 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Investigation into Glomeruli Detection in Kidney H&E and PAS Images using YOLO
Jul 25, 2023

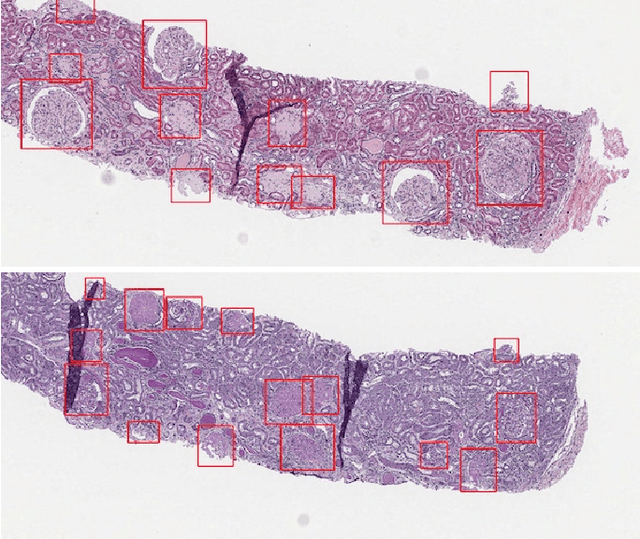
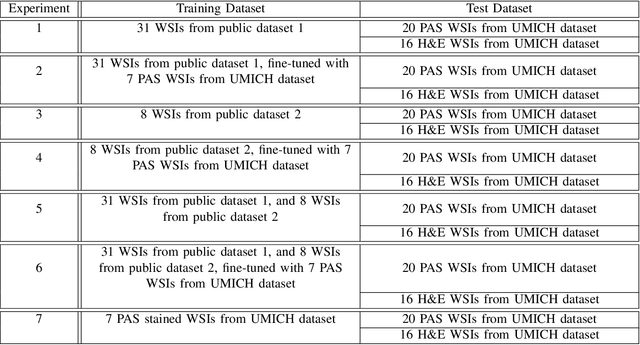
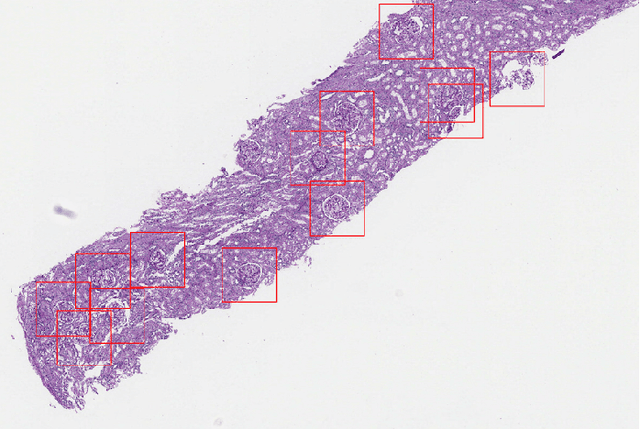
Context: Analyzing digital pathology images is necessary to draw diagnostic conclusions by investigating tissue patterns and cellular morphology. However, manual evaluation can be time-consuming, expensive, and prone to inter- and intra-observer variability. Objective: To assist pathologists using computerized solutions, automated tissue structure detection and segmentation must be proposed. Furthermore, generating pixel-level object annotations for histopathology images is expensive and time-consuming. As a result, detection models with bounding box labels may be a feasible solution. Design: This paper studies. YOLO-v4 (You-Only-Look-Once), a real-time object detector for microscopic images. YOLO uses a single neural network to predict several bounding boxes and class probabilities for objects of interest. YOLO can enhance detection performance by training on whole slide images. YOLO-v4 has been used in this paper. for glomeruli detection in human kidney images. Multiple experiments have been designed and conducted based on different training data of two public datasets and a private dataset from the University of Michigan for fine-tuning the model. The model was tested on the private dataset from the University of Michigan, serving as an external validation of two different stains, namely hematoxylin and eosin (H&E) and periodic acid-Schiff (PAS). Results: Average specificity and sensitivity for all experiments, and comparison of existing segmentation methods on the same datasets are discussed. Conclusions: Automated glomeruli detection in human kidney images is possible using modern AI models. The design and validation for different stains still depends on variability of public multi-stain datasets.
Unlimited Sampling Radar: a Real-Time End-to-End Demonstrator
Jun 30, 2023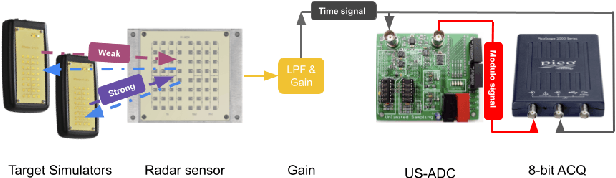
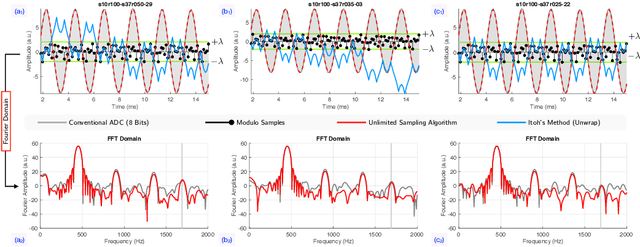
In this paper, the trade-off between the quantization noise and the dynamic range of ADCs used to acquire radar signals is revisited using the Unlimited Sensing Framework (USF) in a practical setting. Trade-offs between saturation and resolution arise in many applications, like radar, where sensors acquire signals which exhibit a high degree of variability in amplitude. To solve this issue, we propose the use of the co-design approach of the USF which acquires folded version of the signal of interest and leverages its structure to reconstruct it after its acquisition. We demonstrate that this method outperforms other standard acquisition methods for Doppler radars. Taking our theory all the way to practice, we develop a prototype USF-enabled Doppler Radar and show the clear benefits of our method. In each experiment, we show that using the USF increases sensitivity compared to a classic acquisition approach.
AICSD: Adaptive Inter-Class Similarity Distillation for Semantic Segmentation
Aug 08, 2023In recent years, deep neural networks have achieved remarkable accuracy in computer vision tasks. With inference time being a crucial factor, particularly in dense prediction tasks such as semantic segmentation, knowledge distillation has emerged as a successful technique for improving the accuracy of lightweight student networks. The existing methods often neglect the information in channels and among different classes. To overcome these limitations, this paper proposes a novel method called Inter-Class Similarity Distillation (ICSD) for the purpose of knowledge distillation. The proposed method transfers high-order relations from the teacher network to the student network by independently computing intra-class distributions for each class from network outputs. This is followed by calculating inter-class similarity matrices for distillation using KL divergence between distributions of each pair of classes. To further improve the effectiveness of the proposed method, an Adaptive Loss Weighting (ALW) training strategy is proposed. Unlike existing methods, the ALW strategy gradually reduces the influence of the teacher network towards the end of training process to account for errors in teacher's predictions. Extensive experiments conducted on two well-known datasets for semantic segmentation, Cityscapes and Pascal VOC 2012, validate the effectiveness of the proposed method in terms of mIoU and pixel accuracy. The proposed method outperforms most of existing knowledge distillation methods as demonstrated by both quantitative and qualitative evaluations. Code is available at: https://github.com/AmirMansurian/AICSD
Data Augmentation for Human Behavior Analysis in Multi-Person Conversations
Aug 03, 2023
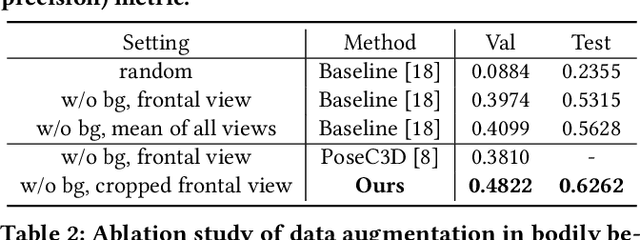
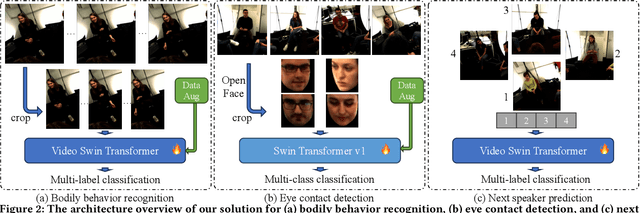

In this paper, we present the solution of our team HFUT-VUT for the MultiMediate Grand Challenge 2023 at ACM Multimedia 2023. The solution covers three sub-challenges: bodily behavior recognition, eye contact detection, and next speaker prediction. We select Swin Transformer as the baseline and exploit data augmentation strategies to address the above three tasks. Specifically, we crop the raw video to remove the noise from other parts. At the same time, we utilize data augmentation to improve the generalization of the model. As a result, our solution achieves the best results of 0.6262 for bodily behavior recognition in terms of mean average precision and the accuracy of 0.7771 for eye contact detection on the corresponding test set. In addition, our approach also achieves comparable results of 0.5281 for the next speaker prediction in terms of unweighted average recall.
Thespian: Multi-Character Text Role-Playing Game Agents
Aug 03, 2023
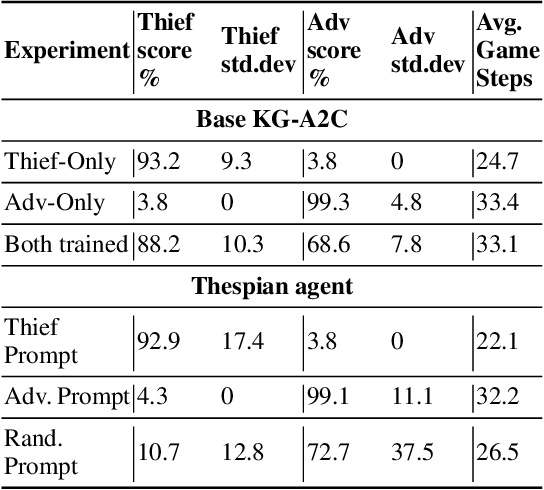
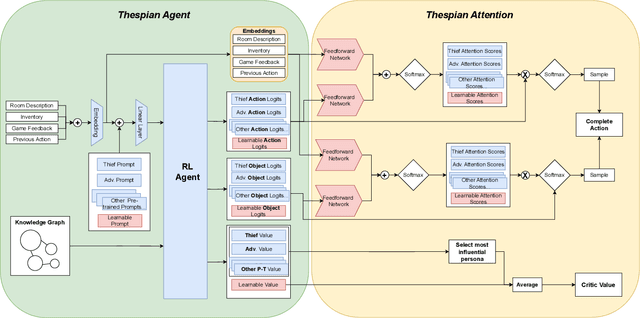

Text-adventure games and text role-playing games are grand challenges for reinforcement learning game playing agents. Text role-playing games are open-ended environments where an agent must faithfully play a particular character. We consider the distinction between characters and actors, where an actor agent has the ability to play multiple characters. We present a framework we call a thespian agent that can learn to emulate multiple characters along with a soft prompt that can be used to direct it as to which character to play at any time. We further describe an attention mechanism that allows the agent to learn new characters that are based on previously learned characters in a few-shot fashion. We show that our agent outperforms the state of the art agent framework in multi-character learning and few-shot learning.
VSMask: Defending Against Voice Synthesis Attack via Real-Time Predictive Perturbation
May 09, 2023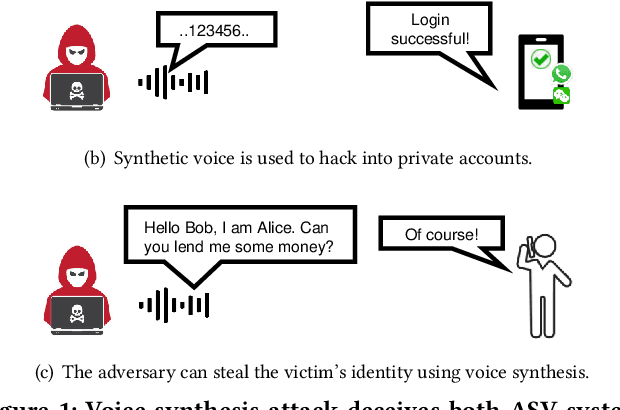
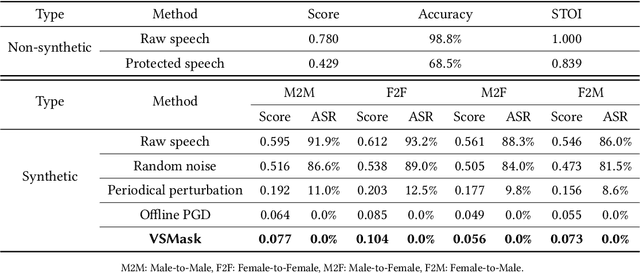
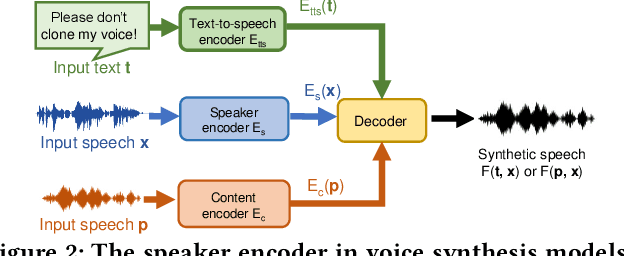
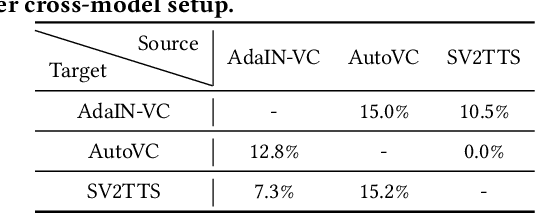
Deep learning based voice synthesis technology generates artificial human-like speeches, which has been used in deepfakes or identity theft attacks. Existing defense mechanisms inject subtle adversarial perturbations into the raw speech audios to mislead the voice synthesis models. However, optimizing the adversarial perturbation not only consumes substantial computation time, but it also requires the availability of entire speech. Therefore, they are not suitable for protecting live speech streams, such as voice messages or online meetings. In this paper, we propose VSMask, a real-time protection mechanism against voice synthesis attacks. Different from offline protection schemes, VSMask leverages a predictive neural network to forecast the most effective perturbation for the upcoming streaming speech. VSMask introduces a universal perturbation tailored for arbitrary speech input to shield a real-time speech in its entirety. To minimize the audio distortion within the protected speech, we implement a weight-based perturbation constraint to reduce the perceptibility of the added perturbation. We comprehensively evaluate VSMask protection performance under different scenarios. The experimental results indicate that VSMask can effectively defend against 3 popular voice synthesis models. None of the synthetic voice could deceive the speaker verification models or human ears with VSMask protection. In a physical world experiment, we demonstrate that VSMask successfully safeguards the real-time speech by injecting the perturbation over the air.
A Deep Learning Approach for Overall Survival Analysis with Missing Values
Jul 21, 2023One of the most challenging fields where Artificial Intelligence (AI) can be applied is lung cancer research, specifically non-small cell lung cancer (NSCLC). In particular, overall survival (OS) is a vital indicator of patient status, helping to identify subgroups with diverse survival probabilities, enabling tailored treatment and improved OS rates. In this analysis, there are two challenges to take into account. First, few studies effectively exploit the information available from each patient, leveraging both uncensored (i.e., dead) and censored (i.e., survivors) patients, considering also the death times. Second, the handling of incomplete data is a common issue in the medical field. This problem is typically tackled through the use of imputation methods. Our objective is to present an AI model able to overcome these limits, effectively learning from both censored and uncensored patients and their available features, for the prediction of OS for NSCLC patients. We present a novel approach to survival analysis in the context of NSCLC, which exploits the strengths of the transformer architecture accounting for only available features without requiring any imputation strategy. By making use of ad-hoc losses for OS, it accounts for both censored and uncensored patients, considering risks over time. We evaluated the results over a period of 6 years using different time granularities obtaining a Ct-index, a time-dependent variant of the C-index, of 71.97, 77.58 and 80.72 for time units of 1 month, 1 year and 2 years, respectively, outperforming all state-of-the-art methods regardless of the imputation method used.
FFF: Fragments-Guided Flexible Fitting for Building Complete Protein Structures
Aug 07, 2023
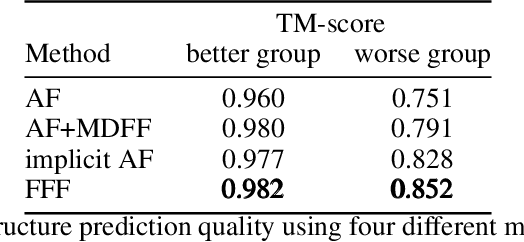
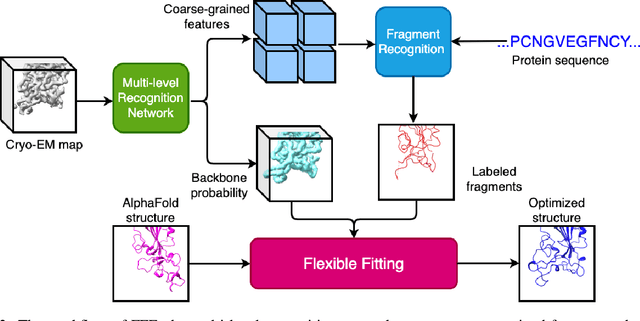
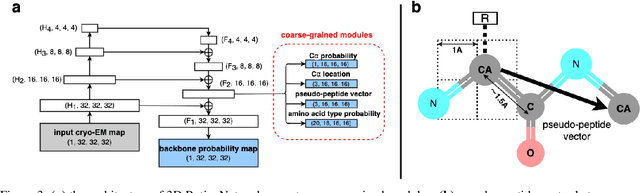
Cryo-electron microscopy (cryo-EM) is a technique for reconstructing the 3-dimensional (3D) structure of biomolecules (especially large protein complexes and molecular assemblies). As the resolution increases to the near-atomic scale, building protein structures de novo from cryo-EM maps becomes possible. Recently, recognition-based de novo building methods have shown the potential to streamline this process. However, it cannot build a complete structure due to the low signal-to-noise ratio (SNR) problem. At the same time, AlphaFold has led to a great breakthrough in predicting protein structures. This has inspired us to combine fragment recognition and structure prediction methods to build a complete structure. In this paper, we propose a new method named FFF that bridges protein structure prediction and protein structure recognition with flexible fitting. First, a multi-level recognition network is used to capture various structural features from the input 3D cryo-EM map. Next, protein structural fragments are generated using pseudo peptide vectors and a protein sequence alignment method based on these extracted features. Finally, a complete structural model is constructed using the predicted protein fragments via flexible fitting. Based on our benchmark tests, FFF outperforms the baseline methods for building complete protein structures.
* Published in the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Learning-based Near-optimal Motion Planning for Intelligent Vehicles with Uncertain Dynamics
Aug 07, 2023Motion planning has been an important research topic in achieving safe and flexible maneuvers for intelligent vehicles. However, it remains challenging to realize efficient and optimal planning in the presence of uncertain model dynamics. In this paper, a sparse kernel-based reinforcement learning (RL) algorithm with Gaussian Process (GP) Regression (called GP-SKRL) is proposed to achieve online adaption and near-optimal motion planning performance. In this algorithm, we design an efficient sparse GP regression method to learn the uncertain dynamics. Based on the updated model, a sparse kernel-based policy iteration algorithm with an exponential barrier function is designed to learn the near-optimal planning policies with the capability to avoid dynamic obstacles. Thereby, batch-mode GP-SKRL with online adaption capability can estimate the changing system dynamics. The converged RL policies are then deployed on vehicles efficiently under a safety-aware module. As a result, the produced driving actions are safe and less conservative, and the planning performance has been noticeably improved. Extensive simulation results show that GP-SKRL outperforms several advanced motion planning methods in terms of average cumulative cost, trajectory length, and task completion time. In particular, experiments on a Hongqi E-HS3 vehicle demonstrate that superior GP-SKRL provides a practical planning solution.
A Meta-learning based Stacked Regression Approach for Customer Lifetime Value Prediction
Aug 07, 2023Companies across the globe are keen on targeting potential high-value customers in an attempt to expand revenue and this could be achieved only by understanding the customers more. Customer Lifetime Value (CLV) is the total monetary value of transactions/purchases made by a customer with the business over an intended period of time and is used as means to estimate future customer interactions. CLV finds application in a number of distinct business domains such as Banking, Insurance, Online-entertainment, Gaming, and E-Commerce. The existing distribution-based and basic (recency, frequency & monetary) based models face a limitation in terms of handling a wide variety of input features. Moreover, the more advanced Deep learning approaches could be superfluous and add an undesirable element of complexity in certain application areas. We, therefore, propose a system which is able to qualify both as effective, and comprehensive yet simple and interpretable. With that in mind, we develop a meta-learning-based stacked regression model which combines the predictions from bagging and boosting models that each is found to perform well individually. Empirical tests have been carried out on an openly available Online Retail dataset to evaluate various models and show the efficacy of the proposed approach.