 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive function approximation based on the Discrete Cosine Transform (DCT)
Sep 01, 2023
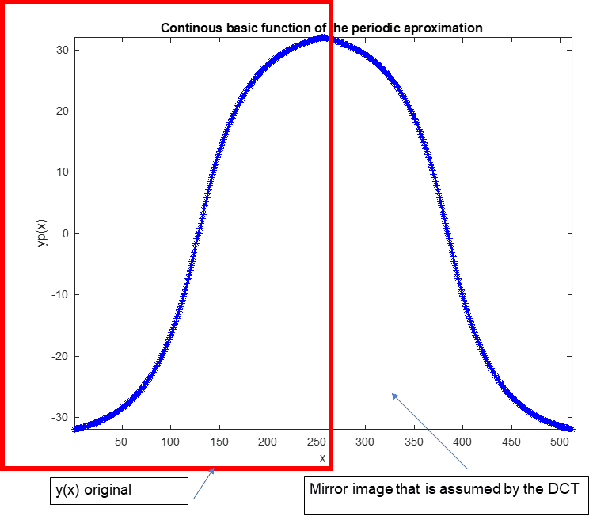
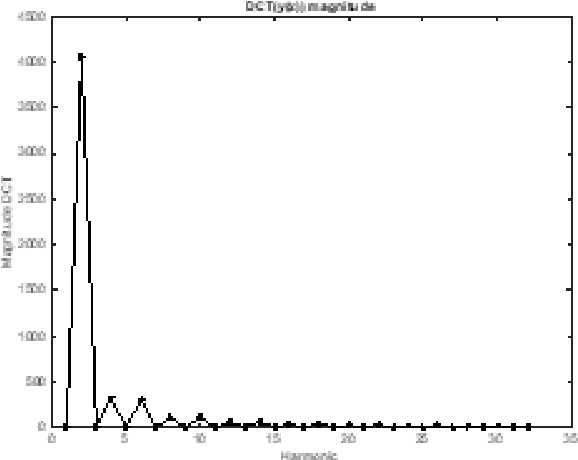
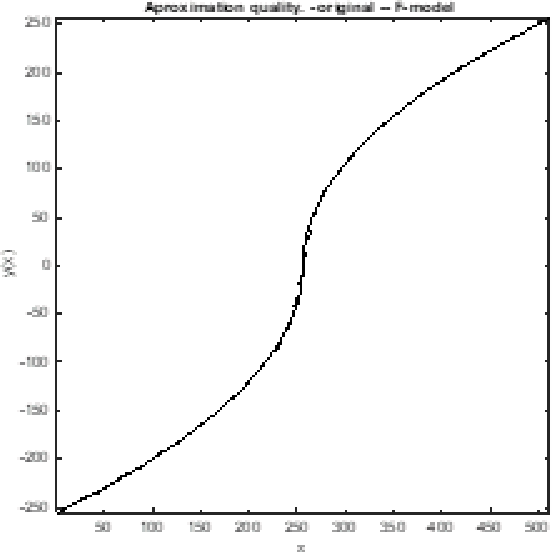
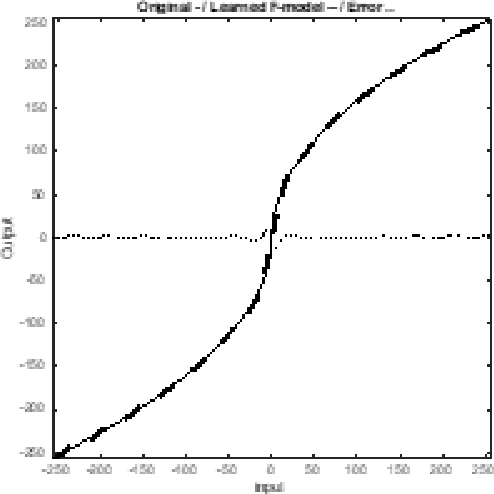
This paper studies the cosine as basis function for the approximation of univariate and continuous functions without memory. This work studies a supervised learning to obtain the approximation coefficients, instead of using the Discrete Cosine Transform (DCT). Due to the finite dynamics and orthogonality of the cosine basis functions, simple gradient algorithms, such as the Normalized Least Mean Squares (NLMS), can benefit from it and present a controlled and predictable convergence time and error misadjustment. Due to its simplicity, the proposed technique ranks as the best in terms of learning quality versus complexity, and it is presented as an attractive technique to be used in more complex supervised learning systems. Simulations illustrate the performance of the approach. This paper celebrates the 50th anniversary of the publication of the DCT by Nasir Ahmed in 1973.
Bootstrap aggregation and confidence measures to improve time series causal discovery
Jun 15, 2023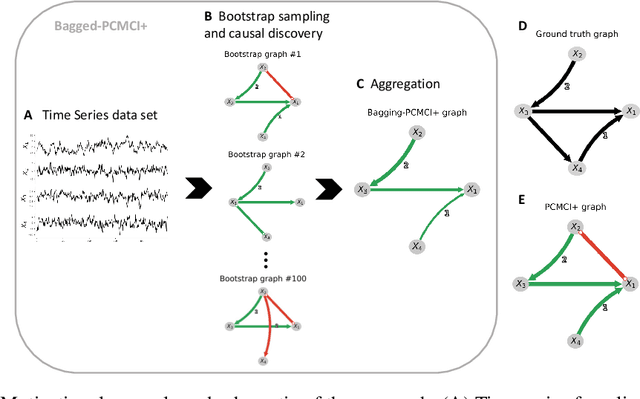
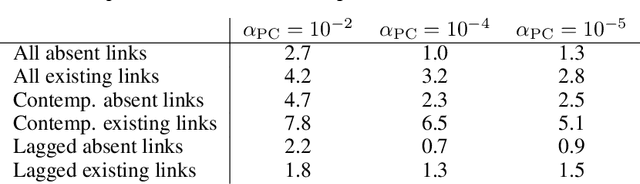
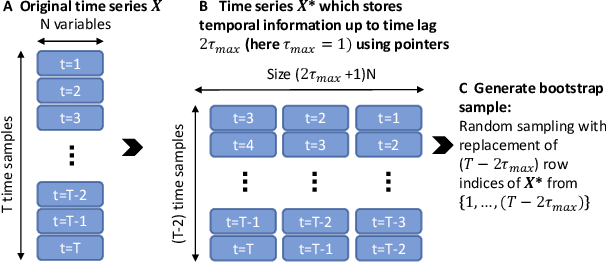
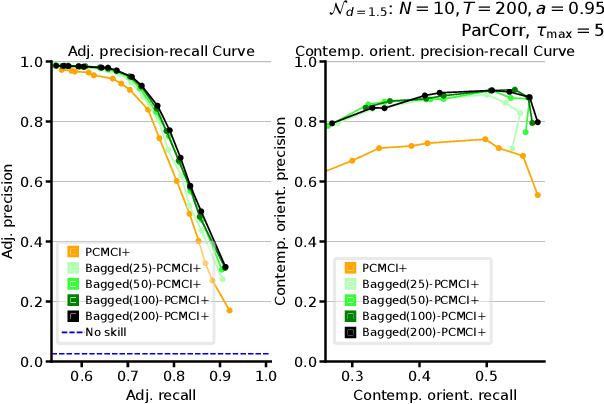
Causal discovery methods have demonstrated the ability to identify the time series graphs representing the causal temporal dependency structure of dynamical systems. However, they do not include a measure of the confidence of the estimated links. Here, we introduce a novel bootstrap aggregation (bagging) and confidence measure method that is combined with time series causal discovery. This new method allows measuring confidence for the links of the time series graphs calculated by causal discovery methods. This is done by bootstrapping the original times series data set while preserving temporal dependencies. Next to confidence measures, aggregating the bootstrapped graphs by majority voting yields a final aggregated output graph. In this work, we combine our approach with the state-of-the-art conditional-independence-based algorithm PCMCI+. With extensive numerical experiments we empirically demonstrate that, in addition to providing confidence measures for links, Bagged-PCMCI+ improves the precision and recall of its base algorithm PCMCI+. Specifically, Bagged-PCMCI+ has a higher detection power regarding adjacencies and a higher precision in orienting contemporaneous edges while at the same time showing a lower rate of false positives. These performance improvements are especially pronounced in the more challenging settings (short time sample size, large number of variables, high autocorrelation). Our bootstrap approach can also be combined with other time series causal discovery algorithms and can be of considerable use in many real-world applications, especially when confidence measures for the links are desired.
Hierarchical Masked 3D Diffusion Model for Video Outpainting
Sep 05, 2023


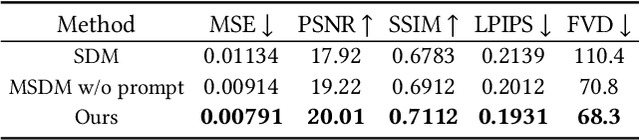
Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks. More results are provided at our https://fanfanda.github.io/M3DDM/.
Granger Causal Inference in Multivariate Hawkes Processes by Minimum Message Length
Sep 05, 2023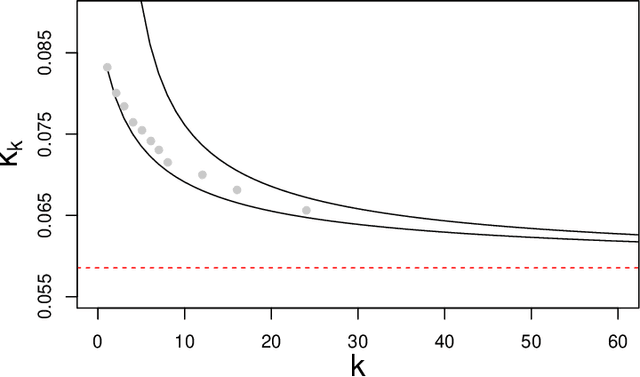
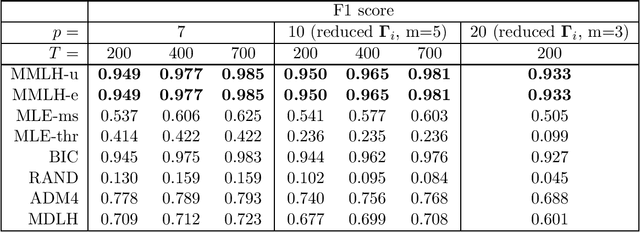
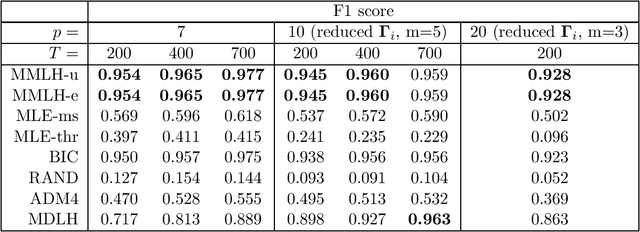
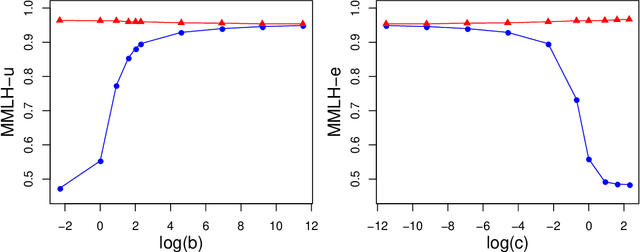
Multivariate Hawkes processes (MHPs) are versatile probabilistic tools used to model various real-life phenomena: earthquakes, operations on stock markets, neuronal activity, virus propagation and many others. In this paper, we focus on MHPs with exponential decay kernels and estimate connectivity graphs, which represent the Granger causal relations between their components. We approach this inference problem by proposing an optimization criterion and model selection algorithm based on the minimum message length (MML) principle. MML compares Granger causal models using the Occam's razor principle in the following way: even when models have a comparable goodness-of-fit to the observed data, the one generating the most concise explanation of the data is preferred. While most of the state-of-art methods using lasso-type penalization tend to overfitting in scenarios with short time horizons, the proposed MML-based method achieves high F1 scores in these settings. We conduct a numerical study comparing the proposed algorithm to other related classical and state-of-art methods, where we achieve the highest F1 scores in specific sparse graph settings. We illustrate the proposed method also on G7 sovereign bond data and obtain causal connections, which are in agreement with the expert knowledge available in the literature.
Distributed Variational Inference for Online Supervised Learning
Sep 05, 2023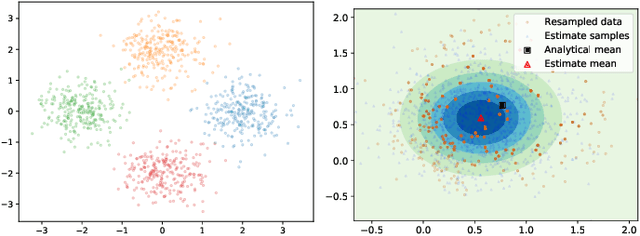
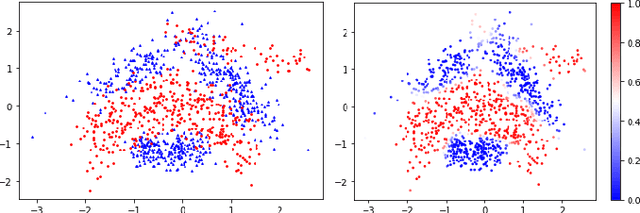
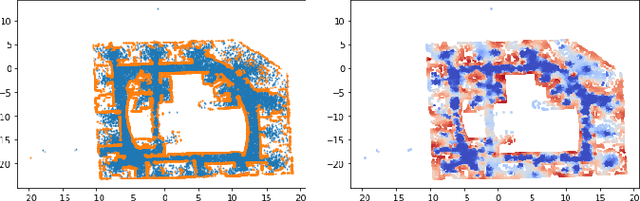
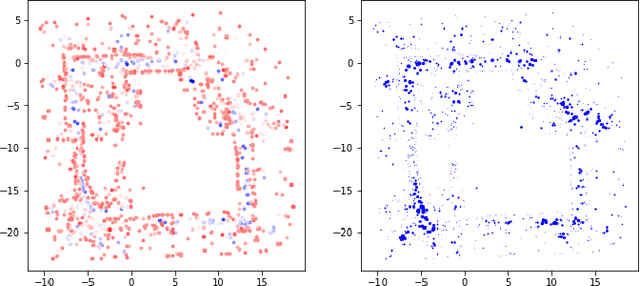
Developing efficient solutions for inference problems in intelligent sensor networks is crucial for the next generation of location, tracking, and mapping services. This paper develops a scalable distributed probabilistic inference algorithm that applies to continuous variables, intractable posteriors and large-scale real-time data in sensor networks. In a centralized setting, variational inference is a fundamental technique for performing approximate Bayesian estimation, in which an intractable posterior density is approximated with a parametric density. Our key contribution lies in the derivation of a separable lower bound on the centralized estimation objective, which enables distributed variational inference with one-hop communication in a sensor network. Our distributed evidence lower bound (DELBO) consists of a weighted sum of observation likelihood and divergence to prior densities, and its gap to the measurement evidence is due to consensus and modeling errors. To solve binary classification and regression problems while handling streaming data, we design an online distributed algorithm that maximizes DELBO, and specialize it to Gaussian variational densities with non-linear likelihoods. The resulting distributed Gaussian variational inference (DGVI) efficiently inverts a $1$-rank correction to the covariance matrix. Finally, we derive a diagonalized version for online distributed inference in high-dimensional models, and apply it to multi-robot probabilistic mapping using indoor LiDAR data.
A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking
Sep 05, 2023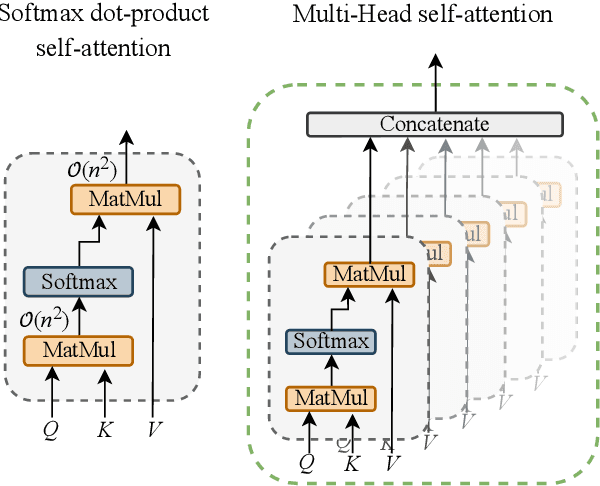

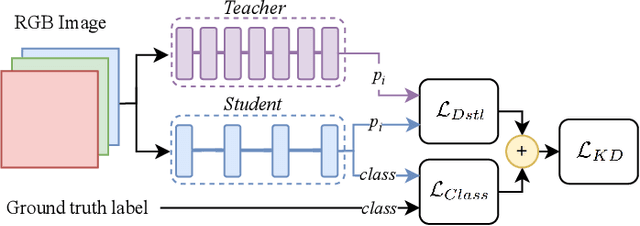
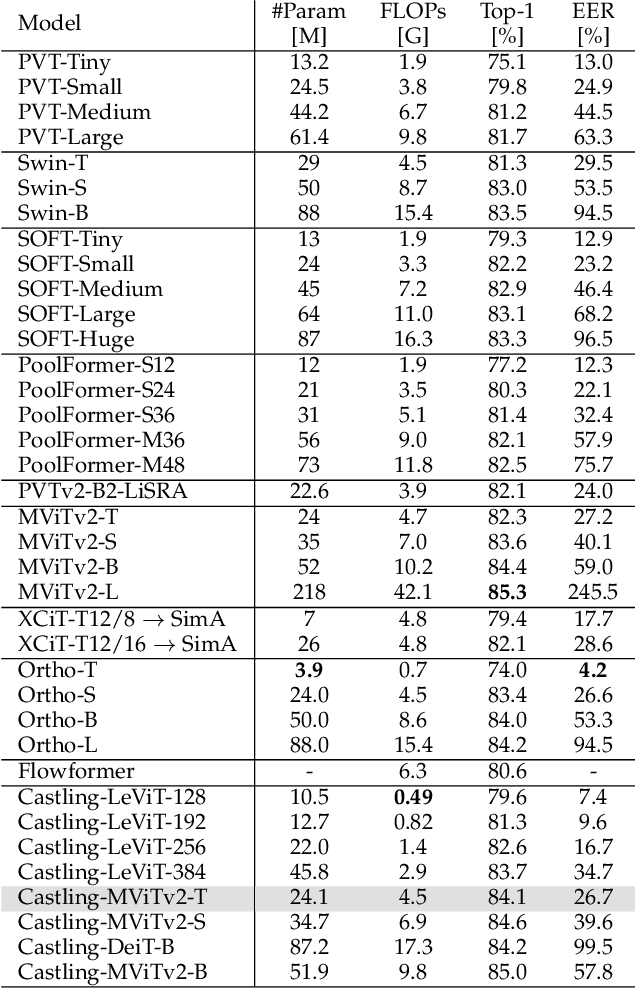
Vision Transformer (ViT) architectures are becoming increasingly popular and widely employed to tackle computer vision applications. Their main feature is the capacity to extract global information through the self-attention mechanism, outperforming earlier convolutional neural networks. However, ViT deployment and performance have grown steadily with their size, number of trainable parameters, and operations. Furthermore, self-attention's computational and memory cost quadratically increases with the image resolution. Generally speaking, it is challenging to employ these architectures in real-world applications due to many hardware and environmental restrictions, such as processing and computational capabilities. Therefore, this survey investigates the most efficient methodologies to ensure sub-optimal estimation performances. More in detail, four efficient categories will be analyzed: compact architecture, pruning, knowledge distillation, and quantization strategies. Moreover, a new metric called Efficient Error Rate has been introduced in order to normalize and compare models' features that affect hardware devices at inference time, such as the number of parameters, bits, FLOPs, and model size. Summarizing, this paper firstly mathematically defines the strategies used to make Vision Transformer efficient, describes and discusses state-of-the-art methodologies, and analyzes their performances over different application scenarios. Toward the end of this paper, we also discuss open challenges and promising research directions.
Perceptual Quality Assessment of 360$^\circ$ Images Based on Generative Scanpath Representation
Sep 07, 2023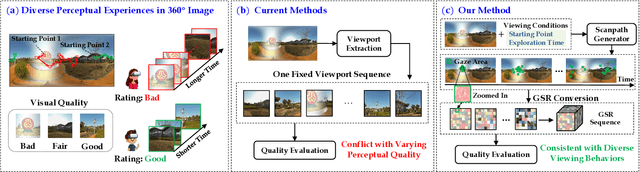
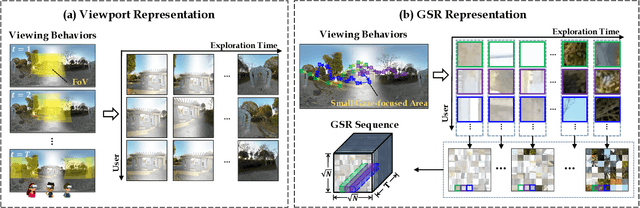
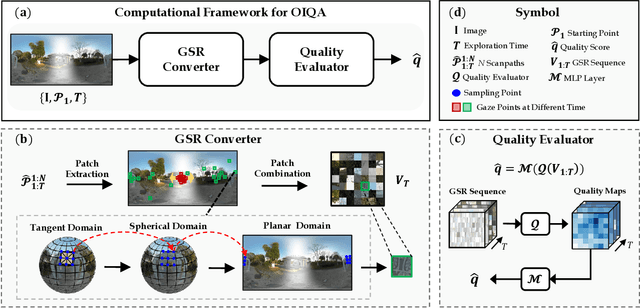
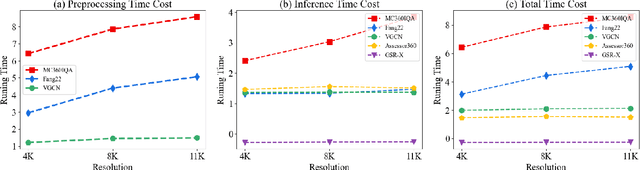
Despite substantial efforts dedicated to the design of heuristic models for omnidirectional (i.e., 360$^\circ$) image quality assessment (OIQA), a conspicuous gap remains due to the lack of consideration for the diversity of viewing behaviors that leads to the varying perceptual quality of 360$^\circ$ images. Two critical aspects underline this oversight: the neglect of viewing conditions that significantly sway user gaze patterns and the overreliance on a single viewport sequence from the 360$^\circ$ image for quality inference. To address these issues, we introduce a unique generative scanpath representation (GSR) for effective quality inference of 360$^\circ$ images, which aggregates varied perceptual experiences of multi-hypothesis users under a predefined viewing condition. More specifically, given a viewing condition characterized by the starting point of viewing and exploration time, a set of scanpaths consisting of dynamic visual fixations can be produced using an apt scanpath generator. Following this vein, we use the scanpaths to convert the 360$^\circ$ image into the unique GSR, which provides a global overview of gazed-focused contents derived from scanpaths. As such, the quality inference of the 360$^\circ$ image is swiftly transformed to that of GSR. We then propose an efficient OIQA computational framework by learning the quality maps of GSR. Comprehensive experimental results validate that the predictions of the proposed framework are highly consistent with human perception in the spatiotemporal domain, especially in the challenging context of locally distorted 360$^\circ$ images under varied viewing conditions. The code will be released at https://github.com/xiangjieSui/GSR
Your Battery Is a Blast! Safeguarding Against Counterfeit Batteries with Authentication
Sep 07, 2023

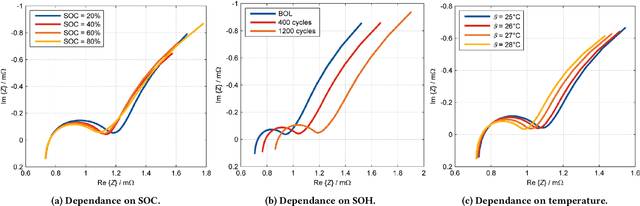
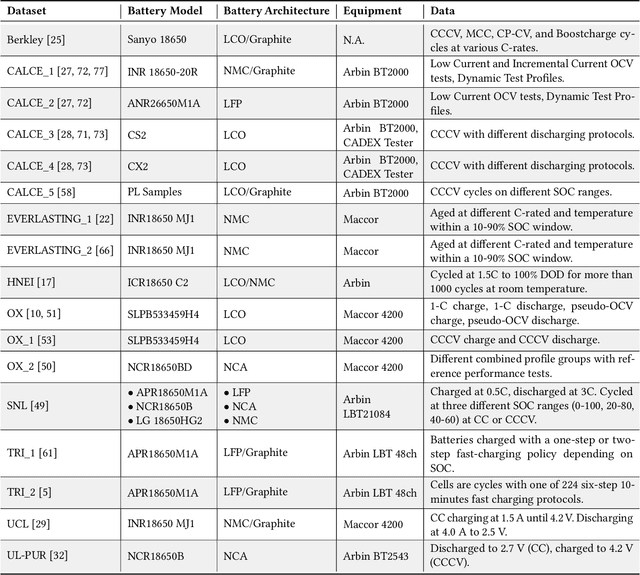
Lithium-ion (Li-ion) batteries are the primary power source in various applications due to their high energy and power density. Their market was estimated to be up to 48 billion U.S. dollars in 2022. However, the widespread adoption of Li-ion batteries has resulted in counterfeit cell production, which can pose safety hazards to users. Counterfeit cells can cause explosions or fires, and their prevalence in the market makes it difficult for users to detect fake cells. Indeed, current battery authentication methods can be susceptible to advanced counterfeiting techniques and are often not adaptable to various cells and systems. In this paper, we improve the state of the art on battery authentication by proposing two novel methodologies, DCAuth and EISthentication, which leverage the internal characteristics of each cell through Machine Learning models. Our methods automatically authenticate lithium-ion battery models and architectures using data from their regular usage without the need for any external device. They are also resilient to the most common and critical counterfeit practices and can scale to several batteries and devices. To evaluate the effectiveness of our proposed methodologies, we analyze time-series data from a total of 20 datasets that we have processed to extract meaningful features for our analysis. Our methods achieve high accuracy in battery authentication for both architectures (up to 0.99) and models (up to 0.96). Moreover, our methods offer comparable identification performances. By using our proposed methodologies, manufacturers can ensure that devices only use legitimate batteries, guaranteeing the operational state of any system and safety measures for the users.
Fully Onboard SLAM for Distributed Mapping with a Swarm of Nano-Drones
Sep 07, 2023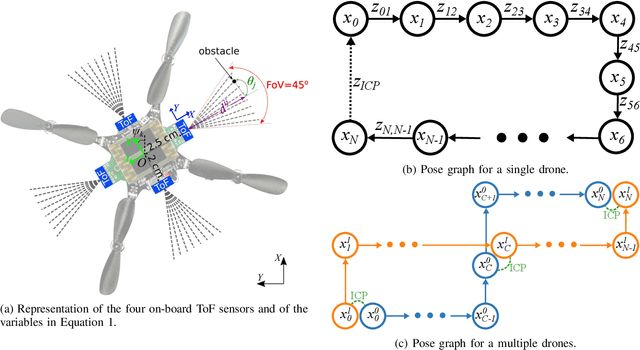
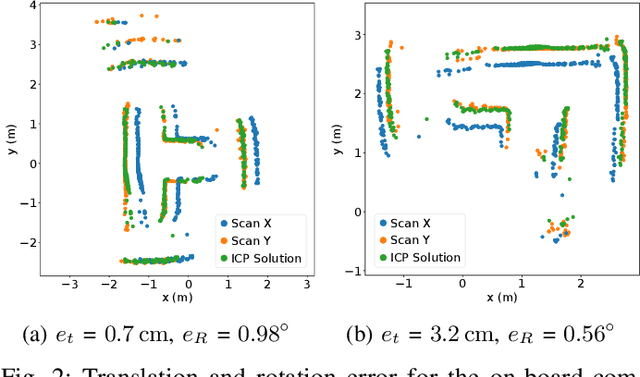
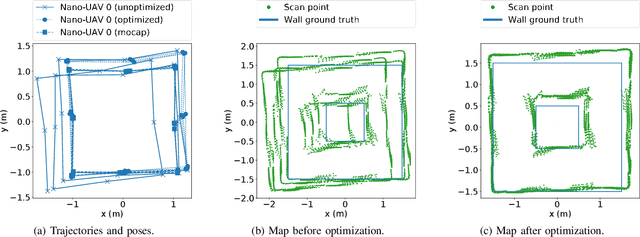
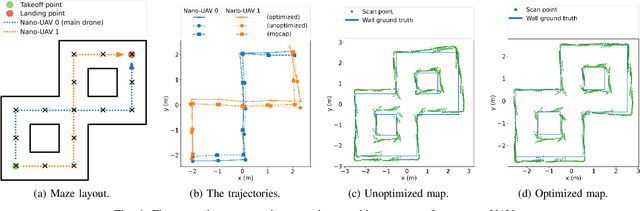
The use of Unmanned Aerial Vehicles (UAVs) is rapidly increasing in applications ranging from surveillance and first-aid missions to industrial automation involving cooperation with other machines or humans. To maximize area coverage and reduce mission latency, swarms of collaborating drones have become a significant research direction. However, this approach requires open challenges in positioning, mapping, and communications to be addressed. This work describes a distributed mapping system based on a swarm of nano-UAVs, characterized by a limited payload of 35 g and tightly constrained on-board sensing and computing capabilities. Each nano-UAV is equipped with four 64-pixel depth sensors that measure the relative distance to obstacles in four directions. The proposed system merges the information from the swarm and generates a coherent grid map without relying on any external infrastructure. The data fusion is performed using the iterative closest point algorithm and a graph-based simultaneous localization and mapping algorithm, running entirely on-board the UAV's low-power ARM Cortex-M microcontroller with just 192 kB of SRAM memory. Field results gathered in three different mazes from a swarm of up to 4 nano-UAVs prove a mapping accuracy of 12 cm and demonstrate that the mapping time is inversely proportional to the number of agents. The proposed framework scales linearly in terms of communication bandwidth and on-board computational complexity, supporting communication between up to 20 nano-UAVs and mapping of areas up to 180 m2 with the chosen configuration requiring only 50 kB of memory.
SageFormer: Series-Aware Graph-Enhanced Transformers for Multivariate Time Series Forecasting
Jul 04, 2023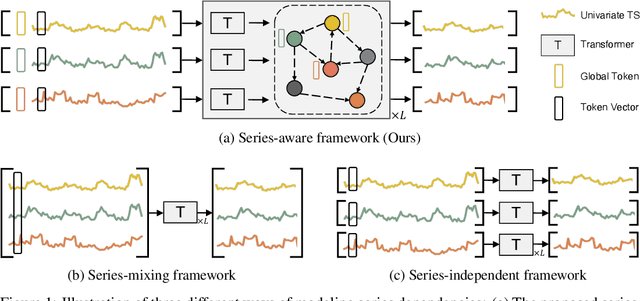

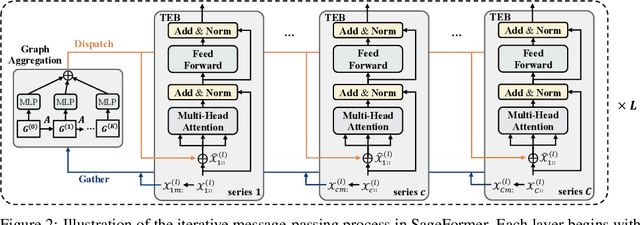
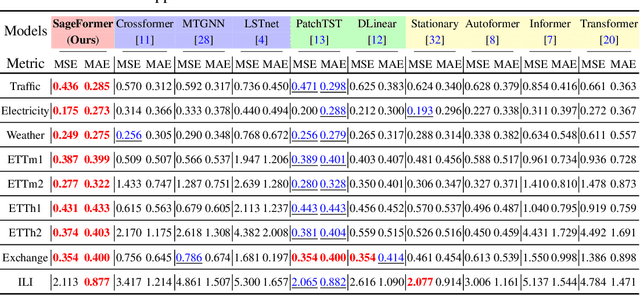
Multivariate time series forecasting plays a critical role in diverse domains. While recent advancements in deep learning methods, especially Transformers, have shown promise, there remains a gap in addressing the significance of inter-series dependencies. This paper introduces SageFormer, a Series-aware Graph-enhanced Transformer model designed to effectively capture and model dependencies between series using graph structures. SageFormer tackles two key challenges: effectively representing diverse temporal patterns across series and mitigating redundant information among series. Importantly, the proposed series-aware framework seamlessly integrates with existing Transformer-based models, augmenting their ability to model inter-series dependencies. Through extensive experiments on real-world and synthetic datasets, we showcase the superior performance of SageFormer compared to previous state-of-the-art approaches.