 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Features matching using natural language processing
Mar 14, 2023
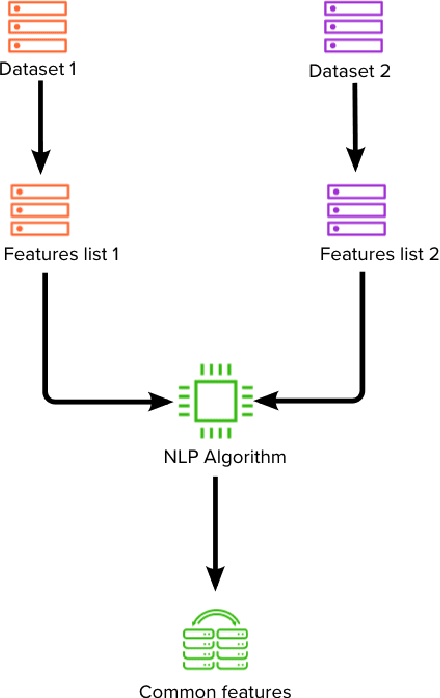

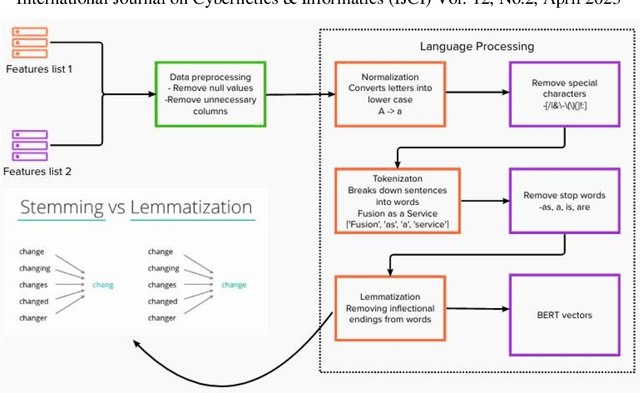
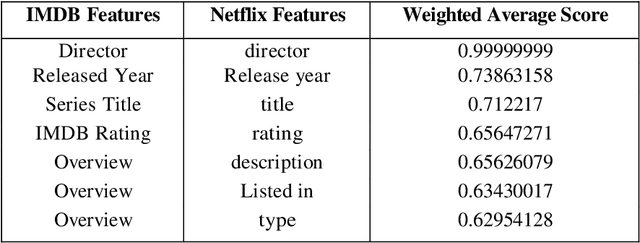
The feature matching is a basic step in matching different datasets. This article proposes shows a new hybrid model of a pretrained Natural Language Processing (NLP) based model called BERT used in parallel with a statistical model based on Jaccard similarity to measure the similarity between list of features from two different datasets. This reduces the time required to search for correlations or manually match each feature from one dataset to another.
* 10 pages, 7 figures, International Conference on NLP & AI (NLPAI 2023)
Building Floorspace in China: A Dataset and Learning Pipeline
Mar 03, 2023
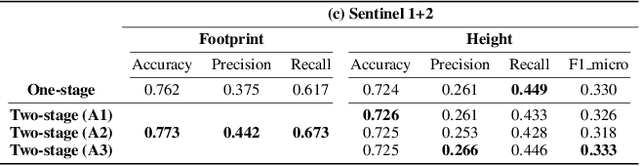
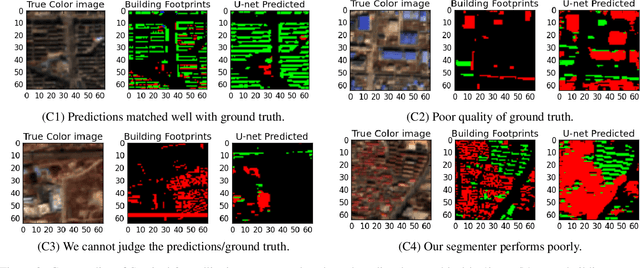
This paper provides the first milestone in measuring the floor space of buildings (that is, building footprint and height) and its evolution over time for China. Doing so requires building on imagery that is of a medium-fine-grained granularity, as longer cross-sections and time series data across many cities are only available in such format. We use a multi-class object segmenter approach to gauge the floor space of buildings in the same framework: first, we determine whether a surface area is covered by buildings (the square footage of occupied land); second, we need to determine the height of buildings from their imagery. We then use Sentinel-1 and -2 satellite images as our main data source. The benefits of these data are their large cross-sectional and longitudinal scope plus their unrestricted accessibility. We provide a detailed description of the algorithms used to generate the data and the results. We analyze the preprocessing steps of reference data (if not ground truth data) and their consequences for measuring the building floor space. We also discuss the future steps in building a time series on urban development based on our preliminary experimental results.
Study on the Data Storage Technology of Mini-Airborne Radar Based on Machine Learning
Mar 03, 2023

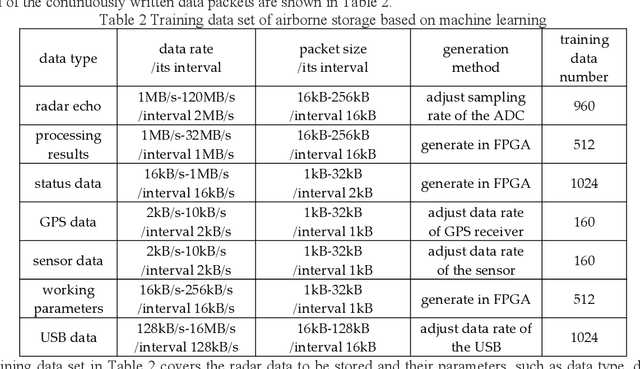

The data rate of airborne radar is much higher than the wireless data transfer rate in many detection applications, so the onboard data storage systems are usually used to store the radar data. Data storage systems with good seismic performance usually use NAND Flash as storage medium, and there is a widespread problem of long file management time, which seriously affects the data storage speed, especially under the limitation of platform miniaturization. To solve this problem, a data storage method based on machine learning is proposed for mini-airborne radar. The storage training model is established based on machine learning, and could process various kinds of radar data. The file management methods are classified and determined using the model, and then are applied to the storage of radar data. To verify the performance of the proposed method, a test was carried out on the data storage system of a mini-airborne radar. The experimental results show that the method based on machine learning can form various data storage methods adapted to different data rates and application scenarios. The ratio of the file management time to the actual data writing time is extremely low.
Generalized Relation Modeling for Transformer Tracking
Mar 29, 2023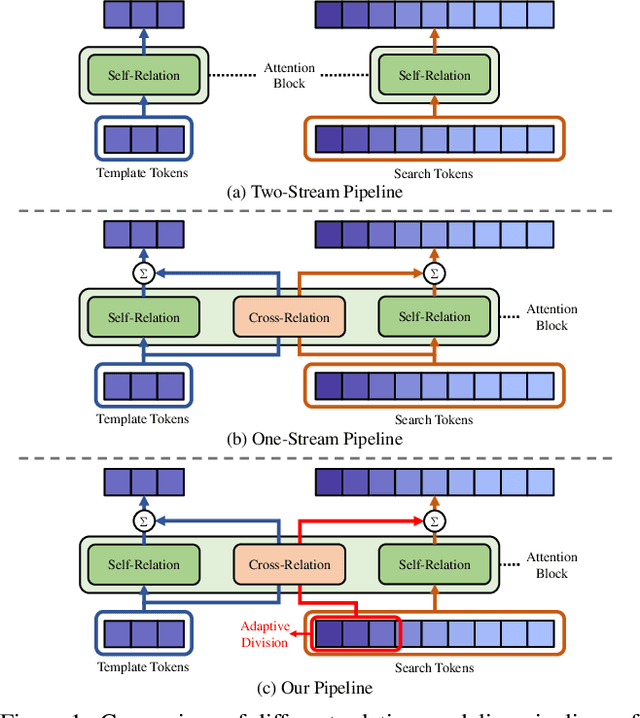
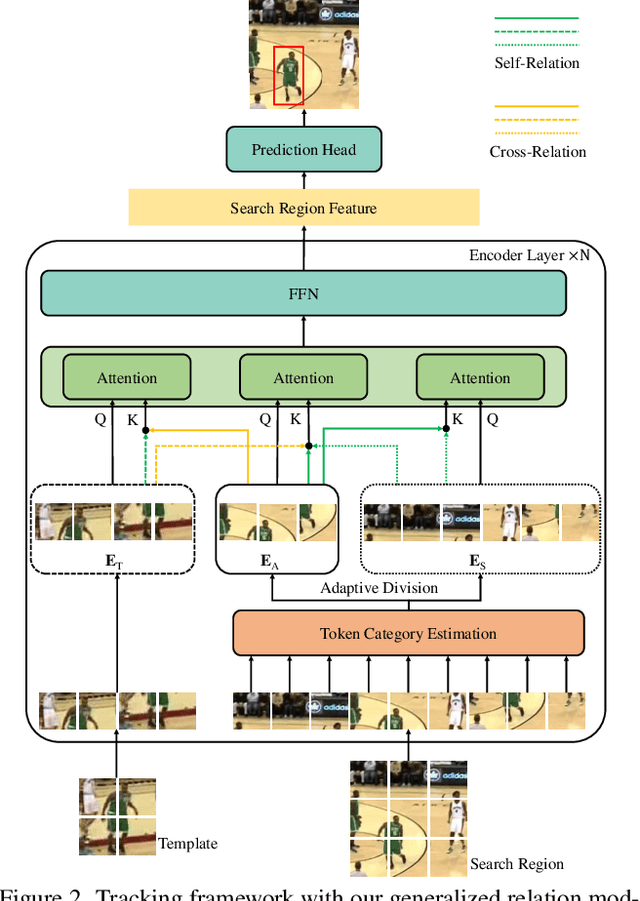

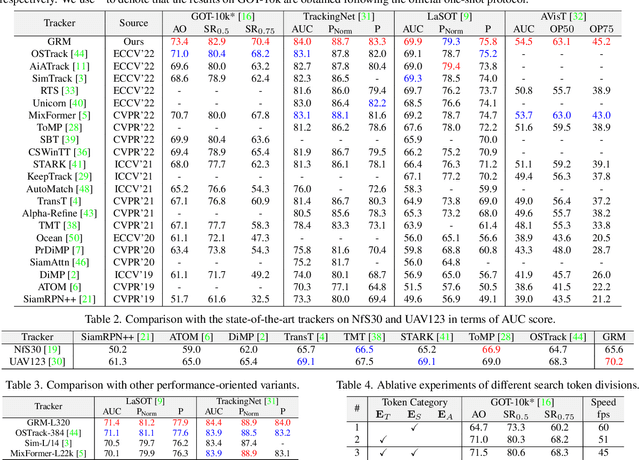
Compared with previous two-stream trackers, the recent one-stream tracking pipeline, which allows earlier interaction between the template and search region, has achieved a remarkable performance gain. However, existing one-stream trackers always let the template interact with all parts inside the search region throughout all the encoder layers. This could potentially lead to target-background confusion when the extracted feature representations are not sufficiently discriminative. To alleviate this issue, we propose a generalized relation modeling method based on adaptive token division. The proposed method is a generalized formulation of attention-based relation modeling for Transformer tracking, which inherits the merits of both previous two-stream and one-stream pipelines whilst enabling more flexible relation modeling by selecting appropriate search tokens to interact with template tokens. An attention masking strategy and the Gumbel-Softmax technique are introduced to facilitate the parallel computation and end-to-end learning of the token division module. Extensive experiments show that our method is superior to the two-stream and one-stream pipelines and achieves state-of-the-art performance on six challenging benchmarks with a real-time running speed.
Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
Mar 29, 2023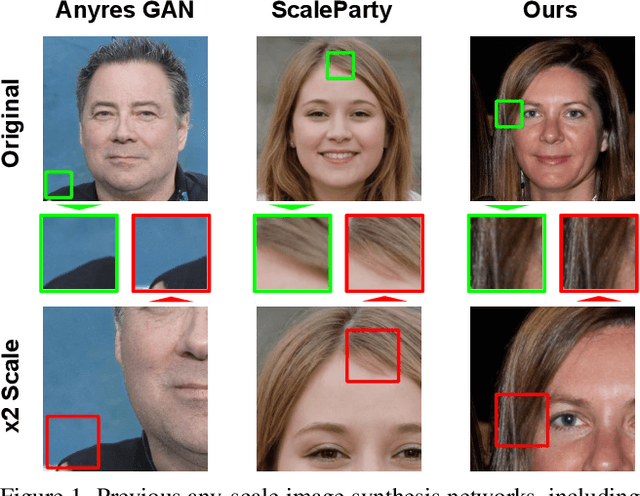
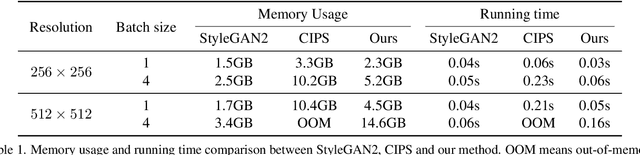
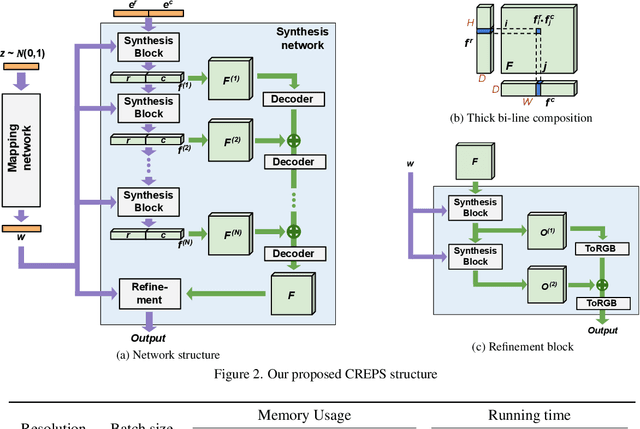

Any-scale image synthesis offers an efficient and scalable solution to synthesize photo-realistic images at any scale, even going beyond 2K resolution. However, existing GAN-based solutions depend excessively on convolutions and a hierarchical architecture, which introduce inconsistency and the $``$texture sticking$"$ issue when scaling the output resolution. From another perspective, INR-based generators are scale-equivariant by design, but their huge memory footprint and slow inference hinder these networks from being adopted in large-scale or real-time systems. In this work, we propose $\textbf{C}$olumn-$\textbf{R}$ow $\textbf{E}$ntangled $\textbf{P}$ixel $\textbf{S}$ynthesis ($\textbf{CREPS}$), a new generative model that is both efficient and scale-equivariant without using any spatial convolutions or coarse-to-fine design. To save memory footprint and make the system scalable, we employ a novel bi-line representation that decomposes layer-wise feature maps into separate $``$thick$"$ column and row encodings. Experiments on various datasets, including FFHQ, LSUN-Church, MetFaces, and Flickr-Scenery, confirm CREPS' ability to synthesize scale-consistent and alias-free images at any arbitrary resolution with proper training and inference speed. Code is available at https://github.com/VinAIResearch/CREPS.
Robust Dancer: Long-term 3D Dance Synthesis Using Unpaired Data
Mar 29, 2023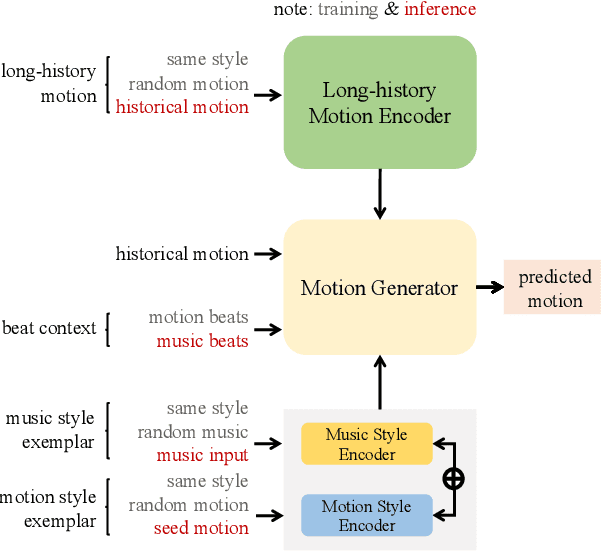
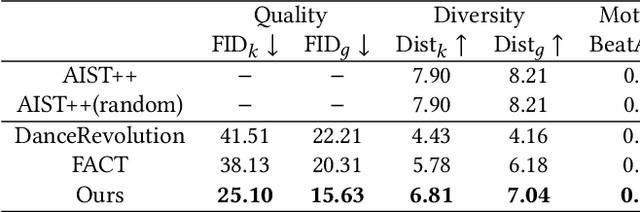
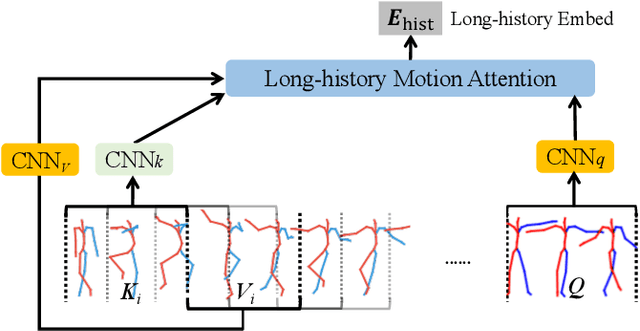
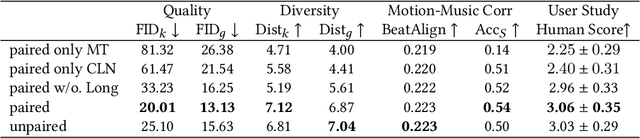
How to automatically synthesize natural-looking dance movements based on a piece of music is an incrementally popular yet challenging task. Most existing data-driven approaches require hard-to-get paired training data and fail to generate long sequences of motion due to error accumulation of autoregressive structure. We present a novel 3D dance synthesis system that only needs unpaired data for training and could generate realistic long-term motions at the same time. For the unpaired data training, we explore the disentanglement of beat and style, and propose a Transformer-based model free of reliance upon paired data. For the synthesis of long-term motions, we devise a new long-history attention strategy. It first queries the long-history embedding through an attention computation and then explicitly fuses this embedding into the generation pipeline via multimodal adaptation gate (MAG). Objective and subjective evaluations show that our results are comparable to strong baseline methods, despite not requiring paired training data, and are robust when inferring long-term music. To our best knowledge, we are the first to achieve unpaired data training - an ability that enables to alleviate data limitations effectively. Our code is released on https://github.com/BFeng14/RobustDancer
MuRAL: Multi-Scale Region-based Active Learning for Object Detection
Mar 29, 2023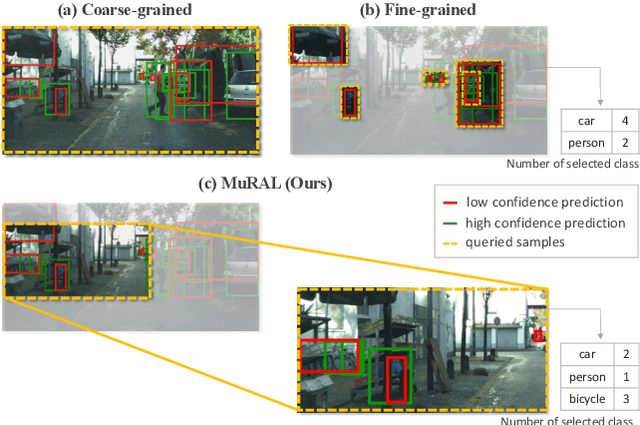
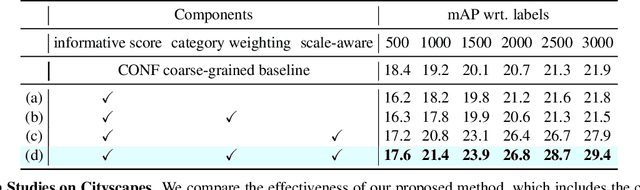
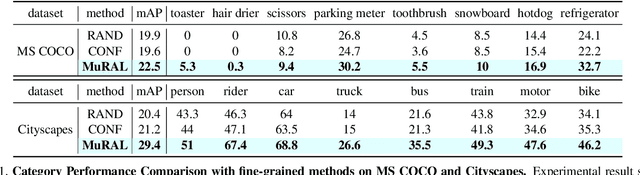

Obtaining large-scale labeled object detection dataset can be costly and time-consuming, as it involves annotating images with bounding boxes and class labels. Thus, some specialized active learning methods have been proposed to reduce the cost by selecting either coarse-grained samples or fine-grained instances from unlabeled data for labeling. However, the former approaches suffer from redundant labeling, while the latter methods generally lead to training instability and sampling bias. To address these challenges, we propose a novel approach called Multi-scale Region-based Active Learning (MuRAL) for object detection. MuRAL identifies informative regions of various scales to reduce annotation costs for well-learned objects and improve training performance. The informative region score is designed to consider both the predicted confidence of instances and the distribution of each object category, enabling our method to focus more on difficult-to-detect classes. Moreover, MuRAL employs a scale-aware selection strategy that ensures diverse regions are selected from different scales for labeling and downstream finetuning, which enhances training stability. Our proposed method surpasses all existing coarse-grained and fine-grained baselines on Cityscapes and MS COCO datasets, and demonstrates significant improvement in difficult category performance.
Modelling Maritime SAR Effective Sweep Widths for Helicopters in VDM
Mar 29, 2023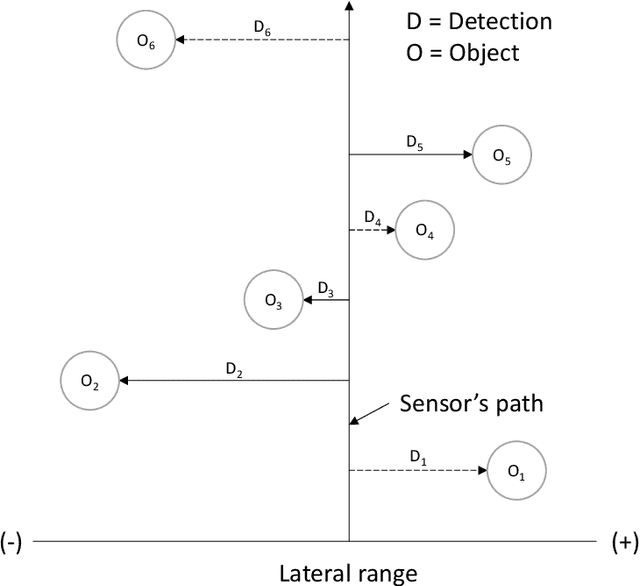
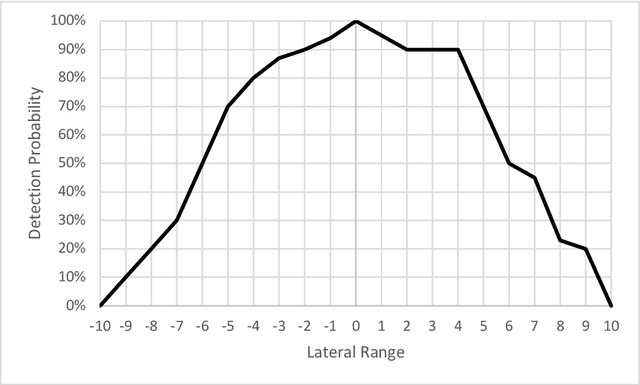
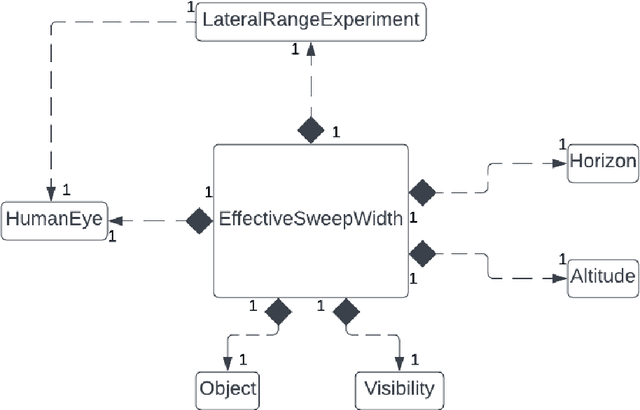

Search and Rescue (SAR) is searching for and providing help to people in danger. In the UK, SAR teams are typically charities with limited resources, and SAR missions are time critical. Search managers need to objectively decide which search assets (e.g. helicopter vs drone) would be better. A key metric in the SAR community is effective sweep width (W), which provides a single measure for a search asset's ability to detect a specific object in specific environmental conditions. Tables of W for different search assets are provided in various manuals, such as the International Aeronautical and Maritime SAR (IAMSAR) Manual. However, these tables take years of expensive testing and experience to produce, and no such tables exist for drones. This paper uses the Vienna Development Method (VDM) to build an initial model of W for a known case (helicopters at sea) with a view to predicting W tables for drones. The model computes W for various search object sizes, helicopter altitude and visibility. The results for the model are quite different from the published tables, which shows that the abstraction level is not yet correct, however it produced useful insights and directions for the next steps.
One-Bit Covariance Reconstruction with Non-zero Thresholds: Algorithm and Performance Analysis
Mar 29, 2023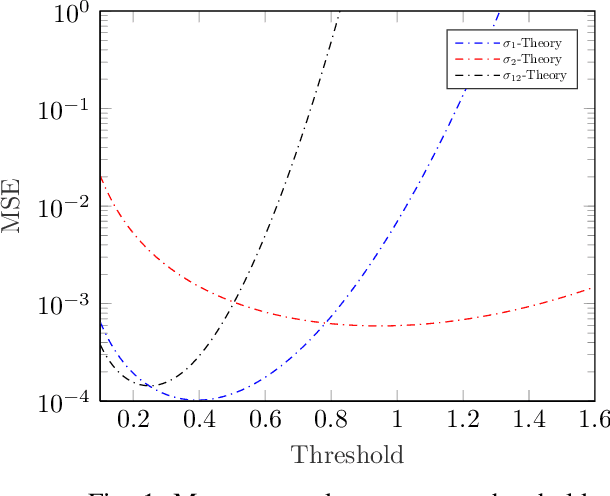
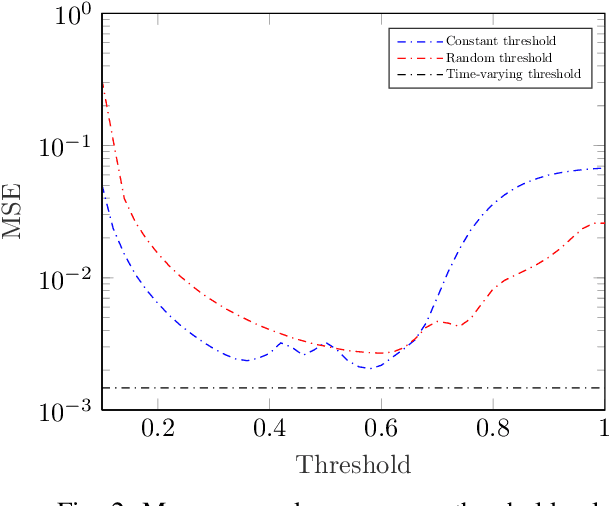

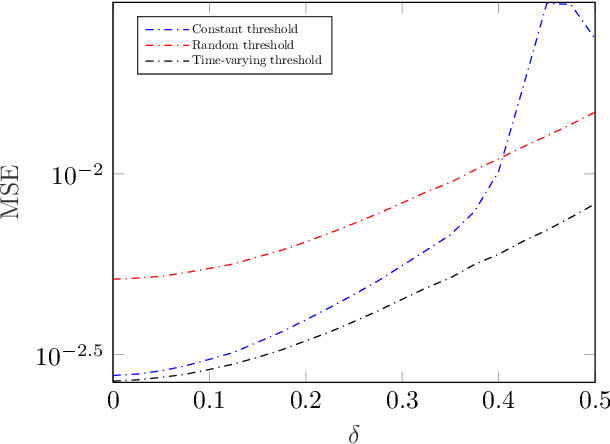
Covariance matrix reconstruction is a topic of great significance in the field of one-bit signal processing and has numerous practical applications. Despite its importance, the conventional arcsine law with zero threshold is incapable of recovering the diagonal elements of the covariance matrix. To address this limitation, recent studies have proposed the use of non-zero clipping thresholds. However, the relationship between the estimation error and the sampling threshold is not yet known. In this paper, we undertake an analysis of the mean squared error by computing the Fisher information matrix for a given threshold. Our results reveal that the optimal threshold can vary considerably, depending on the variances and correlation coefficients. As a result, it is inappropriate to use a constant threshold to encompass parameters that vary widely. To mitigate this issue, we present a recovery scheme that incorporates time-varying thresholds. Our approach differs from existing methods in that it utilizes the exact values of the threshold, rather than its statistical properties, to enhance the estimation performance. Our simulations, including the direction-of-arrival estimation problem, demonstrate the efficacy of the developed scheme, especially in complex scenarios where the covariance elements are widely separated.
Signal processing on large networks with group symmetries
Mar 29, 2023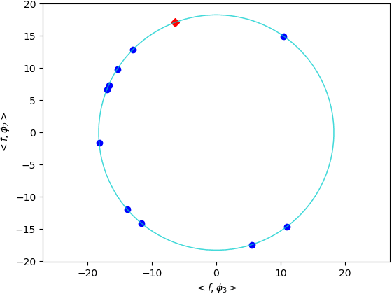
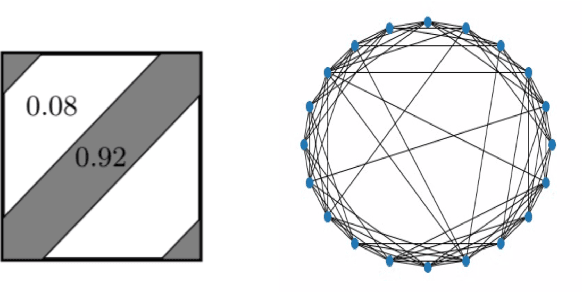
Current methods of graph signal processing rely heavily on the specific structure of the underlying network: the shift operator and the graph Fourier transform are both derived directly from a specific graph. In many cases, the network is subject to error or natural changes over time. This motivated a new perspective on GSP, where the signal processing framework is developed for an entire class of graphs with similar structures. This approach can be formalized via the theory of graph limits, where graphs are considered as random samples from a distribution represented by a graphon. When the network under consideration has underlying symmetries, they may be modeled as samples from Cayley graphons. In Cayley graphons, vertices are sampled from a group, and the link probability between two vertices is determined by a function of the two corresponding group elements. Infinite groups such as the 1-dimensional torus can be used to model networks with an underlying spatial reality. Cayley graphons on finite groups give rise to a Stochastic Block Model, where the link probabilities between blocks form a (edge-weighted) Cayley graph. This manuscript summarizes some work on graph signal processing on large networks, in particular samples of Cayley graphons.