 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalization of Scenario-Based Safety Assessment of Automated Driving Systems
Jul 30, 2025Before introducing an Automated Driving System (ADS) on the road at scale, the manufacturer must conduct some sort of safety assurance. To structure and harmonize the safety assurance process, the UNECE WP.29 Working Party on Automated/Autonomous and Connected Vehicles (GRVA) is developing the New Assessment/Test Method (NATM) that indicates what steps need to be taken for safety assessment of an ADS. In this paper, we will show how to practically conduct safety assessment making use of a scenario database, and what additional steps must be taken to fully operationalize the NATM. In addition, we will elaborate on how the use of scenario databases fits with methods developed in the Horizon Europe projects that focus on safety assessment following the NATM approach.
Comparing Normalizing Flows with Kernel Density Estimation in Estimating Risk of Automated Driving Systems
Jul 30, 2025The development of safety validation methods is essential for the safe deployment and operation of Automated Driving Systems (ADSs). One of the goals of safety validation is to prospectively evaluate the risk of an ADS dealing with real-world traffic. Scenario-based assessment is a widely-used approach, where test cases are derived from real-world driving data. To allow for a quantitative analysis of the system performance, the exposure of the scenarios must be accurately estimated. The exposure of scenarios at parameter level is expressed using a Probability Density Function (PDF). However, assumptions about the PDF, such as parameter independence, can introduce errors, while avoiding assumptions often leads to oversimplified models with limited parameters to mitigate the curse of dimensionality. This paper considers the use of Normalizing Flows (NF) for estimating the PDF of the parameters. NF are a class of generative models that transform a simple base distribution into a complex one using a sequence of invertible and differentiable mappings, enabling flexible, high-dimensional density estimation without restrictive assumptions on the PDF's shape. We demonstrate the effectiveness of NF in quantifying risk and risk uncertainty of an ADS, comparing its performance with Kernel Density Estimation (KDE), a traditional method for non-parametric PDF estimation. While NF require more computational resources compared to KDE, NF is less sensitive to the curse of dimensionality. As a result, NF can improve risk uncertainty estimation, offering a more precise assessment of an ADS's safety. This work illustrates the potential of NF in scenario-based safety. Future work involves experimenting more with using NF for scenario generation and optimizing the NF architecture, transformation types, and training hyperparameters to further enhance their applicability.
A Systematic Review of Edge Case Detection in Automated Driving: Methods, Challenges and Future Directions
Oct 11, 2024



The rapid development of automated vehicles (AVs) promises to revolutionize transportation by enhancing safety and efficiency. However, ensuring their reliability in diverse real-world conditions remains a significant challenge, particularly due to rare and unexpected situations known as edge cases. Although numerous approaches exist for detecting edge cases, there is a notable lack of a comprehensive survey that systematically reviews these techniques. This paper fills this gap by presenting a practical, hierarchical review and systematic classification of edge case detection and assessment methodologies. Our classification is structured on two levels: first, categorizing detection approaches according to AV modules, including perception-related and trajectory-related edge cases; and second, based on underlying methodologies and theories guiding these techniques. We extend this taxonomy by introducing a new class called "knowledge-driven" approaches, which is largely overlooked in the literature. Additionally, we review the techniques and metrics for the evaluation of edge case detection methods and identified edge cases. To our knowledge, this is the first survey to comprehensively cover edge case detection methods across all AV subsystems, discuss knowledge-driven edge cases, and explore evaluation techniques for detection methods. This structured and multi-faceted analysis aims to facilitate targeted research and modular testing of AVs. Moreover, by identifying the strengths and weaknesses of various approaches and discussing the challenges and future directions, this survey intends to assist AV developers, researchers, and policymakers in enhancing the safety and reliability of automated driving (AD) systems through effective edge case detection.
Scenario-based assessment of automated driving systems: How (not) to parameterize scenarios?
Sep 02, 2024


The development of Automated Driving Systems (ADSs) has advanced significantly. To enable their large-scale deployment, the United Nations Regulation 157 (UN R157) concerning the approval of Automated Lane Keeping Systems (ALKSs) has been approved in 2021. UN R157 requires an activated ALKS to avoid any collisions that are reasonably preventable and proposes a method to distinguish reasonably preventable collisions from unpreventable ones using "the simulated performance of a skilled and attentive human driver". With different driver models, benchmarks are set for ALKSs in three types of scenarios. The three types of scenarios considered in the proposed method in UN R157 assume a certain parameterization without any further consideration. This work investigates the parameterization of these scenarios, showing that the choice of parameterization significantly affects the simulation outcomes. By comparing real-world and parameterized scenarios, we show that the influence of parameterization depends on the scenario type, driver model, and evaluation criterion. Alternative parameterizations are proposed, leading to results that are closer to the non-parameterized scenarios in terms of recall, precision, and F1 score. The study highlights the importance of careful scenario parameterization and suggests improvements to the current UN R157 approach.
Coverage Metrics for a Scenario Database for the Scenario-Based Assessment of Automated Driving Systems
Sep 02, 2024



Automated Driving Systems (ADSs) have the potential to make mobility services available and safe for all. A multi-pillar Safety Assessment Framework (SAF) has been proposed for the type-approval process of ADSs. The SAF requires that the test scenarios for the ADS adequately covers the Operational Design Domain (ODD) of the ADS. A common method for generating test scenarios involves basing them on scenarios identified and characterized from driving data. This work addresses two questions when collecting scenarios from driving data. First, do the collected scenarios cover all relevant aspects of the ADS' ODD? Second, do the collected scenarios cover all relevant aspects that are in the driving data, such that no potentially important situations are missed? This work proposes coverage metrics that provide a quantitative answer to these questions. The proposed coverage metrics are illustrated by means of an experiment in which over 200000 scenarios from 10 different scenario categories are collected from the HighD data set. The experiment demonstrates that a coverage of 100 % can be achieved under certain conditions, and it also identifies which data and scenarios could be added to enhance the coverage outcomes in case a 100 % coverage has not been achieved. Whereas this work presents metrics for the quantification of the coverage of driving data and the identified scenarios, this paper concludes with future research directions, including the quantification of the completeness of driving data and the identified scenarios.
A Quantitative Method to Determine What Collisions Are Reasonably Foreseeable and Preventable
Sep 05, 2023



The development of Automated Driving Systems (ADSs) has made significant progress in the last years. To enable the deployment of Automated Vehicles (AVs) equipped with such ADSs, regulations concerning the approval of these systems need to be established. In 2021, the World Forum for Harmonization of Vehicle Regulations has approved a new United Nations regulation concerning the approval of Automated Lane Keeping Systems (ALKSs). An important aspect of this regulation is that "the activated system shall not cause any collisions that are reasonably foreseeable and preventable." The phrasing of "reasonably foreseeable and preventable" might be subjected to different interpretations and, therefore, this might result in disagreements among AV developers and the authorities that are requested to approve AVs. The objective of this work is to propose a method for quantifying what is "reasonably foreseeable and preventable". The proposed method considers the Operational Design Domain (ODD) of the system and can be applied to any ODD. Having a quantitative method for determining what is reasonably foreseeable and preventable provides developers, authorities, and the users of ADSs a better understanding of the residual risks to be expected when deploying these systems in real traffic. Using our proposed method, we can estimate what collisions are reasonably foreseeable and preventable. This will help in setting requirements regarding the safety of ADSs and can lead to stronger justification for design decisions and test coverage for developing ADSs.
* 25 pages, 9 figures, 2 tables
Scenario Extraction from a Large Real-World Dataset for the Assessment of Automated Vehicles
Jun 13, 2023Many players in the automotive field support scenario-based assessment of automated vehicles (AVs), where individual traffic situations can be tested and, thus, facilitate concluding on the performance of AVs in different situations. Since an extremely large number of different scenarios can occur in real-world traffic, the question is how to find a finite set of relevant scenarios. Scenarios extracted from large real-world datasets represent real-world traffic since real driving data is used. Extracting scenarios, however, is challenging because (1) the scenarios to be tested should ensure the AVs behave safely, which conflicts with the fact that the majority of the data contains scenarios that are not interesting from a safety perspective, and (2) extensive data processing is required, which hinders the utilization of large real-world datasets. In this work, we propose a three-step approach for extracting scenarios from real-world driving data. The first step is data preprocessing to tackle the errors and noise in real-world data. The second step performs data tagging to label actors' activities, their interactions with each other, and their interactions with the environment. Finally, the scenarios are extracted by searching for combinations of tags. The proposed approach is evaluated using data simulated with CARLA and applied to a part of a large real-world driving dataset, i.e., the Waymo Open Motion Dataset.
PRISMA: A Novel Approach for Deriving Probabilistic Surrogate Safety Measures for Risk Evaluation
Mar 14, 2023



Surrogate Safety Measures (SSMs) are used to express road safety in terms of the safety risk in traffic conflicts. Typically, SSMs rely on assumptions regarding the future evolution of traffic participant trajectories to generate a measure of risk. As a result, they are only applicable in scenarios where those assumptions hold. To address this issue, we present a novel data-driven Probabilistic RISk Measure derivAtion (PRISMA) method. The PRISMA method is used to derive SSMs that can be used to calculate in real time the probability of a specific event (e.g., a crash). Because we adopt a data-driven approach to predict the possible future evolutions of traffic participant trajectories, less assumptions on these trajectories are needed. Since the PRISMA is not bound to specific assumptions, multiple SSMs for different types of scenarios can be derived. To calculate the probability of the specific event, the PRISMA method uses Monte Carlo simulations to estimate the occurrence probability of the specified event. We further introduce a statistical method that requires fewer simulations to estimate this probability. Combined with a regression model, this enables our derived SSMs to make real-time risk estimations. To illustrate the PRISMA method, an SSM is derived for risk evaluation during longitudinal traffic interactions. It is very difficult, if not impossible, to objectively compare the relative merits of two SSMs. Instead, we provide a method for benchmarking our derived SSM with respect to expected risk trends. The application of the benchmarking illustrates that the SSM matches the expected risk trends. Whereas the derived SSM shows the potential of the PRISMA method, future work involves applying the approach for other types of traffic conflicts, such as lateral traffic conflicts or interactions with vulnerable road users.
Scenario Parameter Generation Method and Scenario Representativeness Metric for Scenario-Based Assessment of Automated Vehicles
Feb 24, 2022

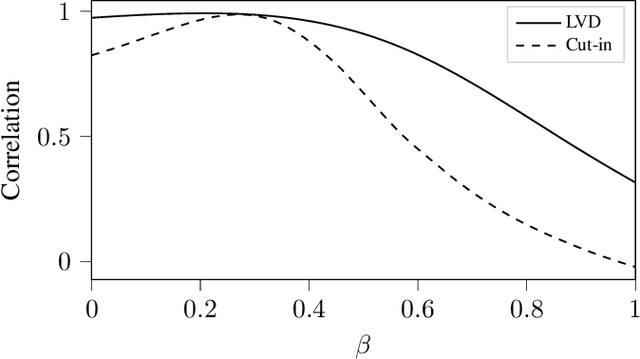
The development of assessment methods for the performance of Automated Vehicles (AVs) is essential to enable the deployment of automated driving technologies, due to the complex operational domain of AVs. One candidate is scenario-based assessment, in which test cases are derived from real-world road traffic scenarios obtained from driving data. Because of the high variety of the possible scenarios, using only observed scenarios for the assessment is not sufficient. Therefore, methods for generating additional scenarios are necessary. Our contribution is twofold. First, we propose a method to determine the parameters that describe the scenarios to a sufficient degree without relying on strong assumptions on the parameters that characterize the scenarios. By estimating the probability density function (pdf) of these parameters, realistic parameter values can be generated. Second, we present the Scenario Representativeness (SR) metric based on the Wasserstein distance, which quantifies to what extent the scenarios with the generated parameter values are representative of real-world scenarios while covering the actual variety found in the real-world scenarios. A comparison of our proposed method with methods relying on assumptions of the scenario parametrization and pdf estimation shows that the proposed method can automatically determine the optimal scenario parametrization and pdf estimation. Furthermore, we demonstrate that our SR metric can be used to choose the (number of) parameters that best describe a scenario. The presented method is promising, because the parameterization and pdf estimation can directly be applied to already available importance sampling strategies for accelerating the evaluation of AVs.
Constrained Sampling from a Kernel Density Estimator to Generate Scenarios for the Assessment of Automated Vehicles
Jul 12, 2021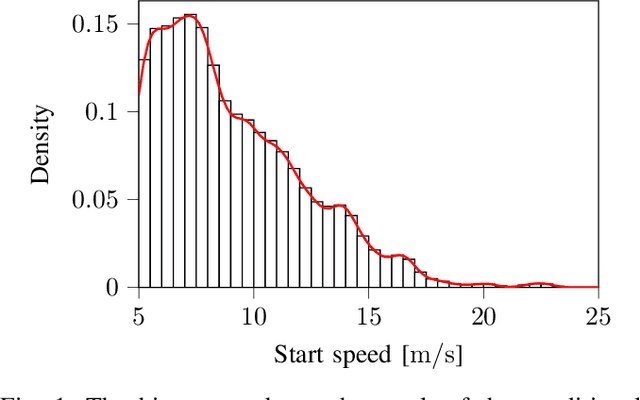
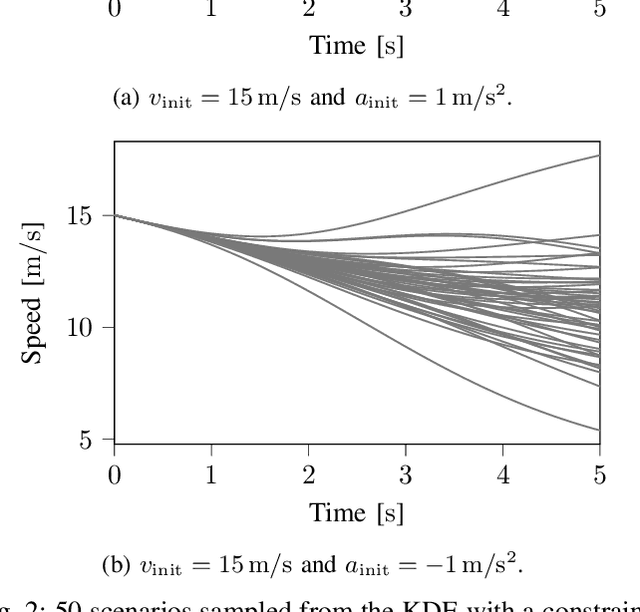
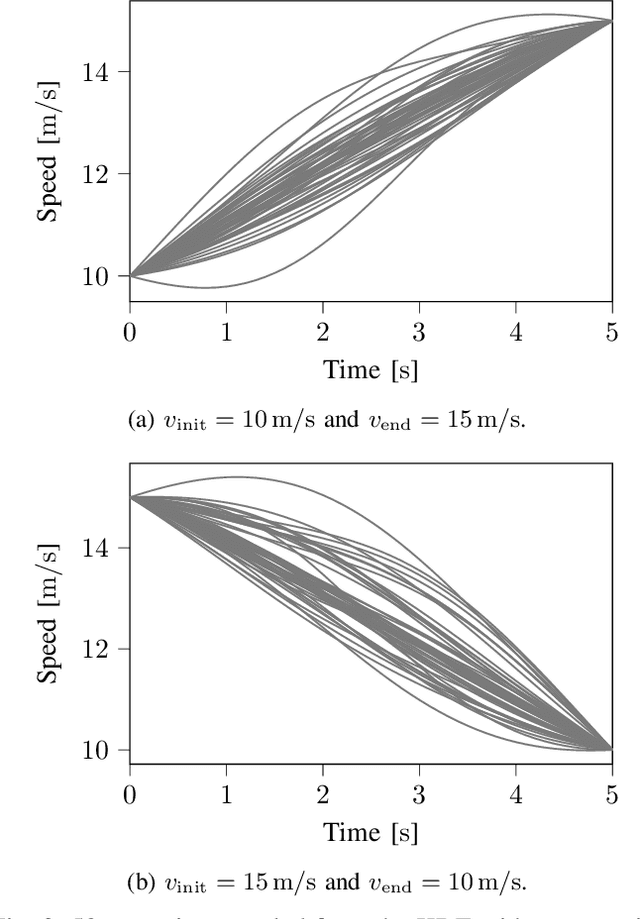
The safety assessment of automated vehicles (AVs) is an important aspect of the development cycle of AVs. A scenario-based assessment approach is accepted by many players in the field as part of the complete safety assessment. A scenario is a representation of a situation on the road to which the AV needs to respond appropriately. One way to generate the required scenario-based test descriptions is to parameterize the scenarios and to draw these parameters from a probability density function (pdf). Because the shape of the pdf is unknown beforehand, assuming a functional form of the pdf and fitting the parameters to the data may lead to inaccurate fits. As an alternative, Kernel Density Estimation (KDE) is a promising candidate for estimating the underlying pdf, because it is flexible with the underlying distribution of the parameters. Drawing random samples from a pdf estimated with KDE is possible without the need of evaluating the actual pdf, which makes it suitable for drawing random samples for, e.g., Monte Carlo methods. Sampling from a KDE while the samples satisfy a linear equality constraint, however, has not been described in the literature, as far as the authors know. In this paper, we propose a method to sample from a pdf estimated using KDE, such that the samples satisfy a linear equality constraint. We also present an algorithm of our method in pseudo-code. The method can be used to generating scenarios that have, e.g., a predetermined starting speed or to generate different types of scenarios. This paper also shows that the method for sampling scenarios can be used in case a Singular Value Decomposition (SVD) is used to reduce the dimension of the parameter vectors.