 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast End-to-End Simulation and Exploration of Many-RISCV-Core Baseband Transceivers for Software-Defined Radio-Access Networks
Aug 08, 2025The fast-rising demand for wireless bandwidth requires rapid evolution of high-performance baseband processing infrastructure. Programmable many-core processors for software-defined radio (SDR) have emerged as high-performance baseband processing engines, offering the flexibility required to capture evolving wireless standards and technologies. This trend must be supported by a design framework enabling functional validation and end-to-end performance analysis of SDR hardware within realistic radio environment models. We propose a static binary translation based simulator augmented with a fast, approximate timing model of the hardware and coupled to wireless channel models to simulate the most performance-critical physical layer functions implemented in software on a many (1024) RISC-V cores cluster customized for SDR. Our framework simulates the detection of a 5G OFDM-symbol on a server-class processor in 9.5s-3min, on a single thread, depending on the input MIMO size (three orders of magnitude faster than RTL simulation). The simulation is easily parallelized to 128 threads with 73-121x speedup compared to a single thread.
A 66-Gb/s/5.5-W RISC-V Many-Core Cluster for 5G+ Software-Defined Radio Uplinks
Aug 08, 2025Following the scale-up of new radio (NR) complexity in 5G and beyond, the physical layer's computing load on base stations is increasing under a strictly constrained latency and power budget; base stations must process > 20-Gb/s uplink wireless data rate on the fly, in < 10 W. At the same time, the programmability and reconfigurability of base station components are the key requirements; it reduces the time and cost of new networks' deployment, it lowers the acceptance threshold for industry players to enter the market, and it ensures return on investments in a fast-paced evolution of standards. In this article, we present the design of a many-core cluster for 5G and beyond base station processing. Our design features 1024, streamlined RISC-V cores with domain-specific FP extensions, and 4-MiB shared memory. It provides the necessary computational capabilities for software-defined processing of the lower physical layer of 5G physical uplink shared channel (PUSCH), satisfying high-end throughput requirements (66 Gb/s for a transition time interval (TTI), 9.4-302 Gb/s depending on the processing stage). The throughput metrics for the implemented functions are ten times higher than in state-of-the-art (SoTA) application-specific instruction processors (ASIPs). The energy efficiency on key NR kernels (2-41 Gb/s/W), measured at 800 MHz, 25 {\deg}C, and 0.8 V, on a placed and routed instance in 12-nm CMOS technology, is competitive with SoTA architectures. The PUSCH processing runs end-to-end on a single cluster in 1.7 ms, at <6-W average power consumption, achieving 12 Gb/s/W.
Efficient Parallelization of 5G-PUSCH on a Scalable RISC-V Many-core Processor
Oct 17, 2022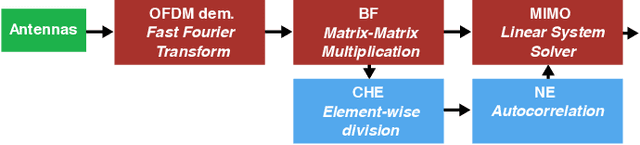
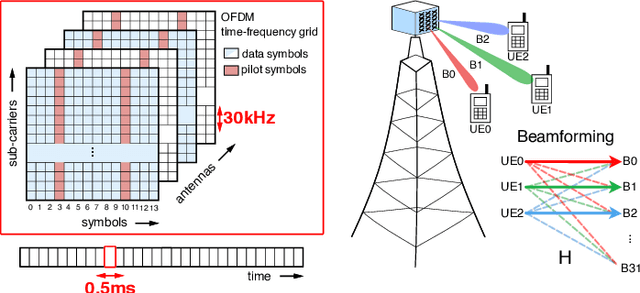
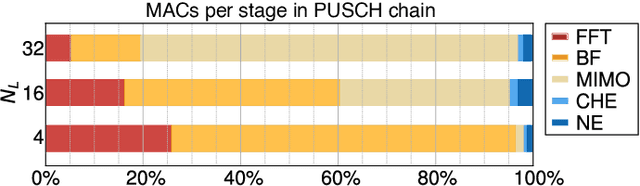
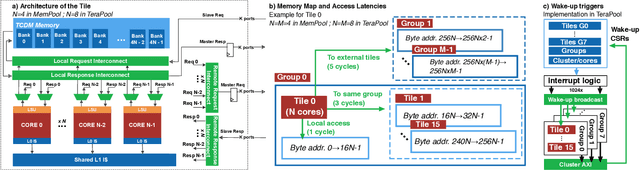
5G Radio access network disaggregation and softwarization pose challenges in terms of computational performance to the processing units. At the physical layer level, the baseband processing computational effort is typically offloaded to specialized hardware accelerators. However, the trend toward software-defined radio-access networks demands flexible, programmable architectures. In this paper, we explore the software design, parallelization and optimization of the key kernels of the lower physical layer (PHY) for physical uplink shared channel (PUSCH) reception on MemPool and TeraPool, two manycore systems having respectively 256 and 1024 small and efficient RISC-V cores with a large shared L1 data memory. PUSCH processing is demanding and strictly time-constrained, it represents a challenge for the baseband processors, and it is also common to most of the uplink channels. Our analysis thus generalizes to the entire lower PHY of the uplink receiver at gNodeB (gNB). Based on the evaluation of the computational effort (in multiply-accumulate operations) required by the PUSCH algorithmic stages, we focus on the parallel implementation of the dominant kernels, namely fast Fourier transform, matrix-matrix multiplication, and matrix decomposition kernels for the solution of linear systems. Our optimized parallel kernels achieve respectively on MemPool and TeraPool speedups of 211, 225, 158, and 762, 880, 722, at high utilization (0.81, 0.89, 0.71, and 0.74, 0.88, 0.71), comparable a single-core serial execution, moving a step closer toward a full-software PUSCH implementation.