 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning Aided Laplace Based Bayesian Inference for Epidemiological Systems
Oct 17, 2022
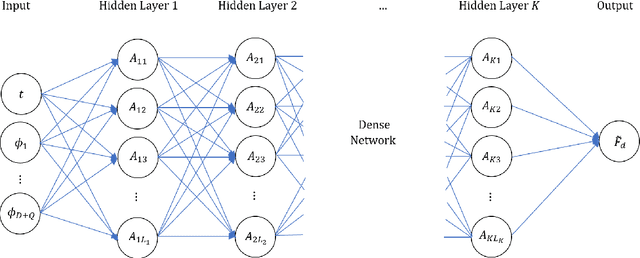
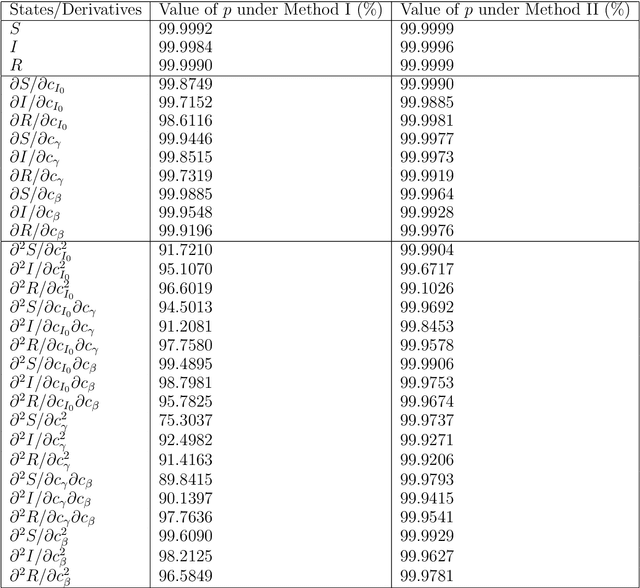
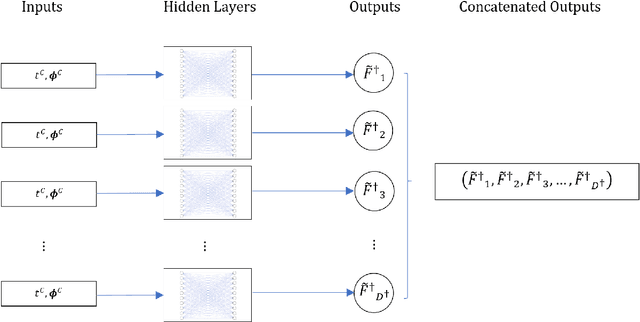

Parameter estimation and associated uncertainty quantification is an important problem in dynamical systems characterized by ordinary differential equation (ODE) models that are often nonlinear. Typically, such models have analytically intractable trajectories which result in likelihoods and posterior distributions that are similarly intractable. Bayesian inference for ODE systems via simulation methods require numerical approximations to produce inference with high accuracy at a cost of heavy computational power and slow convergence. At the same time, Artificial Neural Networks (ANN) offer tractability that can be utilized to construct an approximate but tractable likelihood and posterior distribution. In this paper we propose a hybrid approach, where Laplace-based Bayesian inference is combined with an ANN architecture for obtaining approximations to the ODE trajectories as a function of the unknown initial values and system parameters. Suitable choices of a collocation grid and customized loss functions are proposed to fine tune the ODE trajectories and Laplace approximation. The effectiveness of our proposed methods is demonstrated using an epidemiological system with non-analytical solutions, the Susceptible-Infectious-Removed (SIR) model for infectious diseases, based on simulated and real-life influenza datasets. The novelty and attractiveness of our proposed approach include (i) a new development of Bayesian inference using ANN architectures for ODE based dynamical systems, and (ii) a computationally fast posterior inference by avoiding convergence issues of benchmark Markov Chain Monte Carlo methods. These two features establish the developed approach as an accurate alternative to traditional Bayesian computational methods, with improved computational cost.
Weakly Supervised Face Naming with Symmetry-Enhanced Contrastive Loss
Oct 17, 2022
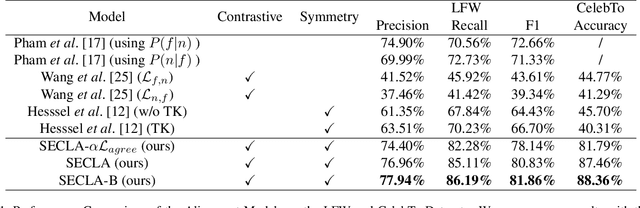
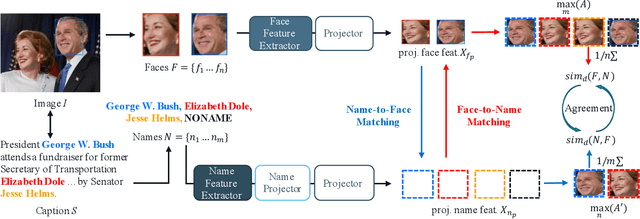
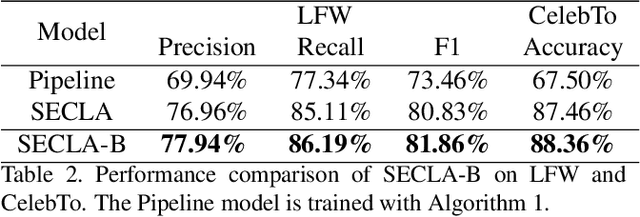
We revisit the weakly supervised cross-modal face-name alignment task; that is, given an image and a caption, we label the faces in the image with the names occurring in the caption. Whereas past approaches have learned the latent alignment between names and faces by uncertainty reasoning over a set of images and their respective captions, in this paper, we rely on appropriate loss functions to learn the alignments in a neural network setting and propose SECLA and SECLA-B. SECLA is a Symmetry-Enhanced Contrastive Learning-based Alignment model that can effectively maximize the similarity scores between corresponding faces and names in a weakly supervised fashion. A variation of the model, SECLA-B, learns to align names and faces as humans do, that is, learning from easy to hard cases to further increase the performance of SECLA. More specifically, SECLA-B applies a two-stage learning framework: (1) Training the model on an easy subset with a few names and faces in each image-caption pair. (2) Leveraging the known pairs of names and faces from the easy cases using a bootstrapping strategy with additional loss to prevent forgetting and learning new alignments at the same time. We achieve state-of-the-art results for both the augmented Labeled Faces in the Wild dataset and the Celebrity Together dataset. In addition, we believe that our methods can be adapted to other multimodal news understanding tasks.
Efficient Parallelization of 5G-PUSCH on a Scalable RISC-V Many-core Processor
Oct 17, 2022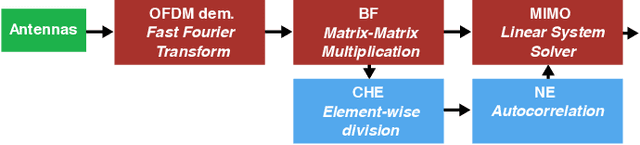
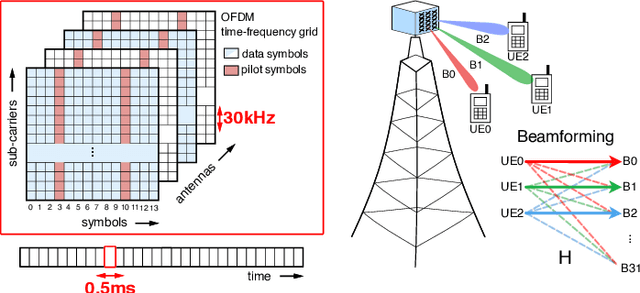
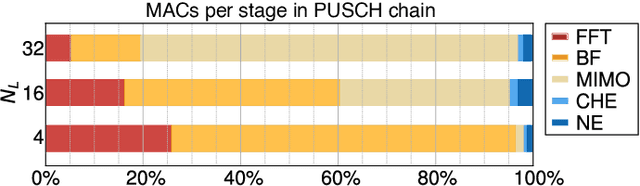
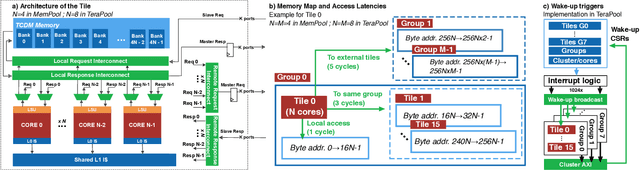
5G Radio access network disaggregation and softwarization pose challenges in terms of computational performance to the processing units. At the physical layer level, the baseband processing computational effort is typically offloaded to specialized hardware accelerators. However, the trend toward software-defined radio-access networks demands flexible, programmable architectures. In this paper, we explore the software design, parallelization and optimization of the key kernels of the lower physical layer (PHY) for physical uplink shared channel (PUSCH) reception on MemPool and TeraPool, two manycore systems having respectively 256 and 1024 small and efficient RISC-V cores with a large shared L1 data memory. PUSCH processing is demanding and strictly time-constrained, it represents a challenge for the baseband processors, and it is also common to most of the uplink channels. Our analysis thus generalizes to the entire lower PHY of the uplink receiver at gNodeB (gNB). Based on the evaluation of the computational effort (in multiply-accumulate operations) required by the PUSCH algorithmic stages, we focus on the parallel implementation of the dominant kernels, namely fast Fourier transform, matrix-matrix multiplication, and matrix decomposition kernels for the solution of linear systems. Our optimized parallel kernels achieve respectively on MemPool and TeraPool speedups of 211, 225, 158, and 762, 880, 722, at high utilization (0.81, 0.89, 0.71, and 0.74, 0.88, 0.71), comparable a single-core serial execution, moving a step closer toward a full-software PUSCH implementation.
A Memory Transformer Network for Incremental Learning
Oct 10, 2022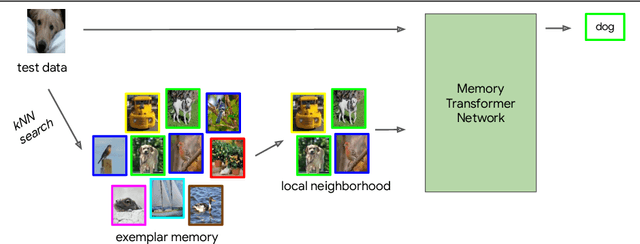
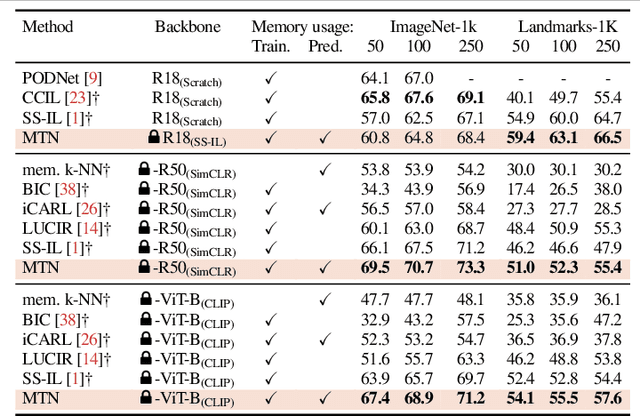
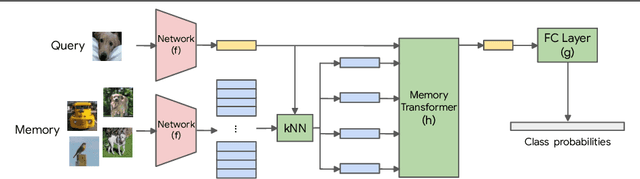
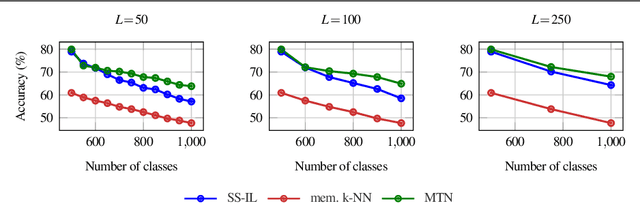
We study class-incremental learning, a training setup in which new classes of data are observed over time for the model to learn from. Despite the straightforward problem formulation, the naive application of classification models to class-incremental learning results in the "catastrophic forgetting" of previously seen classes. One of the most successful existing methods has been the use of a memory of exemplars, which overcomes the issue of catastrophic forgetting by saving a subset of past data into a memory bank and utilizing it to prevent forgetting when training future tasks. In our paper, we propose to enhance the utilization of this memory bank: we not only use it as a source of additional training data like existing works but also integrate it in the prediction process explicitly.Our method, the Memory Transformer Network (MTN), learns how to combine and aggregate the information from the nearest neighbors in the memory with a transformer to make more accurate predictions. We conduct extensive experiments and ablations to evaluate our approach. We show that MTN achieves state-of-the-art performance on the challenging ImageNet-1k and Google-Landmarks-1k incremental learning benchmarks.
Domain-guided data augmentation for deep learning on medical imaging
Oct 10, 2022

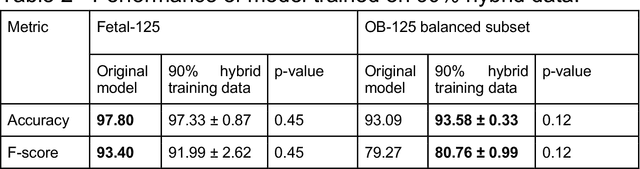
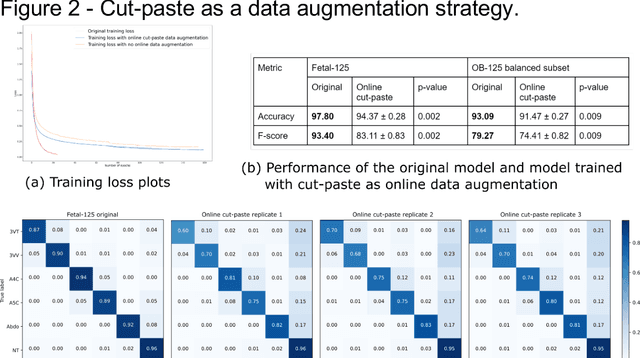
While domain-specific data augmentation can be useful in training neural networks for medical imaging tasks, such techniques have not been widely used to date. Here, we test whether domain-specific data augmentation is useful for medical imaging using a well-benchmarked task: view classification on fetal ultrasound FETAL-125 and OB-125 datasets. We found that using a context-preserving cut-paste strategy, we could create valid training data as measured by performance of the resulting trained model on the benchmark test dataset. When used in an online fashion, models trained on this data performed similarly to those trained using traditional data augmentation (FETAL-125 F-score 85.33+/-0.24 vs 86.89+/-0.60, p-value 0.0139; OB-125 F-score 74.60+/-0.11 vs 72.43+/-0.62, p-value 0.0039). Furthermore, the ability to perform augmentations during training time, as well as the ability to apply chosen augmentations equally across data classes, are important considerations in designing a bespoke data augmentation. Finally, we provide open-source code to facilitate running bespoke data augmentations in an online fashion. Taken together, this work expands the ability to design and apply domain-guided data augmentations for medical imaging tasks.
Dynamic Gap: Formal Guarantees for Safe Gap-based Navigation in Dynamic Environments
Oct 10, 2022
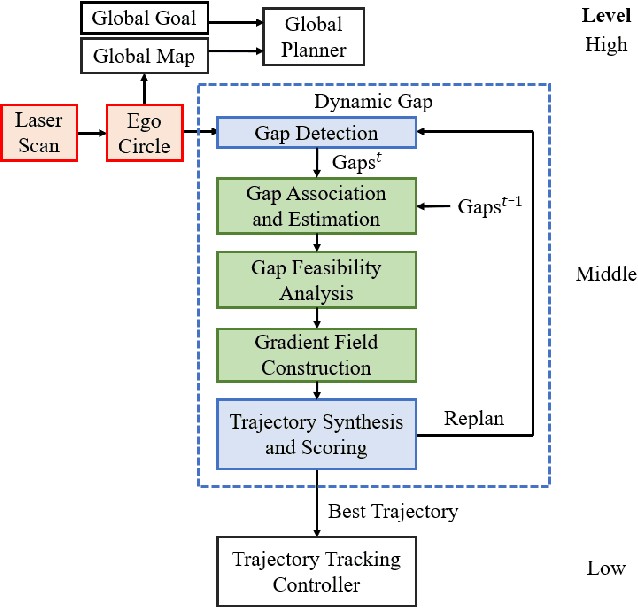
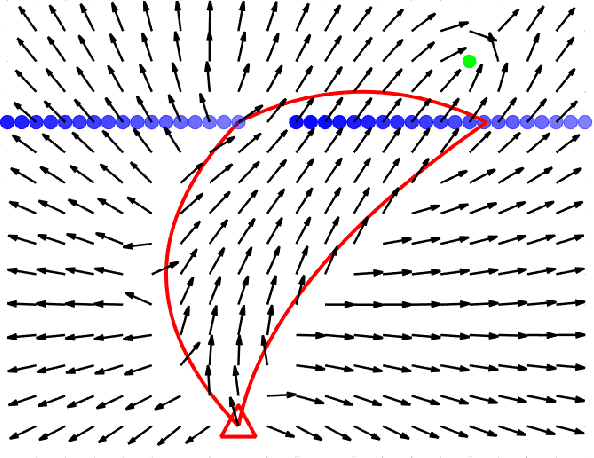
This paper extends the family of gap-based local planners to unknown dynamic environments through generating provable collision-free properties for hierarchical navigation systems. Existing perception-informed local planners that operate in dynamic environments rely on emergent or empirical robustness for collision avoidance as opposed to providing formal guarantees for safety. In addition to this, the obstacle tracking that is performed in these existent planners is often achieved with respect to a global inertial frame, subjecting such tracking estimates to transformation errors from odometry drift. The proposed local planner, called dynamic gap, shifts the tracking paradigm to modeling how the free space, represented as gaps, evolves over time. Gap crossing and closing conditions are developed to aid in determining the feasibility of passage through gaps, and Bezier curves are used to define a safe navigable gap that encapsulates both local environment dynamics and ego-robot reachability. Artificial Harmonic Potential Field (AHPF) methods that guarantee collision-free convergence to the goal are then leveraged to generate safe local trajectories. Monte Carlo benchmarking experiments are run in structured simulation worlds with dynamic agents to showcase the benefits that such formal safety guarantees provide.
Self-supervised Autoregressive Domain Adaptation for Time Series Data
Nov 29, 2021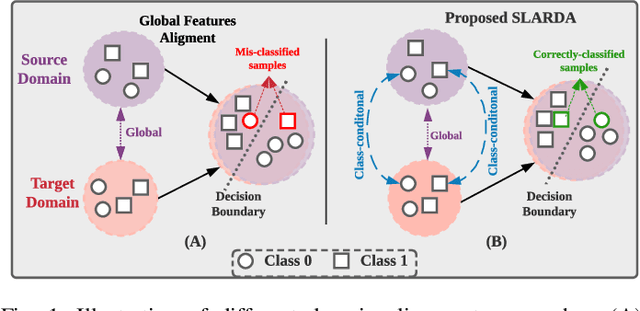
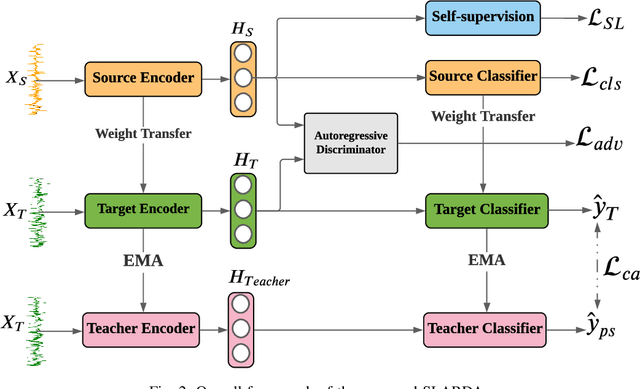
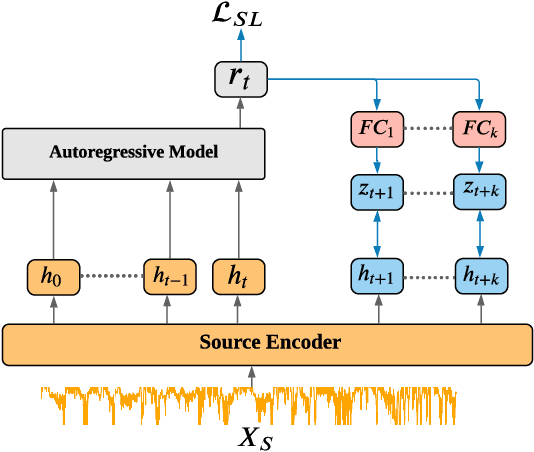
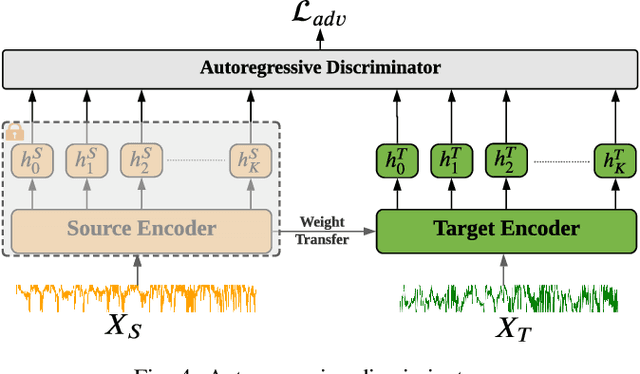
Unsupervised domain adaptation (UDA) has successfully addressed the domain shift problem for visual applications. Yet, these approaches may have limited performance for time series data due to the following reasons. First, they mainly rely on large-scale dataset (i.e., ImageNet) for the source pretraining, which is not applicable for time-series data. Second, they ignore the temporal dimension on the feature space of the source and target domains during the domain alignment step. Last, most of prior UDA methods can only align the global features without considering the fine-grained class distribution of the target domain. To address these limitations, we propose a Self-supervised Autoregressive Domain Adaptation (SLARDA) framework. In particular, we first design a self-supervised learning module that utilizes forecasting as an auxiliary task to improve the transferability of the source features. Second, we propose a novel autoregressive domain adaptation technique that incorporates temporal dependency of both source and target features during domain alignment. Finally, we develop an ensemble teacher model to align the class-wise distribution in the target domain via a confident pseudo labeling approach. Extensive experiments have been conducted on three real-world time series applications with 30 cross-domain scenarios. Results demonstrate that our proposed SLARDA method significantly outperforms the state-of-the-art approaches for time series domain adaptation.
Physiological Signal Processing in Heart Rate Variability Measurement: A Focus on Spectral Analysis
Aug 02, 2022
Fast Fourier Transform (FFT) relies on the HRV frequency-domain analysis techniques. It requires re-sampling of the inherently unevenly sampled heartbeat time-series (RR tachogram) to produce an evenly sampled time series of the heartbeat. However, re-sampling of the heartbeat time -- series is found to produce a substantial error when estimating an artificial RR tachogram.
Data Feedback Loops: Model-driven Amplification of Dataset Biases
Sep 08, 2022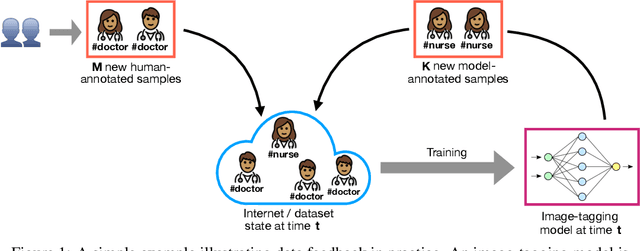

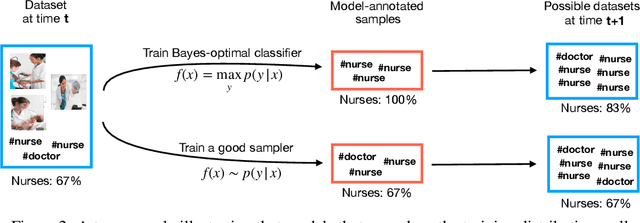

Datasets scraped from the internet have been critical to the successes of large-scale machine learning. Yet, this very success puts the utility of future internet-derived datasets at potential risk, as model outputs begin to replace human annotations as a source of supervision. In this work, we first formalize a system where interactions with one model are recorded as history and scraped as training data in the future. We then analyze its stability over time by tracking changes to a test-time bias statistic (e.g. gender bias of model predictions). We find that the degree of bias amplification is closely linked to whether the model's outputs behave like samples from the training distribution, a behavior which we characterize and define as consistent calibration. Experiments in three conditional prediction scenarios - image classification, visual role-labeling, and language generation - demonstrate that models that exhibit a sampling-like behavior are more calibrated and thus more stable. Based on this insight, we propose an intervention to help calibrate and stabilize unstable feedback systems. Code is available at https://github.com/rtaori/data_feedback.
Log-Gaussian processes for AI-assisted TAS experiments
Sep 02, 2022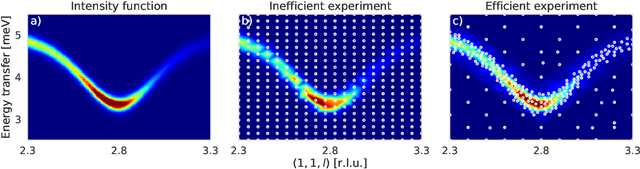
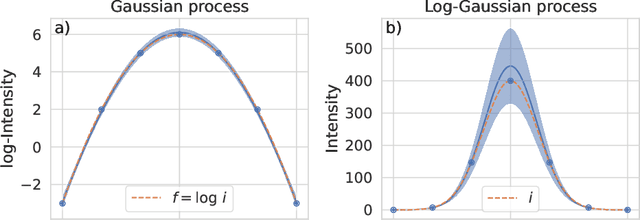
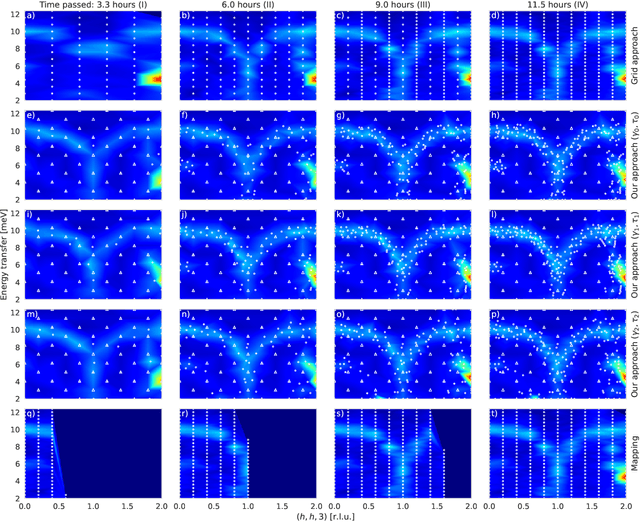
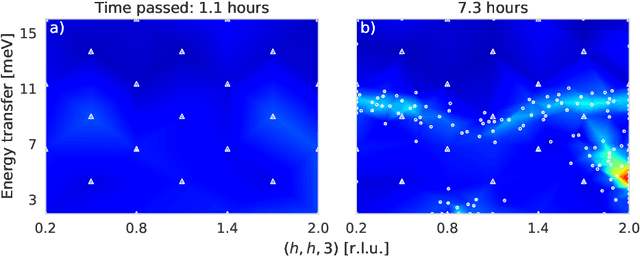
To understand the origins of materials properties, neutron scattering experiments at three-axes spectrometers (TAS) investigate magnetic and lattice excitations in a sample by measuring intensity distributions in its momentum (Q) and energy (E) space. The high demand and limited availability of beam time for TAS experiments however raise the natural question whether we can improve their efficiency or make better use of the experimenter's time. In fact, using TAS, there are a number of scientific questions that require searching for signals of interest in a particular region of Q-E space, but when done manually, it is time consuming and inefficient since the measurement points may be placed in uninformative regions such as the background. Active learning is a promising general machine learning approach that allows to iteratively detect informative regions of signal autonomously, i.e., without human interference, thus avoiding unnecessary measurements and speeding up the experiment. In addition, the autonomous mode allows experimenters to focus on other relevant tasks in the meantime. The approach that we describe in this article exploits log-Gaussian processes which, due to the log transformation, have the largest approximation uncertainties in regions of signal. Maximizing uncertainty as an acquisition function hence directly yields locations for informative measurements. We demonstrate the benefits of our approach on outcomes of a real neutron experiment at the thermal TAS EIGER (PSI) as well as on results of a benchmark in a synthetic setting including numerous different excitations.