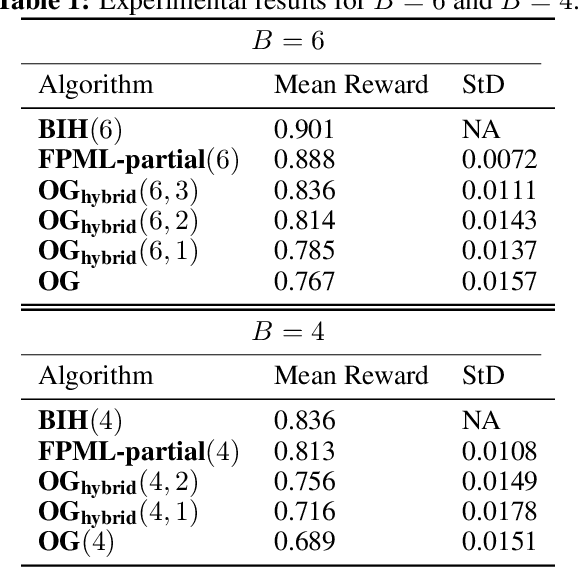
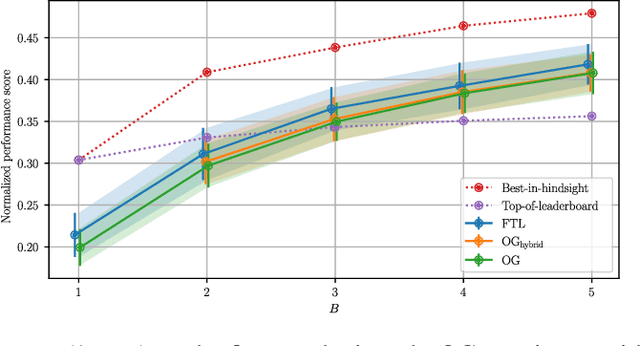
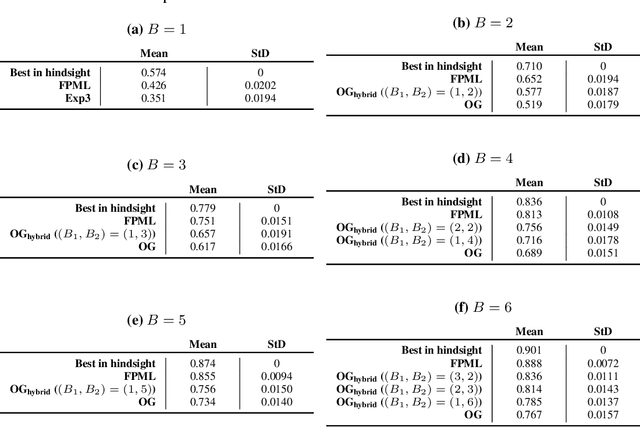
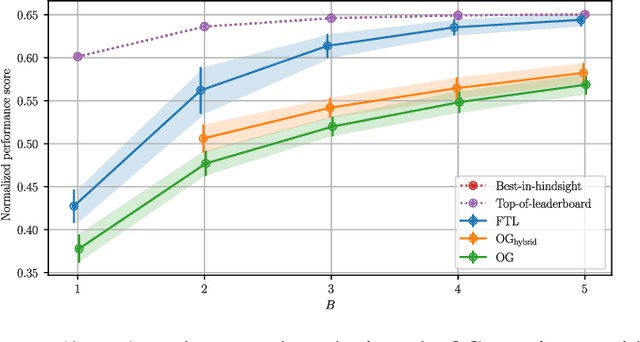
In this work we consider a variant of adversarial online learning where in each round one picks $B$ out of $N$ arms and incurs cost equal to the $\textit{minimum}$ of the costs of each arm chosen. We propose an algorithm called Follow the Perturbed Multiple Leaders (FPML) for this problem, which we show (by adapting the techniques of Kalai and Vempala [2005]) achieves expected regret $\mathcal{O}(T^{\frac{1}{B+1}}\ln(N)^{\frac{B}{B+1}})$ over time horizon $T$ relative to the $\textit{single}$ best arm in hindsight. This introduces a trade-off between the budget $B$ and the single-best-arm regret, and we proceed to investigate several applications of this trade-off. First, we observe that algorithms which use standard regret minimizers as subroutines can sometimes be adapted by replacing these subroutines with FPML, and we use this to generalize existing algorithms for Online Submodular Function Maximization [Streeter and Golovin, 2008] in both the full feedback and semi-bandit feedback settings. Next, we empirically evaluate our new algorithms on an online black-box hyperparameter optimization problem. Finally, we show how FPML can lead to new algorithms for Linear Programming which require stronger oracles at the benefit of fewer oracle calls.
ViFiCon: Vision and Wireless Association Via Self-Supervised Contrastive Learning
Oct 11, 2022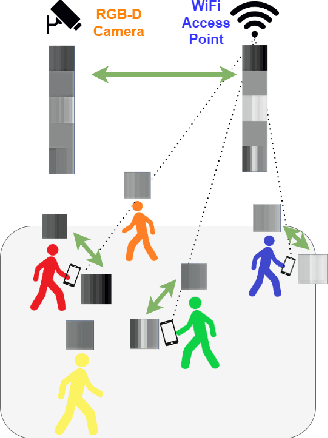

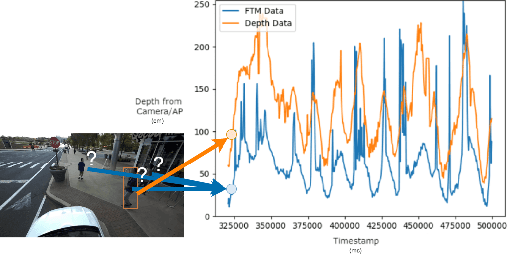

We introduce ViFiCon, a self-supervised contrastive learning scheme which uses synchronized information across vision and wireless modalities to perform cross-modal association. Specifically, the system uses pedestrian data collected from RGB-D camera footage as well as WiFi Fine Time Measurements (FTM) from a user's smartphone device. We represent the temporal sequence by stacking multi-person depth data spatially within a banded image. Depth data from RGB-D (vision domain) is inherently linked with an observable pedestrian, but FTM data (wireless domain) is associated only to a smartphone on the network. To formulate the cross-modal association problem as self-supervised, the network learns a scene-wide synchronization of the two modalities as a pretext task, and then uses that learned representation for the downstream task of associating individual bounding boxes to specific smartphones, i.e. associating vision and wireless information. We use a pre-trained region proposal model on the camera footage and then feed the extrapolated bounding box information into a dual-branch convolutional neural network along with the FTM data. We show that compared to fully supervised SoTA models, ViFiCon achieves high performance vision-to-wireless association, finding which bounding box corresponds to which smartphone device, without hand-labeled association examples for training data.
Zero-Order One-Point Estimate with Distributed Stochastic Gradient-Tracking Technique
Oct 11, 2022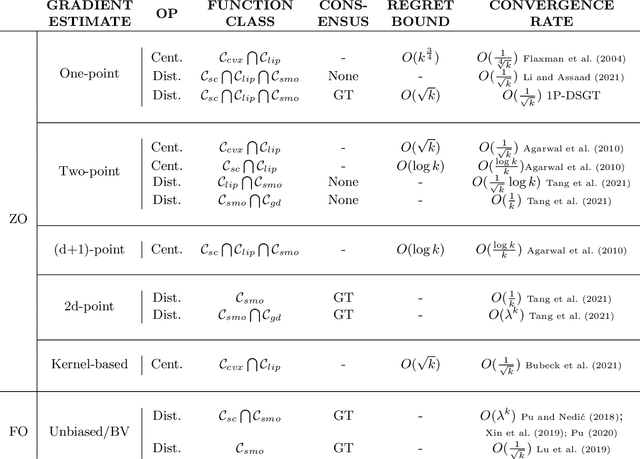
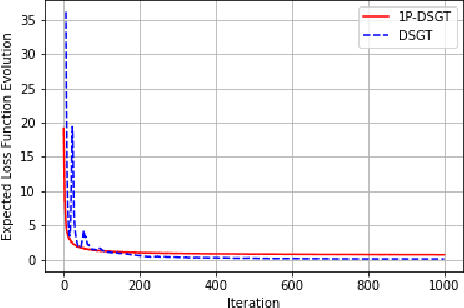
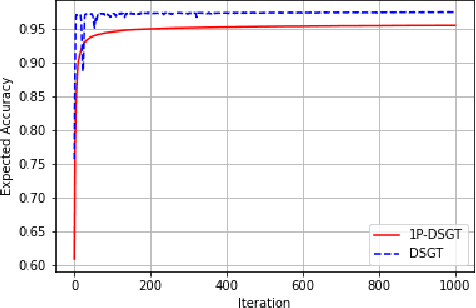
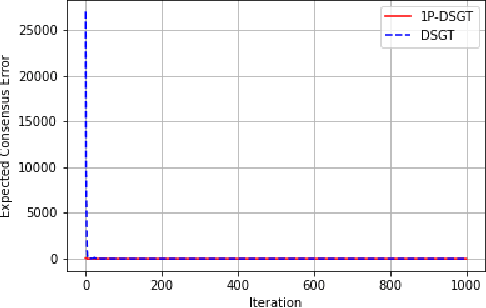
In this work, we consider a distributed multi-agent stochastic optimization problem, where each agent holds a local objective function that is smooth and convex, and that is subject to a stochastic process. The goal is for all agents to collaborate to find a common solution that optimizes the sum of these local functions. With the practical assumption that agents can only obtain noisy numerical function queries at exactly one point at a time, we extend the distributed stochastic gradient-tracking method to the bandit setting where we don't have an estimate of the gradient, and we introduce a zero-order (ZO) one-point estimate (1P-DSGT). We analyze the convergence of this novel technique for smooth and convex objectives using stochastic approximation tools, and we prove that it converges almost surely to the optimum. We then study the convergence rate for when the objectives are additionally strongly convex. We obtain a rate of $O(\frac{1}{\sqrt{k}})$ after a sufficient number of iterations $k > K_2$ which is usually optimal for techniques utilizing one-point estimators. We also provide a regret bound of $O(\sqrt{k})$, which is exceptionally good compared to the aforementioned techniques. We further illustrate the usefulness of the proposed technique using numerical experiments.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022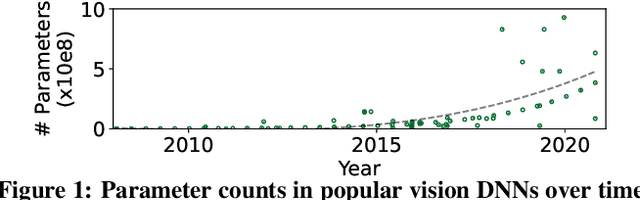
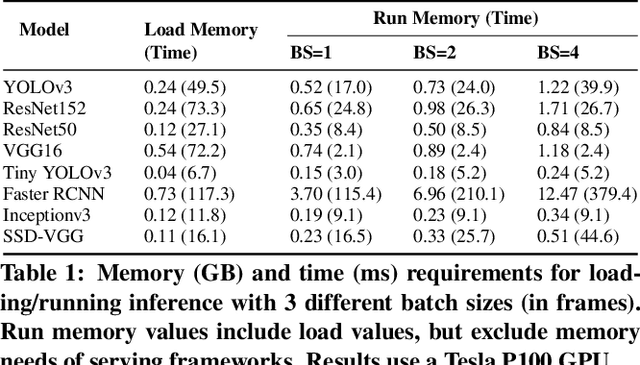
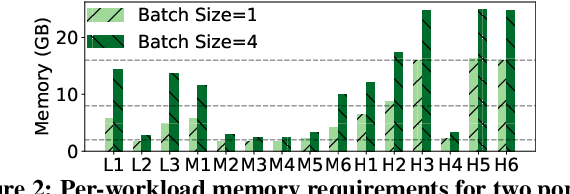

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
Facial Landmark Predictions with Applications to Metaverse
Sep 29, 2022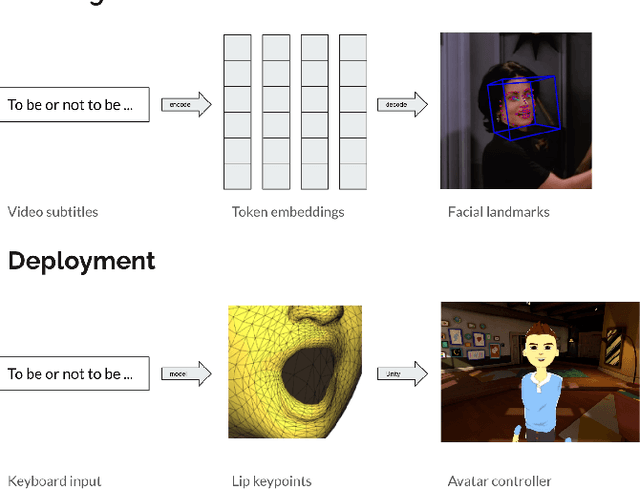
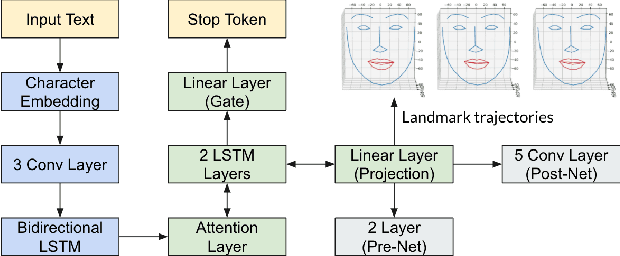
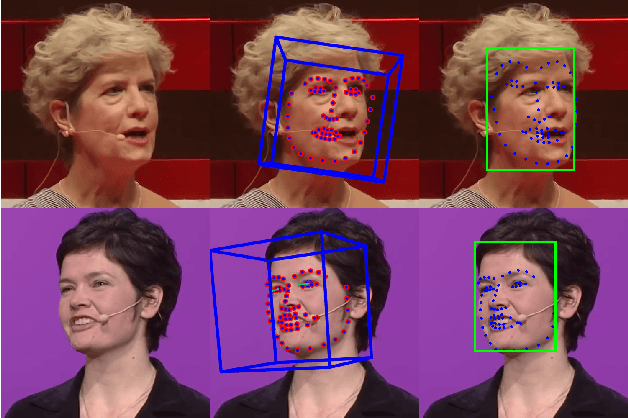
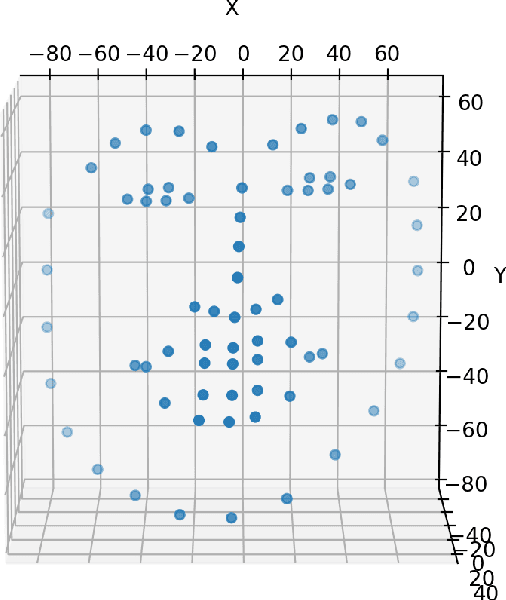
This research aims to make metaverse characters more realistic by adding lip animations learnt from videos in the wild. To achieve this, our approach is to extend Tacotron 2 text-to-speech synthesizer to generate lip movements together with mel spectrogram in one pass. The encoder and gate layer weights are pre-trained on LJ Speech 1.1 data set while the decoder is retrained on 93 clips of TED talk videos extracted from LRS 3 data set. Our novel decoder predicts displacement in 20 lip landmark positions across time, using labels automatically extracted by OpenFace 2.0 landmark predictor. Training converged in 7 hours using less than 5 minutes of video. We conducted ablation study for Pre/Post-Net and pre-trained encoder weights to demonstrate the effectiveness of transfer learning between audio and visual speech data.
Constrained RIS Phase Profile Optimization and Time Sharing for Near-field Localization
Mar 14, 2022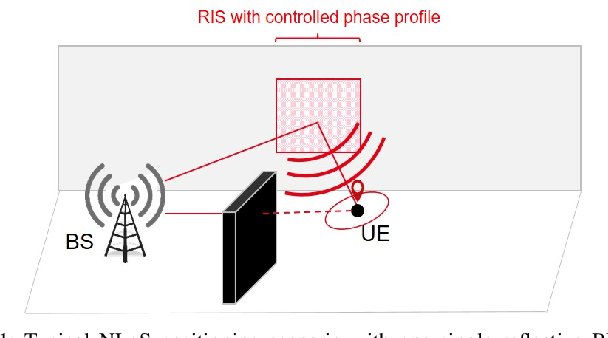
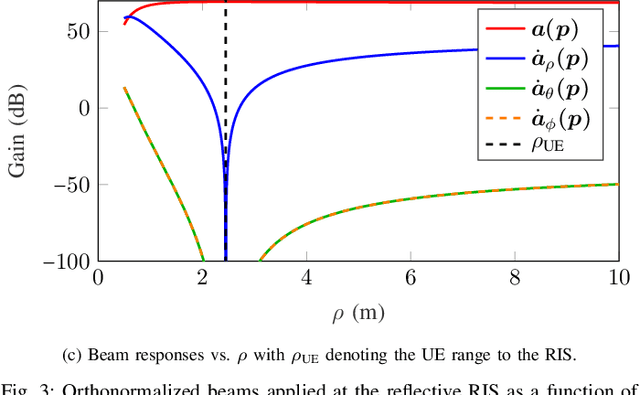
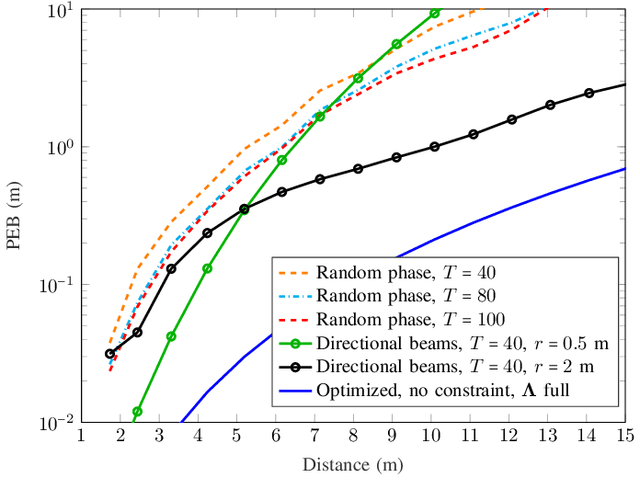
The rising concept of reconfigurable intelligent surface (RIS) has promising potential for Beyond 5G localization applications. We herein investigate different phase profile designs at a reflective RIS, which enable non-line-of-sight positioning in nearfield from downlink single antenna transmissions. We first derive the closed-form expressions of the corresponding Fisher information matrix (FIM) and position error bound (PEB). Accordingly, we then propose a new localization-optimal phase profile design, assuming prior knowledge of the user equipment location. Numerical simulations in a canonical scenario show that our proposal outperforms conventional RIS random and directional beam codebook designs in terms of PEB. We also illustrate the four beams allocated at the RIS (i.e., one directional beam, along with its derivatives with respect to space dimensions) and show how their relative weights according to the optimal solution can be practically implemented through time sharing (i.e., considering feasible beams sequentially).
Visual Backtracking Teleoperation: A Data Collection Protocol for Offline Image-Based Reinforcement Learning
Oct 05, 2022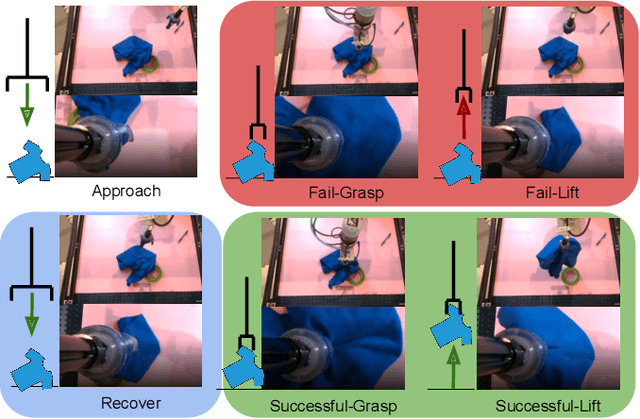
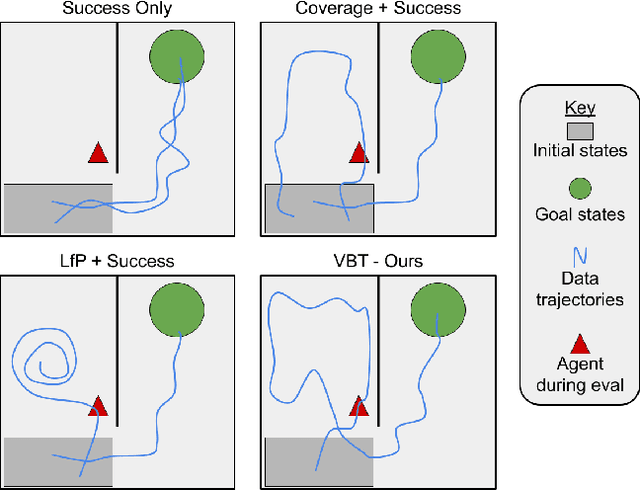
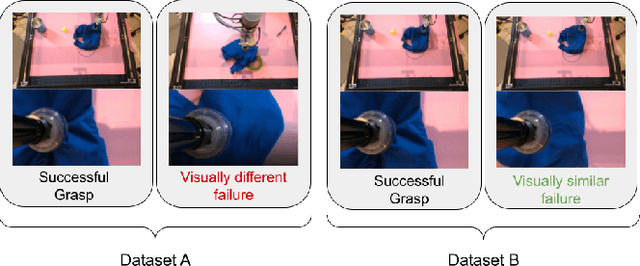
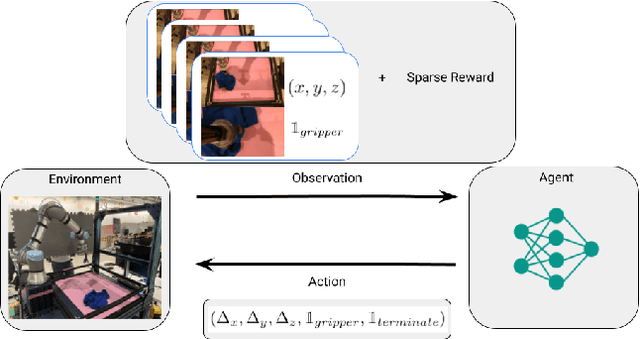
We consider how to most efficiently leverage teleoperator time to collect data for learning robust image-based value functions and policies for sparse reward robotic tasks. To accomplish this goal, we modify the process of data collection to include more than just successful demonstrations of the desired task. Instead we develop a novel protocol that we call Visual Backtracking Teleoperation (VBT), which deliberately collects a dataset of visually similar failures, recoveries, and successes. VBT data collection is particularly useful for efficiently learning accurate value functions from small datasets of image-based observations. We demonstrate VBT on a real robot to perform continuous control from image observations for the deformable manipulation task of T-shirt grasping. We find that by adjusting the data collection process we improve the quality of both the learned value functions and policies over a variety of baseline methods for data collection. Specifically, we find that offline reinforcement learning on VBT data outperforms standard behavior cloning on successful demonstration data by 13% when both methods are given equal-sized datasets of 60 minutes of data from the real robot.
Time Efficient Training of Progressive Generative Adversarial Network using Depthwise Separable Convolution and Super Resolution Generative Adversarial Network
Feb 24, 2022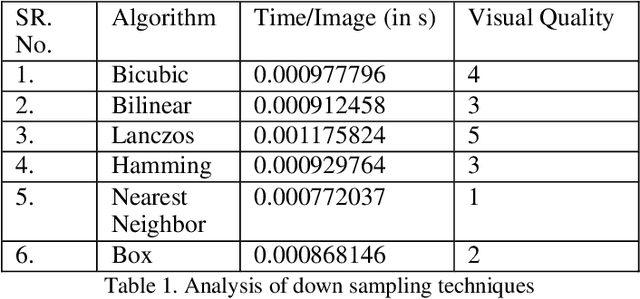

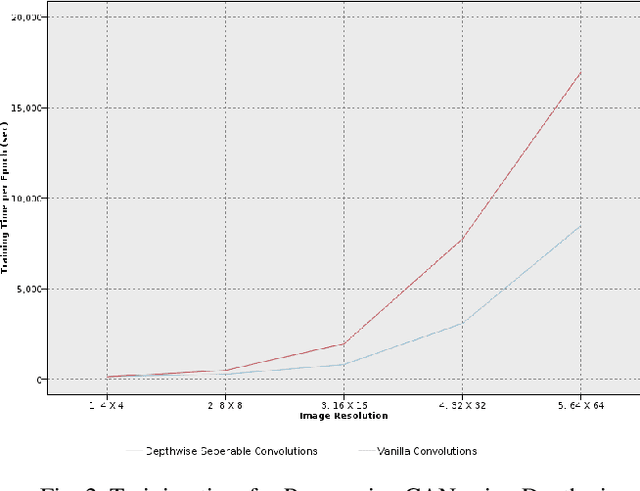

Generative Adversarial Networks have been employed successfully to generate high-resolution augmented images of size 1024^2. Although the augmented images generated are unprecedented, the training time of the model is exceptionally high. Conventional GAN requires training of both Discriminator as well as the Generator. In Progressive GAN, which is the current state-of-the-art GAN for image augmentation, instead of training the GAN all at once, a new concept of progressing growing of Discriminator and Generator simultaneously, was proposed. Although the lower stages such as 4x4 and 8x8 train rather quickly, the later stages consume a tremendous amount of time which could take days to finish the model training. In our paper, we propose a novel pipeline that combines Progressive GAN with slight modifications and Super Resolution GAN. Super Resolution GAN up samples low-resolution images to high-resolution images which can prove to be a useful resource to reduce the training time exponentially.