 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multiple Instance Ensembling For Paranasal Anomaly Classification In The Maxillary Sinus
Mar 31, 2023
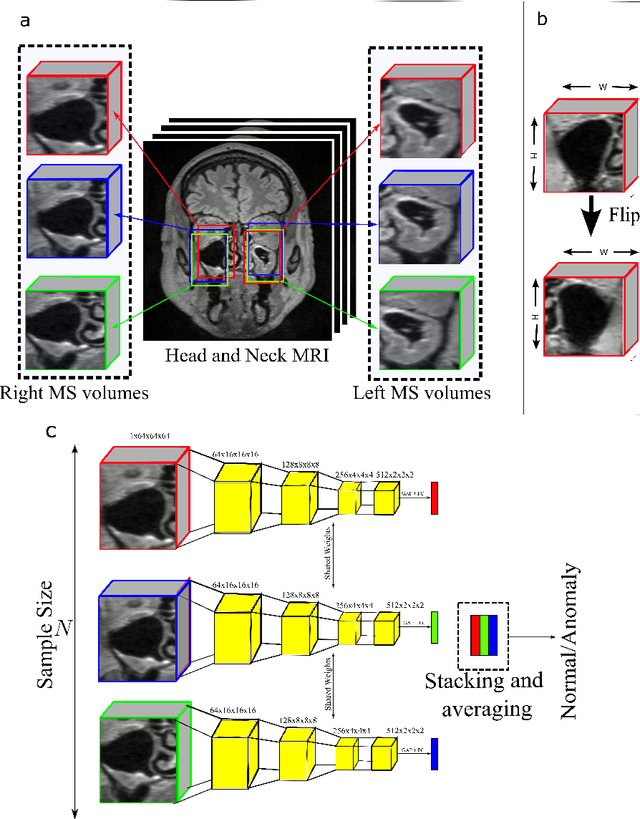
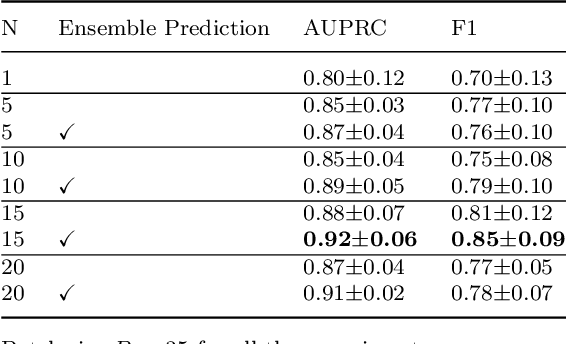
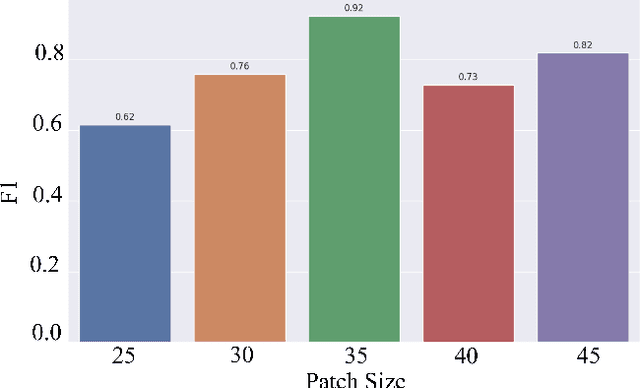
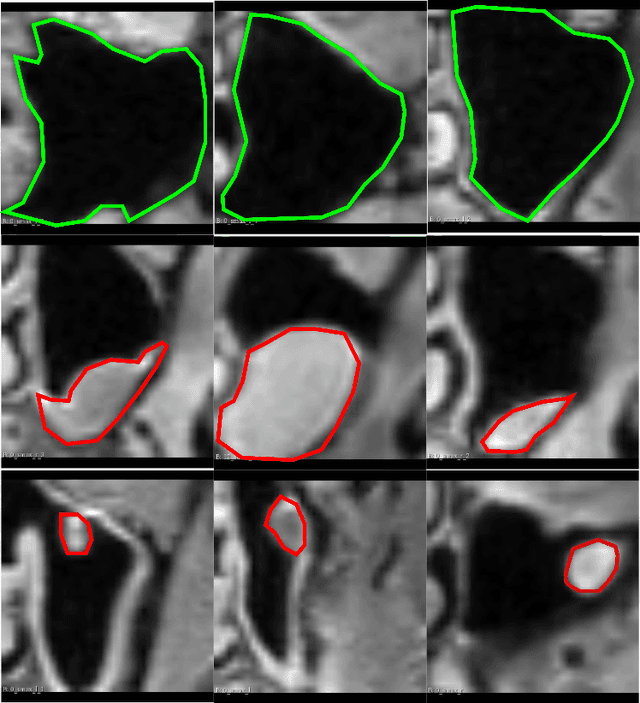
Paranasal anomalies are commonly discovered during routine radiological screenings and can present with a wide range of morphological features. This diversity can make it difficult for convolutional neural networks (CNNs) to accurately classify these anomalies, especially when working with limited datasets. Additionally, current approaches to paranasal anomaly classification are constrained to identifying a single anomaly at a time. These challenges necessitate the need for further research and development in this area. In this study, we investigate the feasibility of using a 3D convolutional neural network (CNN) to classify healthy maxillary sinuses (MS) and MS with polyps or cysts. The task of accurately identifying the relevant MS volume within larger head and neck Magnetic Resonance Imaging (MRI) scans can be difficult, but we develop a straightforward strategy to tackle this challenge. Our end-to-end solution includes the use of a novel sampling technique that not only effectively localizes the relevant MS volume, but also increases the size of the training dataset and improves classification results. Additionally, we employ a multiple instance ensemble prediction method to further boost classification performance. Finally, we identify the optimal size of MS volumes to achieve the highest possible classification performance on our dataset. With our multiple instance ensemble prediction strategy and sampling strategy, our 3D CNNs achieve an F1 of 0.85 whereas without it, they achieve an F1 of 0.70. We demonstrate the feasibility of classifying anomalies in the MS. We propose a data enlarging strategy alongside a novel ensembling strategy that proves to be beneficial for paranasal anomaly classification in the MS.
What Makes for Effective Few-shot Point Cloud Classification?
Mar 31, 2023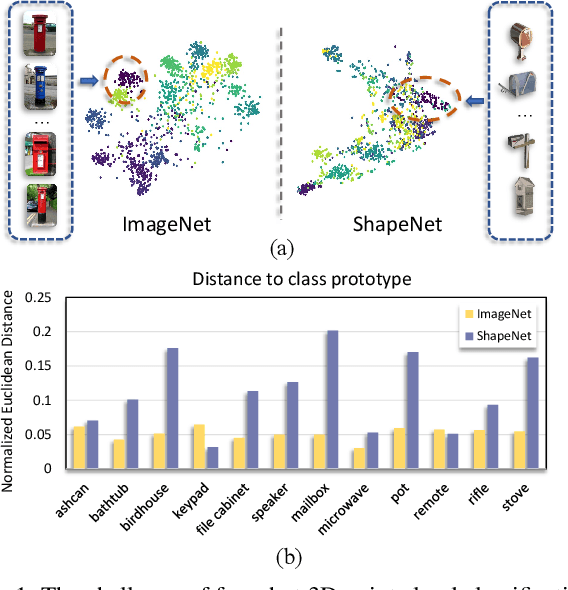

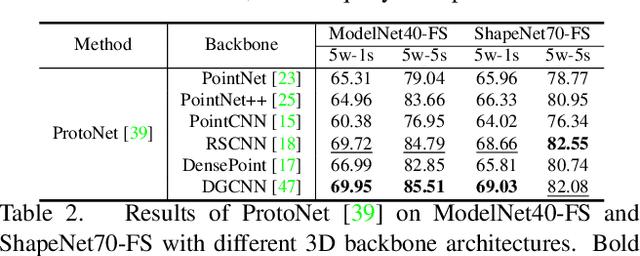
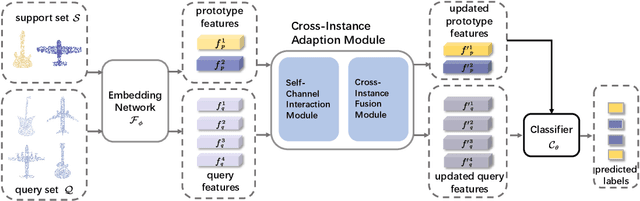
Due to the emergence of powerful computing resources and large-scale annotated datasets, deep learning has seen wide applications in our daily life. However, most current methods require extensive data collection and retraining when dealing with novel classes never seen before. On the other hand, we humans can quickly recognize new classes by looking at a few samples, which motivates the recent popularity of few-shot learning (FSL) in machine learning communities. Most current FSL approaches work on 2D image domain, however, its implication in 3D perception is relatively under-explored. Not only needs to recognize the unseen examples as in 2D domain, 3D few-shot learning is more challenging with unordered structures, high intra-class variances, and subtle inter-class differences. Moreover, different architectures and learning algorithms make it difficult to study the effectiveness of existing 2D methods when migrating to the 3D domain. In this work, for the first time, we perform systematic and extensive studies of recent 2D FSL and 3D backbone networks for benchmarking few-shot point cloud classification, and we suggest a strong baseline and learning architectures for 3D FSL. Then, we propose a novel plug-and-play component called Cross-Instance Adaptation (CIA) module, to address the high intra-class variances and subtle inter-class differences issues, which can be easily inserted into current baselines with significant performance improvement. Extensive experiments on two newly introduced benchmark datasets, ModelNet40-FS and ShapeNet70-FS, demonstrate the superiority of our proposed network for 3D FSL.
Predictive Context-Awareness for Full-Immersive Multiuser Virtual Reality with Redirected Walking
Mar 31, 2023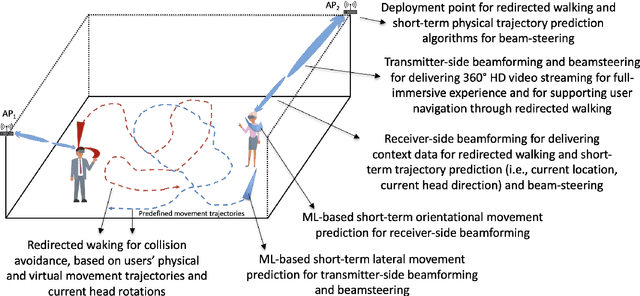
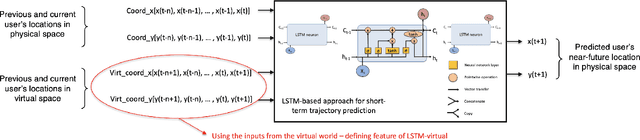
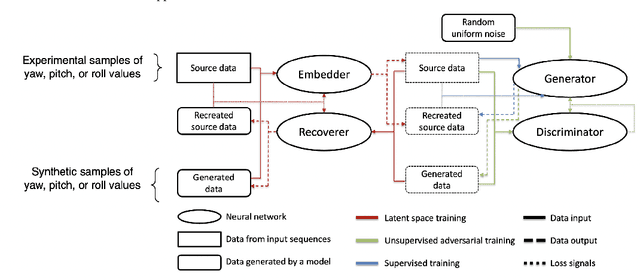
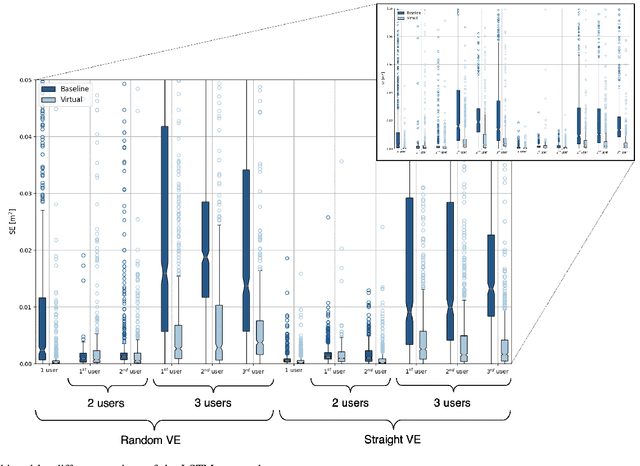
Virtual Reality (VR) technology is being advanced along the lines of enhancing its immersiveness, enabling multiuser Virtual Experiences (VEs), and supporting unconstrained mobility of the users in their VEs, while constraining them within specialized VR setups through Redirected Walking (RDW). For meeting the extreme data-rate and latency requirements of future VR systems, supporting wireless networking infrastructures will operate in millimeter Wave (mmWave) frequencies and leverage highly directional communication in both transmission and reception through beamforming and beamsteering. We propose to leverage predictive context-awareness for optimizing transmitter and receiver-side beamforming and beamsteering. In particular, we argue that short-term prediction of users' lateral movements in multiuser VR setups with RDW can be utilized for optimizing transmitter-side beamforming and beamsteering through Line-of-Sight (LoS) "tracking" in the users' directions. At the same time, short-term prediction of orientational movements can be used for receiver-side beamforming for coverage flexibility enhancements. We target two open problems in predicting these two context information instances: i) lateral movement prediction in multiuser VR settings with RDW and ii) generation of synthetic head rotation datasets to be utilized in the training of existing orientational movements predictors. We follow by experimentally showing that Long Short-Term Memory (LSTM) networks feature promising accuracy in predicting lateral movements, as well as that context-awareness stemming from VEs further benefits this accuracy. Second, we show that a TimeGAN-based approach for orientational data generation can generate synthetic samples closely matching the experimentally obtained ones.
Privacy against Real-Time Speech Emotion Detection via Acoustic Adversarial Evasion of Machine Learning
Nov 17, 2022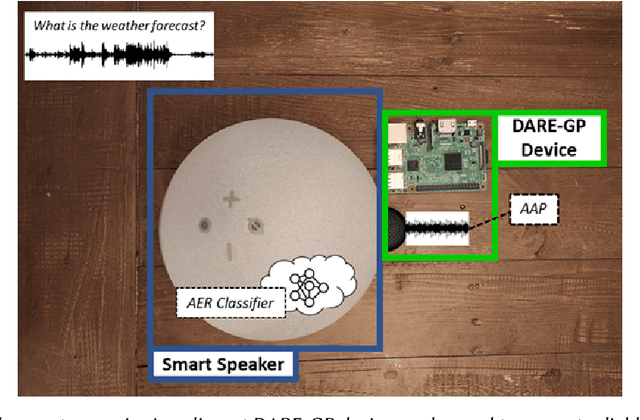
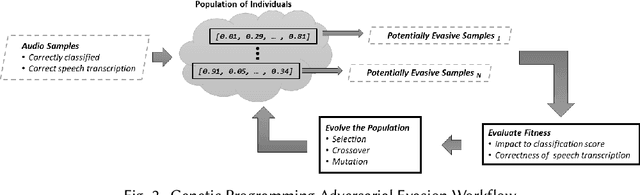

Emotional Surveillance is an emerging area with wide-reaching privacy concerns. These concerns are exacerbated by ubiquitous IoT devices with multiple sensors that can support these surveillance use cases. The work presented here considers one such use case: the use of a speech emotion recognition (SER) classifier tied to a smart speaker. This work demonstrates the ability to evade black-box SER classifiers tied to a smart speaker without compromising the utility of the smart speaker. This privacy concern is considered through the lens of adversarial evasion of machine learning. Our solution, Defeating Acoustic Recognition of Emotion via Genetic Programming (DARE-GP), uses genetic programming to generate non-invasive additive audio perturbations (AAPs). By constraining the evolution of these AAPs, transcription accuracy can be protected while simultaneously degrading SER classifier performance. The additive nature of these AAPs, along with an approach that generates these AAPs for a fixed set of users in an utterance and user location-independent manner, supports real-time, real-world evasion of SER classifiers. DARE-GP's use of spectral features, which underlay the emotional content of speech, allows the transferability of AAPs to previously unseen black-box SER classifiers. Further, DARE-GP outperforms state-of-the-art SER evasion techniques and is robust against defenses employed by a knowledgeable adversary. The evaluations in this work culminate with acoustic evaluations against two off-the-shelf commercial smart speakers, where a single AAP could evade a black box classifier over 70% of the time. The final evaluation deployed AAP playback on a small-form-factor system (raspberry pi) integrated with a wake-word system to evaluate the efficacy of a real-world, real-time deployment where DARE-GP is automatically invoked with the smart speaker's wake word.
Implicit Temporal Reasoning for Evidence-Based Fact-Checking
Feb 24, 2023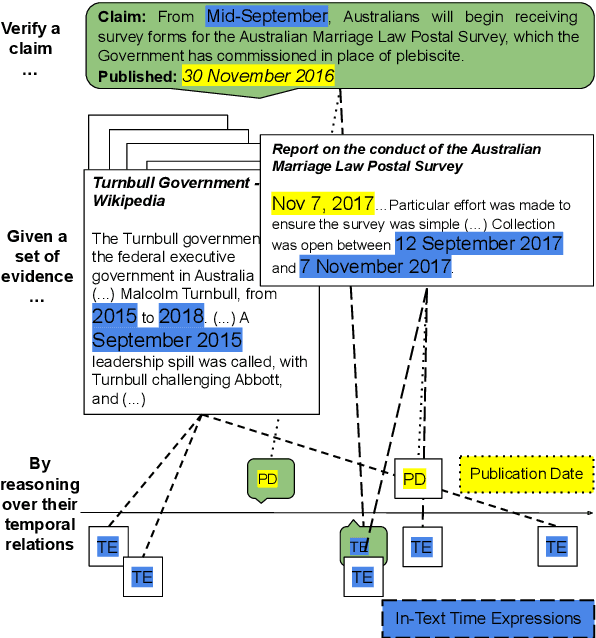
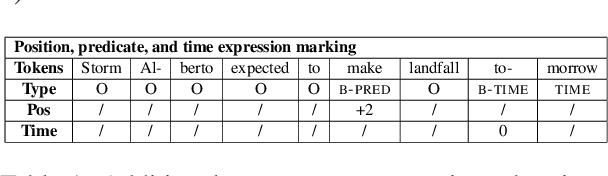
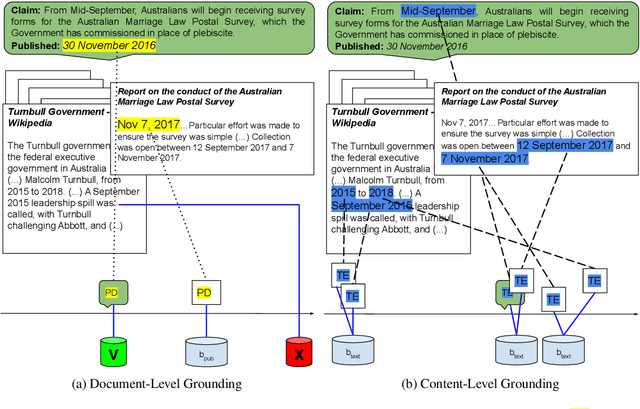
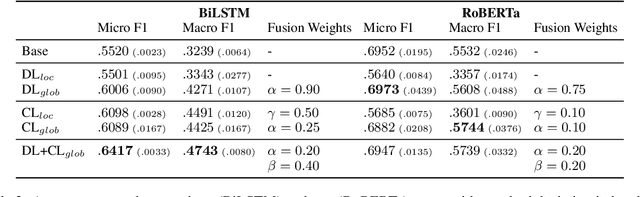
Leveraging contextual knowledge has become standard practice in automated claim verification, yet the impact of temporal reasoning has been largely overlooked. Our study demonstrates that time positively influences the claim verification process of evidence-based fact-checking. The temporal aspects and relations between claims and evidence are first established through grounding on shared timelines, which are constructed using publication dates and time expressions extracted from their text. Temporal information is then provided to RNN-based and Transformer-based classifiers before or after claim and evidence encoding. Our time-aware fact-checking models surpass base models by up to 9% Micro F1 (64.17%) and 15% Macro F1 (47.43%) on the MultiFC dataset. They also outperform prior methods that explicitly model temporal relations between evidence. Our findings show that the presence of temporal information and the manner in which timelines are constructed greatly influence how fact-checking models determine the relevance and supporting or refuting character of evidence documents.
Dynamic Graph Convolution Network with Spatio-Temporal Attention Fusion for Traffic Flow Prediction
Feb 24, 2023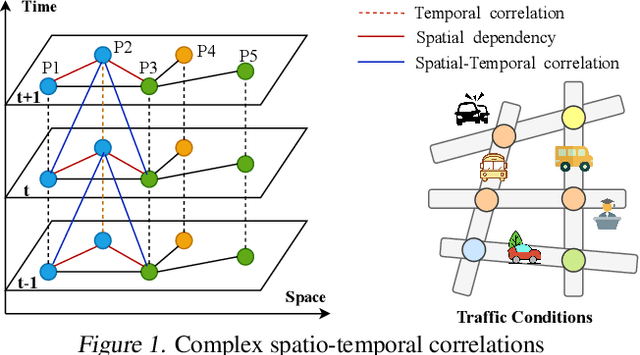
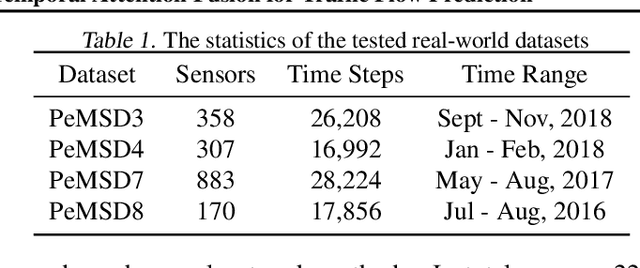
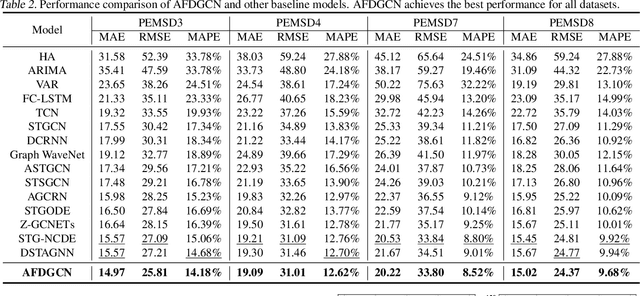
Accurate and real-time traffic state prediction is of great practical importance for urban traffic control and web mapping services (e.g. Google Maps). With the support of massive data, deep learning methods have shown their powerful capability in capturing the complex spatio-temporal patterns of road networks. However, existing approaches use independent components to model temporal and spatial dependencies and thus ignore the heterogeneous characteristics of traffic flow that vary with time and space. In this paper, we propose a novel dynamic graph convolution network with spatio-temporal attention fusion. The method not only captures local spatio-temporal information that changes over time, but also comprehensively models long-distance and multi-scale spatio-temporal patterns based on the fusion mechanism of temporal and spatial attention. This design idea can greatly improve the spatio-temporal perception of the model. We conduct extensive experiments in 4 real-world datasets to demonstrate that our model achieves state-of-the-art performance compared to 22 baseline models.
An ontology-aided, natural language-based approach for multi-constraint BIM model querying
Mar 27, 2023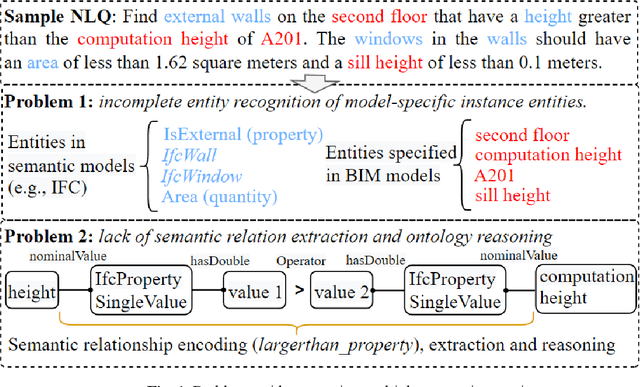
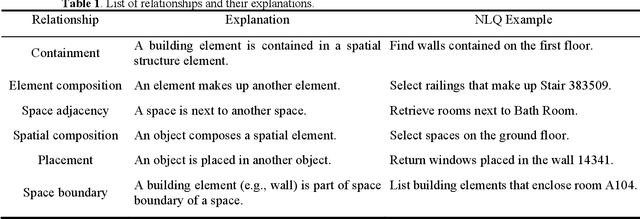
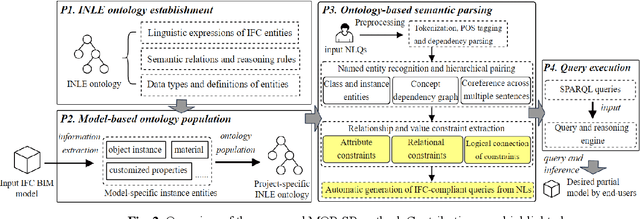
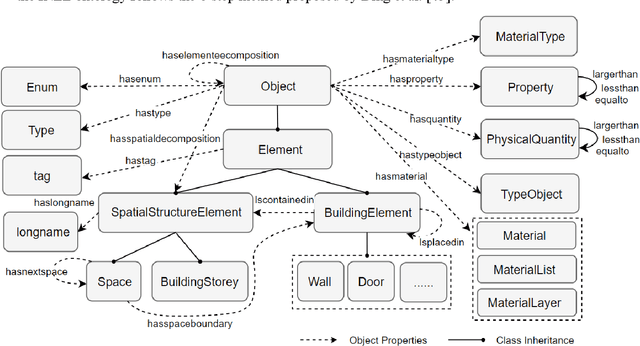
Being able to efficiently retrieve the required building information is critical for construction project stakeholders to carry out their engineering and management activities. Natural language interface (NLI) systems are emerging as a time and cost-effective way to query Building Information Models (BIMs). However, the existing methods cannot logically combine different constraints to perform fine-grained queries, dampening the usability of natural language (NL)-based BIM queries. This paper presents a novel ontology-aided semantic parser to automatically map natural language queries (NLQs) that contain different attribute and relational constraints into computer-readable codes for querying complex BIM models. First, a modular ontology was developed to represent NL expressions of Industry Foundation Classes (IFC) concepts and relationships, and was then populated with entities from target BIM models to assimilate project-specific information. Hereafter, the ontology-aided semantic parser progressively extracts concepts, relationships, and value restrictions from NLQs to fully identify constraint conditions, resulting in standard SPARQL queries with reasoning rules to successfully retrieve IFC-based BIM models. The approach was evaluated based on 225 NLQs collected from BIM users, with a 91% accuracy rate. Finally, a case study about the design-checking of a real-world residential building demonstrates the practical value of the proposed approach in the construction industry.
Online Learning for Incentive-Based Demand Response
Mar 27, 2023In this paper, we consider the problem of learning online to manage Demand Response (DR) resources. A typical DR mechanism requires the DR manager to assign a baseline to the participating consumer, where the baseline is an estimate of the counterfactual consumption of the consumer had it not been called to provide the DR service. A challenge in estimating baseline is the incentive the consumer has to inflate the baseline estimate. We consider the problem of learning online to estimate the baseline and to optimize the operating costs over a period of time under such incentives. We propose an online learning scheme that employs least-squares for estimation with a perturbation to the reward price (for the DR services or load curtailment) that is designed to balance the exploration and exploitation trade-off that arises with online learning. We show that, our proposed scheme is able to achieve a very low regret of $\mathcal{O}\left((\log{T})^2\right)$ with respect to the optimal operating cost over $T$ days of the DR program with full knowledge of the baseline, and is individually rational for the consumers to participate. Our scheme is significantly better than the averaging type approach, which only fetches $\mathcal{O}(T^{1/3})$ regret.
Multi-Flow Transmission in Wireless Interference Networks: A Convergent Graph Learning Approach
Mar 27, 2023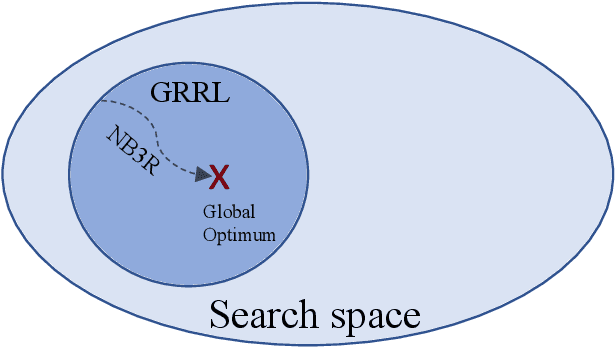
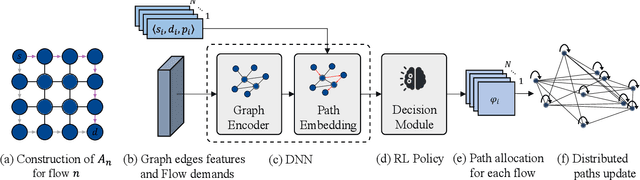
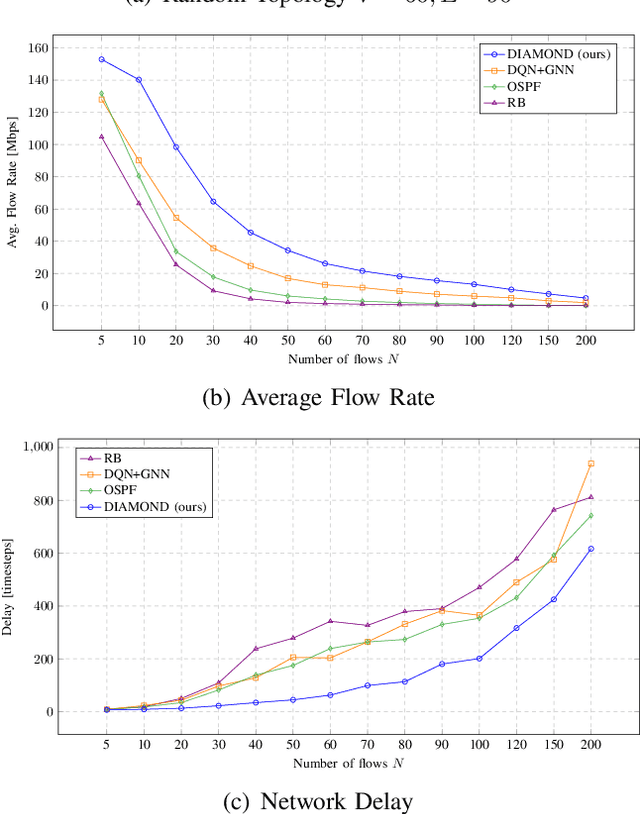
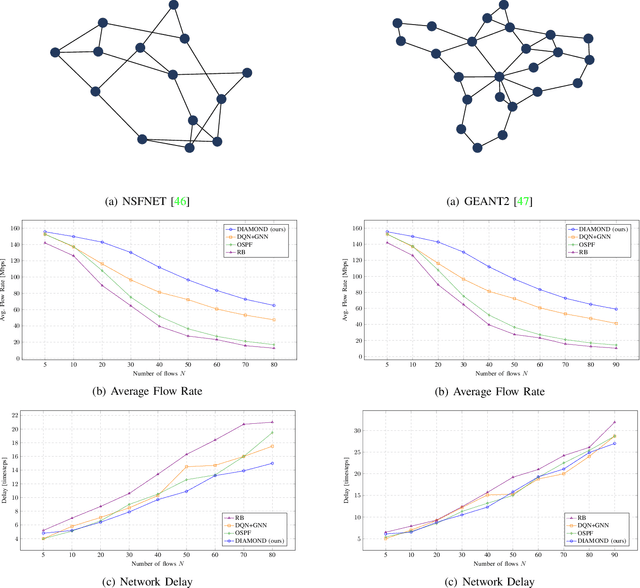
We consider the problem of of multi-flow transmission in wireless networks, where data signals from different flows can interfere with each other due to mutual interference between links along their routes, resulting in reduced link capacities. The objective is to develop a multi-flow transmission strategy that routes flows across the wireless interference network to maximize the network utility. However, obtaining an optimal solution is computationally expensive due to the large state and action spaces involved. To tackle this challenge, we introduce a novel algorithm called Dual-stage Interference-Aware Multi-flow Optimization of Network Data-signals (DIAMOND). The design of DIAMOND allows for a hybrid centralized-distributed implementation, which is a characteristic of 5G and beyond technologies with centralized unit deployments. A centralized stage computes the multi-flow transmission strategy using a novel design of graph neural network (GNN) reinforcement learning (RL) routing agent. Then, a distributed stage improves the performance based on a novel design of distributed learning updates. We provide a theoretical analysis of DIAMOND and prove that it converges to the optimal multi-flow transmission strategy as time increases. We also present extensive simulation results over various network topologies (random deployment, NSFNET, GEANT2), demonstrating the superior performance of DIAMOND compared to existing methods.
DexDeform: Dexterous Deformable Object Manipulation with Human Demonstrations and Differentiable Physics
Mar 27, 2023
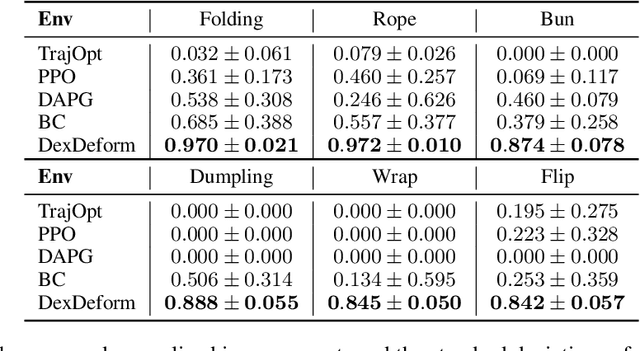
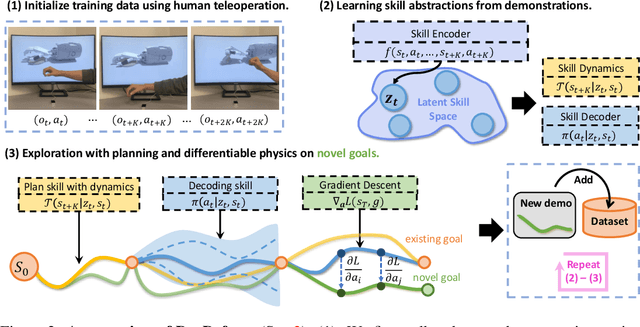

In this work, we aim to learn dexterous manipulation of deformable objects using multi-fingered hands. Reinforcement learning approaches for dexterous rigid object manipulation would struggle in this setting due to the complexity of physics interaction with deformable objects. At the same time, previous trajectory optimization approaches with differentiable physics for deformable manipulation would suffer from local optima caused by the explosion of contact modes from hand-object interactions. To address these challenges, we propose DexDeform, a principled framework that abstracts dexterous manipulation skills from human demonstration and refines the learned skills with differentiable physics. Concretely, we first collect a small set of human demonstrations using teleoperation. And we then train a skill model using demonstrations for planning over action abstractions in imagination. To explore the goal space, we further apply augmentations to the existing deformable shapes in demonstrations and use a gradient optimizer to refine the actions planned by the skill model. Finally, we adopt the refined trajectories as new demonstrations for finetuning the skill model. To evaluate the effectiveness of our approach, we introduce a suite of six challenging dexterous deformable object manipulation tasks. Compared with baselines, DexDeform is able to better explore and generalize across novel goals unseen in the initial human demonstrations.