 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Meaning at Scale: Evaluating Semantic Search for 18th-Century Intellectual History through the Case of Locke
May 10, 2026While digitized corpora have transformed the study of intellectual transmission, current methods rely heavily on lexical text reuse detection, capturing verbatim quotations but fundamentally missing paraphrases and complex implicit engagement. This paper evaluates semantic search in 18th-century intellectual history through the reception of John Locke's foundational work. Using expert annotation grounded in a semantic taxonomy, we examine whether an off-the-shelf semantic search pipeline can surface meaning-level correspondences overlooked by lexical methods. Our results demonstrate that semantic search retrieves substantially more implicit receptions than lexical baselines. However, linguistic diagnostics also reveal a "lexical gatekeeping" effect, where retrieval remains partially constrained by surface vocabulary overlap. These findings highlight both the potential and the limitations of semantic retrieval for analyzing the circulation of ideas in large historical corpora. The data is available at https://github.com/COMHIS/locke-sim-data.
Error Patterns in Historical OCR: A Comparative Analysis of TrOCR and a Vision-Language Model
Feb 16, 2026Optical Character Recognition (OCR) of eighteenth-century printed texts remains challenging due to degraded print quality, archaic glyphs, and non-standardized orthography. Although transformer-based OCR systems and Vision-Language Models (VLMs) achieve strong aggregate accuracy, metrics such as Character Error Rate (CER) and Word Error Rate (WER) provide limited insight into their reliability for scholarly use. We compare a dedicated OCR transformer (TrOCR) and a general-purpose Vision-Language Model (Qwen) on line-level historical English texts using length-weighted accuracy metrics and hypothesis driven error analysis. While Qwen achieves lower CER/WER and greater robustness to degraded input, it exhibits selective linguistic regularization and orthographic normalization that may silently alter historically meaningful forms. TrOCR preserves orthographic fidelity more consistently but is more prone to cascading error propagation. Our findings show that architectural inductive biases shape OCR error structure in systematic ways. Models with similar aggregate accuracy can differ substantially in error locality, detectability, and downstream scholarly risk, underscoring the need for architecture-aware evaluation in historical digitization workflows.
Reception Reader: Exploring Text Reuse in Early Modern British Publications
Feb 08, 2023The Reception Reader is a web tool for studying text reuse in the Early English Books Online (EEBO-TCP) and Eighteenth Century Collections Online (ECCO) data. Users can: 1) explore a visual overview of the reception of a work, or its incoming connections, across time based on shared text segments, 2) interactively survey the details of connected documents, and 3) examine the context of reused text for "close reading". We show examples of how the tool streamlines research and exploration tasks, and discuss the utility and limitations of the user interface along with its current data sources.
Topic modelling discourse dynamics in historical newspapers
Nov 20, 2020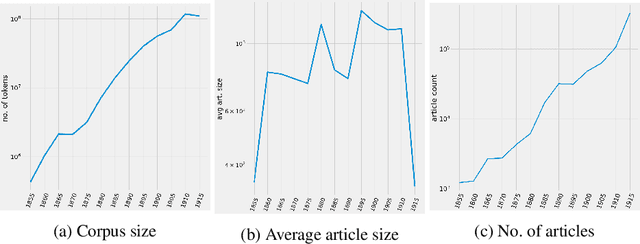
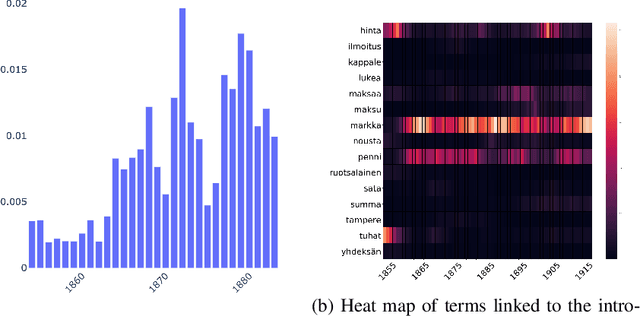
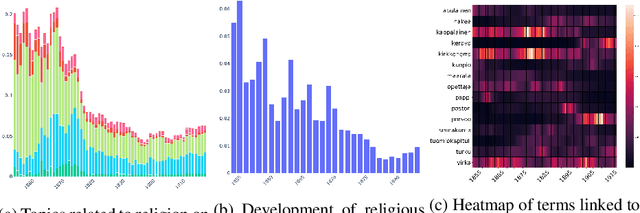
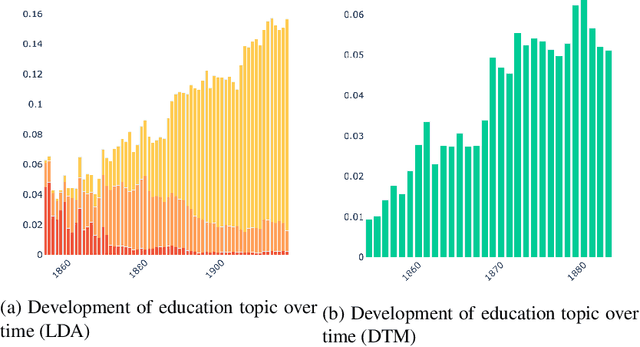
This paper addresses methodological issues in diachronic data analysis for historical research. We apply two families of topic models (LDA and DTM) on a relatively large set of historical newspapers, with the aim of capturing and understanding discourse dynamics. Our case study focuses on newspapers and periodicals published in Finland between 1854 and 1917, but our method can easily be transposed to any diachronic data. Our main contributions are a) a combined sampling, training and inference procedure for applying topic models to huge and imbalanced diachronic text collections; b) a discussion on the differences between two topic models for this type of data; c) quantifying topic prominence for a period and thus a generalization of document-wise topic assignment to a discourse level; and d) a discussion of the role of humanistic interpretation with regard to analysing discourse dynamics through topic models.