 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimateCause: Complex and Implicit Causal Structures in Climate Reports
Apr 16, 2026Understanding climate change requires reasoning over complex causal networks. Yet, existing causal discovery datasets predominantly capture explicit, direct causal relations. We introduce ClimateCause, a manually expert-annotated dataset of higher-order causal structures from science-for-policy climate reports, including implicit and nested causality. Cause-effect expressions are normalized and disentangled into individual causal relations to facilitate graph construction, with unique annotations for cause-effect correlation, relation type, and spatiotemporal context. We further demonstrate ClimateCause's value for quantifying readability based on the semantic complexity of causal graphs underlying a statement. Finally, large language model benchmarking on correlation inference and causal chain reasoning highlights the latter as a key challenge.
Mimicking How Humans Interpret Out-of-Context Sentences Through Controlled Toxicity Decoding
Mar 11, 2025Interpretations of a single sentence can vary, particularly when its context is lost. This paper aims to simulate how readers perceive content with varying toxicity levels by generating diverse interpretations of out-of-context sentences. By modeling toxicity, we can anticipate misunderstandings and reveal hidden toxic meanings. Our proposed decoding strategy explicitly controls toxicity in the set of generated interpretations by (i) aligning interpretation toxicity with the input, (ii) relaxing toxicity constraints for more toxic input sentences, and (iii) promoting diversity in toxicity levels within the set of generated interpretations. Experimental results show that our method improves alignment with human-written interpretations in both syntax and semantics while reducing model prediction uncertainty.
Interpretation modeling: Social grounding of sentences by reasoning over their implicit moral judgments
Nov 27, 2023



The social and implicit nature of human communication ramifies readers' understandings of written sentences. Single gold-standard interpretations rarely exist, challenging conventional assumptions in natural language processing. This work introduces the interpretation modeling (IM) task which involves modeling several interpretations of a sentence's underlying semantics to unearth layers of implicit meaning. To obtain these, IM is guided by multiple annotations of social relation and common ground - in this work approximated by reader attitudes towards the author and their understanding of moral judgments subtly embedded in the sentence. We propose a number of modeling strategies that rely on one-to-one and one-to-many generation methods that take inspiration from the philosophical study of interpretation. A first-of-its-kind IM dataset is curated to support experiments and analyses. The modeling results, coupled with scrutiny of the dataset, underline the challenges of IM as conflicting and complex interpretations are socially plausible. This interplay of diverse readings is affirmed by automated and human evaluations on the generated interpretations. Finally, toxicity analyses in the generated interpretations demonstrate the importance of IM for refining filters of content and assisting content moderators in safeguarding the safety in online discourse.
When Do Discourse Markers Affect Computational Sentence Understanding?
Sep 01, 2023



The capabilities and use cases of automatic natural language processing (NLP) have grown significantly over the last few years. While much work has been devoted to understanding how humans deal with discourse connectives, this phenomenon is understudied in computational systems. Therefore, it is important to put NLP models under the microscope and examine whether they can adequately comprehend, process, and reason within the complexity of natural language. In this chapter, we introduce the main mechanisms behind automatic sentence processing systems step by step and then focus on evaluating discourse connective processing. We assess nine popular systems in their ability to understand English discourse connectives and analyze how context and language understanding tasks affect their connective comprehension. The results show that NLP systems do not process all discourse connectives equally well and that the computational processing complexity of different connective kinds is not always consistently in line with the presumed complexity order found in human processing. In addition, while humans are more inclined to be influenced during the reading procedure but not necessarily in the final comprehension performance, discourse connectives have a significant impact on the final accuracy of NLP systems. The richer knowledge of connectives a system learns, the more negative effect inappropriate connectives have on it. This suggests that the correct explicitation of discourse connectives is important for computational natural language processing.
* Chapter 7 of Discourse Markers in Interaction, published in Trends in Linguistics. Studies and Monographs
Implicit Temporal Reasoning for Evidence-Based Fact-Checking
Feb 24, 2023Leveraging contextual knowledge has become standard practice in automated claim verification, yet the impact of temporal reasoning has been largely overlooked. Our study demonstrates that time positively influences the claim verification process of evidence-based fact-checking. The temporal aspects and relations between claims and evidence are first established through grounding on shared timelines, which are constructed using publication dates and time expressions extracted from their text. Temporal information is then provided to RNN-based and Transformer-based classifiers before or after claim and evidence encoding. Our time-aware fact-checking models surpass base models by up to 9% Micro F1 (64.17%) and 15% Macro F1 (47.43%) on the MultiFC dataset. They also outperform prior methods that explicitly model temporal relations between evidence. Our findings show that the presence of temporal information and the manner in which timelines are constructed greatly influence how fact-checking models determine the relevance and supporting or refuting character of evidence documents.
Like Article, Like Audience: Enforcing Multimodal Correlations for Disinformation Detection
Aug 31, 2021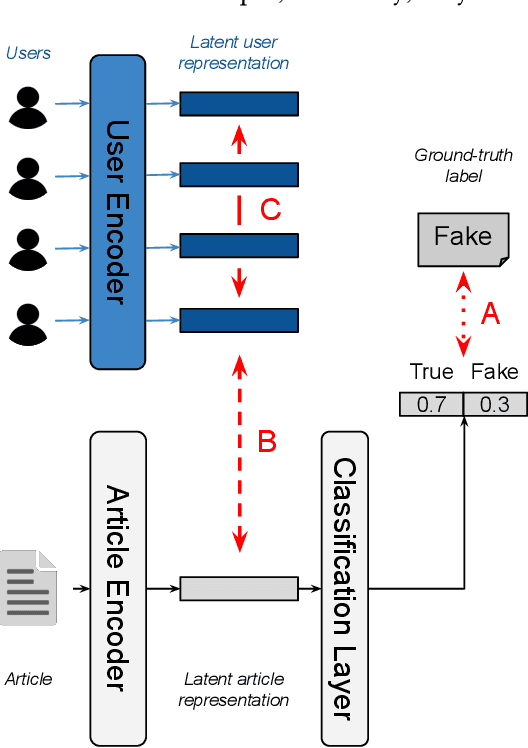
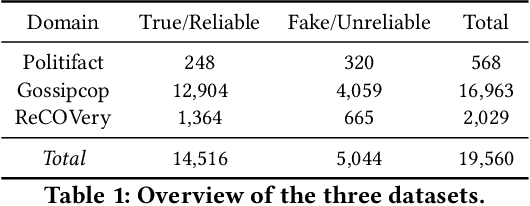
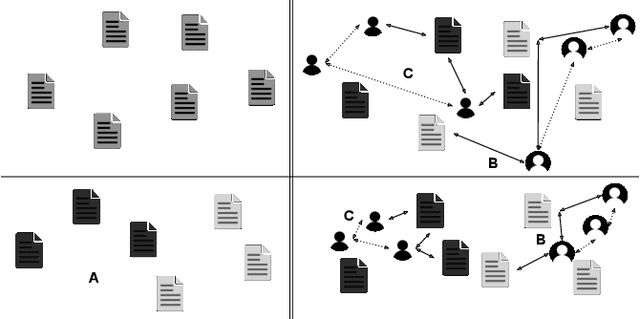

User-generated content (e.g., tweets and profile descriptions) and shared content between users (e.g., news articles) reflect a user's online identity. This paper investigates whether correlations between user-generated and user-shared content can be leveraged for detecting disinformation in online news articles. We develop a multimodal learning algorithm for disinformation detection. The latent representations of news articles and user-generated content allow that during training the model is guided by the profile of users who prefer content similar to the news article that is evaluated, and this effect is reinforced if that content is shared among different users. By only leveraging user information during model optimization, the model does not rely on user profiling when predicting an article's veracity. The algorithm is successfully applied to three widely used neural classifiers, and results are obtained on different datasets. Visualization techniques show that the proposed model learns feature representations of unseen news articles that better discriminate between fake and real news texts.
Time-Aware Evidence Ranking for Fact-Checking
Sep 10, 2020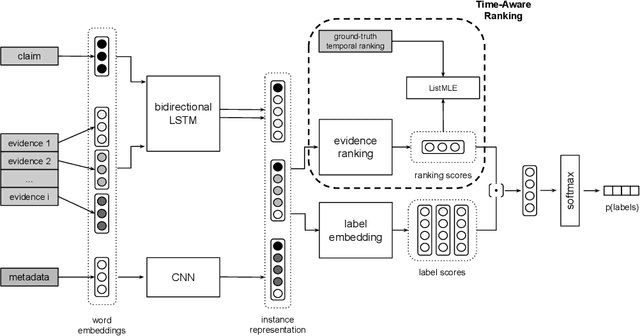
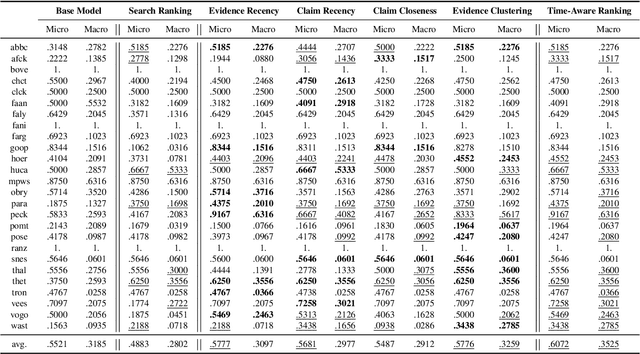
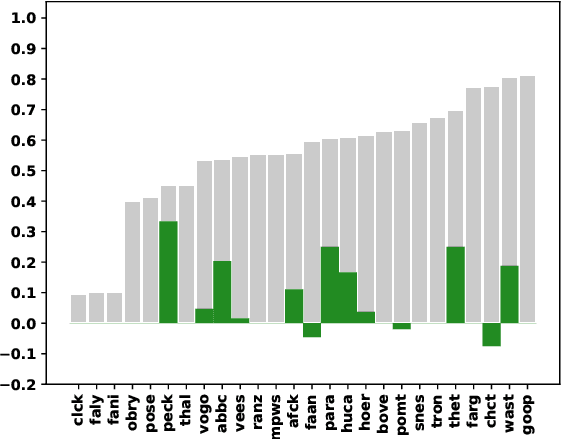
Truth can vary over time. Therefore, fact-checking decisions on claim veracity should take into account temporal information of both the claim and supporting or refuting evidence. Automatic fact-checking models typically take claims and evidence pages as input, and previous work has shown that weighing or ranking these evidence pages by their relevance to the claim is useful. However, the temporal information of the evidence pages is not generally considered when defining evidence relevance. In this work, we investigate the hypothesis that the timestamp of an evidence page is crucial to how it should be ranked for a given claim. We delineate four temporal ranking methods that constrain evidence ranking differently: evidence-based recency, claim-based recency, claim-centered closeness and evidence-centered clustering ranking. Subsequently, we simulate hypothesis-specific evidence rankings given the evidence timestamps as gold standard. Evidence ranking is then optimized using a learning to rank loss function. The best performing time-aware fact-checking model outperforms its baseline by up to 33.34%, depending on the domain. Overall, evidence-based recency and evidence-centered clustering ranking lead to the best results. Our study reveals that time-aware evidence ranking not only surpasses relevance assumptions based purely on semantic similarity or position in a search results list, but also improves veracity predictions of time-sensitive claims in particular.
Checkworthiness in Automatic Claim Detection Models: Definitions and Analysis of Datasets
Aug 20, 2020
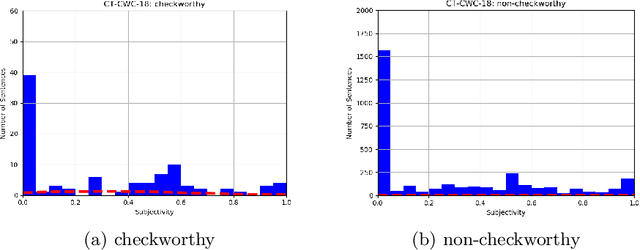
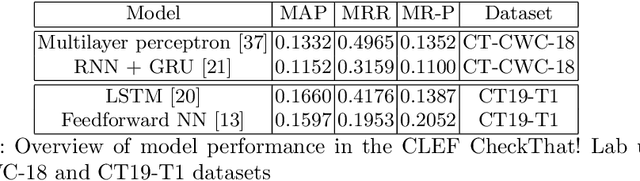
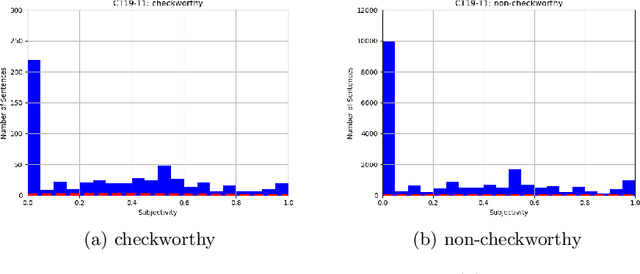
Public, professional and academic interest in automated fact-checking has drastically increased over the past decade, with many aiming to automate one of the first steps in a fact-check procedure: the selection of so-called checkworthy claims. However, there is little agreement on the definition and characteristics of checkworthiness among fact-checkers, which is consequently reflected in the datasets used for training and testing checkworthy claim detection models. After elaborate analysis of checkworthy claim selection procedures in fact-check organisations and analysis of state-of-the-art claim detection datasets, checkworthiness is defined as the concept of having a spatiotemporal and context-dependent worth and need to have the correctness of the objectivity it conveys verified. This is irrespective of the claim's perceived veracity judgement by an individual based on prior knowledge and beliefs. Concerning the characteristics of current datasets, it is argued that the data is not only highly imbalanced and noisy, but also too limited in scope and language. Furthermore, we believe that the subjective concept of checkworthiness might not be a suitable filter for claim detection.
Binary and Multitask Classification Model for Dutch Anaphora Resolution: Die/Dat Prediction
Jan 09, 2020
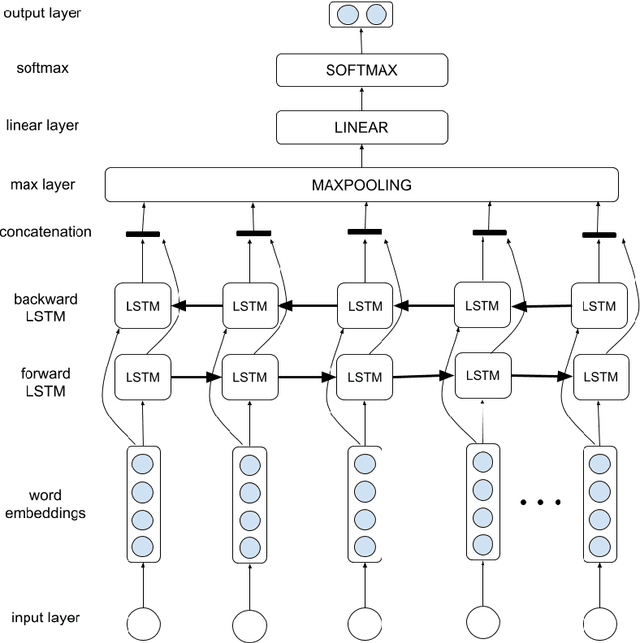
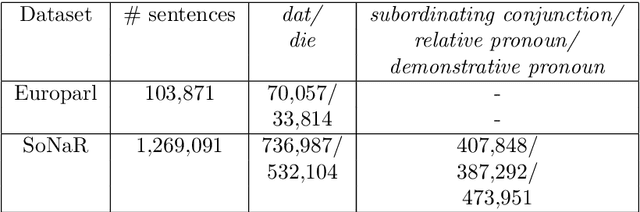
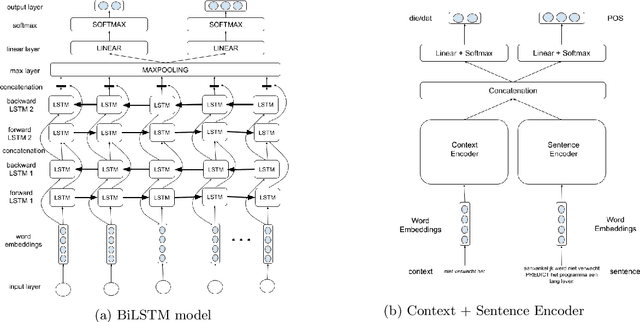
The correct use of Dutch pronouns 'die' and 'dat' is a stumbling block for both native and non-native speakers of Dutch due to the multiplicity of syntactic functions and the dependency on the antecedent's gender and number. Drawing on previous research conducted on neural context-dependent dt-mistake correction models (Heyman et al. 2018), this study constructs the first neural network model for Dutch demonstrative and relative pronoun resolution that specifically focuses on the correction and part-of-speech prediction of these two pronouns. Two separate datasets are built with sentences obtained from, respectively, the Dutch Europarl corpus (Koehn 2015) - which contains the proceedings of the European Parliament from 1996 to the present - and the SoNaR corpus (Oostdijk et al. 2013) - which contains Dutch texts from a variety of domains such as newspapers, blogs and legal texts. Firstly, a binary classification model solely predicts the correct 'die' or 'dat'. The classifier with a bidirectional long short-term memory architecture achieves 84.56% accuracy. Secondly, a multitask classification model simultaneously predicts the correct 'die' or 'dat' and its part-of-speech tag. The model containing a combination of a sentence and context encoder with both a bidirectional long short-term memory architecture results in 88.63% accuracy for die/dat prediction and 87.73% accuracy for part-of-speech prediction. More evenly-balanced data, larger word embeddings, an extra bidirectional long short-term memory layer and integrated part-of-speech knowledge positively affects die/dat prediction performance, while a context encoder architecture raises part-of-speech prediction performance. This study shows promising results and can serve as a starting point for future research on machine learning models for Dutch anaphora resolution.