 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised speech enhancement with diffusion-based generative models
Sep 19, 2023
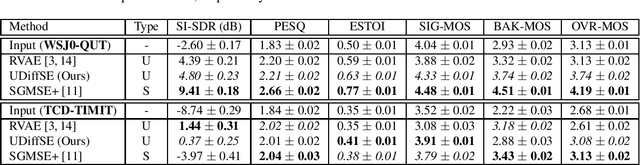
Recently, conditional score-based diffusion models have gained significant attention in the field of supervised speech enhancement, yielding state-of-the-art performance. However, these methods may face challenges when generalising to unseen conditions. To address this issue, we introduce an alternative approach that operates in an unsupervised manner, leveraging the generative power of diffusion models. Specifically, in a training phase, a clean speech prior distribution is learnt in the short-time Fourier transform (STFT) domain using score-based diffusion models, allowing it to unconditionally generate clean speech from Gaussian noise. Then, we develop a posterior sampling methodology for speech enhancement by combining the learnt clean speech prior with a noise model for speech signal inference. The noise parameters are simultaneously learnt along with clean speech estimation through an iterative expectationmaximisation (EM) approach. To the best of our knowledge, this is the first work exploring diffusion-based generative models for unsupervised speech enhancement, demonstrating promising results compared to a recent variational auto-encoder (VAE)-based unsupervised approach and a state-of-the-art diffusion-based supervised method. It thus opens a new direction for future research in unsupervised speech enhancement.
Towards Discriminative Representations with Contrastive Instances for Real-Time UAV Tracking
Aug 22, 2023Maintaining high efficiency and high precision are two fundamental challenges in UAV tracking due to the constraints of computing resources, battery capacity, and UAV maximum load. Discriminative correlation filters (DCF)-based trackers can yield high efficiency on a single CPU but with inferior precision. Lightweight Deep learning (DL)-based trackers can achieve a good balance between efficiency and precision but performance gains are limited by the compression rate. High compression rate often leads to poor discriminative representations. To this end, this paper aims to enhance the discriminative power of feature representations from a new feature-learning perspective. Specifically, we attempt to learn more disciminative representations with contrastive instances for UAV tracking in a simple yet effective manner, which not only requires no manual annotations but also allows for developing and deploying a lightweight model. We are the first to explore contrastive learning for UAV tracking. Extensive experiments on four UAV benchmarks, including UAV123@10fps, DTB70, UAVDT and VisDrone2018, show that the proposed DRCI tracker significantly outperforms state-of-the-art UAV tracking methods.
State2Explanation: Concept-Based Explanations to Benefit Agent Learning and User Understanding
Sep 21, 2023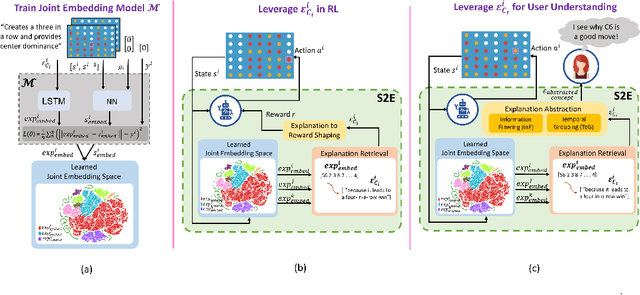
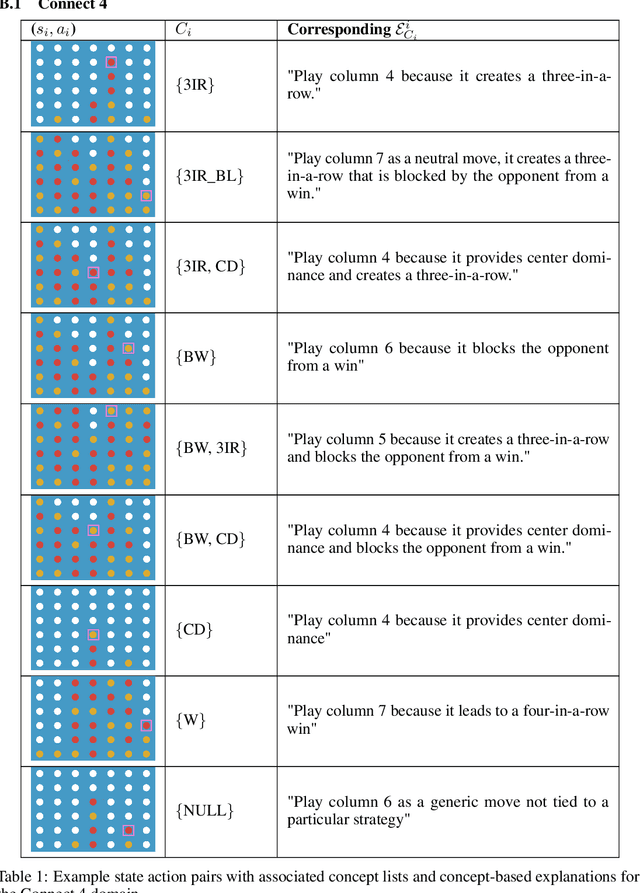
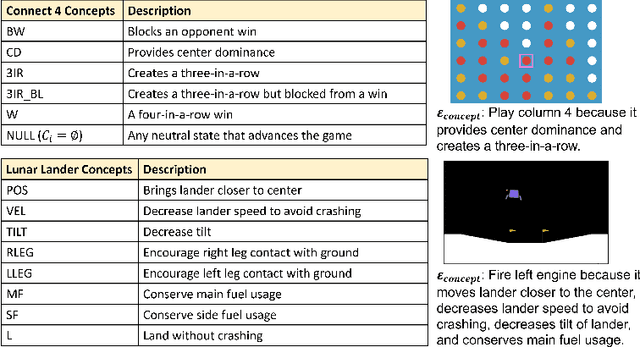

With more complex AI systems used by non-AI experts to complete daily tasks, there is an increasing effort to develop methods that produce explanations of AI decision making understandable by non-AI experts. Towards this effort, leveraging higher-level concepts and producing concept-based explanations have become a popular method. Most concept-based explanations have been developed for classification techniques, and we posit that the few existing methods for sequential decision making are limited in scope. In this work, we first contribute a desiderata for defining "concepts" in sequential decision making settings. Additionally, inspired by the Protege Effect which states explaining knowledge often reinforces one's self-learning, we explore the utility of concept-based explanations providing a dual benefit to the RL agent by improving agent learning rate, and to the end-user by improving end-user understanding of agent decision making. To this end, we contribute a unified framework, State2Explanation (S2E), that involves learning a joint embedding model between state-action pairs and concept-based explanations, and leveraging such learned model to both (1) inform reward shaping during an agent's training, and (2) provide explanations to end-users at deployment for improved task performance. Our experimental validations, in Connect 4 and Lunar Lander, demonstrate the success of S2E in providing a dual-benefit, successfully informing reward shaping and improving agent learning rate, as well as significantly improving end user task performance at deployment time.
A Study of Forward-Forward Algorithm for Self-Supervised Learning
Sep 21, 2023
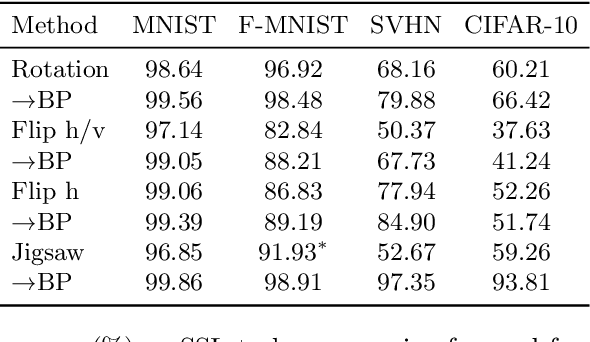
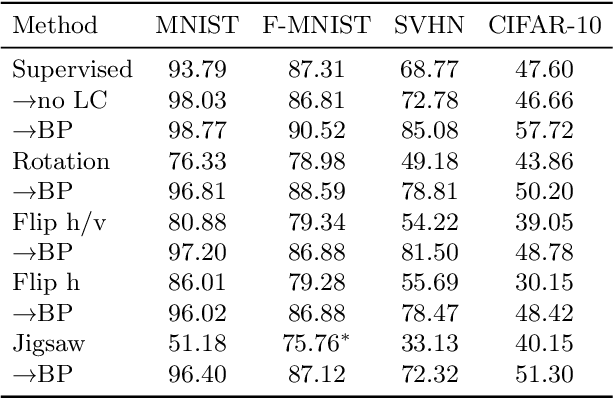

Self-supervised representation learning has seen remarkable progress in the last few years, with some of the recent methods being able to learn useful image representations without labels. These methods are trained using backpropagation, the de facto standard. Recently, Geoffrey Hinton proposed the forward-forward algorithm as an alternative training method. It utilizes two forward passes and a separate loss function for each layer to train the network without backpropagation. In this study, for the first time, we study the performance of forward-forward vs. backpropagation for self-supervised representation learning and provide insights into the learned representation spaces. Our benchmark employs four standard datasets, namely MNIST, F-MNIST, SVHN and CIFAR-10, and three commonly used self-supervised representation learning techniques, namely rotation, flip and jigsaw. Our main finding is that while the forward-forward algorithm performs comparably to backpropagation during (self-)supervised training, the transfer performance is significantly lagging behind in all the studied settings. This may be caused by a combination of factors, including having a loss function for each layer and the way the supervised training is realized in the forward-forward paradigm. In comparison to backpropagation, the forward-forward algorithm focuses more on the boundaries and drops part of the information unnecessary for making decisions which harms the representation learning goal. Further investigation and research are necessary to stabilize the forward-forward strategy for self-supervised learning, to work beyond the datasets and configurations demonstrated by Geoffrey Hinton.
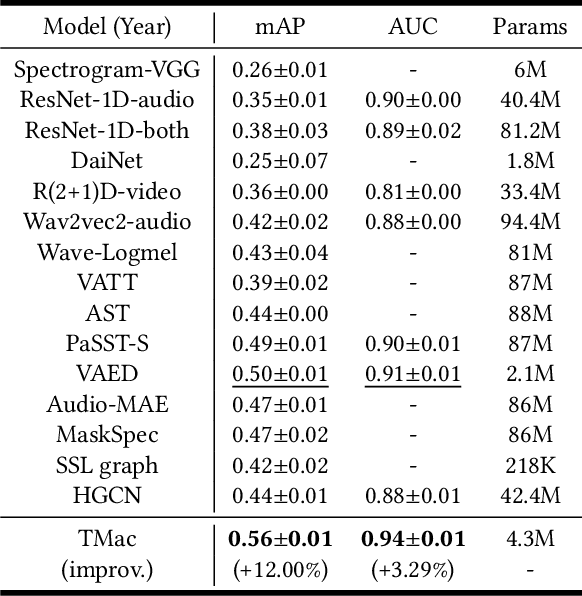
TMac: Temporal Multi-Modal Graph Learning for Acoustic Event Classification
Sep 21, 2023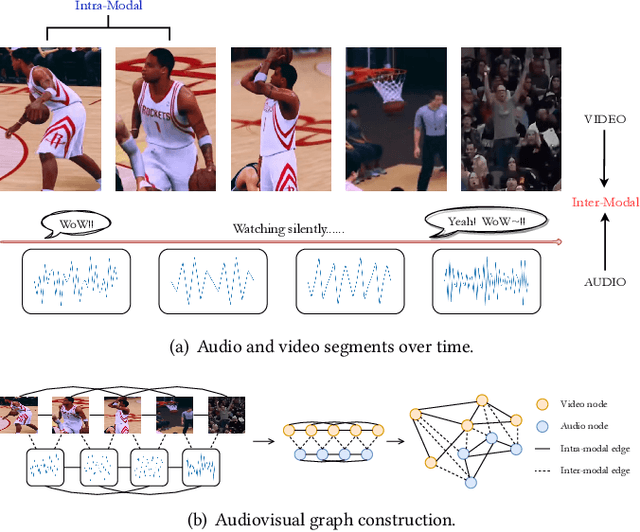

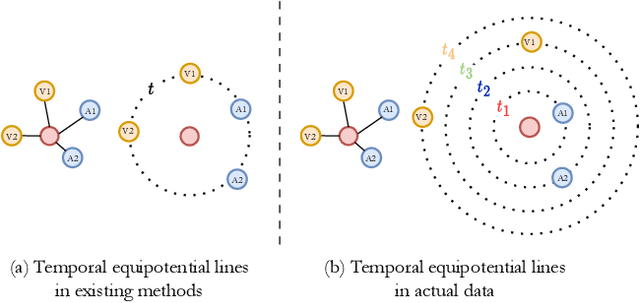
Audiovisual data is everywhere in this digital age, which raises higher requirements for the deep learning models developed on them. To well handle the information of the multi-modal data is the key to a better audiovisual modal. We observe that these audiovisual data naturally have temporal attributes, such as the time information for each frame in the video. More concretely, such data is inherently multi-modal according to both audio and visual cues, which proceed in a strict chronological order. It indicates that temporal information is important in multi-modal acoustic event modeling for both intra- and inter-modal. However, existing methods deal with each modal feature independently and simply fuse them together, which neglects the mining of temporal relation and thus leads to sub-optimal performance. With this motivation, we propose a Temporal Multi-modal graph learning method for Acoustic event Classification, called TMac, by modeling such temporal information via graph learning techniques. In particular, we construct a temporal graph for each acoustic event, dividing its audio data and video data into multiple segments. Each segment can be considered as a node, and the temporal relationships between nodes can be considered as timestamps on their edges. In this case, we can smoothly capture the dynamic information in intra-modal and inter-modal. Several experiments are conducted to demonstrate TMac outperforms other SOTA models in performance. Our code is available at https://github.com/MGitHubL/TMac.
A new meteor detection application robust to camera movements
Sep 12, 2023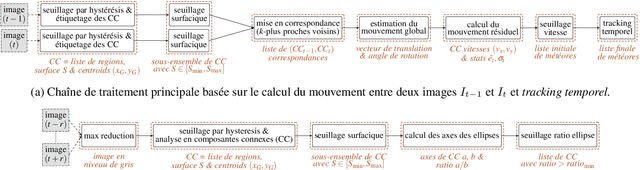
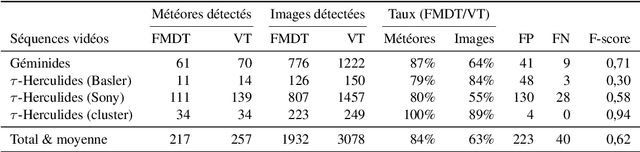


This article presents a new tool for the automatic detection of meteors. Fast Meteor Detection Toolbox (FMDT) is able to detect meteor sightings by analyzing videos acquired by cameras onboard weather balloons or within airplane with stabilization. The challenge consists in designing a processing chain composed of simple algorithms, that are robust to the high fluctuation of the videos and that satisfy the constraints on power consumption (10 W) and real-time processing (25 frames per second).
Euclidean and non-Euclidean Trajectory Optimization Approaches for Quadrotor Racing
Sep 13, 2023We present two approaches to compute raceline trajectories for quadrotors by solving an optimal control problem. The approaches involve expressing quadrotor pose in either a Euclidean or non-Euclidean frame of reference and are both based on collocation. The compute times of both approaches are over 100x faster than published methods. Additionally, both approaches compute trajectories with faster lap time and show improved numerical convergence. In the last part of the paper we devise a novel method to compute racelines in dense obstacle fields using the non-Euclidean approach.
From DDMs to DNNs: Using process data and models of decision-making to improve human-AI interactions
Sep 07, 2023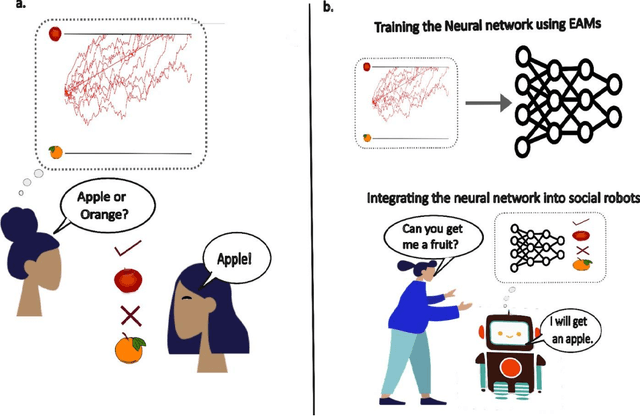
Over the past decades, cognitive neuroscientists and behavioral economists have recognized the value of describing the process of decision making in detail and modeling the emergence of decisions over time. For example, the time it takes to decide can reveal more about an agent's true hidden preferences than only the decision itself. Similarly, data that track the ongoing decision process such as eye movements or neural recordings contain critical information that can be exploited, even if no decision is made. Here, we argue that artificial intelligence (AI) research would benefit from a stronger focus on insights about how decisions emerge over time and incorporate related process data to improve AI predictions in general and human-AI interactions in particular. First, we introduce a highly established computational framework that assumes decisions to emerge from the noisy accumulation of evidence, and we present related empirical work in psychology, neuroscience, and economics. Next, we discuss to what extent current approaches in multi-agent AI do or do not incorporate process data and models of decision making. Finally, we outline how a more principled inclusion of the evidence-accumulation framework into the training and use of AI can help to improve human-AI interactions in the future.
Self-Interpretable Time Series Prediction with Counterfactual Explanations
Jun 22, 2023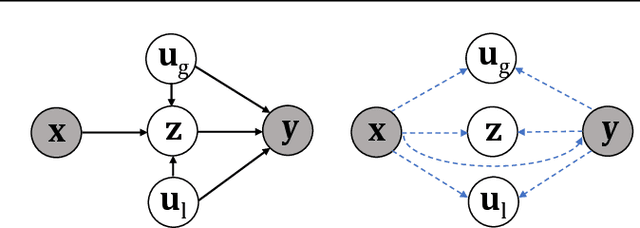

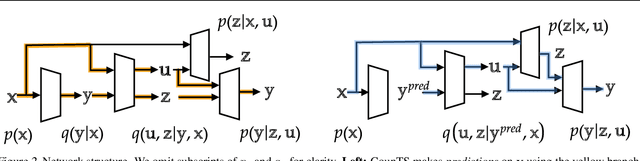

Interpretable time series prediction is crucial for safety-critical areas such as healthcare and autonomous driving. Most existing methods focus on interpreting predictions by assigning important scores to segments of time series. In this paper, we take a different and more challenging route and aim at developing a self-interpretable model, dubbed Counterfactual Time Series (CounTS), which generates counterfactual and actionable explanations for time series predictions. Specifically, we formalize the problem of time series counterfactual explanations, establish associated evaluation protocols, and propose a variational Bayesian deep learning model equipped with counterfactual inference capability of time series abduction, action, and prediction. Compared with state-of-the-art baselines, our self-interpretable model can generate better counterfactual explanations while maintaining comparable prediction accuracy.
Automatic view plane prescription for cardiac magnetic resonance imaging via supervision by spatial relationship between views
Sep 22, 2023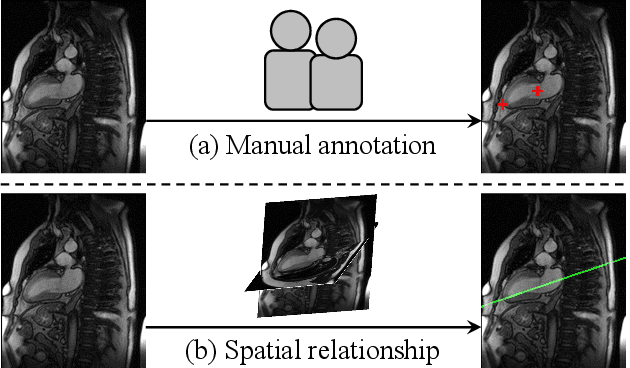
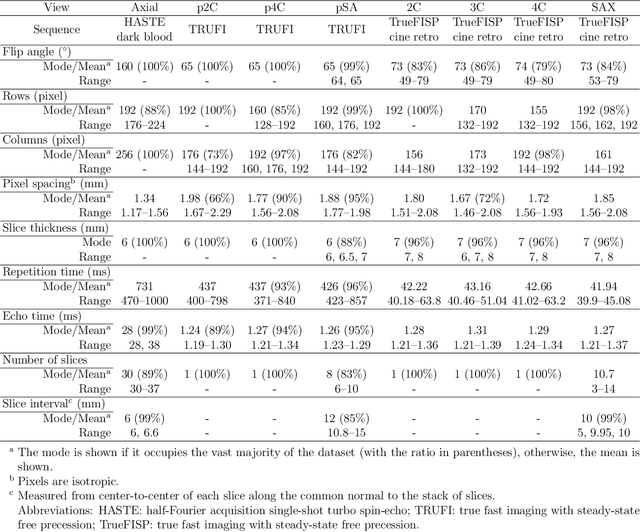
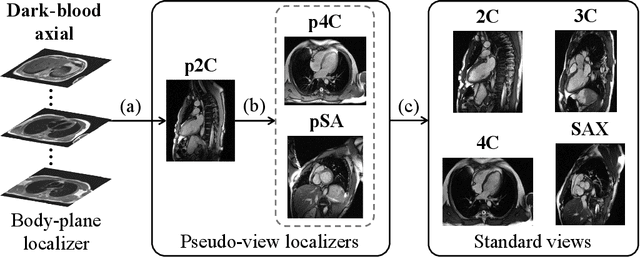
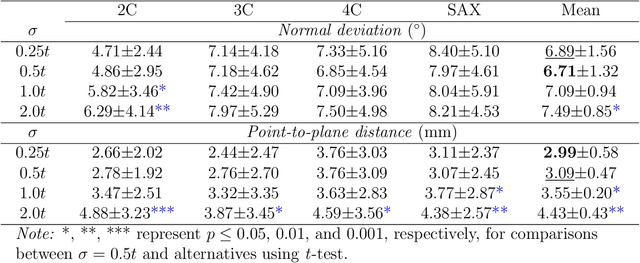
Background: View planning for the acquisition of cardiac magnetic resonance (CMR) imaging remains a demanding task in clinical practice. Purpose: Existing approaches to its automation relied either on an additional volumetric image not typically acquired in clinic routine, or on laborious manual annotations of cardiac structural landmarks. This work presents a clinic-compatible, annotation-free system for automatic CMR view planning. Methods: The system mines the spatial relationship, more specifically, locates the intersecting lines, between the target planes and source views, and trains deep networks to regress heatmaps defined by distances from the intersecting lines. The intersection lines are the prescription lines prescribed by the technologists at the time of image acquisition using cardiac landmarks, and retrospectively identified from the spatial relationship. As the spatial relationship is self-contained in properly stored data, the need for additional manual annotation is eliminated. In addition, the interplay of multiple target planes predicted in a source view is utilized in a stacked hourglass architecture to gradually improve the regression. Then, a multi-view planning strategy is proposed to aggregate information from the predicted heatmaps for all the source views of a target plane, for a globally optimal prescription, mimicking the similar strategy practiced by skilled human prescribers. Results: The experiments include 181 CMR exams. Our system yields the mean angular difference and point-to-plane distance of 5.68 degrees and 3.12 mm, respectively. It not only achieves superior accuracy to existing approaches including conventional atlas-based and newer deep-learning-based in prescribing the four standard CMR planes but also demonstrates prescription of the first cardiac-anatomy-oriented plane(s) from the body-oriented scout.