 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Regret Bounds for Online Kernel Selection under Bandit Feedback
Mar 09, 2023

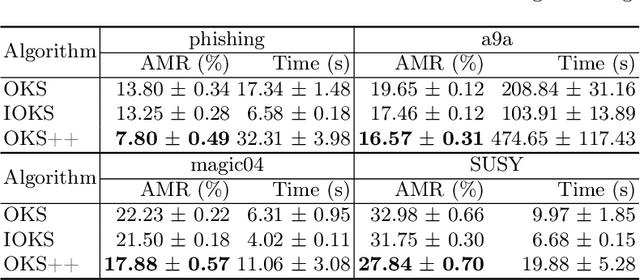
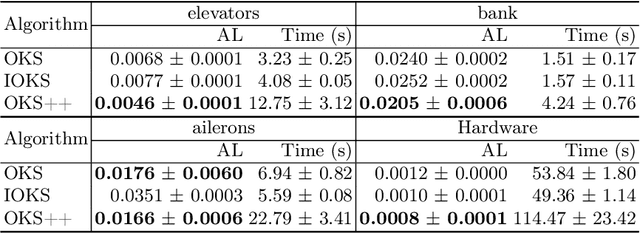
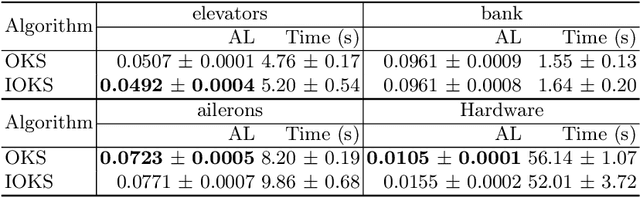
In this paper, we improve the regret bound for online kernel selection under bandit feedback. Previous algorithm enjoys a $O((\Vert f\Vert^2_{\mathcal{H}_i}+1)K^{\frac{1}{3}}T^{\frac{2}{3}})$ expected bound for Lipschitz loss functions. We prove two types of regret bounds improving the previous bound. For smooth loss functions, we propose an algorithm with a $O(U^{\frac{2}{3}}K^{-\frac{1}{3}}(\sum^K_{i=1}L_T(f^\ast_i))^{\frac{2}{3}})$ expected bound where $L_T(f^\ast_i)$ is the cumulative losses of optimal hypothesis in $\mathbb{H}_{i}=\{f\in\mathcal{H}_i:\Vert f\Vert_{\mathcal{H}_i}\leq U\}$. The data-dependent bound keeps the previous worst-case bound and is smaller if most of candidate kernels match well with the data. For Lipschitz loss functions, we propose an algorithm with a $O(U\sqrt{KT}\ln^{\frac{2}{3}}{T})$ expected bound asymptotically improving the previous bound. We apply the two algorithms to online kernel selection with time constraint and prove new regret bounds matching or improving the previous $O(\sqrt{T\ln{K}} +\Vert f\Vert^2_{\mathcal{H}_i}\max\{\sqrt{T},\frac{T}{\sqrt{\mathcal{R}}}\})$ expected bound where $\mathcal{R}$ is the time budget. Finally, we empirically verify our algorithms on online regression and classification tasks.
Application of targeted maximum likelihood estimation in public health and epidemiological studies: a systematic review
Mar 13, 2023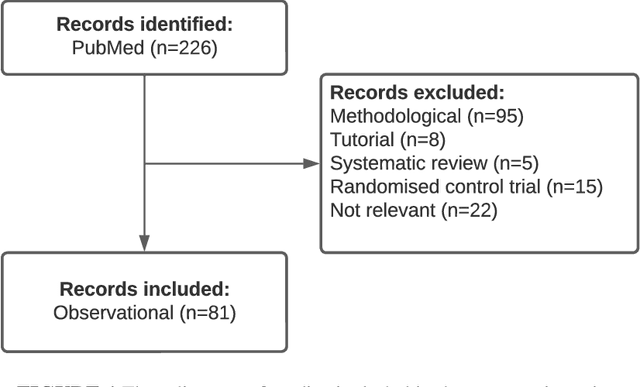
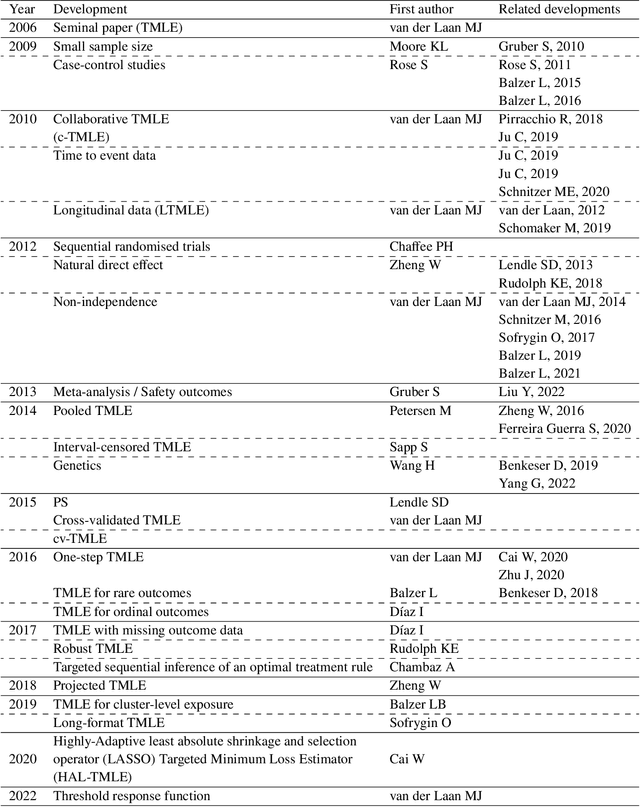
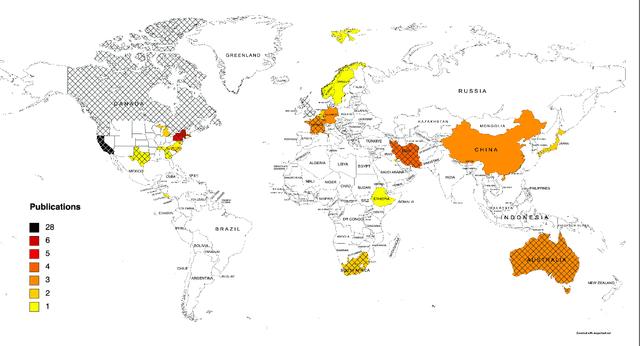

The Targeted Maximum Likelihood Estimation (TMLE) statistical data analysis framework integrates machine learning, statistical theory, and statistical inference to provide a least biased, efficient and robust strategy for estimation and inference of a variety of statistical and causal parameters. We describe and evaluate the epidemiological applications that have benefited from recent methodological developments. We conducted a systematic literature review in PubMed for articles that applied any form of TMLE in observational studies. We summarised the epidemiological discipline, geographical location, expertise of the authors, and TMLE methods over time. We used the Roadmap of Targeted Learning and Causal Inference to extract key methodological aspects of the publications. We showcase the contributions to the literature of these TMLE results. Of the 81 publications included, 25% originated from the University of California at Berkeley, where the framework was first developed by Professor Mark van der Laan. By the first half of 2022, 70% of the publications originated from outside the United States and explored up to 7 different epidemiological disciplines in 2021-22. Double-robustness, bias reduction and model misspecification were the main motivations that drew researchers towards the TMLE framework. Through time, a wide variety of methodological, tutorial and software-specific articles were cited, owing to the constant growth of methodological developments around TMLE. There is a clear dissemination trend of the TMLE framework to various epidemiological disciplines and to increasing numbers of geographical areas. The availability of R packages, publication of tutorial papers, and involvement of methodological experts in applied publications have contributed to an exponential increase in the number of studies that understood the benefits, and adoption, of TMLE.
Visual-Language Prompt Tuning with Knowledge-guided Context Optimization
Mar 23, 2023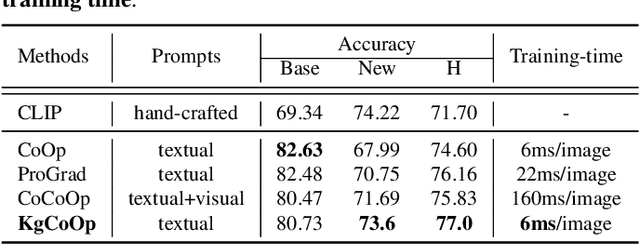
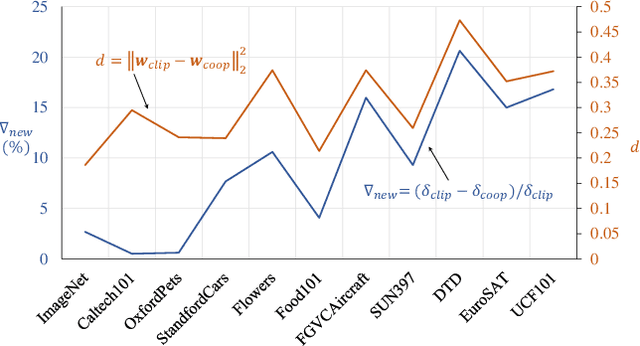
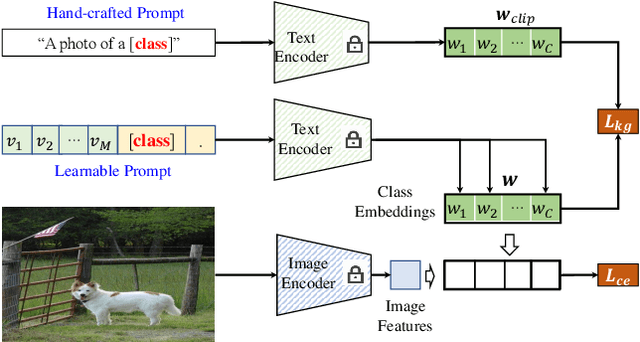
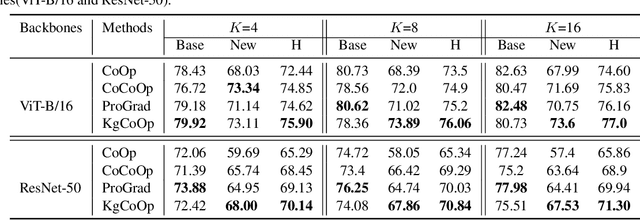
Prompt tuning is an effective way to adapt the pre-trained visual-language model (VLM) to the downstream task using task-related textual tokens. Representative CoOp-based work combines the learnable textual tokens with the class tokens to obtain specific textual knowledge. However, the specific textual knowledge is the worse generalization to the unseen classes because it forgets the essential general textual knowledge having a strong generalization ability. To tackle this issue, we introduce a novel Knowledge-guided Context Optimization (KgCoOp) to enhance the generalization ability of the learnable prompt for unseen classes. The key insight of KgCoOp is that forgetting about essential knowledge can be alleviated by reducing the discrepancy between the learnable prompt and the hand-crafted prompt. Especially, KgCoOp minimizes the discrepancy between the textual embeddings generated by learned prompts and the hand-crafted prompts. Finally, adding the KgCoOp upon the contrastive loss can make a discriminative prompt for both seen and unseen tasks. Extensive evaluation of several benchmarks demonstrates that the proposed Knowledge-guided Context Optimization is an efficient method for prompt tuning, \emph{i.e.,} achieves better performance with less training time.
Artificial-intelligence-based molecular classification of diffuse gliomas using rapid, label-free optical imaging
Mar 23, 2023Molecular classification has transformed the management of brain tumors by enabling more accurate prognostication and personalized treatment. However, timely molecular diagnostic testing for patients with brain tumors is limited, complicating surgical and adjuvant treatment and obstructing clinical trial enrollment. In this study, we developed DeepGlioma, a rapid ($< 90$ seconds), artificial-intelligence-based diagnostic screening system to streamline the molecular diagnosis of diffuse gliomas. DeepGlioma is trained using a multimodal dataset that includes stimulated Raman histology (SRH); a rapid, label-free, non-consumptive, optical imaging method; and large-scale, public genomic data. In a prospective, multicenter, international testing cohort of patients with diffuse glioma ($n=153$) who underwent real-time SRH imaging, we demonstrate that DeepGlioma can predict the molecular alterations used by the World Health Organization to define the adult-type diffuse glioma taxonomy (IDH mutation, 1p19q co-deletion and ATRX mutation), achieving a mean molecular classification accuracy of $93.3\pm 1.6\%$. Our results represent how artificial intelligence and optical histology can be used to provide a rapid and scalable adjunct to wet lab methods for the molecular screening of patients with diffuse glioma.
Attention-based Speech Enhancement Using Human Quality Perception Modelling
Mar 23, 2023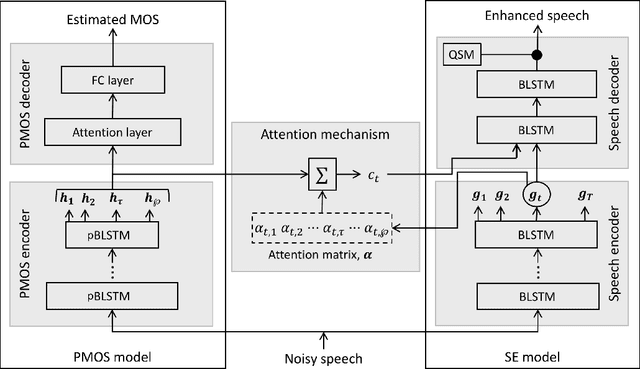
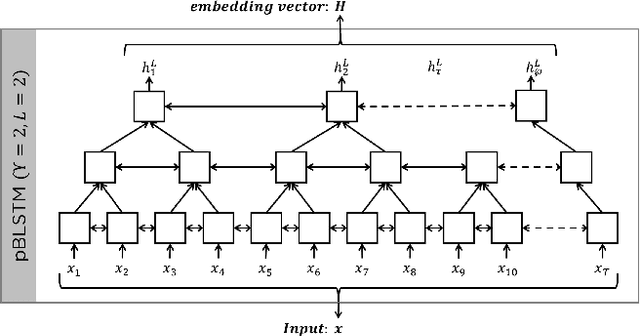
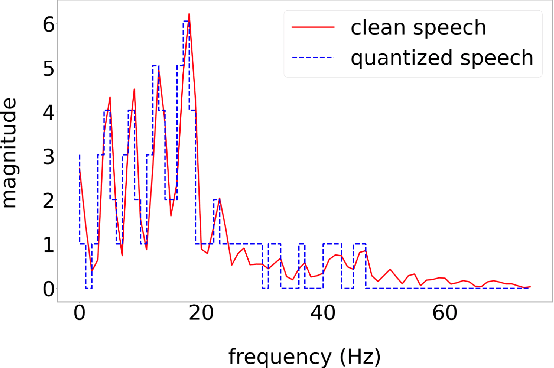
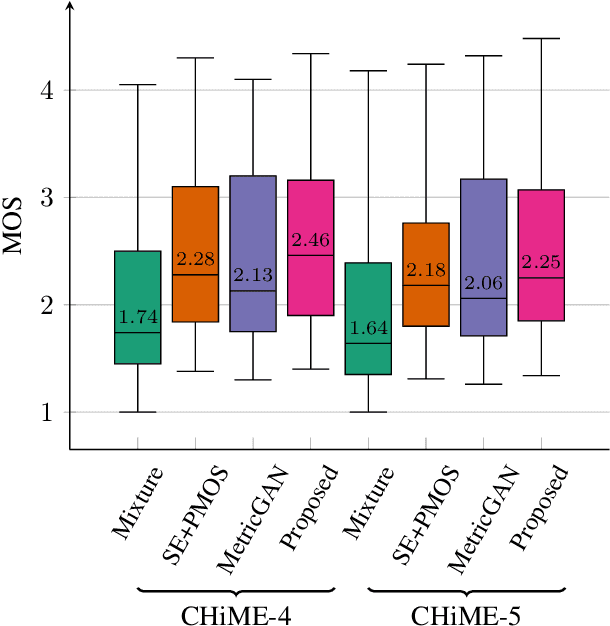
Perceptually-inspired objective functions such as the perceptual evaluation of speech quality (PESQ), signal-to-distortion ratio (SDR), and short-time objective intelligibility (STOI), have recently been used to optimize performance of deep-learning-based speech enhancement algorithms. These objective functions, however, do not always strongly correlate with a listener's assessment of perceptual quality, so optimizing with these measures often results in poorer performance in real-world scenarios. In this work, we propose an attention-based enhancement approach that uses learned speech embedding vectors from a mean-opinion score (MOS) prediction model and a speech enhancement module to jointly enhance noisy speech. The MOS prediction model estimates the perceptual MOS of speech quality, as assessed by human listeners, directly from the audio signal. The enhancement module also employs a quantized language model that enforces spectral constraints for better speech realism and performance. We train the model using real-world noisy speech data that has been captured in everyday environments and test it using unseen corpora. The results show that our proposed approach significantly outperforms other approaches that are optimized with objective measures, where the predicted quality scores strongly correlate with human judgments.
Planning Goals for Exploration
Mar 23, 2023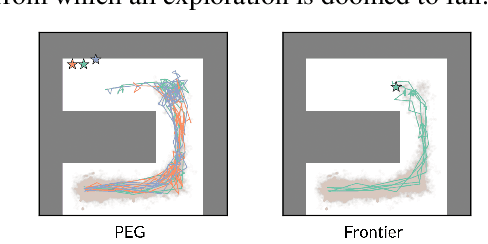
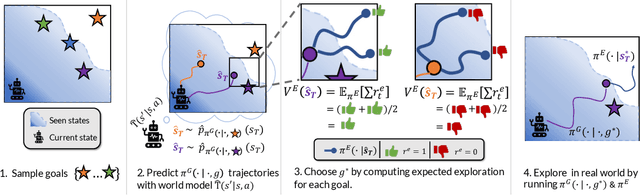


Dropped into an unknown environment, what should an agent do to quickly learn about the environment and how to accomplish diverse tasks within it? We address this question within the goal-conditioned reinforcement learning paradigm, by identifying how the agent should set its goals at training time to maximize exploration. We propose "Planning Exploratory Goals" (PEG), a method that sets goals for each training episode to directly optimize an intrinsic exploration reward. PEG first chooses goal commands such that the agent's goal-conditioned policy, at its current level of training, will end up in states with high exploration potential. It then launches an exploration policy starting at those promising states. To enable this direct optimization, PEG learns world models and adapts sampling-based planning algorithms to "plan goal commands". In challenging simulated robotics environments including a multi-legged ant robot in a maze, and a robot arm on a cluttered tabletop, PEG exploration enables more efficient and effective training of goal-conditioned policies relative to baselines and ablations. Our ant successfully navigates a long maze, and the robot arm successfully builds a stack of three blocks upon command. Website: https://penn-pal-lab.github.io/peg/
Contrastive Representation Learning for Acoustic Parameter Estimation
Mar 13, 2023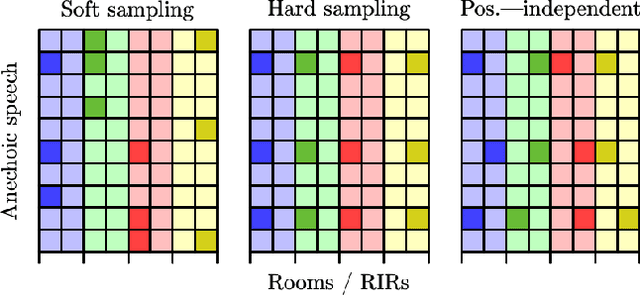


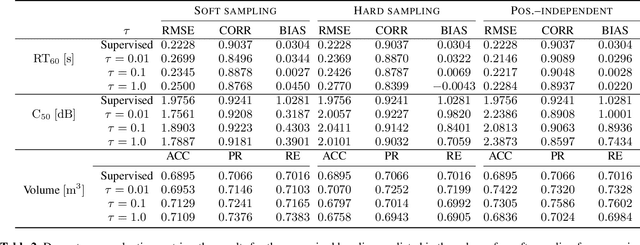
A study is presented in which a contrastive learning approach is used to extract low-dimensional representations of the acoustic environment from single-channel, reverberant speech signals. Convolution of room impulse responses (RIRs) with anechoic source signals is leveraged as a data augmentation technique that offers considerable flexibility in the design of the upstream task. We evaluate the embeddings across three different downstream tasks, which include the regression of acoustic parameters reverberation time RT60 and clarity index C50, and the classification into small and large rooms. We demonstrate that the learned representations generalize well to unseen data and perform similarly to a fully-supervised baseline.
PreMa: Predictive Maintenance of Solenoid Valve in Real-Time at Embedded Edge-Level
Nov 21, 2022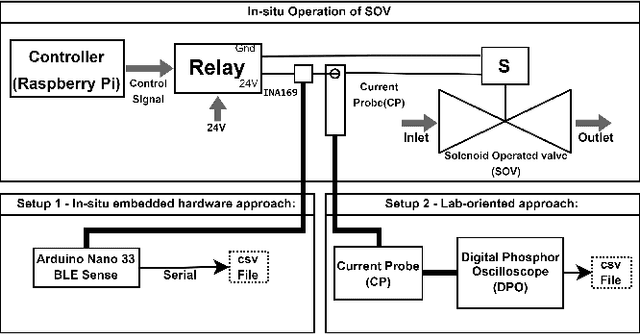
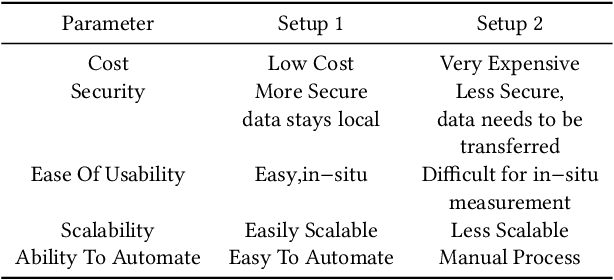
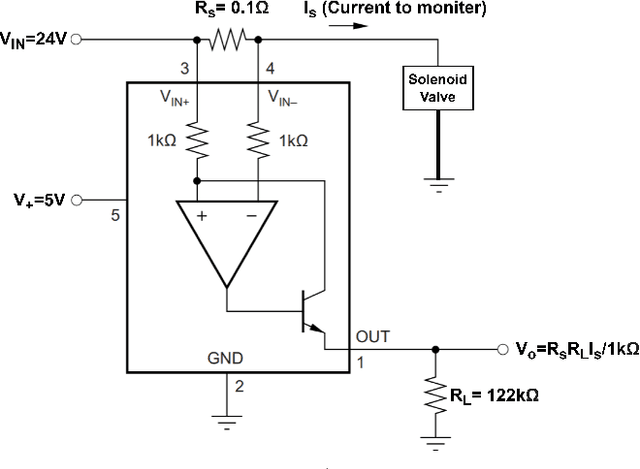

In industrial process automation, sensors (pressure, temperature, etc.), controllers, and actuators (solenoid valves, electro-mechanical relays, circuit breakers, motors, etc.) make sure that production lines are working under the pre-defined conditions. When these systems malfunction or sometimes completely fail, alerts have to be generated in real-time to make sure not only production quality is not compromised but also safety of humans and equipment is assured. In this work, we describe the construction of a smart and real-time edge-based electronic product called PreMa, which is basically a sensor for monitoring the health of a Solenoid Valve (SV). PreMa is compact, low power, easy to install, and cost effective. It has data fidelity and measurement accuracy comparable to signals captured using high end equipment. The smart solenoid sensor runs TinyML, a compact version of TensorFlow (a.k.a. TFLite) machine learning framework. While fault detection inferencing is in-situ, model training uses mobile phones to accomplish the `on-device' training. Our product evaluation shows that the sensor is able to differentiate between the distinct types of faults. These faults include: (a) Spool stuck (b) Spring failure and (c) Under voltage. Furthermore, the product provides maintenance personnel, the remaining useful life (RUL) of the SV. The RUL provides assistance to decide valve replacement or otherwise. We perform an extensive evaluation on optimizing metrics related to performance of the entire system (i.e. embedded platform and the neural network model). The proposed implementation is such that, given any electro-mechanical actuator with similar transient response to that of the SV, the system is capable of condition monitoring, hence presenting a first of its kind generic infrastructure.
Multi-Arm Bin-Picking in Real-Time: A Combined Task and Motion Planning Approach
Nov 20, 2022
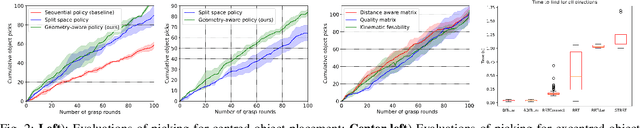

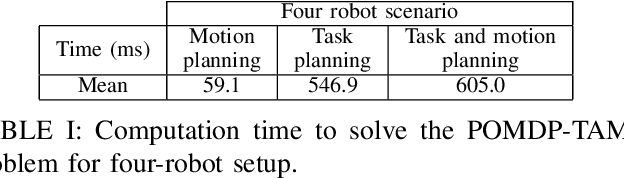
Automated bin-picking is a prerequisite for fully automated manufacturing and warehouses. To successfully pick an item from an unstructured bin the robot needs to first detect possible grasps for the objects, decide on the object to remove and consequently plan and execute a feasible trajectory to retrieve the chosen object. Over the last years significant progress has been made towards solving these problems. However, when multiple robot arms are cooperating the decision and planning problems become exponentially harder. We propose an integrated multi-arm bin-picking pipeline (IMAPIP), and demonstrate that it is able to reliably pick objects from a bin in real-time using multiple robot arms. IMAPIP solves the multi-arm bin-picking task first at high-level using a geometry-aware policy integrated in a combined task and motion planning framework. We then plan motions consistent with this policy using the BIT* algorithm on the motion planning level. We show that this integrated solution enables robot arm cooperation. In our experiments, we show the proposed geometry-aware policy outperforms a baseline by increasing bin-picking time by 28\% using two robot arms. The policy is robust to changes in the position of the bin and number of objects. We also show that IMAPIP to successfully scale up to four robot arms working in close proximity.
PRISMA: A Novel Approach for Deriving Probabilistic Surrogate Safety Measures for Risk Evaluation
Mar 14, 2023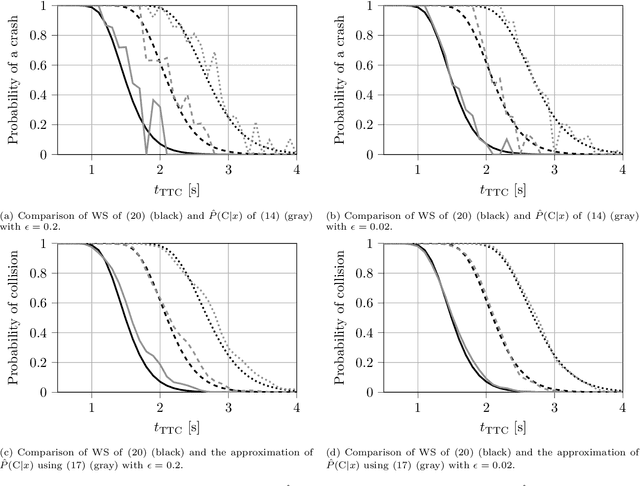
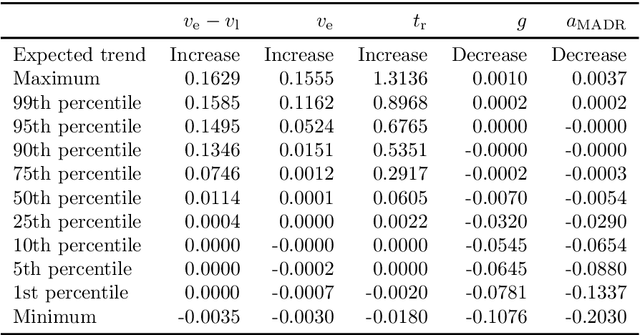
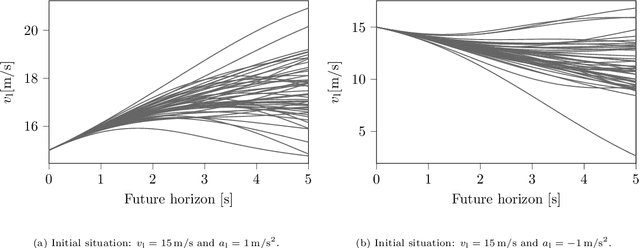
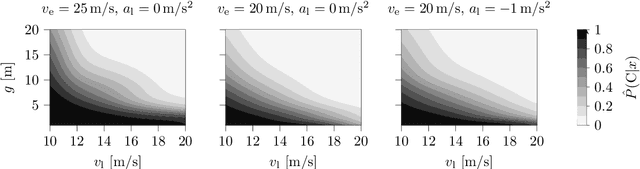
Surrogate Safety Measures (SSMs) are used to express road safety in terms of the safety risk in traffic conflicts. Typically, SSMs rely on assumptions regarding the future evolution of traffic participant trajectories to generate a measure of risk. As a result, they are only applicable in scenarios where those assumptions hold. To address this issue, we present a novel data-driven Probabilistic RISk Measure derivAtion (PRISMA) method. The PRISMA method is used to derive SSMs that can be used to calculate in real time the probability of a specific event (e.g., a crash). Because we adopt a data-driven approach to predict the possible future evolutions of traffic participant trajectories, less assumptions on these trajectories are needed. Since the PRISMA is not bound to specific assumptions, multiple SSMs for different types of scenarios can be derived. To calculate the probability of the specific event, the PRISMA method uses Monte Carlo simulations to estimate the occurrence probability of the specified event. We further introduce a statistical method that requires fewer simulations to estimate this probability. Combined with a regression model, this enables our derived SSMs to make real-time risk estimations. To illustrate the PRISMA method, an SSM is derived for risk evaluation during longitudinal traffic interactions. It is very difficult, if not impossible, to objectively compare the relative merits of two SSMs. Instead, we provide a method for benchmarking our derived SSM with respect to expected risk trends. The application of the benchmarking illustrates that the SSM matches the expected risk trends. Whereas the derived SSM shows the potential of the PRISMA method, future work involves applying the approach for other types of traffic conflicts, such as lateral traffic conflicts or interactions with vulnerable road users.