 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-aware topic identification in social media with pre-trained language models: A case study of electric vehicles
Oct 11, 2022
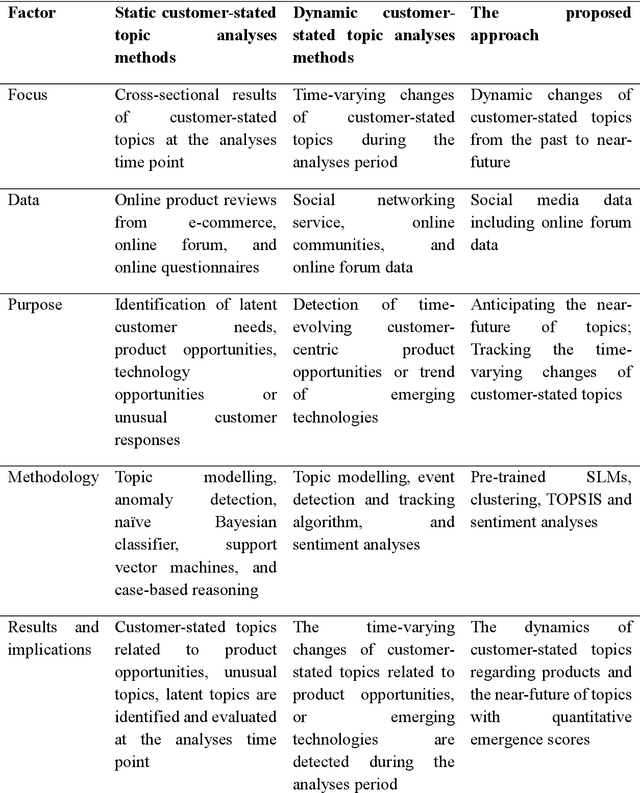
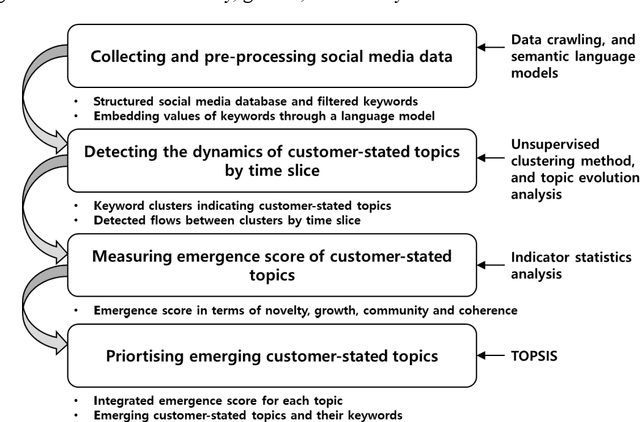
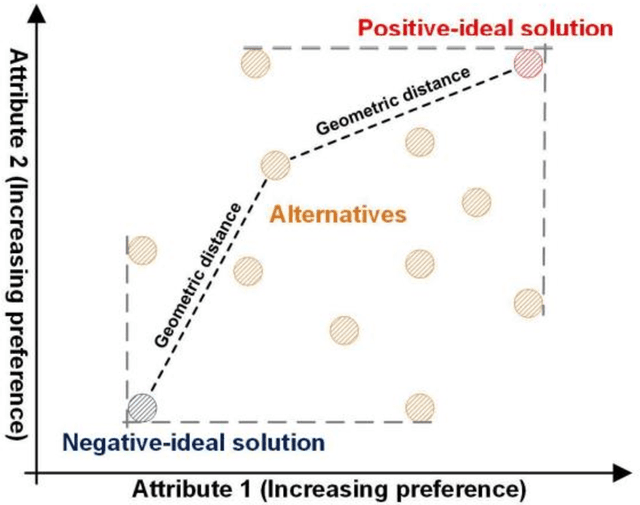
Recent extensively competitive business environment makes companies to keep their eyes on social media, as there is a growing recognition over customer languages (e.g., needs, interests, and complaints) as source of future opportunities. This research avenue analysing social media data has received much attention in academia, but their utilities are limited as most of methods provide retrospective results. Moreover, the increasing number of customer-generated contents and rapidly varying topics have made the necessity of time-aware topic evolution analyses. Recently, several researchers have showed the applicability of pre-trained semantic language models to social media as an input feature, but leaving limitations in understanding evolving topics. In this study, we propose a time-aware topic identification approach with pre-trained language models. The proposed approach consists of two stages: the dynamics-focused function for tracking time-varying topics with language models and the emergence-scoring function to examine future promising topics. Here we apply the proposed approach to reddit data on electric vehicles, and our findings highlight the feasibility of capturing emerging customer topics from voluminous social media in a time-aware manner.
How Does Data Freshness Affect Real-time Supervised Learning?
Aug 15, 2022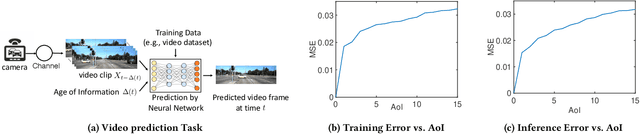
In this paper, we analyze the impact of data freshness on real-time supervised learning, where a neural network is trained to infer a time-varying target (e.g., the position of the vehicle in front) based on features (e.g., video frames) observed at a sensing node (e.g., camera or lidar). One might expect that the performance of real-time supervised learning degrades monotonically as the feature becomes stale. Using an information-theoretic analysis, we show that this is true if the feature and target data sequence can be closely approximated as a Markov chain; it is not true if the data sequence is far from Markovian. Hence, the prediction error of real-time supervised learning is a function of the Age of Information (AoI), where the function could be non-monotonic. Several experiments are conducted to illustrate the monotonic and non-monotonic behaviors of the prediction error. To minimize the inference error in real-time, we propose a new "selection-from-buffer" model for sending the features, which is more general than the "generate-at-will" model used in earlier studies. By using Gittins and Whittle indices, low-complexity scheduling strategies are developed to minimize the inference error, where a new connection between the Gittins index theory and Age of Information (AoI) minimization is discovered. These scheduling results hold (i) for minimizing general AoI functions (monotonic or non-monotonic) and (ii) for general feature transmission time distributions. Data-driven evaluations are presented to illustrate the benefits of the proposed scheduling algorithms.
Uzbek text summarization based on TF-IDF
Mar 01, 2023
The volume of information is increasing at an incredible rate with the rapid development of the Internet and electronic information services. Due to time constraints, we don't have the opportunity to read all this information. Even the task of analyzing textual data related to one field requires a lot of work. The text summarization task helps to solve these problems. This article presents an experiment on summarization task for Uzbek language, the methodology was based on text abstracting based on TF-IDF algorithm. Using this density function, semantically important parts of the text are extracted. We summarize the given text by applying the n-gram method to important parts of the whole text. The authors used a specially handcrafted corpus called "School corpus" to evaluate the performance of the proposed method. The results show that the proposed approach is effective in extracting summaries from Uzbek language text and can potentially be used in various applications such as information retrieval and natural language processing. Overall, this research contributes to the growing body of work on text summarization in under-resourced languages.
Efficient Path Planning In Manipulation Planning Problems by Actively Reusing Validation Effort
Mar 01, 2023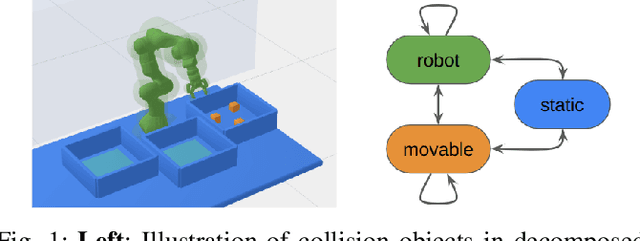
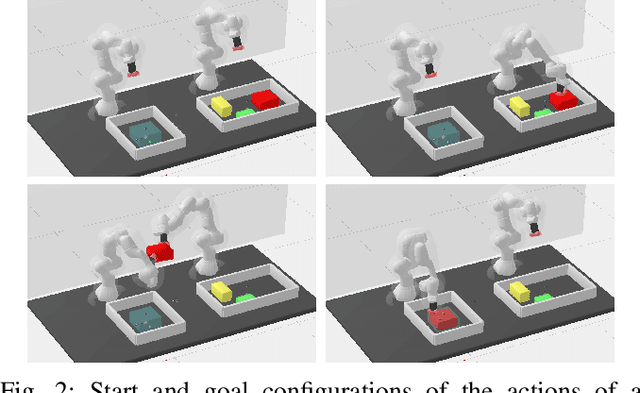

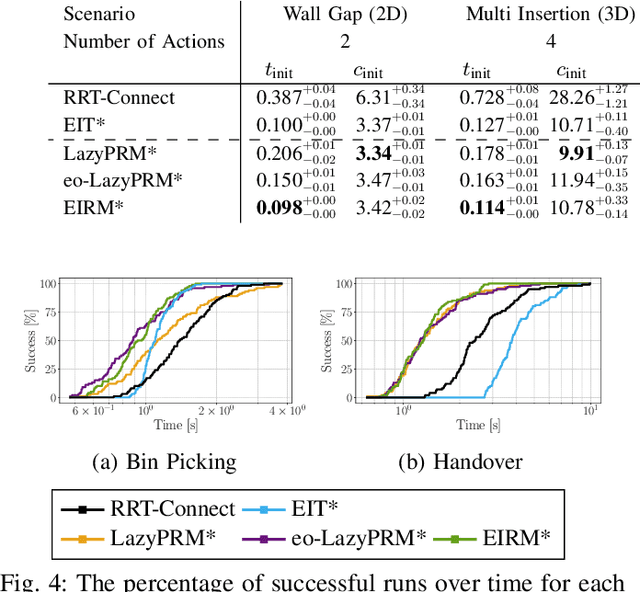
The path planning problems arising in manipulation planning and in task and motion planning settings are typically repetitive: the same manipulator moves in a space that only changes slightly. Despite this potential for reuse of information, few planners fully exploit the available information. To better enable this reuse, we decompose the collision checking into reusable, and non-reusable parts. We then treat the sequences of path planning problems in manipulation planning as a multiquery path planning problem. This allows the usage of planners that actively minimize planning effort over multiple queries, and by doing so, actively reuse previous knowledge. We implement this approach in EIRM* and effort ordered LazyPRM*, and benchmark it on multiple simulated robotic examples. Further, we show that the approach of decomposing collision checks additionally enables the reuse of the gained knowledge over multiple different instances of the same problem, i.e., in a multiquery manipulation planning scenario. The planners using the decomposed collision checking outperform the other planners in initial solution time by up to a factor of two while providing a similar solution quality.
ISBNet: a 3D Point Cloud Instance Segmentation Network with Instance-aware Sampling and Box-aware Dynamic Convolution
Mar 01, 2023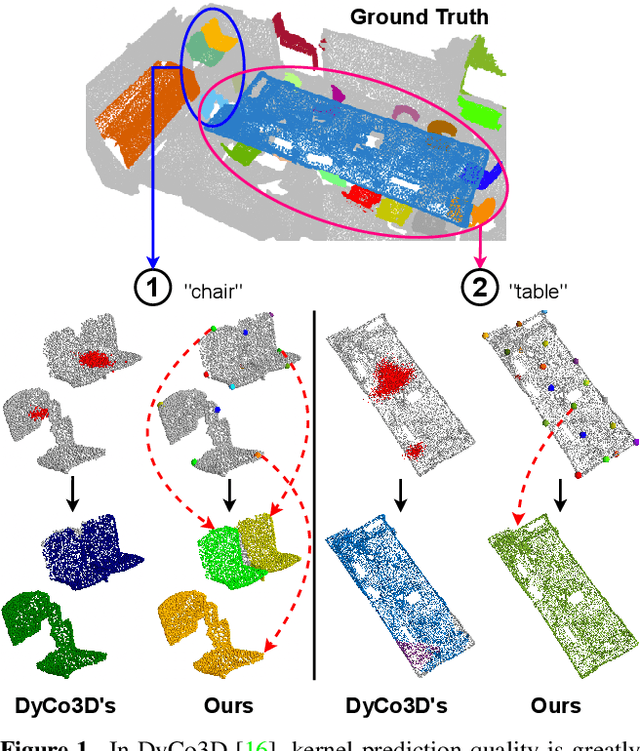
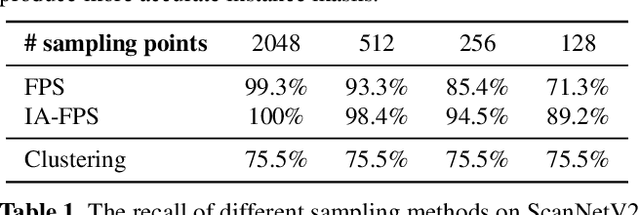
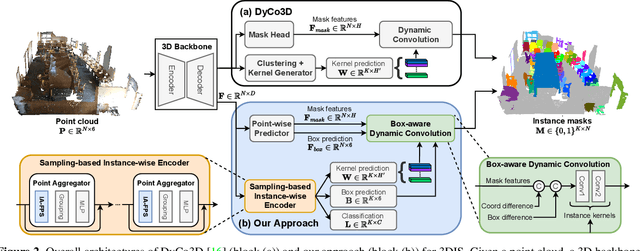
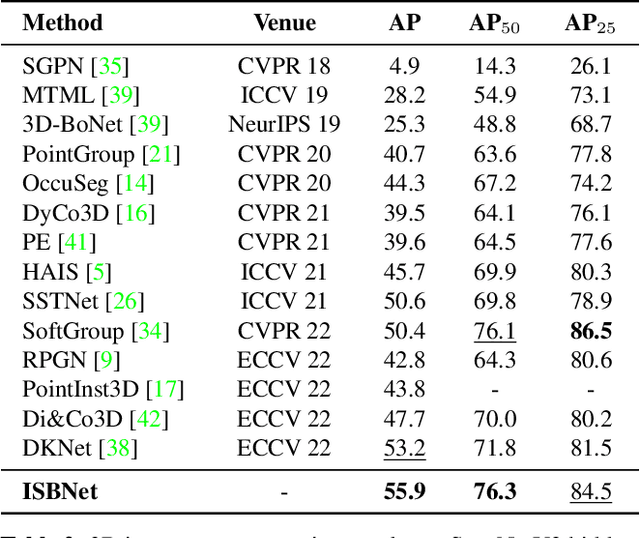
Existing 3D instance segmentation methods are predominated by the bottom-up design -- manually fine-tuned algorithm to group points into clusters followed by a refinement network. However, by relying on the quality of the clusters, these methods generate susceptible results when (1) nearby objects with the same semantic class are packed together, or (2) large objects with loosely connected regions. To address these limitations, we introduce ISBNet, a novel cluster-free method that represents instances as kernels and decodes instance masks via dynamic convolution. To efficiently generate high-recall and discriminative kernels, we propose a simple strategy named Instance-aware Farthest Point Sampling to sample candidates and leverage the local aggregation layer inspired by PointNet++ to encode candidate features. Moreover, we show that predicting and leveraging the 3D axis-aligned bounding boxes in the dynamic convolution further boosts performance. Our method set new state-of-the-art results on ScanNetV2 (55.9), S3DIS (60.8), and STPLS3D (49.2) in terms of AP and retains fast inference time (237ms per scene on ScanNetV2).
Ego-noise reduction of a mobile robot using noise spatial covariance matrix learning and minimum variance distortionless response
Mar 01, 2023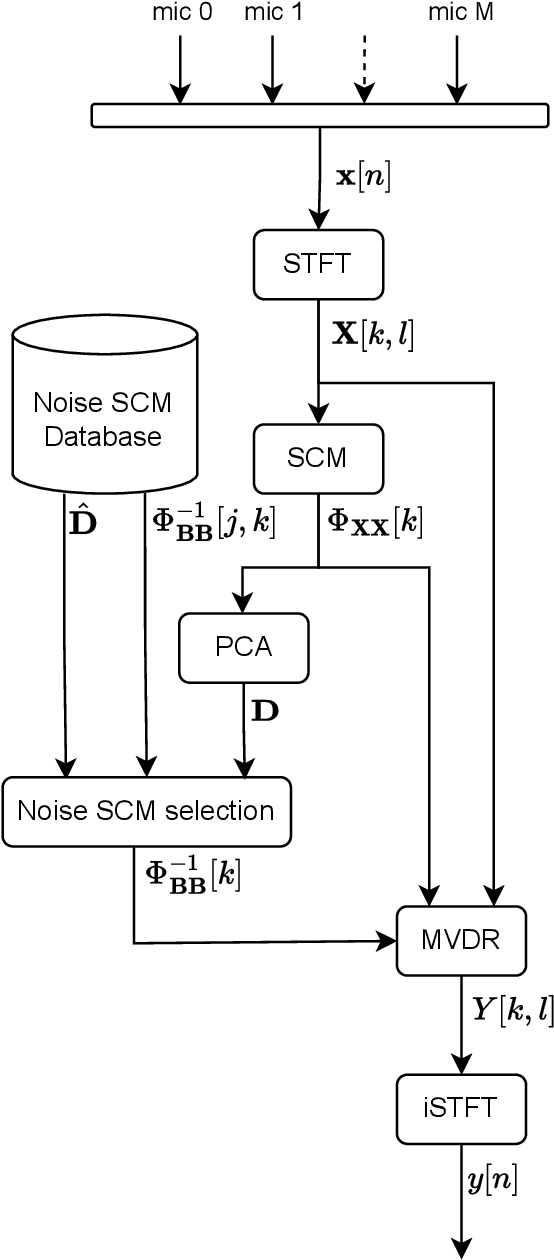


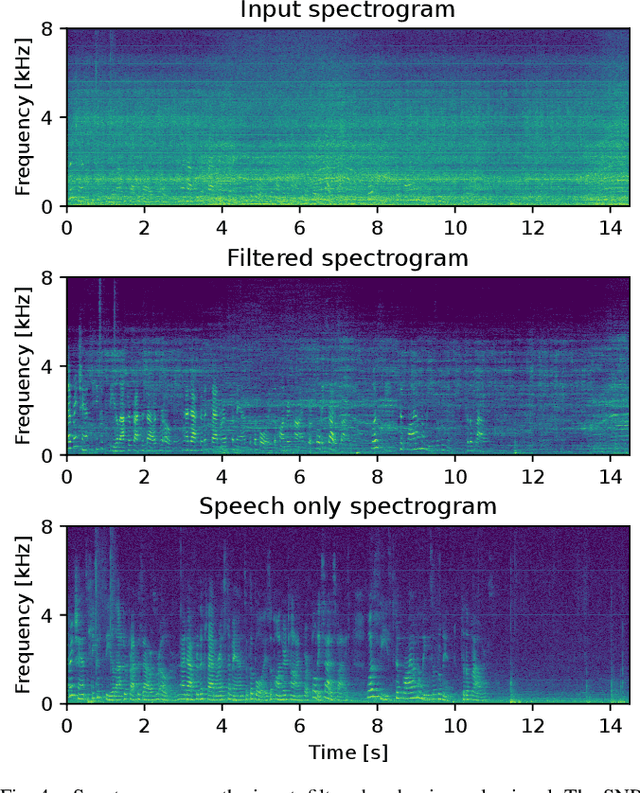
The performance of speech and events recognition systems significantly improved recently thanks to deep learning methods. However, some of these tasks remain challenging when algorithms are deployed on robots due to the unseen mechanical noise and electrical interference generated by their actuators while training the neural networks. Ego-noise reduction as a preprocessing step therefore can help solve this issue when using pre-trained speech and event recognition algorithms on robots. In this paper, we propose a new method to reduce ego-noise using only a microphone array and less than two minute of noise recordings. Using Principal Component Analysis (PCA), the best covariance matrix candidate is selected from a dictionary created online during calibration and used with the Minimum Variance Distortionless Response (MVDR) beamformer. Results show that the proposed method runs in real-time, improves the signal-to-distortion ratio (SDR) by up to 10 dB, decreases the word error rate (WER) by 55\% in some cases and increases the Average Precision (AP) of event detection by up to 0.2.
LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints
Feb 27, 2023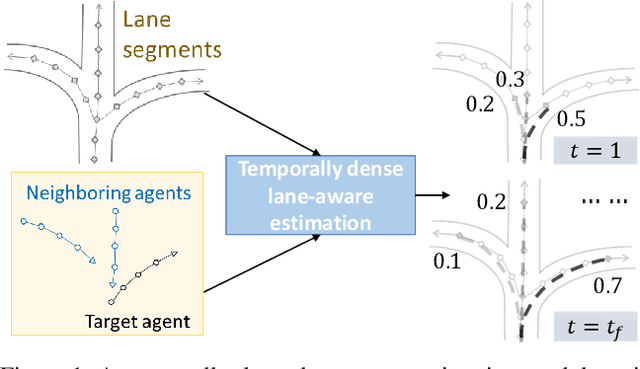
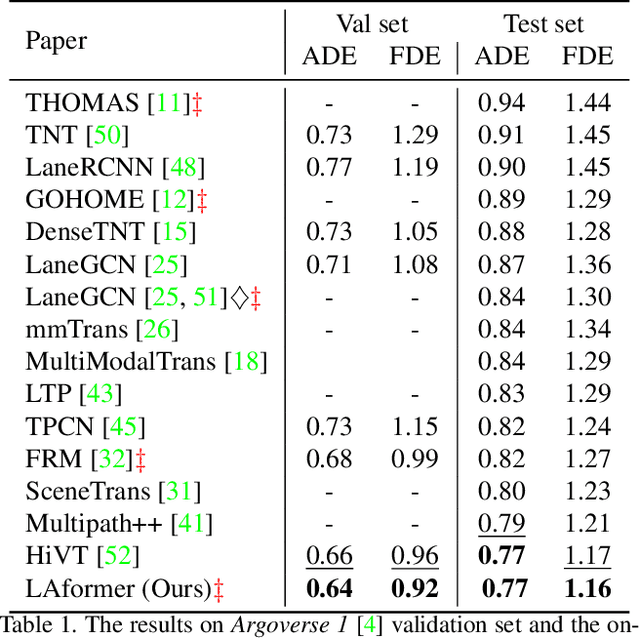
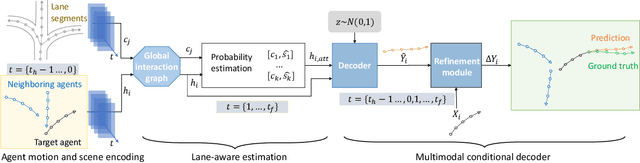
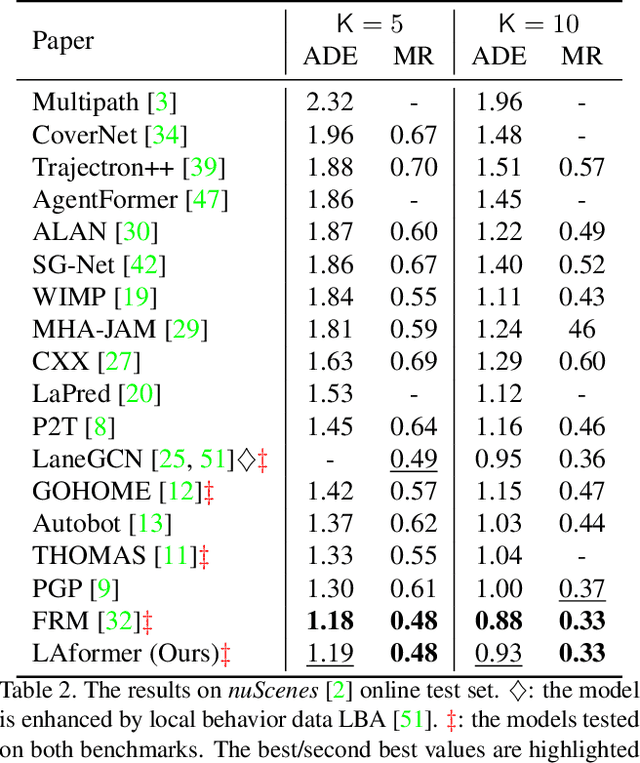
Trajectory prediction for autonomous driving must continuously reason the motion stochasticity of road agents and comply with scene constraints. Existing methods typically rely on one-stage trajectory prediction models, which condition future trajectories on observed trajectories combined with fused scene information. However, they often struggle with complex scene constraints, such as those encountered at intersections. To this end, we present a novel method, called LAformer. It uses a temporally dense lane-aware estimation module to select only the top highly potential lane segments in an HD map, which effectively and continuously aligns motion dynamics with scene information, reducing the representation requirements for the subsequent attention-based decoder by filtering out irrelevant lane segments. Additionally, unlike one-stage prediction models, LAformer utilizes predictions from the first stage as anchor trajectories and adds a second-stage motion refinement module to further explore temporal consistency across the complete time horizon. Extensive experiments on Argoverse 1 and nuScenes demonstrate that LAformer achieves excellent performance for multimodal trajectory prediction.
CP+: Camera Poses Augmentation with Large-scale LiDAR Maps
Feb 27, 2023
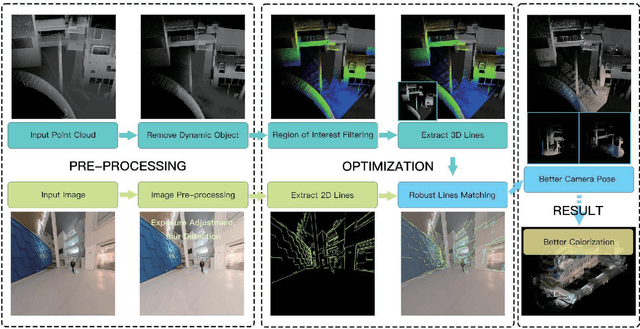
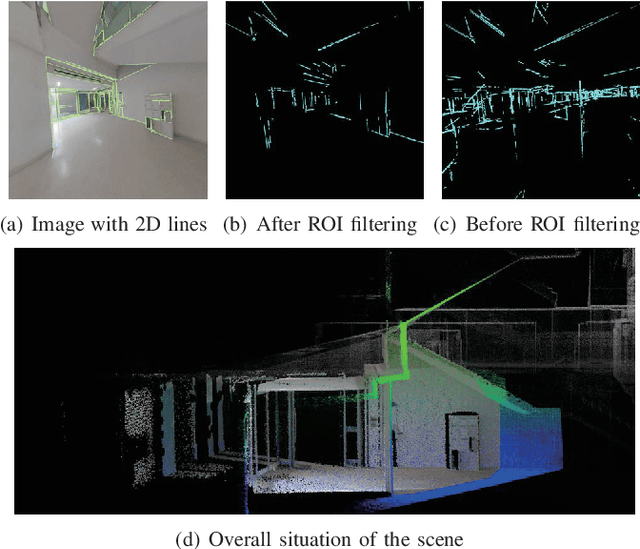

Large-scale colored point clouds have many advantages in navigation or scene display. Relying on cameras and LiDARs, which are now widely used in reconstruction tasks, it is possible to obtain such colored point clouds. However, the information from these two kinds of sensors is not well fused in many existing frameworks, resulting in poor colorization results, thus resulting in inaccurate camera poses and damaged point colorization results. We propose a novel framework called Camera Pose Augmentation (CP+) to improve the camera poses and align them directly with the LiDAR-based point cloud. Initial coarse camera poses are given by LiDAR-Inertial or LiDAR-Inertial-Visual Odometry with approximate extrinsic parameters and time synchronization. The key steps to improve the alignment of the images consist of selecting a point cloud corresponding to a region of interest in each camera view, extracting reliable edge features from this point cloud, and deriving 2D-3D line correspondences which are used towards iterative minimization of the re-projection error.
BaLi-RF: Bandlimited Radiance Fields for Dynamic Scene Modeling
Feb 27, 2023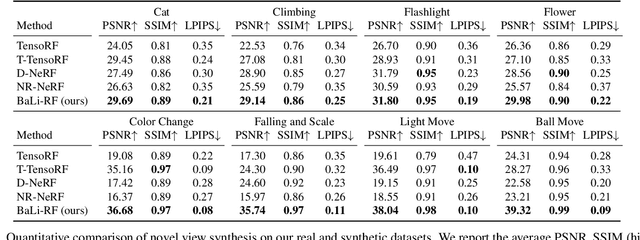
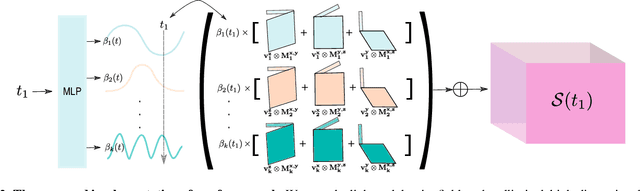

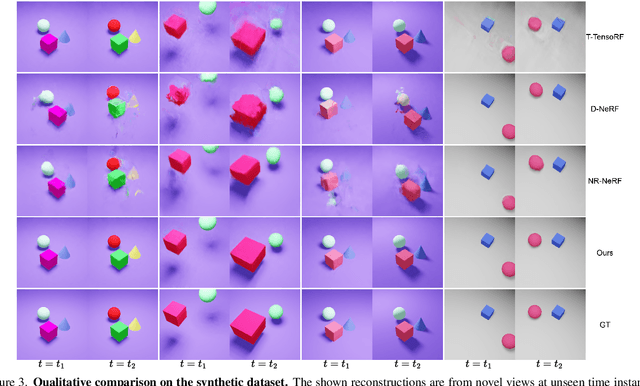
Reasoning the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, extensions have been proposed for dynamic settings. These methods heavily rely on neural priors in order to regularize the problem. In this work, we take a step back and reinvestigate how current implementations may entail deleterious effects, including limited expressiveness, entanglement of light and density fields, and sub-optimal motion localization. As a remedy, we advocate for a bridge between classic non-rigid-structure-from-motion (\nrsfm) and NeRF, enabling the well-studied priors of the former to constrain the latter. To this end, we propose a framework that factorizes time and space by formulating a scene as a composition of bandlimited, high-dimensional signals. We demonstrate compelling results across complex dynamic scenes that involve changes in lighting, texture and long-range dynamics.
Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
Feb 27, 2023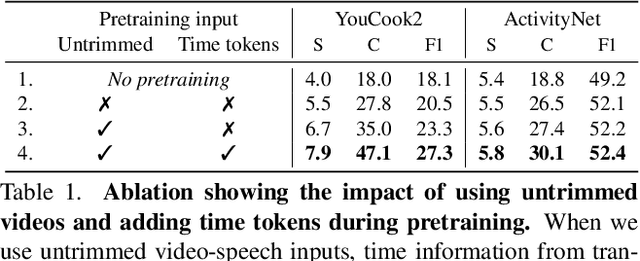
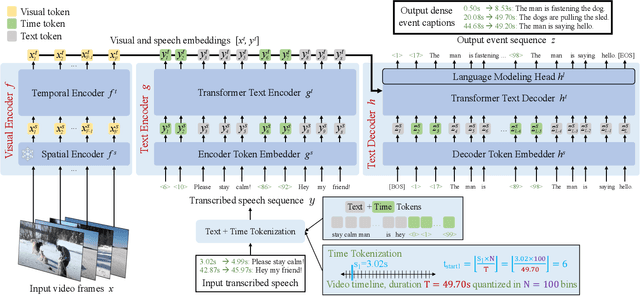
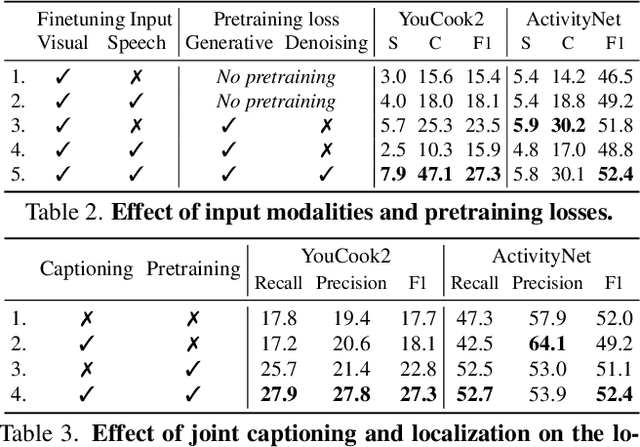
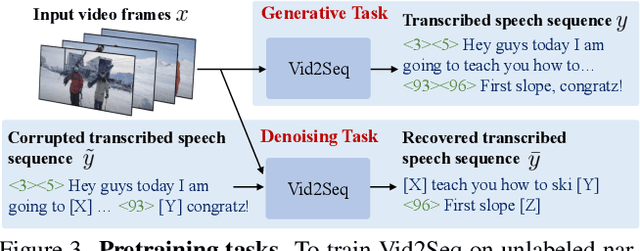
In this work, we introduce Vid2Seq, a multi-modal single-stage dense event captioning model pretrained on narrated videos which are readily-available at scale. The Vid2Seq architecture augments a language model with special time tokens, allowing it to seamlessly predict event boundaries and textual descriptions in the same output sequence. Such a unified model requires large-scale training data, which is not available in current annotated datasets. We show that it is possible to leverage unlabeled narrated videos for dense video captioning, by reformulating sentence boundaries of transcribed speech as pseudo event boundaries, and using the transcribed speech sentences as pseudo event captions. The resulting Vid2Seq model pretrained on the YT-Temporal-1B dataset improves the state of the art on a variety of dense video captioning benchmarks including YouCook2, ViTT and ActivityNet Captions. Vid2Seq also generalizes well to the video paragraph captioning task and the standard task of video clip captioning. Our code and models will be publicly released at https://antoyang.github.io/vid2seq.html.