 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross-Domain Evaluation of POS Taggers: From Wall Street Journal to Fandom Wiki
Apr 27, 2023
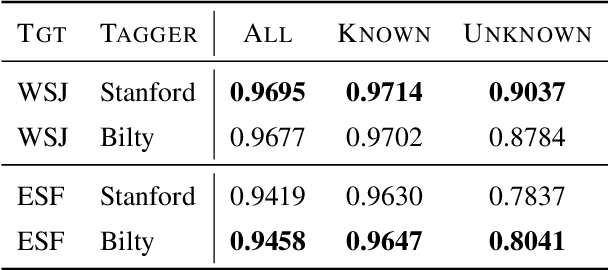
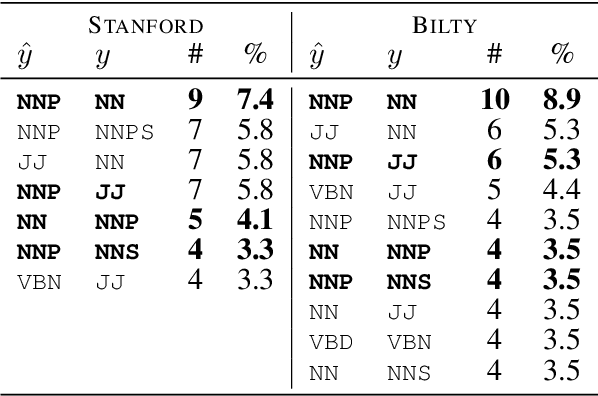
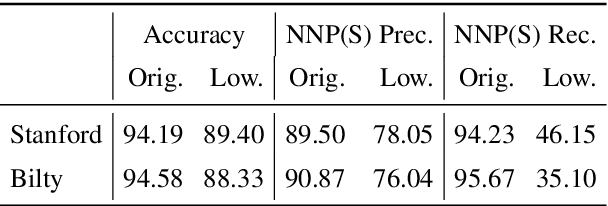
The Wall Street Journal section of the Penn Treebank has been the de-facto standard for evaluating POS taggers for a long time, and accuracies over 97\% have been reported. However, less is known about out-of-domain tagger performance, especially with fine-grained label sets. Using data from Elder Scrolls Fandom, a wiki about the \textit{Elder Scrolls} video game universe, we create a modest dataset for qualitatively evaluating the cross-domain performance of two POS taggers: the Stanford tagger (Toutanova et al. 2003) and Bilty (Plank et al. 2016), both trained on WSJ. Our analyses show that performance on tokens seen during training is almost as good as in-domain performance, but accuracy on unknown tokens decreases from 90.37% to 78.37% (Stanford) and 87.84\% to 80.41\% (Bilty) across domains. Both taggers struggle with proper nouns and inconsistent capitalization.
Partial-Information Multiple Access Protocol for Orthogonal Transmissions
Apr 24, 2023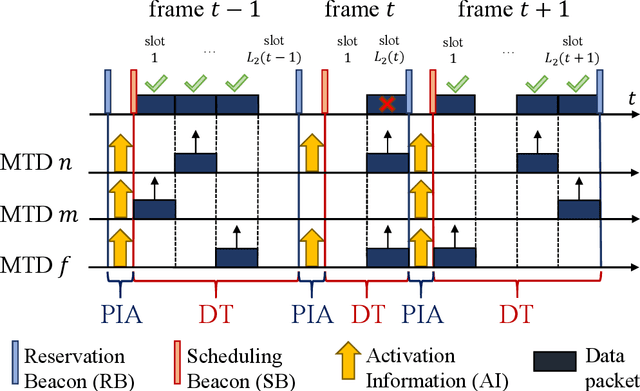
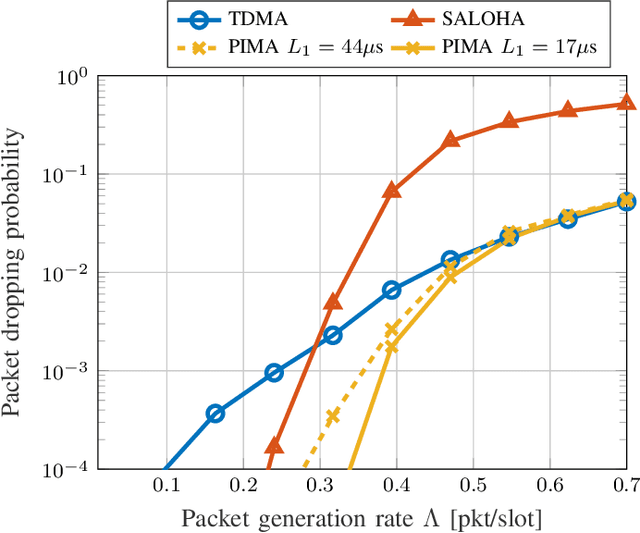
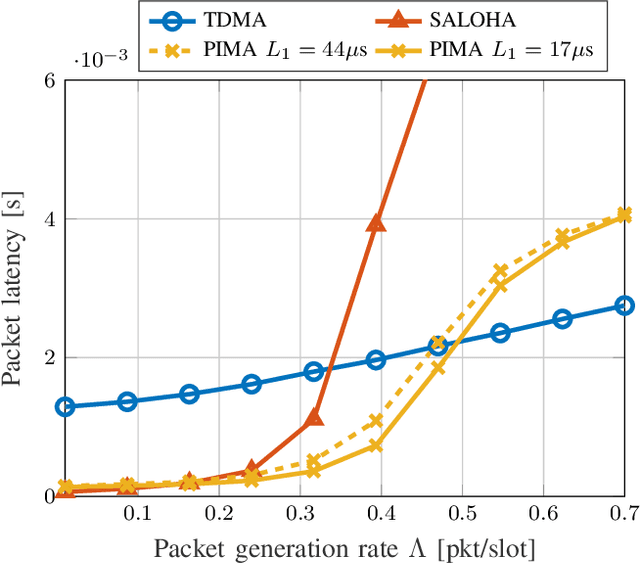
With the stringent requirements introduced by the new sixth-generation (6G) internet-of-things (IoT) use cases, traditional approaches to multiple access control have started to show their limitations. A new wave of grant-free (GF) approaches have been therefore proposed as a viable alternative. However, a definitive solution is still to be accomplished. In our work, we propose a new semi-GF coordinated random access (RA) protocol, denoted as partial-information multiple access (PIMA), to reduce packet loss and latency, particularly in the presence of sporadic activations. We consider a machine-type communications (MTC) scenario, wherein devices need to transmit data packets in the uplink to a base station (BS). When using PIMA, the BS can acquire partial information on the instantaneous traffic conditions and, using compute-over-the-air techniques, estimate the number of devices with packets waiting for transmission in their queue. Based on this knowledge, the BS assigns to each device a single slot for transmission. However, since each slot may still be assigned to multiple users, collisions may occur. Both the total number of allocated slots and the user assignments are optimized, based on the estimated number of active users, to reduce collisions and improve the efficiency of the multiple access scheme. To prove the validity of our solution, we compare PIMA to time-division multiple-access (TDMA) and slotted ALOHA (SALOHA) schemes, the ideal solutions for orthogonal multiple access (OMA) in the time domain in the case of low and high traffic conditions, respectively. We show that PIMA is able not only to adapt to different traffic conditions and to provide fewer packet drops regardless of the intensity of packet generations, but also able to merge the advantages of both TDMA and SALOHA schemes, thus providing performance improvements in terms of packet loss probability and latency.
Optimizing Privacy, Utility and Efficiency in Constrained Multi-Objective Federated Learning
May 03, 2023


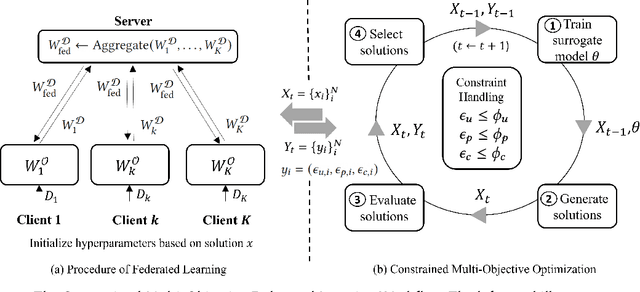
Conventionally, federated learning aims to optimize a single objective, typically the utility. However, for a federated learning system to be trustworthy, it needs to simultaneously satisfy multiple/many objectives, such as maximizing model performance, minimizing privacy leakage and training cost, and being robust to malicious attacks. Multi-Objective Optimization (MOO) aiming to optimize multiple conflicting objectives at the same time is quite suitable for solving the optimization problem of Trustworthy Federated Learning (TFL). In this paper, we unify MOO and TFL by formulating the problem of constrained multi-objective federated learning (CMOFL). Under this formulation, existing MOO algorithms can be adapted to TFL straightforwardly. Different from existing CMOFL works focusing on utility, efficiency, fairness, and robustness, we consider optimizing privacy leakage along with utility loss and training cost, the three primary objectives of a TFL system. We develop two improved CMOFL algorithms based on NSGA-II and PSL, respectively, for effectively and efficiently finding Pareto optimal solutions, and we provide theoretical analysis on their convergence. We design specific measurements of privacy leakage, utility loss, and training cost for three privacy protection mechanisms: Randomization, BatchCrypt (An efficient version of homomorphic encryption), and Sparsification. Empirical experiments conducted under each of the three protection mechanisms demonstrate the effectiveness of our proposed algorithms.
Quantifying the Dissimilarity of Texts
May 03, 2023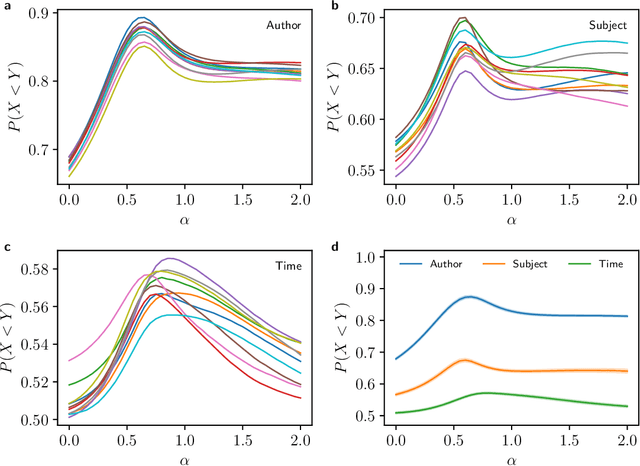
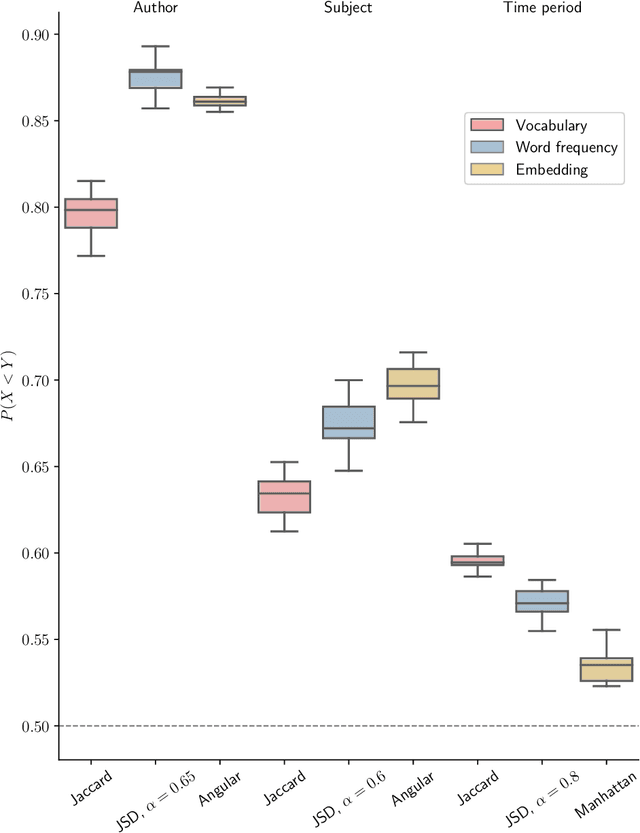
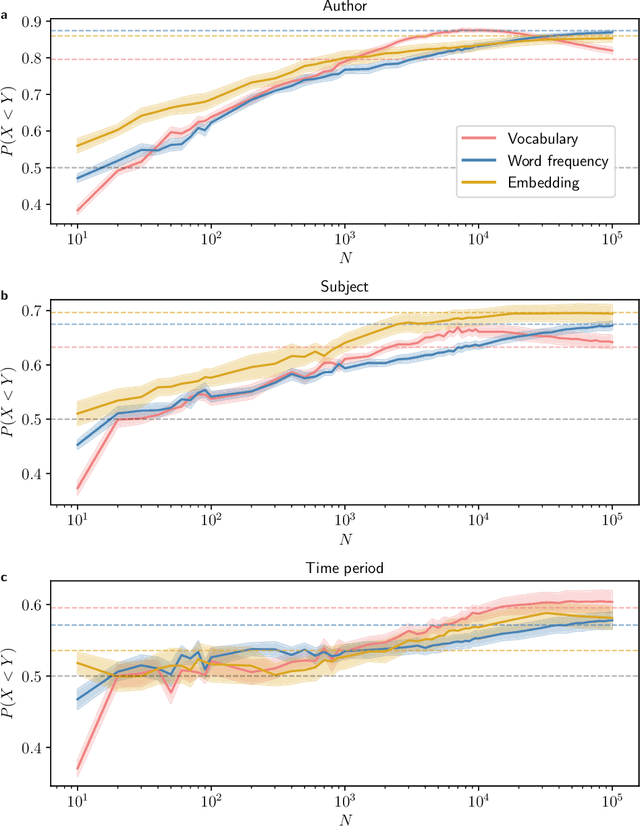
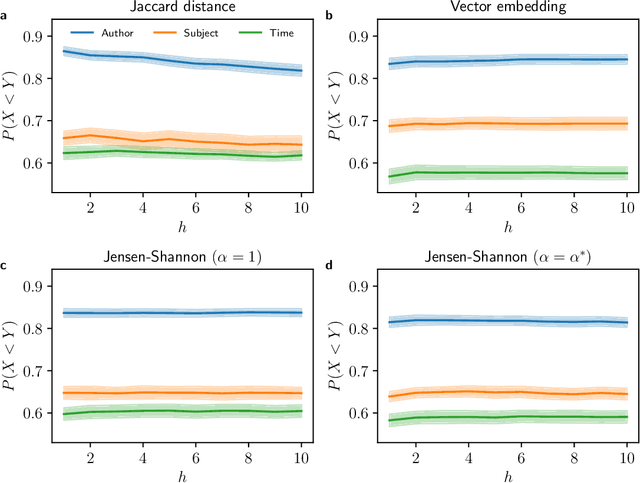
Quantifying the dissimilarity of two texts is an important aspect of a number of natural language processing tasks, including semantic information retrieval, topic classification, and document clustering. In this paper, we compared the properties and performance of different dissimilarity measures $D$ using three different representations of texts -- vocabularies, word frequency distributions, and vector embeddings -- and three simple tasks -- clustering texts by author, subject, and time period. Using the Project Gutenberg database, we found that the generalised Jensen--Shannon divergence applied to word frequencies performed strongly across all tasks, that $D$'s based on vector embedding representations led to stronger performance for smaller texts, and that the optimal choice of approach was ultimately task-dependent. We also investigated, both analytically and numerically, the behaviour of the different $D$'s when the two texts varied in length by a factor $h$. We demonstrated that the (natural) estimator of the Jaccard distance between vocabularies was inconsistent and computed explicitly the $h$-dependency of the bias of the estimator of the generalised Jensen--Shannon divergence applied to word frequencies. We also found numerically that the Jensen--Shannon divergence and embedding-based approaches were robust to changes in $h$, while the Jaccard distance was not.
* 16 pages, 4 figures, part of the Special Issue Novel Methods and Applications in Natural Language Processing
Learning Flow Functions from Data with Applications to Nonlinear Oscillators
Mar 29, 2023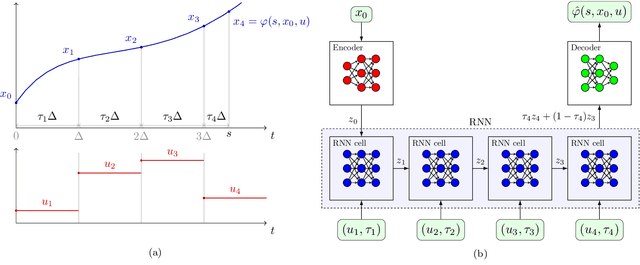
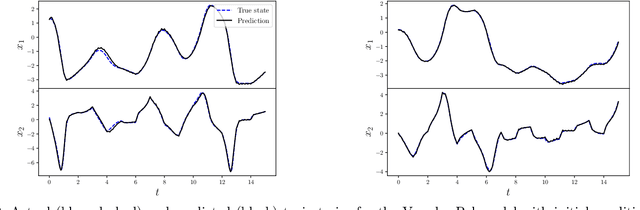
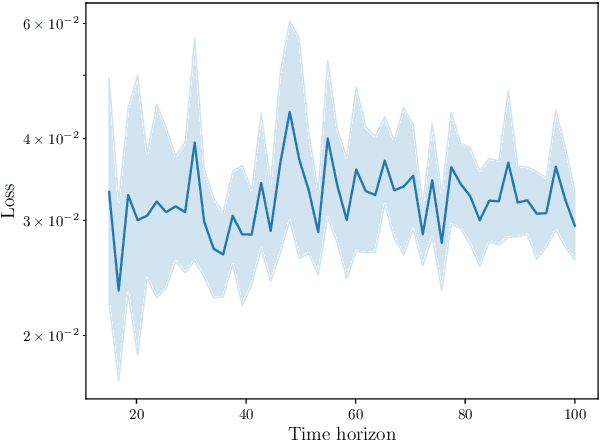
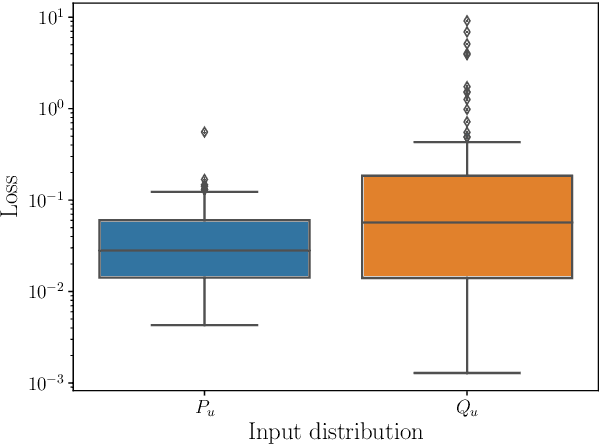
We describe a recurrent neural network (RNN) based architecture to learn the flow function of a causal, time-invariant and continuous-time control system from trajectory data. By restricting the class of control inputs to piecewise constant functions, we show that learning the flow function is equivalent to learning the input-to-state map of a discrete-time dynamical system. This motivates the use of an RNN together with encoder and decoder networks which map the state of the system to the hidden state of the RNN and back. We show that the proposed architecture is able to approximate the flow function by exploiting the system's causality and time-invariance. The output of the learned flow function model can be queried at any time instant. We experimentally validate the proposed method using models of the Van der Pol and FitzHugh Nagumo oscillators. In both cases, the results demonstrate that the architecture is able to closely reproduce the trajectories of these two systems. For the Van der Pol oscillator, we further show that the trained model generalises to the system's response with a prolonged prediction time horizon as well as control inputs outside the training distribution. For the FitzHugh-Nagumo oscillator, we show that the model accurately captures the input-dependent phenomena of excitability.
GazeSAM: What You See is What You Segment
Apr 26, 2023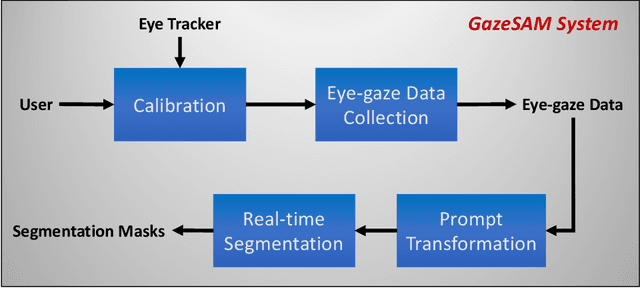
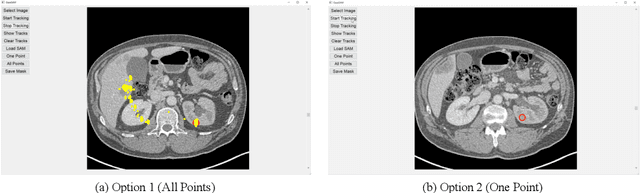
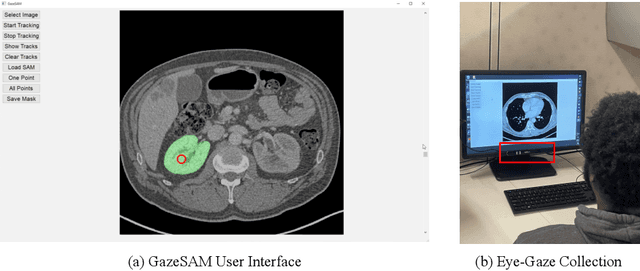
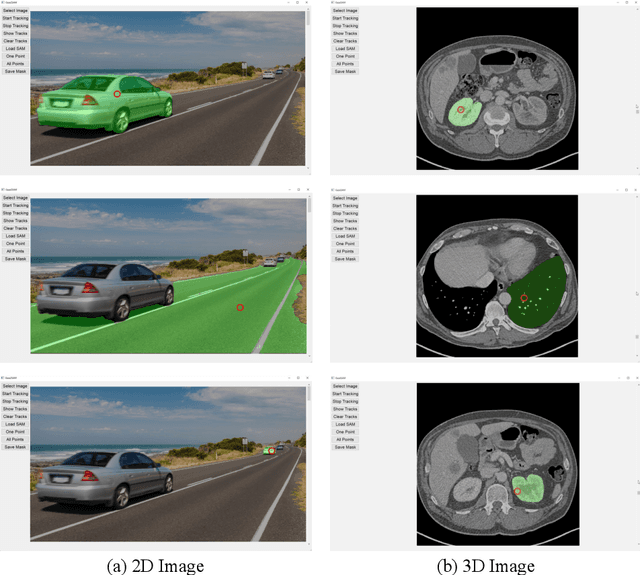
This study investigates the potential of eye-tracking technology and the Segment Anything Model (SAM) to design a collaborative human-computer interaction system that automates medical image segmentation. We present the \textbf{GazeSAM} system to enable radiologists to collect segmentation masks by simply looking at the region of interest during image diagnosis. The proposed system tracks radiologists' eye movement and utilizes the eye-gaze data as the input prompt for SAM, which automatically generates the segmentation mask in real time. This study is the first work to leverage the power of eye-tracking technology and SAM to enhance the efficiency of daily clinical practice. Moreover, eye-gaze data coupled with image and corresponding segmentation labels can be easily recorded for further advanced eye-tracking research. The code is available in \url{https://github.com/ukaukaaaa/GazeSAM}.
Development of a Realistic Crowd Simulation Environment for Fine-grained Validation of People Tracking Methods
Apr 26, 2023
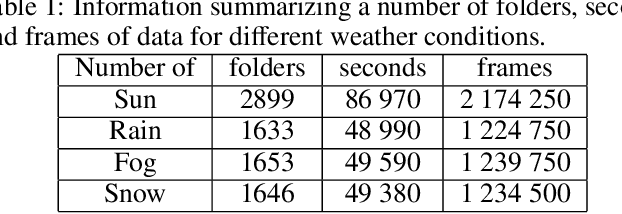


Generally, crowd datasets can be collected or generated from real or synthetic sources. Real data is generated by using infrastructure-based sensors (such as static cameras or other sensors). The use of simulation tools can significantly reduce the time required to generate scenario-specific crowd datasets, facilitate data-driven research, and next build functional machine learning models. The main goal of this work was to develop an extension of crowd simulation (named CrowdSim2) and prove its usability in the application of people-tracking algorithms. The simulator is developed using the very popular Unity 3D engine with particular emphasis on the aspects of realism in the environment, weather conditions, traffic, and the movement and models of individual agents. Finally, three methods of tracking were used to validate generated dataset: IOU-Tracker, Deep-Sort, and Deep-TAMA.
RPTQ: Reorder-based Post-training Quantization for Large Language Models
Apr 25, 2023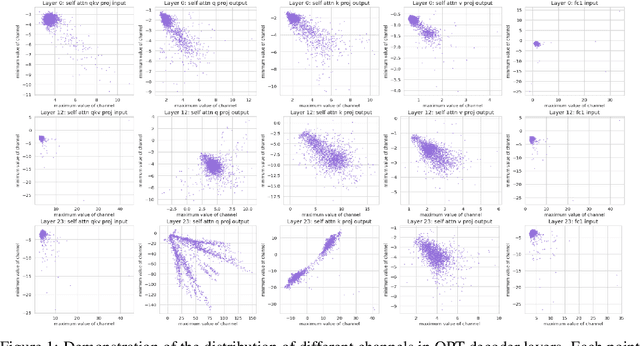
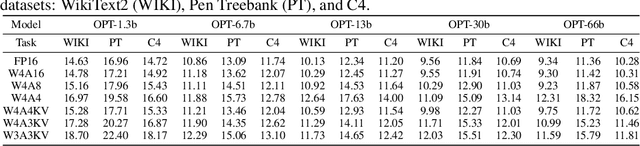
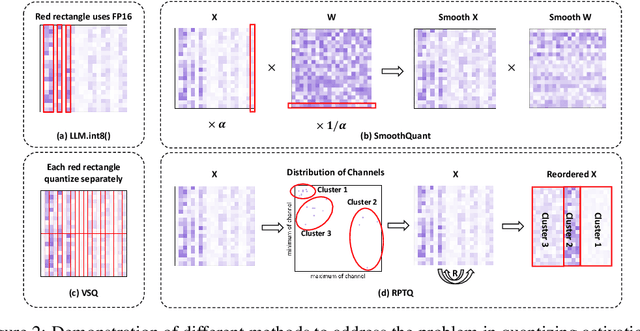
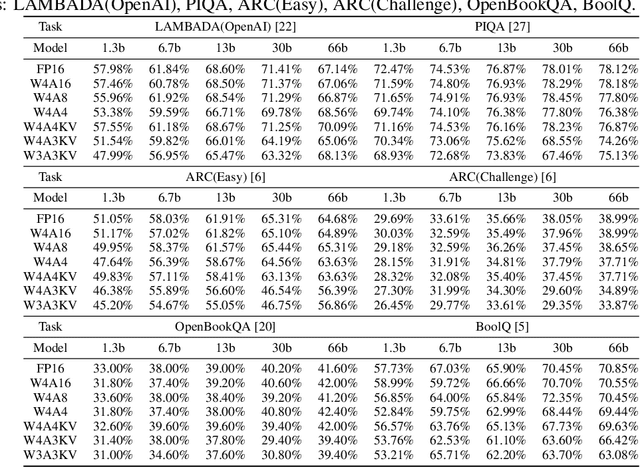
Large-scale language models (LLMs) have demonstrated outstanding performance on various tasks, but their deployment poses challenges due to their enormous model size. In this paper, we identify that the main challenge in quantizing LLMs stems from the different activation ranges between the channels, rather than just the issue of outliers.We propose a novel reorder-based quantization approach, RPTQ, that addresses the issue of quantizing the activations of LLMs. RPTQ rearranges the channels in the activations and then quantizing them in clusters, thereby reducing the impact of range difference of channels. In addition, we reduce the storage and computation overhead by avoiding explicit reordering. By implementing this approach, we achieved a significant breakthrough by pushing LLM models to 3 bit activation for the first time.
A priori compression of convolutional neural networks for wave simulators
Apr 12, 2023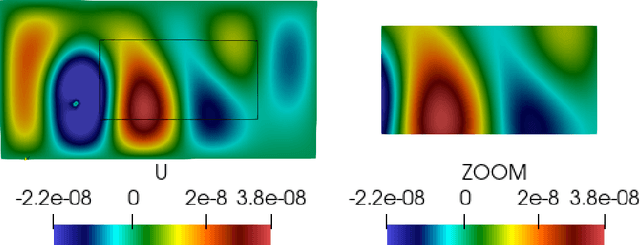
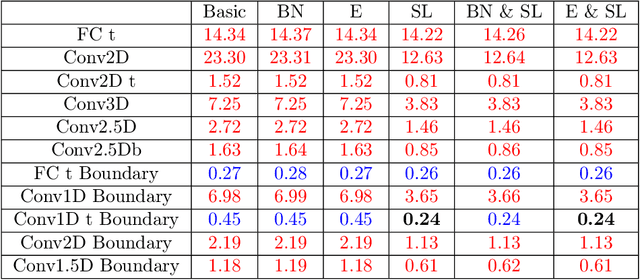
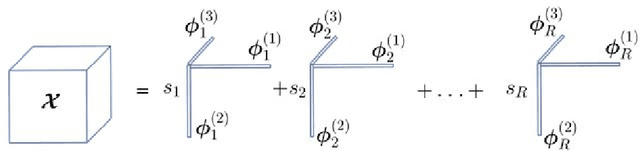
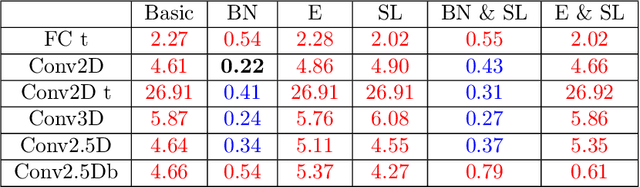
Convolutional neural networks are now seeing widespread use in a variety of fields, including image classification, facial and object recognition, medical imaging analysis, and many more. In addition, there are applications such as physics-informed simulators in which accurate forecasts in real time with a minimal lag are required. The present neural network designs include millions of parameters, which makes it difficult to install such complex models on devices that have limited memory. Compression techniques might be able to resolve these issues by decreasing the size of CNN models that are created by reducing the number of parameters that contribute to the complexity of the models. We propose a compressed tensor format of convolutional layer, a priori, before the training of the neural network. 3-way kernels or 2-way kernels in convolutional layers are replaced by one-way fiters. The overfitting phenomena will be reduced also. The time needed to make predictions or time required for training using the original Convolutional Neural Networks model would be cut significantly if there were fewer parameters to deal with. In this paper we present a method of a priori compressing convolutional neural networks for finite element (FE) predictions of physical data. Afterwards we validate our a priori compressed models on physical data from a FE model solving a 2D wave equation. We show that the proposed convolutinal compression technique achieves equivalent performance as classical convolutional layers with fewer trainable parameters and lower memory footprint.
Time series quantile regression using random forests
Nov 04, 2022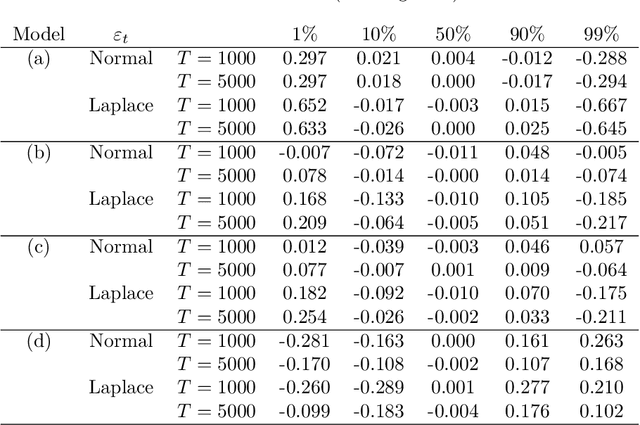
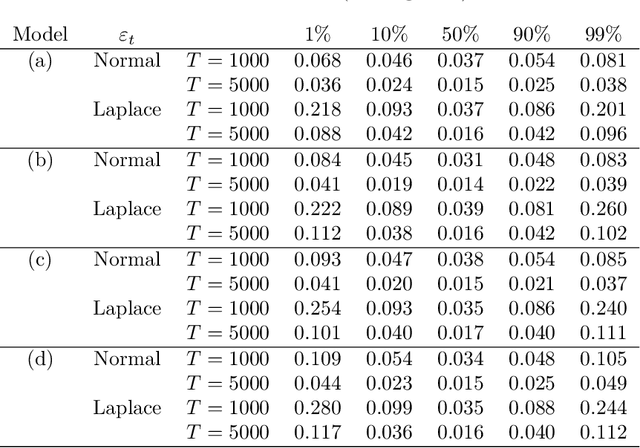
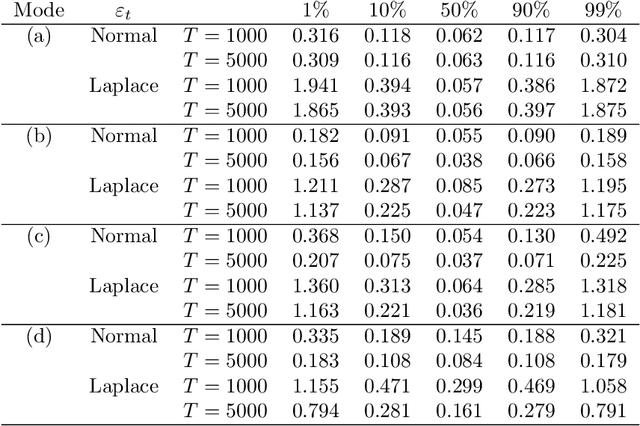
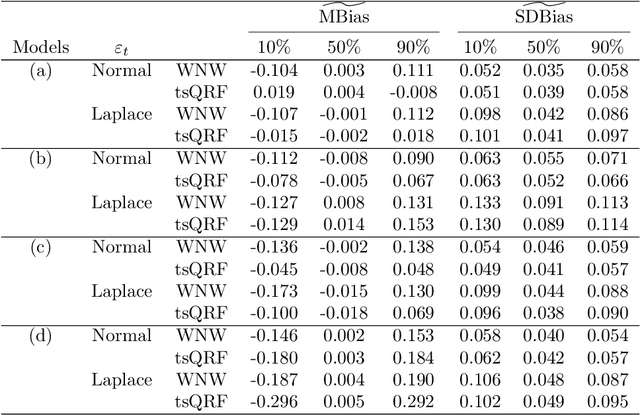
We discuss an application of Generalized Random Forests (GRF) proposed by Athey et al.(2019) to quantile regression for time series data. We extracted the theoretical results of the GRF consistency for i.i.d. data to time series data. In particular, in the main theorem, based only on the general assumptions for time series data in Davis and Nielsen (2020), and trees in Athey et al.(2019), we show that the tsQRF (time series Quantile Regression Forests) estimator is consistent. Davis and Nielsen (2020) also discussed the estimation problem using Random Forests (RF) for time series data, but the construction procedure of the RF treated by the GRF is essentially different, and different ideas are used throughout the theoretical proof. In addition, a simulation and real data analysis were conducted.In the simulation, the accuracy of the conditional quantile estimation was evaluated under time series models. In the real data using the Nikkei Stock Average, our estimator is demonstrated to be more sensitive than the others in terms of volatility, thus preventing underestimation of risk.