 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
JoJoNet: Joint-contrast and Joint-sampling-and-reconstruction Network for Multi-contrast MRI
Oct 27, 2022
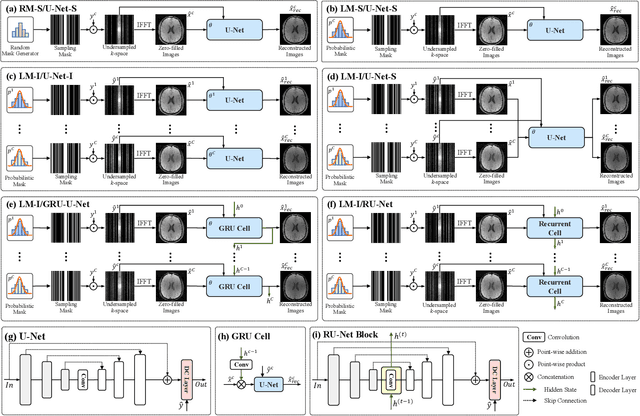
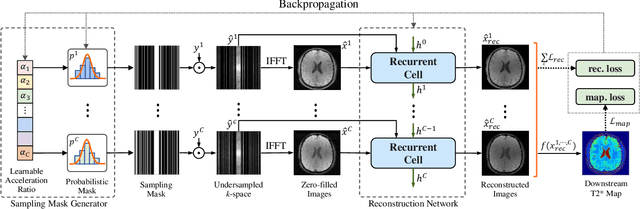
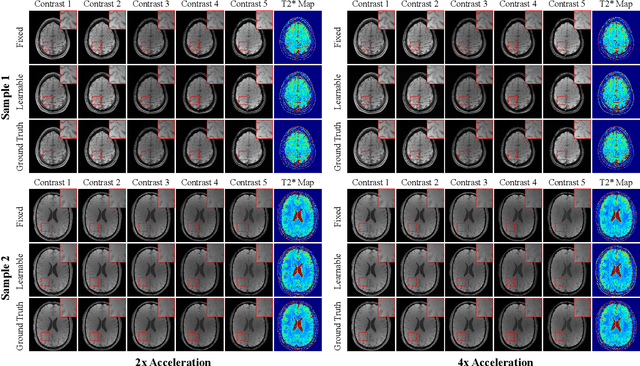
Multi-contrast Magnetic Resonance Imaging (MRI) generates multiple medical images with rich and complementary information for routine clinical use; however, it suffers from a long acquisition time. Recent works for accelerating MRI, mainly designed for single contrast, may not be optimal for multi-contrast scenario since the inherent correlations among the multi-contrast images are not exploited. In addition, independent reconstruction of each contrast usually does not translate to optimal performance of downstream tasks. Motivated by these aspects, in this paper we design an end-to-end framework for accelerating multi-contrast MRI which simultaneously optimizes the entire MR imaging workflow including sampling, reconstruction and downstream tasks to achieve the best overall outcomes. The proposed framework consists of a sampling mask generator for each image contrast and a reconstructor exploiting the inter-contrast correlations with a recurrent structure which enables the information sharing in a holistic way. The sampling mask generator and the reconstructor are trained jointly across the multiple image contrasts. The acceleration ratio of each image contrast is also learnable and can be driven by a downstream task performance. We validate our approach on a multi-contrast brain dataset and a multi-contrast knee dataset. Experiments show that (1) our framework consistently outperforms the baselines designed for single contrast on both datasets; (2) our newly designed recurrent reconstruction network effectively improves the reconstruction quality for multi-contrast images; (3) the learnable acceleration ratio improves the downstream task performance significantly. Overall, this work has potentials to open up new avenues for optimizing the entire multi-contrast MR imaging workflow.
Self-Supervised Training of Speaker Encoder with Multi-Modal Diverse Positive Pairs
Oct 27, 2022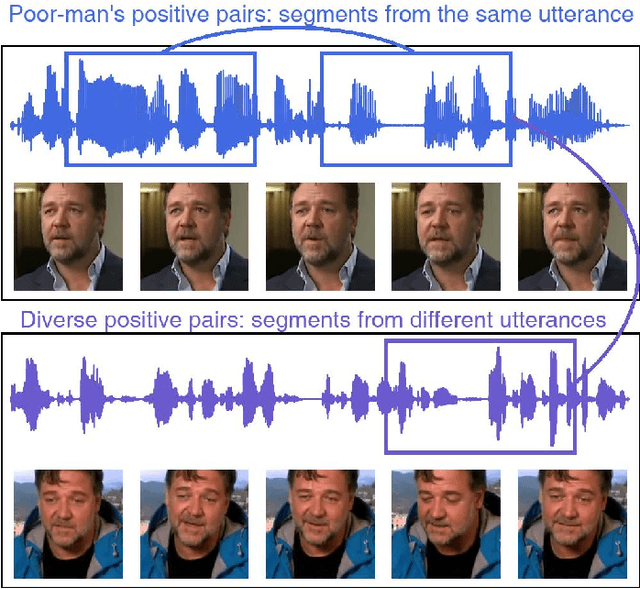
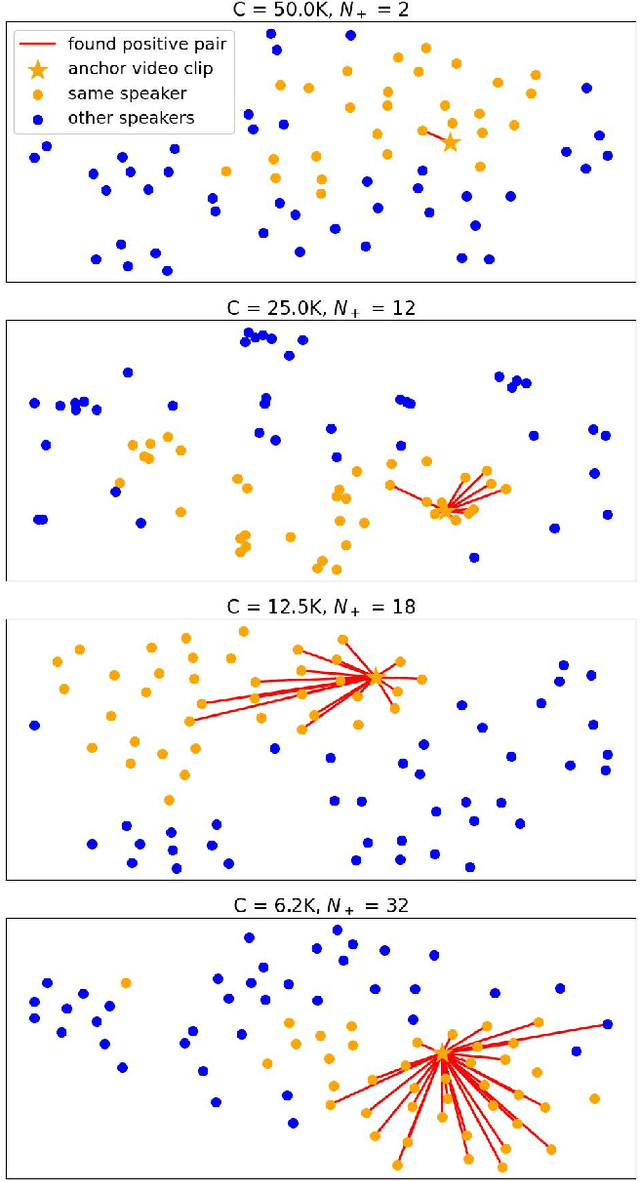
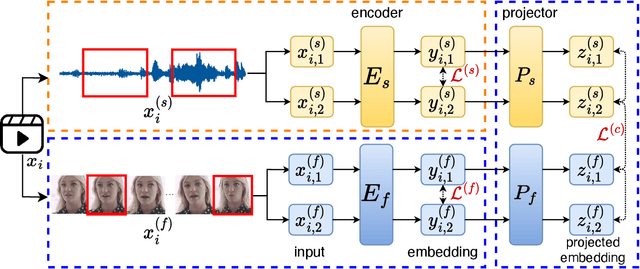
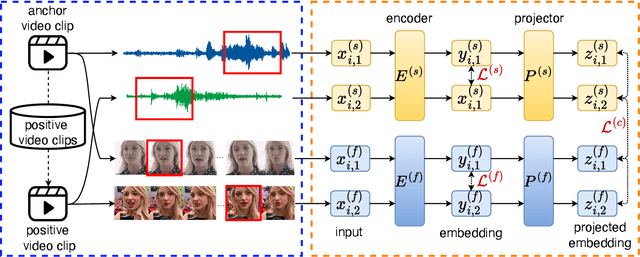
We study a novel neural architecture and its training strategies of speaker encoder for speaker recognition without using any identity labels. The speaker encoder is trained to extract a fixed-size speaker embedding from a spoken utterance of various length. Contrastive learning is a typical self-supervised learning technique. However, the quality of the speaker encoder depends very much on the sampling strategy of positive and negative pairs. It is common that we sample a positive pair of segments from the same utterance. Unfortunately, such poor-man's positive pairs (PPP) lack necessary diversity for the training of a robust encoder. In this work, we propose a multi-modal contrastive learning technique with novel sampling strategies. By cross-referencing between speech and face data, we study a method that finds diverse positive pairs (DPP) for contrastive learning, thus improving the robustness of the speaker encoder. We train the speaker encoder on the VoxCeleb2 dataset without any speaker labels, and achieve an equal error rate (EER) of 2.89\%, 3.17\% and 6.27\% under the proposed progressive clustering strategy, and an EER of 1.44\%, 1.77\% and 3.27\% under the two-stage learning strategy with pseudo labels, on the three test sets of VoxCeleb1. This novel solution outperforms the state-of-the-art self-supervised learning methods by a large margin, at the same time, achieves comparable results with the supervised learning counterpart. We also evaluate our self-supervised learning technique on LRS2 and LRW datasets, where the speaker information is unknown. All experiments suggest that the proposed neural architecture and sampling strategies are robust across datasets.
Neural parameter calibration for large-scale multi-agent models
Sep 27, 2022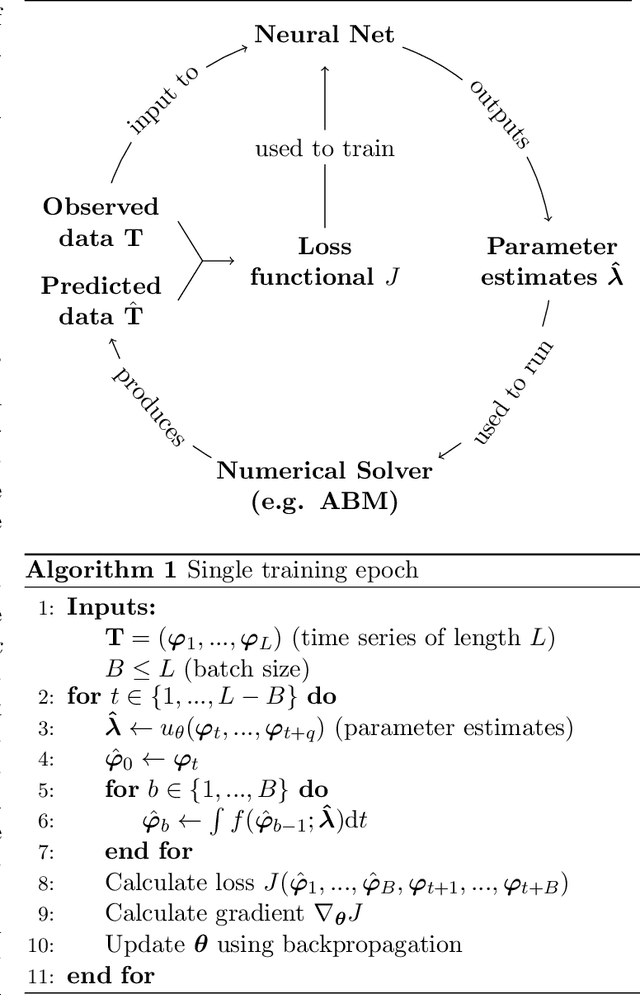
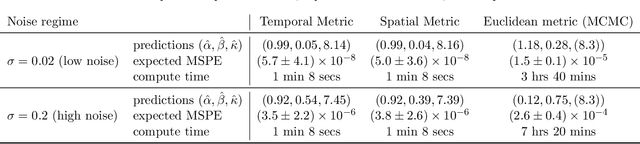

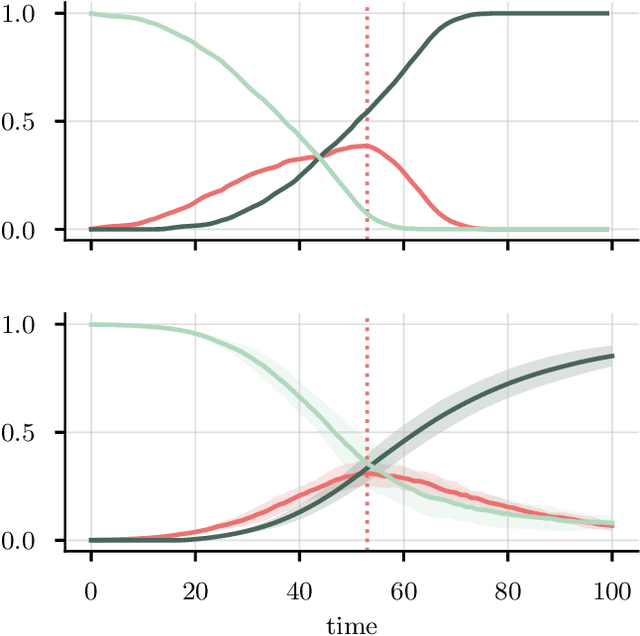
Computational models have become a powerful tool in the quantitative sciences to understand the behaviour of complex systems that evolve in time. However, they often contain a potentially large number of free parameters whose values cannot be obtained from theory but need to be inferred from data. This is especially the case for models in the social sciences, economics, or computational epidemiology. Yet many current parameter estimation methods are mathematically involved and computationally slow to run. In this paper we present a computationally simple and fast method to retrieve accurate probability densities for model parameters using neural differential equations. We present a pipeline comprising multi-agent models acting as forward solvers for systems of ordinary or stochastic differential equations, and a neural network to then extract parameters from the data generated by the model. The two combined create a powerful tool that can quickly estimate densities on model parameters, even for very large systems. We demonstrate the method on synthetic time series data of the SIR model of the spread of infection, and perform an in-depth analysis of the Harris-Wilson model of economic activity on a network, representing a non-convex problem. For the latter, we apply our method both to synthetic data and to data of economic activity across Greater London. We find that our method calibrates the model orders of magnitude more accurately than a previous study of the same dataset using classical techniques, while running between 195 and 390 times faster.
Continuous and Discrete LTI Systems
Aug 25, 2022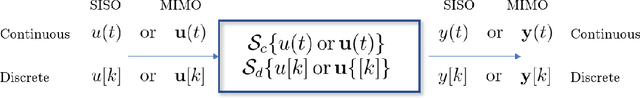
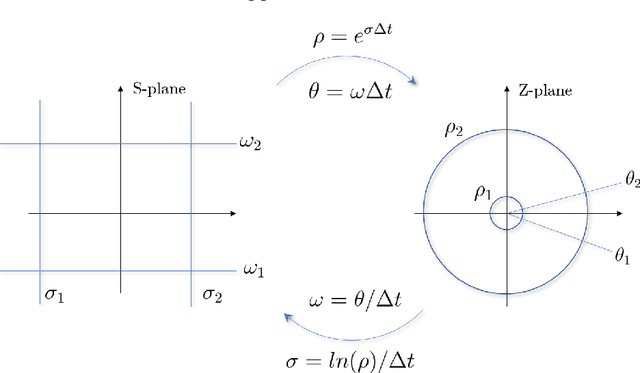
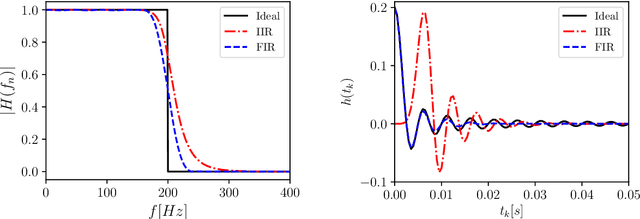
This chapter reviews the fundamentals of continuous and discrete Linear Time-Invariant (LTI) systems with Single Input-Single Output (SISO). We start from the general notions of signals and systems, the signal representation problem and the related orthogonal bases in discrete and continuous forms. We then move to the key properties of LTI systems and discuss their eigenfunctions, the input-output relations in the time and frequency domains, the conformal mapping linking the continuous and the discrete formulations, and the modeling via differential and difference equations. Finally, we close with two important applications: (linear) models for time series analysis and forecasting and (linear) digital filters for multi-resolution analysis. This chapter contains seven exercises, the solution of which is provided in the book's webpage.
Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models
Oct 06, 2022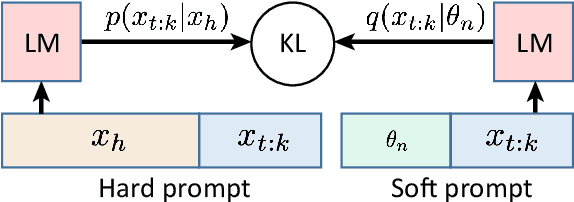

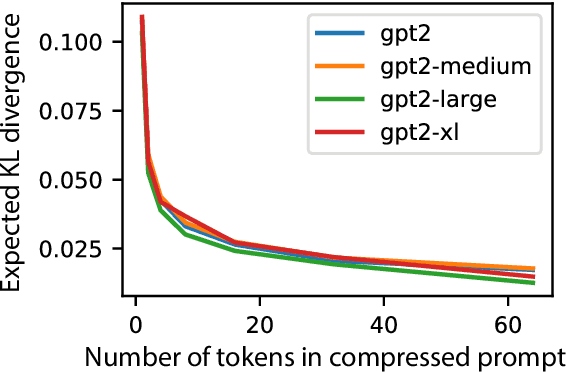
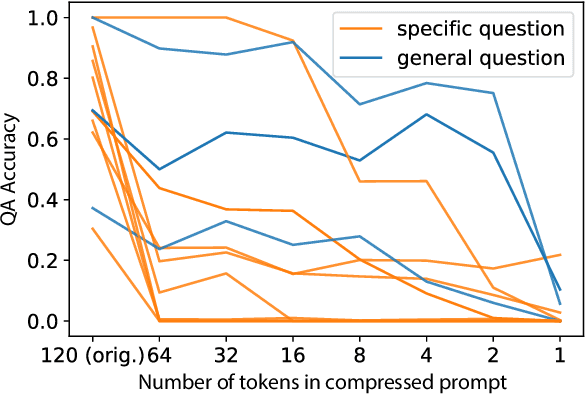
We explore the idea of compressing the prompts used to condition language models, and show that compressed prompts can retain a substantive amount of information about the original prompt. For severely compressed prompts, while fine-grained information is lost, abstract information and general sentiments can be retained with surprisingly few parameters, which can be useful in the context of decode-time algorithms for controllability and toxicity reduction. We explore contrastive conditioning to steer language model generation towards desirable text and away from undesirable text, and find that some complex prompts can be effectively compressed into a single token to guide generation. We also show that compressed prompts are largely compositional, and can be constructed such that they can be used to control independent aspects of generated text.
An adaptive multi-fidelity framework for safety analysis of connected and automated vehicles
Oct 25, 2022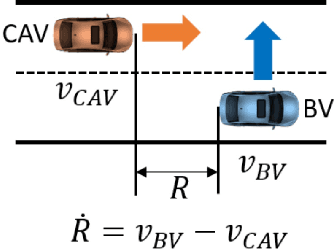
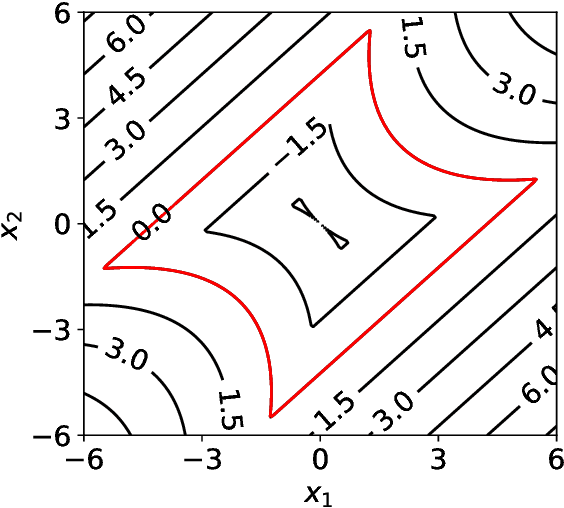
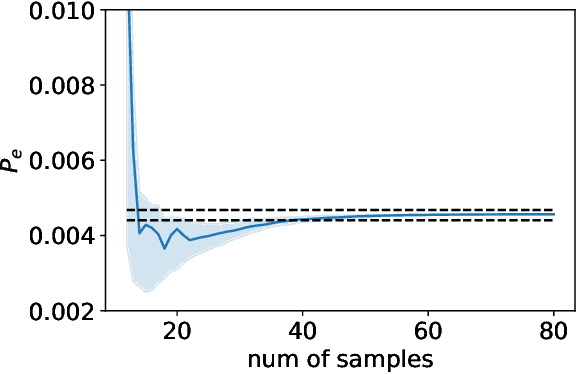
Testing and evaluation are expensive but critical steps in the development and deployment of connected and automated vehicles (CAVs). In this paper, we develop an adaptive sampling framework to efficiently evaluate the accident rate of CAVs, particularly for scenario-based tests where the probability distribution of input parameters is known from the Naturalistic Driving Data. Our framework relies on a surrogate model to approximate the CAV performance and a novel acquisition function to maximize the benefit (information to accident rate) of the next sample formulated through an information-theoretic consideration. In addition to the standard application with only a single high-fidelity model of CAV performance, we also extend our approach to the bi-fidelity context where an additional low-fidelity model can be used at a lower computational cost to approximate the CAV performance. Accordingly for the second case, our approach is formulated such that it allows the choice of the next sample, in terms of both fidelity level (i.e., which model to use) and sampling location to maximize the benefit per cost. Our framework is tested in a widely-considered two-dimensional cut-in problem for CAVs, where Intelligent Driving Model (IDM) with different time resolutions are used to construct the high and low-fidelity models. We show that our single-fidelity method outperforms the existing approach for the same problem, and the bi-fidelity method can further save half of the computational cost to reach a similar accuracy in estimating the accident rate.
One-shot, Offline and Production-Scalable PID Optimisation with Deep Reinforcement Learning
Oct 25, 2022
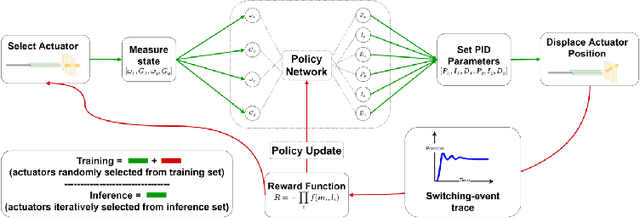
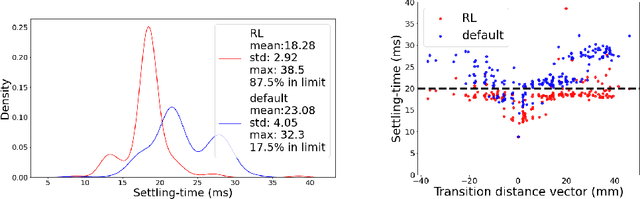
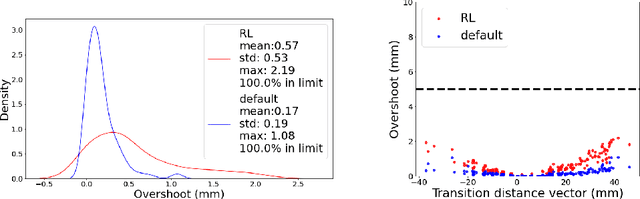
Proportional-integral-derivative (PID) control underlies more than $97\%$ of automated industrial processes. Controlling these processes effectively with respect to some specified set of performance goals requires finding an optimal set of PID parameters to moderate the PID loop. Tuning these parameters is a long and exhaustive process. A method (patent pending) based on deep reinforcement learning is presented that learns a relationship between generic system properties (e.g. resonance frequency), a multi-objective performance goal and optimal PID parameter values. Performance is demonstrated in the context of a real optical switching product of the foremost manufacturer of such devices globally. Switching is handled by piezoelectric actuators where switching time and optical loss are derived from the speed and stability of actuator-control processes respectively. The method achieves a $5\times$ improvement in the number of actuators that fall within the most challenging target switching speed, $\geq 20\%$ improvement in mean switching speed at the same optical loss and $\geq 75\%$ reduction in performance inconsistency when temperature varies between 5 and 73 degrees celcius. Furthermore, once trained (which takes $\mathcal{O}(hours)$), the model generates actuator-unique PID parameters in a one-shot inference process that takes $\mathcal{O}(ms)$ in comparison to up to $\mathcal{O}(week)$ required for conventional tuning methods, therefore accomplishing these performance improvements whilst achieving up to a $10^6\times$ speed-up. After training, the method can be applied entirely offline, incurring effectively zero optimisation-overhead in production.
Test time Adaptation through Perturbation Robustness
Oct 19, 2021
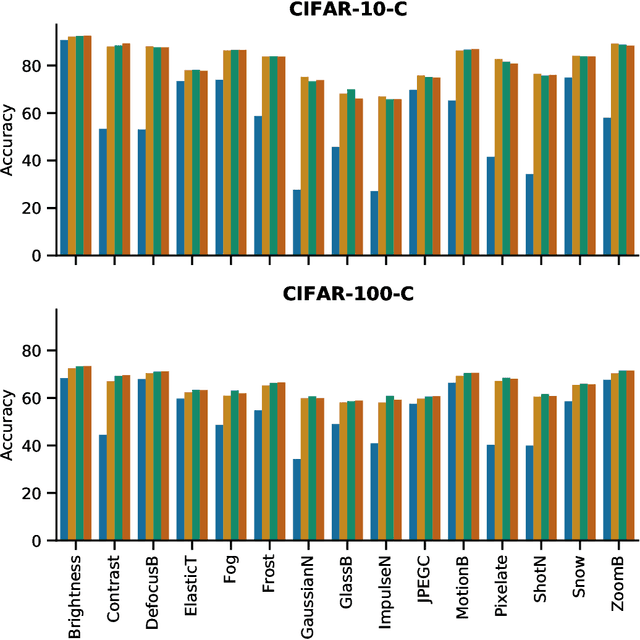

Data samples generated by several real world processes are dynamic in nature \textit{i.e.}, their characteristics vary with time. Thus it is not possible to train and tackle all possible distributional shifts between training and inference, using the host of transfer learning methods in literature. In this paper, we tackle this problem of adapting to domain shift at inference time \textit{i.e.}, we do not change the training process, but quickly adapt the model at test-time to handle any domain shift. For this, we propose to enforce consistency of predictions of data sampled in the vicinity of test sample on the image manifold. On a host of test scenarios like dealing with corruptions (CIFAR-10-C and CIFAR-100-C), and domain adaptation (VisDA-C), our method is at par or significantly outperforms previous methods.
A Spiking Neural Network Learning Markov Chain
Sep 20, 2022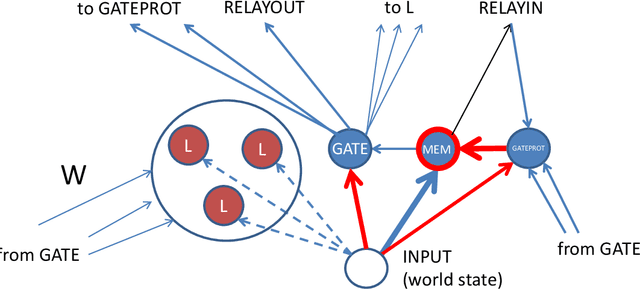
In this paper, the question how spiking neural network (SNN) learns and fixes in its internal structures a model of external world dynamics is explored. This question is important for implementation of the model-based reinforcement learning (RL), the realistic RL regime where the decisions made by SNN and their evaluation in terms of reward/punishment signals may be separated by significant time interval and sequence of intermediate evaluation-neutral world states. In the present work, I formalize world dynamics as a Markov chain with unknown a priori state transition probabilities, which should be learnt by the network. To make this problem formulation more realistic, I solve it in continuous time, so that duration of every state in the Markov chain may be different and is unknown. It is demonstrated how this task can be accomplished by an SNN with specially designed structure and local synaptic plasticity rules. As an example, we show how this network motif works in the simple but non-trivial world where a ball moves inside a square box and bounces from its walls with a random new direction and velocity.
RASR: Risk-Averse Soft-Robust MDPs with EVaR and Entropic Risk
Sep 14, 2022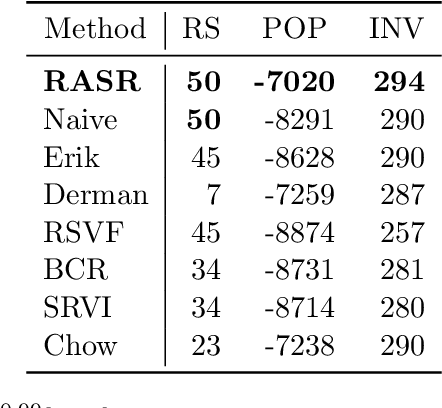

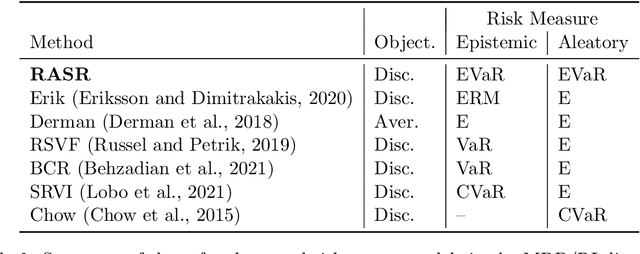
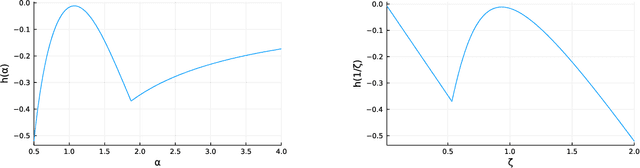
Prior work on safe Reinforcement Learning (RL) has studied risk-aversion to randomness in dynamics (aleatory) and to model uncertainty (epistemic) in isolation. We propose and analyze a new framework to jointly model the risk associated with epistemic and aleatory uncertainties in finite-horizon and discounted infinite-horizon MDPs. We call this framework that combines Risk-Averse and Soft-Robust methods RASR. We show that when the risk-aversion is defined using either EVaR or the entropic risk, the optimal policy in RASR can be computed efficiently using a new dynamic program formulation with a time-dependent risk level. As a result, the optimal risk-averse policies are deterministic but time-dependent, even in the infinite-horizon discounted setting. We also show that particular RASR objectives reduce to risk-averse RL with mean posterior transition probabilities. Our empirical results show that our new algorithms consistently mitigate uncertainty as measured by EVaR and other standard risk measures.