 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy
Mar 01, 2023

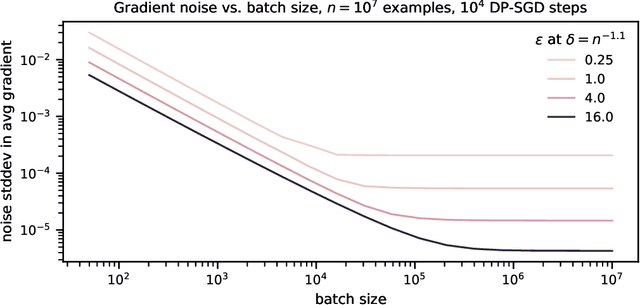

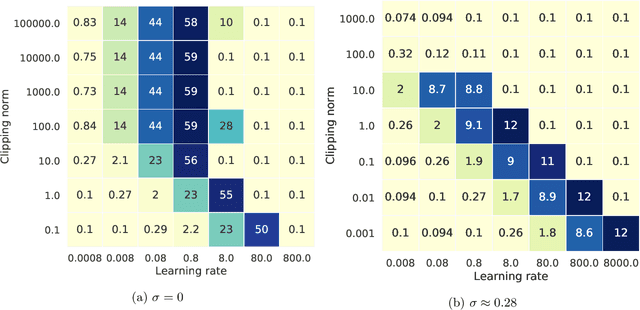
ML models are ubiquitous in real world applications and are a constant focus of research. At the same time, the community has started to realize the importance of protecting the privacy of ML training data. Differential Privacy (DP) has become a gold standard for making formal statements about data anonymization. However, while some adoption of DP has happened in industry, attempts to apply DP to real world complex ML models are still few and far between. The adoption of DP is hindered by limited practical guidance of what DP protection entails, what privacy guarantees to aim for, and the difficulty of achieving good privacy-utility-computation trade-offs for ML models. Tricks for tuning and maximizing performance are scattered among papers or stored in the heads of practitioners. Furthermore, the literature seems to present conflicting evidence on how and whether to apply architectural adjustments and which components are ``safe'' to use with DP. This work is a self-contained guide that gives an in-depth overview of the field of DP ML and presents information about achieving the best possible DP ML model with rigorous privacy guarantees. Our target audience is both researchers and practitioners. Researchers interested in DP for ML will benefit from a clear overview of current advances and areas for improvement. We include theory-focused sections that highlight important topics such as privacy accounting and its assumptions, and convergence. For a practitioner, we provide a background in DP theory and a clear step-by-step guide for choosing an appropriate privacy definition and approach, implementing DP training, potentially updating the model architecture, and tuning hyperparameters. For both researchers and practitioners, consistently and fully reporting privacy guarantees is critical, and so we propose a set of specific best practices for stating guarantees.
On the Importance of Feature Representation for Flood Mapping using Classical Machine Learning Approaches
Mar 01, 2023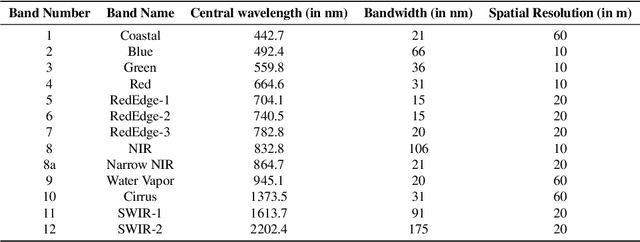
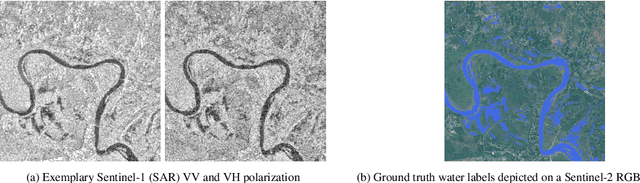

Climate change has increased the severity and frequency of weather disasters all around the world. Flood inundation mapping based on earth observation data can help in this context, by providing cheap and accurate maps depicting the area affected by a flood event to emergency-relief units in near-real-time. Building upon the recent development of the Sen1Floods11 dataset, which provides a limited amount of hand-labeled high-quality training data, this paper evaluates the potential of five traditional machine learning approaches such as gradient boosted decision trees, support vector machines or quadratic discriminant analysis. By performing a grid-search-based hyperparameter optimization on 23 feature spaces we can show that all considered classifiers are capable of outperforming the current state-of-the-art neural network-based approaches in terms of total IoU on their best-performing feature spaces. With total and mean IoU values of 0.8751 and 0.7031 compared to 0.70 and 0.5873 as the previous best-reported results, we show that a simple gradient boosting classifier can significantly improve over deep neural network based approaches, despite using less training data. Furthermore, an analysis of the regional distribution of the Sen1Floods11 dataset reveals a problem of spatial imbalance. We show that traditional machine learning models can learn this bias and argue that modified metric evaluations are required to counter artifacts due to spatial imbalance. Lastly, a qualitative analysis shows that this pixel-wise classifier provides highly-precise surface water classifications indicating that a good choice of a feature space and pixel-wise classification can generate high-quality flood maps using optical and SAR data. We make our code publicly available at: https://github.com/DFKI-Earth-And-Space-Applications/Flood_Mapping_Feature_Space_Importance
Understanding Natural Language Understanding Systems. A Critical Analysis
Mar 01, 2023The development of machines that {\guillemotleft}talk like us{\guillemotright}, also known as Natural Language Understanding (NLU) systems, is the Holy Grail of Artificial Intelligence (AI), since language is the quintessence of human intelligence. The brief but intense life of NLU research in AI and Natural Language Processing (NLP) is full of ups and downs, with periods of high hopes that the Grail is finally within reach, typically followed by phases of equally deep despair and disillusion. But never has the trust that we can build {\guillemotleft}talking machines{\guillemotright} been stronger than the one engendered by the last generation of NLU systems. But is it gold all that glitters in AI? do state-of-the-art systems possess something comparable to the human knowledge of language? Are we at the dawn of a new era, in which the Grail is finally closer to us? In fact, the latest achievements of AI systems have sparkled, or better renewed, an intense scientific debate on their true language understanding capabilities. Some defend the idea that, yes, we are on the right track, despite the limits that computational models still show. Others are instead radically skeptic and even dismissal: The present limits are not just contingent and temporary problems of NLU systems, but the sign of the intrinsic inadequacy of the epistemological and technological paradigm grounding them. This paper aims at contributing to such debate by carrying out a critical analysis of the linguistic abilities of the most recent NLU systems. I contend that they incorporate important aspects of the way language is learnt and processed by humans, but at the same time they lack key interpretive and inferential skills that it is unlikely they can attain unless they are integrated with structured knowledge and the ability to exploit it for language use.
New starting point registration method for tagged MRI tongue motion estimation
Feb 08, 2023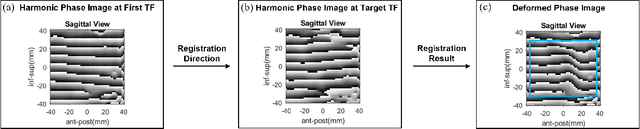
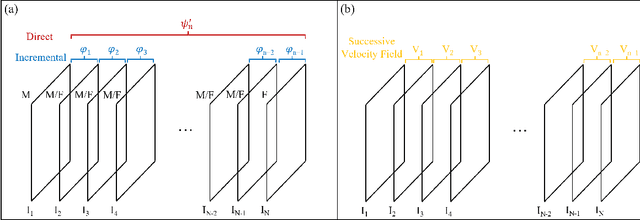
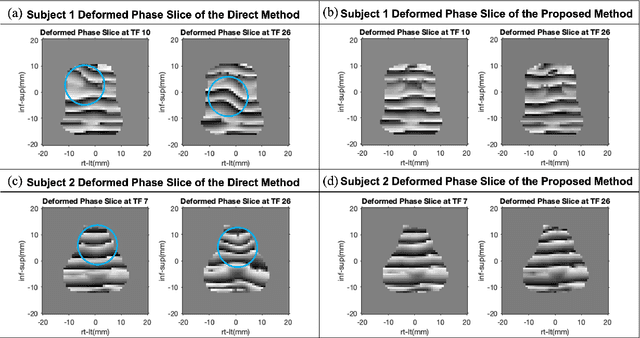
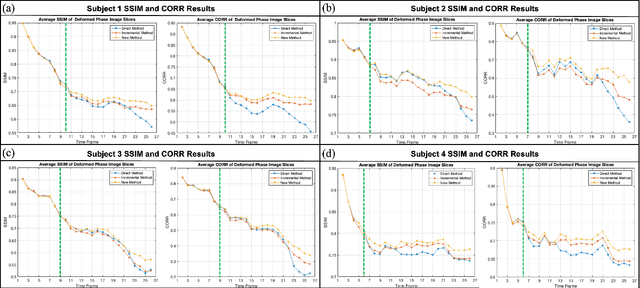
Accurate tongue motion estimation is essential for tongue function evaluation. The harmonic phase processing (HARP) method and the phase vector incompressible registration algorithm (PVIRA) based on HARP can generate motion estimates from tagged MRI images, but they suffer from tag jumping due to large motions. This paper proposes a new registration method by combining the stationary velocity fields produced by PVIRA between successive time frames as a new initialization of the final registration stage to avoid tag jumping. The experiment results demonstrate the proposed method can avoid tag jumping and outperform the existing methods on tongue motion estimates.
(Re)Defining Expertise in Machine Learning Development
Feb 08, 2023Domain experts are often engaged in the development of machine learning systems in a variety of ways, such as in data collection and evaluation of system performance. At the same time, who counts as an 'expert' and what constitutes 'expertise' is not always explicitly defined. In this project, we conduct a systematic literature review of machine learning research to understand 1) the bases on which expertise is defined and recognized and 2) the roles experts play in ML development. Our goal is to produce a high-level taxonomy to highlight limits and opportunities in how experts are identified and engaged in ML research.
Reception Reader: Exploring Text Reuse in Early Modern British Publications
Feb 08, 2023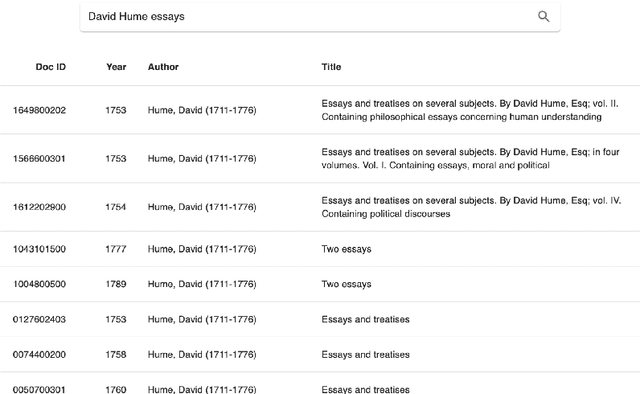
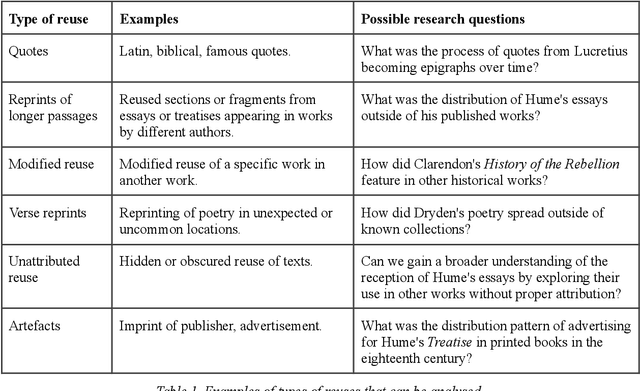
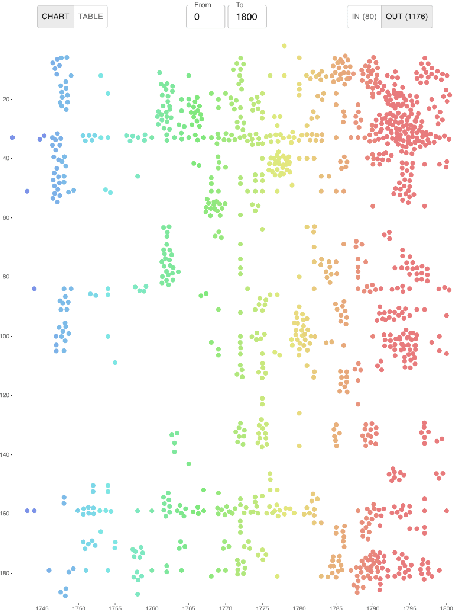

The Reception Reader is a web tool for studying text reuse in the Early English Books Online (EEBO-TCP) and Eighteenth Century Collections Online (ECCO) data. Users can: 1) explore a visual overview of the reception of a work, or its incoming connections, across time based on shared text segments, 2) interactively survey the details of connected documents, and 3) examine the context of reused text for "close reading". We show examples of how the tool streamlines research and exploration tasks, and discuss the utility and limitations of the user interface along with its current data sources.
Multi-Level Association Rule Mining for Wireless Network Time Series Data
Dec 15, 2022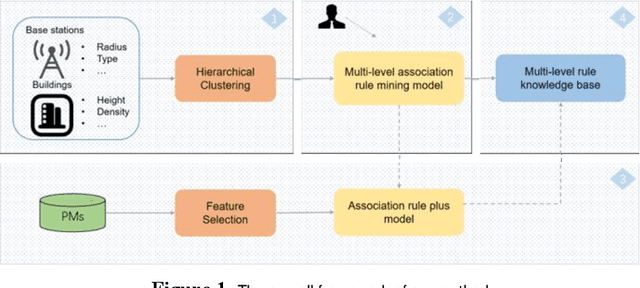
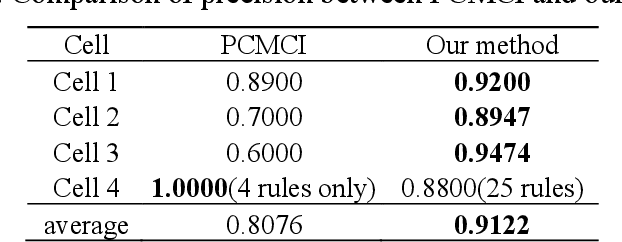
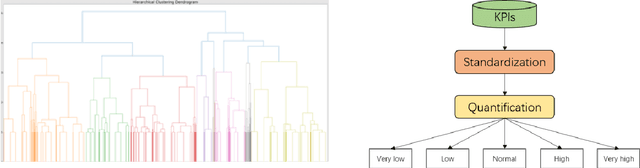
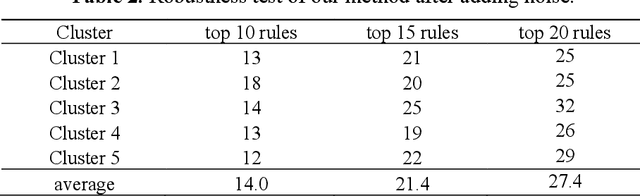
Key performance indicators(KPIs) are of great significance in the monitoring of wireless network service quality. The network service quality can be improved by adjusting relevant configuration parameters(CPs) of the base station. However, there are numerous CPs and different cells may affect each other, which bring great challenges to the association analysis of wireless network data. In this paper, we propose an adjustable multi-level association rule mining framework, which can quantitatively mine association rules at each level with environmental information, including engineering parameters and performance management(PMs), and it has interpretability at each level. Specifically, We first cluster similar cells, then quantify KPIs and CPs, and integrate expert knowledge into the association rule mining model, which improve the robustness of the model. The experimental results in real world dataset prove the effectiveness of our method.
USR: Unsupervised Separated 3D Garment and Human Reconstruction via Geometry and Semantic Consistency
Feb 22, 2023
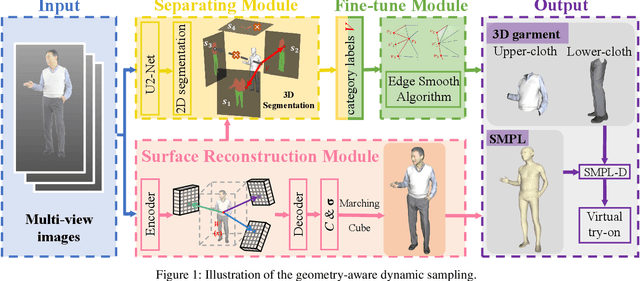
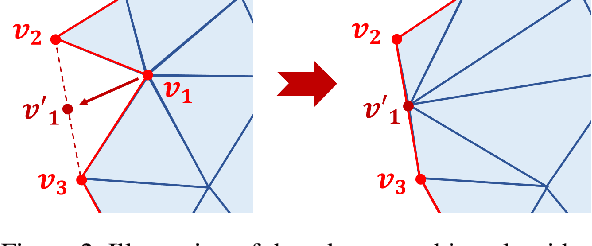
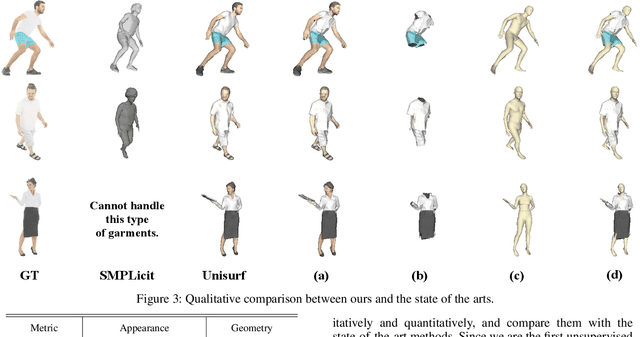
Dressed people reconstruction from images is a popular task with promising applications in the creative media and game industry. However, most existing methods reconstruct the human body and garments as a whole with the supervision of 3D models, which hinders the downstream interaction tasks and requires hard-to-obtain data. To address these issues, we propose an unsupervised separated 3D garments and human reconstruction model (USR), which reconstructs the human body and authentic textured clothes in layers without 3D models. More specifically, our method proposes a generalized surface-aware neural radiance field to learn the mapping between sparse multi-view images and geometries of the dressed people. Based on the full geometry, we introduce a Semantic and Confidence Guided Separation strategy (SCGS) to detect, segment, and reconstruct the clothes layer, leveraging the consistency between 2D semantic and 3D geometry. Moreover, we propose a Geometry Fine-tune Module to smooth edges. Extensive experiments on our dataset show that comparing with state-of-the-art methods, USR achieves improvements on both geometry and appearance reconstruction while supporting generalizing to unseen people in real time. Besides, we also introduce SMPL-D model to show the benefit of the separated modeling of clothes and the human body that allows swapping clothes and virtual try-on.
Mining compact high utility sequential patterns
Feb 22, 2023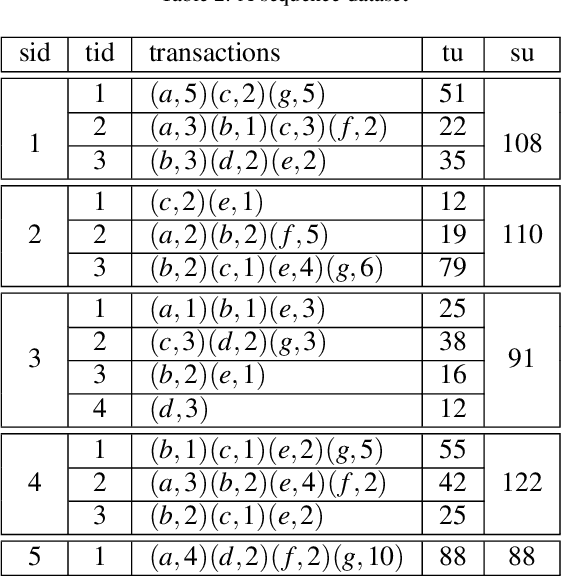
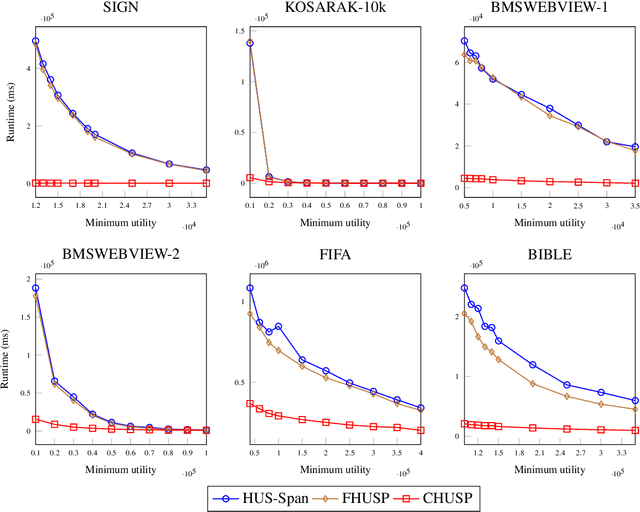
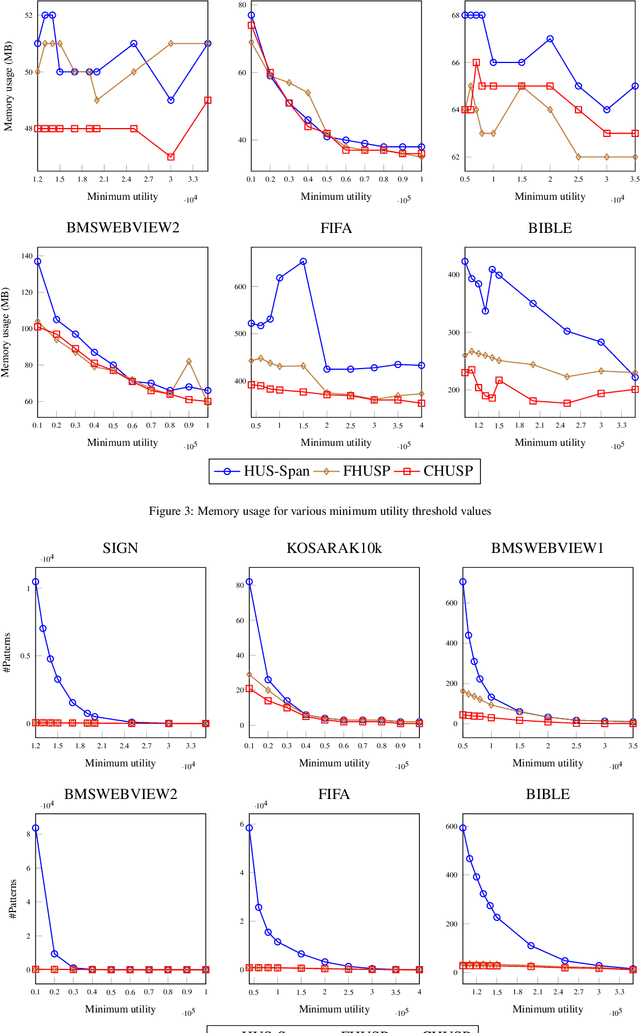
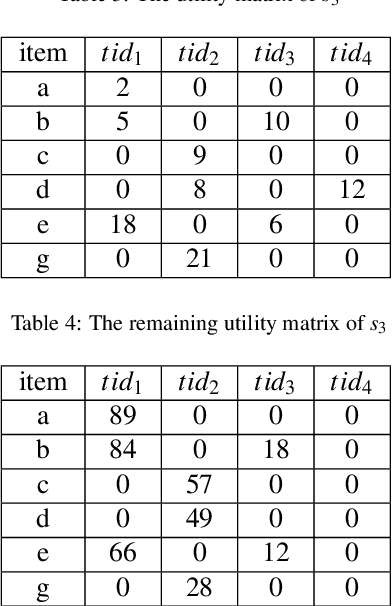
High utility sequential pattern mining (HUSPM) aims to mine all patterns that yield a high utility (profit) in a sequence dataset. HUSPM is useful for several applications such as market basket analysis, marketing, and website clickstream analysis. In these applications, users may also consider high utility patterns frequently appearing in the dataset to obtain more fruitful information. However, this task is high computation since algorithms may generate a combinatorial explosive number of candidates that may be redundant or of low importance. To reduce complexity and obtain a compact set of frequent high utility sequential patterns (FHUSPs), this paper proposes an algorithm named CHUSP for mining closed frequent high utility sequential patterns (CHUSPs). Such patterns keep a concise representation while preserving the same expressive power of the complete set of FHUSPs. The proposed algorithm relies on a CHUS data structure to maintain information during mining. It uses three pruning strategies to eliminate early low-utility and non-frequent patterns, thereby reducing the search space. An extensive experimental evaluation was performed on six real-life datasets to evaluate the performance of CHUSP in terms of execution time, memory usage, and the number of generated patterns. Experimental results show that CHUSP can efficiently discover the compact set of CHUSPs under different user-defined thresholds.
When Combinatorial Thompson Sampling meets Approximation Regret
Feb 22, 2023We study the Combinatorial Thompson Sampling policy (CTS) for combinatorial multi-armed bandit problems (CMAB), within an approximation regret setting. Although CTS has attracted a lot of interest, it has a drawback that other usual CMAB policies do not have when considering non-exact oracles: for some oracles, CTS has a poor approximation regret (scaling linearly with the time horizon $T$) [Wang and Chen, 2018]. A study is then necessary to discriminate the oracles on which CTS could learn. This study was started by Kong et al. [2021]: they gave the first approximation regret analysis of CTS for the greedy oracle, obtaining an upper bound of order $\mathcal{O}(\log(T)/\Delta^2)$, where $\Delta$ is some minimal reward gap. In this paper, our objective is to push this study further than the simple case of the greedy oracle. We provide the first $\mathcal{O}(\log(T)/\Delta)$ approximation regret upper bound for CTS, obtained under a specific condition on the approximation oracle, allowing a reduction to the exact oracle analysis. We thus term this condition REDUCE2EXACT, and observe that it is satisfied in many concrete examples. Moreover, it can be extended to the probabilistically triggered arms setting, thus capturing even more problems, such as online influence maximization.