 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fully Onboard SLAM for Distributed Mapping with a Swarm of Nano-Drones
Sep 07, 2023
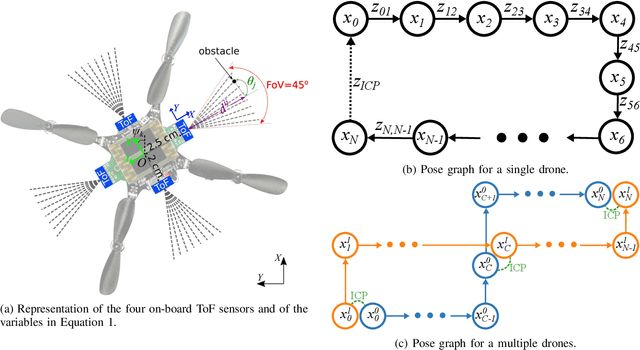
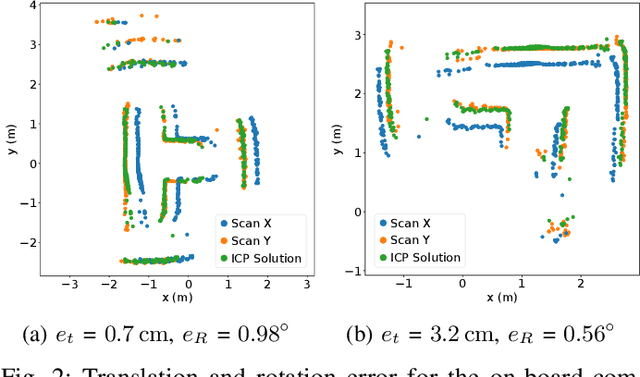
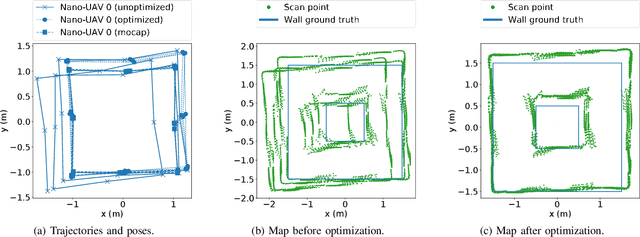
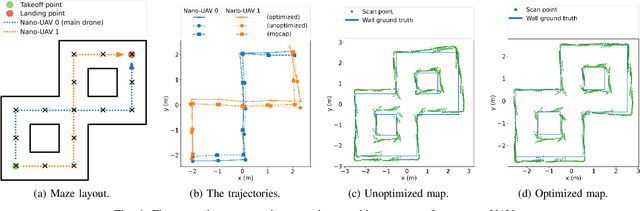
The use of Unmanned Aerial Vehicles (UAVs) is rapidly increasing in applications ranging from surveillance and first-aid missions to industrial automation involving cooperation with other machines or humans. To maximize area coverage and reduce mission latency, swarms of collaborating drones have become a significant research direction. However, this approach requires open challenges in positioning, mapping, and communications to be addressed. This work describes a distributed mapping system based on a swarm of nano-UAVs, characterized by a limited payload of 35 g and tightly constrained on-board sensing and computing capabilities. Each nano-UAV is equipped with four 64-pixel depth sensors that measure the relative distance to obstacles in four directions. The proposed system merges the information from the swarm and generates a coherent grid map without relying on any external infrastructure. The data fusion is performed using the iterative closest point algorithm and a graph-based simultaneous localization and mapping algorithm, running entirely on-board the UAV's low-power ARM Cortex-M microcontroller with just 192 kB of SRAM memory. Field results gathered in three different mazes from a swarm of up to 4 nano-UAVs prove a mapping accuracy of 12 cm and demonstrate that the mapping time is inversely proportional to the number of agents. The proposed framework scales linearly in terms of communication bandwidth and on-board computational complexity, supporting communication between up to 20 nano-UAVs and mapping of areas up to 180 m2 with the chosen configuration requiring only 50 kB of memory.
Modulation and Estimation with a Helper
Sep 08, 2023The problem of transmitting a parameter value over an additive white Gaussian noise (AWGN) channel is considered, where, in addition to the transmitter and the receiver, there is a helper that observes the noise non-causally and provides a description of limited rate $R_\mathrm{h}$ to the transmitter and/or the receiver. We derive upper and lower bounds on the optimal achievable $\alpha$-th moment of the estimation error and show that they coincide for small values of $\alpha$ and for low SNR values. The upper bound relies on a recently proposed channel-coding scheme that effectively conveys $R_\mathrm{h}$ bits essentially error-free and the rest of the rate - over the same AWGN channel without help, with the error-free bits allocated to the most significant bits of the quantized parameter. We then concentrate on the setting with a total transmit energy constraint, for which we derive achievability results for both channel coding and parameter modulation for several scenarios: when the helper assists only the transmitter or only the receiver and knows the noise, and when the helper assists the transmitter and/or the receiver and knows both the noise and the message. In particular, for the message-informed helper that assists both the receiver and the transmitter, it is shown that the error probability in the channel-coding task decays doubly exponentially. Finally, we translate these results to those for continuous-time power-limited AWGN channels with unconstrained bandwidth. As a byproduct, we show that the capacity with a message-informed helper that is available only at the transmitter can exceed the capacity of the same scenario when the helper knows only the noise but not the message.
NESTLE: a No-Code Tool for Statistical Analysis of Legal Corpus
Sep 08, 2023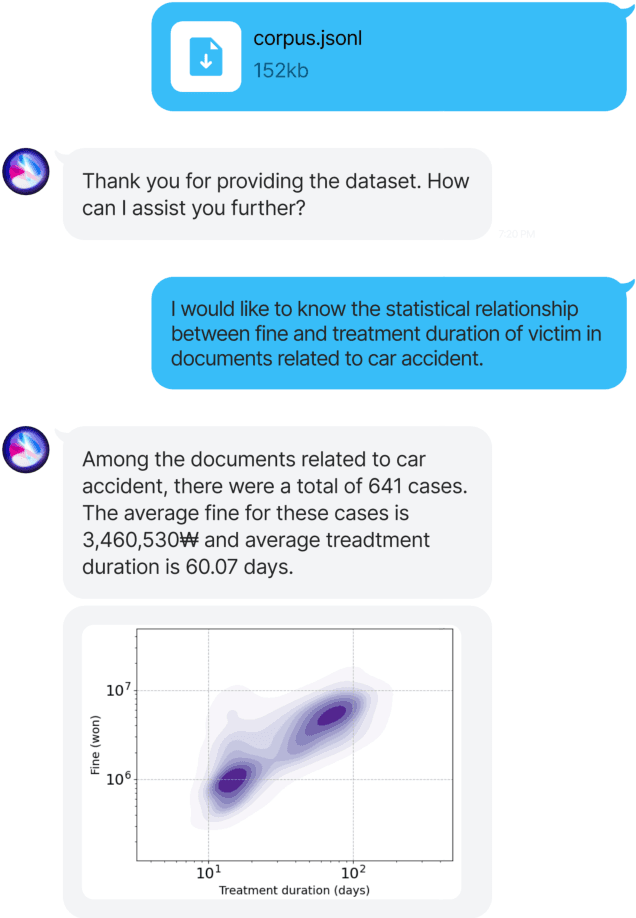
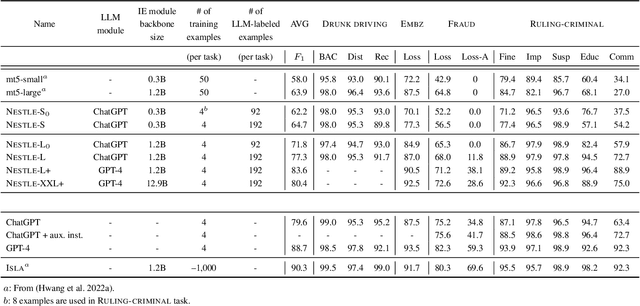
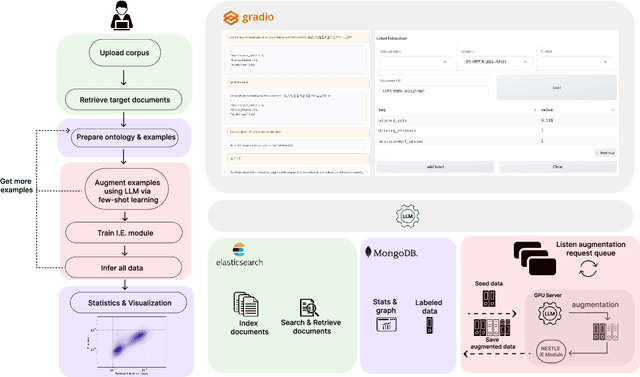

The statistical analysis of large scale legal corpus can provide valuable legal insights. For such analysis one needs to (1) select a subset of the corpus using document retrieval tools, (2) structuralize text using information extraction (IE) systems, and (3) visualize the data for the statistical analysis. Each process demands either specialized tools or programming skills whereas no comprehensive unified "no-code" tools have been available. Especially for IE, if the target information is not predefined in the ontology of the IE system, one needs to build their own system. Here we provide NESTLE, a no code tool for large-scale statistical analysis of legal corpus. With NESTLE, users can search target documents, extract information, and visualize the structured data all via the chat interface with accompanying auxiliary GUI for the fine-level control. NESTLE consists of three main components: a search engine, an end-to-end IE system, and a Large Language Model (LLM) that glues the whole components together and provides the chat interface. Powered by LLM and the end-to-end IE system, NESTLE can extract any type of information that has not been predefined in the IE system opening up the possibility of unlimited customizable statistical analysis of the corpus without writing a single line of code. The use of the custom end-to-end IE system also enables faster and low-cost IE on large scale corpus. We validate our system on 15 Korean precedent IE tasks and 3 legal text classification tasks from LEXGLUE. The comprehensive experiments reveal NESTLE can achieve GPT-4 comparable performance by training the internal IE module with 4 human-labeled, and 192 LLM-labeled examples. The detailed analysis provides the insight on the trade-off between accuracy, time, and cost in building such system.
Topology-aware MLP for Skeleton-based Action Recognition
Sep 04, 2023Graph convolution networks (GCNs) have achieved remarkable performance in skeleton-based action recognition. However, existing previous GCN-based methods have relied excessively on elaborate human body priors and constructed complex feature aggregation mechanisms, which limits the generalizability of networks. To solve these problems, we propose a novel Spatial Topology Gating Unit (STGU), which is an MLP-based variant without extra priors, to capture the co-occurrence topology features that encode the spatial dependency across all joints. In STGU, to model the sample-specific and completely independent point-wise topology attention, a new gate-based feature interaction mechanism is introduced to activate the features point-to-point by the attention map generated from the input. Based on the STGU, in this work, we propose the first topology-aware MLP-based model, Ta-MLP, for skeleton-based action recognition. In comparison with existing previous methods on three large-scale datasets, Ta-MLP achieves competitive performance. In addition, Ta-MLP reduces the parameters by up to 62.5% with favorable results. Compared with previous state-of-the-art (SOAT) approaches, Ta-MLP pushes the frontier of real-time action recognition. The code will be available at https://github.com/BUPTSJZhang/Ta-MLP.
On the fly Deep Neural Network Optimization Control for Low-Power Computer Vision
Sep 04, 2023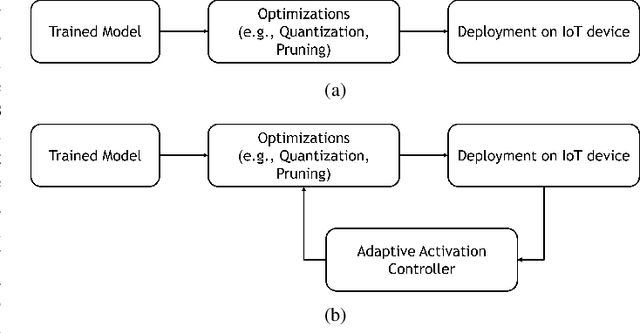
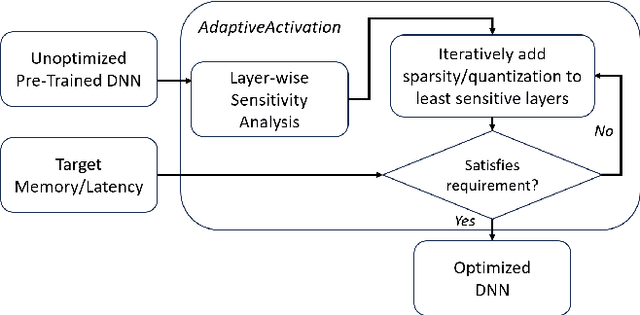
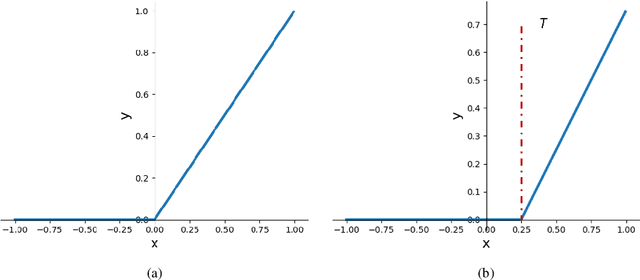
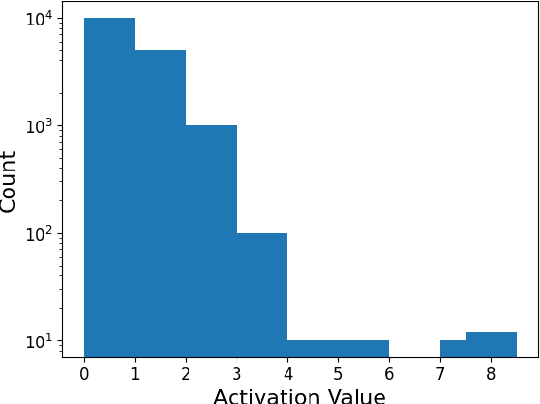
Processing visual data on mobile devices has many applications, e.g., emergency response and tracking. State-of-the-art computer vision techniques rely on large Deep Neural Networks (DNNs) that are usually too power-hungry to be deployed on resource-constrained edge devices. Many techniques improve the efficiency of DNNs by using sparsity or quantization. However, the accuracy and efficiency of these techniques cannot be adapted for diverse edge applications with different hardware constraints and accuracy requirements. This paper presents a novel technique to allow DNNs to adapt their accuracy and energy consumption during run-time, without the need for any re-training. Our technique called AdaptiveActivation introduces a hyper-parameter that controls the output range of the DNNs' activation function to dynamically adjust the sparsity and precision in the DNN. AdaptiveActivation can be applied to any existing pre-trained DNN to improve their deployability in diverse edge environments. We conduct experiments on popular edge devices and show that the accuracy is within 1.5% of the baseline. We also show that our approach requires 10%--38% less memory than the baseline techniques leading to more accuracy-efficiency tradeoff options
Fair Ranking under Disparate Uncertainty
Sep 04, 2023Ranking is a ubiquitous method for focusing the attention of human evaluators on a manageable subset of options. Its use ranges from surfacing potentially relevant products on an e-commerce site to prioritizing college applications for human review. While ranking can make human evaluation far more effective by focusing attention on the most promising options, we argue that it can introduce unfairness if the uncertainty of the underlying relevance model differs between groups of options. Unfortunately, such disparity in uncertainty appears widespread, since the relevance estimates for minority groups tend to have higher uncertainty due to a lack of data or appropriate features. To overcome this fairness issue, we propose Equal-Opportunity Ranking (EOR) as a new fairness criterion for ranking that provably corrects for the disparity in uncertainty between groups. Furthermore, we present a practical algorithm for computing EOR rankings in time $O(n \log(n))$ and prove its close approximation guarantee to the globally optimal solution. In a comprehensive empirical evaluation on synthetic data, a US Census dataset, and a real-world case study of Amazon search queries, we find that the algorithm reliably guarantees EOR fairness while providing effective rankings.
Real-time Vision-based Navigation for a Robot in an Indoor Environment
Jul 02, 2023
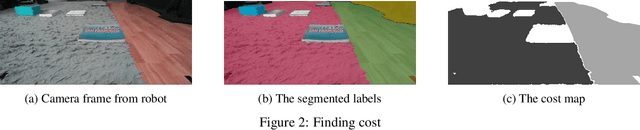
This paper presents a study on the development of an obstacle-avoidance navigation system for autonomous navigation in home environments. The system utilizes vision-based techniques and advanced path-planning algorithms to enable the robot to navigate toward the destination while avoiding obstacles. The performance of the system is evaluated through qualitative and quantitative metrics, highlighting its strengths and limitations. The findings contribute to the advancement of indoor robot navigation, showcasing the potential of vision-based techniques for real-time, autonomous navigation.
A Partially Observable Deep Multi-Agent Active Inference Framework for Resource Allocation in 6G and Beyond Wireless Communications Networks
Aug 27, 2023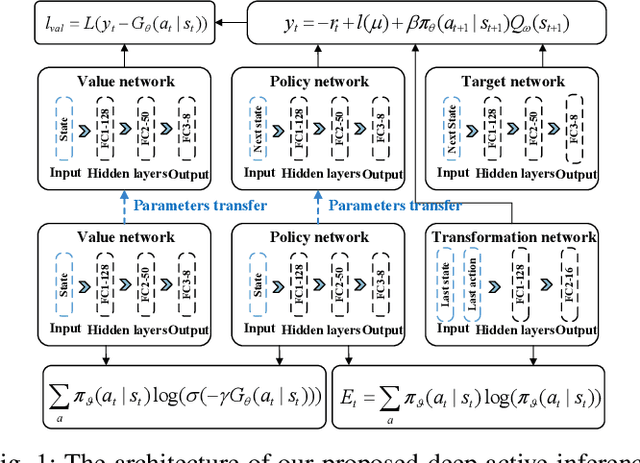
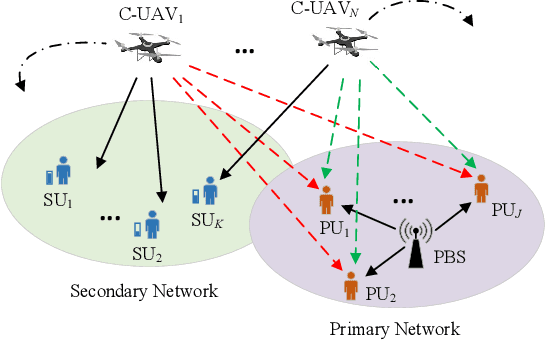
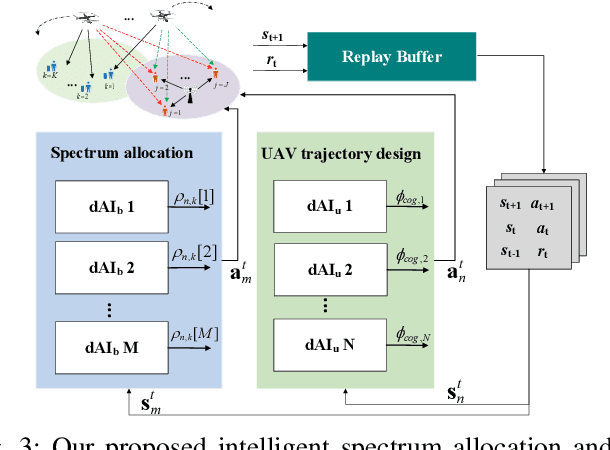
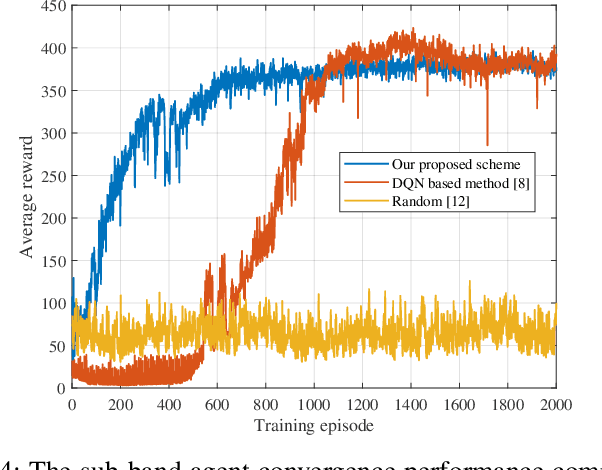
Resource allocation is of crucial importance in wireless communications. However, it is extremely challenging to design efficient resource allocation schemes for future wireless communication networks since the formulated resource allocation problems are generally non-convex and consist of various coupled variables. Moreover, the dynamic changes of practical wireless communication environment and user service requirements thirst for efficient real-time resource allocation. To tackle these issues, a novel partially observable deep multi-agent active inference (PODMAI) framework is proposed for realizing intelligent resource allocation. A belief based learning method is exploited for updating the policy by minimizing the variational free energy. A decentralized training with a decentralized execution multi-agent strategy is designed to overcome the limitations of the partially observable state information. Exploited the proposed framework, an intelligent spectrum allocation and trajectory optimization scheme is developed for a spectrum sharing unmanned aerial vehicle (UAV) network with dynamic transmission rate requirements as an example. Simulation results demonstrate that our proposed framework can significantly improve the sum transmission rate of the secondary network compared to various benchmark schemes. Moreover, the convergence speed of the proposed PODMAI is significantly improved compared with the conventional reinforcement learning framework. Overall, our proposed framework can enrich the intelligent resource allocation frameworks and pave the way for realizing real-time resource allocation.
Multipath Time-delay Estimation with Impulsive Noise via Bayesian Compressive Sensing
Jul 05, 2023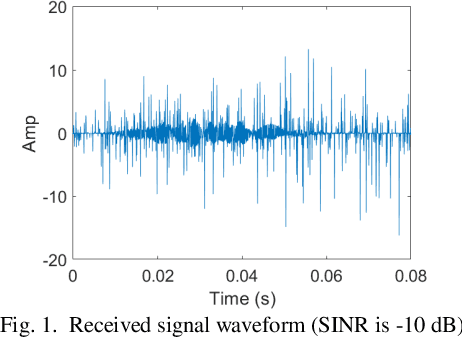
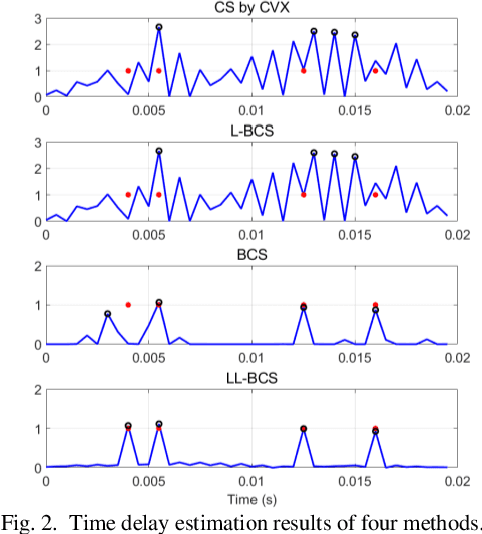
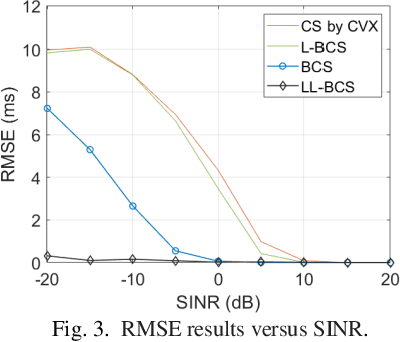

Multipath time-delay estimation is commonly encountered in radar and sonar signal processing. In some real-life environments, impulse noise is ubiquitous and significantly degrades estimation performance. Here, we propose a Bayesian approach to tailor the Bayesian Compressive Sensing (BCS) to mitigate impulsive noises. In particular, a heavy-tail Laplacian distribution is used as a statistical model for impulse noise, while Laplacian prior is used for sparse multipath modeling. The Bayesian learning problem contains hyperparameters learning and parameter estimation, solved under the BCS inference framework. The performance of our proposed method is compared with benchmark methods, including compressive sensing (CS), BCS, and Laplacian-prior BCS (L-BCS). The simulation results show that our proposed method can estimate the multipath parameters more accurately and have a lower root mean squared estimation error (RMSE) in intensely impulsive noise.
Physics-inspired Neural Networks for Parameter Learning of Adaptive Cruise Control Systems
Sep 03, 2023This paper proposes and develops a physics-inspired neural network (PiNN) for learning the parameters of commercially implemented adaptive cruise control (ACC) systems in automotive industry. To emulate the core functionality of stock ACC systems, which have proprietary control logic and undisclosed parameters, the constant time-headway policy (CTHP) is adopted. Leveraging the multi-layer artificial neural networks as universal approximators, the developed PiNN serves as a surrogate model for the longitudinal dynamics of ACC-engaged vehicles, efficiently learning the unknown parameters of the CTHP. The ability of the PiNN to infer the unknown ACC parameters is meticulous evaluated using both synthetic and high-fidelity empirical data of space-gap and relative velocity involving ACC-engaged vehicles in platoon formation. The results have demonstrated the superior predictive ability of the proposed PiNN in learning the unknown design parameters of stock ACC systems from different car manufacturers. The set of ACC model parameters obtained from the PiNN revealed that the stock ACC systems of the considered vehicles in three experimental campaigns are neither $L_2$ nor $L_\infty$ string stable.