 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Deep Learning for Abstractive Code Summarization of Unofficial Documentation
Nov 07, 2023



Usually, programming languages have official documentation to guide developers with APIs, methods, and classes. However, researchers identified insufficient or inadequate documentation examples and flaws with the API's complex structure as barriers to learning an API. As a result, developers may consult other sources (StackOverflow, GitHub, etc.) to learn more about an API. Recent research studies have shown that unofficial documentation is a valuable source of information for generating code summaries. We, therefore, have been motivated to leverage such a type of documentation along with deep learning techniques towards generating high-quality summaries for APIs discussed in informal documentation. This paper proposes an automatic approach using the BART algorithm, a state-of-the-art transformer model, to generate summaries for APIs discussed in StackOverflow. We built an oracle of human-generated summaries to evaluate our approach against it using ROUGE and BLEU metrics which are the most widely used evaluation metrics in text summarization. Furthermore, we evaluated our summaries empirically against a previous work in terms of quality. Our findings demonstrate that using deep learning algorithms can improve summaries' quality and outperform the previous work by an average of %57 for Precision, %66 for Recall, and %61 for F-measure, and it runs 4.4 times faster.
Improving Code Example Recommendations on Informal Documentation Using BERT and Query-Aware LSH: A Comparative Study
May 04, 2023The study of code example recommendation has been conducted extensively in the past and recently in order to assist developers in their software development tasks. This is because developers often spend significant time searching for relevant code examples on the internet, utilizing open-source projects and informal documentation. For finding useful code examples, informal documentation, such as Stack Overflow discussions and forums, can be invaluable. We have focused our research on Stack Overflow, which is a popular resource for discussing different topics among software developers. For increasing the quality of the recommended code examples, we have collected and recommended the best code examples in the Java programming language. We have utilized BERT in our approach, which is a Large Language Model (LLM) for text representation that can effectively extract semantic information from textual data. Our first step involved using BERT to convert code examples into numerical vectors. Subsequently, we applied LSH to identify Approximate Nearest Neighbors (ANN). Our research involved the implementation of two variants of this approach, namely the Random Hyperplane-based LSH and the Query-Aware LSH. Our study compared two algorithms using four parameters: HitRate, Mean Reciprocal Rank (MRR), Average Execution Time, and Relevance. The results of our analysis revealed that the Query- Aware (QA) approach outperformed the Random Hyperplane-based (RH) approach in terms of HitRate. Specifically, the QA approach achieved a HitRate improvement of 20% to 35% for query pairs compared to the RH approach. Creating hashing tables and assigning data samples to buckets using the QA approach is at least four times faster than the RH approach. The QA approach returns code examples within milliseconds, while it takes several seconds (sec) for the RH approach to recommend code examples.
Leveraging Data Mining Algorithms to Recommend Source Code Changes
Apr 29, 2023Context: Recent research has used data mining to develop techniques that can guide developers through source code changes. To the best of our knowledge, very few studies have investigated data mining techniques and--or compared their results with other algorithms or a baseline. Objectives: This paper proposes an automatic method for recommending source code changes using four data mining algorithms. We not only use these algorithms to recommend source code changes, but we also conduct an empirical evaluation. Methods: Our investigation includes seven open-source projects from which we extracted source change history at the file level. We used four widely data mining algorithms \ie{} Apriori, FP-Growth, Eclat, and Relim to compare the algorithms in terms of performance (Precision, Recall and F-measure) and execution time. Results: Our findings provide empirical evidence that while some Frequent Pattern Mining algorithms, such as Apriori may outperform other algorithms in some cases, the results are not consistent throughout all the software projects, which is more likely due to the nature and characteristics of the studied projects, in particular their change history. Conclusion: Apriori seems appropriate for large-scale projects, whereas Eclat appears to be suitable for small-scale projects. Moreover, FP-Growth seems an efficient approach in terms of execution time.
Leveraging Unsupervised Learning to Summarize APIs Discussed in Stack Overflow
Nov 27, 2021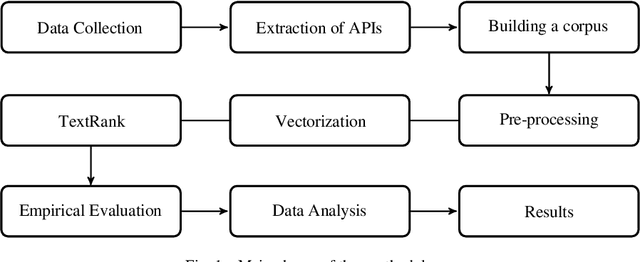
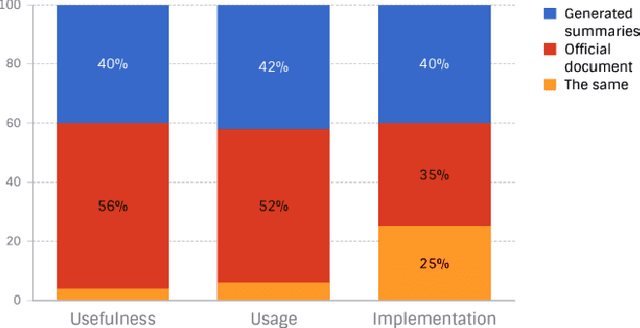
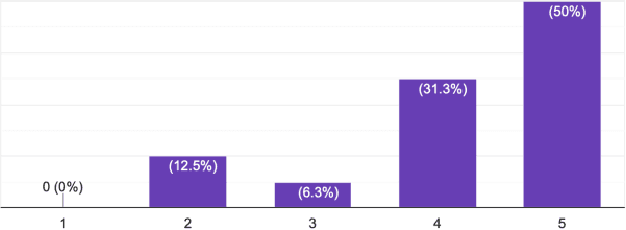
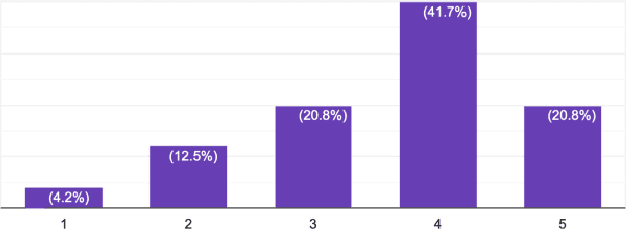
Automated source code summarization is a task that generates summarized information about the purpose, usage, and--or implementation of methods and classes to support understanding of these code entities. Multiple approaches and techniques have been proposed for supervised and unsupervised learning in code summarization, however, they were mostly focused on generating a summary for a piece of code. In addition, very few works have leveraged unofficial documentation. This paper proposes an automatic and novel approach for summarizing Android API methods discussed in Stack Overflow that we consider as unofficial documentation in this research. Our approach takes the API method's name as an input and generates a natural language summary based on Stack Overflow discussions of that API method. We have conducted a survey that involves 16 Android developers to evaluate the quality of our automatically generated summaries and compare them with the official Android documentation. Our results demonstrate that while developers find the official documentation more useful in general, the generated summaries are also competitive, in particular for offering implementation details, and can be used as a complementary source for guiding developers in software development and maintenance tasks.