 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Loss is All You Need to Recover Analogies as Parallel Lines
Jun 14, 2023
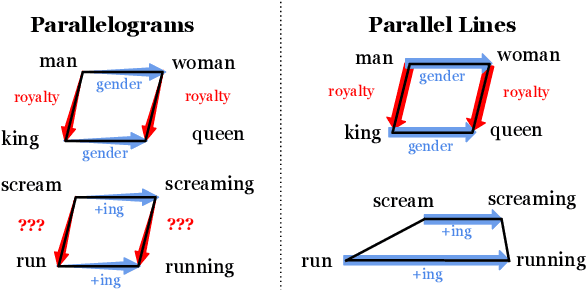
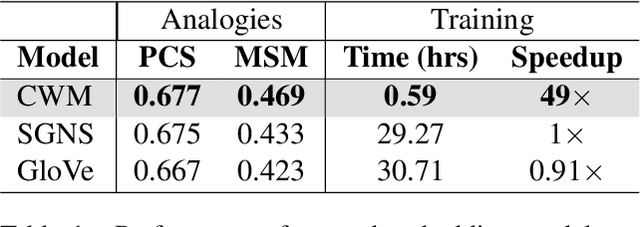

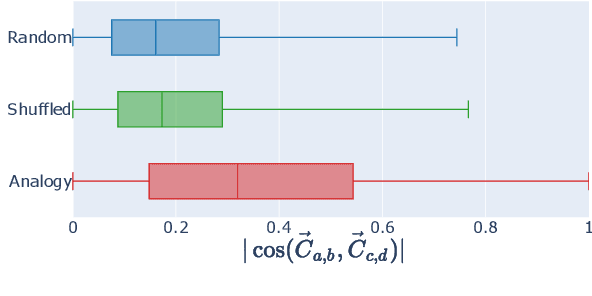
While static word embedding models are known to represent linguistic analogies as parallel lines in high-dimensional space, the underlying mechanism as to why they result in such geometric structures remains obscure. We find that an elementary contrastive-style method employed over distributional information performs competitively with popular word embedding models on analogy recovery tasks, while achieving dramatic speedups in training time. Further, we demonstrate that a contrastive loss is sufficient to create these parallel structures in word embeddings, and establish a precise relationship between the co-occurrence statistics and the geometric structure of the resulting word embeddings.
3D VR Sketch Guided 3D Shape Prototyping and Exploration
Jun 23, 2023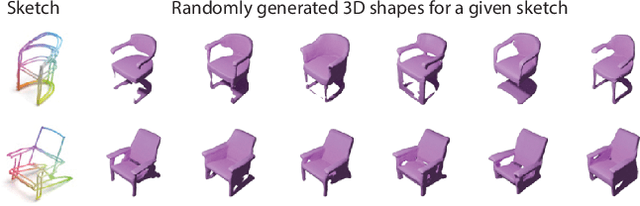
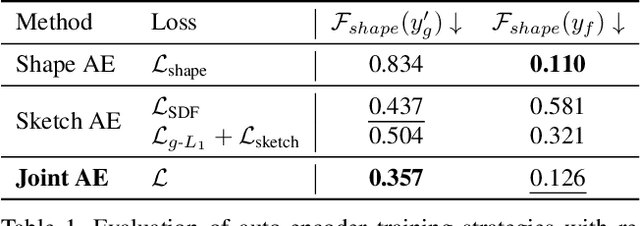
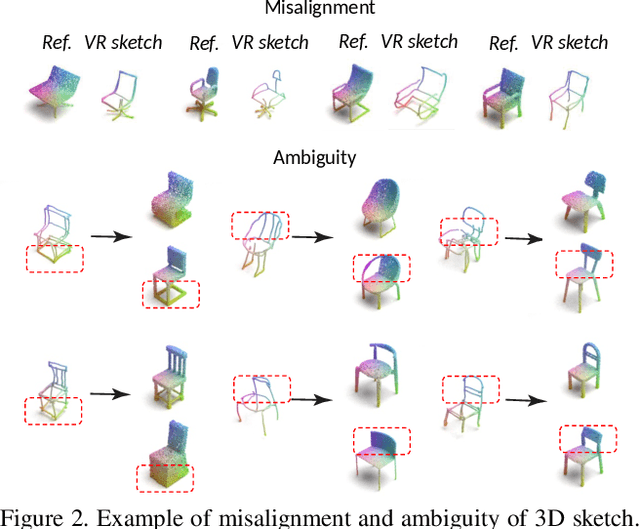
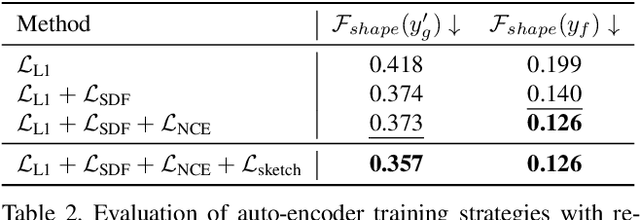
3D shape modeling is labor-intensive and time-consuming and requires years of expertise. Recently, 2D sketches and text inputs were considered as conditional modalities to 3D shape generation networks to facilitate 3D shape modeling. However, text does not contain enough fine-grained information and is more suitable to describe a category or appearance rather than geometry, while 2D sketches are ambiguous, and depicting complex 3D shapes in 2D again requires extensive practice. Instead, we explore virtual reality sketches that are drawn directly in 3D. We assume that the sketches are created by novices, without any art training, and aim to reconstruct physically-plausible 3D shapes. Since such sketches are potentially ambiguous, we tackle the problem of the generation of multiple 3D shapes that follow the input sketch structure. Limited in the size of the training data, we carefully design our method, training the model step-by-step and leveraging multi-modal 3D shape representation. To guarantee the plausibility of generated 3D shapes we leverage the normalizing flow that models the distribution of the latent space of 3D shapes. To encourage the fidelity of the generated 3D models to an input sketch, we propose a dedicated loss that we deploy at different stages of the training process. We plan to make our code publicly available.
CLUE: Calibrated Latent Guidance for Offline Reinforcement Learning
Jun 23, 2023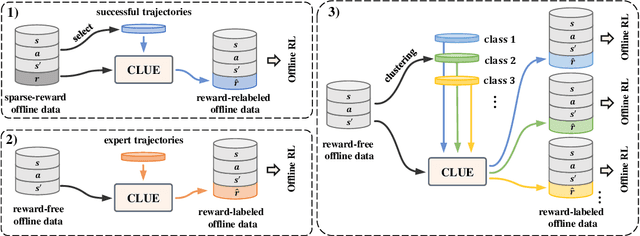
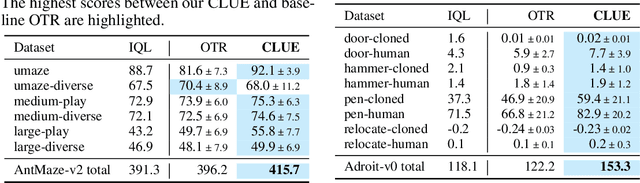
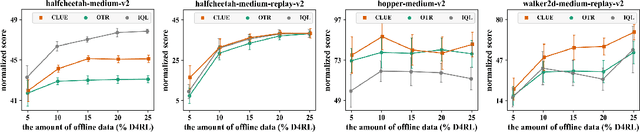
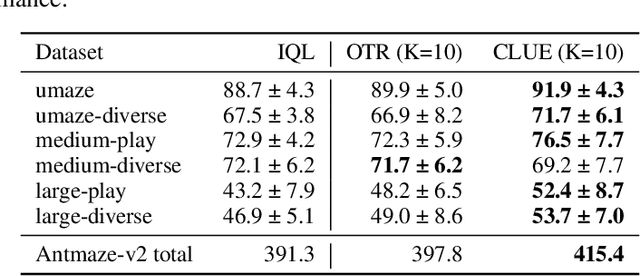
Offline reinforcement learning (RL) aims to learn an optimal policy from pre-collected and labeled datasets, which eliminates the time-consuming data collection in online RL. However, offline RL still bears a large burden of specifying/handcrafting extrinsic rewards for each transition in the offline data. As a remedy for the labor-intensive labeling, we propose to endow offline RL tasks with a few expert data and utilize the limited expert data to drive intrinsic rewards, thus eliminating the need for extrinsic rewards. To achieve that, we introduce \textbf{C}alibrated \textbf{L}atent g\textbf{U}idanc\textbf{E} (CLUE), which utilizes a conditional variational auto-encoder to learn a latent space such that intrinsic rewards can be directly qualified over the latent space. CLUE's key idea is to align the intrinsic rewards consistent with the expert intention via enforcing the embeddings of expert data to a calibrated contextual representation. We instantiate the expert-driven intrinsic rewards in sparse-reward offline RL tasks, offline imitation learning (IL) tasks, and unsupervised offline RL tasks. Empirically, we find that CLUE can effectively improve the sparse-reward offline RL performance, outperform the state-of-the-art offline IL baselines, and discover diverse skills from static reward-free offline data.
GICI-LIB: A GNSS/INS/Camera Integrated Navigation Library
Jun 23, 2023
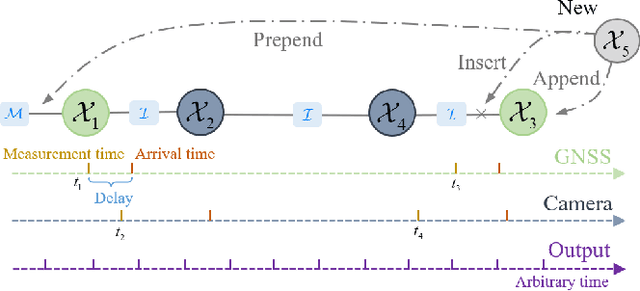
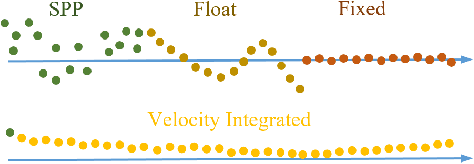

Accurate navigation is essential for autonomous robots and vehicles. In recent years, the integration of the Global Navigation Satellite System (GNSS), Inertial Navigation System (INS), and camera has garnered considerable attention due to its robustness and high accuracy in diverse environments. In such systems, fully utilizing the role of GNSS is cumbersome because of the diverse choices of formulations, error models, satellite constellations, signal frequencies, and service types, which lead to different precision, robustness, and usage dependencies. To clarify the capacity of GNSS algorithms and accelerate the development efficiency of employing GNSS in multi-sensor fusion algorithms, we open source the GNSS/INS/Camera Integration Library (GICI-LIB), together with detailed documentation and a comprehensive land vehicle dataset. A factor graph optimization-based multi-sensor fusion framework is established, which combines almost all GNSS measurement error sources by fully considering temporal and spatial correlations between measurements. The graph structure is designed for flexibility, making it easy to form any kind of integration algorithm. For illustration, four Real-Time Kinematic (RTK)-based algorithms from GICI-LIB are evaluated using our dataset. Results confirm the potential of the GICI system to provide continuous precise navigation solutions in a wide spectrum of urban environments.
Phase Unwrapping of Color Doppler Echocardiography using Deep Learning
Jun 23, 2023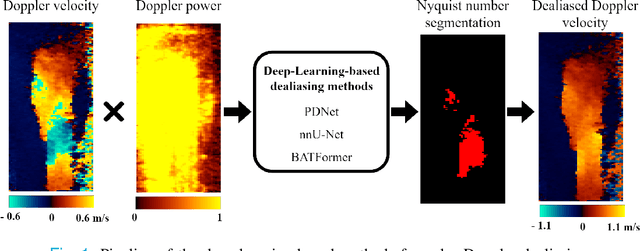
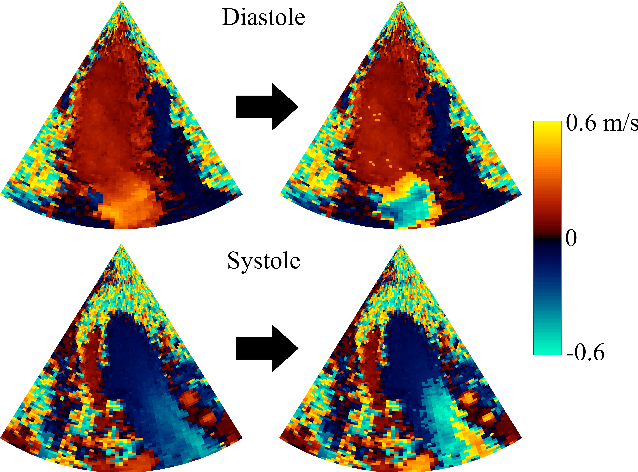

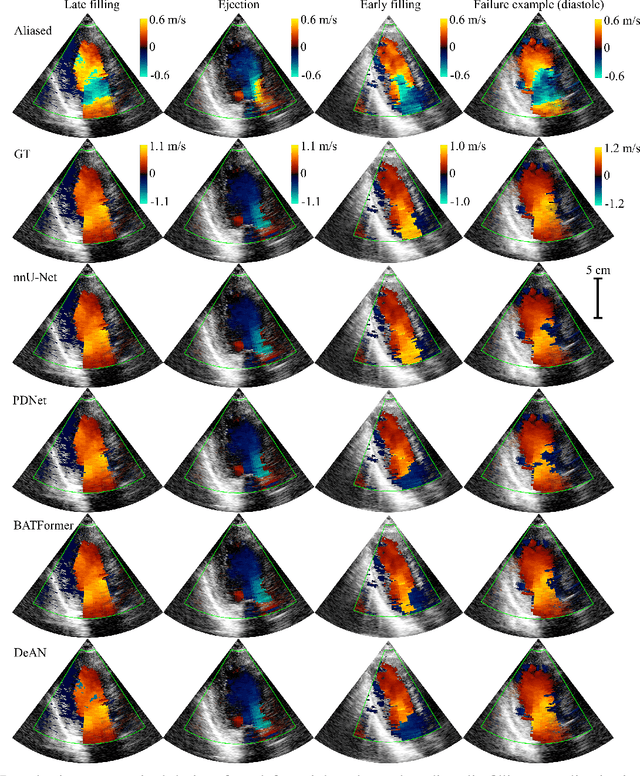
Color Doppler echocardiography is a widely used non-invasive imaging modality that provides real-time information about the intracardiac blood flow. In an apical long-axis view of the left ventricle, color Doppler is subject to phase wrapping, or aliasing, especially during cardiac filling and ejection. When setting up quantitative methods based on color Doppler, it is necessary to correct this wrapping artifact. We developed an unfolded primal-dual network to unwrap (dealias) color Doppler echocardiographic images and compared its effectiveness against two state-of-the-art segmentation approaches based on nnU-Net and transformer models. We trained and evaluated the performance of each method on an in-house dataset and found that the nnU-Net-based method provided the best dealiased results, followed by the primal-dual approach and the transformer-based technique. Noteworthy, the primal-dual network, which had significantly fewer trainable parameters, performed competitively with respect to the other two methods, demonstrating the high potential of deep unfolding methods. Our results suggest that deep learning-based methods can effectively remove aliasing artifacts in color Doppler echocardiographic images, outperforming DeAN, a state-of-the-art semi-automatic technique. Overall, our results show that deep learning-based methods have the potential to effectively preprocess color Doppler images for downstream quantitative analysis.
G-CAME: Gaussian-Class Activation Mapping Explainer for Object Detectors
Jun 06, 2023
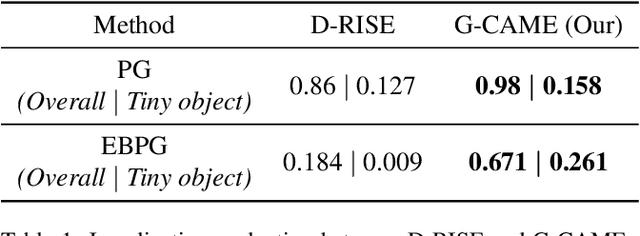
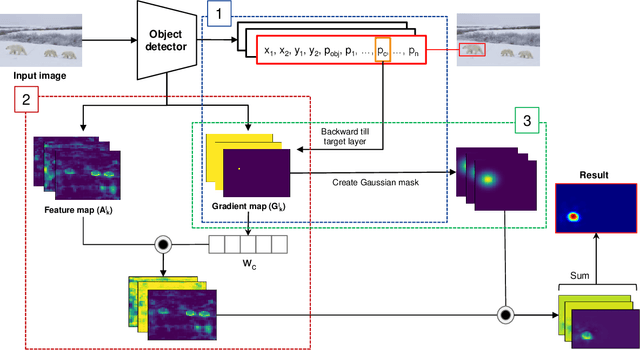
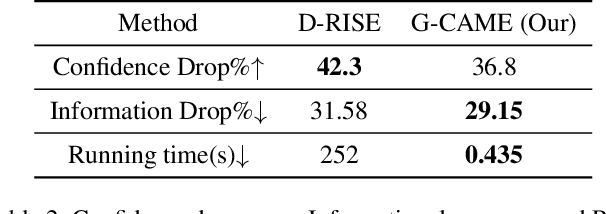
Nowadays, deep neural networks for object detection in images are very prevalent. However, due to the complexity of these networks, users find it hard to understand why these objects are detected by models. We proposed Gaussian Class Activation Mapping Explainer (G-CAME), which generates a saliency map as the explanation for object detection models. G-CAME can be considered a CAM-based method that uses the activation maps of selected layers combined with the Gaussian kernel to highlight the important regions in the image for the predicted box. Compared with other Region-based methods, G-CAME can transcend time constraints as it takes a very short time to explain an object. We also evaluated our method qualitatively and quantitatively with YOLOX on the MS-COCO 2017 dataset and guided to apply G-CAME into the two-stage Faster-RCNN model.
Online Learning under Adversarial Nonlinear Constraints
Jun 06, 2023

In many applications, learning systems are required to process continuous non-stationary data streams. We study this problem in an online learning framework and propose an algorithm that can deal with adversarial time-varying and nonlinear constraints. As we show in our work, the algorithm called Constraint Violation Velocity Projection (CVV-Pro) achieves $\sqrt{T}$ regret and converges to the feasible set at a rate of $1/\sqrt{T}$, despite the fact that the feasible set is slowly time-varying and a priori unknown to the learner. CVV-Pro only relies on local sparse linear approximations of the feasible set and therefore avoids optimizing over the entire set at each iteration, which is in sharp contrast to projected gradients or Frank-Wolfe methods. We also empirically evaluate our algorithm on two-player games, where the players are subjected to a shared constraint.
minimizing estimation error variance using a weighted sum of samples from the soil moisture active passive (SMAP) satellite
Jun 18, 2023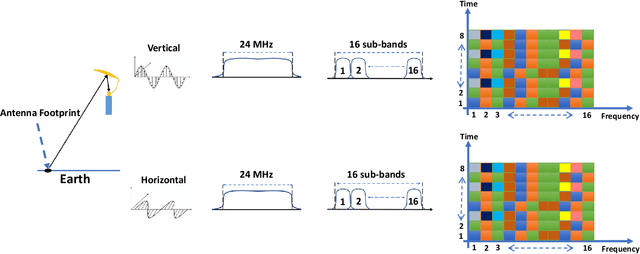
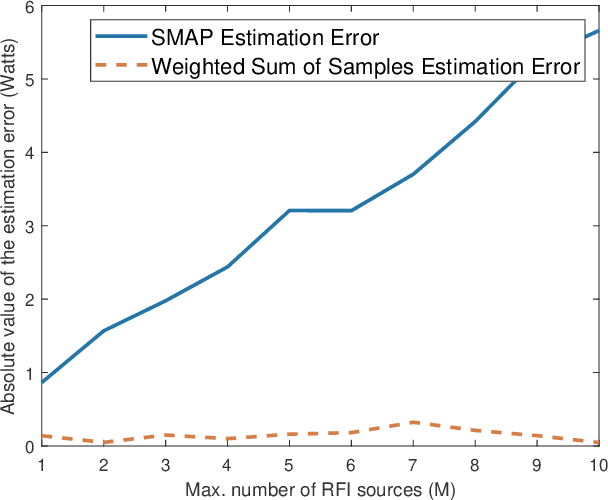
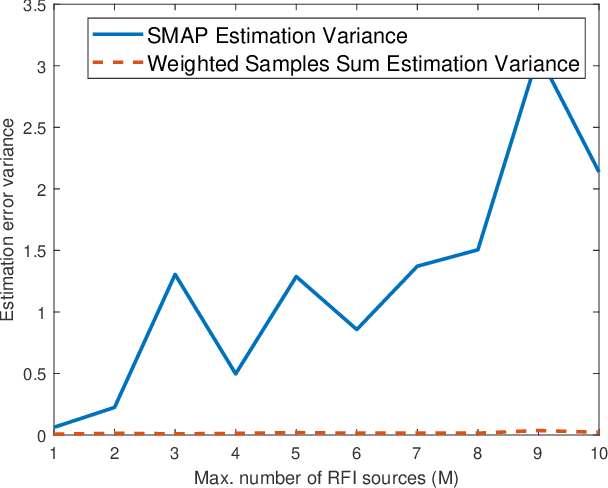
The National Aeronautics and Space Administration's (NASA) Soil Moisture Active Passive (SMAP) is the latest passive remote sensing satellite operating in the protected L-band spectrum from 1.400 to 1.427 GHz. SMAP provides global-scale soil moisture images with point-wise passive scanning of the earth's thermal radiations. SMAP takes multiple samples in frequency and time from each antenna footprint to increase the likelihood of capturing RFI-free samples. SMAP's current RFI detection and mitigation algorithm excludes samples detected to be RFI-contaminated and averages the remaining samples. But this approach can be less effective for harsh RFI environments, where RFI contamination is present in all or a large number of samples. In this paper, we investigate a bias-free weighted sum of samples estimator, where the weights can be computed based on the RFI's statistical properties.
TransRUPNet for Improved Out-of-Distribution Generalization in Polyp Segmentation
Jun 03, 2023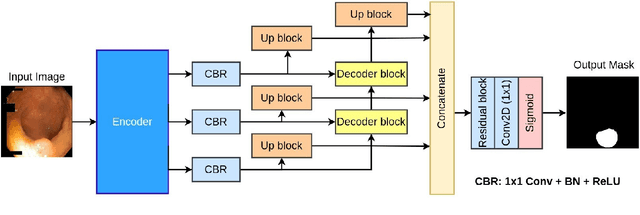
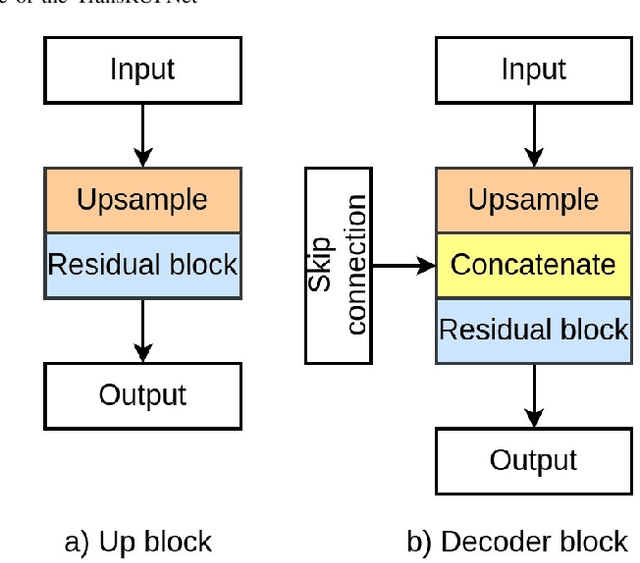
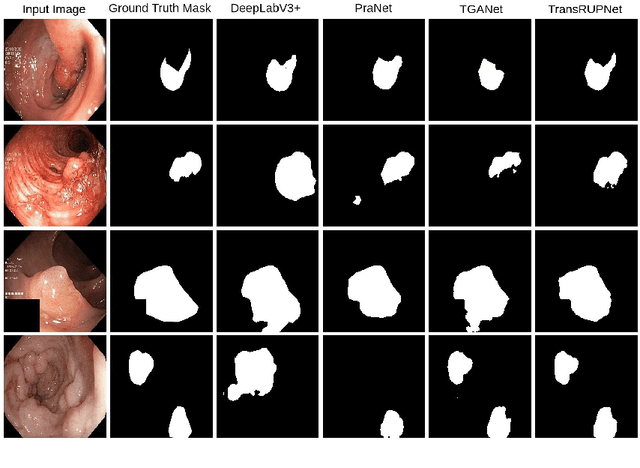
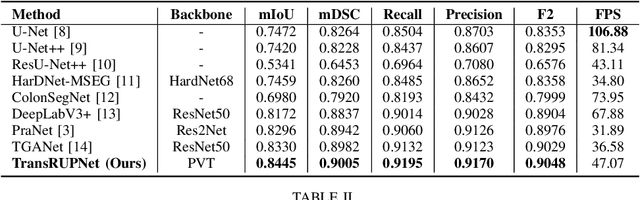
Out-of-distribution (OOD) generalization is a critical challenge in deep learning. It is specifically important when the test samples are drawn from a different distribution than the training data. We develop a novel real-time deep learning based architecture, TransRUPNet that is based on a Transformer and residual upsampling network for colorectal polyp segmentation to improve OOD generalization. The proposed architecture, TransRUPNet, is an encoder-decoder network that consists of three encoder blocks, three decoder blocks, and some additional upsampling blocks at the end of the network. With the image size of $256\times256$, the proposed method achieves an excellent real-time operation speed of \textbf{47.07} frames per second with an average mean dice coefficient score of 0.7786 and mean Intersection over Union of 0.7210 on the out-of-distribution polyp datasets. The results on the publicly available PolypGen dataset (OOD dataset in our case) suggest that TransRUPNet can give real-time feedback while retaining high accuracy for in-distribution dataset. Furthermore, we demonstrate the generalizability of the proposed method by showing that it significantly improves performance on OOD datasets compared to the existing methods.
Pixel-wise Agricultural Image Time Series Classification: Comparisons and a Deformable Prototype-based Approach
Mar 22, 2023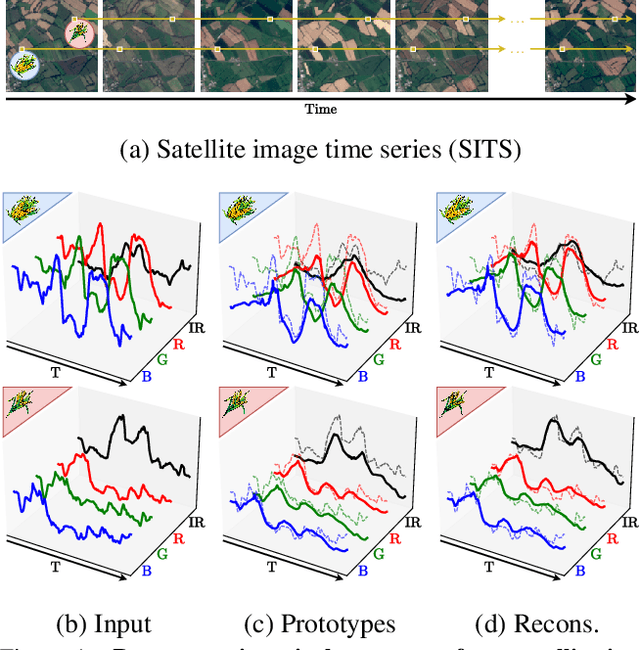
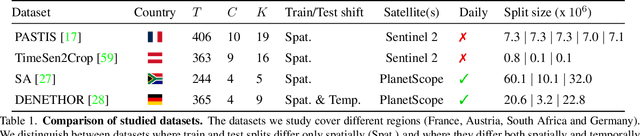

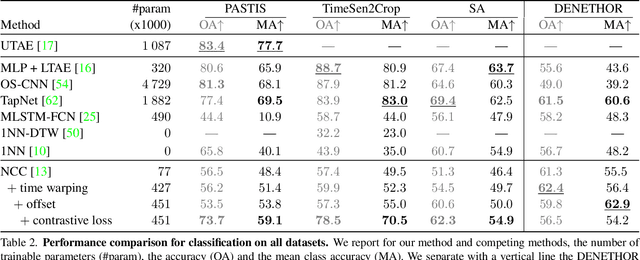
Improvements in Earth observation by satellites allow for imagery of ever higher temporal and spatial resolution. Leveraging this data for agricultural monitoring is key for addressing environmental and economic challenges. Current methods for crop segmentation using temporal data either rely on annotated data or are heavily engineered to compensate the lack of supervision. In this paper, we present and compare datasets and methods for both supervised and unsupervised pixel-wise segmentation of satellite image time series (SITS). We also introduce an approach to add invariance to spectral deformations and temporal shifts to classical prototype-based methods such as K-means and Nearest Centroid Classifier (NCC). We show this simple and highly interpretable method leads to meaningful results in both the supervised and unsupervised settings and significantly improves the state of the art for unsupervised classification of agricultural time series on four recent SITS datasets.