 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Learning of Temporal Distinctiveness for Survival Analysis in Electronic Health Records
Aug 24, 2023
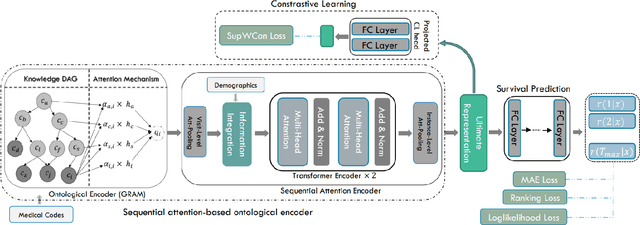

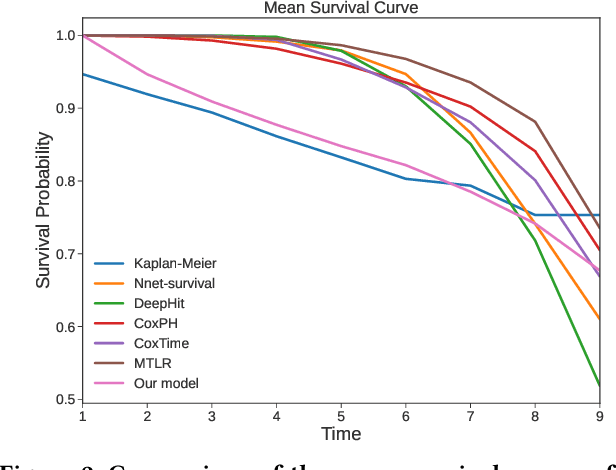
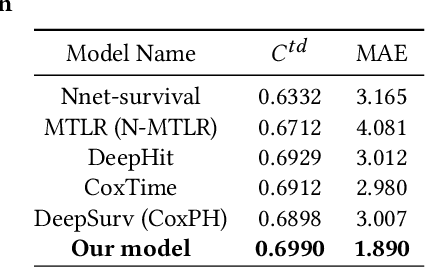
Survival analysis plays a crucial role in many healthcare decisions, where the risk prediction for the events of interest can support an informative outlook for a patient's medical journey. Given the existence of data censoring, an effective way of survival analysis is to enforce the pairwise temporal concordance between censored and observed data, aiming to utilize the time interval before censoring as partially observed time-to-event labels for supervised learning. Although existing studies mostly employed ranking methods to pursue an ordering objective, contrastive methods which learn a discriminative embedding by having data contrast against each other, have not been explored thoroughly for survival analysis. Therefore, in this paper, we propose a novel Ontology-aware Temporality-based Contrastive Survival (OTCSurv) analysis framework that utilizes survival durations from both censored and observed data to define temporal distinctiveness and construct negative sample pairs with adjustable hardness for contrastive learning. Specifically, we first use an ontological encoder and a sequential self-attention encoder to represent the longitudinal EHR data with rich contexts. Second, we design a temporal contrastive loss to capture varying survival durations in a supervised setting through a hardness-aware negative sampling mechanism. Last, we incorporate the contrastive task into the time-to-event predictive task with multiple loss components. We conduct extensive experiments using a large EHR dataset to forecast the risk of hospitalized patients who are in danger of developing acute kidney injury (AKI), a critical and urgent medical condition. The effectiveness and explainability of the proposed model are validated through comprehensive quantitative and qualitative studies.
Multilingual Text Representation
Sep 02, 2023Modern NLP breakthrough includes large multilingual models capable of performing tasks across more than 100 languages. State-of-the-art language models came a long way, starting from the simple one-hot representation of words capable of performing tasks like natural language understanding, common-sense reasoning, or question-answering, thus capturing both the syntax and semantics of texts. At the same time, language models are expanding beyond our known language boundary, even competitively performing over very low-resource dialects of endangered languages. However, there are still problems to solve to ensure an equitable representation of texts through a unified modeling space across language and speakers. In this survey, we shed light on this iterative progression of multilingual text representation and discuss the driving factors that ultimately led to the current state-of-the-art. Subsequently, we discuss how the full potential of language democratization could be obtained, reaching beyond the known limits and what is the scope of improvement in that space.
Bypassing the Simulator: Near-Optimal Adversarial Linear Contextual Bandits
Sep 02, 2023
We consider the adversarial linear contextual bandit problem, where the loss vectors are selected fully adversarially and the per-round action set (i.e. the context) is drawn from a fixed distribution. Existing methods for this problem either require access to a simulator to generate free i.i.d. contexts, achieve a sub-optimal regret no better than $\widetilde{O}(T^{\frac{5}{6}})$, or are computationally inefficient. We greatly improve these results by achieving a regret of $\widetilde{O}(\sqrt{T})$ without a simulator, while maintaining computational efficiency when the action set in each round is small. In the special case of sleeping bandits with adversarial loss and stochastic arm availability, our result answers affirmatively the open question by Saha et al. [2020] on whether there exists a polynomial-time algorithm with $poly(d)\sqrt{T}$ regret. Our approach naturally handles the case where the loss is linear up to an additive misspecification error, and our regret shows near-optimal dependence on the magnitude of the error.
Neuro-symbolic Empowered Denoising Diffusion Probabilistic Models for Real-time Anomaly Detection in Industry 4.0
Jul 13, 2023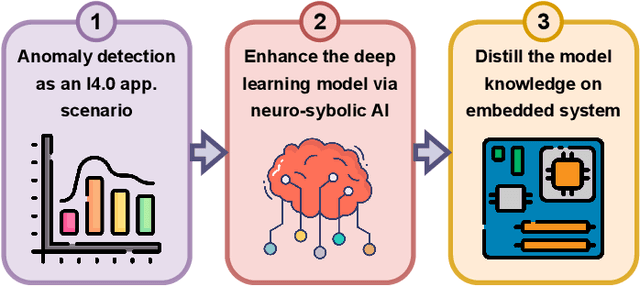
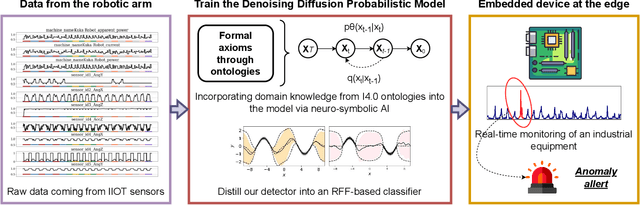
Industry 4.0 involves the integration of digital technologies, such as IoT, Big Data, and AI, into manufacturing and industrial processes to increase efficiency and productivity. As these technologies become more interconnected and interdependent, Industry 4.0 systems become more complex, which brings the difficulty of identifying and stopping anomalies that may cause disturbances in the manufacturing process. This paper aims to propose a diffusion-based model for real-time anomaly prediction in Industry 4.0 processes. Using a neuro-symbolic approach, we integrate industrial ontologies in the model, thereby adding formal knowledge on smart manufacturing. Finally, we propose a simple yet effective way of distilling diffusion models through Random Fourier Features for deployment on an embedded system for direct integration into the manufacturing process. To the best of our knowledge, this approach has never been explored before.
Solving Attention Kernel Regression Problem via Pre-conditioner
Aug 28, 2023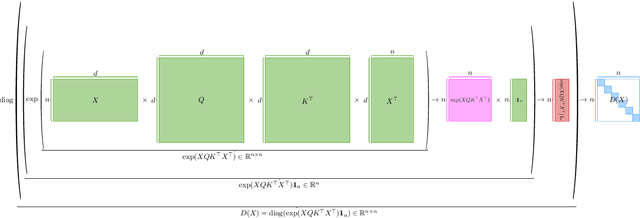
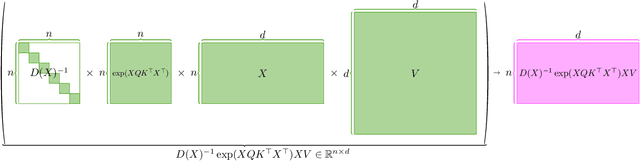
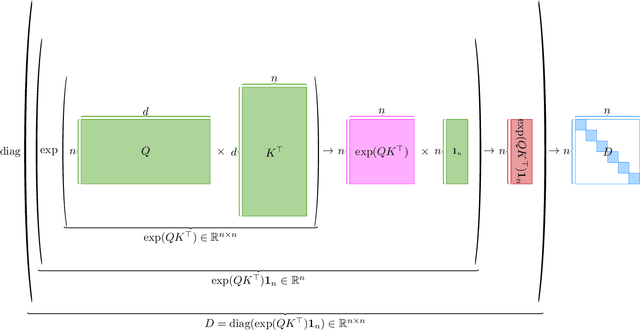
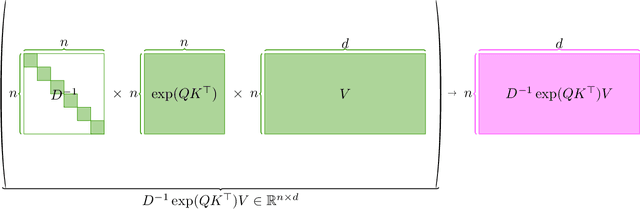
Large language models have shown impressive performance in many tasks. One of the major features from the computation perspective is computing the attention matrix. Previous works [Zandieh, Han, Daliri, and Karba 2023, Alman and Song 2023] have formally studied the possibility and impossibility of approximating the attention matrix. In this work, we define and study a new problem which is called the attention kernel regression problem. We show how to solve the attention kernel regression in the input sparsity time of the data matrix.
Neural Differential Recurrent Neural Network with Adaptive Time Steps
Jun 02, 2023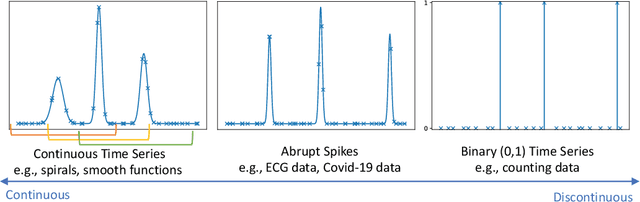

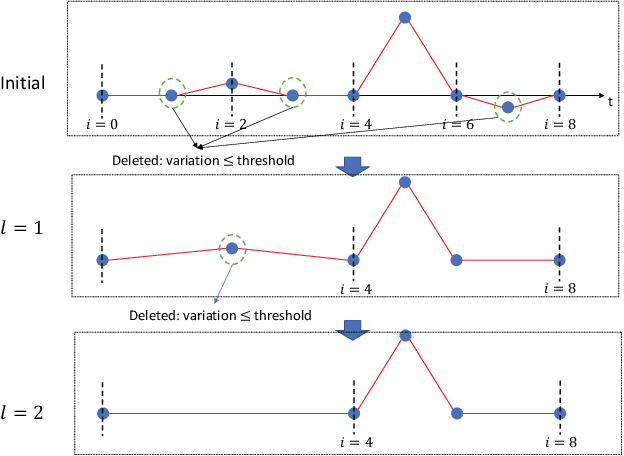
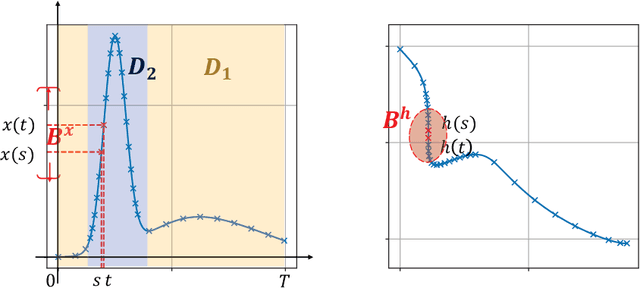
The neural Ordinary Differential Equation (ODE) model has shown success in learning complex continuous-time processes from observations on discrete time stamps. In this work, we consider the modeling and forecasting of time series data that are non-stationary and may have sharp changes like spikes. We propose an RNN-based model, called RNN-ODE-Adap, that uses a neural ODE to represent the time development of the hidden states, and we adaptively select time steps based on the steepness of changes of the data over time so as to train the model more efficiently for the "spike-like" time series. Theoretically, RNN-ODE-Adap yields provably a consistent estimation of the intensity function for the Hawkes-type time series data. We also provide an approximation analysis of the RNN-ODE model showing the benefit of adaptive steps. The proposed model is demonstrated to achieve higher prediction accuracy with reduced computational cost on simulated dynamic system data and point process data and on a real electrocardiography dataset.
Non-autoregressive Conditional Diffusion Models for Time Series Prediction
Jun 08, 2023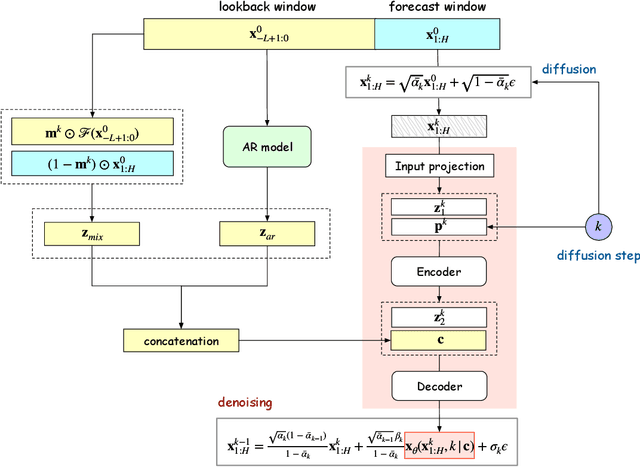
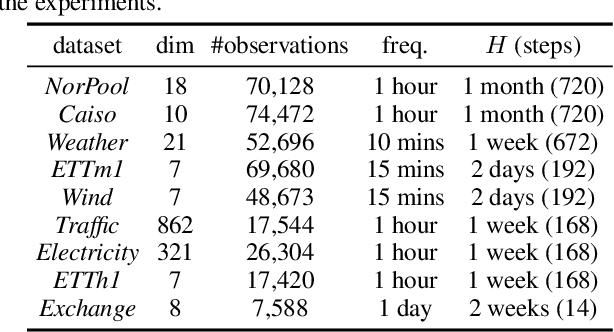
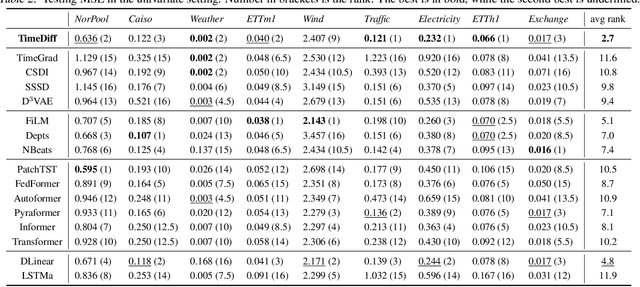
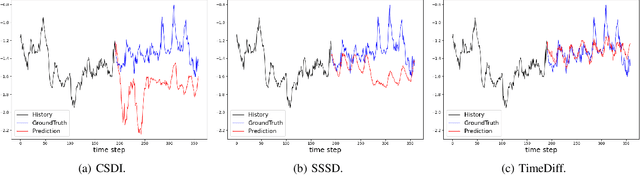
Recently, denoising diffusion models have led to significant breakthroughs in the generation of images, audio and text. However, it is still an open question on how to adapt their strong modeling ability to model time series. In this paper, we propose TimeDiff, a non-autoregressive diffusion model that achieves high-quality time series prediction with the introduction of two novel conditioning mechanisms: future mixup and autoregressive initialization. Similar to teacher forcing, future mixup allows parts of the ground-truth future predictions for conditioning, while autoregressive initialization helps better initialize the model with basic time series patterns such as short-term trends. Extensive experiments are performed on nine real-world datasets. Results show that TimeDiff consistently outperforms existing time series diffusion models, and also achieves the best overall performance across a variety of the existing strong baselines (including transformers and FiLM).
Non-parametric Probabilistic Time Series Forecasting via Innovations Representation
Jun 05, 2023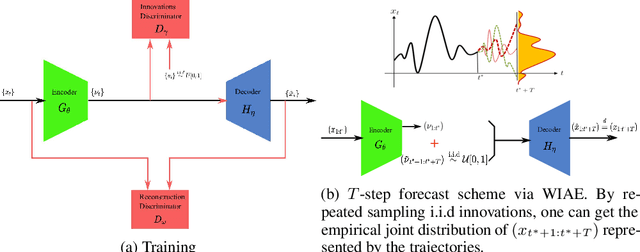
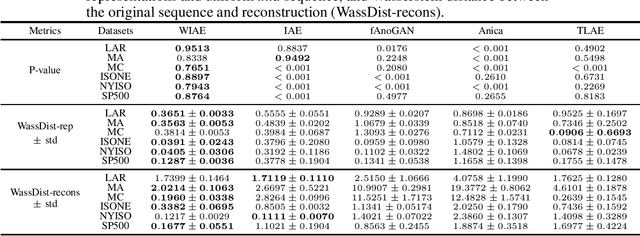
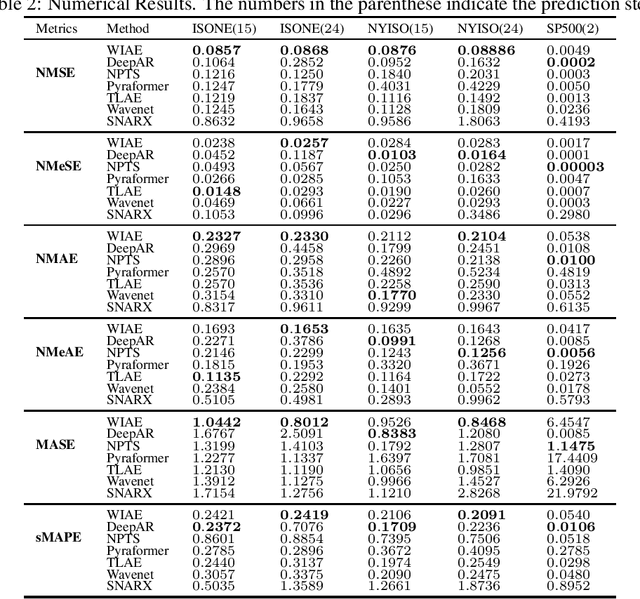
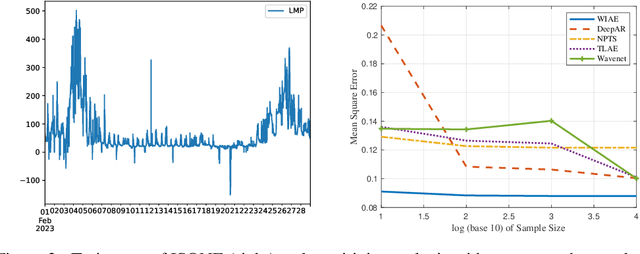
Probabilistic time series forecasting predicts the conditional probability distributions of the time series at a future time given past realizations. Such techniques are critical in risk-based decision-making and planning under uncertainties. Existing approaches are primarily based on parametric or semi-parametric time-series models that are restrictive, difficult to validate, and challenging to adapt to varying conditions. This paper proposes a nonparametric method based on the classic notion of {\em innovations} pioneered by Norbert Wiener and Gopinath Kallianpur that causally transforms a nonparametric random process to an independent and identical uniformly distributed {\em innovations process}. We present a machine-learning architecture and a learning algorithm that circumvent two limitations of the original Wiener-Kallianpur innovations representation: (i) the need for known probability distributions of the time series and (ii) the existence of a causal decoder that reproduces the original time series from the innovations representation. We develop a deep-learning approach and a Monte Carlo sampling technique to obtain a generative model for the predicted conditional probability distribution of the time series based on a weak notion of Wiener-Kallianpur innovations representation. The efficacy of the proposed probabilistic forecasting technique is demonstrated on a variety of electricity price datasets, showing marked improvement over leading benchmarks of probabilistic forecasting techniques.
Launch Power Optimization for Dynamic Elastic Optical Networks over C+L Bands
Aug 25, 2023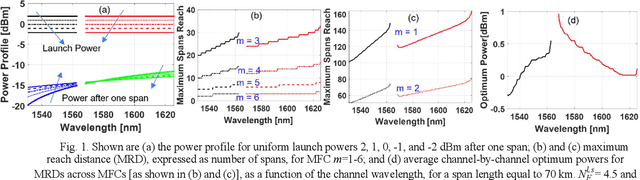


We propose an algorithm for calculating the optimum launch power over the entire C+L bands by maximizing the cumulative link GSNR of a channel plan built upon multiple modulation formats, with application to dynamic EONs. Exact last-fit spectrum assignment proves to outperform exact first-fit in terms of average GSNR at arrival time.
LiDAR-BEVMTN: Real-Time LiDAR Bird's-Eye View Multi-Task Perception Network for Autonomous Driving
Jul 17, 2023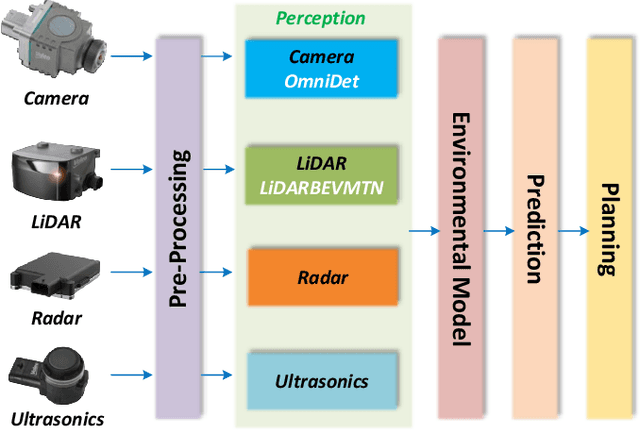

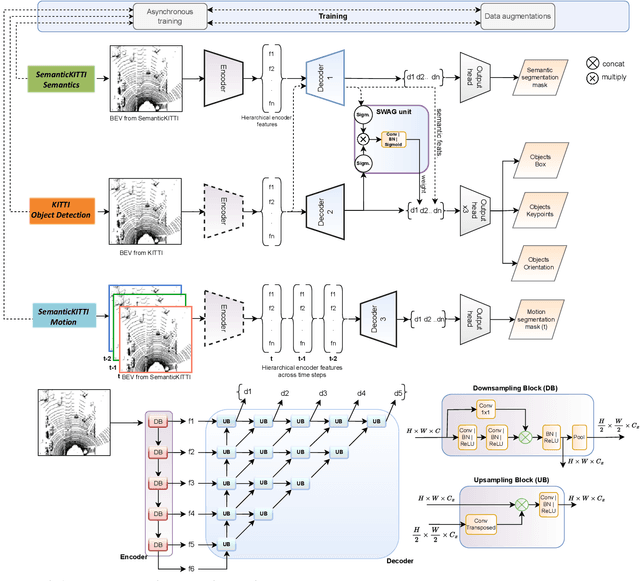

LiDAR is crucial for robust 3D scene perception in autonomous driving. LiDAR perception has the largest body of literature after camera perception. However, multi-task learning across tasks like detection, segmentation, and motion estimation using LiDAR remains relatively unexplored, especially on automotive-grade embedded platforms. We present a real-time multi-task convolutional neural network for LiDAR-based object detection, semantics, and motion segmentation. The unified architecture comprises a shared encoder and task-specific decoders, enabling joint representation learning. We propose a novel Semantic Weighting and Guidance (SWAG) module to transfer semantic features for improved object detection selectively. Our heterogeneous training scheme combines diverse datasets and exploits complementary cues between tasks. The work provides the first embedded implementation unifying these key perception tasks from LiDAR point clouds achieving 3ms latency on the embedded NVIDIA Xavier platform. We achieve state-of-the-art results for two tasks, semantic and motion segmentation, and close to state-of-the-art performance for 3D object detection. By maximizing hardware efficiency and leveraging multi-task synergies, our method delivers an accurate and efficient solution tailored for real-world automated driving deployment. Qualitative results can be seen at https://youtu.be/H-hWRzv2lIY.