 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TinyTrain: Deep Neural Network Training at the Extreme Edge
Jul 19, 2023
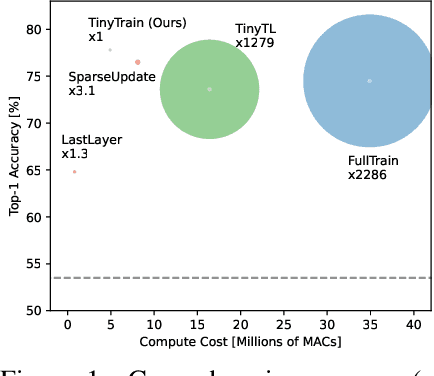
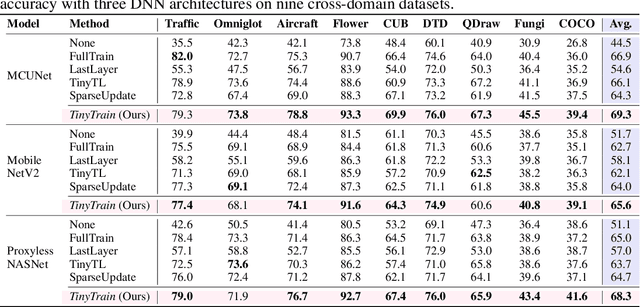
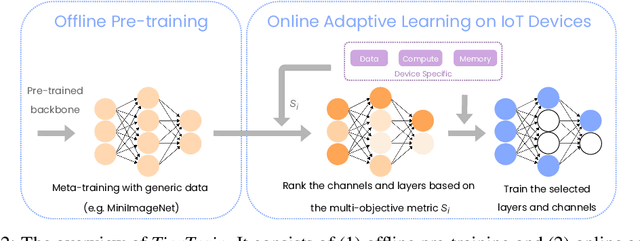
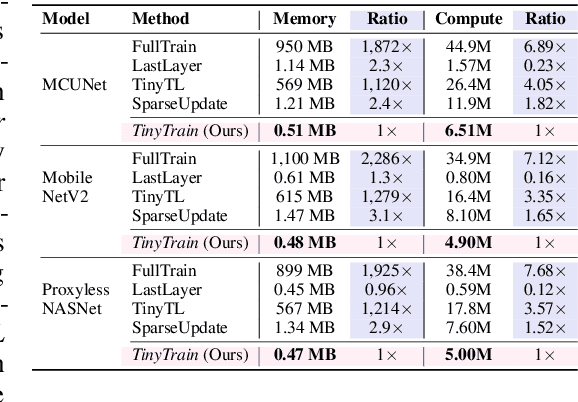
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCU), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss ($\geq$10\%). We propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0\% in accuracy, while reducing the backward-pass memory and computation cost by up to 2,286$\times$ and 7.68$\times$, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5$\times$ faster and 3.5$\times$ more energy-efficient training over status-quo approaches, and 2.8$\times$ smaller memory footprint than SOTA approaches, while remaining within the 1 MB memory envelope of MCU-grade platforms.
A Fast Task Offloading Optimization Framework for IRS-Assisted Multi-Access Edge Computing System
Jul 17, 2023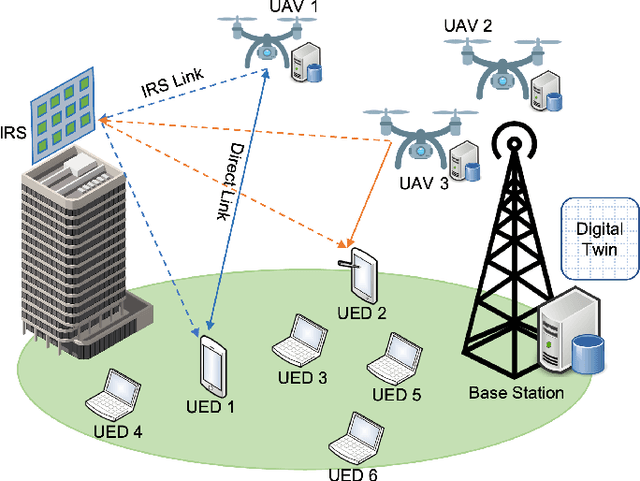
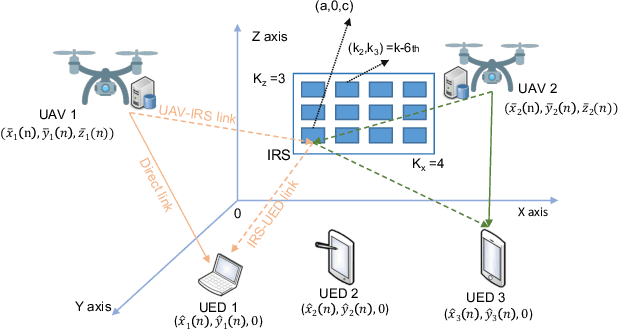
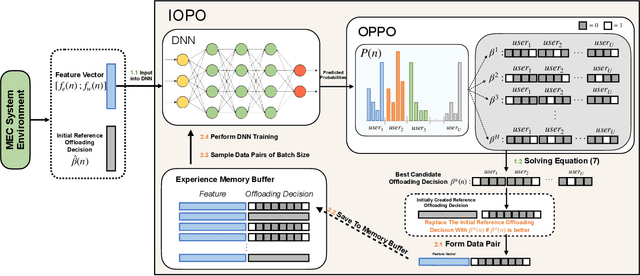
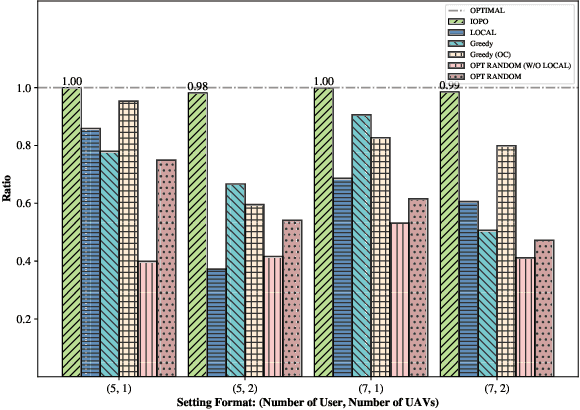
Terahertz communication networks and intelligent reflecting surfaces exhibit significant potential in advancing wireless networks, particularly within the domain of aerial-based multi-access edge computing systems. These technologies enable efficient offloading of computational tasks from user electronic devices to Unmanned Aerial Vehicles or local execution. For the generation of high-quality task-offloading allocations, conventional numerical optimization methods often struggle to solve challenging combinatorial optimization problems within the limited channel coherence time, thereby failing to respond quickly to dynamic changes in system conditions. To address this challenge, we propose a deep learning-based optimization framework called Iterative Order-Preserving policy Optimization (IOPO), which enables the generation of energy-efficient task-offloading decisions within milliseconds. Unlike exhaustive search methods, IOPO provides continuous updates to the offloading decisions without resorting to exhaustive search, resulting in accelerated convergence and reduced computational complexity, particularly when dealing with complex problems characterized by extensive solution spaces. Experimental results demonstrate that the proposed framework can generate energy-efficient task-offloading decisions within a very short time period, outperforming other benchmark methods.
Basal-Bolus Advisor for Type 1 Diabetes (T1D) Patients Using Multi-Agent Reinforcement Learning (RL) Methodology
Jul 17, 2023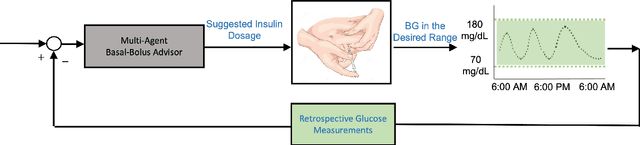
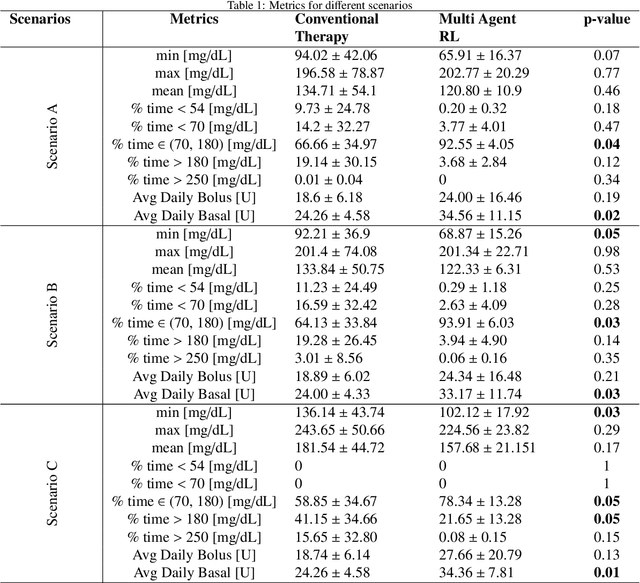
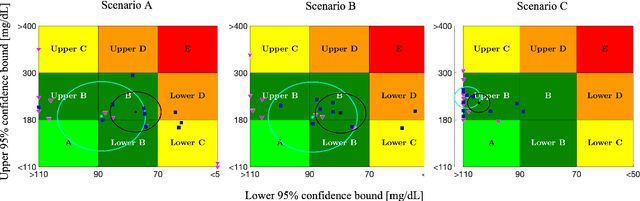
This paper presents a novel multi-agent reinforcement learning (RL) approach for personalized glucose control in individuals with type 1 diabetes (T1D). The method employs a closed-loop system consisting of a blood glucose (BG) metabolic model and a multi-agent soft actor-critic RL model acting as the basal-bolus advisor. Performance evaluation is conducted in three scenarios, comparing the RL agents to conventional therapy. Evaluation metrics include glucose levels (minimum, maximum, and mean), time spent in different BG ranges, and average daily bolus and basal insulin dosages. Results demonstrate that the RL-based basal-bolus advisor significantly improves glucose control, reducing glycemic variability and increasing time spent within the target range (70-180 mg/dL). Hypoglycemia events are effectively prevented, and severe hyperglycemia events are reduced. The RL approach also leads to a statistically significant reduction in average daily basal insulin dosage compared to conventional therapy. These findings highlight the effectiveness of the multi-agent RL approach in achieving better glucose control and mitigating the risk of severe hyperglycemia in individuals with T1D.
Online Learning with Costly Features in Non-stationary Environments
Jul 18, 2023Maximizing long-term rewards is the primary goal in sequential decision-making problems. The majority of existing methods assume that side information is freely available, enabling the learning agent to observe all features' states before making a decision. In real-world problems, however, collecting beneficial information is often costly. That implies that, besides individual arms' reward, learning the observations of the features' states is essential to improve the decision-making strategy. The problem is aggravated in a non-stationary environment where reward and cost distributions undergo abrupt changes over time. To address the aforementioned dual learning problem, we extend the contextual bandit setting and allow the agent to observe subsets of features' states. The objective is to maximize the long-term average gain, which is the difference between the accumulated rewards and the paid costs on average. Therefore, the agent faces a trade-off between minimizing the cost of information acquisition and possibly improving the decision-making process using the obtained information. To this end, we develop an algorithm that guarantees a sublinear regret in time. Numerical results demonstrate the superiority of our proposed policy in a real-world scenario.
The Decimation Scheme for Symmetric Matrix Factorization
Jul 31, 2023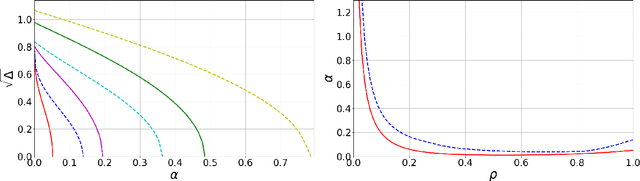
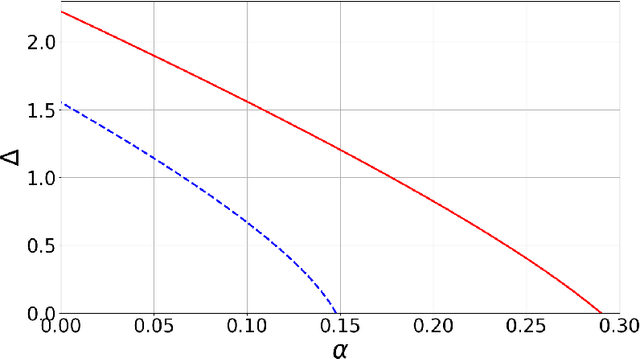
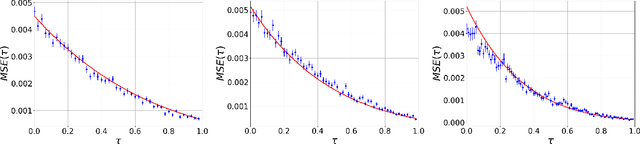
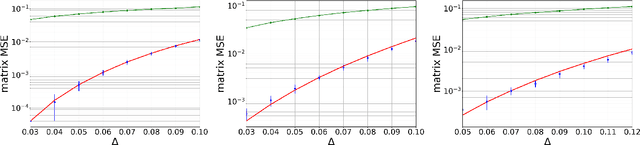
Matrix factorization is an inference problem that has acquired importance due to its vast range of applications that go from dictionary learning to recommendation systems and machine learning with deep networks. The study of its fundamental statistical limits represents a true challenge, and despite a decade-long history of efforts in the community, there is still no closed formula able to describe its optimal performances in the case where the rank of the matrix scales linearly with its size. In the present paper, we study this extensive rank problem, extending the alternative 'decimation' procedure that we recently introduced, and carry out a thorough study of its performance. Decimation aims at recovering one column/line of the factors at a time, by mapping the problem into a sequence of neural network models of associative memory at a tunable temperature. Though being sub-optimal, decimation has the advantage of being theoretically analyzable. We extend its scope and analysis to two families of matrices. For a large class of compactly supported priors, we show that the replica symmetric free entropy of the neural network models takes a universal form in the low temperature limit. For sparse Ising prior, we show that the storage capacity of the neural network models diverges as sparsity in the patterns increases, and we introduce a simple algorithm based on a ground state search that implements decimation and performs matrix factorization, with no need of an informative initialization.
Revisiting the Parameter Efficiency of Adapters from the Perspective of Precision Redundancy
Jul 31, 2023Current state-of-the-art results in computer vision depend in part on fine-tuning large pre-trained vision models. However, with the exponential growth of model sizes, the conventional full fine-tuning, which needs to store a individual network copy for each tasks, leads to increasingly huge storage and transmission overhead. Adapter-based Parameter-Efficient Tuning (PET) methods address this challenge by tuning lightweight adapters inserted into the frozen pre-trained models. In this paper, we investigate how to make adapters even more efficient, reaching a new minimum size required to store a task-specific fine-tuned network. Inspired by the observation that the parameters of adapters converge at flat local minima, we find that adapters are resistant to noise in parameter space, which means they are also resistant to low numerical precision. To train low-precision adapters, we propose a computational-efficient quantization method which minimizes the quantization error. Through extensive experiments, we find that low-precision adapters exhibit minimal performance degradation, and even 1-bit precision is sufficient for adapters. The experimental results demonstrate that 1-bit adapters outperform all other PET methods on both the VTAB-1K benchmark and few-shot FGVC tasks, while requiring the smallest storage size. Our findings show, for the first time, the significant potential of quantization techniques in PET, providing a general solution to enhance the parameter efficiency of adapter-based PET methods. Code: https://github.com/JieShibo/PETL-ViT
Chatbot Application to Support Smart Agriculture in Thailand
Jul 31, 2023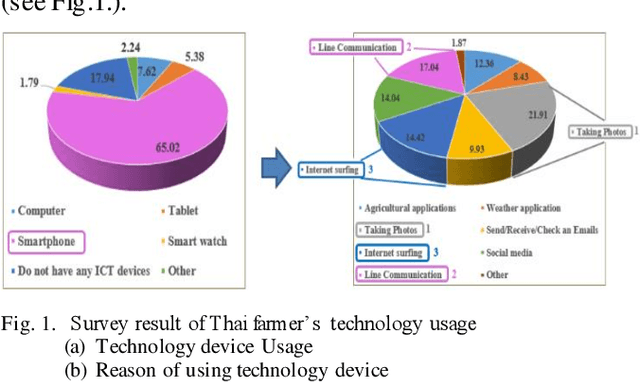
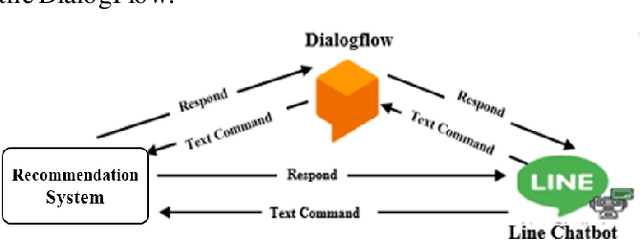
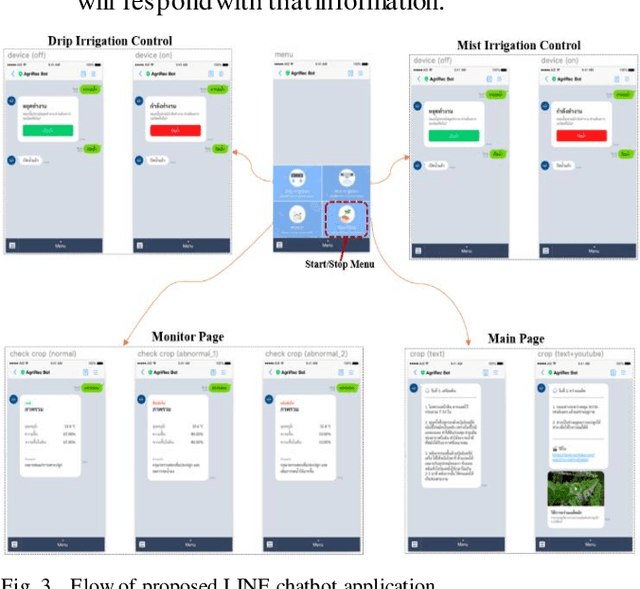
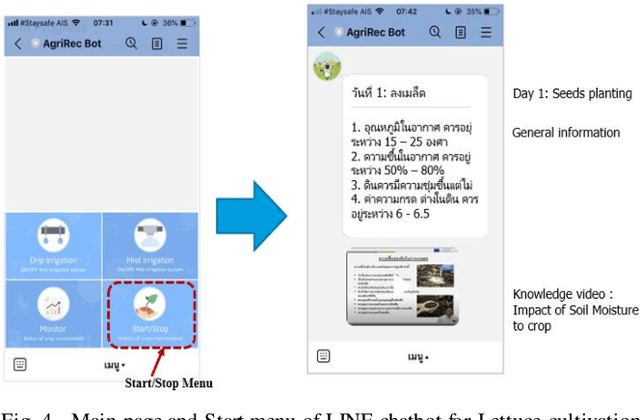
A chatbot is a software developed to help reply to text or voice conversations automatically and quickly in real time. In the agriculture sector, the existing smart agriculture systems just use data from sensing and internet of things (IoT) technologies that exclude crop cultivation knowledge to support decision-making by farmers. To enhance this, the chatbot application can be an assistant to farmers to provide crop cultivation knowledge. Consequently, we propose the LINE chatbot application as an information and knowledge representation providing crop cultivation recommendations to farmers. It works with smart agriculture and recommendation systems. Our proposed LINE chatbot application consists of five main functions (start/stop menu, main page, drip irri gation page, mist irrigation page, and monitor page). Farmers will receive information for data monitoring to support their decision-making. Moreover, they can control the irrigation system via the LINE chatbot. Furthermore, farmers can ask questions relevant to the crop environment via a chat box. After implementing our proposed chatbot, farmers are very satisfied with the application, scoring a 96% satisfaction score. However, in terms of asking questions via chat box, this LINE chatbot application is a rule-based bot or script bot. Farmers have to type in the correct keywords as prescribed, otherwise they won't get a response from the chatbots. In the future, we will enhance the asking function of our LINE chatbot to be an intelligent bot.
Validation of a Zero-Shot Learning Natural Language Processing Tool for Data Abstraction from Unstructured Healthcare Data
Jul 23, 2023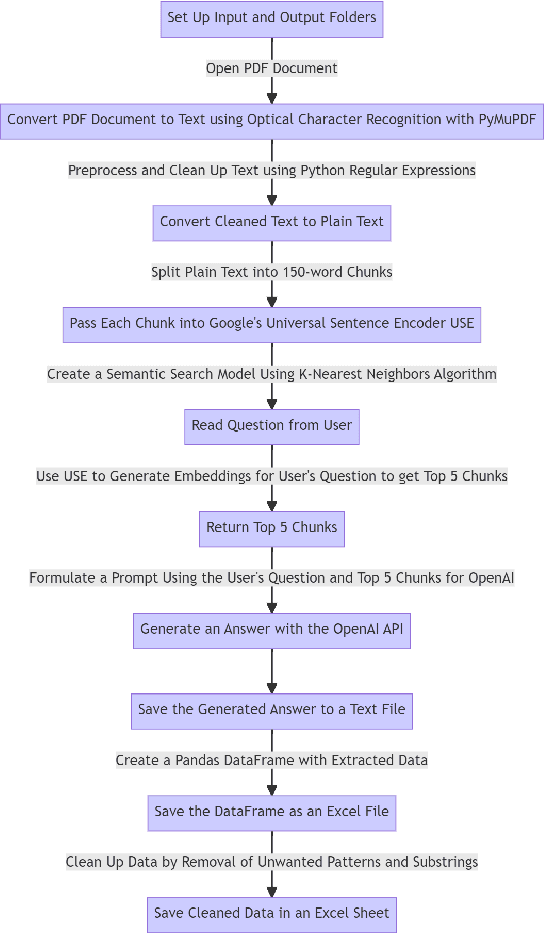

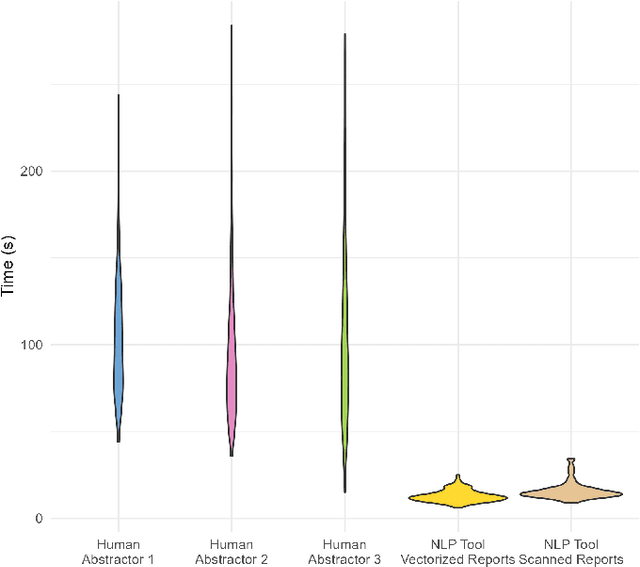
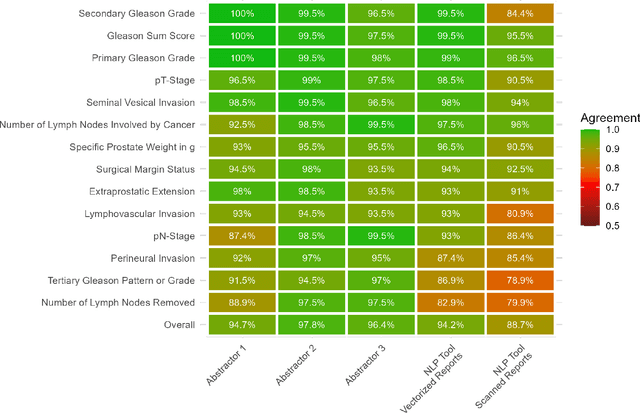
Objectives: To describe the development and validation of a zero-shot learning natural language processing (NLP) tool for abstracting data from unstructured text contained within PDF documents, such as those found within electronic health records. Materials and Methods: A data abstraction tool based on the GPT-3.5 model from OpenAI was developed and compared to three physician human abstractors in terms of time to task completion and accuracy for abstracting data on 14 unique variables from a set of 199 de-identified radical prostatectomy pathology reports. The reports were processed by the software tool in vectorized and scanned formats to establish the impact of optical character recognition on data abstraction. The tool was assessed for superiority for data abstraction speed and non-inferiority for accuracy. Results: The human abstractors required a mean of 101s per report for data abstraction, with times varying from 15 to 284 s. In comparison, the software tool required a mean of 12.8 s to process the vectorized reports and a mean of 15.8 to process the scanned reports (P < 0.001). The overall accuracies of the three human abstractors were 94.7%, 97.8%, and 96.4% for the combined set of 2786 datapoints. The software tool had an overall accuracy of 94.2% for the vectorized reports, proving to be non-inferior to the human abstractors at a margin of -10% ($\alpha$=0.025). The tool had a slightly lower accuracy of 88.7% using the scanned reports, proving to be non-inferiority to 2 out of 3 human abstractors. Conclusion: The developed zero-shot learning NLP tool affords researchers comparable levels of accuracy to that of human abstractors, with significant time savings benefits. Because of the lack of need for task-specific model training, the developed tool is highly generalizable and can be used for a wide variety of data abstraction tasks, even outside the field of medicine.
Reinforcement Learning for Credit Index Option Hedging
Jul 19, 2023In this paper, we focus on finding the optimal hedging strategy of a credit index option using reinforcement learning. We take a practical approach, where the focus is on realism i.e. discrete time, transaction costs; even testing our policy on real market data. We apply a state of the art algorithm, the Trust Region Volatility Optimization (TRVO) algorithm and show that the derived hedging strategy outperforms the practitioner's Black & Scholes delta hedge.
Temporal and Heterogeneous Graph Neural Network for Financial Time Series Prediction
May 09, 2023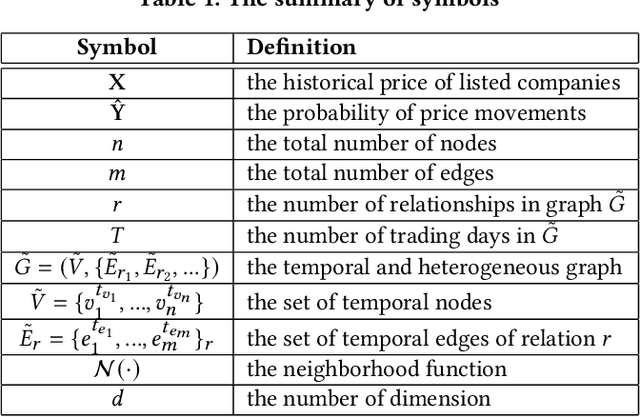
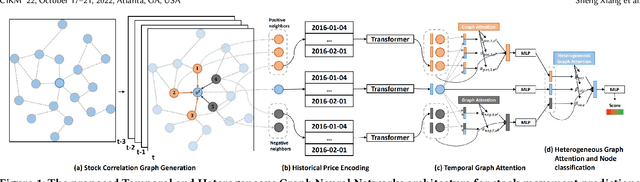
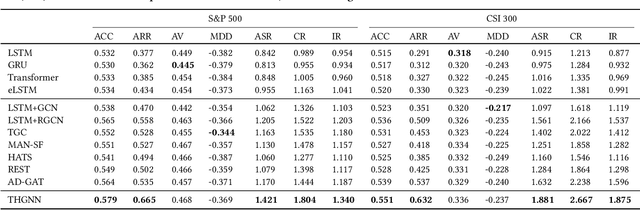
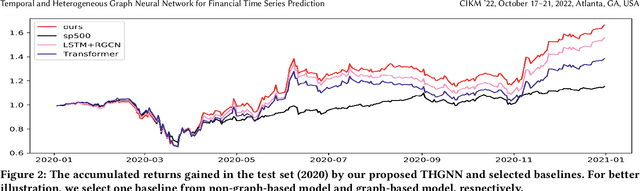
The price movement prediction of stock market has been a classical yet challenging problem, with the attention of both economists and computer scientists. In recent years, graph neural network has significantly improved the prediction performance by employing deep learning on company relations. However, existing relation graphs are usually constructed by handcraft human labeling or nature language processing, which are suffering from heavy resource requirement and low accuracy. Besides, they cannot effectively response to the dynamic changes in relation graphs. Therefore, in this paper, we propose a temporal and heterogeneous graph neural network-based (THGNN) approach to learn the dynamic relations among price movements in financial time series. In particular, we first generate the company relation graph for each trading day according to their historic price. Then we leverage a transformer encoder to encode the price movement information into temporal representations. Afterward, we propose a heterogeneous graph attention network to jointly optimize the embeddings of the financial time series data by transformer encoder and infer the probability of target movements. Finally, we conduct extensive experiments on the stock market in the United States and China. The results demonstrate the effectiveness and superior performance of our proposed methods compared with state-of-the-art baselines. Moreover, we also deploy the proposed THGNN in a real-world quantitative algorithm trading system, the accumulated portfolio return obtained by our method significantly outperforms other baselines.