 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MaskCL: Semantic Mask-Driven Contrastive Learning for Unsupervised Person Re-Identification with Clothes Change
May 23, 2023
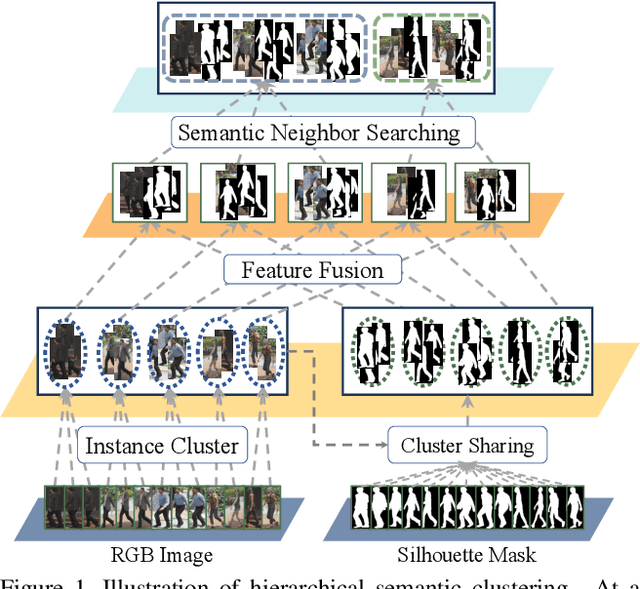
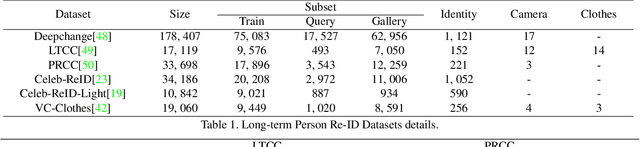

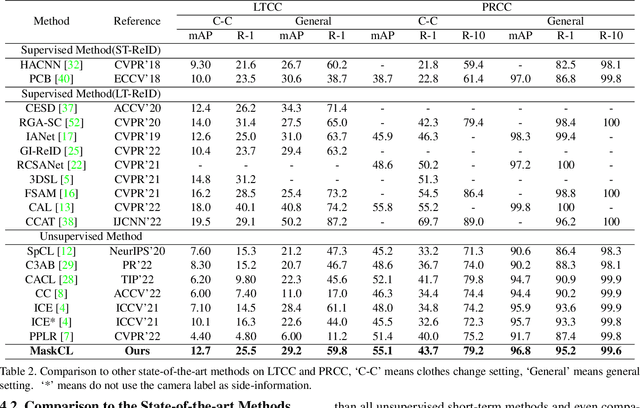
This paper considers a novel and challenging problem: unsupervised long-term person re-identification with clothes change. Unfortunately, conventional unsupervised person re-id methods are designed for short-term cases and thus fail to perceive clothes-independent patterns due to simply being driven by RGB prompt. To tackle with such a bottleneck, we propose a semantic mask-driven contrastive learning approach, in which silhouette masks are embedded into contrastive learning framework as the semantic prompts and cross-clothes invariance is learnt from hierarchically semantic neighbor structure by combining both RGB and semantic features in a two-branches network. Since such a challenging re-id task setting is investigated for the first time, we conducted extensive experiments to evaluate state-of-the-art unsupervised short-term person re-id methods on five widely-used clothes-change re-id datasets. Experimental results verify that our approach outperforms the unsupervised re-id competitors by a clear margin, remaining a narrow gap to the supervised baselines.
Identifying Time Lag in Dynamical Systems with Copula Entropy based Transfer Entropy
Jan 15, 2023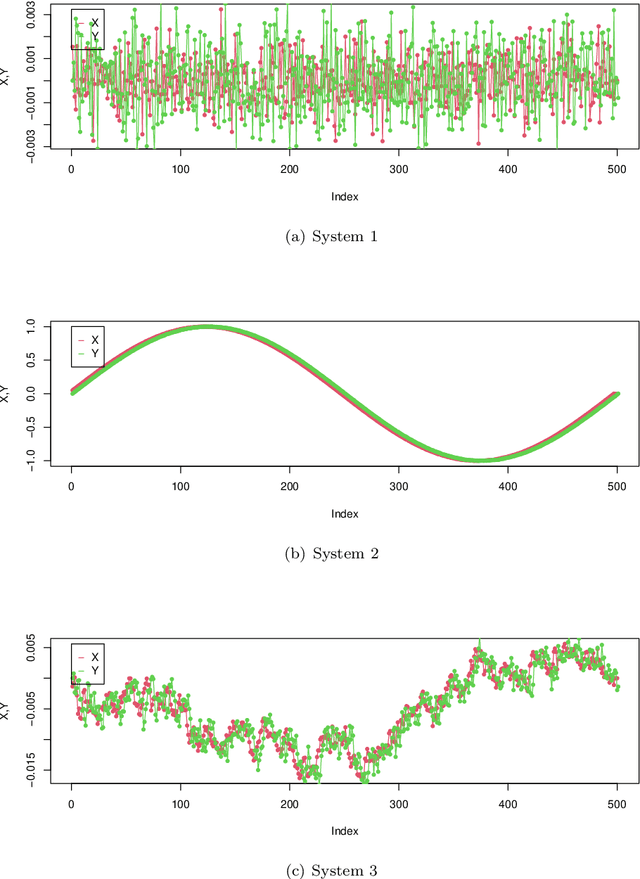
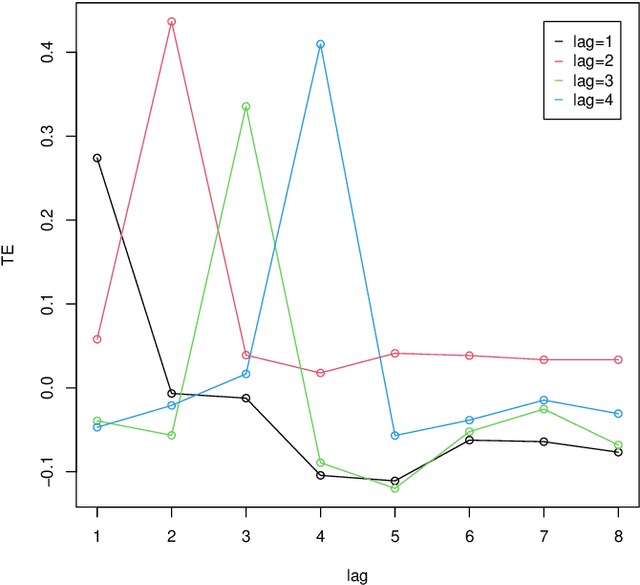
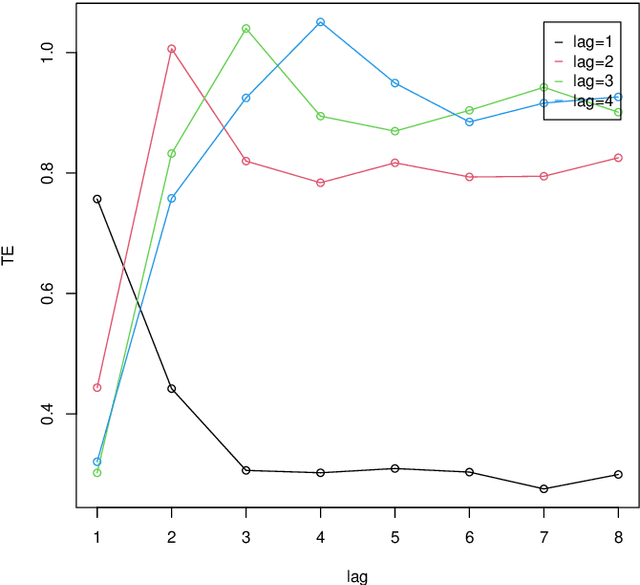
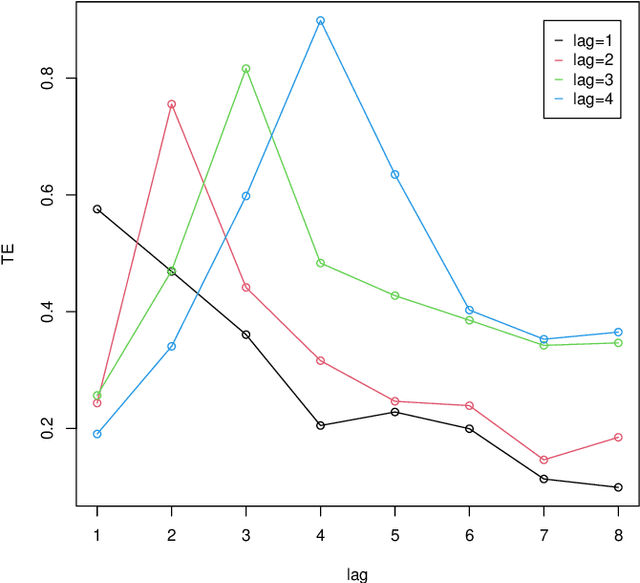
Time lag between variables is a key characteristics of dynamical systems in different fields and identifying such time lag is a central problem in complex systems with many applications. Transfer Entropy (TE) was proposed as a tool for time lag identification recently. Unfortunately, estimating TE has been a notoriously difficult problem. Copula Entropy (CE) is a measure of statistical independence and it was proved that TE can be represented with only CE. Therefore, a non-parametric estimator of TE based on CE was proposed according to such representation recently. In this paper we propose to use the CE-based estimator of TE to identify time lag in dynamical systems. Both simulated and real data are used to verify the effectiveness of the proposed method in the experiments. Experimental results show that the proposed method can identify the time lags in the three simulated systems. The real data experiment with the data on power consumption of the Tetouan city also demonstrates that our method can identify the pattern of time lags through the estimated TE from the weather factors to the power consumption of the city.
A method for analyzing sampling jitter in audio equipment
May 08, 2023A method for analyzing sampling jitter in audio equipment is proposed. The method is based on the time-domain analysis where the time fluctuations of zero-crossing points in recorded sinusoidal waves are employed to characterize jitter. This method enables the separate evaluation of jitter in an audio player from those in audio recorders when the same playback signal is simultaneously fed into two audio recorders. Experiments are conducted using commercially available portable devices with a maximum sampling rate of 192~000 samples per second. The results show jitter values of a few tens of picoseconds can be identified in an audio player. Moreover, the proposed method enables the separation of jitter from phase-independent noise utilizing the left and right channels of the audio equipment. As such, this method is applicable for performance evaluation of audio equipment, signal generators, and clock sources.
Explanations as Features: LLM-Based Features for Text-Attributed Graphs
May 31, 2023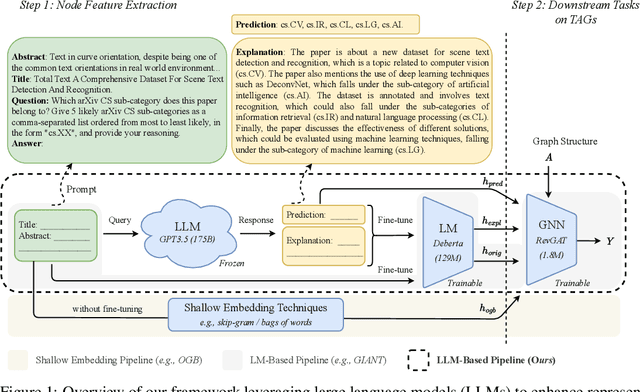
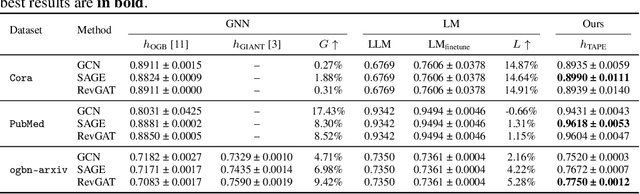
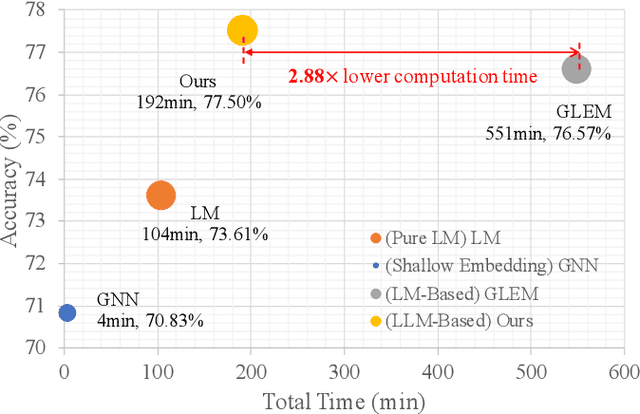
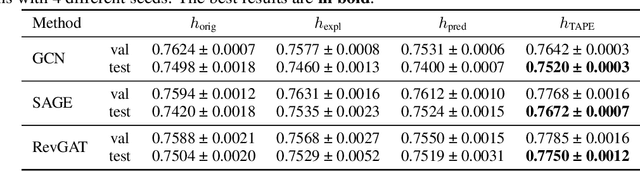
Representation learning on text-attributed graphs (TAGs) has become a critical research problem in recent years. A typical example of a TAG is a paper citation graph, where the text of each paper serves as node attributes. Most graph neural network (GNN) pipelines handle these text attributes by transforming them into shallow or hand-crafted features, such as skip-gram or bag-of-words features. Recent efforts have focused on enhancing these pipelines with language models. With the advent of powerful large language models (LLMs) such as GPT, which demonstrate an ability to reason and to utilize general knowledge, there is a growing need for techniques which combine the textual modelling abilities of LLMs with the structural learning capabilities of GNNs. Hence, in this work, we focus on leveraging LLMs to capture textual information as features, which can be used to boost GNN performance on downstream tasks. A key innovation is our use of \emph{explanations as features}: we prompt an LLM to perform zero-shot classification and to provide textual explanations for its decisions, and find that the resulting explanations can be transformed into useful and informative features to augment downstream GNNs. Through experiments we show that our enriched features improve the performance of a variety of GNN models across different datasets. Notably, we achieve top-1 performance on \texttt{ogbn-arxiv} by a significant margin over the closest baseline even with $2.88\times$ lower computation time, as well as top-1 performance on TAG versions of the widely used \texttt{PubMed} and \texttt{Cora} benchmarks~\footnote{Our codes and datasets are available at: \url{https://github.com/XiaoxinHe/TAPE}}.
Ambiguity in solving imaging inverse problems with deep learning based operators
May 31, 2023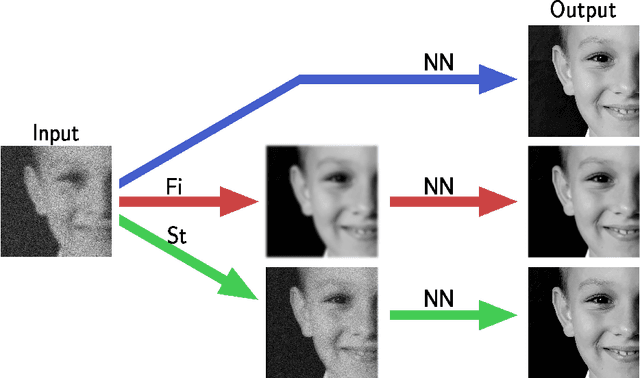
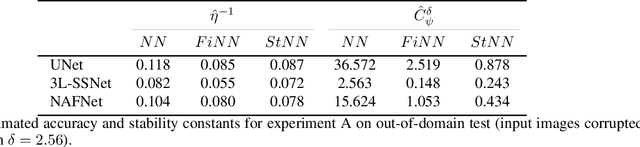
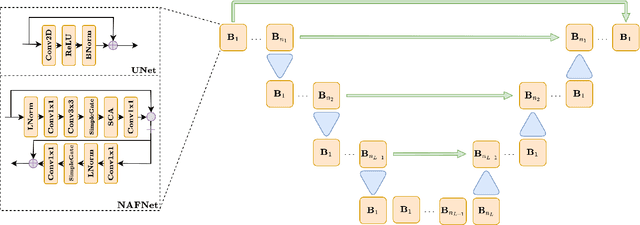

In recent years, large convolutional neural networks have been widely used as tools for image deblurring, because of their ability in restoring images very precisely. It is well known that image deblurring is mathematically modeled as an ill-posed inverse problem and its solution is difficult to approximate when noise affects the data. Really, one limitation of neural networks for deblurring is their sensitivity to noise and other perturbations, which can lead to instability and produce poor reconstructions. In addition, networks do not necessarily take into account the numerical formulation of the underlying imaging problem, when trained end-to-end. In this paper, we propose some strategies to improve stability without losing to much accuracy to deblur images with deep-learning based methods. First, we suggest a very small neural architecture, which reduces the execution time for training, satisfying a green AI need, and does not extremely amplify noise in the computed image. Second, we introduce a unified framework where a pre-processing step balances the lack of stability of the following, neural network-based, step. Two different pre-processors are presented: the former implements a strong parameter-free denoiser, and the latter is a variational model-based regularized formulation of the latent imaging problem. This framework is also formally characterized by mathematical analysis. Numerical experiments are performed to verify the accuracy and stability of the proposed approaches for image deblurring when unknown or not-quantified noise is present; the results confirm that they improve the network stability with respect to noise. In particular, the model-based framework represents the most reliable trade-off between visual precision and robustness.
Efficient PDE-Constrained optimization under high-dimensional uncertainty using derivative-informed neural operators
May 31, 2023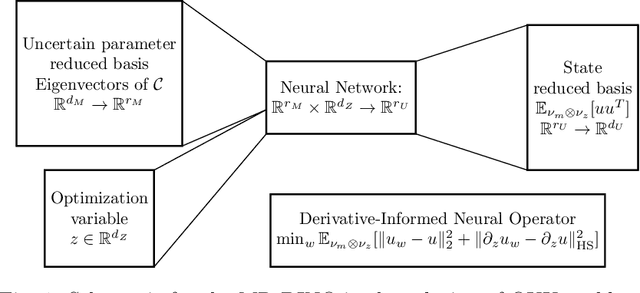

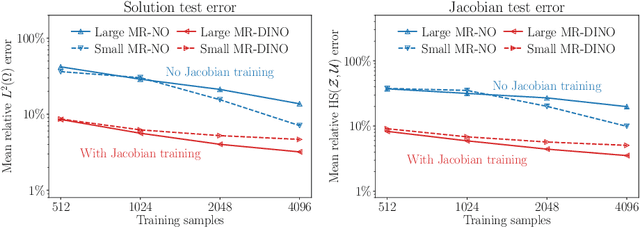
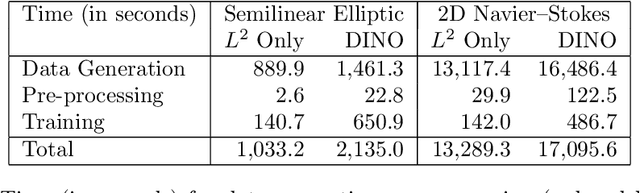
We propose a novel machine learning framework for solving optimization problems governed by large-scale partial differential equations (PDEs) with high-dimensional random parameters. Such optimization under uncertainty (OUU) problems may be computational prohibitive using classical methods, particularly when a large number of samples is needed to evaluate risk measures at every iteration of an optimization algorithm, where each sample requires the solution of an expensive-to-solve PDE. To address this challenge, we propose a new neural operator approximation of the PDE solution operator that has the combined merits of (1) accurate approximation of not only the map from the joint inputs of random parameters and optimization variables to the PDE state, but also its derivative with respect to the optimization variables, (2) efficient construction of the neural network using reduced basis architectures that are scalable to high-dimensional OUU problems, and (3) requiring only a limited number of training data to achieve high accuracy for both the PDE solution and the OUU solution. We refer to such neural operators as multi-input reduced basis derivative informed neural operators (MR-DINOs). We demonstrate the accuracy and efficiency our approach through several numerical experiments, i.e. the risk-averse control of a semilinear elliptic PDE and the steady state Navier--Stokes equations in two and three spatial dimensions, each involving random field inputs. Across the examples, MR-DINOs offer $10^{3}$--$10^{7} \times$ reductions in execution time, and are able to produce OUU solutions of comparable accuracies to those from standard PDE based solutions while being over $10 \times$ more cost-efficient after factoring in the cost of construction.
Consensus-based Networked Tracking in Presence of Heterogeneous Time-Delays
Feb 15, 2023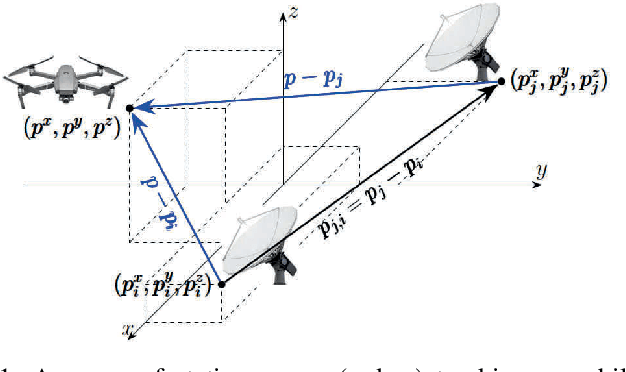
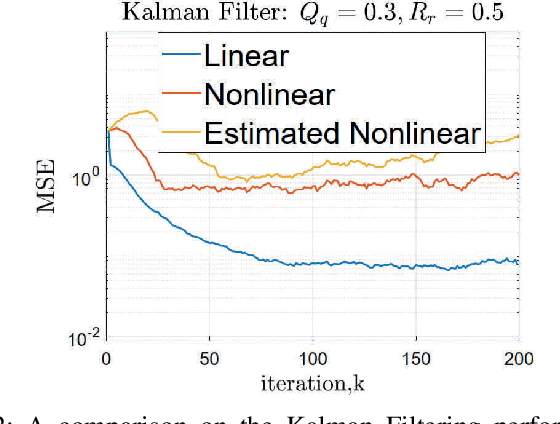
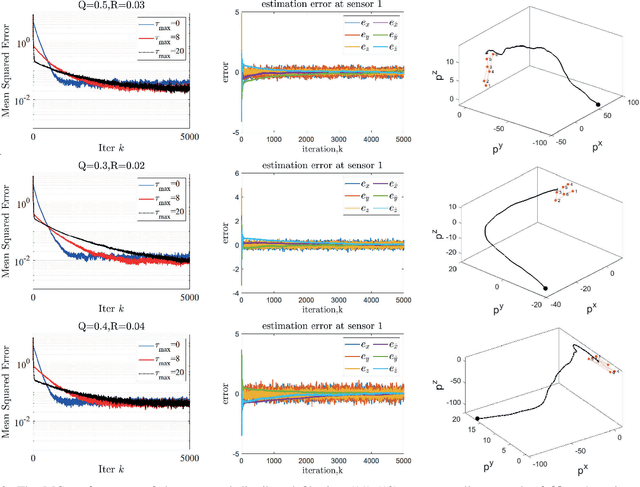
We propose a distributed (single) target tracking scheme based on networked estimation and consensus algorithms over static sensor networks. The tracking part is based on linear time-difference-of-arrival (TDOA) measurement proposed in our previous works. This paper, in particular, develops delay-tolerant distributed filtering solutions over sparse data-transmission networks. We assume general arbitrary heterogeneous delays at different links. This may occur in many realistic large-scale applications where the data-sharing between different nodes is subject to latency due to communication-resource constraints or large spatially distributed sensor networks. The solution we propose in this work shows improved performance (verified by both theory and simulations) in such scenarios. Another privilege of such distributed schemes is the possibility to add localized fault-detection and isolation (FDI) strategies along with survivable graph-theoretic design, which opens many follow-up venues to this research. To our best knowledge no such delay-tolerant distributed linear algorithm is given in the existing distributed tracking literature.
Early Classifying Multimodal Sequences
May 02, 2023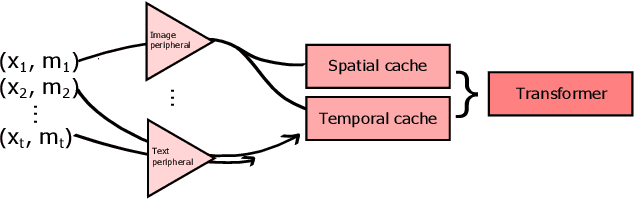
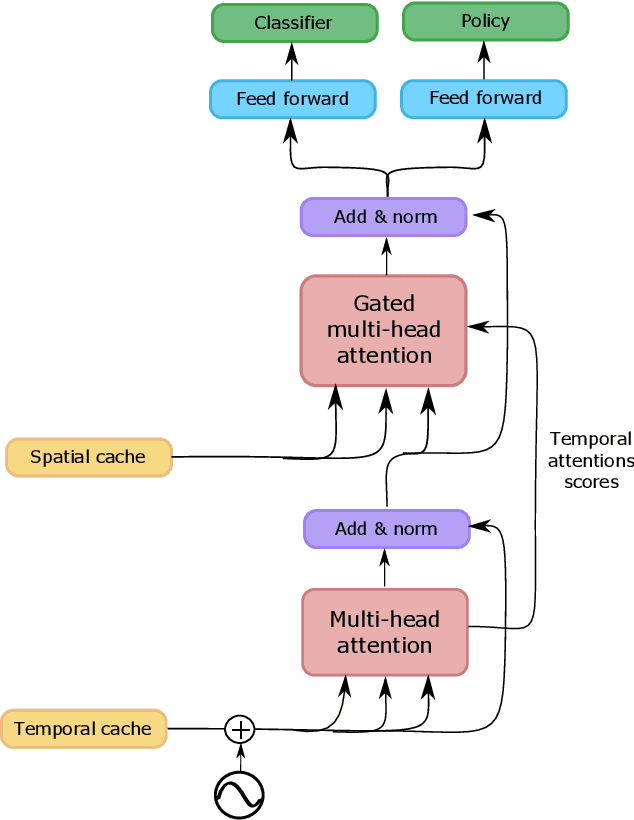
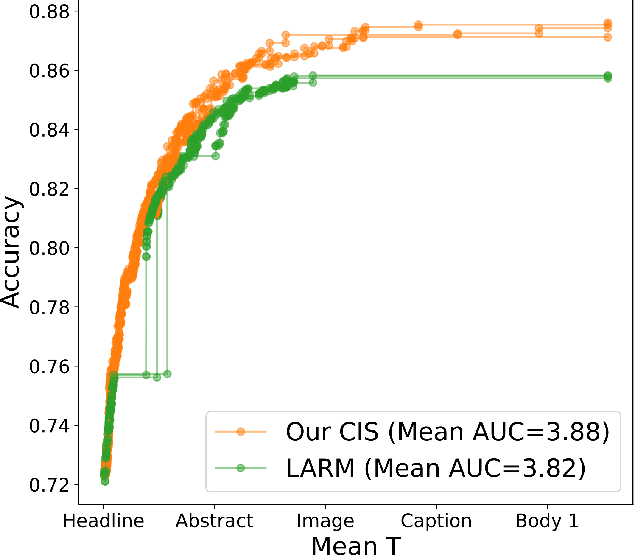
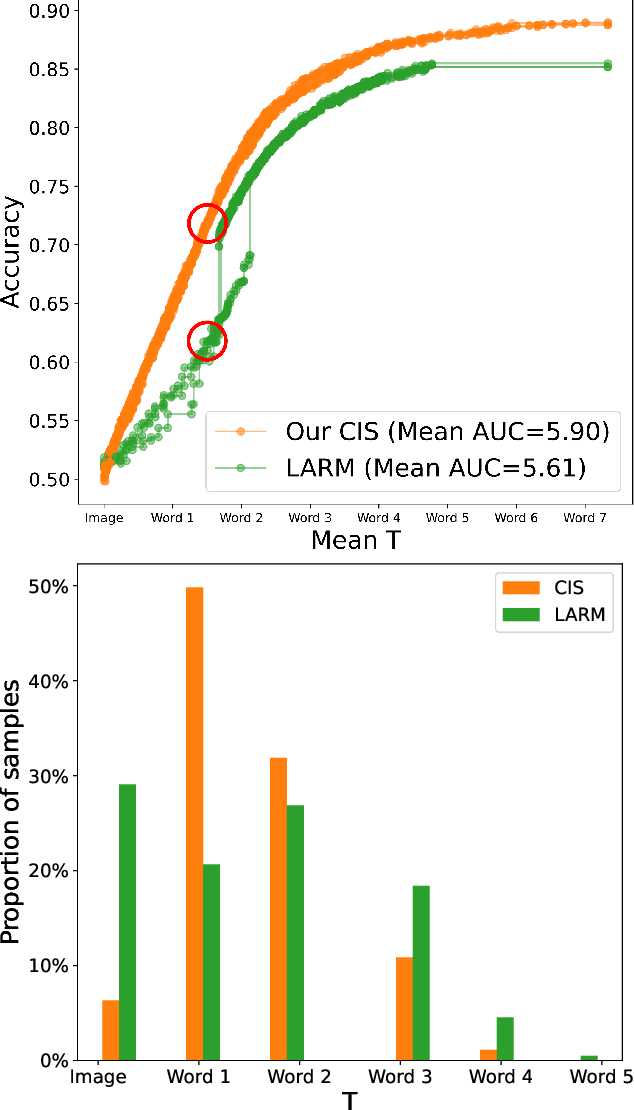
Often pieces of information are received sequentially over time. When did one collect enough such pieces to classify? Trading wait time for decision certainty leads to early classification problems that have recently gained attention as a means of adapting classification to more dynamic environments. However, so far results have been limited to unimodal sequences. In this pilot study, we expand into early classifying multimodal sequences by combining existing methods. We show our new method yields experimental AUC advantages of up to 8.7%.
Counter-Hypothetical Particle Filters for Single Object Pose Tracking
May 28, 2023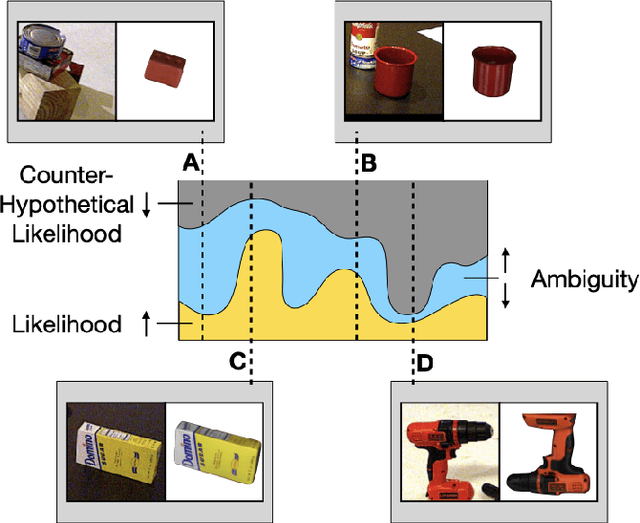
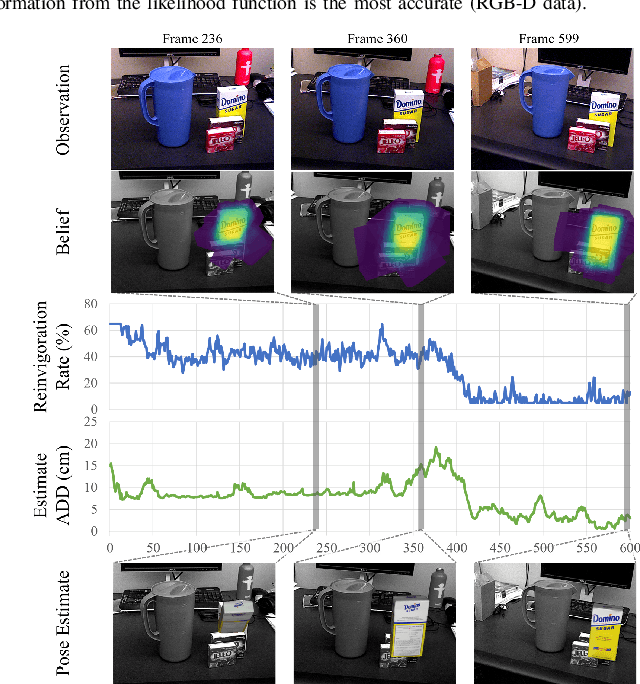
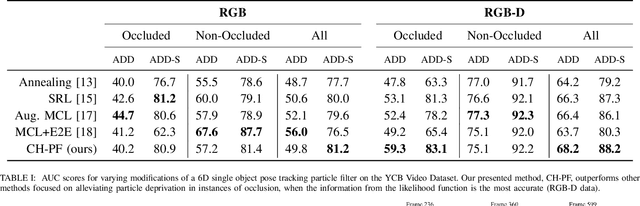
Particle filtering is a common technique for six degree of freedom (6D) pose estimation due to its ability to tractably represent belief over object pose. However, the particle filter is prone to particle deprivation due to the high-dimensional nature of 6D pose. When particle deprivation occurs, it can cause mode collapse of the underlying belief distribution during importance sampling. If the region surrounding the true state suffers from mode collapse, recovering its belief is challenging since the area is no longer represented in the probability mass formed by the particles. Previous methods mitigate this problem by randomizing and resetting particles in the belief distribution, but determining the frequency of reinvigoration has relied on hand-tuning abstract heuristics. In this paper, we estimate the necessary reinvigoration rate at each time step by introducing a Counter-Hypothetical likelihood function, which is used alongside the standard likelihood. Inspired by the notions of plausibility and implausibility from Evidential Reasoning, the addition of our Counter-Hypothetical likelihood function assigns a level of doubt to each particle. The competing cumulative values of confidence and doubt across the particle set are used to estimate the level of failure within the filter, in order to determine the portion of particles to be reinvigorated. We demonstrate the effectiveness of our method on the rigid body object 6D pose tracking task.
Minimally Invasive Live Tissue High-fidelity Thermophysical Modeling using Real-time Thermography
Jan 23, 2023

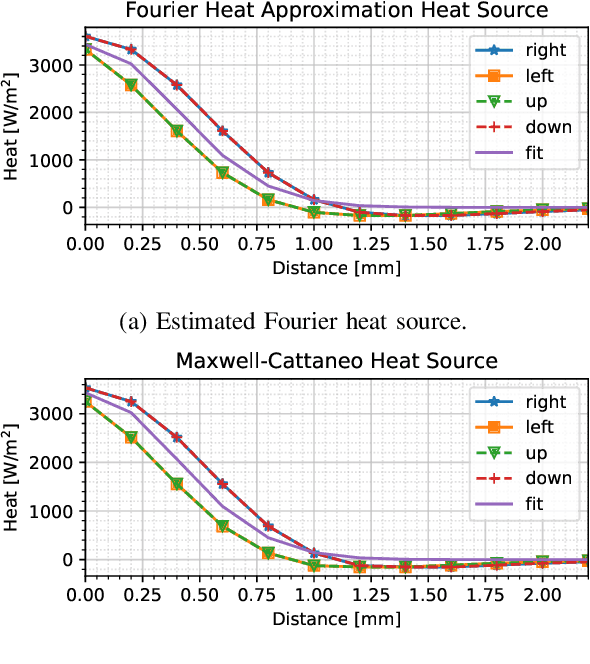
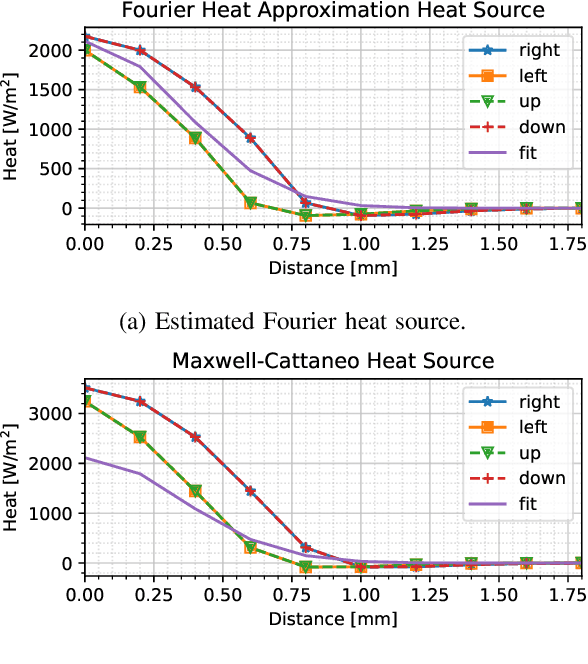
We present a novel thermodynamic parameter estimation framework for energy-based surgery on live tissue, with direct applications to tissue characterization during electrosurgery. This framework addresses the problem of estimating tissue-specific thermodynamics in real-time, which would enable accurate prediction of thermal damage impact to the tissue and damage-conscious planning of electrosurgical procedures. Our approach provides basic thermodynamic information such as thermal diffusivity, and also allows for obtaining the thermal relaxation time and a model of the heat source, yielding in real-time a controlled hyperbolic thermodynamics model. The latter accounts for the finite thermal propagation time necessary for modeling of the electrosurgical action, in which the probe motion speed often surpasses the speed of thermal propagation in the tissue operated on. Our approach relies solely on thermographer feedback and a knowledge of the power level and position of the electrosurgical pencil, imposing only very minor adjustments to normal electrosurgery to obtain a high-fidelity model of the tissue-probe interaction. Our method is minimally invasive and can be performed in situ. We apply our method first to simulated data based on porcine muscle tissue to verify its accuracy and then to in vivo liver tissue, and compare the results with those from the literature. This comparison shows that parameterizing the Maxwell--Cattaneo model through the framework proposed yields a noticeably higher fidelity real-time adaptable representation of the thermodynamic tissue response to the electrosurgical impact than currently available. A discussion on the differences between the live and the dead tissue thermodynamics is also provided.