 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Performance Comparison of Design Optimization and Deep Learning-based Inverse Design
Aug 23, 2023
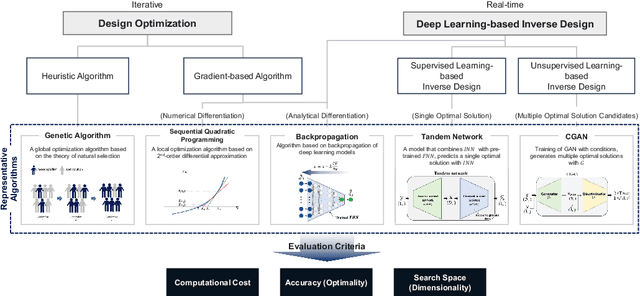
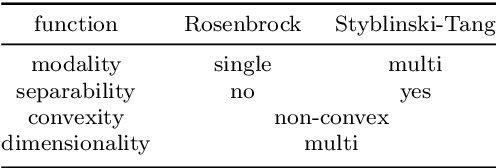
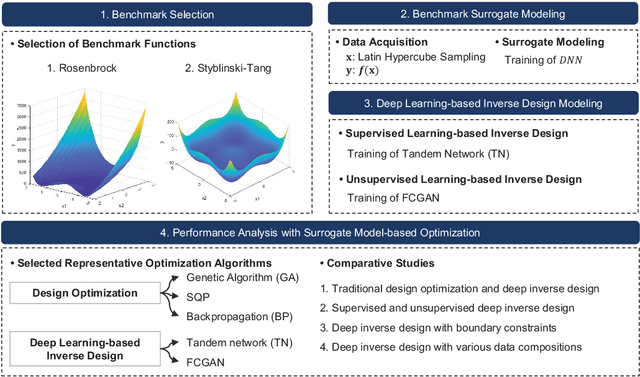

Surrogate model-based optimization has been increasingly used in the field of engineering design. It involves creating a surrogate model with objective functions or constraints based on the data obtained from simulations or real-world experiments, and then finding the optimal solution from the model using numerical optimization methods. Recent advancements in deep learning-based inverse design methods have made it possible to generate real-time optimal solutions for engineering design problems, eliminating the requirement for iterative optimization processes. Nevertheless, no comprehensive study has yet closely examined the specific advantages and disadvantages of this novel approach compared to the traditional design optimization method. The objective of this paper is to compare the performance of traditional design optimization methods with deep learning-based inverse design methods by employing benchmark problems across various scenarios. Based on the findings of this study, we provide guidelines that can be taken into account for the future utilization of deep learning-based inverse design. It is anticipated that these guidelines will enhance the practical applicability of this approach to real engineering design problems.
Minimalist Traffic Prediction: Linear Layer Is All You Need
Aug 23, 2023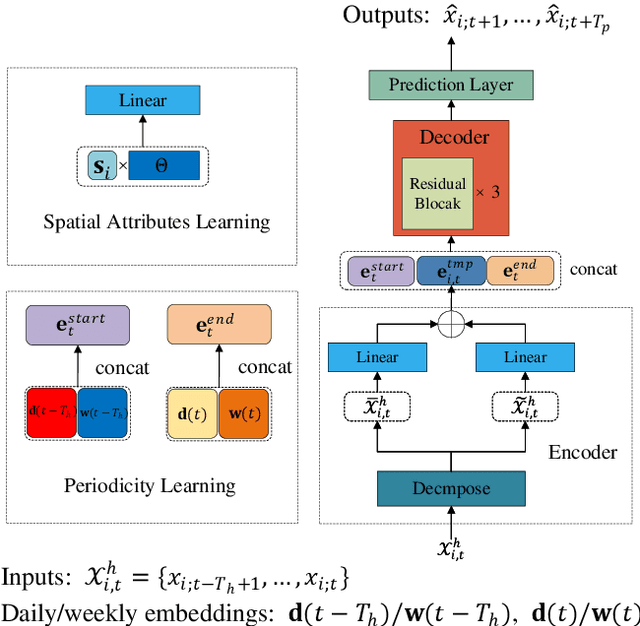
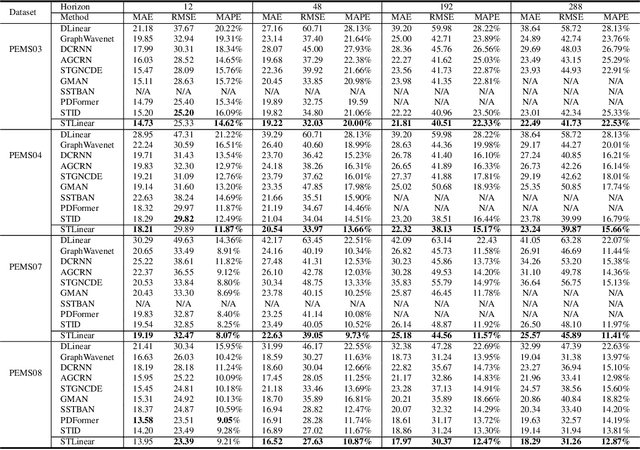
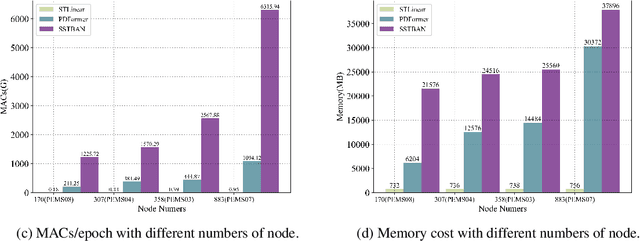
Traffic prediction is essential for the progression of Intelligent Transportation Systems (ITS) and the vision of smart cities. While Spatial-Temporal Graph Neural Networks (STGNNs) have shown promise in this domain by leveraging Graph Neural Networks (GNNs) integrated with either RNNs or Transformers, they present challenges such as computational complexity, gradient issues, and resource-intensiveness. This paper addresses these challenges, advocating for three main solutions: a node-embedding approach, time series decomposition, and periodicity learning. We introduce STLinear, a minimalist model architecture designed for optimized efficiency and performance. Unlike traditional STGNNs, STlinear operates fully locally, avoiding inter-node data exchanges, and relies exclusively on linear layers, drastically cutting computational demands. Our empirical studies on real-world datasets confirm STLinear's prowess, matching or exceeding the accuracy of leading STGNNs, but with significantly reduced complexity and computation overhead (more than 95% reduction in MACs per epoch compared to state-of-the-art STGNN baseline published in 2023). In summary, STLinear emerges as a potent, efficient alternative to conventional STGNNs, with profound implications for the future of ITS and smart city initiatives.
Example-Based Framework for Perceptually Guided Audio Texture Generation
Aug 23, 2023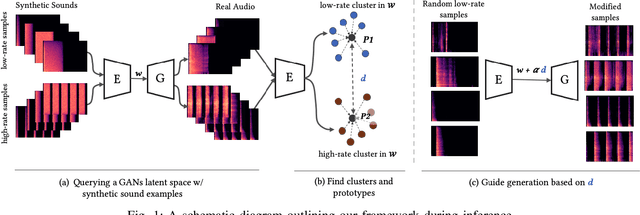

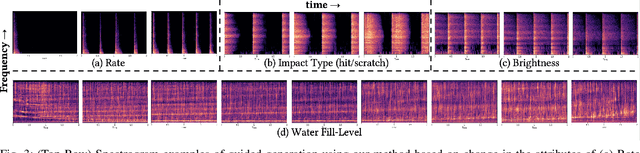
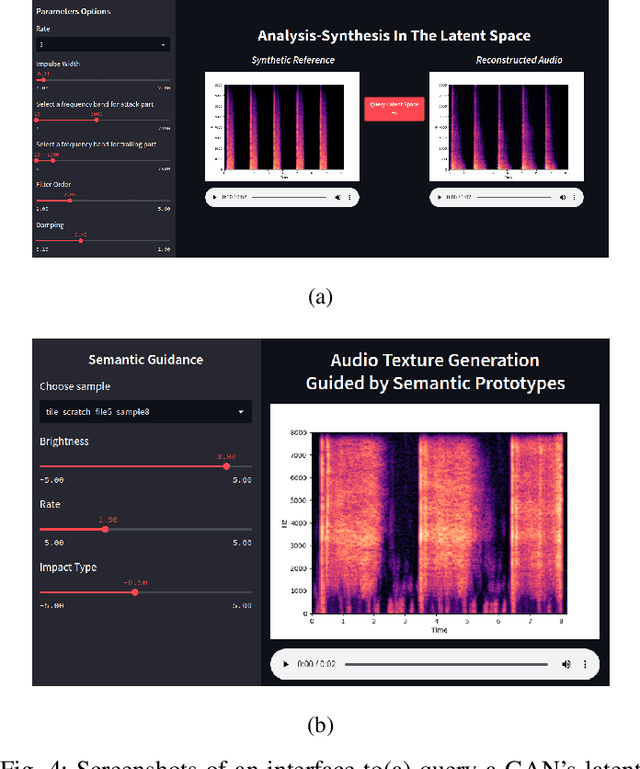
Generative models for synthesizing audio textures explicitly encode controllability by conditioning the model with labelled data. While datasets for audio textures can be easily recorded in-the-wild, semantically labeling them is expensive, time-consuming, and prone to errors due to human annotator subjectivity. Thus, to control generation, there is a need to automatically infer user-defined perceptual factors of variation in the latent space of a generative model while modelling unlabeled textures. In this paper, we propose an example-based framework to determine vectors to guide texture generation based on user-defined semantic attributes. By synthesizing a few synthetic examples to indicate the presence or absence of a semantic attribute, we can infer the guidance vectors in the latent space of a generative model to control that attribute during generation. Our results show that our method is capable of finding perceptually relevant and deterministic guidance vectors for controllable generation for both discrete as well as continuous textures. Furthermore, we demonstrate the application of this method to other tasks such as selective semantic attribute transfer.
Curriculum Learning with Adam: The Devil Is in the Wrong Details
Aug 23, 2023


Curriculum learning (CL) posits that machine learning models -- similar to humans -- may learn more efficiently from data that match their current learning progress. However, CL methods are still poorly understood and, in particular for natural language processing (NLP), have achieved only limited success. In this paper, we explore why. Starting from an attempt to replicate and extend a number of recent curriculum methods, we find that their results are surprisingly brittle when applied to NLP. A deep dive into the (in)effectiveness of the curricula in some scenarios shows us why: when curricula are employed in combination with the popular Adam optimisation algorithm, they oftentimes learn to adapt to suboptimally chosen optimisation parameters for this algorithm. We present a number of different case studies with different common hand-crafted and automated CL approaches to illustrate this phenomenon, and we find that none of them outperforms optimisation with only Adam with well-chosen hyperparameters. As such, our results contribute to understanding why CL methods work, but at the same time urge caution when claiming positive results.
Empowering Refugee Claimants and their Lawyers: Using Machine Learning to Examine Decision-Making in Refugee Law
Aug 22, 2023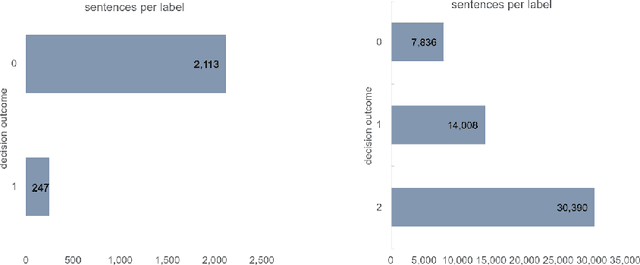
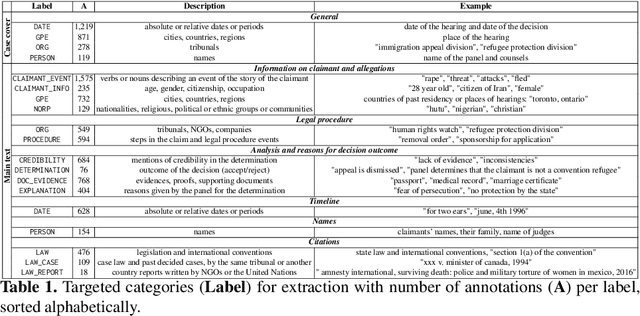
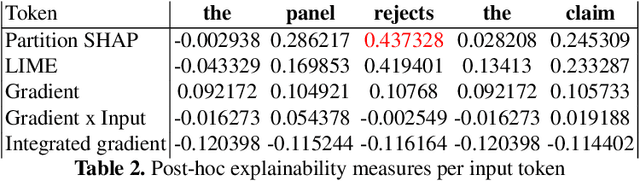
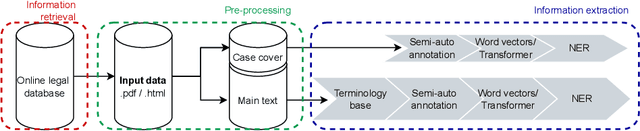
Our project aims at helping and supporting stakeholders in refugee status adjudications, such as lawyers, judges, governing bodies, and claimants, in order to make better decisions through data-driven intelligence and increase the understanding and transparency of the refugee application process for all involved parties. This PhD project has two primary objectives: (1) to retrieve past cases, and (2) to analyze legal decision-making processes on a dataset of Canadian cases. In this paper, we present the current state of our work, which includes a completed experiment on part (1) and ongoing efforts related to part (2). We believe that NLP-based solutions are well-suited to address these challenges, and we investigate the feasibility of automating all steps involved. In addition, we introduce a novel benchmark for future NLP research in refugee law. Our methodology aims to be inclusive to all end-users and stakeholders, with expected benefits including reduced time-to-decision, fairer and more transparent outcomes, and improved decision quality.
Hamiltonian GAN
Aug 22, 2023
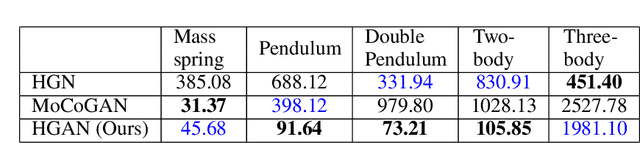
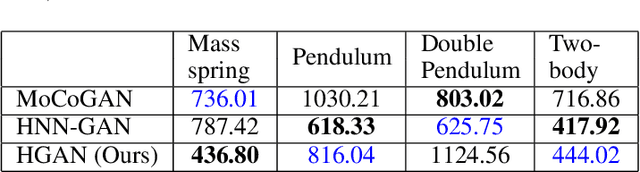

A growing body of work leverages the Hamiltonian formalism as an inductive bias for physically plausible neural network based video generation. The structure of the Hamiltonian ensures conservation of a learned quantity (e.g., energy) and imposes a phase-space interpretation on the low-dimensional manifold underlying the input video. While this interpretation has the potential to facilitate the integration of learned representations in downstream tasks, existing methods are limited in their applicability as they require a structural prior for the configuration space at design time. In this work, we present a GAN-based video generation pipeline with a learned configuration space map and Hamiltonian neural network motion model, to learn a representation of the configuration space from data. We train our model with a physics-inspired cyclic-coordinate loss function which encourages a minimal representation of the configuration space and improves interpretability. We demonstrate the efficacy and advantages of our approach on the Hamiltonian Dynamics Suite Toy Physics dataset.
Interpretable Distribution-Invariant Fairness Measures for Continuous Scores
Aug 22, 2023Measures of algorithmic fairness are usually discussed in the context of binary decisions. We extend the approach to continuous scores. So far, ROC-based measures have mainly been suggested for this purpose. Other existing methods depend heavily on the distribution of scores, are unsuitable for ranking tasks, or their effect sizes are not interpretable. Here, we propose a distributionally invariant version of fairness measures for continuous scores with a reasonable interpretation based on the Wasserstein distance. Our measures are easily computable and well suited for quantifying and interpreting the strength of group disparities as well as for comparing biases across different models, datasets, or time points. We derive a link between the different families of existing fairness measures for scores and show that the proposed distributionally invariant fairness measures outperform ROC-based fairness measures because they are more explicit and can quantify significant biases that ROC-based fairness measures miss. Finally, we demonstrate their effectiveness through experiments on the most commonly used fairness benchmark datasets.
Towards Autonomous Excavation Planning
Aug 22, 2023
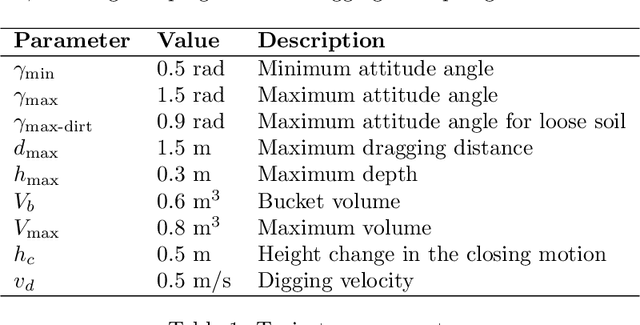
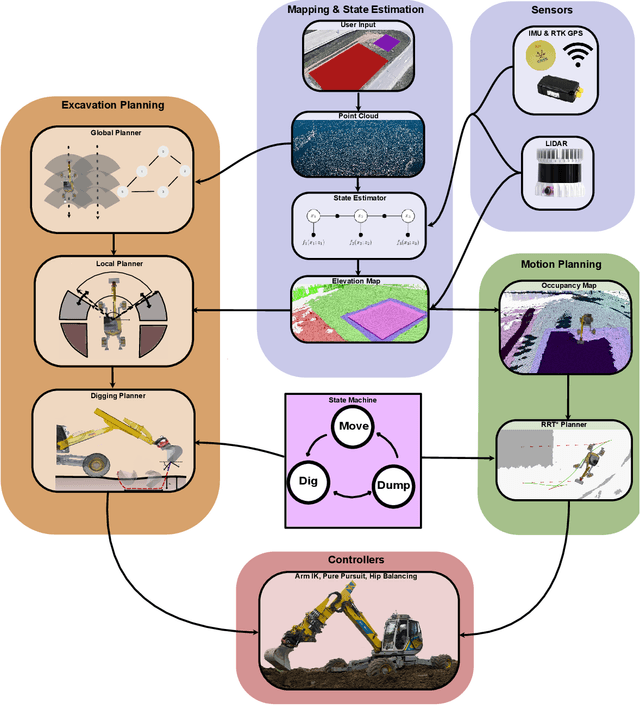

Excavation plans are crucial in construction projects, dictating the dirt disposal strategy and excavation sequence based on the final geometry and machinery available. While most construction processes rely heavily on coarse sequence planning and local execution planning driven by human expertise and intuition, fully automated planning tools are notably absent from the industry. This paper introduces a fully autonomous excavation planning system. Initially, the site is mapped, followed by user selection of the desired excavation geometry. The system then invokes a global planner to determine the sequence of poses for the excavator, ensuring complete site coverage. For each pose, a local excavation planner decides how to move the soil around the machine, and a digging planner subsequently dictates the sequence of digging trajectories to complete a patch. We showcased our system by autonomously excavating the largest pit documented so far, achieving an average digging cycle time of roughly 30 seconds, comparable to the one of a human operator.
Evaluation of Deep Neural Operator Models toward Ocean Forecasting
Aug 22, 2023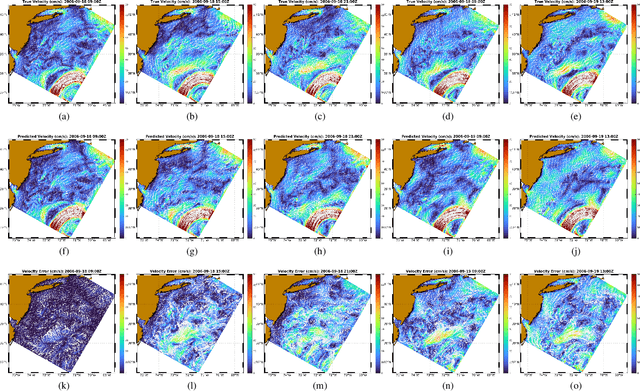
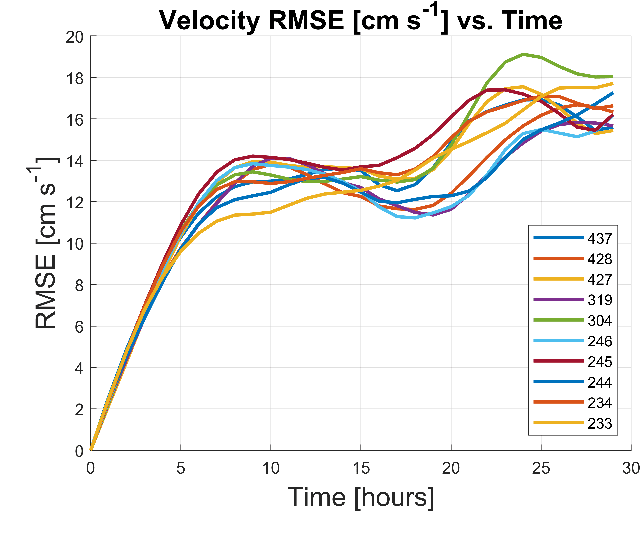
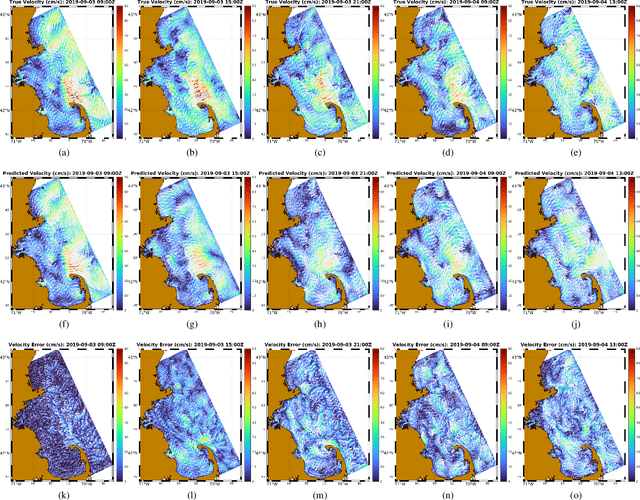
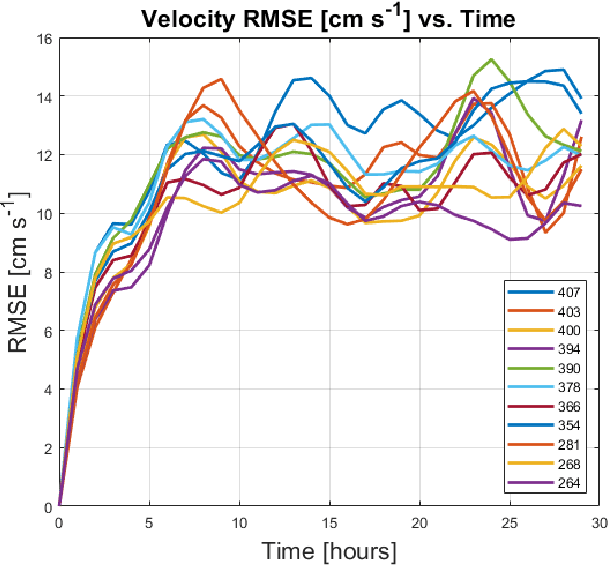
Data-driven, deep-learning modeling frameworks have been recently developed for forecasting time series data. Such machine learning models may be useful in multiple domains including the atmospheric and oceanic ones, and in general, the larger fluids community. The present work investigates the possible effectiveness of such deep neural operator models for reproducing and predicting classic fluid flows and simulations of realistic ocean dynamics. We first briefly evaluate the capabilities of such deep neural operator models when trained on a simulated two-dimensional fluid flow past a cylinder. We then investigate their application to forecasting ocean surface circulation in the Middle Atlantic Bight and Massachusetts Bay, learning from high-resolution data-assimilative simulations employed for real sea experiments. We confirm that trained deep neural operator models are capable of predicting idealized periodic eddy shedding. For realistic ocean surface flows and our preliminary study, they can predict several of the features and show some skill, providing potential for future research and applications.
Lifted Algorithms for Symmetric Weighted First-Order Model Sampling
Aug 17, 2023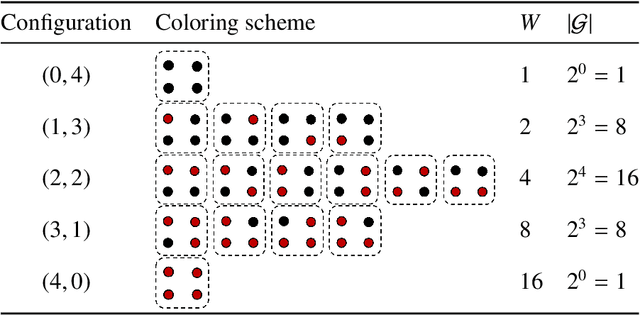
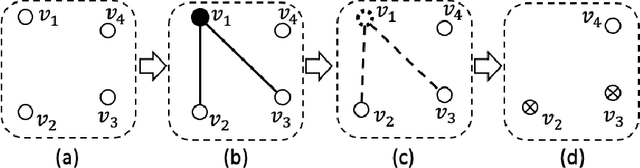
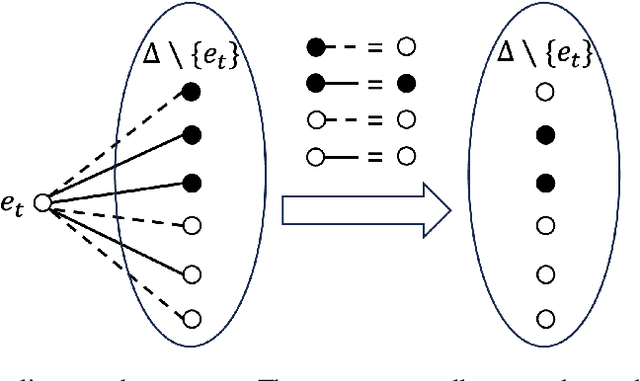
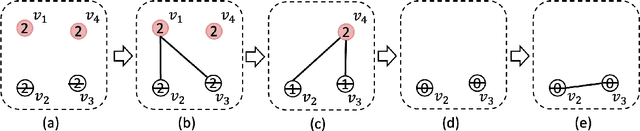
Weighted model counting (WMC) is the task of computing the weighted sum of all satisfying assignments (i.e., models) of a propositional formula. Similarly, weighted model sampling (WMS) aims to randomly generate models with probability proportional to their respective weights. Both WMC and WMS are hard to solve exactly, falling under the \#P-hard complexity class. However, it is known that the counting problem may sometimes be tractable, if the propositional formula can be compactly represented and expressed in first-order logic. In such cases, model counting problems can be solved in time polynomial in the domain size, and are known as \textit{domain-liftable}. The following question then arises: Is it also the case for weighted model sampling? This paper addresses this question and answers it affirmatively. Specifically, we prove the \textit{domain-liftability under sampling} for the two-variables fragment of first-order logic with counting quantifiers in this paper, by devising an efficient sampling algorithm for this fragment that runs in time polynomial in the domain size. We then further show that this result continues to hold even in the presence of cardinality constraints. To empirically verify our approach, we conduct experiments over various first-order formulas designed for the uniform generation of combinatorial structures and sampling in statistical-relational models. The results demonstrate that our algorithm outperforms a start-of-the-art WMS sampler by a substantial margin, confirming the theoretical results.