 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepJoin: Joinable Table Discovery with Pre-trained Language Models
Dec 15, 2022
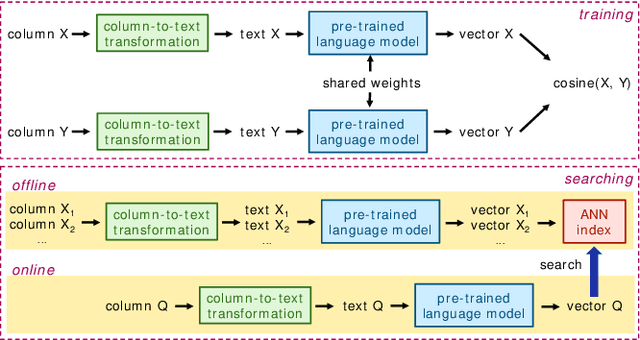

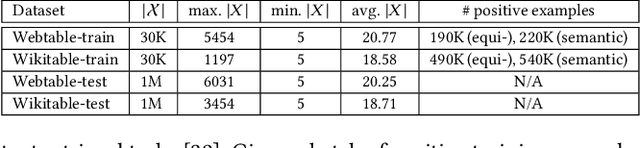
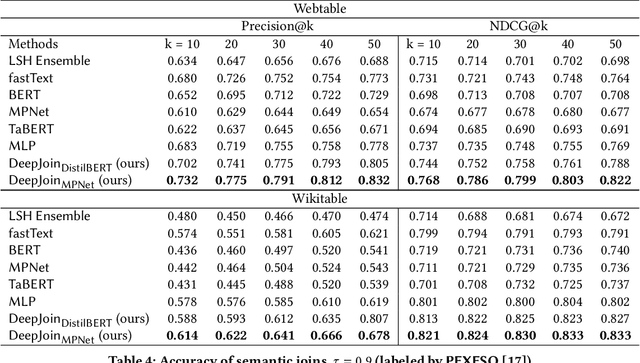
Due to the usefulness in data enrichment for data analysis tasks, joinable table discovery has become an important operation in data lake management. Existing approaches target equi-joins, the most common way of combining tables for creating a unified view, or semantic joins, which tolerate misspellings and different formats to deliver more join results. They are either exact solutions whose running time is linear in the sizes of query column and target table repository or approximate solutions lacking precision. In this paper, we propose Deepjoin, a deep learning model for accurate and efficient joinable table discovery. Our solution is an embedding-based retrieval, which employs a pre-trained language model (PLM) and is designed as one framework serving both equi- and semantic joins. We propose a set of contextualization options to transform column contents to a text sequence. The PLM reads the sequence and is fine-tuned to embed columns to vectors such that columns are expected to be joinable if they are close to each other in the vector space. Since the output of the PLM is fixed in length, the subsequent search procedure becomes independent of the column size. With a state-of-the-art approximate nearest neighbor search algorithm, the search time is logarithmic in the repository size. To train the model, we devise the techniques for preparing training data as well as data augmentation. The experiments on real datasets demonstrate that by training on a small subset of a corpus, Deepjoin generalizes to large datasets and its precision consistently outperforms other approximate solutions'. Deepjoin is even more accurate than an exact solution to semantic joins when evaluated with labels from experts. Moreover, when equipped with a GPU, Deepjoin is up to two orders of magnitude faster than existing solutions.
E-TRoll: Tactile Sensing and Classification via A Simple Robotic Gripper for Extended Rolling Manipulations
Dec 08, 2022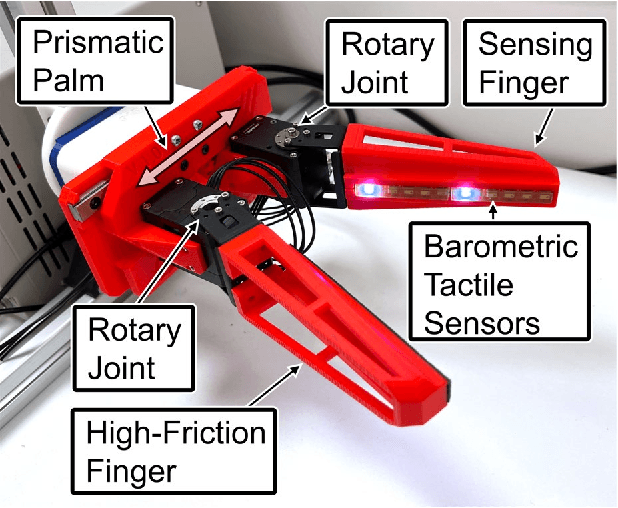
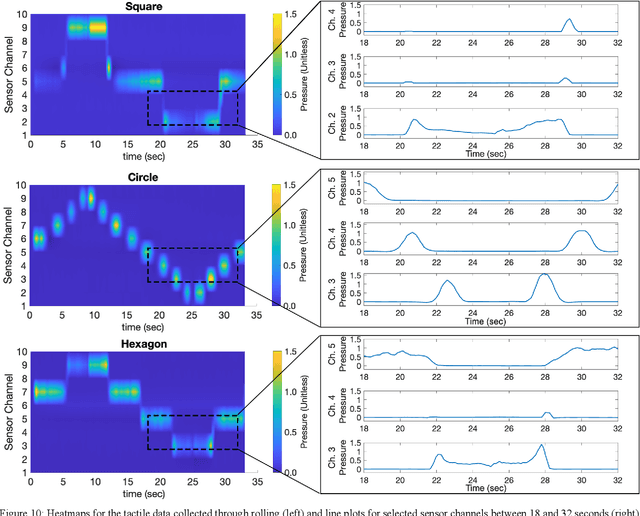
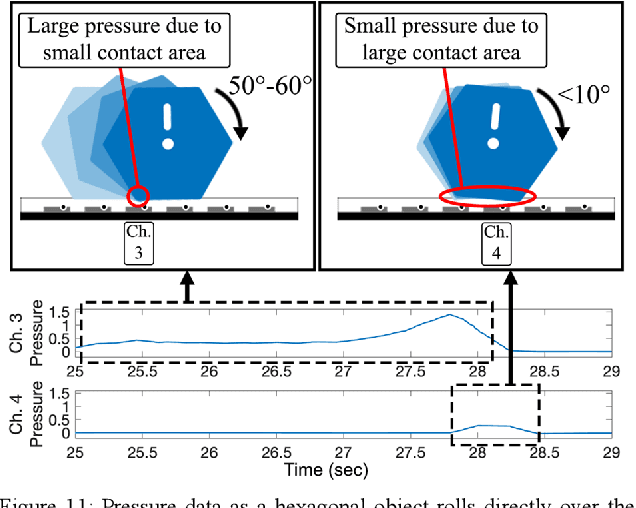
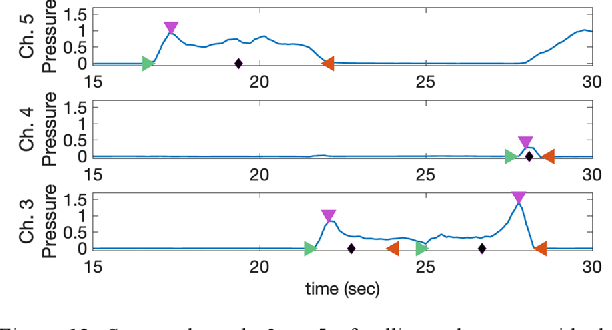
Robotic tactile sensing provides a method of recognizing objects and their properties where vision fails. Prior work on tactile perception in robotic manipulation has frequently focused on exploratory procedures (EPs). However, the also-human-inspired technique of in-hand-manipulation can glean rich data in a fraction of the time of EPs. We propose a simple 3-DOF robotic hand design, optimized for object rolling tasks via a variable-width palm and associated control system. This system dynamically adjusts the distance between the finger bases in response to object behavior. Compared to fixed finger bases, this technique significantly increases the area of the object that is exposed to finger-mounted tactile arrays during a single rolling motion (an increase of over 60% was observed for a cylinder with a 30-millimeter diameter). In addition, this paper presents a feature extraction algorithm for the collected spatiotemporal dataset, which focuses on object corner identification, analysis, and compact representation. This technique drastically reduces the dimensionality of each data sample from 10 x 1500 time series data to 80 features, which was further reduced by Principal Component Analysis (PCA) to 22 components. An ensemble subspace k-nearest neighbors (KNN) classification model was trained with 90 observations on rolling three different geometric objects, resulting in a three-fold cross-validation accuracy of 95.6% for object shape recognition.
FiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Dec 15, 2022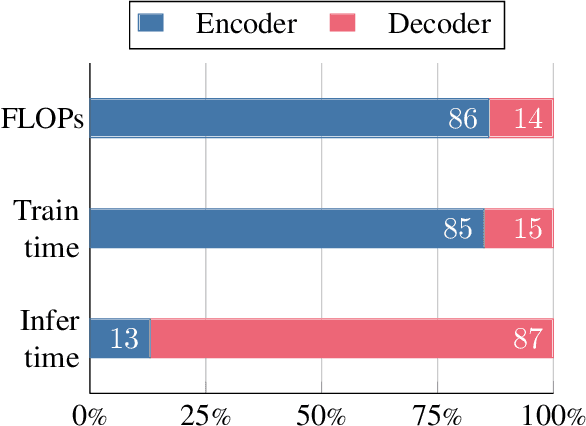

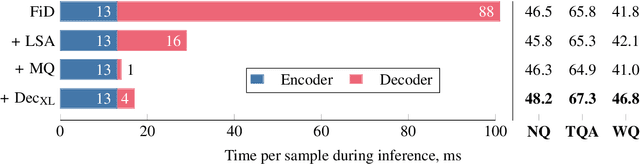
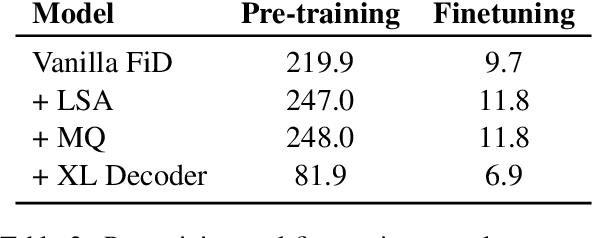
Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
Using Two Losses and Two Datasets Simultaneously to Improve TempoWiC Accuracy
Dec 15, 2022
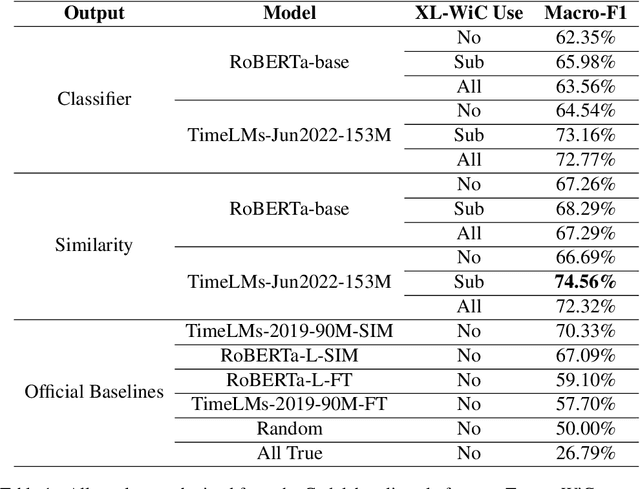
WSD (Word Sense Disambiguation) is the task of identifying which sense of a word is meant in a sentence or other segment of text. Researchers have worked on this task (e.g. Pustejovsky, 2002) for years but it's still a challenging one even for SOTA (state-of-the-art) LMs (language models). The new dataset, TempoWiC introduced by Loureiro et al. (2022b) focuses on the fact that words change over time. Their best baseline achieves 70.33% macro-F1. In this work, we use two different losses simultaneously to train RoBERTa-based classification models. We also improve our model by using another similar dataset to generalize better. Our best configuration beats their best baseline by 4.23% and reaches 74.56% macroF1.
Modelling spatiotemporal turbulent dynamics with the convolutional autoencoder echo state network
Nov 21, 2022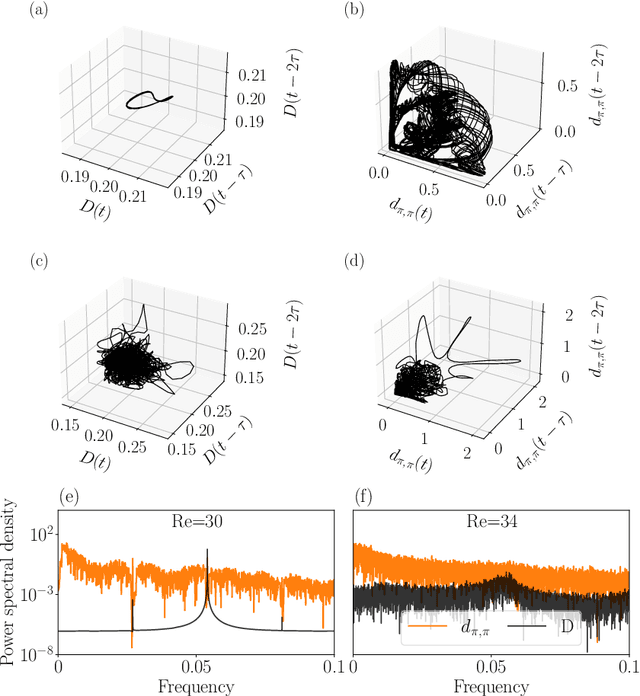
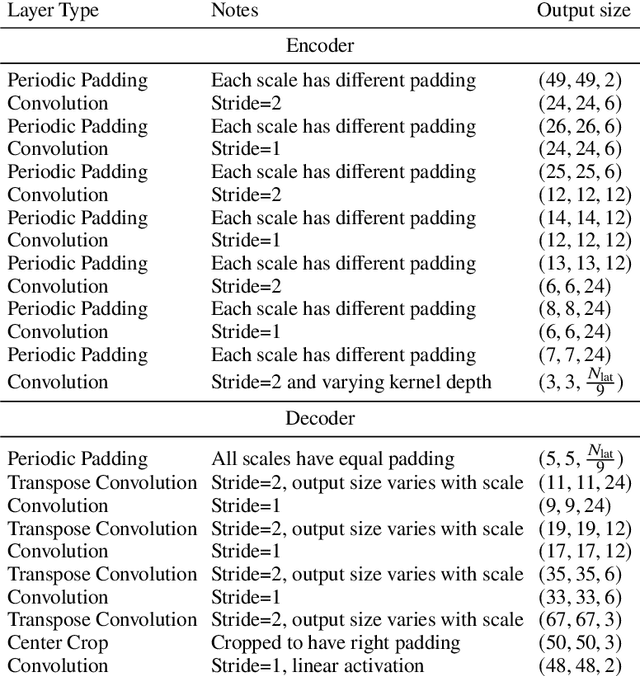
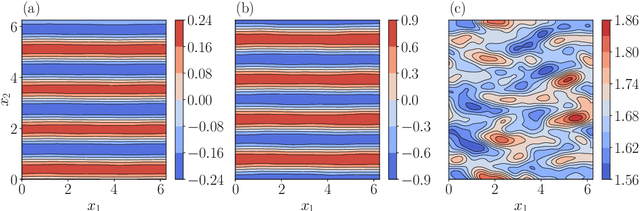
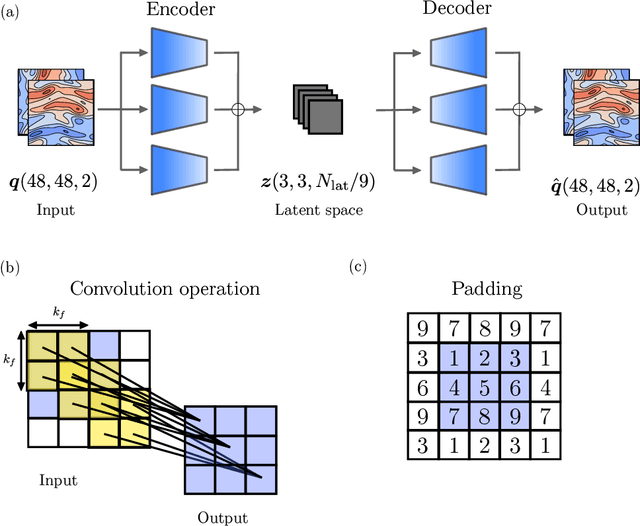
The spatiotemporal dynamics of turbulent flows is chaotic and difficult to predict. This makes the design of accurate and stable reduced-order models challenging. The overarching objective of this paper is to propose a nonlinear decomposition of the turbulent state for a reduced-order representation of the dynamics. We divide the turbulent flow into a spatial problem and a temporal problem. First, we compute the latent space, which is the manifold onto which the turbulent dynamics live (i.e., it is a numerical approximation of the turbulent attractor). The latent space is found by a series of nonlinear filtering operations, which are performed by a convolutional autoencoder (CAE). The CAE provides the decomposition in space. Second, we predict the time evolution of the turbulent state in the latent space, which is performed by an echo state network (ESN). The ESN provides the decomposition in time. Third, by assembling the CAE and the ESN, we obtain an autonomous dynamical system: the convolutional autoncoder echo state network (CAE-ESN). This is the reduced-order model of the turbulent flow. We test the CAE-ESN on a two-dimensional flow. We show that, after training, the CAE-ESN (i) finds a latent-space representation of the turbulent flow that has less than 1% of the degrees of freedom than the physical space; (ii) time-accurately and statistically predicts the flow in both quasiperiodic and turbulent regimes; (iii) is robust for different flow regimes (Reynolds numbers); and (iv) takes less than 1% of computational time to predict the turbulent flow than solving the governing equations. This work opens up new possibilities for nonlinear decompositions and reduced-order modelling of turbulent flows from data.
Singlularity Avoidance with Application to Online Trajectory Optimization for Serial Manipulators
Nov 10, 2022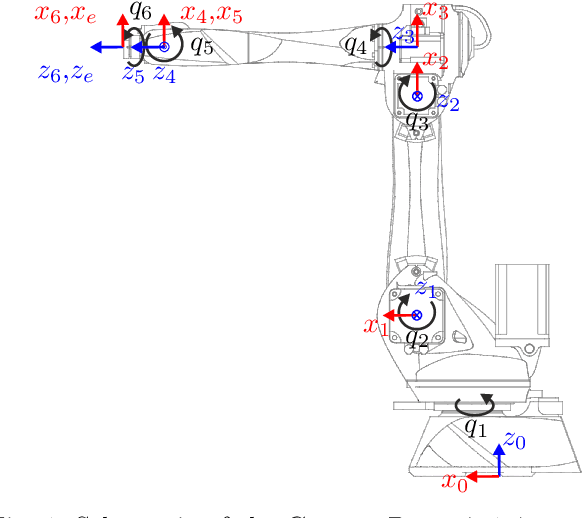
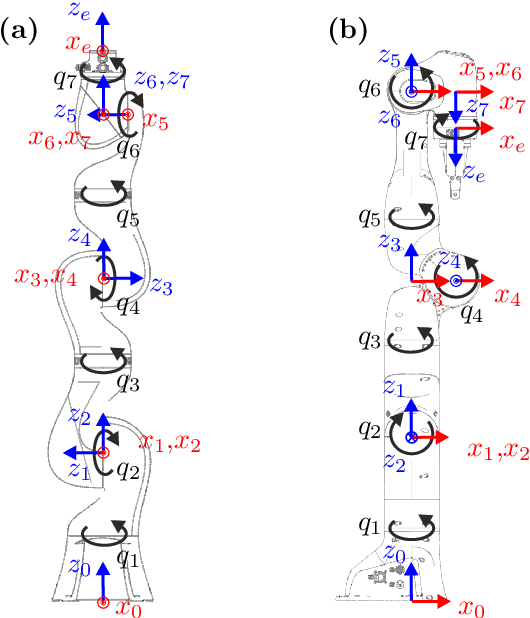


This work proposes a novel singularity avoidance approach for real-time trajectory optimization based on known singular configurations. The focus of this work lies on analyzing kinematically singular configurations for three robots with different kinematic structures, i.e., the Comau Racer 7-1.4, the KUKA LBR iiwa R820, and the Franka Emika Panda, and exploiting these configurations in form of tailored potential functions for singularity avoidance. Monte Carlo simulations of the proposed method and the commonly used manipulability maximization approach are performed for comparison. The numerical results show that the average computing time can be reduced and shorter trajectories in both time and path length are obtained with the proposed approach
Few-shot Non-line-of-sight Imaging with Signal-surface Collaborative Regularization
Nov 21, 2022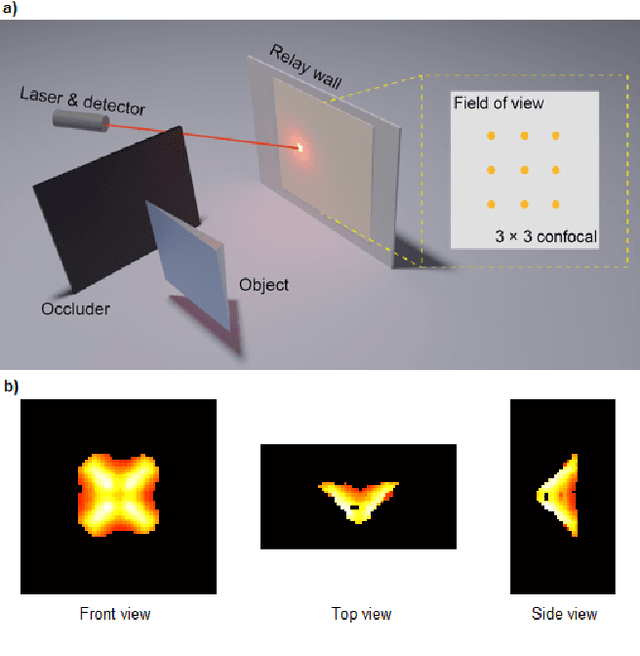

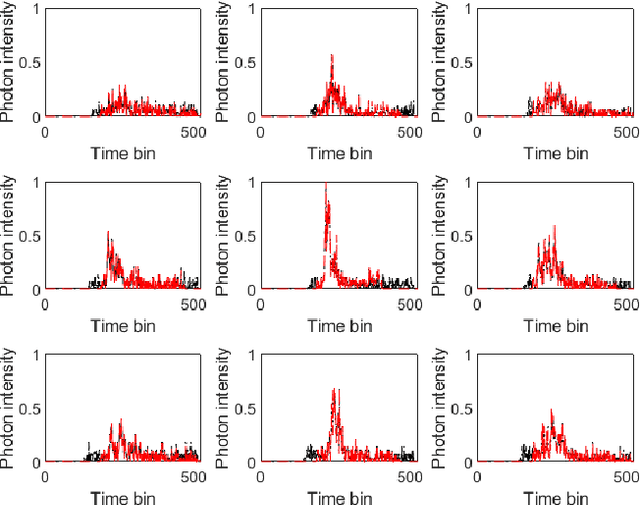

The non-line-of-sight imaging technique aims to reconstruct targets from multiply reflected light. For most existing methods, dense points on the relay surface are raster scanned to obtain high-quality reconstructions, which requires a long acquisition time. In this work, we propose a signal-surface collaborative regularization (SSCR) framework that provides noise-robust reconstructions with a minimal number of measurements. Using Bayesian inference, we design joint regularizations of the estimated signal, the 3D voxel-based representation of the objects, and the 2D surface-based description of the targets. To our best knowledge, this is the first work that combines regularizations in mixed dimensions for hidden targets. Experiments on synthetic and experimental datasets illustrated the efficiency and robustness of the proposed method under both confocal and non-confocal settings. We report the reconstruction of the hidden targets with complex geometric structures with only $5 \times 5$ confocal measurements from public datasets, indicating an acceleration of the conventional measurement process by a factor of 10000. Besides, the proposed method enjoys low time and memory complexities with sparse measurements. Our approach has great potential in real-time non-line-of-sight imaging applications such as rescue operations and autonomous driving.
A Novel Multi-Layer Modular Approach for Real-Time Gravitational-Wave Detection
Jun 13, 2022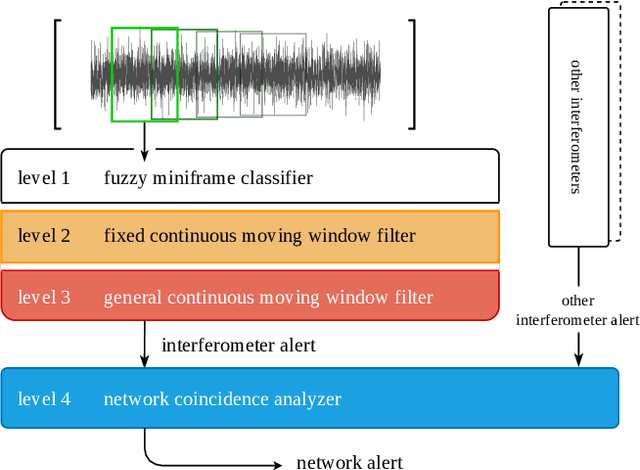
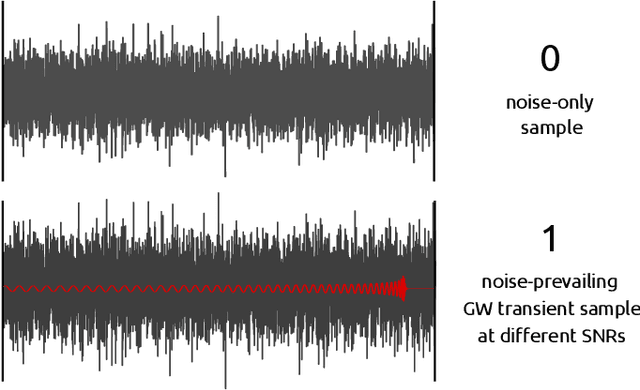
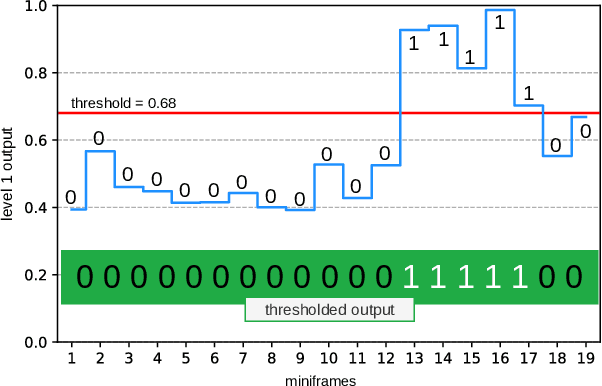
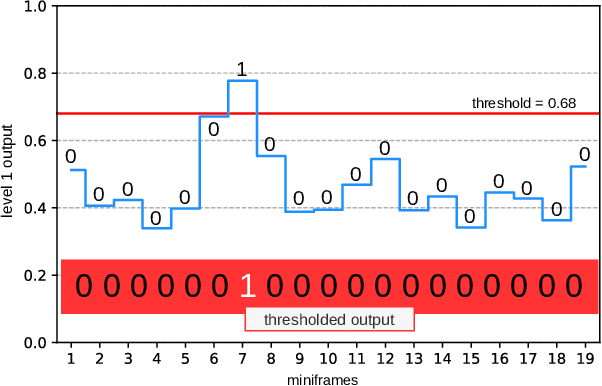
Advanced LIGO and Advanced Virgo ground-based interferometers are poised to probe an unprecedentedly large volume of space, enhancing the discovery power of the observations to even new sources of gravitational wave emitters. In this scenario, the development of highly optimized gravitational wave detection algorithms is crucial. We propose a novel layered framework for real-time detection of gravitational waves inspired by speech processing techniques and, in the present implementation, based on a state-of-the-art machine learning approach involving a hybridization of genetic programming and neural networks. The key aspects of the newly proposed framework are: the well structured, layered approach, and the low computational complexity. The paper describes the basic concepts of the framework and the derivation of the first three layers. Even if, in the present implementation, the layers are based on models derived using a machine learning approach, the proposed layered structure has a universal nature. To train and test the models, we used simulated binary black hole gravitational wave waveforms in synthetic Gaussian noise representative of Advanced LIGO sensitivity design. Compared to more complex approaches, such as convolutional neural networks, our framework, even using the simple ground model described in the paper, has similar performance but with a much lower computational complexity and a higher degree of modularity. Furthermore, the underlying exploitation of short-term features makes the results of the new framework virtually independent against time-position of gravitational wave signals, simplifying its future exploitation in real-time multi-layer pipelines for gravitational-wave detection with second generation interferometers.
Inflected Forms Are Redundant in Question Generation Models
Jan 01, 2023

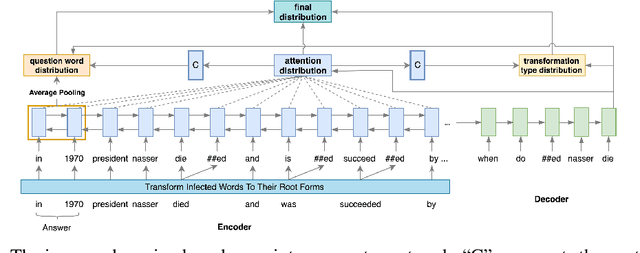
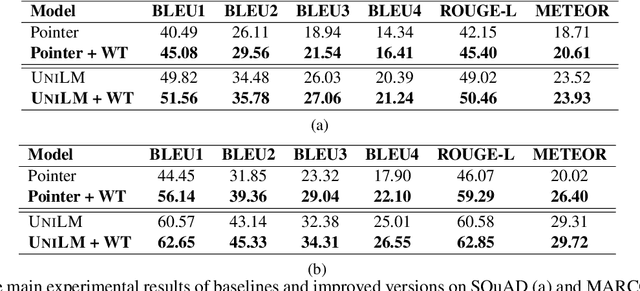
Neural models with an encoder-decoder framework provide a feasible solution to Question Generation (QG). However, after analyzing the model vocabulary we find that current models (both RNN-based and pre-training based) have more than 23\% inflected forms. As a result, the encoder will generate separate embeddings for the inflected forms, leading to a waste of training data and parameters. Even worse, in decoding these models are vulnerable to irrelevant noise and they suffer from high computational costs. In this paper, we propose an approach to enhance the performance of QG by fusing word transformation. Firstly, we identify the inflected forms of words from the input of encoder, and replace them with the root words, letting the encoder pay more attention to the repetitive root words. Secondly, we propose to adapt QG as a combination of the following actions in the encode-decoder framework: generating a question word, copying a word from the source sequence or generating a word transformation type. Such extension can greatly decrease the size of predicted words in the decoder as well as noise. We apply our approach to a typical RNN-based model and \textsc{UniLM} to get the improved versions. We conduct extensive experiments on SQuAD and MS MARCO datasets. The experimental results show that the improved versions can significantly outperform the corresponding baselines in terms of BLEU, ROUGE-L and METEOR as well as time cost.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023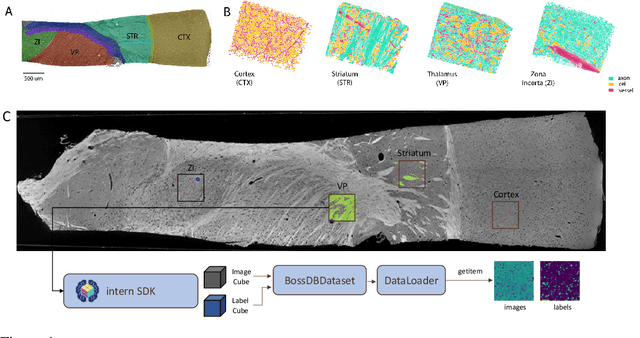
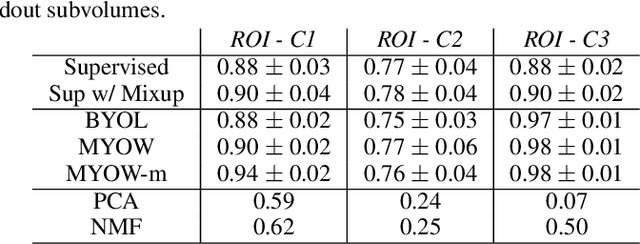

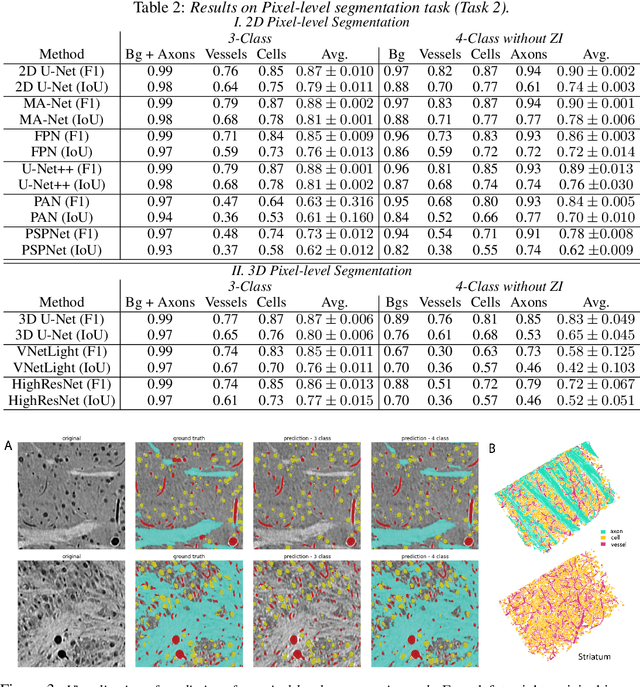
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .