 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Representations of Sound for Automatic Insect Recognition
Apr 25, 2023
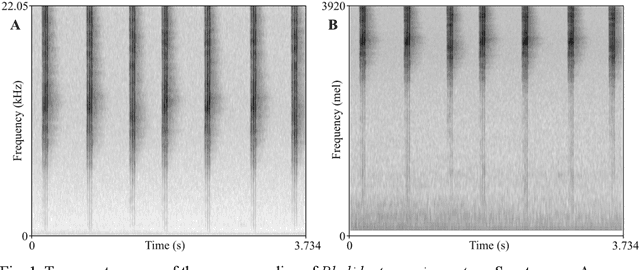
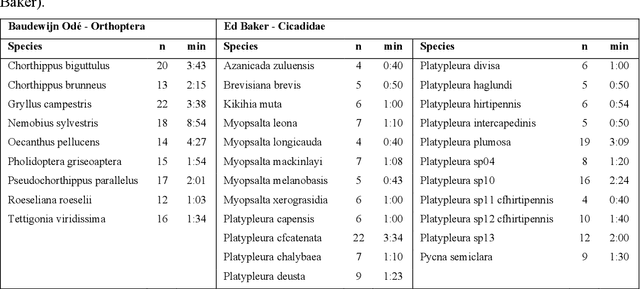
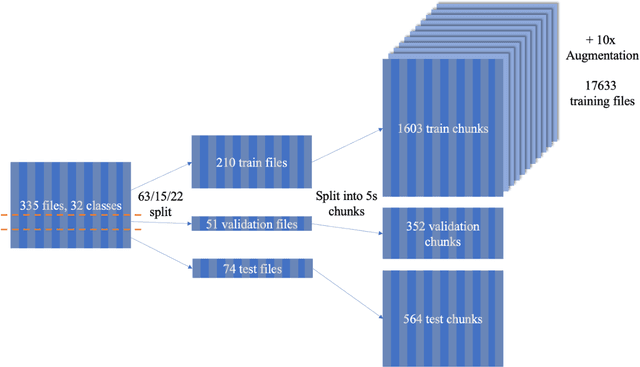
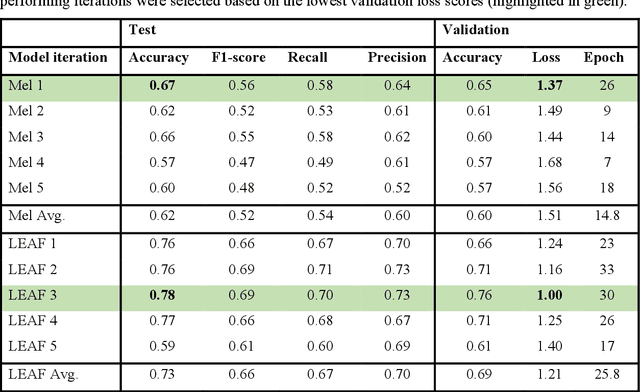
Insect population numbers and biodiversity have been rapidly declining with time, and monitoring these trends has become increasingly important for conservation measures to be effectively implemented. But monitoring methods are often invasive, time and resource intense, and prone to various biases. Many insect species produce characteristic sounds that can easily be detected and recorded without large cost or effort. Using deep learning methods, insect sounds from field recordings could be automatically detected and classified to monitor biodiversity and species distribution ranges. We implement this using recently published datasets of insect sounds (Orthoptera and Cicadidae) and machine learning methods and evaluate their potential for acoustic insect monitoring. We compare the performance of the conventional spectrogram-based audio representation against LEAF, a new adaptive and waveform-based frontend. LEAF achieved better classification performance than the mel-spectrogram frontend by adapting its feature extraction parameters during training. This result is encouraging for future implementations of deep learning technology for automatic insect sound recognition, especially as larger datasets become available.
X-TIME: An in-memory engine for accelerating machine learning on tabular data with CAMs
Apr 05, 2023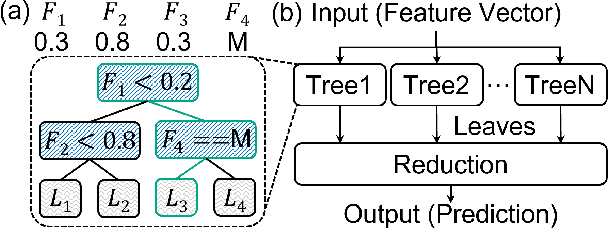
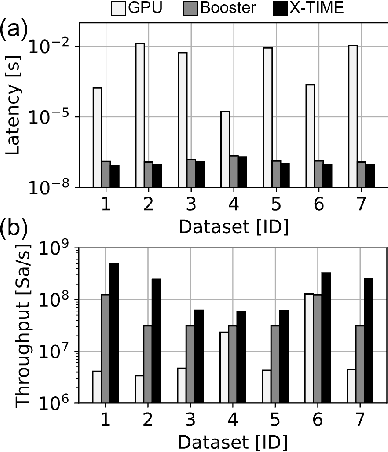
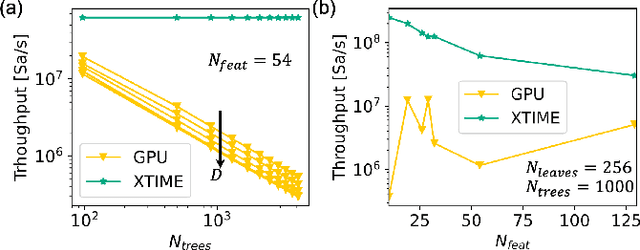
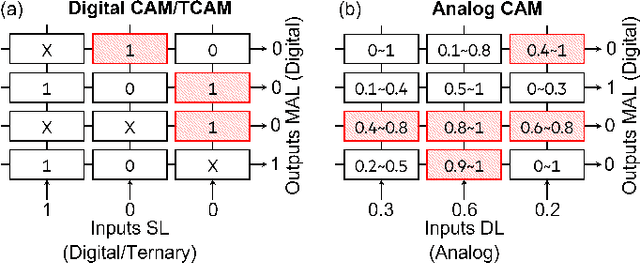
Structured, or tabular, data is the most common format in data science. While deep learning models have proven formidable in learning from unstructured data such as images or speech, they are less accurate than simpler approaches when learning from tabular data. In contrast, modern tree-based Machine Learning (ML) models shine in extracting relevant information from structured data. An essential requirement in data science is to reduce model inference latency in cases where, for example, models are used in a closed loop with simulation to accelerate scientific discovery. However, the hardware acceleration community has mostly focused on deep neural networks and largely ignored other forms of machine learning. Previous work has described the use of an analog content addressable memory (CAM) component for efficiently mapping random forests. In this work, we focus on an overall analog-digital architecture implementing a novel increased precision analog CAM and a programmable network on chip allowing the inference of state-of-the-art tree-based ML models, such as XGBoost and CatBoost. Results evaluated in a single chip at 16nm technology show 119x lower latency at 9740x higher throughput compared with a state-of-the-art GPU, with a 19W peak power consumption.
Combating Uncertainties in Wind and Distributed PV Energy Sources Using Integrated Reinforcement Learning and Time-Series Forecasting
Feb 27, 2023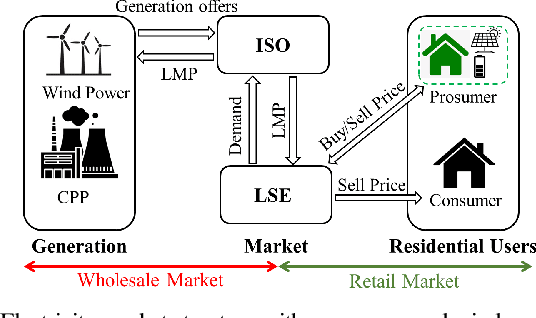
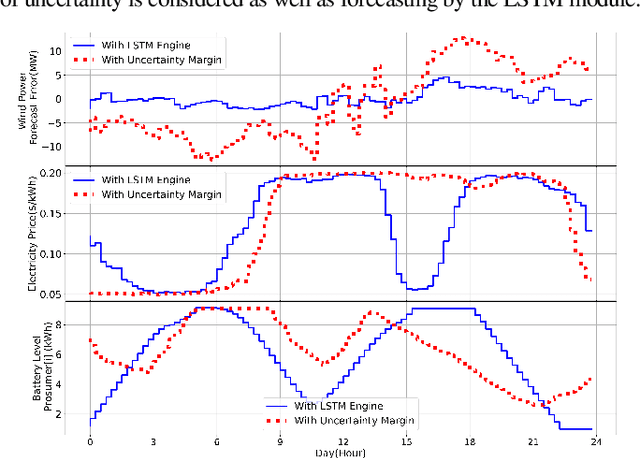
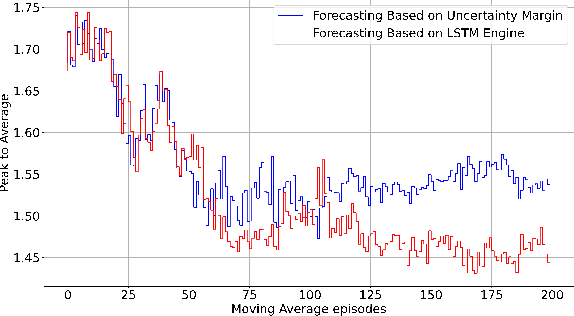
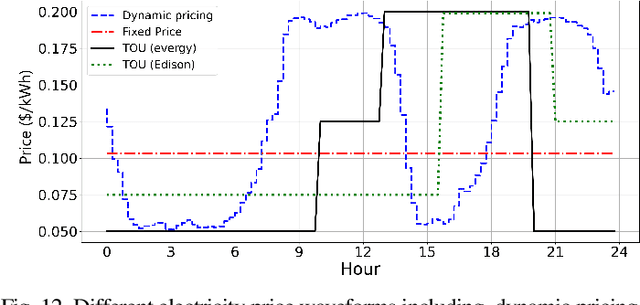
Renewable energy sources, such as wind and solar power, are increasingly being integrated into smart grid systems. However, when compared to traditional energy resources, the unpredictability of renewable energy generation poses significant challenges for both electricity providers and utility companies. Furthermore, the large-scale integration of distributed energy resources (such as PV systems) creates new challenges for energy management in microgrids. To tackle these issues, we propose a novel framework with two objectives: (i) combating uncertainty of renewable energy in smart grid by leveraging time-series forecasting with Long-Short Term Memory (LSTM) solutions, and (ii) establishing distributed and dynamic decision-making framework with multi-agent reinforcement learning using Deep Deterministic Policy Gradient (DDPG) algorithm. The proposed framework considers both objectives concurrently to fully integrate them, while considering both wholesale and retail markets, thereby enabling efficient energy management in the presence of uncertain and distributed renewable energy sources. Through extensive numerical simulations, we demonstrate that the proposed solution significantly improves the profit of load serving entities (LSE) by providing a more accurate wind generation forecast. Furthermore, our results demonstrate that households with PV and battery installations can increase their profits by using intelligent battery charge/discharge actions determined by the DDPG agents.
Obstacle-Transformer: A Trajectory Prediction Network Based on Surrounding Trajectories
Apr 16, 2023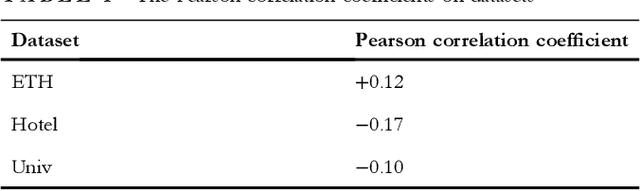
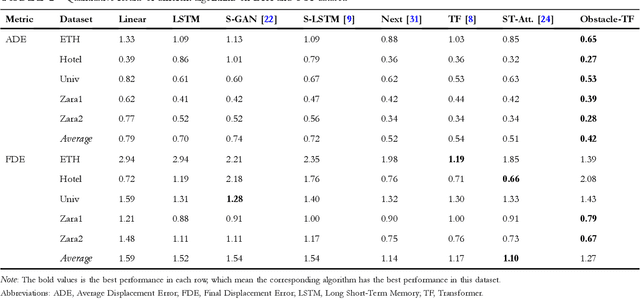
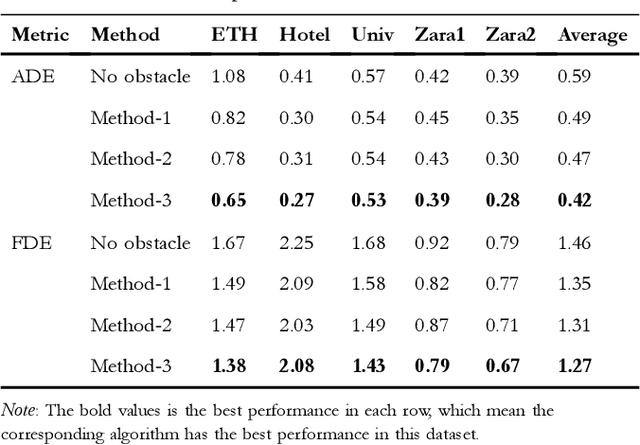
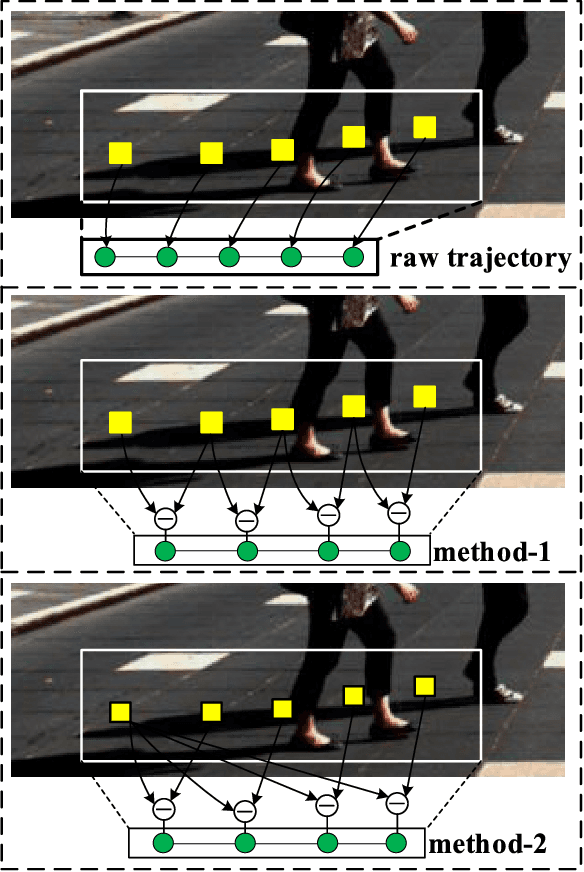
Recurrent Neural Network, Long Short-Term Memory, and Transformer have made great progress in predicting the trajectories of moving objects. Although the trajectory element with the surrounding scene features has been merged to improve performance, there still exist some problems to be solved. One is that the time series processing models will increase the inference time with the increase of the number of prediction sequences. Another lies in which the features can not be extracted from the scene's image and point cloud in some situations. Therefore, this paper proposes an Obstacle-Transformer to predict trajectory in a constant inference time. An ``obstacle'' is designed by the surrounding trajectory rather than images or point clouds, making Obstacle-Transformer more applicable in a wider range of scenarios. Experiments are conducted on ETH and UCY data sets to verify the performance of our model.
* 8 pages, 4 figures
Neural Network Representation of Time Integrators
Nov 30, 2022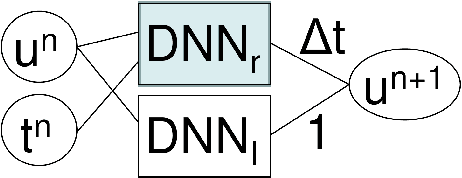
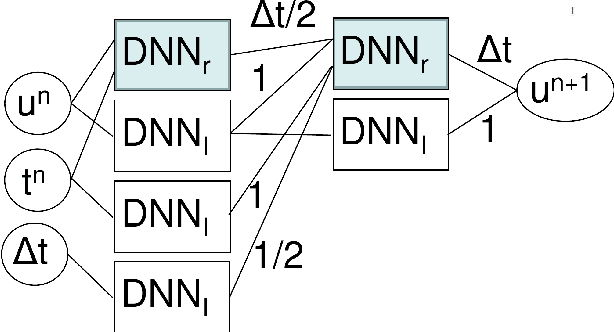
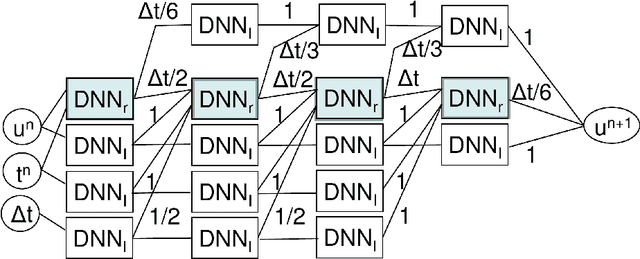
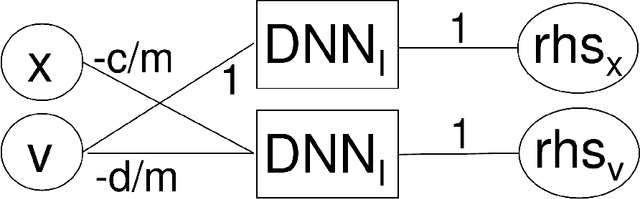
Deep neural network (DNN) architectures are constructed that are the exact equivalent of explicit Runge-Kutta schemes for numerical time integration. The network weights and biases are given, i.e., no training is needed. In this way, the only task left for physics-based integrators is the DNN approximation of the right-hand side. This allows to clearly delineate the approximation estimates for right-hand side errors and time integration errors. The architecture required for the integration of a simple mass-damper-stiffness case is included as an example.
The ACM Multimedia 2023 Computational Paralinguistics Challenge: Emotion Share & Requests
May 01, 2023
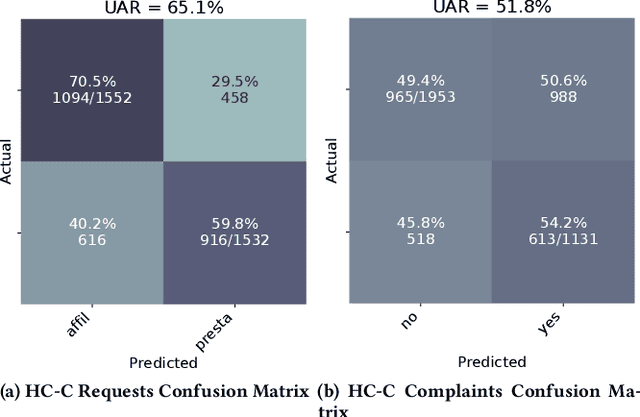
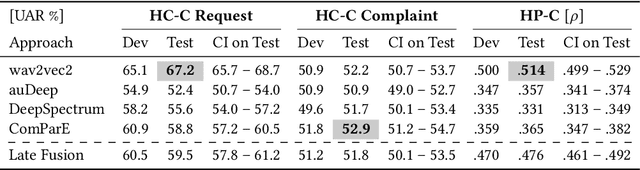
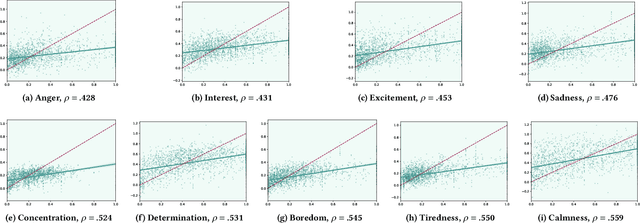
The ACM Multimedia 2023 Computational Paralinguistics Challenge addresses two different problems for the first time in a research competition under well-defined conditions: In the Emotion Share Sub-Challenge, a regression on speech has to be made; and in the Requests Sub-Challenges, requests and complaints need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, wav2vec2 models are used.
A Central Asian Food Dataset for Personalized Dietary Interventions, Extended Abstract
May 12, 2023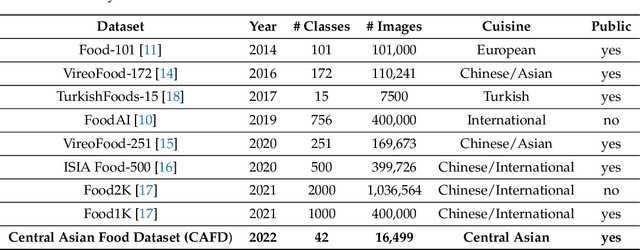

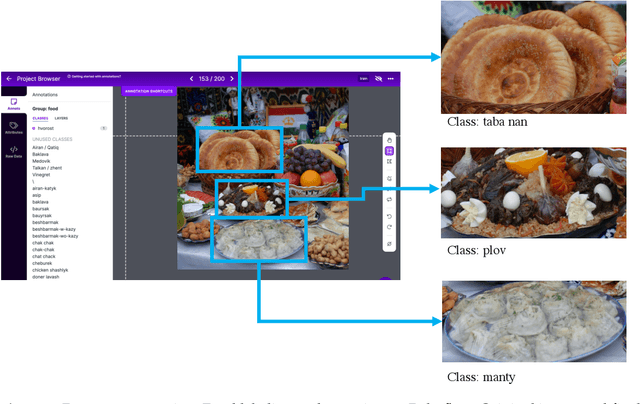

Nowadays, it is common for people to take photographs of every beverage, snack, or meal they eat and then post these photographs on social media platforms. Leveraging these social trends, real-time food recognition and reliable classification of these captured food images can potentially help replace some of the tedious recording and coding of food diaries to enable personalized dietary interventions. Although Central Asian cuisine is culturally and historically distinct, there has been little published data on the food and dietary habits of people in this region. To fill this gap, we aim to create a reliable dataset of regional foods that is easily accessible to both public consumers and researchers. To the best of our knowledge, this is the first work on creating a Central Asian Food Dataset (CAFD). The final dataset contains 42 food categories and over 16,000 images of national dishes unique to this region. We achieved a classification accuracy of 88.70\% (42 classes) on the CAFD using the ResNet152 neural network model. The food recognition models trained on the CAFD demonstrate computer vision's effectiveness and high accuracy for dietary assessment.
A transformer-based method for zero and few-shot biomedical named entity recognition
May 12, 2023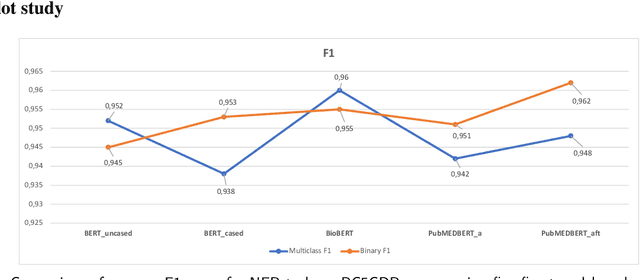
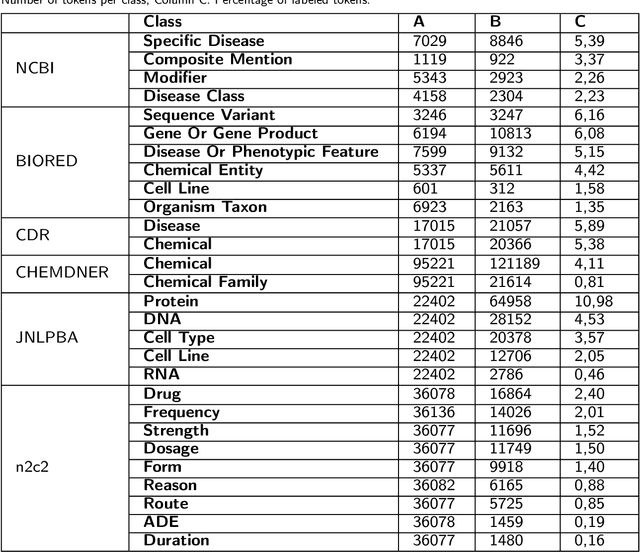

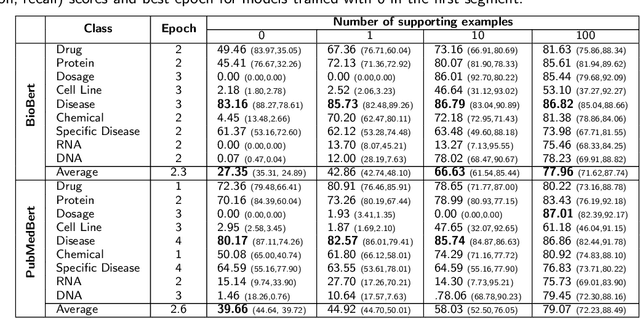
Supervised named entity recognition (NER) in the biomedical domain is dependent on large sets of annotated texts with the given named entities, whose creation can be time-consuming and expensive. Furthermore, the extraction of new entities often requires conducting additional annotation tasks and retraining the model. To address these challenges, this paper proposes a transformer-based method for zero- and few-shot NER in the biomedical domain. The method is based on transforming the task of multi-class token classification into binary token classification (token contains the searched entity or does not contain the searched entity) and pre-training on a larger amount of datasets and biomedical entities, from where the method can learn semantic relations between the given and potential classes. We have achieved average F1 scores of 35.44% for zero-shot NER, 50.10% for one-shot NER, 69.94% for 10-shot NER, and 79.51% for 100-shot NER on 9 diverse evaluated biomedical entities with PubMedBERT fine-tuned model. The results demonstrate the effectiveness of the proposed method for recognizing new entities with limited examples, with comparable or better results from the state-of-the-art zero- and few-shot NER methods.
An Efficient Plane Extraction Approach for Bundle Adjustment on LiDAR Point clouds
Apr 29, 2023
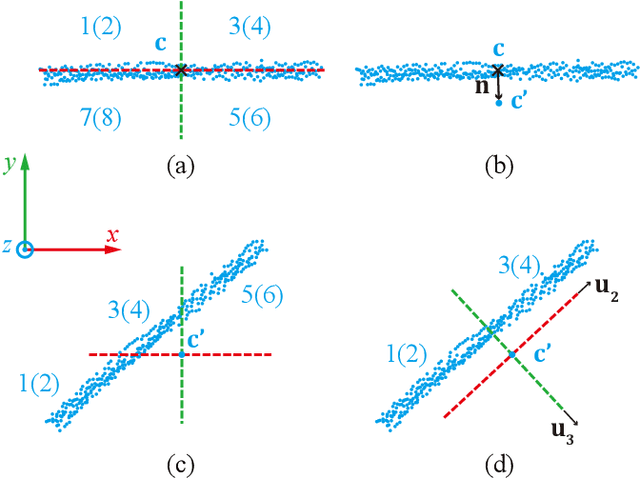
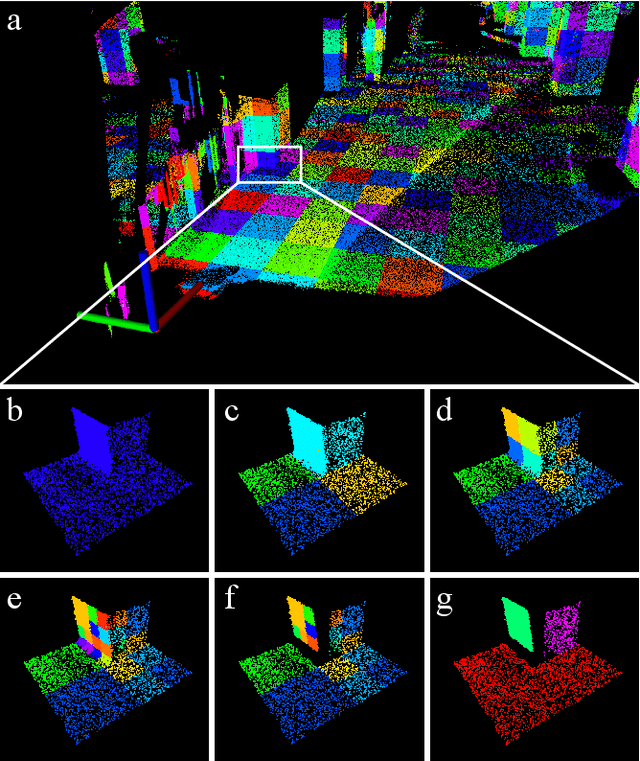

Bundle adjustment (BA) on LiDAR point clouds has been extensively investigated in recent years due to its ability to optimize multiple poses together, resulting in high accuracy and global consistency for point cloud. However, the accuracy and speed of LiDAR bundle adjustment depend on the quality of plane extraction, which provides point association for LiDAR BA. In this study, we propose a novel and efficient voxel-based approach for plane extraction that is specially designed to provide point association for LiDAR bundle adjustment. To begin, we partition the space into multiple voxels of a fixed size and then split these root voxels based on whether the points are on the same plane, using an octree structure. We also design a novel plane determination method based on principle component analysis (PCA), which segments the points into four even quarters and compare their minimum eigenvalues with that of the initial point cloud. Finally, we adopt a plane merging method to prevent too many small planes from being in a single voxel, which can increase the optimization time required for BA. Our experimental results on HILTI demonstrate that our approach achieves the best precision and least time cost compared to other plane extraction methods.
Leveraging Data Mining Algorithms to Recommend Source Code Changes
Apr 29, 2023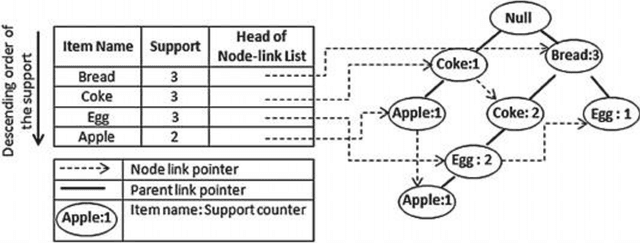
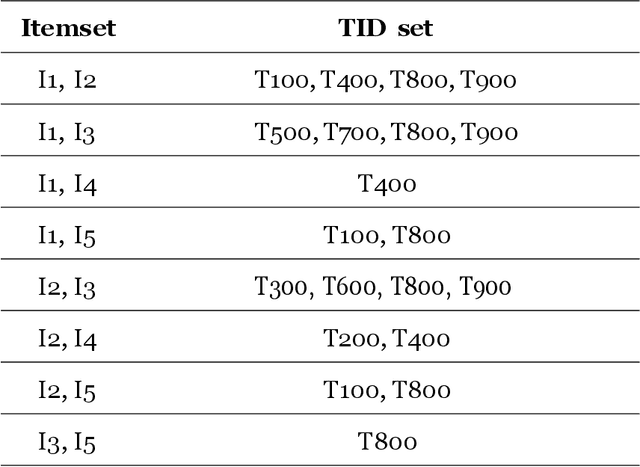
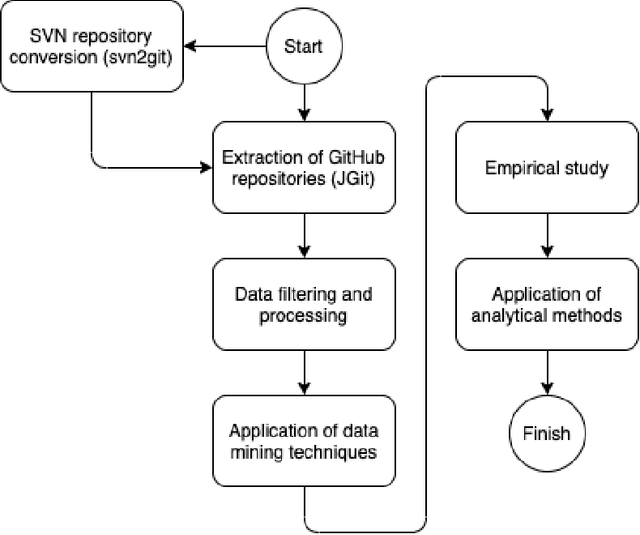

Context: Recent research has used data mining to develop techniques that can guide developers through source code changes. To the best of our knowledge, very few studies have investigated data mining techniques and--or compared their results with other algorithms or a baseline. Objectives: This paper proposes an automatic method for recommending source code changes using four data mining algorithms. We not only use these algorithms to recommend source code changes, but we also conduct an empirical evaluation. Methods: Our investigation includes seven open-source projects from which we extracted source change history at the file level. We used four widely data mining algorithms \ie{} Apriori, FP-Growth, Eclat, and Relim to compare the algorithms in terms of performance (Precision, Recall and F-measure) and execution time. Results: Our findings provide empirical evidence that while some Frequent Pattern Mining algorithms, such as Apriori may outperform other algorithms in some cases, the results are not consistent throughout all the software projects, which is more likely due to the nature and characteristics of the studied projects, in particular their change history. Conclusion: Apriori seems appropriate for large-scale projects, whereas Eclat appears to be suitable for small-scale projects. Moreover, FP-Growth seems an efficient approach in terms of execution time.