 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DELO: Deep Evidential LiDAR Odometry using Partial Optimal Transport
Aug 14, 2023
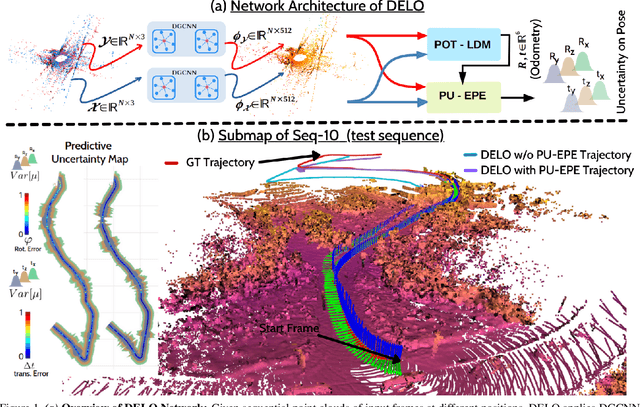
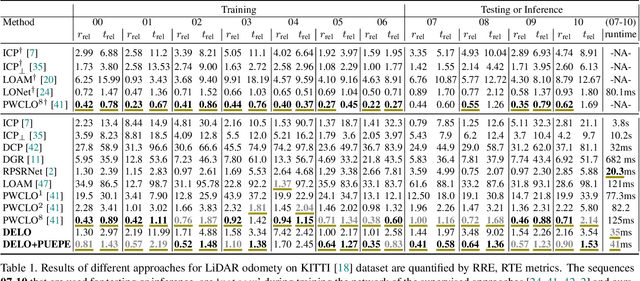
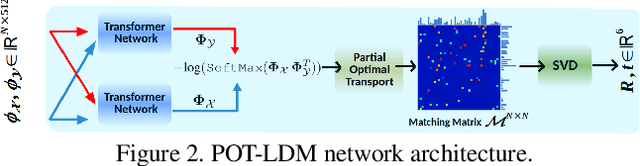
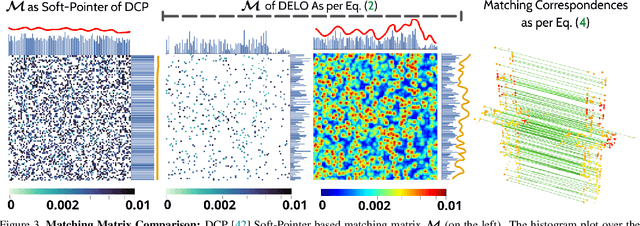
Accurate, robust, and real-time LiDAR-based odometry (LO) is imperative for many applications like robot navigation, globally consistent 3D scene map reconstruction, or safe motion-planning. Though LiDAR sensor is known for its precise range measurement, the non-uniform and uncertain point sampling density induce structural inconsistencies. Hence, existing supervised and unsupervised point set registration methods fail to establish one-to-one matching correspondences between LiDAR frames. We introduce a novel deep learning-based real-time (approx. 35-40ms per frame) LO method that jointly learns accurate frame-to-frame correspondences and model's predictive uncertainty (PU) as evidence to safe-guard LO predictions. In this work, we propose (i) partial optimal transportation of LiDAR feature descriptor for robust LO estimation, (ii) joint learning of predictive uncertainty while learning odometry over driving sequences, and (iii) demonstrate how PU can serve as evidence for necessary pose-graph optimization when LO network is either under or over confident. We evaluate our method on KITTI dataset and show competitive performance, even superior generalization ability over recent state-of-the-art approaches. Source codes are available.
Model Predictive Contouring Control for Vehicle Obstacle Avoidance at the Limit of Handling
Aug 13, 2023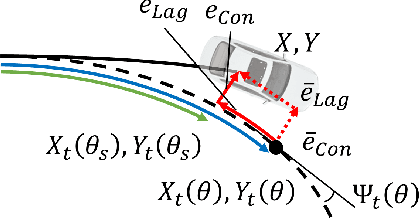
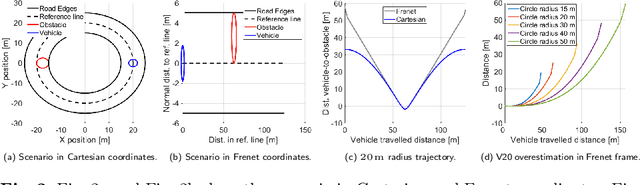
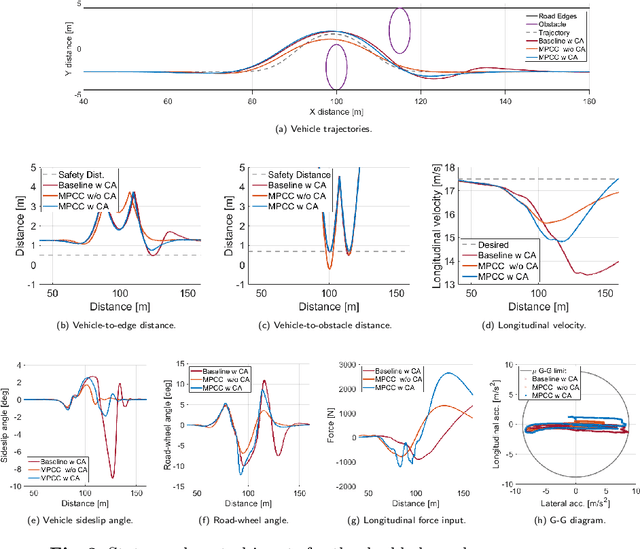
This paper proposes a non-linear Model Predictive Contouring Control (MPCC) for obstacle avoidance in automated vehicles driven at the limit of handling. The proposed controller integrates motion planning, path tracking and vehicle stability objectives, prioritising obstacle avoidance in emergencies. The controller's prediction model is a non-linear single-track vehicle model with the Fiala tyre to capture the vehicle's non-linear behaviour. The MPCC computes the optimal steering angle and brake torques to minimise tracking error in safe situations and maximise the vehicle-to-obstacle distance in emergencies. Furthermore, the MPCC is extended with the tyre friction circle to fully exploit the vehicle's manoeuvrability and stability. The MPCC controller is tested using real-time rapid prototyping hardware to prove its real-time capability. The performance is compared with a state-of-the-art Model Predictive Control (MPC) in a high-fidelity simulation environment. The double lane change scenario results demonstrate a significant improvement in successfully avoiding obstacles and maintaining vehicle stability.
A 3-step Low-latency Low-Power Multichannel Time-to-Digital Converter based on Time Residual Amplifier
Jun 01, 2023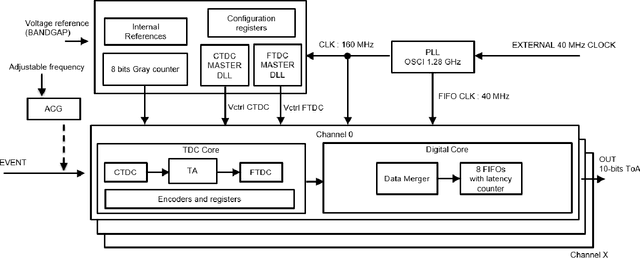
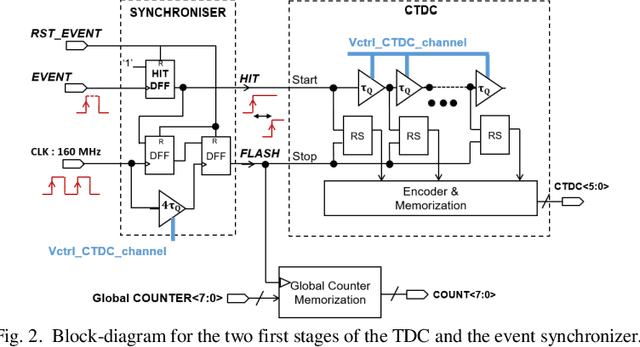
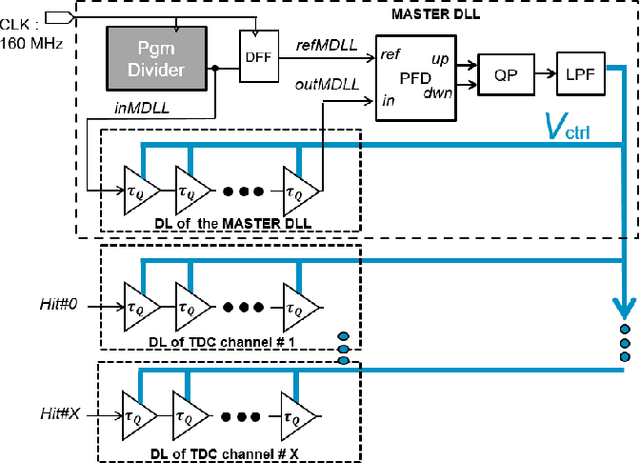
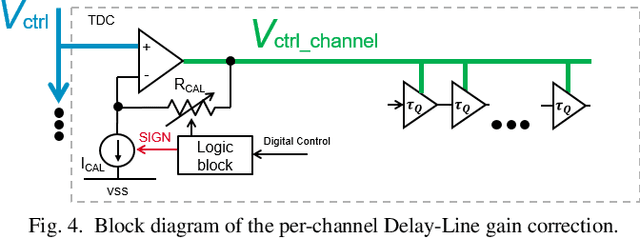
This paper proposes and evaluates a novel architecture for a low-power Time-to-Digital Converter with high resolution, optimized for both integration in multichannel chips and high rate operation (40 Mconversion/s/channel). This converter is based on a three-step architecture. The first step uses a counter whereas the following ones are based on two kinds of Delay Line structures. A programmable time amplifier is used between the second and third steps to reach the final resolution of 24.4 ps in the standard mode of operation. The system makes use of common continuously stabilized master blocks that control trimmable slave blocks, in each channel, against the effects of global PVT variations. Thanks to this structure, the power consumption of a channel is considerably reduced when it does not process a hit, and limited to 2.2 mW when it processes a hit. In the 130 nm CMOS technology used for the prototype, the area of a TDC channel is only 0.051 mm2. This compactness combined with low power consumption is a key advantage for integration in multi-channel front-end chips. The performance of this new structure has been evaluated on prototype chips. Measurements show excellent timing performance over a wide range of operating temperatures (-40{\deg}C to 60{\deg}C) in agreement with our expectations. For example, the measured timing integral nonlinearity is better than 1 LSB (25 ps) and the overall timing precision is better than 21 ps RMS.
Modeling Player Personality Factors from In-Game Behavior and Affective Expression
Aug 27, 2023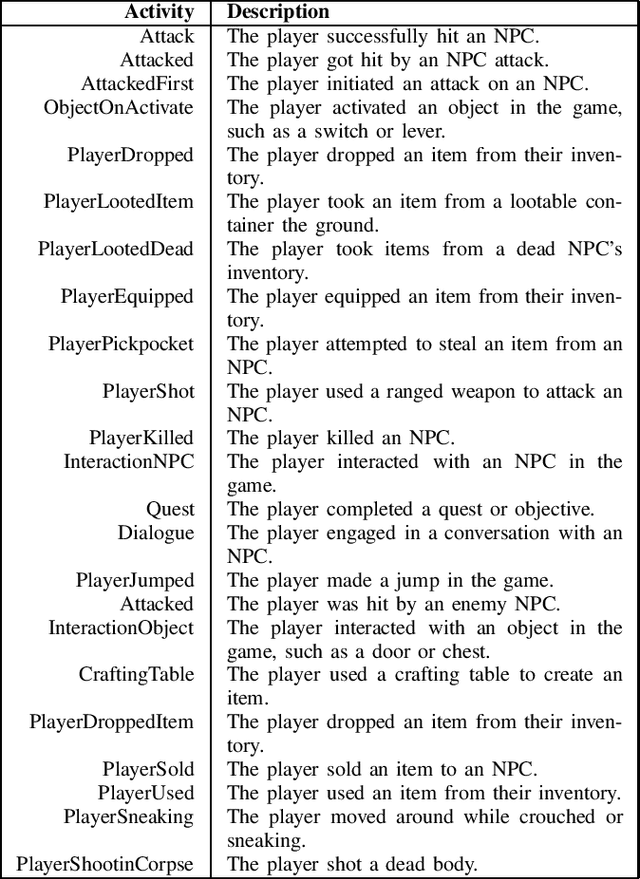
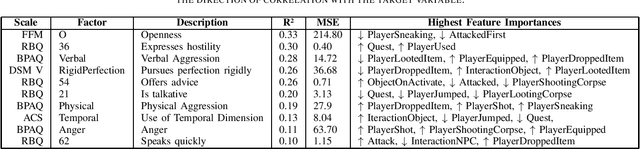
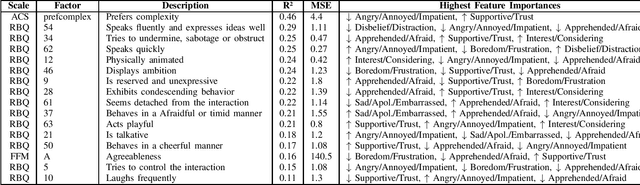
Developing a thorough understanding of the target audience (and/or single individuals) is a key factor for success - which is exceptionally important and powerful for the domain of video games that can not only benefit from informed decision making during development, but ideally even tailor game content, difficulty and player experience while playing. The granular assessment of individual personality and differences across players is a particularly difficult endeavor, given the highly variant human nature, disagreement in psychological background models and because of the effortful data collection that most often builds upon long, time-consuming and deterrent questionnaires. In this work, we explore possibilities to predict a series of player personality questionnaire metrics from recorded in-game behavior and extend related work by explicitly adding affective dialog decisions to the game environment which could elevate the model's accuracy. Using random forest regression, we predicted a wide variety of personality metrics from seven established questionnaires across 62 players over 60 minute gameplay of a customized version of the role-playing game Fallout: New Vegas. While some personality variables could already be identified from reasonable underlying in-game actions and affective expressions, we did not find ways to predict others or encountered questionable correlations that could not be justified by theoretical background literature. Yet, building on the initial opportunities of this explorative study, we are striving to massively enlarge our data set to players from an ecologically valid industrial game environment and investigate the performance of more sophisticated machine learning approaches.
ZeroLeak: Using LLMs for Scalable and Cost Effective Side-Channel Patching
Aug 24, 2023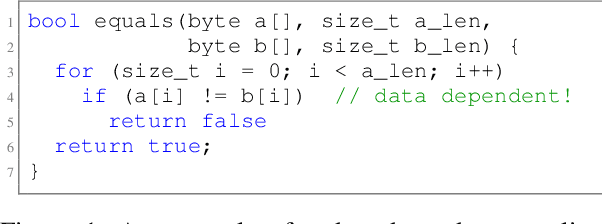

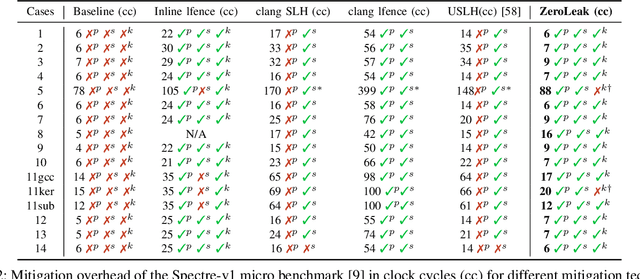
Security critical software, e.g., OpenSSL, comes with numerous side-channel leakages left unpatched due to a lack of resources or experts. The situation will only worsen as the pace of code development accelerates, with developers relying on Large Language Models (LLMs) to automatically generate code. In this work, we explore the use of LLMs in generating patches for vulnerable code with microarchitectural side-channel leakages. For this, we investigate the generative abilities of powerful LLMs by carefully crafting prompts following a zero-shot learning approach. All generated code is dynamically analyzed by leakage detection tools, which are capable of pinpointing information leakage at the instruction level leaked either from secret dependent accesses or branches or vulnerable Spectre gadgets, respectively. Carefully crafted prompts are used to generate candidate replacements for vulnerable code, which are then analyzed for correctness and for leakage resilience. From a cost/performance perspective, the GPT4-based configuration costs in API calls a mere few cents per vulnerability fixed. Our results show that LLM-based patching is far more cost-effective and thus provides a scalable solution. Finally, the framework we propose will improve in time, especially as vulnerability detection tools and LLMs mature.
Not Only Rewards But Also Constraints: Applications on Legged Robot Locomotion
Aug 24, 2023
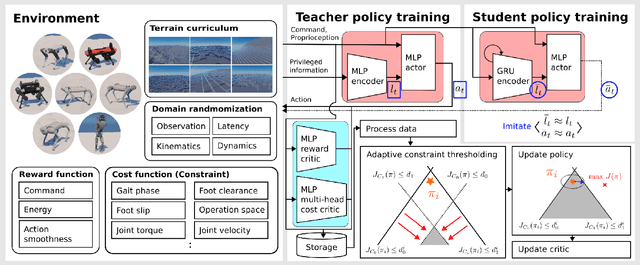
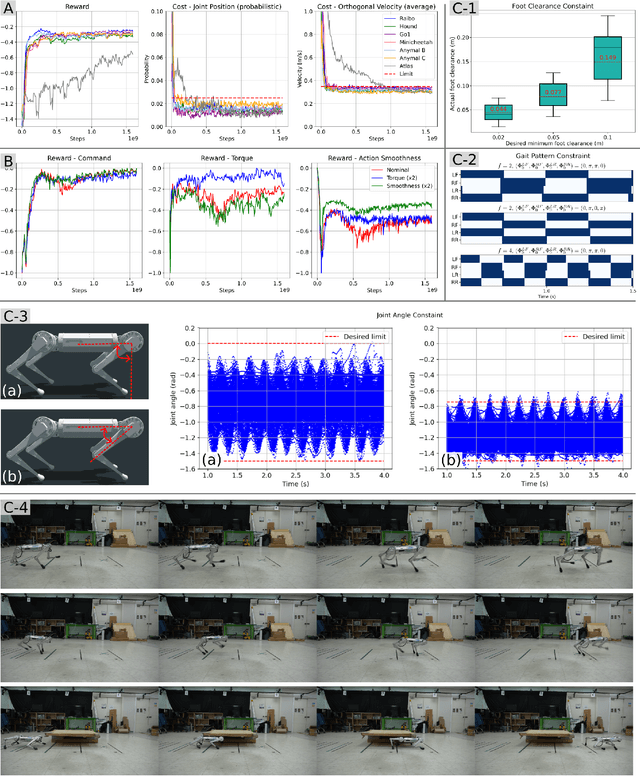

Several earlier studies have shown impressive control performance in complex robotic systems by designing the controller using a neural network and training it with model-free reinforcement learning. However, these outstanding controllers with natural motion style and high task performance are developed through extensive reward engineering, which is a highly laborious and time-consuming process of designing numerous reward terms and determining suitable reward coefficients. In this work, we propose a novel reinforcement learning framework for training neural network controllers for complex robotic systems consisting of both rewards and constraints. To let the engineers appropriately reflect their intent to constraints and handle them with minimal computation overhead, two constraint types and an efficient policy optimization algorithm are suggested. The learning framework is applied to train locomotion controllers for several legged robots with different morphology and physical attributes to traverse challenging terrains. Extensive simulation and real-world experiments demonstrate that performant controllers can be trained with significantly less reward engineering, by tuning only a single reward coefficient. Furthermore, a more straightforward and intuitive engineering process can be utilized, thanks to the interpretability and generalizability of constraints. The summary video is available at https://youtu.be/KAlm3yskhvM.
Synchronize Feature Extracting and Matching: A Single Branch Framework for 3D Object Tracking
Aug 24, 2023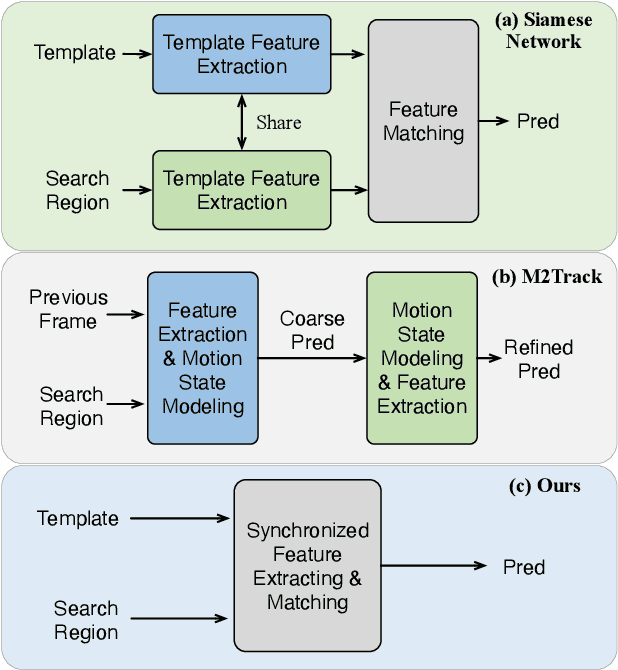
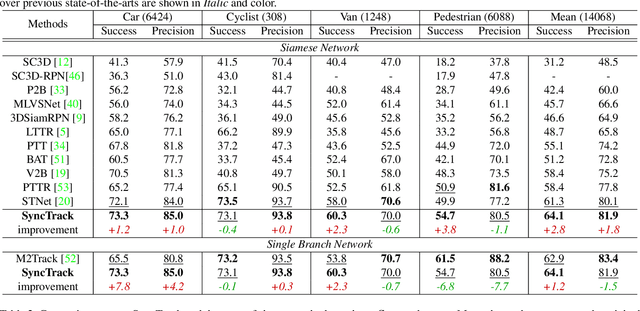
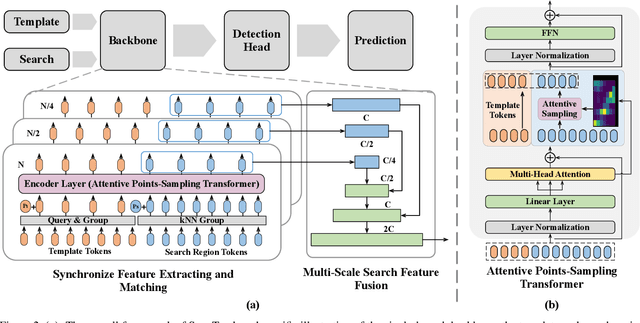
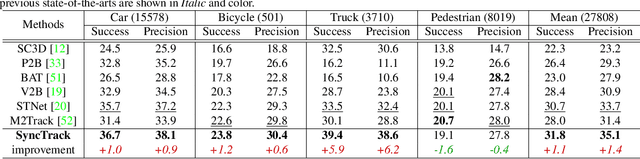
Siamese network has been a de facto benchmark framework for 3D LiDAR object tracking with a shared-parametric encoder extracting features from template and search region, respectively. This paradigm relies heavily on an additional matching network to model the cross-correlation/similarity of the template and search region. In this paper, we forsake the conventional Siamese paradigm and propose a novel single-branch framework, SyncTrack, synchronizing the feature extracting and matching to avoid forwarding encoder twice for template and search region as well as introducing extra parameters of matching network. The synchronization mechanism is based on the dynamic affinity of the Transformer, and an in-depth analysis of the relevance is provided theoretically. Moreover, based on the synchronization, we introduce a novel Attentive Points-Sampling strategy into the Transformer layers (APST), replacing the random/Farthest Points Sampling (FPS) method with sampling under the supervision of attentive relations between the template and search region. It implies connecting point-wise sampling with the feature learning, beneficial to aggregating more distinctive and geometric features for tracking with sparse points. Extensive experiments on two benchmark datasets (KITTI and NuScenes) show that SyncTrack achieves state-of-the-art performance in real-time tracking.
A Greedy Approach for Offering to Telecom Subscribers
Aug 24, 2023Customer retention or churn prevention is a challenging task of a telecom operator. One of the effective approaches is to offer some attractive incentive or additional services or money to the subscribers for keeping them engaged and make sure they stay in the operator's network for longer time. Often, operators allocate certain amount of monetary budget to carry out the offer campaign. The difficult part of this campaign is the selection of a set of customers from a large subscriber-base and deciding the amount that should be offered to an individual so that operator's objective is achieved. There may be multiple objectives (e.g., maximizing revenue, minimizing number of churns) for selection of subscriber and selection of an offer to the selected subscriber. Apart from monetary benefit, offers may include additional data, SMS, hots-spot tethering, and many more. This problem is known as offer optimization. In this paper, we propose a novel combinatorial algorithm for solving offer optimization under heterogeneous offers by maximizing expected revenue under the scenario of subscriber churn, which is, in general, seen in telecom domain. The proposed algorithm is efficient and accurate even for a very large subscriber-base.
Hybrid noise shaping for audio coding using perfectly overlapped window
Aug 24, 2023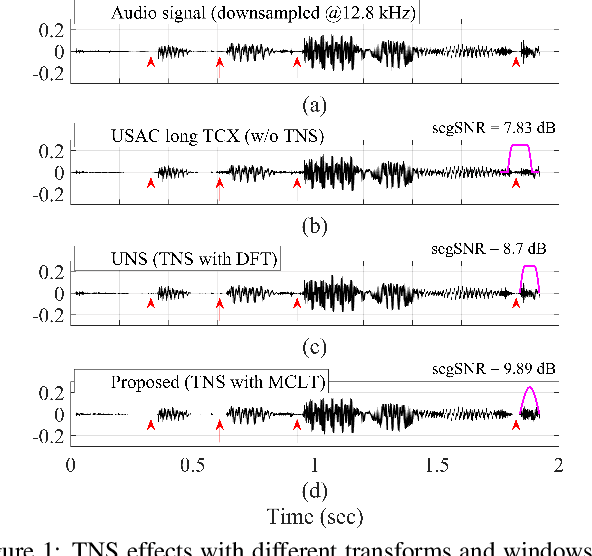
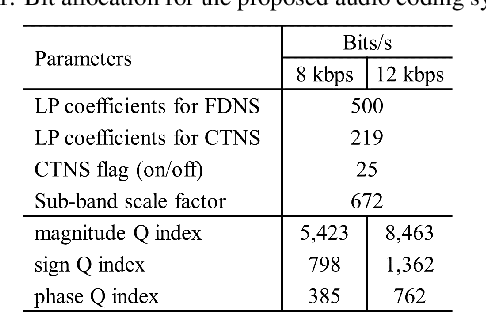
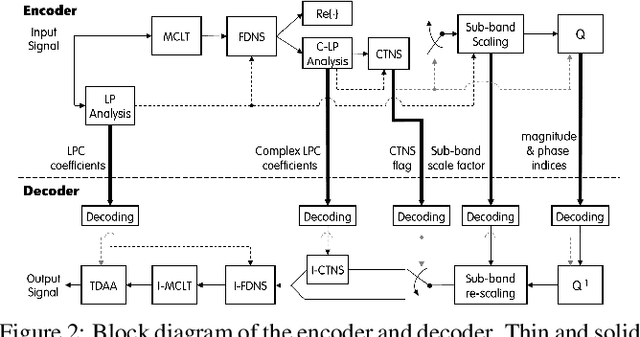
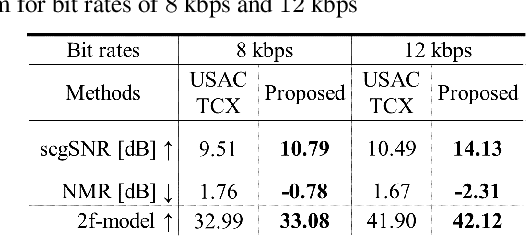
In recent years, audio coding technology has been standardized based on several frameworks that incorporate linear predictive coding (LPC). However, coding the transient signal using frequency-domain LP residual signals remains a challenge. To address this, temporal noise shaping (TNS) can be adapted, although it cannot be effectively operated since the estimated temporal envelope in the modified discrete cosine transform (MDCT) domain is accompanied by the time-domain aliasing (TDA) terms. In this study, we propose the modulated complex lapped transform-based coding framework integrated with transform coded excitation (TCX) and complex LPC-based TNS (CTNS). Our approach uses a 50\% overlap window and switching scheme for the CTNS to improve the coding efficiency. Additionally, an adaptive calculation of the target bits for the sub-bands using the frequency envelope information based on the quantized LPC coefficients is proposed. To minimize the quantization mismatch between both modes, an integrated quantization for real and complex values and a TDA augmentation method that compensates for the artificially generated TDA components during switching operations are proposed. The proposed coding framework shows a superior performance in both objective metrics and subjective listening tests, thereby demonstrating its low bit-rate audio coding.
Intentionally-underestimated Value Function at Terminal State for Temporal-difference Learning with Mis-designed Reward
Aug 24, 2023Robot control using reinforcement learning has become popular, but its learning process generally terminates halfway through an episode for safety and time-saving reasons. This study addresses the problem of the most popular exception handling that temporal-difference (TD) learning performs at such termination. That is, by forcibly assuming zero value after termination, unintentionally implicit underestimation or overestimation occurs, depending on the reward design in the normal states. When the episode is terminated due to task failure, the failure may be highly valued with the unintentional overestimation, and the wrong policy may be acquired. Although this problem can be avoided by paying attention to the reward design, it is essential in practical use of TD learning to review the exception handling at termination. This paper therefore proposes a method to intentionally underestimate the value after termination to avoid learning failures due to the unintentional overestimation. In addition, the degree of underestimation is adjusted according to the degree of stationarity at termination, thereby preventing excessive exploration due to the intentional underestimation. Simulations and real robot experiments showed that the proposed method can stably obtain the optimal policies for various tasks and reward designs. https://youtu.be/AxXr8uFOe7M